Dies ist eine englischsprachige Zusammenfassung von zwei absolut herausragenden Artikeln von
Vitaliy Malkin aus "Informzashita", dessen Team True0xA3 im Mai 2019 während der
Positive Hack Days 9 die Gewinner des prestigeträchtigen Black Hat-Wettbewerbs The Standoff wurde.
Vitaliy hat drei detaillierte Artikel über Habr veröffentlicht, von denen zwei der Beschreibung der Strategien gewidmet waren, die das True0xA3-Team vor und während des Wettbewerbs angewendet hat, um diesem Team den Titel der Gewinner zu sichern. Ich hatte das Gefühl, dass das einzige, was diesen beiden Artikeln fehlte, eine Zusammenfassung auf Englisch war, damit ein breiteres Publikum von Lesern sie genießen konnte. Im Folgenden finden Sie eine Zusammenfassung von zwei Artikeln von
Vitaliy Malkin sowie Bilder, die Vitaliy veröffentlicht hat, um seine Punkte zu verdeutlichen. Vitaliy hat mir erlaubt, die Übersetzung zu machen und sie zu veröffentlichen.
TEIL I. Vorbereitung auf die Schlacht
Originalartikel ist hierI. Anfangsziele
Das Team bestand aus 16 bewährten Pentestern und 4 Praktikanten, die mit 6 Servern und unserer eigenen CUDA-Station bewaffnet waren, sowie der Bereitschaft, die Distanz zu gehen.
Die aktiven Vorbereitungen begannen 8 Tage vor Beginn von The Standoff. Dies war unser dritter Versuch, The Standoff zu gewinnen. Einige von uns hatten also genug Erfahrung, um zu wissen, was zu tun war. Von Anfang an haben wir die folgenden Prioritäten für das Team besprochen:
- Reibungslose Koordination zwischen den Teammitgliedern
- Sammlung von niedrig hängenden Früchten
- Ausnutzung von für uns nicht typischen Schwachstellen wie automatisierten Prozessleitsystemen (APCS), verteilten Kontrollsystemen (DCS), IoT und GSM
- Unsere eigene Infrastruktur und Ausrüstung im Voraus einrichten
- Entwicklung einer Strategie für Persistenz und Verhärtung
Koordination:
Dies ist die Schwäche aller Neulinge im Standoff: Aufgaben werden nicht effektiv verteilt; Mehrere Personen arbeiten an derselben Aufgabe. Es ist nicht klar, welche Aufgaben bereits erledigt wurden. Ergebnisse einer Aufgabe werden nicht an die richtigen Mitglieder des Teams usw. weitergeleitet. Je größer das Team ist, desto weniger effektiv ist die Koordination zwischen den Teammitgliedern. Am wichtigsten ist, dass es mindestens eine Person gibt, die das gesamte Bild vom Standpunkt der Infrastruktur aus versteht und mehrere Schwachstellen in einem fokussierten Angriffsvektor zusammenfassen kann.
In diesem Jahr haben wir die Kollaborationsplattform Discord verwendet. Es ähnelt dem IRC-Chat, bietet jedoch zusätzliche Funktionen wie das Hochladen von Dateien und Sprachanrufe. Für jedes Ziel in der Standoff-Karte haben wir einen separaten Kanal erstellt, in dem alle Daten gesammelt werden. Auf diese Weise kann ein neues Teammitglied, das einer Aufgabe zugewiesen ist, problemlos alle Informationen anzeigen, die bereits für diese Aufgabe gesammelt wurden, die Ergebnisse der Bereitstellungen usw. Alle Infokanäle hatten ein Limit von 1 Nachricht pro Minute, um Überschwemmungen zu verhindern. Jedes Objekt im Standoff hatte einen eigenen Chat-Bereich.
Jedes Mitglied des Teams erhielt einen klar definierten Arbeitsumfang. Um die Koordination zu verbessern, wurde eine Person beauftragt, endgültige Entscheidungen über alle Aufgaben zu treffen. Dies hinderte uns daran, während des Wettbewerbs in lange Diskussionen und Meinungsverschiedenheiten zu geraten.
Tief hängende Früchte sammeln
Ich glaube, der wichtigste Faktor im Spiel war die Fähigkeit, mehrere Projekte zu verwalten und Ziele richtig zu priorisieren. Im letztjährigen Spiel konnten wir ein Büro übernehmen und dort bleiben, einfach weil wir bekannte Schwachstellen ausgenutzt haben. In diesem Jahr haben wir beschlossen, vorab eine Liste solcher Schwachstellen zu erstellen und unser Wissen zu organisieren:
ms17-010; ms08-67; SMBCRY LibSSH RCE; HP DATA Protectoer; HP iLo; ipmi Cisco Smart Install Java RMI JDWP; JBOSS; drupalgeddon2; Weblogic Herzblut Muschelschock; IBM Websphere iis-webdav; Dienstleistungen; vnc; ftp-anon; NFS smb-null; KaterAnschließend haben wir zwei Dienste erstellt, Checker und Penetrator, die das Testen auf Schwachstellen und die Bereitstellung der öffentlich verfügbaren Exploits und Metasploits automatisierten. Die Dienste nutzten die Ergebnisse von nmap, um unsere Arbeit zu beschleunigen.
