
In den letzten Jahren haben sich Zeitreihendatenbanken von einer merkwürdigen Sache (hoch spezialisiert auf offene Überwachungssysteme (und an bestimmte Lösungen gebunden) oder Big-Data-Projekte) zu einem „Konsumgüter“ entwickelt. Auf dem Gebiet der Russischen Föderation gilt Yandex und ClickHouse ein besonderer Dank dafür. Wenn Sie bis zu diesem Zeitpunkt eine große Menge von Zeitreihendaten speichern mussten, mussten Sie entweder die Notwendigkeit akzeptieren, einen monströsen Hadoop-Stapel zu erstellen und ihn zu begleiten, oder mit systemspezifischen Protokollen kommunizieren.
Es könnte den Anschein haben, dass ein Artikel, über den TSDB verwendet werden sollte, 2019 nur aus einem Satz bestehen wird: „Verwenden Sie einfach ClickHouse“. Aber ... es gibt Nuancen.
In der Tat entwickelt sich ClickHouse aktiv weiter, die Benutzerbasis wächst und der Support ist sehr aktiv. Sind wir jedoch zu Geiseln des öffentlichen Erfolgs von ClickHouse geworden, der andere, möglicherweise effektivere / zuverlässigere Lösungen überschattet hat?
Anfang letzten Jahres haben wir mit der Verarbeitung unseres eigenen Überwachungssystems begonnen. Dabei stellte sich die Frage nach der Auswahl der geeigneten Datenbank zum Speichern von Daten. Ich möchte hier über die Geschichte dieser Wahl erzählen.
Erklärung des Problems
Zunächst das notwendige Vorwort. Warum brauchen wir ein eigenes Überwachungssystem und wie wurde es eingerichtet?
Wir haben 2008 mit der Bereitstellung von Support-Services begonnen, und bis 2010 wurde klar, dass es schwierig war, Daten zu Prozessen in der Client-Infrastruktur mit den damals existierenden Lösungen zu aggregieren (wir sprechen über, Gott vergebe mir, Cacti, Zabbix und die Entstehenden Graphit).
Unsere Hauptanforderungen waren:
- Unterstützung (zu dieser Zeit - Dutzende und in Zukunft - Hunderte) von Kunden innerhalb desselben Systems und gleichzeitig das Vorhandensein eines zentralisierten Alarmverwaltungssystems;
- Flexibilität bei der Verwaltung des Warnsystems (Eskalation von Warnungen zwischen Teilnehmern, Zeitplanabrechnung, Wissensdatenbank);
- die Möglichkeit einer tiefen Detaillierung von Grafiken (Zabbix zeichnete zu dieser Zeit Grafiken in Form von Bildern);
- Langzeitspeicherung einer großen Datenmenge (ein Jahr oder länger) und die Möglichkeit, diese schnell auszuwählen.
In diesem Artikel interessieren wir uns für den letzten Punkt.
Apropos Lagerung: Die Anforderungen waren wie folgt:
- Das System sollte schnell funktionieren.
- Es ist wünschenswert, dass das System über eine SQL-Schnittstelle verfügt.
- Das System muss stabil sein und eine aktive Benutzerbasis und Unterstützung haben (sobald wir die Notwendigkeit hatten, Systeme wie beispielsweise MemcacheDB, die wir nicht mehr entwickelt haben, oder den verteilten Speicher MooseFS zu unterstützen, dessen Bugtracker auf Chinesisch durchgeführt wurde: Wiederholung dieser Geschichte für unser Projekt wollte nicht);
- Korrespondenz mit dem CAP-Theorem: Konsistenz (erforderlich) - Die Daten müssen relevant sein. Wir möchten nicht, dass das Benachrichtigungsverwaltungssystem keine neuen Daten erhält und Warnungen über das Nichtankommen von Daten für alle Projekte ausgibt. Partitionstoleranz (notwendig) - Wir möchten keine Split-Brain-Systeme erhalten. Verfügbarkeit (nicht kritisch, bei einem aktiven Replikat) - Wir können im Falle eines Unfalls selbst mit einem Code zum Backup-System wechseln.
Seltsamerweise war MySQL damals die perfekte Lösung für uns. Unsere Datenstruktur war äußerst einfach: Server-ID, Zähler-ID, Zeitstempel und Wert; Die schnelle Abtastung heißer Daten wurde durch einen großen Pufferpool bereitgestellt, und die Abtastung historischer Daten wurde durch SSD bereitgestellt.
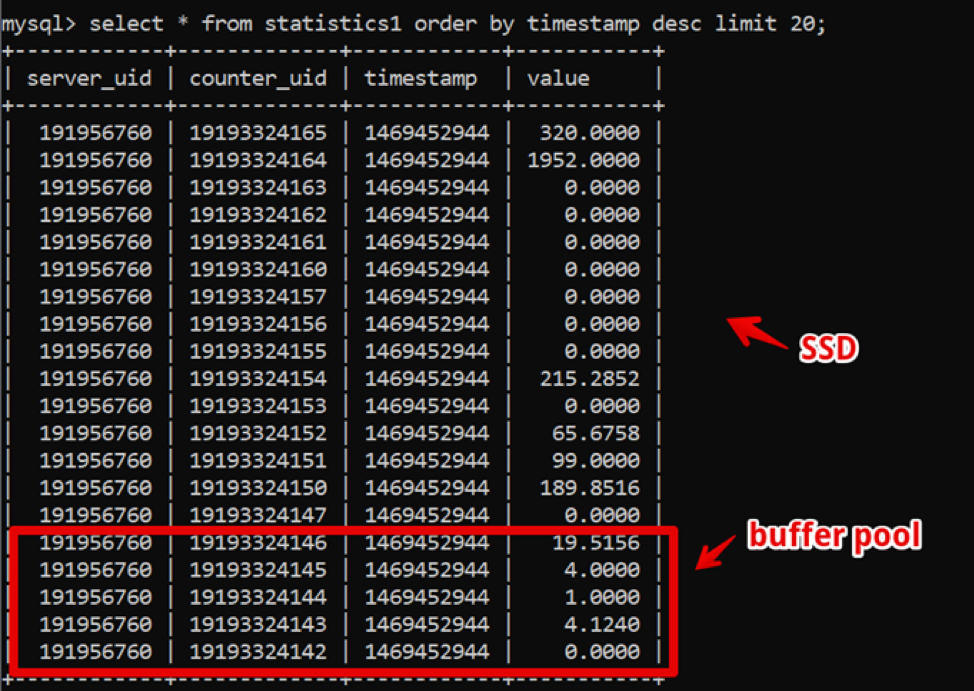
Auf diese Weise haben wir eine Stichprobe von neuen zweiwöchigen Daten mit einer Detaillierung von bis zu einer Sekunde 200 ms vor dem vollständigen Rendern der Daten erzielt und einige Zeit in diesem System gelebt.
In der Zwischenzeit verging die Zeit und die Datenmenge wuchs. Bis 2016 erreichte das Datenvolumen mehrere zehn Terabyte, was im Hinblick auf den geleasten SSD-Speicher einen erheblichen Aufwand darstellte.
Zu diesem Zeitpunkt verbreiteten sich Säulendatenbanken aktiv, worüber wir uns aktiv Gedanken machten: In Säulendatenbanken werden Daten, wie Sie verstehen, in Spalten gespeichert, und wenn Sie sich unsere Daten ansehen, ist es leicht, eine große Anzahl von Takes zu erkennen, die dies sein könnten Wenn Sie eine Spaltendatenbank verwenden, komprimieren Sie mit Komprimierung.
Das Schlüsselsystem für die Arbeit des Unternehmens funktionierte jedoch weiterhin stabil, und ich wollte nicht mit dem Übergang zu etwas anderem experimentieren.
