Willkommen, Habr!
Zu einer Zeit waren wir die ersten,
die das Kafka- Thema auf dem russischen Markt eingeführt und dessen Entwicklung weiter
überwacht haben. Insbesondere das Thema Interaktion zwischen Kafka und
Kubernetes erschien uns interessant. Bereits im Oktober letzten Jahres wurde auf Confluents Blog ein (und eher vorsichtiger) Übersichtsartikel zu diesem Thema veröffentlicht, der von Gwen Shapira verfasst wurde. Heute möchten wir Sie auf einen neueren Artikel von Johann Gyger vom April aufmerksam machen, der, obwohl nicht ohne Fragezeichen im Titel, das Thema inhaltlicher betrachtet und den Text mit interessanten Links begleitet. Bitte verzeihen Sie uns die kostenlose Übersetzung von "Chaos Monkey", wenn Sie können!
Einführung
Kubernetes ist für zustandslose Lasten ausgelegt. In der Regel werden solche Workloads in Form einer Microservice-Architektur dargestellt. Sie sind leichtgewichtig, gut für die horizontale Skalierung geeignet, befolgen die Prinzipien von 12-Faktor-Anwendungen und ermöglichen die Arbeit mit Leistungsschaltern und Chaosaffen.
Kafka hingegen befindet sich im Wesentlichen als verteilte Datenbank. Wenn Sie arbeiten, müssen Sie sich mit der Krankheit auseinandersetzen, und sie ist viel schwerer als ein Microservice. Kubernetes unterstützt Stateful Loads, aber wie Kelsey Hightower in zwei seiner Tweets hervorhebt, sollten sie mit Vorsicht behandelt werden:
Es scheint einigen, dass wenn Sie Kubernetes auf eine Stateful Load rollen, es sich in eine vollständig verwaltete Datenbank verwandelt, die mit RDS konkurrieren kann. Es ist nicht so. Wenn Sie nur hart arbeiten, zusätzliche Komponenten anschrauben und ein Team von SRE-Ingenieuren gewinnen, können Sie RDS möglicherweise auf Kubernetes installieren.
Ich empfehle immer, dass jeder äußerste Vorsicht walten lässt, wenn er zustandserhaltende Lasten auf Kubernetes startet. Die meisten, die daran interessiert sind, ob ich Stateful Loads auf Kubernetes ausführen kann, haben nicht genügend Erfahrung mit Kubernetes und häufig mit der Last, nach der sie fragen.
Soll ich Kafka auf Kubernetes ausführen? Gegenfrage: Wird Kafka ohne Kubernetes besser funktionieren? Deshalb möchte ich in diesem Artikel hervorheben, wie sich Kafka und Kubernetes ergänzen und welche Fallstricke in Kombination auftreten können.
Vorlaufzeit
Lassen Sie uns über das Grundlegende sprechen - die Laufzeitumgebung selbst
Der ProzessKafka-Broker sind praktisch, wenn Sie mit der CPU arbeiten. TLS kann einen gewissen Overhead verursachen. Gleichzeitig können Kafka-Clients die CPU stärker belasten, wenn sie Verschlüsselung verwenden. Dies wirkt sich jedoch nicht auf Broker aus.
Die ErinnerungKafka-Makler verschlingen die Erinnerung. Die Größe des JVM-Heapspeichers ist normalerweise auf 4 bis 5 GB begrenzt. Sie benötigen jedoch auch viel Systemspeicher, da Kafka den Seitencache sehr aktiv verwendet. Legen Sie in Kubernetes die Containerlimits für Ressourcen und Anforderungen entsprechend fest.
Data WarehouseDie Datenspeicherung in den Containern ist kurzlebig - Daten gehen beim Neustart verloren. Sie können das
emptyDir Volume für Kafka-Daten verwenden. Der Effekt ist ähnlich: Ihre
emptyDir gehen nach Abschluss verloren. Ihre Nachrichten können weiterhin auf anderen Brokern als Replikate gespeichert werden. Daher muss ein fehlgeschlagener Broker nach einem Neustart zuerst alle Daten replizieren. Dieser Vorgang kann viel Zeit in Anspruch nehmen.
Aus diesem Grund sollte eine langfristige Datenspeicherung verwendet werden. Es sei ein nicht lokaler Langzeitspeicher mit dem XFS-Dateisystem oder genauer gesagt ext4. Verwenden Sie kein NFS. Ich warnte. NFS-Versionen v3 oder v4 funktionieren nicht. Kurz gesagt, der Kafka-Broker wird beendet, wenn er das Datenverzeichnis aufgrund des in NFS relevanten Problems des „dummen Umbenennens“ nicht löschen kann. Wenn ich Sie immer noch nicht überzeugt habe,
lesen Sie diesen Artikel sehr sorgfältig. Das Data Warehouse muss nicht lokal sein, damit Kubernetes nach einem Neustart oder Umzug flexibler einen neuen Knoten auswählen kann.
NetzwerkWie bei den meisten verteilten Systemen hängt die Leistung von Kafka stark davon ab, dass die Netzwerklatenz minimal und die Bandbreite maximal ist. Versuchen Sie nicht, alle Broker auf demselben Knoten zu platzieren, da dies die Verfügbarkeit verringert. Wenn der Kubernetes-Knoten ausfällt, fällt auch der gesamte Kafka-Cluster aus. Verteilen Sie den Kafka-Cluster auch nicht auf ganze Rechenzentren. Gleiches gilt für den Kubernetes-Cluster. Ein guter Kompromiss ist in diesem Fall die Auswahl verschiedener Zugangszonen.
Konfiguration
Gemeinsame ManifesteAuf der Kubernetes-Website finden Sie eine
sehr gute Anleitung zum Konfigurieren von ZooKeeper mithilfe von Manifesten. Da ZooKeeper Teil von Kafka ist, ist es daher zweckmäßig, sich mit den hier anwendbaren Konzepten von Kubernetes vertraut zu machen. Sobald Sie dies herausgefunden haben, können Sie dieselben Konzepte mit dem Kafka-Cluster verwenden.
- Sub : sub ist die kleinste einsetzbare Einheit in Kubernetes. Der Pod enthält Ihre Workload, und der Pod selbst entspricht dem Prozess in Ihrem Cluster. Ein Herd enthält einen oder mehrere Behälter. Jeder ZooKeeper-Server im Ensemble und jeder Broker im Kafka-Cluster arbeiten in einem separaten Ansatz.
- StatefulSet : StatefulSet ist ein Kubernetes-Objekt, das mit mehreren Stateful-Workloads arbeitet, für die eine Koordination erforderlich ist. StatefulSet bietet Garantien hinsichtlich der Bestellung von Herden und ihrer Einzigartigkeit.
- Headless Services : Mit Services können Sie Pods unter Verwendung eines logischen Namens von Clients trennen. Kubernetes ist in diesem Fall für den Lastausgleich verantwortlich. Bei der Aufrechterhaltung zustandsbehafteter Workloads wie bei ZooKeeper und Kafka müssen Clients jedoch Informationen mit einer bestimmten Instanz austauschen. Hier bieten sich kopflose Dienste an: In diesem Fall hat der Client immer noch einen logischen Namen, aber Sie müssen nicht direkt nach unten gehen.
- Volume für die Langzeitspeicherung : Diese Volumes werden für die Konfiguration des oben erwähnten nicht-lokalen Block-Langzeitspeichers benötigt.
Yolean bietet eine umfassende Reihe von Manifesten, die den Einstieg in Kafka auf Kubernetes erleichtern.
HelmkartenHelm ist ein Paketmanager für ein Kubernetes, der mit Paketmanagern für das Betriebssystem wie yum, apt, Homebrew oder Chocolatey verglichen werden kann. Mit dieser Funktion können Sie vordefinierte Softwarepakete installieren, die in Helm-Diagrammen beschrieben sind. Ein gut ausgewähltes Helm-Diagramm erleichtert die schwierige Aufgabe: Wie werden alle Parameter für die Verwendung von Kafka auf Kubernetes richtig konfiguriert? Es gibt mehrere Kafka-Diagramme: Das offizielle befindet sich
in einem Inkubator-Zustand , eines von
Confluent und eines von
Bitnami .
BetreiberDa Helm bestimmte Nachteile hat, gewinnt ein anderes Tool erheblich an Beliebtheit: Kubernetes-Operatoren. Der Betreiber packt nicht nur die Software für Kubernetes, sondern ermöglicht Ihnen auch, diese Software bereitzustellen und auch zu verwalten.
In der Liste der
großartigen Betreiber werden zwei Betreiber für Kafka erwähnt. Einer von ihnen ist
Strimzi . Mit Hilfe von Strimzi ist es einfach, innerhalb von Minuten einen Kafka-Cluster zu erstellen. Es ist praktisch keine Konfiguration erforderlich. Darüber hinaus bietet der Bediener selbst einige nützliche Funktionen, z. B. die TLS-Verschlüsselung vom Typ "Punkt-zu-Punkt" innerhalb des Clusters. Confluent bietet auch
einen eigenen Operator .
LeistungEs ist sehr wichtig, die Leistung zu testen, indem Sie die installierte Kafka-Instanz mit Kontrollpunkten versorgen. Mithilfe dieser Tests können Sie potenzielle Engpässe identifizieren, bevor Probleme auftreten. Glücklicherweise bietet Kafka bereits zwei Leistungstest-Tools an:
kafka-producer-perf-test.sh und
kafka-consumer-perf-test.sh . Nutze sie aktiv. Als Referenz können Sie auf die in
diesem Beitrag von Jay Kreps beschriebenen Ergebnisse verweisen oder
diese Stéphane Maarek Amazon MSK-Bewertung verwenden.
Operationen
ÜberwachungTransparenz im System ist sehr wichtig - sonst werden Sie nicht verstehen, was darin passiert. Heute gibt es ein solides Toolkit, das eine Überwachung basierend auf Metriken im Stil von Cloud Native bietet. Zwei beliebte Werkzeuge für diesen Zweck sind Prometheus und Grafana. Prometheus kann mithilfe des JMX-Exporters auf einfachste Weise Metriken aus allen Java-Prozessen (Kafka, Zookeeper, Kafka Connect) erfassen. Wenn Sie cAdvisor-Metriken hinzufügen, können Sie besser verstehen, wie Ressourcen in Kubernetes verwendet werden.
Strimzi hat ein sehr praktisches Grafana-Dashboard-Beispiel für Kafka. Es visualisiert wichtige Metriken, z. B. über nicht replizierte Sektoren oder solche, die offline sind. Dort ist alles sehr klar. Diese Metriken werden durch Informationen zur Ressourcennutzung und -leistung sowie Stabilitätsindikatoren ergänzt. So erhalten Sie ohne Grund eine grundlegende Überwachung des Kafka-Clusters!
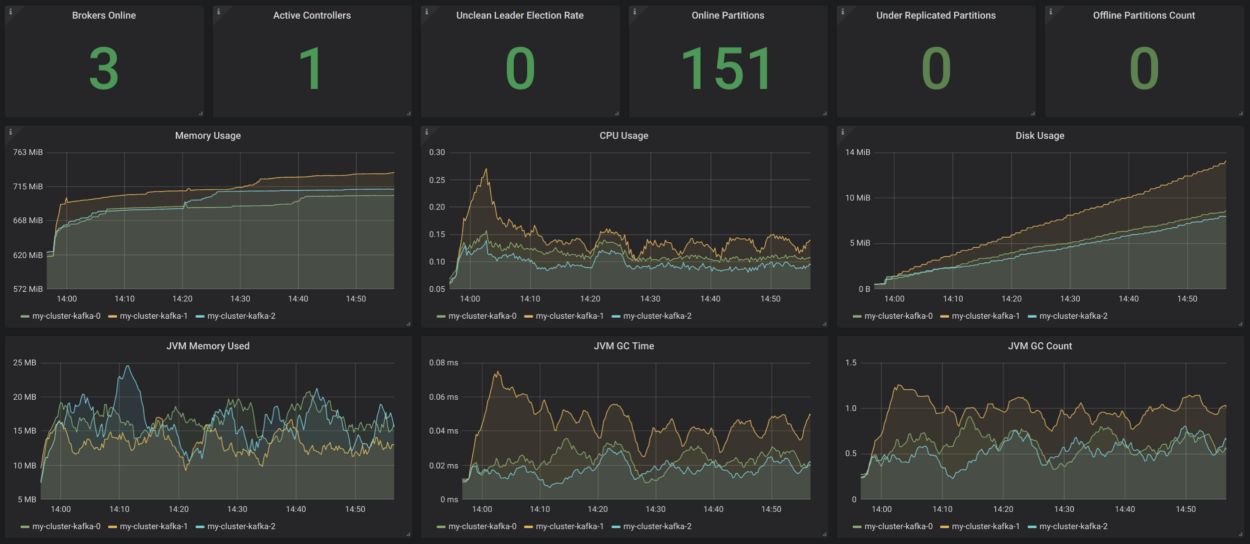
Quelle:
strimzi.io/docs/master/#kafka_dashboardEs wäre schön, all dies durch Kundenüberwachung (Metriken für Verbraucher und Hersteller) sowie Verzögerungsüberwachung (dafür gibt es
Burrow ) und End-to-End-Überwachung zu ergänzen - verwenden Sie dazu
Kafka Monitor .
ProtokollierungDie Protokollierung ist eine weitere wichtige Aufgabe. Stellen Sie sicher, dass alle Container in Ihrer Kafka-Installation in
stdout und
stderr protokolliert sind, und stellen Sie sicher, dass Ihr Kubernetes-Cluster alle Protokolle in einer zentralen
Protokollierungsinfrastruktur wie
Elasticsearch aggregiert.
GesundheitscheckKubernetes verwendet Lebendigkeits- und Bereitschaftssonden, um zu überprüfen, ob Ihre Pods ordnungsgemäß funktionieren. Wenn der Live-Test fehlschlägt, stoppt Kubernetes diesen Container und startet ihn automatisch neu, wenn die Neustartrichtlinie entsprechend festgelegt ist. Wenn die Verfügbarkeitsprüfung fehlschlägt, isoliert Kubernetes dies vom Anforderungsdienst. In solchen Fällen ist ein manueller Eingriff überhaupt nicht mehr erforderlich, und dies ist ein großes Plus.
Einführung von UpdatesStatefulSet unterstützt automatische Updates: Wenn Sie eine RollingUpdate-Strategie auswählen, wird jede unter Kafka nacheinander aktualisiert. Auf diese Weise können Ausfallzeiten auf Null reduziert werden.
SkalierenDas Skalieren eines Kafka-Clusters ist keine leichte Aufgabe. In Kubernetes ist es jedoch sehr einfach, Pods auf eine bestimmte Anzahl von Replikaten zu skalieren. Dies bedeutet, dass Sie deklarativ so viele Kafka-Broker identifizieren können, wie Sie möchten. Am schwierigsten ist in diesem Fall die Neuzuweisung von Sektoren nach dem Vergrößern oder vor dem Verkleinern. Auch hier hilft Ihnen Kubernetes bei dieser Aufgabe.
VerwaltungAufgaben im Zusammenhang mit der Verwaltung Ihres Kafka-Clusters, insbesondere dem Erstellen von Themen und dem Neuzuweisen von Sektoren, können mithilfe vorhandener Shell-Skripts ausgeführt werden, wodurch die Befehlszeilenschnittstelle in Ihren Pods geöffnet wird. Diese Lösung ist jedoch nicht zu schön. Strimzi unterstützt die Verwaltung von Themen mit einem anderen Operator. Hier gibt es etwas zu ändern.
Sichern & WiederherstellenJetzt hängt die Verfügbarkeit von Kafka von der Verfügbarkeit von Kubernetes ab. Wenn Ihr Kubernetes-Cluster fällt, fällt im schlimmsten Fall auch der Kafka-Cluster. Nach Murphys Gesetz wird dies passieren und Sie verlieren Daten. Um dieses Risiko zu verringern, sollten Sie ein gutes Backup-Konzept haben. Sie können MirrorMaker verwenden. Eine andere Option ist die Verwendung von S3, wie in diesem
Beitrag von Zalando beschrieben.
Fazit
Bei der Arbeit mit kleinen oder mittleren Kafka-Clustern ist es auf jeden Fall ratsam, Kubernetes zu verwenden, da dies zusätzliche Flexibilität bietet und die Arbeit mit Bedienern vereinfacht. Wenn Sie sehr schwerwiegende nicht funktionale Anforderungen hinsichtlich Latenz und / oder Durchsatz haben, ist es möglicherweise besser, eine andere Bereitstellungsoption in Betracht zu ziehen.