Verwenden Sie als Beispiel Daten aus einem IT Service Management System (ITSM).
In einem früheren Artikel über
SAP Process Mining oder das Verständnis unserer Geschäftsprozesse haben wir über Process Mining und seine Anwendung in einer Unternehmensumgebung gesprochen. Heute möchten wir mehr über das Datenmodell und den Prozess seiner Erstellung sprechen. Wir werden uns die Komponenten ansehen, wie sie miteinander verbunden sind, welches Datenformat von Dateneigentümern angefordert werden muss und wie die Ereignistabelle für SAP Process Mining von Celonis erstellt werden könnte.
Datenmodell im SAP PROCESS MINING von CELONIS
Die Datenstruktur im SAP Process Mining by Celonis-Tool ist recht einfach:
- "Ereignistabelle." Dies ist ein erforderlicher Teil des Datenmodells. Eine solche Tabelle kann in jedem einzelnen Datenmodell nur eine sein. Darauf wird automatisch ein Prozessdiagramm generiert. Siehe Abbildung 1.
- Verzeichnisse sind alle anderen Tabellen, die die „Ereignistabelle“ um zusätzliche analytische Informationen erweitern. Im Gegensatz zu ihr in der Referenz ändern sich die Informationen nicht im Laufe der Zeit. Genauer gesagt sollte sich das von uns analysierte Zeitintervall nicht ändern. Beispielsweise kann es sich um eine Tabelle mit einer Beschreibung der Eigenschaften von Verträgen, Beschaffungsgegenständen, Anwendungen für etwas, Mitarbeitern, Vorschriften, Auftragnehmern und anderen Objekten handeln, die irgendwie in den Prozess involviert sind. In diesem Fall beschreibt die Referenz alle Arten von statischen Eigenschaften dieser Objekte (Beträge, Typen, Namen, Namen, Größen, Abteilungen, Adressen und andere verschiedene Attribute). Verzeichnisse sind optional. Sie können das Datenmodell ohne sie ausführen. Die einfache Analyse eines solchen Prozesses ist weniger interessant.
 Abbildung 1. Datenmodell in Proces Mining: Eine Ereignistabelle und ein Verweis auf Prozessinstanzen
Abbildung 1. Datenmodell in Proces Mining: Eine Ereignistabelle und ein Verweis auf ProzessinstanzenEine Ereignistabelle ist eine Standardtabelle (physischer Speicher im Gegensatz zu logischen Tabellen) in der In-Memory-Plattform von SAP HANA. Verzeichnisse können als Standardtabellen (physischer Speicher) und Berechnungstabellen (Berechnungsansichten) dargestellt werden. Mit seltenen Ausnahmen kann es erforderlich sein, dem vorhandenen Datenmodell eine kleine Referenz in Form von CSV oder XLSX hinzuzufügen. Diese Funktion ist direkt in der grafischen Oberfläche vorhanden.
Im Folgenden werden wir uns jede dieser beiden Komponenten des Datenmodells genauer ansehen.
Eine "Ereignistabelle" (auch "Ereignisprotokoll" genannt) enthält mindestens drei erforderliche Spalten:
- Eine Prozesskennung ist ein eindeutiger Schlüssel für jede Prozessinstanz (z. B. eine Referenz, ein Vorfall oder eine Aufgabennummer). Im Beispiel in Abbildung 2 ist dies die Spalte „CASE_ID“.
- Aktivität. Dies ist der Name des Schrittes im Prozess - eine Art Ereignis, an dem wir interessiert sind. Aus den Aktivitäten wird das Prozessdiagramm erstellt (Spalte „EREIGNIS“).
- Zeitstempel des Ereignisses (Spalte "TIMESTAMP").
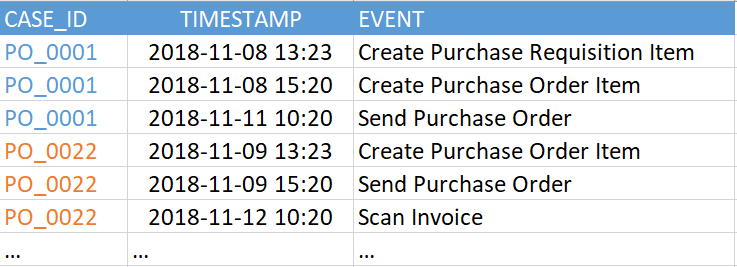 Abbildung 2. Beispiel für eine Ereignistabelle
Abbildung 2. Beispiel für eine EreignistabelleDie aktuelle Version von SAP Process Mining von Celonis unterstützt bis zu 1000 eindeutige Ereignisse in einem einzigen Datenmodell. Das heißt, die Anzahl der eindeutigen Werte in der Spalte "EREIGNIS" im obigen Beispiel (in Ihrer Ereignistabelle kann sie anders aufgerufen werden) sollte nicht mehr als 1000 betragen. Und die Ereignisse selbst (dh die Zeilen in dieser Tabelle) können sehr viel sein. Wir haben Beispiele für Hunderte Millionen Ereignisse in einem Datenmodell gesehen.
Ein Zeitstempel kann entweder durch eine Spalte dargestellt werden. Anschließend müssen Sie bestimmen, was er bedeutet - den Beginn oder das Ende eines Schritts oder zwei Spalten wie in Abbildung 3, wenn Anfang und Ende eines Schritts explizit angegeben sind. Der grundlegende Unterschied zwischen der zweispaltigen Version besteht darin, dass das System automatisch parallel ausgeführte Schritte erkennen kann. Dies zeigt sich beim Vergleich der Start- und Endzeiten der verschiedenen Schritte.
 Abbildung 3. Beispiel einer Ereignistabelle mit zwei Zeitstempeln
Abbildung 3. Beispiel einer Ereignistabelle mit zwei ZeitstempelnAlle anderen Spalten in dieser Tabelle sind optional. Das Prozessdiagramm kann auch mithilfe der drei erforderlichen Spalten erfolgreich wiederhergestellt werden. Es ist jedoch schwierig, das Gefühl zu beseitigen, dass etwas fehlt. Es wird daher dringend empfohlen, sich nicht auf eine minimale Anzahl von Lautsprechern zu beschränken.
Zusätzliche Spalten sind alle Informationen, die Sie interessieren, die sich während des Prozesses ändern oder einem bestimmten Ereignis zugeordnet sind. Zum Beispiel der Name des Mitarbeiters, der das Ereignis durchgeführt hat, die Arbeitsgruppe, die aktuelle Priorität der Anwendung. Die Betonung der Zeitabhängigkeit ist hier kein Zufall. Es wird empfohlen, nur veränderbare Daten in der Ereignistabelle zu belassen. Alle anderen statischen Informationen werden am besten in separaten Verzeichnissen abgelegt. Mit anderen Worten, das Ereignisprotokoll sollte nach Möglichkeit normalisiert werden. Dies geschieht nicht so sehr, um die Datenmenge zu reduzieren, sondern um die weitere Arbeit mit PQL-Ausdrücken in der Phase der Erstellung von Analyseberichten zu erleichtern.
Lass alles an Ort und Stelle seinWas passiert, wenn Sie der „Ereignistabelle“ eine Spalte mit Referenzinformationen hinzufügen? Im Allgemeinen wird zumindest zunächst nichts Schreckliches passieren. Und zum schnellen Testen einer Idee ist diese Option durchaus geeignet. Es kann nur zwei negative Konsequenzen geben: unnötige Reproduktion von Kopien von Daten und zusätzliche Schwierigkeiten bei einigen analytischen Formeln. Diese Schwierigkeiten hätten vermieden werden können, wenn alle zusätzlichen Daten an das Verzeichnis übermittelt worden wären. Im Allgemeinen ist es besser, dies sofort zu tun.
Ein bisschen über die LizenzierungDie Ereignistabelle ist mit der Lizenzierung von SAP Process Mining durch Celonis verknüpft. Ein Datenmodell = 1 Lizenz = 1 Ereignisprotokoll. Mit einer bestimmten Reservierung können wir sagen, dass 1 Ereignisprotokoll = 1 Geschäftsprozess ist. Die Einschränkung lautet wie folgt: Situationen können auftreten, wenn mehrere Prozesse in ein Ereignisprotokoll passen und umgekehrt - mehrere Ereignisprotokolle werden absichtlich für einen Prozess erstellt. Darüber hinaus kann der Begriff „Geschäftsprozess“ unter Datengesichtspunkten recht weit gefasst werden. Aus Lizenzgründen wurde daher für das offensichtliche Kriterium die Anzahl der Ereignisprotokolle ausgewählt. Auf dieses Kriterium sollte man sich verlassen.
