Die Analyse eines Verkaufstrichters ist eine typische Aufgabe für das Internet-Marketing und insbesondere für den E-Commerce. Mit seiner Hilfe können Sie:
- Finden Sie heraus, bei welchen Schritten zum Kauf Sie potenzielle Kunden verlieren.
- Um das Volumen des zusätzlichen Einnahmezuflusses zu simulieren, im Falle der Erweiterung jedes Schritts auf dem Weg zum Kauf.
- Bewerten Sie die Qualität des auf verschiedenen Werbeplattformen gekauften Verkehrs.
- Bewerten Sie die Qualität der Verarbeitung eingehender Anträge für jeden Manager.
In diesem Artikel werde ich darüber sprechen, wie Sie Daten in der Sprache R von der Yandex Metrics Logs-API anfordern, einen darauf basierenden Trichter erstellen und visualisieren.
Einer der Hauptvorteile der R-Sprache ist das Vorhandensein einer großen Anzahl von Paketen, die ihre Grundfunktionalität erweitern. In diesem Artikel werden wir uns die ggplot2 rym , funneljoin und ggplot2 .
Mit rym laden wir Daten aus der Logs-API, funneljoin mit funneljoin einen Verhaltenstrichter und visualisieren das Ergebnis mit ggplot2 .

Inhalt
Fordern Sie Daten von der Protokoll-API Yandex Metrics an
Wer nicht weiß, was die Logs-API hier ist, ist ein Zitat aus der offiziellen Yandex-Hilfe.
Mit der Protokoll-API können Sie nicht aggregierte Daten empfangen, die von Yandex.Metrica erfasst wurden. Diese API richtet sich an Benutzer des Dienstes, die statistische Daten unabhängig verarbeiten und zur Lösung eindeutiger Analyseprobleme verwenden möchten.
Um mit der Yandex.Metrica Logs-API in R zu arbeiten, verwenden wir das rym Paket.
Nützliche Links zum Rym-Paket rym R-Paket ist eine Schnittstelle für die Interaktion mit der Yandex Metrica-API. Ermöglicht die Arbeit mit der Verwaltungs- API, der Berichts- API, der Gore-API-kompatiblen Google Analytics v3 und der Protokoll-API .
Installation des Rym-Pakets
Um mit einem Paket in R arbeiten zu können, muss es zuerst installiert und heruntergeladen werden. Installieren Sie ein Paket einmal mit dem Befehl install.packages() . Es ist erforderlich, das Paket in jeder neuen Arbeitssitzung in R mithilfe der Funktion library() .
Verwenden Sie den folgenden Code, um das rym Paket zu installieren und zu verbinden:
install.packages("rym") library(rym)
Arbeiten mit der Protokoll-API Yandex Metrics mit dem rym-Paket
Um Verhaltenstrichter zu erstellen, müssen wir eine Tabelle aller auf Ihrer Website durchgeführten Besuche herunterladen und die Daten für die weitere Analyse vorbereiten.
Autorisierung in der Yandex Metrics API
Die Arbeit mit der API beginnt mit der Autorisierung. Im rym Paket rym der Autorisierungsprozess teilweise automatisiert und beginnt, wenn eine seiner Funktionen aufgerufen wird.
Wenn Sie zum ersten Mal auf die API zugreifen, werden Sie zum Browser weitergeleitet, um die Berechtigung zum Zugriff auf Ihre Yandex-Metriken für das rym Paket zu bestätigen. Nach der Bestätigung werden Sie zu der Seite weitergeleitet, auf der ein Autorisierungsbestätigungscode für Sie generiert wird. Es muss als Antwort auf die Anforderung "Enter authorize code:" kopiert und in die R-Konsole eingefügt werden.
Als Nächstes können Sie die Anmeldeinformationen in einer lokalen Datei speichern, indem Sie auf die Anfrage "Do you want save API credential in local file ..." y oder yes antworten. In diesem Fall müssen Sie sich bei den nächsten Aufrufen der API nicht erneut über den Browser authentifizieren, und die Anmeldeinformationen werden aus der lokalen Datei geladen.
Daten von der Yandex Metrica API anfordern
Das erste, was wir von der Yandex Metrics-API verlangen, ist eine Liste der verfügbaren Zähler und konfigurierten Ziele. Dies erfolgt mit den Funktionen rym_get_counters() und rym_get_goals() .
# library(rym) # counters <- rym_get_counters(login = " ") # goals <- rym_get_goals("0000000", # login = " ")
Ersetzen " " anhand des obigen Codebeispiels " " durch Ihren Yandex-Benutzernamen, unter dem die von Ihnen benötigten Yandex-Metriken verfügbar sind. Und "0000000" auf die Nummer des Zählers, den Sie benötigen. Sie können die Nummern der Zähler sehen, die Ihnen in der Tabelle der geladenen Zähler zur Verfügung stehen .
Die Tabelle der verfügbaren Zähler - Zähler hat die folgende Form:
# A tibble: 2 x 9 id status owner_login name code_status site permission type gdpr_agreement_accepted <int> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <int> 1 11111111 Active site.ru1 Aerosus CS_NOT_FOUND site.ru edit simple 0 2 00000000 Active site.ru Aerosus RU CS_OK site.ru edit simple 1
Das ID- Feld zeigt die Nummern aller verfügbaren Yandex-Metrikzähler an.
Die Zieltabelle lautet wie folgt:
# A tibble: 4 x 5 id name type is_retargeting conditions <int> <fct> <fct> <int> <fct> 1 47873638 url 0 type:contain, url:site.ru/checkout/cart/ 2 47873764 url 0 type:contain, url:site.ru/onestepcheckout/ 3 47874133 url 0 type:contain, url:/checkout/onepage/success 4 50646283 action 0 type:exact, url:click_phone
Das heißt, In dem Zähler, mit dem ich arbeite, sind die folgenden Aktionen konfiguriert:
- Gehe zum Korb
- Zur Zahlung gehen
- Vielen Dank für die Bestellung
- Klicken Sie auf die Schaltfläche Telefon
In Zukunft werden wir für die Datenkonvertierung die in der tidyverse Bibliothek enthaltenen Pakete verwenden: tidyr , dplyr . Installieren und verbinden Sie daher diese Pakete oder die gesamte tidyverse Bibliothek, bevor Sie das folgende tidyverse verwenden.
# install.packages("tidyverse") # library(tidyverse) install.packages(c("dplyr", "tidyr")) library(dplyr) library(tidyr)
Mit der Funktion rym_get_logs() können Sie Daten von den API-Metriken der Yandex-Metriken-Protokolle anfordern.
# logs <- rym_get_logs(counter = "0000000", date.from = "2019-04-01", date.to = "2019-06-30", fields = "ym:s:visitID, ym:s:clientID, ym:s:date, ym:s:goalsID, ym:s:lastTrafficSource, ym:s:isNewUser", login = " ") %>% mutate(ym.s.date = as.Date(ym.s.date), ym.s.clientID = as.character(ym.s.clientID))
Die Hauptargumente für die Funktion rym_get_logs() :
- Zähler - Zählernummer, von der Sie Protokolle anfordern;
- date.from - Startdatum;
- Datum bis Ende;
- Felder - Eine Liste der Felder, die Sie laden möchten.
- Login - Yandex-Login, unter dem der im Zähler angegebene Zähler verfügbar ist.
Daher haben wir Besuchsdaten von der Protokoll-API angefordert, die die folgenden Spalten enthält:
- ym: s: visitID - Besuchs-ID
- ym: s: clientID - Benutzer-ID auf der Site
- ym: s: date - Datum des Besuchs
- ym: s: destinationID - Kennung der während dieses Besuchs erreichten Ziele
- ym: s: lastTrafficSource - Verkehrsquelle
- ym: s: isNewUser - Erster Besuch der Besucher
Eine vollständige Liste der verfügbaren Felder finden Sie in der Hilfe zur Protokoll-API.
Die empfangenen Daten reichen aus, um einen Trichter zu erstellen, in dessen Zusammenhang die Arbeit mit der Protokoll-API abgeschlossen ist, und wir fahren mit dem nächsten Schritt fort - der Nachbearbeitung der heruntergeladenen Daten.
Trichter Gebäude Trichter verbinden Paket
Ein wesentlicher Teil der in diesem Abschnitt bereitgestellten Informationen stammt aus dem Trichter-README-Paket, das als Referenz verfügbar ist.
Ziel von funneljoin ist es, die Trichteranalyse des Benutzerverhaltens zu vereinfachen. Ihre Aufgabe besteht beispielsweise darin, Personen zu finden, die Ihre Website besucht und sich dann registriert haben, und herauszufinden, wie viel Zeit zwischen dem ersten Besuch und der Registrierung vergangen ist. Oder Sie müssen Benutzer finden, die die Produktkarte angesehen und innerhalb von zwei Tagen in den Warenkorb gelegt haben. Das funneljoin Paket und die Funktion after_join() helfen bei der Lösung solcher Probleme.
Argumente after_join() :
- x - eine Reihe von Daten, die Informationen zum Abschluss des ersten Ereignisses enthalten (im ersten Beispiel Besuch der Website, im zweiten Beispiel Anzeigen der Produktkarte).
- y - ein Datensatz mit Informationen zum Abschluss des zweiten Ereignisses (im ersten Beispiel der Registrierung, im zweiten Beispiel zum Hinzufügen des Produkts zum Warenkorb).
- by_time - Eine Spalte mit Informationen zum Datum des Auftretens der Ereignisse in den Tabellen x und y .
- by_user - eine Spalte mit Benutzerkennungen in den Tabellen x und y .
- mode - die Verbindungsmethode: "inner", "full", "anti", "semi", "right", "left". Stattdessen können Sie auch
after_mode_join (z. B. after_inner_join anstelle von after_join (..., mode = "inner") ). - Typ - Der Typ der Sequenz, die zum Definieren von Ereignispaaren verwendet wird, z. B. "first-first", "last-first", "any-firstafter". Ausführlicher beschrieben im Abschnitt "Arten von Trichtern".
- max_gap / min_gap (optional) - Filtern nach der maximalen und minimalen Zeitdauer zwischen dem ersten und dem zweiten Ereignis.
- gap_col (optional) - Gibt an, ob eine numerische .gap- Spalte mit einem Zeitunterschied zwischen Ereignissen zurückgegeben werden soll. Der Standardwert ist FALSE.
Trichterverbindung installieren
Zum Zeitpunkt dieses Schreibens war das funneljoin Paket funneljoin nicht auf CRAN veröffentlicht, sodass Sie es von GitHub aus installieren können. Um Pakete von GitHub zu installieren, benötigen Sie ein zusätzliches Paket - devtools .
install.packages("devtools") devtools::install_github("robinsones/funneljoin")
Von der Protokoll-API empfangene Nachbearbeitungsdaten
Für eine detailliertere Untersuchung der Trichterkonstruktionsfunktion müssen wir die von der Logs-API erhaltenen Daten in die gewünschte Form bringen. Die bequemste Möglichkeit, Daten zu manipulieren, wie ich oben geschrieben habe, bieten die dplyr tidyr und dplyr .
Gehen Sie wie folgt vor, um loszulegen:
- In diesem Fall enthält eine Zeile der Protokolltabelle Informationen zu einem Besuch, und die Spalte ym.s.goalsID ist ein Array der Form -
[0,1,0,...] , das Kennungen der während dieses Besuchs erreichten Ziele enthält. Um das Array in eine Form zu bringen, die für die weitere Arbeit geeignet ist, müssen zusätzliche Zeichen entfernt werden, in unserem Fall eckige Klammern. - Die Tabelle muss neu formatiert werden, damit eine Zeile Informationen zu einem Ziel enthält, das während des Besuchs erreicht wurde. Das heißt, Wenn während eines Besuchs drei Ziele erreicht wurden, wird dieser Besuch in drei Zeilen unterteilt, und jede Zeile in der Spalte ym.s.goalsID enthält die Kennung nur eines Ziels.
- Fügen Sie der Protokolltabelle eine Tabelle mit einer Liste von Zielen hinzu, um genau zu verstehen, welche Ziele bei jedem Besuch erreicht wurden.
- Benennen Sie die Namensspalte mit Zielnamen in Ereignisse um .
Alle oben genannten Aktionen werden mit dem folgenden Code implementiert:
Nachbearbeitungscode für Daten, die von der Protokoll-API empfangen wurden # logs_goals <- logs %>% mutate(ym.s.goalsID = str_replace_all(ym.s.goalsID, # "\\[|\\]", "") %>% str_split(",")) %>% # unnest(cols = c(ym.s.goalsID)) %>% mutate(ym.s.goalsID = as.integer(ym.s.goalsID)) %>% # id left_join(goals, by = c("ym.s.goalsID" = "id")) %>% # rename(events = name) # events
Eine kleine Erklärung des Codes. Der Operator %>% wird als Pipeline bezeichnet und macht den Code lesbarer und kompakter. Tatsächlich nimmt es das Ergebnis der Ausführung einer Funktion und übergibt es als erstes Argument an die nächste Funktion. Auf diese Weise wird eine Art Förderer erhalten, mit dem Sie den RAM nicht mit überflüssigen Variablen verstopfen können, die Zwischenergebnisse speichern.
Die Funktion str_replace_all entfernt eckige Klammern in der Spalte ym.s.goalsID . str_split teilt die str_split aus der Spalte ym.s.goalsID in separate Werte auf und unnest teilt sie in separate Zeilen auf, wobei die Werte aller anderen Spalten dupliziert werden.
Mit mutate wir Ziel-IDs in einen Integer-Typ um.
left_join an das Ergebnis an, in dem Informationen zu den konfigurierten Zielen left_join . Verwenden der Spalte ym.s.goalsID aus der aktuellen Tabelle und der Spalte id aus der Zieltabelle als Schlüssel.
Schließlich benennt die Umbenennungsfunktion die Namensspalte in Ereignisse um .
Jetzt hat die Tabelle logs_goals das Aussehen , das für die weitere Arbeit erforderlich ist.
Erstellen Sie als Nächstes drei neue Tabellen:
- first_visits - Daten der ersten Sitzungen für alle neuen Benutzer
- Warenkorb - Datum des Hinzufügens von Produkten zum Warenkorb
- Bestellungen - Bestellungen
Code zur Tabellenerstellung # first_visits <- logs_goals %>% filter(ym.s.isNewUser == 1 ) %>% # select(ym.s.clientID, # clientID ym.s.date) # date # cart <- logs_goals %>% filter(events == " ") %>% select(ym.s.clientID, ym.s.date) # orders <- logs_goals %>% filter(events == " ") %>% select(ym.s.clientID, ym.s.date)
Jede neue Tabelle ist das Ergebnis der Filterung der im letzten Schritt erhaltenen Haupttabelle logs_goals . Die Filterung erfolgt durch die filter .
Um Trichter zu erstellen, reicht es aus, Informationen über die Benutzer-ID und das Datum des Ereignisses, die in den Spalten ym.s.clientID und ym.s.date gespeichert sind, in den neuen Tabellen zu belassen . Die gewünschten Spalten wurden mit der select .
Trichtertypen
Das Argument type akzeptiert eine beliebige Kombination der lastbefore first , last , any und firstafter mit first , last , any und firstafter . Das Folgende ist ein Beispiel für die nützlichsten Kombinationen, die Sie verwenden können:
first-first : Ermittelt die frühesten x- und y- Ereignisse für jeden Benutzer. Zum Beispiel möchten wir das Datum des ersten Besuchs und das Datum des ersten Kaufs erhalten. In diesem Fall verwenden Sie den Trichtertyp first-first .
# first-first first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "first-first")
# A tibble: 42 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1552251706539589249 2019-04-18 2019-05-15 2 1554193975665391000 2019-04-02 2019-04-15 3 1554317571426012455 2019-04-03 2019-04-04 4 15544716161033564779 2019-04-05 2019-04-08 5 1554648729526295287 2019-04-07 2019-04-11 6 1554722099539384487 2019-04-08 2019-04-17 7 1554723388680198551 2019-04-08 2019-04-08 8 15547828551024398507 2019-04-09 2019-05-13 9 1554866701619747784 2019-04-10 2019-04-10 10 1554914125524519624 2019-04-10 2019-04-10 # ... with 32 more rows
Wir haben eine Tabelle erhalten, in der 1 Zeile Daten zum Datum des ersten Besuchs des Benutzers auf der Website und zum Datum seiner ersten Bestellung enthält.
first-firstafter : first-firstafter sich das früheste x , dann das erste y nach dem ersten x . Beispielsweise hat ein Benutzer Ihre Website wiederholt besucht und im Verlauf der Besuche Produkte zum Warenkorb hinzugefügt. Wenn Sie das Datum des Hinzufügens des allerersten Produkts zum Warenkorb und das Datum der nächstgelegenen Bestellung first-firstafter , verwenden Sie den Trichtertyp " first-firstafter ".
cart %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "first-firstafter")
# A tibble: 49 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-02 2019-04-05 2 1552251706539589249 2019-05-15 2019-05-15 3 1552997205196001429 2019-05-23 2019-05-23 4 1553261825377658768 2019-04-11 2019-04-11 5 1553541720631103579 2019-04-04 2019-04-05 6 1553761108775329787 2019-04-16 2019-04-16 7 1553828761648236553 2019-04-03 2019-04-03 8 1554193975665391000 2019-04-13 2019-04-15 9 1554317571426012455 2019-04-04 2019-04-04 10 15544716161033564779 2019-04-08 2019-04-08 # ... with 39 more rows
lastbefore-firstafter : erstes x gefolgt von y vor dem nächsten x . Beispielsweise hat ein Benutzer Ihre Website wiederholt besucht. Einige der Sitzungen endeten mit einem Kauf. Wenn Sie das Datum der letzten Sitzung vor dem Kauf und das darauf folgende lastbefore-firstafter , verwenden Sie den Trichtertyp lastbefore-firstafter .
first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "lastbefore-firstafter")
# A tibble: 50 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-05 2019-04-05 2 1552251706539589249 2019-05-15 2019-05-15 3 1552251706539589249 2019-05-16 2019-05-16 4 1552997205196001429 2019-05-23 2019-05-23 5 1553261825377658768 2019-04-11 2019-04-11 6 1553541720631103579 2019-04-05 2019-04-05 7 1553761108775329787 2019-04-16 2019-04-16 8 1553828761648236553 2019-04-03 2019-04-03 9 1554193975665391000 2019-04-15 2019-04-15 10 1554317571426012455 2019-04-04 2019-04-04 # ... with 40 more rows
In diesem Fall haben wir eine Tabelle erhalten, in der eine Zeile das Datum enthält, an dem das letzte Produkt vor Abschluss jeder Bestellung in den Warenkorb gelegt wurde, sowie das Datum der Bestellung selbst.
any-firstafter : any-firstafter sich alle x und das erste y danach. Beispielsweise hat ein Benutzer Ihre Website wiederholt besucht, bei jedem Besuch verschiedene Produkte in den Warenkorb gelegt und regelmäßig Bestellungen mit allen hinzugefügten Produkten getätigt. Wenn Sie die Daten aller Wareneingänge in den Warenkorb und die any-firstafter , verwenden Sie den Trichtertyp any-firstafter .
cart %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "any-firstafter")
# A tibble: 239 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-02 2019-04-05 2 1551433754595068897 2019-04-02 2019-04-05 3 1551433754595068897 2019-04-03 2019-04-05 4 1551433754595068897 2019-04-03 2019-04-05 5 1551433754595068897 2019-04-03 2019-04-05 6 1551433754595068897 2019-04-05 2019-04-05 7 1551433754595068897 2019-04-05 2019-04-05 8 1551433754595068897 2019-04-05 2019-04-05 9 1551433754595068897 2019-04-05 2019-04-05 10 1551433754595068897 2019-04-05 2019-04-05 # ... with 229 more rows
- any-any: Holen Sie sich alle x und alle y neben jedes x . Sie möchten beispielsweise eine Liste aller Besuche auf der Website mit allen nachfolgenden Bestellungen jedes Benutzers erhalten.
first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "any-any")
# A tibble: 122 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1552251706539589249 2019-04-18 2019-05-15 2 1552251706539589249 2019-04-18 2019-05-15 3 1552251706539589249 2019-04-18 2019-05-15 4 1552251706539589249 2019-04-18 2019-05-16 5 1554193975665391000 2019-04-02 2019-04-15 6 1554193975665391000 2019-04-02 2019-04-25 7 1554317571426012455 2019-04-03 2019-04-04 8 15544716161033564779 2019-04-05 2019-04-08 9 1554648729526295287 2019-04-07 2019-04-11 10 1554722099539384487 2019-04-08 2019-04-17 # ... with 112 more rows
Trichterstufen
Die obigen Beispiele zeigen die Arbeit mit der Funktion after_inner_join() . Es ist praktisch, sie in Fällen zu verwenden, in denen alle Ereignisse durch separate Tabellen getrennt sind, in unserem Fall gemäß den Tabellen first_visits , cart und orders .
Die Protokoll-API bietet Ihnen jedoch Informationen zu allen Ereignissen in einer Tabelle, und die Funktionen funnel_start() und funnel_step() sind eine bequemere Möglichkeit, eine Folge von Aktionen zu erstellen. funnel_start hilft beim funnel_start des ersten Schritts des Trichters und verwendet fünf Argumente:
- tbl - Ereignistabelle;
- moment_type - Das erste Ereignis im Trichter;
- Moment - Der Name der Spalte, die den Namen des Ereignisses enthält.
- tstamp - Name der Spalte mit dem Datum, an dem das Ereignis aufgetreten ist;
- Benutzer - Der Name der Spalte mit den Benutzerkennungen.
logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID")
# A tibble: 52 x 2 ym.s.clientID `ym.s.date_ ` <chr> <date> 1 1556018960123772801 2019-04-24 2 1561216372134023321 2019-06-22 3 1556955573636389438 2019-05-04 4 1559220890220134879 2019-05-30 5 1553261825377658768 2019-04-11 6 1561823182372545402 2019-06-29 7 1556047887455246275 2019-04-23 8 1554722099539384487 2019-04-17 9 1555420652241964245 2019-04-17 10 1553541720631103579 2019-04-05 # ... with 42 more rows
funnel_start gibt eine Tabelle mit den Spalten ym.s.clientI und ym.s.date_ zurück ym.s.date_ (der Name Ihrer Spalte mit dem Datum, _ und dem Namen des Ereignisses).
Die folgenden Schritte können mit der Funktion funnel_step() hinzugefügt werden. In funnel_start wir bereits die Bezeichner aller erforderlichen Spalten angegeben. Jetzt müssen wir mithilfe des Argumentes moment_type angeben, welches Ereignis der nächste Schritt im Trichter sein soll , und der Verbindungstyp ist type (z. B. "first-first" , "first-any" ).
logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_step(moment_type = " ", type = "first-last")
# A tibble: 319 x 3 ym.s.clientID `ym.s.date_ ` `ym.s.date_ ` <chr> <date> <date> 1 1550828847886891355 2019-04-01 NA 2 1551901759770098825 2019-04-01 NA 3 1553595703262002507 2019-04-01 NA 4 1553856088331234886 2019-04-01 NA 5 1554044683888242311 2019-04-01 NA 6 1554095525459102609 2019-04-01 NA 7 1554100987632346537 2019-04-01 NA 8 1551433754595068897 2019-04-02 2019-04-05 9 1553627918798485452 2019-04-02 NA 10 155418104743178061 2019-04-02 NA # ... with 309 more rows
Mit funnel_step Sie Trichter mit einer beliebigen Anzahl von Schritten erstellen. In meinem Beispiel können Sie den folgenden Code verwenden, um für jeden Benutzer einen vollständigen Trichter zu erstellen:
Code zum Erstellen eines vollständigen Trichters für jeden Benutzer # # events - " " logs_goals <- logs_goals %>% filter(ym.s.isNewUser == 1 ) %>% mutate(events = " ") %>% bind_rows(logs_goals) # logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_step(moment_type = " ", type = "first-last") %>% funnel_step(moment_type = " ", type = "first-last") %>% funnel_step(moment_type = " ", type = "first-last")
Und jetzt ist die Kirsche auf dem Kuchen summarize_funnel() . Eine Funktion, mit der Sie den Prozentsatz der Benutzer anzeigen können, die vom vorherigen zum nächsten Schritt gewechselt sind, und den Prozentsatz der Benutzer, die vom ersten Schritt zum nächsten übergegangen sind.
my_funnel <- logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_steps(moment_type = c(" ", " ", " "), type = "first-last") %>% summarize_funnel()
# A tibble: 4 x 4 moment_type nb_step pct_cumulative pct_step <fct> <dbl> <dbl> <dbl> 1 18637 1 NA 2 1589 0.0853 0.0853 3 689 0.0494 0.579 4 34 0.0370 0.749
nb_step — , , pct_cumulative — , pct_step — .
my_funnel , ggplot2 .
ggplot2 — R, . , , .
ggplot2 , 2005 . , photoshop, , .
# install.packages("ggplot2") library(ggplot2) my_funnel %>% mutate(padding = (sum(my_funnel$nb_step) - nb_step) / 2) %>% gather(key = "variable", value = "val", -moment_type) %>% filter(variable %in% c("nb_step", "padding")) %>% arrange(desc(variable)) %>% mutate(moment_type = factor(moment_type, levels = c(" ", " ", " ", " "))) %>% ggplot( aes(x = moment_type) ) + geom_bar(aes(y = val, fill = variable), stat='identity', position='stack') + scale_fill_manual(values = c('coral', NA) ) + geom_text(data = my_funnel, aes(y = sum(my_funnel$nb_step) / 2, label = paste(round(round(pct_cumulative * 100,2)), '%')), colour='tomato4', fontface = "bold") + coord_flip() + theme(legend.position = 'none') + labs(x='moment', y='volume')
:
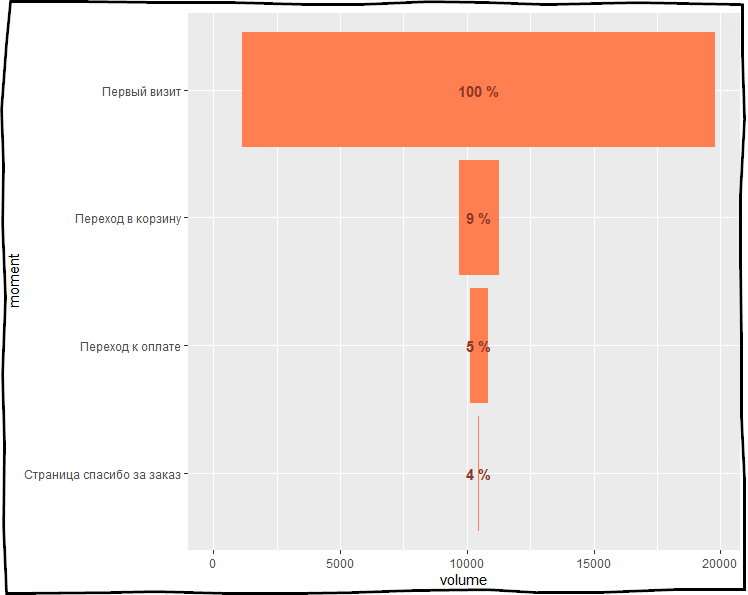
.