2017, auf der Percona Live-Konferenz in San Jose, wahrscheinlich zum ersten Mal, dass sich die Clickhouse-Entwickler bekannt gaben. Auf den ersten Blick war das System produktionsbereit (Yandex.Metrica ist eine harte Produktion), der Support war schnell und einfach, und vor allem war die Bedienung einfach. Seit 2018 haben wir den Übergangsprozess gestartet. Zu diesem Zeitpunkt gab es jedoch viele „erwachsene“ und bewährte TSDB-Systeme, und wir beschlossen, viel Zeit zuzuweisen und Alternativen zu vergleichen, um sicherzustellen, dass es keine alternativen Clickhouse-Lösungen gemäß unseren Anforderungen gab.
Zusätzlich zu den bereits angegebenen Lagerungsanforderungen erschienen neue:
- Das neue System sollte mindestens die gleiche Leistung wie MySQL bei gleicher Eisenmenge bieten.
- Die Lagerung des neuen Systems sollte deutlich weniger Platz beanspruchen.
- DBMS sollte immer noch einfach zu verwalten sein.
- Ich wollte die Anwendung beim Ändern des DBMS minimieren.
Welche Systeme haben wir in Betracht gezogen?
Apache Hive / Apache ImpalaAlter ramponierter Hadoop-Stapel. Tatsächlich ist dies eine SQL-Schnittstelle, die auf dem Speichern von Daten in nativen Formaten in HDFS basiert.
Vorteile.
- Bei stabilem Betrieb ist es sehr einfach, die Daten zu skalieren.
- Es gibt Spaltenlösungen für die Datenspeicherung (weniger Speicherplatz).
- Sehr schnelle Ausführung paralleler Aufgaben bei Vorhandensein von Ressourcen.
Nachteile
- Dies ist ein Hadoop, und es ist schwierig zu bedienen. Wenn wir nicht bereit sind, eine vorgefertigte Lösung in der Cloud zu übernehmen (und wir sind nicht bereit für die Kosten), muss der gesamte Stapel von den Administratoren zusammengestellt und unterstützt werden, aber das möchte ich wirklich nicht.
- Daten werden sehr schnell aggregiert.
Allerdings:

Die Geschwindigkeit wird durch Skalieren der Anzahl der Computerserver erreicht. Einfach ausgedrückt, wenn wir ein großes Unternehmen sind, das sich mit Analytik und Geschäft befasst, ist es von entscheidender Bedeutung, Informationen so schnell wie möglich zu aggregieren (selbst auf Kosten einer großen Anzahl von Computerressourcen) - dies kann unsere Wahl sein. Aber wir waren nicht bereit, den Eisenpark zu vervielfachen, um die Aufgaben zu beschleunigen.
Druide / PinotSchon viel mehr über TSDB speziell, aber nochmal - Hadoop-Stack.
Es gibt einen
großartigen Artikel, in dem die Vor- und Nachteile von Druid und Pinot im Vergleich zu ClickHouse verglichen werden .
In wenigen Worten: Druide / Pinot sehen in Fällen besser aus als Clickhouse, in denen:
- Sie haben eine heterogene Natur der Daten (in unserem Fall erfassen wir nur Zeitreihen von Servermetriken, und tatsächlich ist dies eine Tabelle. Es kann aber auch andere Fälle geben: Gerätezeitreihen, wirtschaftliche Zeitreihen usw. - jede mit ihrer eigenen Struktur, die aggregiert und verarbeitet werden müssen).
- Darüber hinaus gibt es viele dieser Daten.
- Tabellen und Daten mit Zeitreihen werden angezeigt und ausgeblendet (dh es wurde eine Art Datensatz eingegeben, der analysiert und gelöscht wurde).
- Es gibt kein klares Kriterium, nach dem Daten partitioniert werden können.
In entgegengesetzten Fällen zeigt sich ClickHouse besser, und dies ist unser Fall.
Clickhouse- SQL-ähnlich.
- Einfach zu verwalten.
- Die Leute sagen, dass es funktioniert.
Es fällt in die engere Auswahl der Tests.