VerzeichnisseVerzeichnisse sind optional, das Hinzufügen zum Datenmodell ist optional. Sie enthalten zusätzliche Informationen, die für die Analyse des Prozesses nützlich sein können. Im Gegensatz zur Ereignistabelle sind die Informationen in den Verzeichnissen jedoch statisch und hängen nicht von der Zeit ab, zu der das Ereignis aufgetreten ist.
Ein besonderer Fall sollte hier erwähnt werden. Wenn es um die Daten des Benutzers geht, der die Schritte im Geschäftsprozess ausführt, stellt sich die Frage: Ist diese Informationsreferenz? Einerseits ja - das sind statische Daten. Es wäre schön, in der Ereignistabelle nur eine bestimmte „USER_ID“ zu belassen, nach der Name, Position und Abteilung des Benutzers, Mitgliedschaft in der Arbeitsgruppe usw. mit der Aktivität verknüpft werden. Stellen wir uns andererseits vor, wir analysieren einen Geschäftsprozess in einem Zeitraum von 2-3 Jahren. Während dieser Zeit konnte der Benutzer mehrere Beiträge wechseln und zwischen Abteilungen oder Arbeitsgruppen wechseln. Es stellt sich heraus, dass dies Informationen sind, die sich bereits im Laufe der Zeit ändern. In diesem Fall sollte es in der Ereignistabelle belassen werden, was wiederum dazu führt, dass zusätzlich zu "USER_ID" im Ereignisprotokoll Spalten wie "Arbeitsgruppe", "Position", "Abteilung" und sogar "vollständiger Name" (Nachname) angezeigt werden es könnte sich auch während dieser Zeit ändern). Im Allgemeinen liegt die Frage, ob Benutzerinformationen normalisiert werden sollen oder nicht, im Ermessen des Kunden.
Verzeichnisse können jederzeit zu einem vorhandenen Datenmodell hinzugefügt werden.
Dies zu tun ist ganz einfach:
- In SAP HANA wird eine Tabelle erstellt.
- Die Tabelle wird dem allgemeinen Datenmodell über die Schaltfläche "Daten importieren" hinzugefügt.
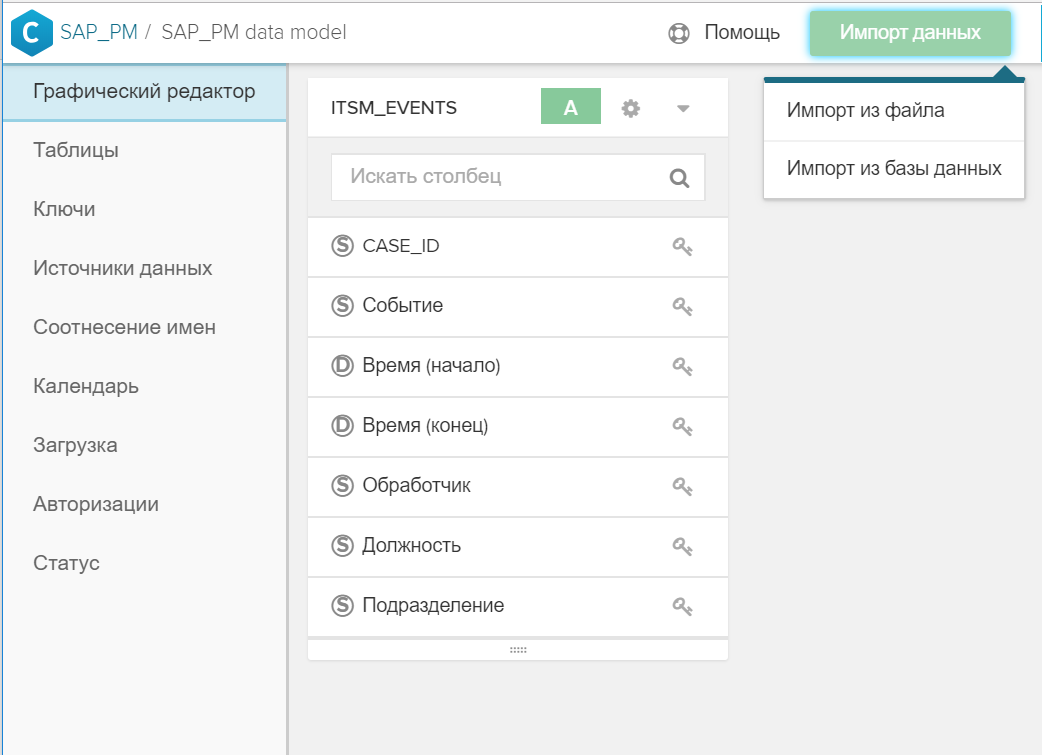
Abbildung 4. Importieren Sie eine Tabelle oder Datei in ein vorhandenes Datenmodell - Der Schlüssel (oder die Schlüssel) wird in der grafischen Oberfläche angezeigt, über die das neue Verzeichnis der Ereignistabelle und / oder anderen Verzeichnissen zugeordnet wird. Klicken Sie dazu einfach auf das Symbol
 in einer Tabelle und dann auf der entsprechenden in einer anderen Tabelle.