Ausnutzung von für uns nicht typischen Schwachstellen
Wir hatten nicht viel Erfahrung mit der Analyse von Schwachstellen von automatisierten Prozessleitsystemen (APCS). Ungefähr 8 Tage vor dem Standoff haben wir begonnen, uns mit dem Thema zu befassen. Die Situation mit IoT und GSM war noch schlimmer. Wir hatten nie Erfahrung mit diesen Systemen außerhalb der vorherigen Standoffs.
Daher haben wir in der Vorbereitungsphase zwei Personen ausgewählt, um automatisierte Prozessleitsysteme (APCS) zu studieren, und zwei weitere, um GSM und IoT zu studieren. Das erste Team innerhalb einer Woche erstellte eine Liste typischer Ansätze zum Pentesting der SCADA-Systeme und untersuchte Details von Videos der Infrastruktur des Vorjahres innerhalb des Standoffs. Sie haben außerdem ungefähr 200 GB verschiedener HMI-, Treiber- und anderer Software für die Controller heruntergeladen. Das IoT-Team bereitete Hardware vor und las alle verfügbaren Artikel zu GSM. Wir hofften es würde reichen (Spoiler Alarm: war es nicht!)
Aufbau unserer eigenen Infrastruktur und Ausrüstung
Da wir ein ziemlich großes Team hatten, beschlossen wir, zusätzliche Ausrüstung zu benötigen. Das haben wir mitgenommen:
- CUDA-Server
- Backup-Laptop
- WLAN-Router
- Wechseln
- Vielzahl von Netzwerkkabeln
- WiFi Alfa
- Gummiente
Letztes Jahr haben wir verstanden, wie wichtig die Verwendung von CUDA-Servern beim Hacken einiger Handshakes ist. Es ist wichtig zu beachten, dass dieses Jahr wie auch in den Vorjahren alle roten Teammitglieder hinter einem NAT standen, sodass wir keine Reverse-Connectes von DMZ verwenden konnten. Wir gingen jedoch davon aus, dass alle Hosts außer Automated Process Control Systems (APCS) über eine Internetverbindung verfügen würden. Vor diesem Hintergrund haben wir uns entschlossen, drei Server-Listener zu starten, die über das Internet verfügbar sind. Um das Schwenken zu vereinfachen, haben wir unseren eigenen OpenVPN-Server mit aktiviertem Client-zu-Client verwendet. Leider war eine automatisierte Erstellung von Kanälen nicht möglich, daher widmete sich eines von 28 Teammitgliedern 12 Stunden lang nur der Verwaltung der Kanäle.
Entwicklung einer Strategie für Persistenz und Verhärtung
Unsere bisherigen Erfahrungen mit dem Standoff haben uns bereits gelehrt, dass es nicht ausreicht, einen Server zu übernehmen. Ebenso wichtig war es, zu verhindern, dass auch andere Teams Fuß fassen. Daher haben wir viel Zeit mit dem RAT (Remote Administration Tool) mit neuen Signaturen und Skripten verbracht, um Windows-Systeme zu härten. Wir haben eine Standard-RAT verwendet, aber die Verschleierungsmethode geringfügig geändert. Die Regeln stellten eine größere Schwierigkeit dar. Insgesamt haben wir die folgende Liste von Skripten entwickelt:
- Schließen der SMB- (Server Message Block) und RPC-Ports (Remote Procedure Call)
- Verschieben von RDP (Remotedesktopprotokoll) auf nicht standardmäßige Ports
- Deaktivieren der reversiblen Verschlüsselung, der Gastkonten und anderer typischer Probleme der Sicherheitsgrundlinie
Für Linux-Systeme haben wir ein spezielles Init-Skript entwickelt, das alle Ports geschlossen, SSH auf einen nicht standardmäßigen Port verschoben und öffentliche Schlüssel für den Zugriff des Teams auf SSH erstellt hat
II. Briefing
Am 17. Mai, 5 Tage vor dem Standoff, stellten die Organisatoren das Briefing für die roten Teams bereit. Sie lieferten viele Informationen, die unsere Vorbereitung beeinflussten. Sie veröffentlichten die Karte des Netzwerks, mit der wir das Netzwerk in Zonen unterteilen und einem Teammitglied Verantwortlichkeiten für jede Zone zuweisen konnten. Die wichtigste Information, die die Organisatoren zur Verfügung stellten, war, dass APCS nur von einem Segment des Netzwerks aus zugänglich ist und dieses Segment nicht geschützt ist. Darüber hinaus wurde bekannt gegeben, dass die höchsten Punkte für das APCS und für die gesicherten Büros vergeben werden. Sie sagten auch, dass sie die Fähigkeit roter Teams belohnen würden, sich gegenseitig aus dem Netzwerk zu werfen.
Wir haben dies so interpretiert: "Wer die Bigbrogroup erobert, wird wahrscheinlich das Spiel gewinnen." Dies liegt daran, dass wir aufgrund unserer früheren Erfahrungen gelernt haben, dass die blauen Teams die anfälligen Server töten, unabhängig davon, wie die Organisatoren den Serviceverlust bestrafen, wenn sie sie nicht schnell genug patchen können. Dies liegt daran, dass ihre jeweiligen Unternehmen sich viel mehr Sorgen um die Werbung eines völlig gehackten Systems machen als um einige verlorene Punkte in einem Spiel. Unsere Vermutung war richtig, wie wir bald sehen werden.
Aus diesem Grund haben wir beschlossen, das Team in vier Teile zu unterteilen:
I. Bigbrogroup . Wir haben uns entschlossen, diese Aufgabe vor allen anderen zu priorisieren, und haben unsere erfahrensten Pentester in diese Gruppe aufgenommen. Dieses Miniteam bestand aus 5 Personen. Sein Hauptziel war es, die Domain zu übernehmen und zu verhindern, dass andere Teams Zugang zum APCS erhalten.
II. Drahtlose Netzwerke . Dieses Team war dafür verantwortlich, Wifi zu beobachten, neue WAPs zu verfolgen, die Handshakes zu erfassen und sie brutal zu erzwingen. Sie waren auch für das APS verantwortlich, aber ihr Hauptziel war es, andere Teams daran zu hindern, Wifi zu übernehmen
III. Ungeschützte Netzwerke . Dieses Team verbrachte die ersten 4 Stunden damit, alle ungeschützten Netzwerke zu testen und Schwachstellen zu analysieren. Wir haben verstanden, dass in den ersten 4 Stunden in den geschützten Segmenten nichts Interessantes passieren konnte, zumindest nichts, was blaue Teams nicht abschlagen konnten. Deshalb haben wir beschlossen, diese ersten Stunden damit zu verbringen, die ungeschützten Netzwerke zu schützen, in denen Dinge geändert werden könnten. Und wie sich herausstellte, war es ein guter Ansatz.
IV. Scannergruppe . Die blauen Teams teilten uns im Voraus mit, dass sich die Netzwerktopologie ständig ändern wird. Daher haben wir zwei Personen für das Scannen des Netzwerks und das Erkennen von Änderungen eingesetzt. Die Automatisierung dieses Prozesses erwies sich als schwierig, da wir mehrere Netzwerke mit mehreren Einstellungen hatten. Zum Beispiel funktionierte unsere nmap in der ersten Stunde im T3-Modus, aber gegen Mittag funktionierte sie kaum im T1-Modus.
Ein weiterer wichtiger Vektor war die Liste der Software und Technologien, die die Organisatoren während des Briefings zur Verfügung stellten. Wir haben für jede der Technologien eine Kompetenzgruppe erstellt, mit der die typischen Schwachstellen schnell bewertet werden können. Bei einigen Diensten wurden bekannte Sicherheitslücken gefunden, es konnten jedoch keine veröffentlichten Exploits gefunden werden. Dies war beispielsweise bei Redis Post-Exploitation RCE der Fall. Wir waren uns ziemlich sicher, dass diese Sicherheitsanfälligkeit in der Standoff-Infrastruktur vorhanden sein würde, daher haben wir beschlossen, unseren eigenen 1-Tages-Exploit zu schreiben. Natürlich konnten wir nicht den gesamten Exploit schreiben, aber insgesamt haben wir 5 unveröffentlichte Exploits gesammelt, die wir bereitstellen konnten.
Leider konnten wir nicht alle Technologien untersuchen, aber es stellte sich als nicht so kritisch heraus. Da wir die mit der höchsten Priorität untersucht haben, hat es sich als ausreichend erwiesen. Wir haben auch die Liste der Controller für APCS erstellt, die wir ebenfalls eingehend untersucht haben.
Während der Vorbereitungsphase haben wir verschiedene Tools für die Schleichverbindung zum APCS-Netzwerk gesammelt. Zum Beispiel haben wir eine billige Version einer Ananas mit einer Himbeere vorbereitet. Es würde eine Verbindung zum Ethernet des Produktionsnetzwerks und über GSM zum Steuerungsdienst herstellen. Wir könnten dann eine Ethernet-Verbindung remote konfigurieren und sie dann über ein eingebautes WLAN-Modul senden. Leider haben die Organisatoren während des Spiels klargestellt, dass eine physische Verbindung zum APCS verboten ist, sodass wir das Modul letztendlich nicht verwenden konnten.
Wir haben eine Menge Informationen über die Arbeit der Bank, Offshore-Konten und den Betrug gefunden. Wir haben jedoch auch herausgefunden, dass die Bank nicht so viel Geld hat, also haben wir beschlossen, keine Zeit damit zu verbringen, uns auf dieses Objekt vorzubereiten, und es während des Spiels nur nach Gehör zu spielen.
Zusammenfassend haben wir in der Vorbereitungsphase viel Arbeit geleistet. Ich möchte darauf hinweisen, dass wir neben dem offensichtlichen Vorteil, Gewinner des Standoff-Wettbewerbs zu sein, weniger auffällige, aber nicht weniger wichtige Vorteile erzielt haben, wie z
- Wir machten eine Pause von der täglichen Arbeit und versuchten etwas, auf das wir lange gehofft hatten
- Dies war unsere erste Erfahrung, bei der das gesamte Pentesting-Team an einer einzigen Aufgabe arbeitete, sodass der Teambuilding-Effekt sehr spürbar war
- Viele der Informationen, die wir während der Vorbereitung des Spiels gesammelt haben, können wir für unsere realen Pentesting-Projekte verwenden. Wir haben unser Kompetenzniveau erhöht und neue, gebrauchsfertige Tools entwickelt
Rückblickend stelle ich fest, dass unser Sieg im Standoff wahrscheinlich lange vor Spielbeginn in der Vorbereitungsphase gesichert war. Was nun tatsächlich während des Standoffs passiert ist, wird in Teil II dieser Serie beschrieben
Teil II. Den Standoff gewinnen. Die Lifehacks teilen
Der Originalartikel ist hierVon Vitaliy Malkin, dem Leiter des roten Teams der Firma InformZachita und dem Kapitän des True0xA3-Teams. True0xA3 gewann einen der prestigeträchtigsten White-Hat-Wettbewerbe in Russland - den Standoff an den PHDays 2019.
Tag eins
9:45 MSKDer Tag begann mit dem Erhalt der Ergebnisse des MassScan. Wir haben zunächst alle Hosts mit 445 geöffneten Ports aufgelistet und genau um 10 Uhr den Checker für den Metasploit MS17-010 bereitgestellt. Nach unserem Plan war es unser Hauptziel, den Domain-Controller der Domain-Bigbrogroup zu erfassen, daher waren 2 Personen aus unserem Team genau dem gewidmet. Unten sehen Sie die anfänglichen Zuordnungen für jede Gruppe.
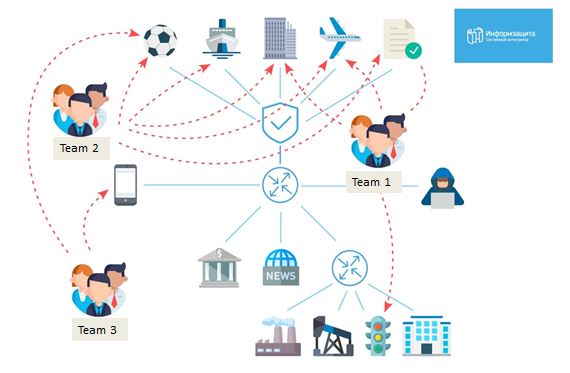
Wie Sie sehen, haben wir versucht, jedes Büro im Spiel zu durchdringen, und die Tatsache, dass wir 20 Leute hatten, machte einen großen Unterschied.