InfluxdbAusländische Alternative zu ClickHouse. Von den Minuspunkten: Hochverfügbarkeit ist nur in der kommerziellen Version vorhanden, muss aber verglichen werden.
Es fällt in die engere Auswahl der Tests.
CassandraEinerseits wissen wir, dass es zum Speichern metrischer Zeitreihen von Überwachungssystemen wie beispielsweise
SignalFX oder OkMeter verwendet wird. Es gibt jedoch Besonderheiten.
Cassandra ist keine Spaltendatenbank im üblichen Sinne. Es sieht eher wie ein Kleinbuchstabe aus, aber jede Zeile kann eine andere Anzahl von Spalten haben, wodurch es einfach ist, eine Spaltendarstellung zu organisieren. In diesem Sinne ist es klar, dass Sie mit einem Limit von 2 Milliarden Spalten einige Daten in den Spalten speichern können (ja, dieselbe Zeitreihe). In MySQL gibt es beispielsweise eine Begrenzung für 4096 Spalten, und es ist leicht, auf einen Fehler mit Code 1117 zu stoßen, wenn Sie versuchen, dasselbe zu tun.
Die Cassandra-Engine konzentriert sich auf das Speichern großer Datenmengen in einem verteilten System ohne Assistenten, und im obigen CAP-Theorem geht es bei Cassandra mehr um AP, dh um die Zugänglichkeit von Daten und den Widerstand gegen Partitionierung. Daher kann dieses Tool großartig sein, wenn Sie nur in diese Datenbank schreiben und selten daraus lesen müssen. Und hier ist es logisch, Cassandra als "kalten" Speicher zu verwenden. Das heißt, als langfristig zuverlässiger Ort zum Speichern großer Mengen historischer Daten, die selten benötigt werden, aber bei Bedarf abgerufen werden können. Der Vollständigkeit halber werden wir es dennoch testen. Wie ich bereits sagte, besteht jedoch kein Wunsch, den Code für die ausgewählte DB-Lösung aktiv neu zu schreiben. Daher werden wir ihn etwas eingeschränkt testen - ohne die Datenbankstruktur an die Besonderheiten von Cassandra anzupassen.
PrometheusAus Interesse haben wir uns entschlossen, die Leistung des Prometheus-Stores zu testen - nur um zu verstehen, ob und wie viel wir schneller als aktuelle Lösungen oder langsamer sind.
Methodik und Testergebnisse
Daher haben wir 5 Datenbanken in den folgenden 6 Konfigurationen getestet: ClickHouse (1 Knoten), ClickHouse (verteilte Tabelle mit 3 Knoten), InfluxDB, MySQL 8, Cassandra (3 Knoten) und Prometheus. Der Testplan lautet wie folgt:
- Geben Sie die historischen Daten für die Woche ein (840 Millionen Werte pro Tag; 208.000 Metriken).
- eine Aufzeichnungslast erzeugen (6 Lastmodi wurden berücksichtigt, siehe unten);
- Parallel zur Aufzeichnung erstellen wir regelmäßig Stichproben, die die Anforderungen eines Benutzers emulieren, der mit Diagrammen arbeitet. Um die Sache nicht zu kompliziert zu machen, haben wir Daten mit 10 Metriken (genauso viele davon im CPU-Diagramm) pro Woche ausgewählt.
Wir laden, indem wir das Verhalten unseres Überwachungsagenten emulieren, der alle 15 Sekunden Werte an jede Metrik sendet. In diesem Fall sind wir daran interessiert zu variieren:
- Gesamtzahl der Metriken, in die Daten geschrieben werden;
- Intervall des Sendens von Werten in einer Metrik;
- Chargengröße.
Über die Größe der Charge. Da fast nicht empfohlen wird, fast alle unsere experimentellen Basen mit einzelnen Einfügungen zu laden, benötigen wir ein Relais, das eingehende Metriken sammelt, sie so weit wie möglich gruppiert und sie mit einer Paketeinfügung in die Basis schreibt.
Stellen Sie sich zum besseren Verständnis der späteren Interpretation der empfangenen Daten vor, dass wir nicht nur eine Reihe von Metriken senden, sondern die Metriken in Servern organisiert sind - 125 Metriken pro Server. Hier ist der Server nur eine virtuelle Entität - nur um zu verstehen, dass beispielsweise 10.000 Metriken ungefähr 80 Servern entsprechen.
Und so, unter Berücksichtigung all dessen, unsere 6 Aufzeichnungslademodi der Basis:
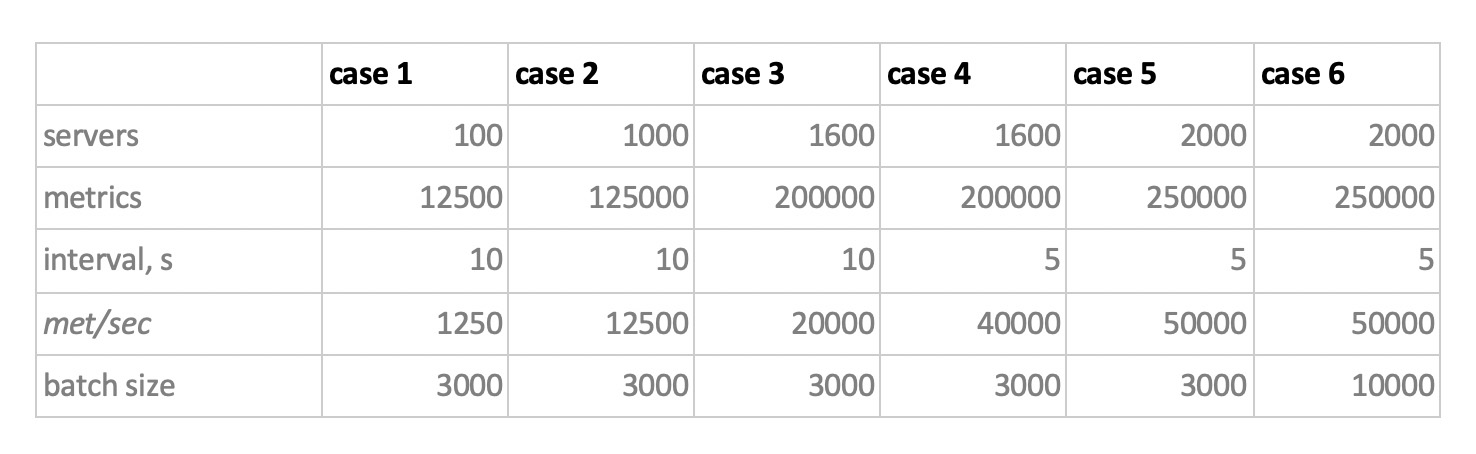
Es gibt zwei Punkte. Erstens haben sich für Cassandra solche Chargengrößen als zu groß herausgestellt, dort haben wir Werte von 50 oder 100 verwendet. Und zweitens, da der Prometeus streng im Pull-Modus arbeitet, d.h. Er geht und sammelt Daten aus metrischen Quellen (und selbst Pushgateway ändert trotz des Namens die Situation nicht grundlegend). Die entsprechenden Lasten wurden mithilfe einer Kombination statischer Konfigurationen implementiert.