in einer Tabelle und dann auf der entsprechenden in einer anderen Tabelle.
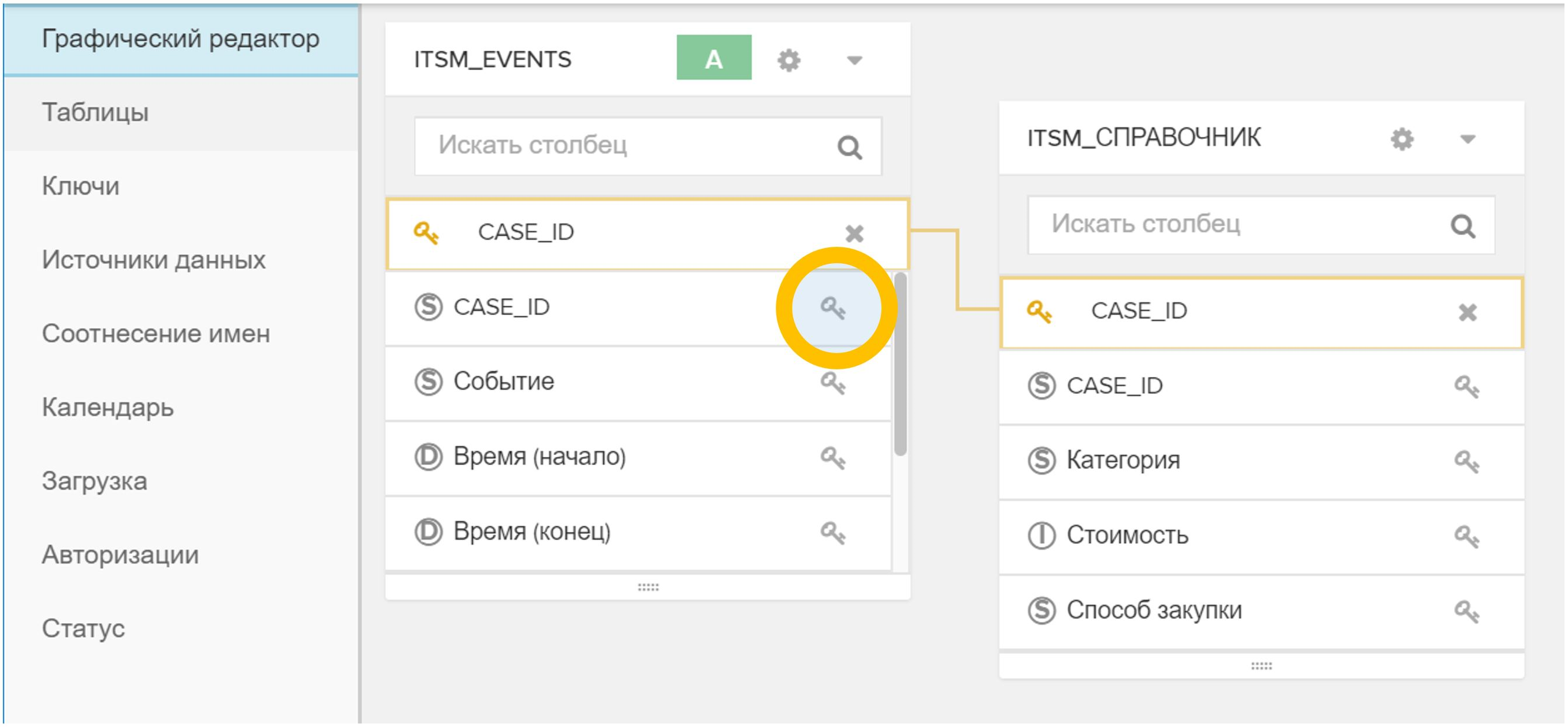
Abbildung 5. Verknüpfen von Tabellen in einem Datenmodell durch ein beliebiges Feld (in diesem Fall CASE_ID) - Klicken Sie im Menü "Status" auf die Schaltfläche "Von Quelle neu laden". Dieser Vorgang dauert normalerweise einige Sekunden.
