Hinweis perev. : Was heute als SRE (Site Reliability Engineering - „Gewährleistung der Zuverlässigkeit von Informationssystemen“) bezeichnet wird, umfasst eine breite Palette von Maßnahmen für den Betrieb von Softwareprodukten, mit denen das erforderliche Maß an Zuverlässigkeit erreicht werden soll. Die Überwachung ist eines der Schlüsselereignisse, und die „goldenen Signale“ bilden die wichtigsten Metriken, die darin berücksichtigt werden sollten. Nachdem wir auf Habré kein Material darüber gefunden hatten, beschlossen wir, eine kurze Notiz der Autoren der Incident Management-Plattform (VictorOps) zu übersetzen, die eine Vorstellung von der allgemeinen Idee dieses Ansatzes gibt.
Effektives Site Reliability Engineering (
SRE ) basiert auf einem tiefen Verständnis der zugrunde liegenden Service-Infrastruktur und -Architektur. Die Erhöhung der Transparenz des Status der Anwendung und der Infrastruktur ist nur der Beginn proaktiver Arbeiten zur Schaffung zuverlässiger Systeme. Gleichzeitig gelten die sogenannten „vier goldenen Signale“ SRE als bester Ausgangspunkt für die Überwachung des Systemstatus. Nachdem wir diese vier grundlegenden Überwachungsmethoden festgelegt haben, können wir die Transparenz des Systems weiter erhöhen.
Durch die Erhöhung der Transparenz in Verbindung mit effektiven Methoden für die Zusammenarbeit können SRE-Teams Systeme schnell überwachen und Maßnahmen ergreifen, um die Folgen von Vorfällen zu beseitigen und die allgemeine Wirksamkeit von
Überwachungs- und Warnmethoden zu erhöhen. Mithilfe von Gold SRE-Signalen können Teams potenzielle Schwachstellen in der Zuverlässigkeit erkennen und sich auf die Behebung von Infrastrukturproblemen konzentrieren. Lassen Sie uns die Beziehung zwischen Überwachungsmethoden und SRE-Befehlen untersuchen und herausfinden, welche Auswirkungen die Goldsignale auf den Prozess haben.
Überwachung und SRE
In Teil III unseres
DevOps-Wörterbuchs haben wir das Internet untersucht und versucht, eine Definition von SRE zu finden. In einem verwandten
Wikipedia-Artikel heißt es:
„Ben Treynor, der Gründer des Site Reliability Teams bei Google [sagt], dass SRE„ das ist, was passiert, wenn ein Softwareentwickler das tut, was früher als Wartung bezeichnet wurde “ . SRE kombiniert die Herausforderungen und Fähigkeiten des Software-Engineerings mit den Herausforderungen des IT-Betriebs und hilft Ihnen, Lösungen für Zuverlässigkeitsprobleme zu finden. Es versteht sich, dass SRE-Teams ihre Dienste überwachen sollten, um Bereiche zu identifizieren, in denen die Zuverlässigkeit verbessert werden kann.
Genau das ist die Überwachungsaufgabe für die SRE-Teams. Es spielt nur eine geringe Rolle bei der
Schaffung hochtransparenter Systeme . Dies ist jedoch ein wichtiges Element für das Verständnis des Status von Anwendungen und Infrastruktur. Vier goldene Überwachungssignale und SRE bieten ein grundlegendes Maß an Transparenz hinsichtlich der Zuverlässigkeit von allem, was Sie erstellen. Nachdem Sie ein angenehmes Maß an Beobachtbarkeit des Zustands der Goldsignale erreicht haben, können Sie diese zusätzlichen Informationen mithilfe von Überwachungstools für eine eingehendere Analyse verwenden.
Nachdem wir uns für die Wichtigkeit der Überwachung der Gold-SRE-Signale entschieden haben, wenden wir uns den realen Metriken zu, aus denen sie bestehen.
Vier goldene Überwachungssignale
Zu Beginn des Weges zur Verbesserung der Überwachungsbemühungen kann es schwierig sein zu verstehen, wo man anfangen soll. Die vier goldenen SRE- und Überwachungssignale wurden erstmals in
Googles Buch über SRE zitiert und werden jetzt von vielen Teams aktiv genutzt. Es ist großartig, mit ihnen zu beginnen, da sie dabei helfen, die wichtigsten Metriken hervorzuheben, die immer verfolgt werden sollten.