Die Testergebnisse sind wie folgt:
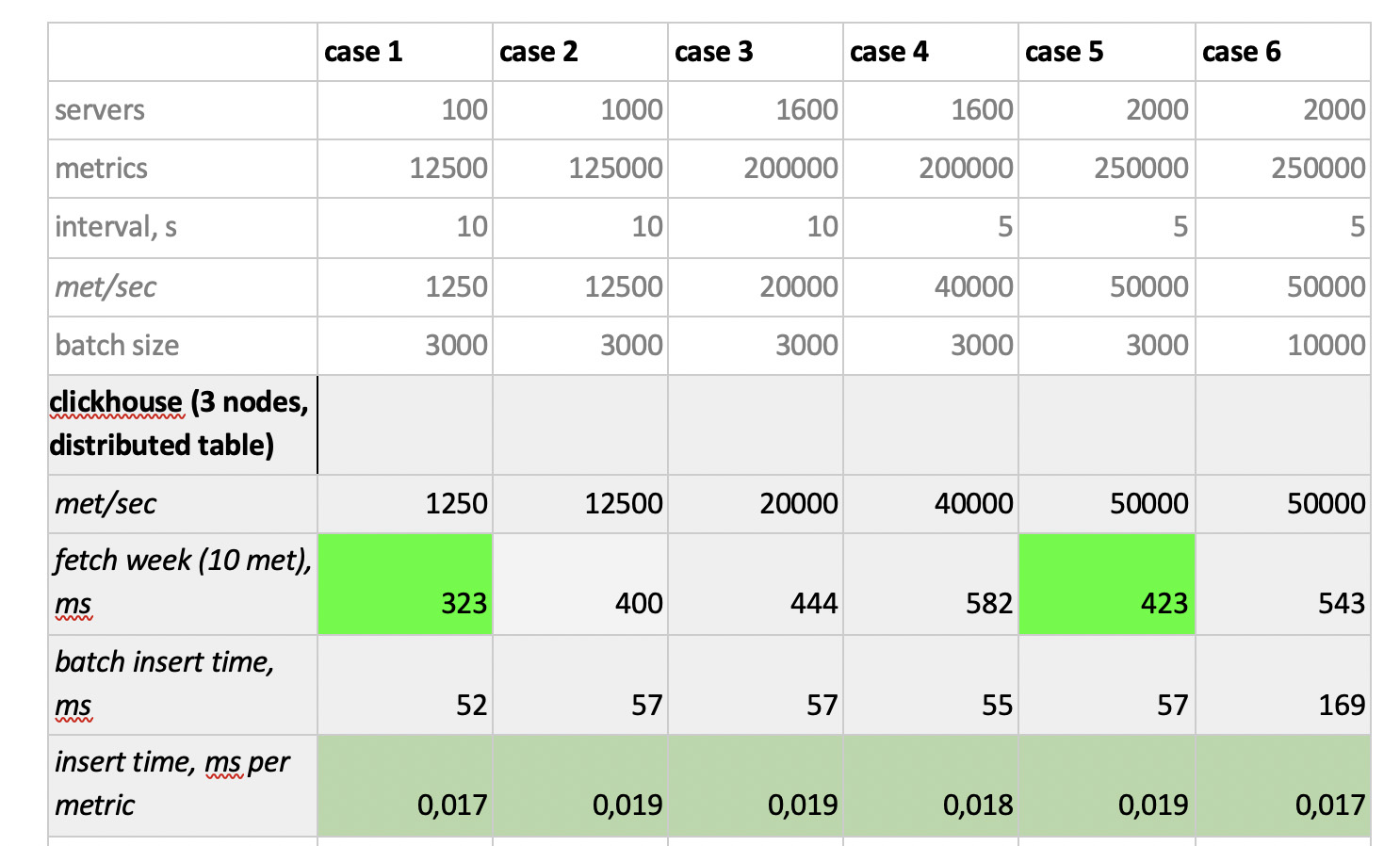
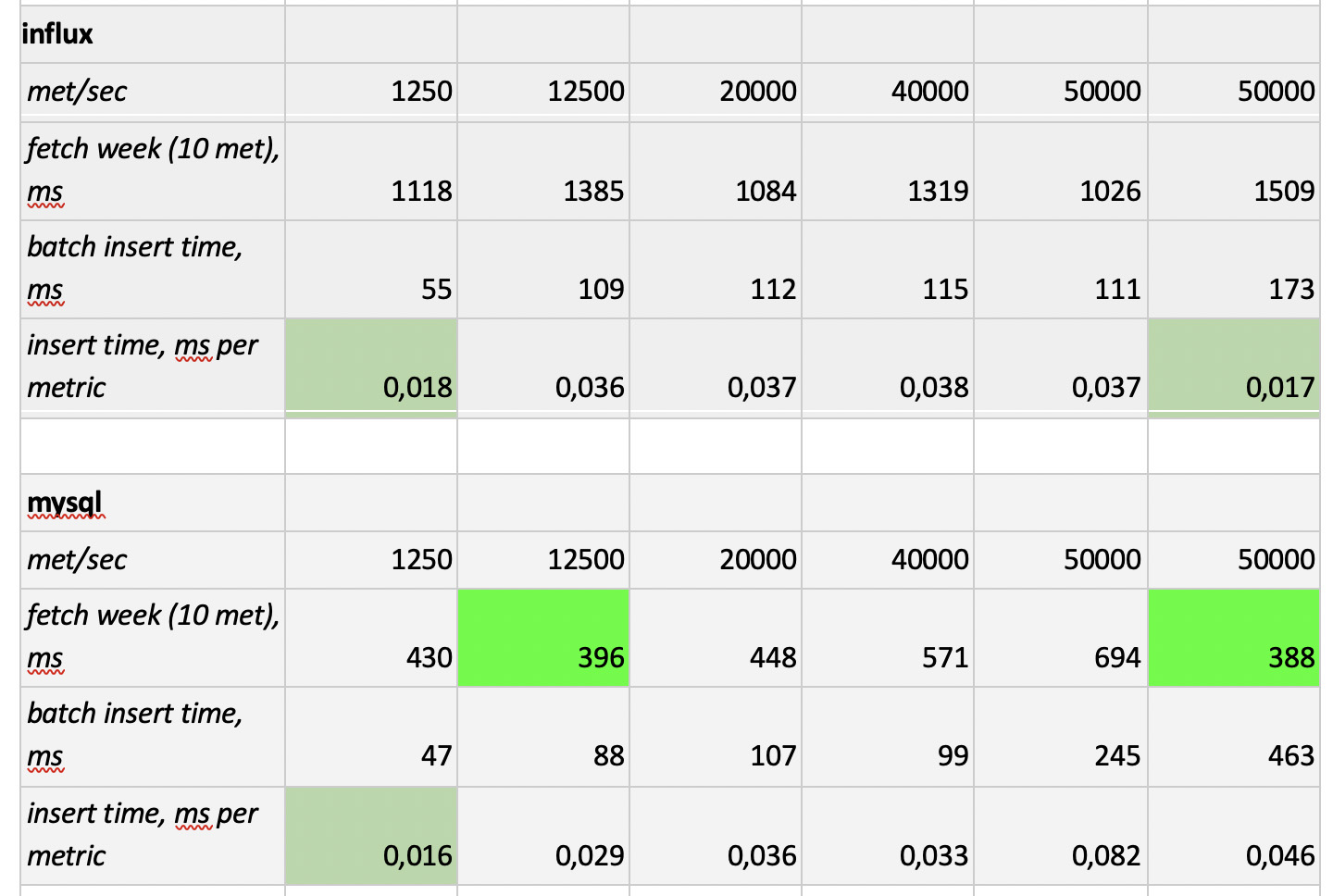
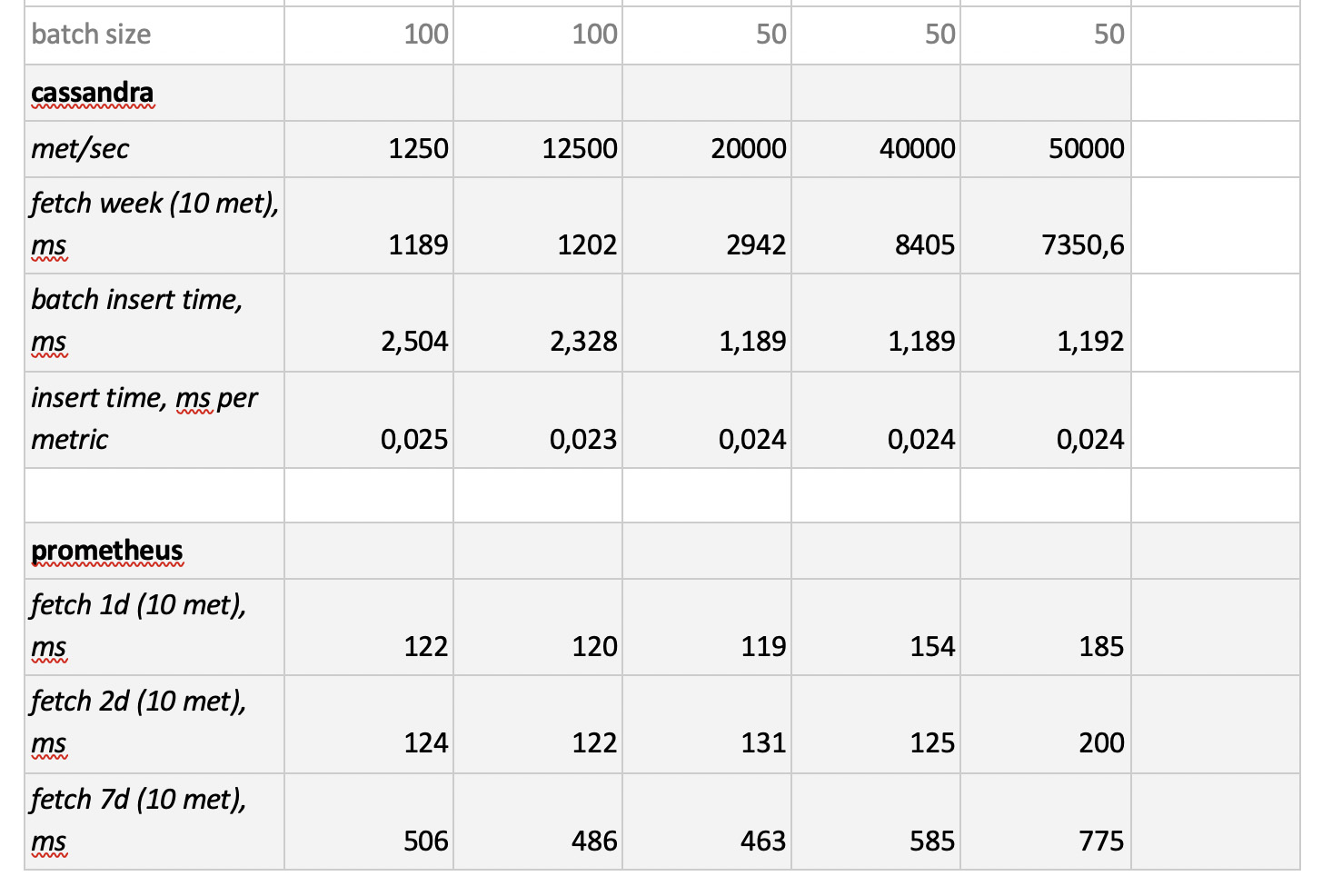 Was erwähnenswert ist
Was erwähnenswert ist : fantastisch schnelle Samples von Prometheus, furchtbar langsame Samples von Cassandra, unannehmbar langsame Samples von InfluxDB; ClickHouse hat in Bezug auf die Aufnahmegeschwindigkeit gewonnen, und Prometheus nimmt nicht am Wettbewerb teil, da es in sich selbst einfügt und wir nichts messen.
Als Ergebnis : ClickHouse und InfluxDB haben sich am besten gezeigt, aber ein Cluster von Influx kann nur auf der Basis der Enterprise-Version erstellt werden, die Geld kostet, und ClickHouse kostet nichts und wird in Russland hergestellt. Es ist logisch, dass in den USA die Wahl wahrscheinlich zugunsten von inInfluxDB und in unserem Fall zugunsten von ClickHouse getroffen wird.