10:15Eines der Teammitglieder von Team1 findet einen Host in der Domäne bigbrogroup.phd, der für MS17-010 anfällig ist. Wir haben den Exploit in großer Eile eingesetzt. Vor ein paar Jahren hatten wir die Situation, dass wir die Meterpreter-Shell (Phishing-Angriff mit dem Remote-Ausführungscode) auf ein wichtiges Ziel bringen konnten, aber innerhalb von 10 Sekunden aus dem System geworfen wurden. Dieses Jahr waren wir besser vorbereitet. Wir übernehmen den Host, schließen den SMB-Port und ändern das RDP in Port 50002. Wir achten sehr auf den Persistenzprozess in der Domäne. Daher erstellen wir einige lokale Administratorkonten und stellen unsere eigenen Remote Administration Tools (RAT) bereit. . Erst danach gingen wir zur nächsten Aufgabe über
10:25Wir gehen weiterhin die Ergebnisse der Informationen durch, die wir vom Gastgeber gesammelt haben. Neben dem Zugriff auf das interne Netzwerk und der Verbindung zum Domänencontroller finden wir auch das Token des Domänenadministrators. Bevor wir uns zu sehr darüber aufregen, prüfen wir, ob das Token noch gültig ist. Und dann freuen wir uns. Erste Domain ist gefallen. Die Gesamtzeit beträgt 27 Minuten und 52 Sekunden
Eine halbe Stunde nach dem Start besuchen wir das Spielerportal, um die Regeln für das Einreichen von Flaggen und das Erhalten von Punkten zu verstehen. Wir sehen die Standardliste: die Domain-Administrator-Logins, lokalen Administratoren, Exchange-Administratoren und einige andere Administratoren. Von der Domain laden wir ntds.dit herunter und bereiten gleichzeitig unsere CUDA-Station vor. Dann stellen wir fest, dass dies eine reversible Verschlüsselung in der Domäne ist, sodass wir jetzt alle benötigten Passwörter erhalten können. Um zu verstehen, welche Passwörter wir benötigen, bilden wir ein Team von 2 Personen, die mit der Analyse der Struktur des AD und seiner Gruppen beginnen. 5 Minuten später geben sie die Ergebnisse ab. Wir geben unsere Fahnen ab und warten. Es war an der Zeit, unser erstes Blut zu holen, zumindest um die Moral des Teams zu verbessern, wenn nichts anderes. Aber nichts. Wir haben eine Stunde gebraucht, um zu verstehen, dass der Checker so funktioniert:
- Es ist automatisiert
- Es hat ein sehr unflexibles Format
- Wenn Sie Ihre Flags auf den Scheck stellen und innerhalb weniger Sekunden keine Antwort erhalten haben, stimmt Ihr Format nicht mit dem Format des Prüfers überein
Schließlich finden wir das richtige Format heraus und gegen 11 Uhr bekommen wir unser erstes Blut. Puh!
11:15Team 1 wird in zwei Unterteams aufgeteilt. Subteam 1 stärkt die Domäne weiterhin: Sie erhalten krbtgt, härten die Baseline und ändern Kennwörter für die Verzeichnisdienste. Die Standoff-Organisatoren sagten uns während des Briefings, dass die ersten auf der Domain spielen dürfen, wie sie wollen. Daher ändern wir die Administratorkennwörter so, dass selbst wenn jemand hereinkommt und es schafft, uns rauszuschmeißen, er nicht in der Lage ist, die Anmeldungen dazu zu bringen, seine Flaggen für Punkte abzugeben.
Team 2 untersucht weiterhin die Domänenstruktur und findet ein anderes Flag. Auf dem Desktop des CFO finden sie einen Finanzbericht. Leider ist es komprimiert und passwortgeschützt. Also schalten wir die CUDA-Station ein. Wir verwandeln den Reißverschluss in einen Hash und senden ihn an Hashcat.
Team 2 findet weiterhin interessante Dienste mit RCE (Remote Code Execution) und beginnt, diese zu untersuchen. Einer davon ist ein Überwachungsdienst für die Domain cf-media, die auf der Basis von Nagios basiert. Ein anderer ist der Fahrplanmanager einer Reederei, die auf einer seltsamen Technologie basiert, die wir noch nie gesehen haben. Es gibt auch einige interessante Dienste wie DOC-zu-DPF-Wandler.
Das zweite Subteam von Team 1 hat zu diesem Zeitpunkt bereits begonnen, an der Bank zu arbeiten, und in MongoDB eine interessante Datenbank gefunden, die unter anderem den Namen unseres Teams und anderer Teams sowie deren Guthaben enthält. Wir ändern die Bilanz unseres Teams auf 50 Millionen und gehen weiter.
14.00 UhrDas Glück hat uns verlassen. Erstens waren die beiden Dienste, für die wir RCE in den geschützten Segmenten hatten, nicht mehr verfügbar. Das blaue Team hat sie einfach ausgeschaltet. Natürlich beschweren wir uns bei den Organisatoren über Regelverstöße, aber ohne Wirkung. Im Standoff sind keine Geschäftsprozesse zu schützen! Zweitens können wir keine Kundenliste finden. Wir vermuten, dass es irgendwo in den Tiefen von 1C versteckt ist, aber wir haben keine Datenbanken, keine Konfigurationsdateien. Sackgasse.
Wir versuchen, den VPN-Kanal zwischen unseren Remote-Servern und den Automated Process Control Systems (APCS) einzurichten. Aus irgendeinem seltsamen Grund tun wir dies nicht auf dem Domänencontroller von bigbrogroup, und die Verbindung zwischen den Schnittstellen wird unterbrochen. Jetzt ist der Domänencontroller nicht mehr zugänglich. Der Teil des Teams, der für den Zugriff auf die Domain verantwortlich ist, erleidet fast einen Herzinfarkt. Die Spannung zwischen den Teammitgliedern wächst, das Zeigen mit dem Finger beginnt.
Dann stellen wir fest, dass auf den Domänencontroller zugegriffen werden kann, die VPN-Verbindung jedoch instabil ist. Wir gehen unsere Schritte vorsichtig zurück, schalten über RDP das VPN aus und voila, der Domänencontroller ist wieder erreichbar. Das Team atmet gemeinsam aus. Am Ende haben wir das VPN von einem anderen Server aus eingerichtet. Der Domänencontroller wird babysittet und verwöhnt. Alle teilnehmenden Teams haben noch 0 Punkte, und das ist beruhigend.
16:50Die Organisatoren veröffentlichen schließlich einen Bergmann. Mit psexec richten wir es auf allen Endpunkten ein, die wir steuern. Dies führt zu einem stetigen Einkommensfluss.
Team 2 arbeitet noch an der Nagios-Sicherheitslücke. Sie haben die Version mit der Sicherheitslücke
<= 5.5.6 CVE-2018-15710 CVE-2018-15708. Ein öffentlicher Exploit ist verfügbar, benötigt jedoch eine Reverse-Verbindung, um die Web-Shell herunterzuladen. Da wir hinter dem NAT stehen, müssen wir den Exploit neu schreiben und in zwei Teile teilen. Der erste Teil zwingt Nagios, über das Internet eine Verbindung zu unserem Remote-Server herzustellen, und der zweite Teil, der sich auf dem Server selbst befindet, gibt Nagios die Web-Shell. Dadurch erhalten wir über einen Proxy Zugriff auf die cf-media-Domäne. Da die Verbindung jedoch instabil und schwierig zu verwenden ist, beschließen wir, den Exploit für die BugBounty-Dollars zu verkaufen und gleichzeitig zu versuchen, unseren Zugriff auf root zu verbessern.
18:07Hier kommen die versprochenen "Überraschungen" der Veranstalter. Sie geben bekannt, dass BigBroGroup gerade CF-Media gekauft hat. Wir sind nicht schrecklich überrascht. Bei unserer Untersuchung der Domäne bigbrogroup haben wir die Vertrauensbeziehungen zwischen Domänen bigbrogroup und cf-media festgestellt.
Zum Zeitpunkt der Ankündigung der Übernahme der CF-Medien hatten wir noch keine Verbindung zu ihrem Netzwerk. Aber nach der Ankündigung erschien der Zugang. Dies rettete uns davor, unsere Räder zu drehen und zu versuchen, von Nagios aus zu schwenken. Die Anmeldeinformationen von Bigbrogroup funktionieren in der cf-media-Domäne, die Benutzer haben jedoch keine Berechtigungen. Es wurden noch keine leicht ausnutzbaren Sicherheitslücken gefunden, aber wir sind ziemlich optimistisch, dass etwas auftauchen wird.
18:30Plötzlich werden wir aus der Bigbrogroup-Domain geworfen. Von wem? Wie? Es sieht so aus, als ob Team TSARKA der Schuldige ist! Sie ändern das Administratorkennwort, aber wir haben 4 andere Administratorkonten in den Reserven. Wir ändern das Domain-Administratorkennwort erneut und setzen alle Kennwörter zurück. Aber Minuten später werden wir wieder rausgeschmissen! Genau zu diesem Zeitpunkt finden wir einen Vektor für die cf-media-Domäne. Auf einem ihrer Server stimmen der Benutzername und das Kennwort mit denen überein, die wir zuvor in der Domäne bigbrogroup gefunden haben. Oh, Passwort wiederverwenden! Was würden wir ohne dich tun? Jetzt brauchen wir nur noch einen Hash. Wir verwenden Hashkiller und erhalten das Passwort P @ ssw0rd. Weitermachen.
19:00Der Kampf um die Kontrolle über die Bidbrogroup wird zu einem ernsthaften Problem. TSARKA hat das Passwort zweimal in krbtgt geändert, wir verlieren alle Administratorkonten ... wie geht es weiter? Sackgasse?
19:30Endlich erhalten wir die Domain-Administratorrechte für cf-media und beginnen, unsere Flags abzugeben. Trotz der Tatsache, dass dies eine gesicherte Domäne sein soll, sehen wir eine reversible Verschlüsselung. Jetzt haben wir also die Anmeldungen und Passwörter und gehen die gleichen Schritte wie bei der Bigbrogroup durch. Wir erstellen zusätzliche Administratoren, stärken unseren Halt, härten die Basislinie, ändern Kennwörter und stellen eine VPN-Verbindung her. Wir finden einen zweiten Finanzbericht, ebenfalls als geschützte Reißverschluss. Wir wenden uns an das Team, das für den ersten Bericht verantwortlich ist. Sie haben es geschafft, es zu brutalisieren, aber die Organisatoren werden es nicht akzeptieren. Es stellte sich heraus, dass es als geschütztes 7zip eingereicht werden musste! Wir mussten es also nicht einmal brutal machen! 3 Stunden Arbeit für nichts.