Schauen wir uns also die goldenen Signale an und sehen, warum ihre Überwachung ein wesentlicher Bestandteil bei der Gewährleistung der Zuverlässigkeit eines Systems ist.
1. Latenz
Wie lange dauert die Bearbeitung einer Anfrage? Definieren Sie einen Referenzpunkt für Verzögerungen, die für erfolgreiche Anforderungen typisch sind, und vergleichen Sie ihn mit Verzögerungen für nicht erfolgreiche Anforderungen. Durch das Verfolgen von durch Fehler verursachten Verzögerungen können Sie alle Probleme im Zusammenhang mit der Geschwindigkeit der Erkennung und Reaktion von Vorfällen beheben.
2. Verkehr
Dieses Signal bedarf keiner besonderen Erläuterung. Welche Auswirkung hat die Anzahl der Benutzer oder die Anzahl der Transaktionen, die den Dienst durchlaufen, auf das System? Abhängig von der Funktionalität des Dienstes kann sich die Verkehrsmessung von Unternehmen zu Unternehmen erheblich unterscheiden. Indem Sie die Interaktionen mit realen Benutzern und dem Datenverkehr verfolgen, können Sie besser verstehen, wie Endbenutzer den Service wahrnehmen, und sich ein Bild davon machen, wie sich Systeme unter Stress verhalten.
3. Fehler
Natürlich sollte jedes Team Fehler im Auge behalten. Unabhängig davon, ob Fehler manuell ausgelöst werden oder autonom sind (wie eine fehlgeschlagene HTTP-Anforderung), sollten SRE-Befehle sie verfolgen. Viele SRE-Teams verwenden eine spezielle
Incident-Management-Software, um sie auf kritische Fehler aufmerksam
zu machen, ihre Ursachen zu finden und Korrekturmaßnahmen zu ergreifen.
4. Sättigung
Jedes Team sollte die Auslastung seines Systems überwachen. Es ist wichtig, eine Metrik für die Sättigung festzulegen, was bedeuten würde, dass der Dienst das Maximum seiner Fähigkeiten erreicht hat. Die meisten Dienste verlieren bereits an Leistung, bevor die Last 100% erreicht. Daher ist es wichtig, die Funktionalität Ihres eigenen Systems zu verstehen, um die sinnvolle Sättigungsrichtlinie zu ermitteln.
Durch das Einrichten von Überwachungs- und Warnregeln für die vier goldenen Signale decken Sie die meisten wichtigen Vorfälle im System ab. Um jedoch ein proaktives Überwachungssystem und SRE zu erstellen, müssen Sie noch tiefer graben.
Hinweis perev. : Als Beispiel für die Darstellung eines Dashboards mit "Golden Signals" -Diagrammen präsentieren wir das Ergebnis der entsprechenden Überwachungskonfiguration für Kubernetes aus diesem Artikel von Sysdig :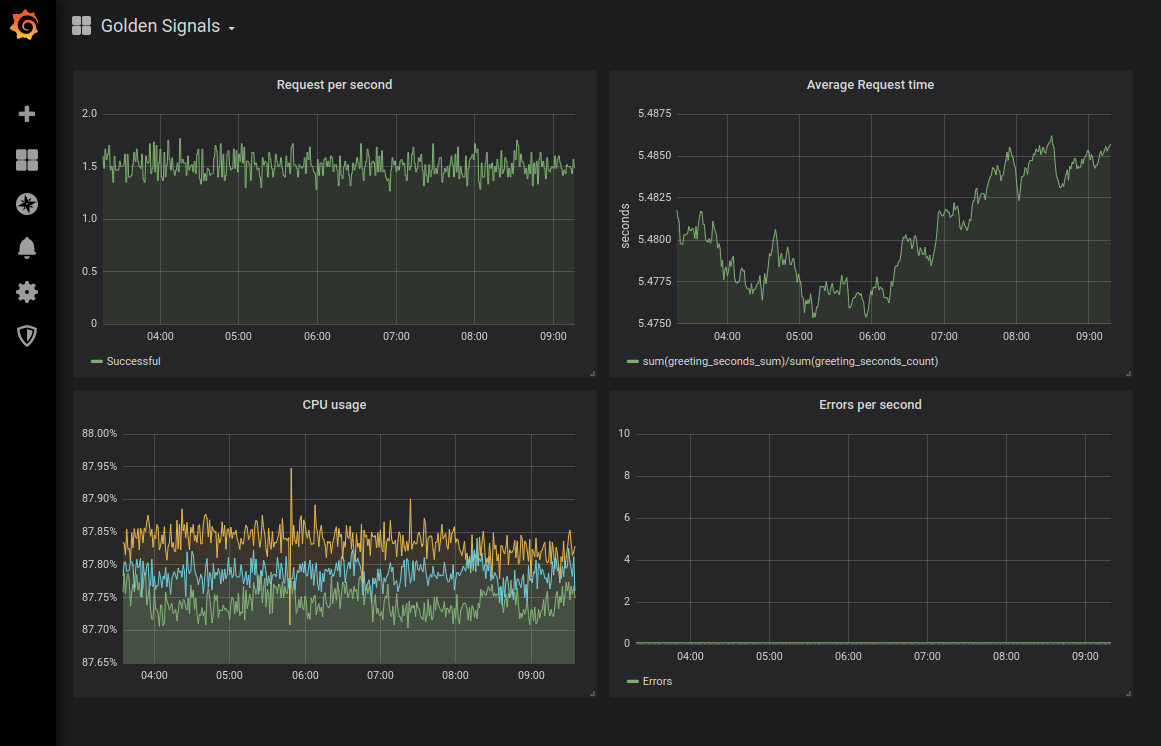 Hinweis perev. : Und hier ist eine visuellere Darstellung der Goldsignale von Denise Yu , die als praktisches Memo verwendet werden kann:
Hinweis perev. : Und hier ist eine visuellere Darstellung der Goldsignale von Denise Yu , die als praktisches Memo verwendet werden kann:
Proaktives SRE geht über Goldsignale hinaus
Die Überwachung goldener Signale ist ein guter Anfang für die Analyse von Vorfällen im Dienst, reicht jedoch nicht aus. Erfahrene SRE-Teams erkunden ihre Systeme proaktiv mit zahlreichen zusätzlichen Methoden. SRE-Teams führen in der Vorbereitungsphase und in der Produktion organisierte Tests durch und untersuchen aktiv ihre Systeme und nutzen die erhaltenen Informationen, um die Zuverlässigkeit der Dienste zu erhöhen.
Chaos Engineering
Chaos Engineering ist eine Disziplin, mit der Teams ihre Systeme testen, um Schwachstellen und Schwachstellen proaktiv zu erkennen. Wenn Sie das Chaos manuell in den Dienst einführen, können Sie sehen, wie das System auf verschiedene Umstände reagiert.
Hinweis perev. : Lesen Sie mehr über diesen Ansatz im Artikel „Chaos Engineering: Die Kunst der absichtlichen Zerstörung“ ( Teil 1 und Teil 2 ).Spieltage
Während sich das Chaos Engineering auf das Verständnis des Systems konzentriert, helfen
Spieltage den Mitarbeitern, es zu verstehen. Sie werden verwendet, um die Widerstandsfähigkeit von Teams zu testen, wenn es darum geht, auf Vorfälle zu reagieren und deren Konsequenzen zu beseitigen. Die Ergebnisse von Spieltagen können verwendet werden, um effizientere Prozesse zu entwickeln oder um den Bedarf an neuen Tools zu ermitteln, die die Effizienz der Mitarbeiter steigern.
Synthetische Überwachung
Mithilfe der
synthetischen Überwachung können Teams künstliche Benutzer erstellen und ihr Verhalten mithilfe des Dienstes simulieren. Sie können bestimmte Verhaltensmuster festlegen und beobachten, wie sich das System unter einer bestimmten Last verhält. Die synthetische Überwachung ist eine hervorragende Methode zum detaillierten Testen und Bestimmen der Zuverlässigkeit bestimmter Dienste im gesamten System.
...
Jedes Team, das den Status des Systems visuell überwachen möchte, muss die goldenen SRE-Signale überwachen. Die Vorstellung vom Zustand und der allgemeinen Zuverlässigkeit des Systems ist jedoch keineswegs gleichbedeutend mit der Erhöhung seiner Zuverlässigkeit. In einem modernen Ökosystem mit stark verteilten Systemen und schneller Bereitstellung stehen SRE-Teams vor einer gewaltigen Aufgabe. Goldsignale für Überwachung und SRE können der Ausgangspunkt sein, von dem aus weitere
Verbesserungen innerhalb des SRE beginnen.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: