Moderne Informationssysteme sind recht komplex. Last but not least ist ihre Komplexität auf die Komplexität der in ihnen verarbeiteten Daten zurückzuführen. Die Komplexität der Daten liegt häufig in der Vielfalt der verwendeten Datenmodelle. Wenn die Daten beispielsweise "groß" werden, wird eine der unbequemen Eigenschaften nicht nur als ihr Volumen ("Volumen"), sondern auch als ihre Vielfalt ("Vielfalt") betrachtet.
Wenn Sie immer noch keinen Fehler in der Argumentation finden, lesen Sie weiter.

Polyglotte Persistenz
Das Vorstehende führt dazu, dass es manchmal sogar im Rahmen eines Systems erforderlich ist, mehrere verschiedene DBMS zum Speichern von Daten und Lösen verschiedener Aufgaben für deren Verarbeitung zu verwenden, von denen jedes sein eigenes Datenmodell unterstützt. Mit der leichten Hand von M. Fowler, dem Autor mehrerer bekannter Bücher und einem der Mitautoren des Agilen Manifests, wurde diese Situation als multivariate Speicherung („polyglotte Persistenz“) bezeichnet.
Fowler besitzt auch das folgende Beispiel für die Organisation der Datenspeicherung in einer voll funktionsfähigen und hoch geladenen Anwendung im Bereich des elektronischen Handels.

Dieses Beispiel ist natürlich etwas übertrieben, aber einige Überlegungen zur Auswahl des einen oder anderen DBMS für den entsprechenden Zweck finden Sie beispielsweise hier .
Es ist klar, dass es nicht einfach ist, Minister in einem solchen Zoo zu sein.
- Die Menge an Code, die die Datenspeicherung durchführt, wächst proportional zur Anzahl der verwendeten DBMS. Die Menge an Code, die die Daten synchronisiert, ist gut, wenn nicht proportional zum Quadrat dieser Zahl.
- Ein Vielfaches der Anzahl der verwendeten DBMS erhöht die Kosten für die Bereitstellung von Unternehmensmerkmalen (Skalierbarkeit, Fehlertoleranz, Hochverfügbarkeit) für jedes der verwendeten DBMS.
- Es ist nicht möglich, die Unternehmensmerkmale des gesamten Speichersubsystems anzugeben - insbesondere die Transaktionsmerkmale.
Aus Sicht des Direktors des Zoos sieht alles so aus:
- Mehrfache Erhöhung der Kosten für Lizenzen und technischen Support durch den DBMS-Hersteller.
- Mitarbeiter aufblähen und längere Vorlaufzeiten.
- Direkte finanzielle Verluste oder Strafen aufgrund inkonsistenter Daten.
Die Gesamtbetriebskosten des Systems (TCO) steigen erheblich an. Gibt es einen Ausweg aus der Situation des „multivariaten Speichers“?
Multimodell
Der Begriff "multivariater Speicher" wurde 2011 verwendet. Das Bewusstsein für die Probleme des Ansatzes und die Suche nach einer Lösung dauerte mehrere Jahre, und bis 2015 wurde die Antwort von Gartner-Analysten formuliert:
Diesmal scheinen sich die Analysten von Gartner nicht mit der Prognose geirrt zu haben. Wenn Sie zu der Seite mit der Hauptbewertung von DBMS für DB-Engines gehen, können Sie sehen, dass sich die meisten ihrer Führungskräfte genau als DBMS mit mehreren Modellen positionieren. Das gleiche kann auf der Seite mit jeder privaten Bewertung gesehen werden.
Die folgende Tabelle zeigt das DBMS - die führenden Unternehmen in den einzelnen privaten Ratings, die ihr Multi-Modell deklarieren. Für jedes DBMS wird das ursprünglich unterstützte Modell (einmal das einzige) und damit die jetzt unterstützten Modelle angegeben. Es gibt auch DBMS, die sich als "anfänglich Multi-Modell" positionieren und laut den Erstellern kein anfänglich vererbtes Modell haben.
TabellennotizenSternchen in der Tabelle kennzeichnen Aussagen, die Vorbehalte erfordern:
- PostgreSQL unterstützt kein Diagrammdatenmodell, wird jedoch von einem darauf basierenden Produkt wie beispielsweise AgensGraph unterstützt.
- In Bezug auf MongoDB ist es korrekter, mehr über das Vorhandensein von Diagrammoperatoren in der Abfragesprache (
$lookup , $graphLookup ) zu $graphLookup als über die Unterstützung des Diagrammmodells, obwohl ihre Einführung natürlich einige Optimierungen auf der Ebene des physischen Speichers in Richtung der Unterstützung des Diagrammmodells erforderte. - Für Redis bezieht sich dies auf die RedisGraph- Erweiterung.
Außerdem werden wir für jede der Klassen zeigen, wie die Unterstützung mehrerer Modelle im DBMS aus dieser Klasse implementiert wird. Wir werden die wichtigsten relationalen, Dokument- und Diagrammmodelle betrachten und anhand von Beispielen für ein bestimmtes DBMS zeigen, wie die "fehlenden" implementiert werden.
Multimodell-DBMS basierend auf einem relationalen Modell
Die führenden DBMS sind derzeit relational, die Gartner-Prognose könnte nicht als wahr angesehen werden, wenn die RDBMS keine Bewegung in Richtung Multi-Modell zeigten. Und sie demonstrieren. Jetzt kann die Idee, dass ein Multimodell-DBMS wie ein Schweizer Messer ist, was nicht gut gemacht werden kann, sofort an Larry Ellison gesendet werden.
Dem Autor gefällt jedoch die Implementierung von Multimodelling in Microsoft SQL Server, an dessen Beispiel die RDBMS-Unterstützung für Dokument- und Diagrammmodelle beschrieben wird.
Dokumentmodell in MS SQL Server
Über die Unterstützung des Dokumentmodells durch MS SQL Server gab es bereits zwei hervorragende Artikel zu Habré. Ich werde mich auf eine kurze Nacherzählung und einen Kommentar beschränken:
Die Unterstützung des Dokumentmodells in MS SQL Server ist typisch für relationale DBMS: Es wird vorgeschlagen, JSON-Dokumente in Nur-Text-Feldern zu speichern. Die Unterstützung von Dokumentmodellen besteht darin, spezielle Operatoren zum Parsen dieses JSON bereitzustellen:
Das zweite Argument für beide Operatoren ist ein Ausdruck in JSONPath-ähnlicher Syntax.
Es kann abstrakt gesagt werden, dass auf diese Weise gespeicherte Dokumente im Gegensatz zu Tupeln keine „erstklassigen Entitäten“ in einem relationalen DBMS sind. Insbesondere verfügt MS SQL Server derzeit nicht über Indizes für die Felder von JSON-Dokumenten, was es schwierig macht, Tabellen anhand der Werte dieser Felder zu verknüpfen und sogar Dokumente anhand dieser Werte auszuwählen. In diesem Feld ist es jedoch möglich, eine berechenbare Spalte und einen Index dafür zu erstellen.
Darüber hinaus bietet MS SQL Server die Möglichkeit, mithilfe der FOR JSON PATH Anweisung bequem ein JSON-Dokument aus dem Inhalt von Tabellen zu FOR JSON PATH Funktion ist in gewissem Sinne das Gegenteil des vorherigen normalen Speichers. Es ist klar, dass dieser Ansatz, egal wie schnell das RDBMS ist, der Ideologie von Dokument-DBMS widerspricht, die tatsächlich vorgefertigte Antworten auf häufig gestellte Fragen speichern und nur Probleme der einfachen Entwicklung, aber nicht der Geschwindigkeit lösen können.
Schließlich können Sie mit MS SQL Server das Problem lösen, das umgekehrt zum Design des Dokuments ist: Sie können JSON mit OPENJSON in Tabellen OPENJSON . Wenn das Dokument nicht vollständig flach ist, müssen Sie CROSS APPLY .
Diagrammmodell in MS SQL Server
Die Unterstützung für in Microsoft SQL Server implementierte Grafikmodelle ( LPG ) ist ebenfalls vorhersehbar : Es wird vorgeschlagen, spezielle Tabellen zum Speichern von Knoten und zum Speichern von Diagrammkanten zu verwenden. Solche Tabellen werden mit den Ausdrücken CREATE TABLE AS NODE bzw. CREATE TABLE AS EDGE .
Tabellen des ersten Typs ähneln normalen Tabellen zum Speichern von Datensätzen mit dem einzigen externen Unterschied, dass die Tabelle das Systemfeld $node_id - eine in der Datenbank eindeutige Diagrammknoten- $node_id .
In ähnlicher Weise haben Tabellen des zweiten Typs die Systemfelder $from_id und $to_id . Datensätze in solchen Tabellen definieren klar die Beziehungen zwischen Knoten. In einer separaten Tabelle werden Beziehungen jedes Typs gespeichert.
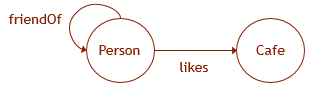 Wir veranschaulichen, was am Beispiel gesagt wurde. Lassen Sie die Diagrammdaten ein Schema haben, wie in der Abbildung gezeigt. Um die entsprechende Struktur in der Datenbank zu erstellen, müssen Sie die folgenden DDL-Abfragen ausführen:
Wir veranschaulichen, was am Beispiel gesagt wurde. Lassen Sie die Diagrammdaten ein Schema haben, wie in der Abbildung gezeigt. Um die entsprechende Struktur in der Datenbank zu erstellen, müssen Sie die folgenden DDL-Abfragen ausführen:
CREATE TABLE Person ( ID INTEGER NOT NULL, name VARCHAR(100) ) AS NODE; CREATE TABLE Cafe ( ID INTEGER NOT NULL, name VARCHAR(100), ) AS NODE; CREATE TABLE likes ( rating INTEGER ) AS EDGE; CREATE TABLE friendOf AS EDGE;
Die Hauptspezifität solcher Tabellen besteht darin, dass es möglich ist, Diagrammmuster mit Cypher-ähnlicher Syntax in Abfragen für sie zu verwenden (" * " usw. werden jedoch noch nicht unterstützt). Basierend auf Leistungsmessungen kann auch angenommen werden, dass sich die Methode zum Speichern von Daten in diesen Tabellen von dem Mechanismus zum Speichern von Daten in normalen Tabellen unterscheidet und für die Durchführung solcher Diagrammabfragen optimiert ist.
SELECT Cafe.name FROM Person, likes, Cafe WHERE MATCH (Person-(friendOf)-(likes)->Cafe) AND Person.name = 'John';
Darüber hinaus ist es ziemlich schwierig, diese Diagrammmuster bei der Arbeit mit solchen Tabellen nicht zu verwenden, da bei normalen SQL-Abfragen zur Lösung ähnlicher Probleme zusätzliche Anstrengungen erforderlich sind, um System- "Diagramm" -Knoten- $node_id ( $node_id , $from_id , $to_id ; dafür zu erhalten) Aus dem gleichen Grund werden Dateneinfügungsanfragen hier nicht als zu umständlich angegeben.
Wenn ich die Beschreibung der Implementierungen der Dokument- und Diagrammmodelle in MS SQL Server zusammenfasse, möchte ich feststellen, dass solche Implementierungen eines Modells über einem anderen nicht in erster Linie im Hinblick auf das Sprachdesign erfolgreich zu sein scheinen. Es ist erforderlich, eine Sprache mit einer anderen zu erweitern, Sprachen sind nicht vollständig „orthogonal“, die Kompatibilitätsregeln können ziemlich bizarr sein.
Multimodell-DBMS basierend auf einem Dokumentmodell
In diesem Abschnitt möchte ich die Implementierung von Multimodellen in Dokument-DBMS am Beispiel der nicht so beliebten MongoDB veranschaulichen (wie bereits erwähnt, enthält sie nur bedingte Diagrammoperatoren $lookup und $graphLookup , die nicht für Shard-Sammlungen funktionieren). In diesem Beispiel ist sie jedoch ausgereifter und Unternehmen »DBMS MarkLogic .
Lassen Sie die Sammlung also eine Reihe von XML-Dokumenten der folgenden Form enthalten (MarkLogic ermöglicht auch das Speichern von JSON-Dokumenten):
<Person INN="631803299804"> <name>John</name> <surname>Smith</surname> </Person>
Relationales Modell bei MarkLogic
Eine relationale Darstellung einer Sammlung von Dokumenten kann mithilfe einer Anzeigevorlage erstellt werden (der Inhalt der value im folgenden Beispiel kann ein beliebiger XPath sein):
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <rows> <row> <view-name>Person</view-name> <columns> <column> <name>SSN</name> <value>@SSN</value> <type>string</type> </column> <column> <name>name</name> <value>name</value> </column> <column> <name>surname</name> <value>surname</value> </column> </columns> </row> <rows> </template>
Eine SQL-Abfrage kann an die erstellte Ansicht adressiert werden (z. B. über ODBC):
SELECT name, surname FROM Person WHERE name="John"
Leider ist die mit der Anzeigevorlage erstellte relationale Ansicht schreibgeschützt. Bei der Verarbeitung einer Anfrage versucht MarkLogic, Dokumentindizes zu verwenden. Früher gab es in MarkLogic nur begrenzte relationale Ansichten, die vollständig indexbasiert und beschreibbar waren. Jetzt gelten sie als veraltet.
Diagrammmodell in MarkLogic
Mit der Unterstützung des Graph ( RDF ) -Modells sind die Dinge ziemlich gleich. Mit der Anzeigevorlage können Sie erneut eine RDF-Darstellung der Dokumentensammlung aus dem obigen Beispiel erstellen:
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <vars> <var> <name>PREFIX</name> <val>"http://example.org/example#"</val> </var> </vars> <triples> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || surname )</value></predicate> <object><value>xs:string( surname )</value></object> </triple> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || name )</value></predicate> <object><value>xs:string( name )</value></object> </triple> </triples> </template>
Das resultierende RDF-Diagramm kann mit einer SPARQL-Abfrage adressiert werden:
PREFIX : <http://example.org/example
Im Gegensatz zum relationalen Modell unterstützt das MarkLogic-Diagrammmodell zwei weitere Möglichkeiten:
- Das DBMS kann ein vollwertiges separates Repository für RDF-Daten sein (Triplets darin werden im Gegensatz zu dem oben extrahierten Extrakt als verwaltet bezeichnet ).
- RDF in spezieller Serialisierung kann einfach in XML- oder JSON-Dokumente eingefügt werden (und Triplets werden dann als nicht verwaltet bezeichnet ). Dies ist wahrscheinlich eine solche Alternative zu
idref Mechanismen usw.
Die Optic-API gibt eine gute Vorstellung davon, wie „wirklich“ alles in MarkLogic funktioniert. In diesem Sinne ist sie auf niedriger Ebene, obwohl ihr Zweck eher das Gegenteil ist - zu versuchen, vom verwendeten Datenmodell zu abstrahieren, um eine konsistente Arbeit mit Daten in verschiedenen Modellen, Transaktions- und Transaktionsmöglichkeiten sicherzustellen pr
Multimodell-DBMS „ohne Hauptmodell“
DBMS sind auch auf dem Markt erhältlich und positionieren sich als anfänglich Multi-Modell ohne vererbtes Grundmodell. Dazu gehören ArangoDB , OrientDB (seit 2018 gehört das Entwicklungsunternehmen zu SAP) und CosmosDB (ein in der Microsoft Azure-Cloud-Plattform enthaltener Dienst).
Tatsächlich gibt es in ArangoDB und OrientDB „grundlegende“ Modelle. In beiden Fällen handelt es sich um proprietäre Datenmodelle, bei denen es sich um Dokumentverallgemeinerungen handelt. Verallgemeinerungen dienen hauptsächlich dazu, die Erstellung von grafischen und relationalen Abfragen zu erleichtern.
Diese Modelle sind die einzigen, die für die Verwendung in den angegebenen DBMS verfügbar sind. Ihre eigenen Abfragesprachen funktionieren mit ihnen. Natürlich sind solche Modelle und DBMS vielversprechend, aber die mangelnde Kompatibilität mit Standardmodellen und -sprachen macht es unmöglich, diese DBMS in Legacy-Systemen zu verwenden und sie durch das bereits verwendete DBMS zu ersetzen.
Über ArangoDB und OrientDB auf Habré gab es bereits einen wunderbaren Artikel: JOIN in NoSQL-Datenbanken .
Arangodb
ArangoDB beansprucht Unterstützung für ein Diagrammdatenmodell.
Diagrammknoten in ArangoDB sind normale Dokumente, und Kanten sind Dokumente einer besonderen Art, die zusammen mit den üblichen Systemfeldern ( _key , _id , _rev ) die Systemfelder _from und _to . Dokumente in Dokument-DBMS werden traditionell zu Sammlungen zusammengefasst. Sammlungen von Dokumenten, die Kanten darstellen, werden in ArangoDB als Kantensammlungen bezeichnet. Dokumente von Kantensammlungen sind übrigens auch Dokumente, sodass Kanten in ArangoDB auch als Knoten fungieren können.
AusgangsdatenAngenommen, wir haben eine Sammlung von persons deren Dokumente folgendermaßen aussehen:
[ { "_id" : "people/alice" , "_key" : "alice" , "name" : "" }, { "_id" : "people/bob" , "_key" : "bob" , "name" : "" } ]
Lassen Sie auch eine Sammlung von cafes :
[ { "_id" : "cafes/jd" , "_key" : "jd" , "name" : " " }, { "_id" : "cafes/jj" , "_key" : "jj" , "name" : "-" } ]
Dann könnte die likes Sammlung folgendermaßen aussehen:
[ { "_id" : "likes/1" , "_key" : "1" , "_from" : "persons/alice" , "_to" : "cafes/jd", "since" : 2010 }, { "_id" : "likes/2" , "_key" : "2" , "_from" : "persons/alice" , "_to" : "cafes/jj", "since" : 2011 } , { "_id" : "likes/3" , "_key" : "3" , "_from" : "persons/bob" , "_to" : "cafes/jd", "since" : 2012 } ]
Abfragen und ErgebnisseEine grafische Abfrage in AQL, die in ArangoDB verwendet wird und in lesbarer Form Informationen darüber zurückgibt, wer welches Café mag, sieht folgendermaßen aus:
FOR p IN persons FOR c IN OUTBOUND p likes RETURN { person : p.name , likes : c.name }
In einem relationalen Stil kann diese Abfrage wie folgt umgeschrieben werden, wenn es wahrscheinlicher ist, dass wir die Beziehungen „berechnen“, anstatt sie zu speichern (Sie könnten übrigens auch auf die likes Sammlung verzichten):
FOR p IN persons FOR l IN likes FILTER p._key == l._from FOR c IN cafes FILTER l._to == c._key RETURN { person : p.name , likes : c.name }
Das Ergebnis ist in beiden Fällen das gleiche:
[ { "person" : "" , likes : "-" } , { "person" : "" , likes : " " } , { "person" : "" , likes : " " } ]
Weitere Fragen und ErgebnisseWenn das Format des obigen Ergebnisses für ein relationales DBMS typischer ist als für ein Dokument, können Sie diese Abfrage versuchen (oder COLLECT ):
FOR p IN persons RETURN { person : p.name, likes : ( FOR c IN OUTBOUND p likes RETURN c.name ) }
Das Ergebnis ist wie folgt:
[ { "person" : "" , likes : ["-" , " "] } , { "person" : "" , likes : [" "] } ]
Oriententb
Die Implementierung des Diagrammmodells über dem Dokumentmodell in OrientDB basiert auf der Fähigkeit von Dokumentfeldern, zusätzlich zu mehr oder weniger standardmäßigen Skalarwerten Werte von Typen wie LINK , LINKLIST , LINKSET , LINKMAP und LINKBAG . Die Werte dieser Typen sind Links oder Sammlungen von Links zu Systemdokument-IDs .
Die vom System zugewiesene Dokumentkennung hat eine „physikalische Bedeutung“, die die Position des Datensatzes in der Datenbank @rid : #3:16 , und sieht @rid : #3:16 so aus: @rid : #3:16 . Daher sind die Werte von Referenzeigenschaften eher Zeiger (wie in einem Diagrammmodell) als Auswahlbedingungen (wie in einem relationalen Modell).
Wie in ArangoDB werden in OrientDB die Kanten als separate Dokumente dargestellt (obwohl die Kante, wenn sie keine eigenen Eigenschaften hat, leichtgewichtig gemacht werden kann und kein separates Dokument ihr entspricht).
AusgangsdatenIn einem Format, das dem OrientDB-Datenbank- Dump-Format nahe kommt , sehen die Daten aus dem vorherigen Beispiel für ArangoDB ungefähr so aus:
[ { "@type": "document", "@rid": "#11:0", "@class": "Person", "name": "", "out_likes": [ "#30:1", "#30:2" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#12:0", "@class": "Person", "name": "", "out_likes": [ "#30:3" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#21:0", "@class": "Cafe", "name": "-", "in_likes": [ "#30:2", "#30:3" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#22:0", "@class": "Cafe", "name": " ", "in_likes": [ "#30:1" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#30:1", "@class": "likes", "in": "#22:0", "out": "#11:0", "since": 1262286000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:2", "@class": "likes", "in": "#21:0", "out": "#11:0", "since": 1293822000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:3", "@class": "likes", "in": "#21:0", "out": "#12:0", "since": 1325354400000, "@fieldTypes": "in=LINK,out=LINK,since=date" } ]
Wie wir sehen können, speichern die Eckpunkte auch Informationen über eingehende und ausgehende Kanten. Wenn Sie die Dokument-API verwenden, müssen Sie die referenzielle Integrität selbst befolgen, und die Graph-API kümmert sich darum. Aber mal sehen, wie der Aufruf von OrientDB in "sauber" aussieht, nicht in Programmiersprachen integriert, Abfragesprachen.
Abfragen und ErgebnisseEine Abfrage, deren Zweck der Abfrage aus dem Beispiel für ArangoDB in OrientDB ähnelt, sieht folgendermaßen aus:
SELECT name AS person_name, OUT('likes').name AS cafe_name FROM Person UNWIND cafe_name
Das Ergebnis wird wie folgt erhalten:
[ { "person_name": "", "cafe_name": " " }, { "person_name": "", "cafe_name": "-" }, { "person_name": "", "cafe_name": "-" } ]
Wenn das Format des Ergebnisses erneut zu "relational" erscheint, müssen Sie die Zeile mit UNWIND() entfernen:
[ { "person_name": "", "cafe_name": [ " ", "-" ] }, { "person_name": "", "cafe_name": [ "-" ' } ]
Die OrientDB-Abfragesprache kann als SQL mit Gremlin-ähnlichen Einfügungen beschrieben werden. In Version 2.2 wurde das Cypher-ähnliche Anforderungsformular MATCH :
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe} RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name GROUP BY person_name
Das Format des Ergebnisses ist das gleiche wie in der vorherigen Abfrage. Überlegen Sie, was entfernt werden muss, um es „relationaler“ zu machen, wie in der ersten Abfrage.
Azure CosmosDB
In geringerem Maße bezieht sich das, was oben über ArangoDB und OrientDB gesagt wurde, auf Azure CosmosDB. CosmosDB bietet die folgenden Datenzugriffs-APIs: SQL, MongoDB, Gremlin und Cassandra.
Die SQL-API und die MongoDB-API werden verwendet, um auf Daten im Dokumentmodell zuzugreifen. Gremlin-API und Cassandra-API - für den Zugriff auf Daten in Grafiken bzw. Spalten. Daten in allen Modellen werden im Format des internen CosmosDB-Modells gespeichert: ARS („Atom-Record-Sequence“), das sich ebenfalls in der Nähe des Dokuments befindet.

Das vom Benutzer ausgewählte Datenmodell und die verwendete API sind jedoch zum Zeitpunkt der Erstellung des Kontos im Dienst festgelegt. Es ist unmöglich, auf die in ein Modell geladenen Daten im Format eines anderen Modells zuzugreifen, was durch Folgendes veranschaulicht würde:

Daher bietet das Multimodell in Azure CosmosDB heute nur die Möglichkeit, mehrere Datenbanken zu verwenden, die unterschiedliche Modelle desselben Herstellers unterstützen, wodurch nicht alle Probleme des multivariaten Speichers gelöst werden.
Multimodell-DBMS basierend auf einem Diagrammmodell?
Es ist bemerkenswert, dass es auf dem Markt keine Multimodell-DBMS gibt, die auf einem Diagrammmodell basieren (mit Ausnahme der Multimodell-Unterstützung für zwei Grafikmodelle gleichzeitig: RDF und LPG; siehe dies in einer früheren Veröffentlichung ). Die größten Schwierigkeiten sind die Implementierung über dem Diagrammmodell des Dokuments und nicht die relationale.
Die Frage, wie ein relationales Modell über ein Graphmodell implementiert werden kann, wurde bereits zum Zeitpunkt der Bildung des letzteren berücksichtigt. Wie David McGovern zum Beispiel sagte :
Der Graph-Ansatz enthält nichts, was das Erstellen einer Ebene (z. B. durch geeignete Indizierung) in einer Graph-Datenbank verhindert, die eine relationale Ansicht mit (1) Wiederherstellung von Tupeln aus den üblichen Schlüsselwertpaaren und (2) Gruppierung von Tupeln nach ermöglicht Beziehungstyp.
Wenn Sie das Dokumentmodell über dem Diagramm implementieren, müssen Sie beispielsweise Folgendes berücksichtigen:
- Elemente des JSON-Arrays werden als geordnet betrachtet und kommen vom oberen Rand des Diagramms - nein;
- Die Daten im Dokumentmodell sind normalerweise denormalisiert. Sie möchten immer noch nicht mehrere Kopien desselben angehängten Dokuments speichern, und Unterdokumente haben normalerweise keine Bezeichner.
- Andererseits besteht die Ideologie von Dokument-DBMS darin, dass Dokumente vorgefertigte „Einheiten“ sind, die nicht jedes Mal neu erstellt werden müssen. Es ist erforderlich, im Diagrammmodell die Möglichkeit bereitzustellen, den dem fertigen Dokument entsprechenden Untergraphen schnell zu erhalten.
Etwas WerbungDer Autor des Artikels bezieht sich auf die Entwicklung des NitrosBase-DBMS, dessen internes Modell grafisch ist, und dessen Darstellung externe Modelle - relational und dokumentarisch - sind. Alle Modelle sind gleich: Fast alle Daten sind in jedem von ihnen in der dafür vorgesehenen Abfragesprache verfügbar. Darüber hinaus können sich die Daten in jeder Darstellung ändern. Änderungen werden im internen Modell und entsprechend in anderen Darstellungen berücksichtigt.
Wie das Modell-Matching in NitrosBase aussieht - ich werde es hoffentlich in einem der folgenden Artikel beschreiben.
Fazit
Ich hoffe, dass die allgemeinen Konturen des sogenannten Multimodellierens für den Leser mehr oder weniger klar geworden sind. Ganz unterschiedliche DBMS werden als Multimodelle bezeichnet, und „Unterstützung für mehrere Modelle“ kann unterschiedlich aussehen. Um zu verstehen, was in jedem Fall als "Multi-Modell" bezeichnet wird, ist es hilfreich, die folgenden Fragen zu beantworten:
- Geht es um die Unterstützung traditioneller Modelle oder um ein einzelnes Hybridmodell?
- Sind die Modelle „gleich“ oder unterliegt eines den anderen?
- Sind die Modelle einander "gleichgültig"? Können die in einem Modell aufgezeichneten Daten in einem anderen gelesen oder sogar überschrieben werden?
Ich denke, dass es bereits möglich ist, die Frage nach der Relevanz von Multimodell-DBMS positiv zu beantworten, aber die Frage, welche spezifischen Sorten in naher Zukunft stärker nachgefragt werden, ist interessant. Es scheint, dass DBMS mit mehreren Modellen, die traditionelle Modelle unterstützen, hauptsächlich relationale, stärker nachgefragt werden. , , , — .