Wir geben beide Berichte als geschützte 7zip-Dateien ab. Unser Gesamtguthaben beträgt bisher 1 Million Punkte, und TSARKA hat 125.000 Punkte, und sie beginnen, ihre Flaggen aus der Bigbrogroup-Domäne abzugeben. Wir erkennen, dass wir sie davon abhalten müssen, ihre Flaggen abzugeben, aber wie?
19:30Wir finden eine Lösung! Wir haben immer noch die Anmeldeinformationen der lokalen Administratoren. Wir melden uns an, übernehmen das Ticket und schalten einfach den Domänencontroller aus. Der Controller wird ausgeschaltet. Wir schließen alle Server-Ports außer RDP und ändern die Passwörter aller unserer lokalen Administratoren. Jetzt sind wir in unserem kleinen Raum und sie sind in ihrem. Wenn nur die VPN-Verbindung stabil bleiben würde! Das Team atmet gemeinsam aus.
In der Zwischenzeit haben wir Miner auf allen Endpunkten in der cf-media-Domäne eingerichtet. TSARKA liegt im Gesamtvolumen vor uns, aber wir sind nicht weit dahinter und haben mehr PS.
Nacht
Hier sehen Sie die Änderungen, die wir während der Nacht im Team vorgenommen haben.

Einige der Teammitglieder müssen für die Nacht gehen. Bis Mitternacht sind es nur noch 9 Leute. Die Produktivität fällt gegen Null. Jede Stunde stehen wir auf, um unsere Gesichter mit Wasser zu bespritzen und nach draußen zu gehen, um etwas Luft zu schnappen, nur um die Schläfrigkeit abzuschütteln.
Jetzt kommen wir endlich zu den Automated Process Control Systems (APCS)
02.00Die letzten Stunden waren sehr entmutigend. Wir haben mehrere Vektoren gefunden, aber sie sind bereits geschlossen. Wir können nicht sagen, ob sie von Anfang an geschlossen waren oder ob TSARKA bereits hier war. Wenn wir das APCS langsam studieren, finden wir einen anfälligen NetBus-Controller. Wir verwenden ein Metasploit-Modul, dessen Funktionsweise wir nicht vollständig verstehen. Plötzlich gehen die Lichter in der Stadt aus. Die Organisatoren geben bekannt, dass sie dies berücksichtigen werden, wenn wir das Licht wieder einschalten können. In diesem Moment fällt unser VPN aus. Der Server, der das VPN verwaltet, wurde von TSARKA übernommen! Es sieht so aus, als hätten wir die APCS zu laut besprochen und sie haben es geschafft, sie zu übernehmen.
03.30Selbst die engagiertesten von uns beginnen zu nicken. Nur 7 arbeiten noch. Ohne Erklärung ist das VPN plötzlich wieder eingeschaltet. Wir wiederholen den Trick schnell mit den Lichtern der Stadt und sehen, dass unser Gleichgewicht um 200.000 Punkte steigt !!!
Ein Teil des Teams sucht noch nach zusätzlichen Vektoren, während ein anderer am APCS arbeitet. Dort finden wir zwei zusätzliche Schwachstellen. Eine davon können wir ausnutzen. Das Ergebnis des Exploits könnte jedoch ein Umschreiben der Firmware des Mikrocontrollers sein. Wir besprechen dies mit den Organisatoren und beschließen, dass wir darauf warten, dass der Rest unseres Teams am Morgen wieder zu uns kommt, und dann gemeinsam entscheiden, was zu tun ist.
05:30Unser VPN arbeitet ungefähr 10 Minuten pro Stunde und trennt dann wieder die Verbindung. Innerhalb dieser Zeit versuchen wir zu arbeiten. Die Produktivität liegt jedoch nahe Null. Schließlich beschließen wir, uns jeweils eine Stunde Zeit zu nehmen, um ein Nickerchen zu machen. Spoiler Alarm - schlechte Idee!
5 Personen arbeiten noch am APCS.
Morgen
Am Morgen stellen wir plötzlich fest, dass wir fast 1 Million Punkte vor anderen Teams liegen. TSARKA konnte zwei Flaggen von APCS sowie mehrere Flaggen des Telekommunikationsanbieters und der Bigbrogroup abgeben. Außerdem arbeiten Bergleute, und sie müssen eine Krypto haben, die sie noch nicht abgegeben haben. Wir haben geschätzt, dass sie mindestens 200-300.000 weitere Punkte in Krypto hatten. Das ist nervig. Wir haben das Gefühl, dass sie möglicherweise noch ein paar Flaggen haben, die sie strategisch bis in die letzten Stunden zurückhalten. Aber unser Team kommt wieder online. Der morgendliche Soundcheck in der Hauptarena ist etwas nervig, verjagt aber den Schlaf.
Wir arbeiten immer noch daran, in das APCS einzudringen, aber die Hoffnung schwindet. Der Unterschied in den Punkten zwischen der ersten und der zweiten Mannschaft und dem Rest der Mannschaften ist gigantisch. Wir befürchten, dass die Organisatoren beschließen könnten, noch ein paar "Überraschungen" zu machen, um die Dinge durcheinander zu bringen.
Nach einer gemeinsamen Pressekonferenz mit TSARKA in der Hauptarena beschließen wir, unsere Strategie von "mehr Flaggen erhalten" zu ändern, um "zu verhindern, dass TSARKA mehr Flaggen einreicht".
Auf einem unserer Server starten wir Cain & Abel und leiten den gesamten Datenverkehr auf unseren Server um. Wir finden einige VPNs aus Kasachstan und töten sie. Dann beschließen wir, den gesamten Datenverkehr überall zu beenden, und erstellen eine lokale Firewall auf dem VPN-Kanal, um den gesamten Datenverkehr innerhalb des APCS-Netzwerks zu löschen. So schützen Sie ein APCS! Die Organisatoren beschweren sich nun, dass sie die Verbindung zum APCS verloren haben. Wir öffnen den Zugriff für ihre IP-Adressen (auf diese Weise schützen Sie das APCS NICHT).
12:47Wir haben uns zu Recht Sorgen gemacht, dass die Organisatoren versuchen, die Dinge durcheinander zu bringen. Aus dem Nichts gibt es einen Datendump mit 4 Anmeldungen für jede Domain. Wir mobilisieren das gesamte Team.
Ziele:
Team 1 : Übernehmen Sie sofort alle geschützten Segmente.
Team 2 : Verwenden Sie Outlook Web Access, um alle Kennwörter für die Anmeldungen zu ändern.
Einige blaue Teams, die viel Aktivität spüren, schalten einfach das VPN aus. Andere sind kniffliger und ändern die Systemsprache in Chinesisch. Technisch ist der Service noch aktiv! Aber in der Praxis ist es natürlich nicht verwendbar (Organisatoren, aufgepasst!). Über VPN können wir eine Verbindung zu 3 der Netzwerke herstellen. In einem von ihnen dauern wir nur 1 Minute, bevor wir rausgeschmissen werden.
 12:52
12:52Wir suchen einen fehlerhaften Server mit der Sicherheitsanfälligkeit MS17-010 (angeblich ein geschütztes Segment?). Wir nutzen es schnell und stoßen auf keinen Widerstand. Wir erhalten den Hash des Domain-Administrators und greifen über Pth auf den Domain-Controller zu. Und raten Sie mal, was wir dort finden? Reversible Verschlüsselung!
Wer dieses Segment beschützt hat, hat seine Hausaufgaben nicht gemacht. Wir sammeln alle Flags mit Ausnahme des Teils, der sich auf 1C bezieht. Es besteht eine gute Chance, dass wir es bekommen, wenn wir weitere 30-40 Minuten dort verbringen, aber wir beschließen, den behealthy Domain Controller einfach auszuschalten. Wer braucht Wettbewerb?
13:20Wir geben unsere Fahnen ab. Wir haben jetzt 2.900.000 Punkte plus ein paar ausstehende Bug Bounties. TSARKA hat etwas mehr als 1 Million. Sie geben ihre Kryptowährung ab und erhalten weitere 200.000. Wir sind uns jetzt ziemlich sicher, dass sie nicht aufholen können, es wäre fast unmöglich.
13:55Die Leute kommen und gratulieren uns. Wir sind immer noch besorgt über einige Überraschungen der Organisatoren, aber es sieht so aus, als würden wir wirklich als Gewinner bekannt gegeben!
Dies ist die Chronik der 28 Stunden von True0xA3. Natürlich habe ich viel ausgelassen. Zum Beispiel die Pressekonferenzen in der Arena, die Folter, die das Wifi und das GSM waren, die Interaktion mit den Reportern ... aber ich hoffe, ich habe die interessantesten Momente festgehalten.
Dies war eine der aufregendsten Erfahrungen für unser Team, und ich hoffe, dass ich Ihnen zumindest ein wenig ein Gefühl dafür vermitteln konnte, wie sich die Atmosphäre des Standoffs anfühlt, und Sie dazu verleiten konnte, auch zu versuchen, daran teilzunehmen !
Als nächstes werde ich den letzten Teil dieser Reihe veröffentlichen, in dem ich unsere Fehler und die Möglichkeiten, sie in Zukunft zu beheben, analysieren werde. Weil das Lernen über die Fehler eines anderen die beste Art des Lernens ist, oder?