Denken Sie, dass es schwierig ist, einen eigenen Chatbot in Python zu schreiben, der die Konversation unterstützen kann? Es stellte sich als sehr einfach heraus, wenn Sie einen guten Datensatz finden. Darüber hinaus kann dies auch ohne neuronale Netze erfolgen, obwohl noch etwas mathematische Magie benötigt wird.
Wir werden in kleinen Schritten vorgehen: Denken Sie zuerst daran, wie Sie Daten in Python laden, dann lernen Sie, Wörter zu zählen, verbinden Sie nach und nach lineare Algebra und Theorver, und am Ende erstellen wir aus dem resultierenden Chat-Algorithmus einen Bot für Telegramm.
Dieses Tutorial ist für diejenigen geeignet, die Python bereits ein wenig berührt haben, aber mit maschinellem Lernen nicht besonders vertraut sind. Ich habe absichtlich keine nlp-sh-Bibliotheken verwendet, um zu zeigen, dass etwas, das funktioniert, auf bloßem sklearn zusammengestellt werden kann.
Suchen Sie im Dialogdatensatz nach einer Antwort
Vor einem Jahr wurde ich gebeten, den Leuten, die zuvor noch nicht mit Datenanalyse beschäftigt waren, eine inspirierende Anwendung für maschinelles Lernen zu zeigen, die Sie selbst erstellen können. Ich habe versucht, einen Bot-Talker mitzubringen, und wir haben es wirklich an einem Abend geschafft. Wir mochten den Prozess und das Ergebnis und schrieben darüber in
meinem Blog . Und jetzt dachte ich, dass Habru interessant sein würde.
Also los geht's. Unsere Aufgabe ist es, einen Algorithmus zu erstellen, der auf jede Phrase eine angemessene Antwort gibt. Zum Beispiel zu "Wie geht es dir?" antworte "ausgezeichnet und du?". Der einfachste Weg, dies zu erreichen, besteht darin, eine vorgefertigte Datenbank mit Fragen und Antworten zu finden. Nehmen Sie zum Beispiel Untertitel aus einer großen Anzahl von Filmen.
Ich werde jedoch noch betrügerischer handeln und die Daten aus
dem Wettbewerb Yandex.Algorithm 2018 übernehmen - dies sind dieselben Dialoge aus den Filmen, für die Toloka-Mitarbeiter gute und keine schlechten Fortsetzungen markiert haben. Yandex sammelte diese Daten, um Alice zu trainieren (Artikel über ihre Eingeweide
1 ,
2 ,
3 ). Eigentlich hat mich Alice inspiriert, als ich diesen Bot erfunden habe. Die
Tabelle von Yandex zeigt die letzten drei Sätze und die Antwort darauf (Antwort), aber wir werden nur den neuesten verwenden (context_0).
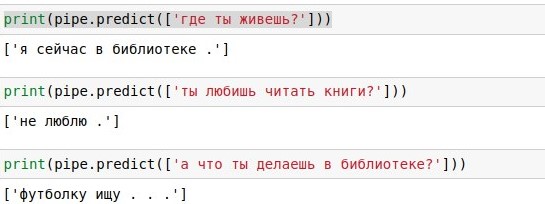
Mit einer solchen Datenbank von Dialogen können Sie einfach nach jedem Replikat des Benutzers suchen und eine Antwort darauf geben (wenn es viele solcher Replikate gibt, wählen Sie zufällig). Mit "Wie geht es dir?" es stellte sich als großartig heraus, wie der beigefügte Screenshot zeigt. Dies ist, wenn überhaupt, ein
Jupyter-Notizbuch in Python 3. Wenn Sie dies selbst wiederholen möchten, ist es am einfachsten,
Anaconda zu installieren - es enthält Python und eine Reihe nützlicher Pakete dafür. Oder Sie können nichts installieren, sondern ein Notebook
in einer Google Cloud ausführen.

Das Problem bei wörtlichen Suchen besteht darin, dass die Abdeckung gering ist. Zum Satz "Wie geht es dir?" In der Datenbank mit 40.000 Antworten gab es keine genaue Übereinstimmung, obwohl sie dieselbe Bedeutung hat. Daher werden wir im nächsten Abschnitt unseren Code mithilfe verschiedener mathematischer Methoden ergänzen, um eine ungefähre Suche zu implementieren. Zuvor können Sie die
Pandas- Bibliothek lesen und herausfinden, was jede der 6 Zeilen des obigen Codes bewirkt.
Textvektorisierung
Jetzt geht es darum, wie Texte in numerische Vektoren umgewandelt werden, um eine ungefähre Suche nach ihnen durchzuführen.
Wir haben uns bereits mit der Pandas-Bibliothek in Python getroffen - sie ermöglicht es Ihnen, Tabellen zu laden, darin zu suchen usw. Lassen Sie uns nun die
Scikit-Learn- Bibliothek (sklearn) ansprechen, die eine schwierigere Datenmanipulation ermöglicht - das sogenannte maschinelle Lernen. Dies bedeutet, dass jeder Algorithmus zuerst die Daten (Fit) anzeigen muss, damit er etwas Wichtiges über sie erfährt. Infolgedessen „lernt“ der Algorithmus, mit diesen Daten etwas Nützliches zu tun - sie zu transformieren (transformieren) oder sogar unbekannte Werte vorherzusagen (vorhersagen).
In diesem Fall möchten wir Texte („Fragen“) in numerische Vektoren konvertieren. Dies ist notwendig, damit mit dem mathematischen Konzept der Distanz Texte gefunden werden können, die „nahe“ beieinander liegen. Der Abstand zwischen zwei Punkten kann nach dem Satz von Pythagoras berechnet werden - als Wurzel der Summe der Quadrate der Differenzen ihrer Koordinaten. In der Mathematik wird dies als euklidische Metrik bezeichnet. Wenn wir Texte in Objekte mit Koordinaten verwandeln können, können wir die euklidische Metrik berechnen und beispielsweise in der Datenbank eine Frage finden, die am ehesten der Frage ähnelt, was Sie denken.
Der einfachste Weg, die Koordinaten des Textes anzugeben, besteht darin, alle Wörter in der Sprache zu nummerieren und zu sagen, dass die i-te Koordinate des Textes gleich der Anzahl der Vorkommen des i-ten Wortes darin ist. Für den Text "Ich kann nicht anders als zu weinen" ist die Koordinate des Wortes "nicht" 2, die Koordinaten der Wörter "Ich", "Kann" und "Weinen" sind 1 und die Koordinaten aller anderen Wörter (Zehntausende davon) sind 0. Diese Darstellung verliert Informationen über die Wortreihenfolge, funktioniert aber immer noch ziemlich gut.
Das Problem ist, dass für häufig vorkommende Wörter (z. B. Partikel „und“ und „a“) die Koordinaten unverhältnismäßig groß sind, obwohl sie nur wenige Informationen enthalten. Um dieses Problem zu verringern, kann die Koordinate jedes Wortes durch den Logarithmus der Anzahl der Texte geteilt werden, in denen ein solches Wort vorkommt - dies wird als tf-idf bezeichnet und funktioniert auch gut.

Es gibt nur ein Problem: In unserer Datenbank mit 60.000 Textfragen, die 14.000 verschiedene Wörter enthalten. Wenn Sie alle Fragen in Vektoren umwandeln, erhalten Sie eine Matrix von 60k * 14k. Es ist nicht sehr cool, damit zu arbeiten, daher werden wir später über das Reduzieren der Dimension sprechen.
Maßreduzierung
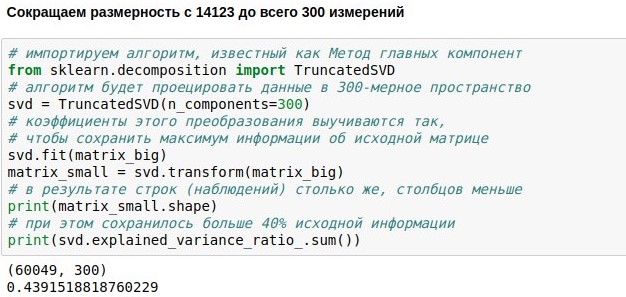
Wir haben uns bereits die Aufgabe gestellt, einen Chat-Chatbot zu erstellen, Daten herunterzuladen und für sein Training zu vektorisieren. Jetzt haben wir eine numerische Matrix, die Benutzerreplikate darstellt. Es besteht aus 60.000 Zeilen (es gab so viele Replikate in der Datenbank der Dialoge) und 14.000 Spalten (es waren so viele verschiedene Wörter darin). Unsere Aufgabe ist es jetzt, es kleiner zu machen. Zum Beispiel, um jeden Text nicht als 14123-dimensionalen, sondern nur als 300-dimensionalen Vektor darzustellen.
Dies kann erreicht werden, indem unsere Matrix der Größe 60049x14123 mit einer speziell ausgewählten Projektionsmatrix der Größe 14123x300 multipliziert wird. Am Ende erhalten wir das Ergebnis 60049x300. Der PCA-Algorithmus (
Hauptkomponentenmethode ) wählt die Projektionsmatrix so aus, dass die ursprüngliche Matrix dann mit dem kleinsten Standardfehler rekonstruiert werden kann. In unserem Fall konnten etwa 44% der ursprünglichen Matrix beibehalten werden, obwohl die Abmessung um fast das 50-fache reduziert wurde.
Was macht eine so effektive Komprimierung möglich? Denken Sie daran, dass die ursprüngliche Matrix Zähler für die Erwähnung einzelner Wörter in den Texten enthält. Wörter werden aber in der Regel nicht unabhängig voneinander, sondern im Kontext verwendet. Je öfter beispielsweise das Wort "Blockieren" im Text der Nachrichten vorkommt, desto öfter wird höchstwahrscheinlich auch das Wort "Telegramme" in diesem Text gefunden. Aber die Korrelation des Wortes "Blockieren" zum Beispiel mit dem Wort "Kaftan" ist negativ - sie kommen in verschiedenen Kontexten vor.
Es stellt sich also heraus, dass sich die Methode der Hauptkomponenten nicht an alle 14.000 Wörter erinnert, sondern an 300 typische Kontexte, in denen versucht werden kann, diese Wörter wiederherzustellen. Die Spalten der Projektionsmatrix, die auch Wörtern entsprechen, sind normalerweise ähnlich, da diese Wörter häufig im selben Kontext gefunden werden. Dies bedeutet, dass redundante Messungen reduziert werden können, ohne an Informativität zu verlieren.
In vielen modernen Anwendungen wird die
Wortprojektionsmatrix durch neuronale Netze (z. B.
word2vec ) berechnet. Tatsächlich reicht eine einfache lineare Algebra jedoch bereits für ein praktisch nützliches Ergebnis aus. Die Methode der Hauptkomponenten wird rechnerisch auf SVD reduziert und dient zur Berechnung der Eigenvektoren und Eigenwerte der Matrix. Dies kann jedoch programmiert werden, ohne die Details zu kennen.
Suchen Sie nach Nachbarn in der Nähe
In den vorherigen Abschnitten haben wir das Dialogfeld auf Python hochgeladen, es vektorisiert und die Dimension reduziert. Jetzt möchten wir endlich lernen, wie wir in unserem 300-dimensionalen Raum nach unseren nächsten Nachbarn suchen und schließlich Fragen sinnvoll beantworten können.
Da wir gelernt haben, Fragen auf den euklidischen Raum von nicht sehr hoher Dimension abzubilden, kann die Suche nach Nachbarn darin ziemlich schnell durchgeführt werden. Wir werden den vorgefertigten
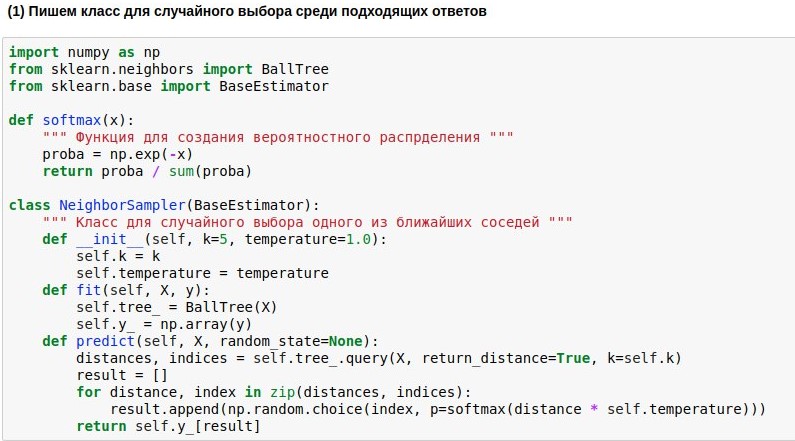
BallTree- Nachbarn-Suchalgorithmus verwenden. Aber wir werden unser Wrapper-Modell schreiben, das einen der k nächsten Nachbarn auswählt, und je näher der Nachbar ist, desto höher ist die Wahrscheinlichkeit seiner Wahl. Denn immer einen der nächsten Nachbarn zu nehmen ist langweilig, aber überhaupt nicht an die Ähnlichkeit gebunden zu sein, ist gefährlich.
Daher möchten wir die gefundenen Abstände von der Abfrage zu den Referenztexten in die Wahrscheinlichkeit der Auswahl dieser Texte umwandeln. Dazu können Sie die Softmax-Funktion verwenden, die häufig noch am Ausgang neuronaler Netze steht. Sie verwandelt ihre Argumente in eine Reihe nicht negativer Zahlen, deren Summe 1 ist - genau das, was wir brauchen. Ferner können wir die erhaltenen "Wahrscheinlichkeiten" für eine zufällige Auswahl der Antwort verwenden.