- my_funnel .
ggplot — , , , X moment_type .geom_bar — — , aes .scale_fill_manual — , , .geom_text — , % .coord_flip — , .theme — : , .. .labs — .
, , , , .
lapply , R. , , bind_rows .
# first_visits <- rename(first_visits, firstSource = ym.s.lastTrafficSource) # logs_goals <- select(first_visits, ym.s.clientID, firstSource) %>% left_join(logs_goals, ., by = "ym.s.clientID") # my_multi_funnel <- lapply(c("ad", "organic", "direct"), function(source) { logs_goals %>% filter(firstSource == source) %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_steps(moment_type = c(" ", " ", " "), type = "first-last") %>% summarize_funnel() %>% mutate(firstSource = source) }) %>% bind_rows() #
# A tibble: 12 x 5 moment_type nb_step pct_cumulative pct_step firstSource <fct> <int> <dbl> <dbl> <chr> 1 14392 1 NA ad 2 154 0.0107 0.0107 ad 3 63 0.00438 0.409 ad 4 14 0.000973 0.222 ad 5 3372 1 NA organic 6 68 0.0202 0.0202 organic 7 37 0.0110 0.544 organic 8 13 0.00386 0.351 organic 9 607 1 NA direct 10 49 0.0807 0.0807 direct 11 21 0.0346 0.429 direct 12 8 0.0132 0.381 direct
my_multi_funnel , .
# my_multi_funnel %>% mutate(padding = ( 1 - pct_cumulative) / 2 ) %>% gather(key = "variable", value = "val", -moment_type, -firstSource) %>% filter(variable %in% c("pct_cumulative", "padding")) %>% arrange(desc(variable)) %>% mutate(moment_type = factor(moment_type, levels = c(" ", " ", " ", " ")), variable = factor(variable, levels = c("pct_cumulative", "padding"))) %>% ggplot( aes(x = moment_type) ) + geom_bar(aes(y = val, fill = variable), stat='identity', position='stack') + scale_fill_manual(values = c('coral', NA) ) + geom_text(data = my_multi_funnel_df, aes(y = 1 / 2, label =paste(round(round(pct_cumulative * 100, 2)), '%')), colour='tomato4', fontface = "bold") + coord_flip() + theme(legend.position = 'none') + labs(x='moment', y='volume') + facet_grid(. ~ firstSource)
:

?
first_visits ym.s.lastTrafficSource firstSource .left_join ym.s.clientID . firstSource .lapply ad, organic direct. bind_rows .facet_grid(. ~ firstSource) , firstSource .
PS
. PS , R. R4marketing , R .
:
Fazit
, , R :
- .;
- R RStudio;
rym , funneljoin ggplot2 ;rym rym_get_logs() .;funneljoin .ggplot2 .
, Logs API , : CRM, 1 . , : , -.