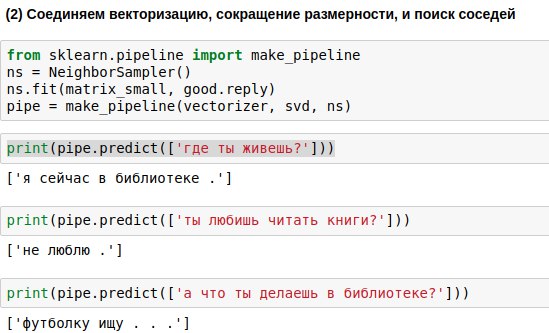
Die vom Benutzer eingegebenen Phrasen müssen alle drei Algorithmen durchlaufen - den Vektorisierer, die Hauptkomponentenmethode und den Antwortauswahlalgorithmus. Um weniger Code zu schreiben, können Sie sie zu einer einzigen Kette (Pipeline) verknüpfen und die Algorithmen nacheinander anwenden.
Als Ergebnis haben wir einen Algorithmus erhalten, der auf die Frage eines Benutzers eine ähnliche Frage finden und eine Antwort darauf geben kann. Und manchmal klingen diese Antworten sogar fast bedeutungsvoll.
Veröffentlichen eines Bots im Telegramm
Wir haben bereits herausgefunden, wie ein Chatbot-Chatroom erstellt werden kann, der ungefähr relevante Antworten auf Benutzeranfragen liefert. Jetzt zeige ich Ihnen, wie Sie einen solchen Chatbot auf Telegram veröffentlichen können.
Der einfachste Weg, dies zu verwenden, ist die vorgefertigte Wrapper-Telegramm-API für Python - zum Beispiel
pytelegrambotapi . Also, Schritt für Schritt Anleitung:
- Registrieren Sie Ihren zukünftigen Bot bei @botfather und erhalten Sie ein Zugriffstoken, das Sie in Ihren Code einfügen müssen.
- Führen Sie den Installationsbefehl einmal aus - pip install pytelegrambotapi in der Befehlszeile (oder über! Direkt im Editor).
- Führen Sie den Code wie im Screenshot aus. Die Zelle wechselt in den Ausführungsmodus (*). In diesem Modus können Sie so viel mit Ihrem Bot kommunizieren, wie Sie möchten. Um den Bot zu stoppen, drücken Sie Strg + C. Die traurige, aber wichtige Wahrheit: Wenn Sie sich in Russland befinden, müssen Sie höchstwahrscheinlich vor dem Starten dieser Zelle das VPN einschalten, um beim Herstellen einer Verbindung zu Telegrammen keinen Fehler zu erhalten. Eine einfachere Alternative zu VPN besteht darin, den gesamten Code nicht auf Ihrem lokalen Computer, sondern in Google Colab ( so ähnlich ) zu schreiben.
- Wenn der Bot dauerhaft funktionieren soll, müssen Sie seinen Code in einen Cloud-Dienst einfügen, z. B. AWS, Heroku, now.sh oder Yandex.Cloud. Auf den Websites dieser Dienste oder in Artikeln direkt auf Habré erfahren Sie, wie Sie sie bis ins kleinste Detail ausführen. Zum Beispiel eine Rübe mit einem kleinen Beispiel eines Bots, der auf Heroku läuft und Protokolle in Mongodb legt.
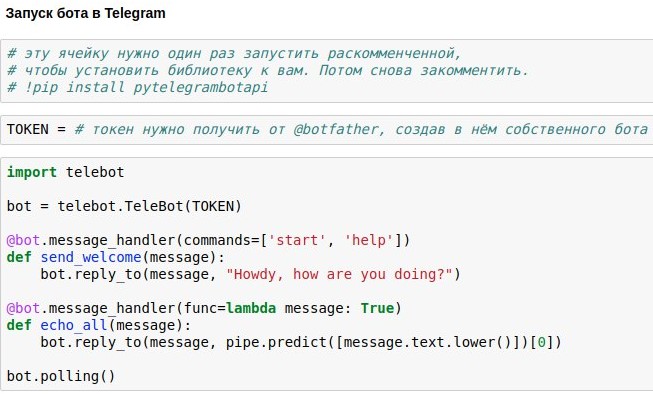
Ich lade absichtlich nicht den vollständigen Code für den Artikel hoch - Sie werden viel mehr Freude und nützliche Erfahrung haben, wenn Sie ihn selbst drucken und aufgrund Ihrer eigenen Bemühungen einen funktionierenden Bot erhalten. Nun, oder wenn Sie zu faul sind, können Sie mit
meiner Version des Bots chatten.