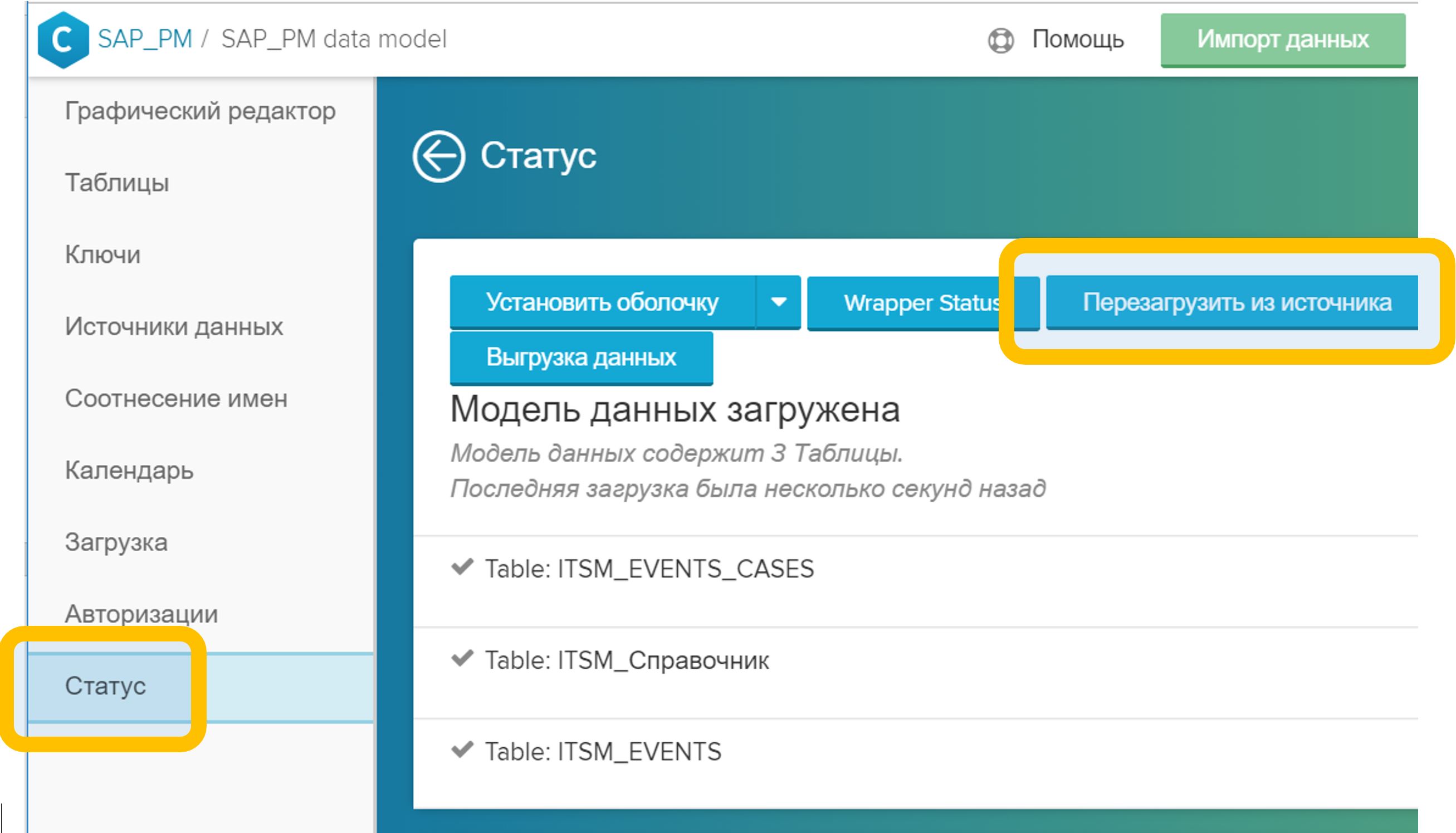 Abbildung 6. Neuladen des Datenmodells aus der Quelle
Abbildung 6. Neuladen des Datenmodells aus der Quelle
Nach Abschluss dieser Schritte können Sie sofort neue Analysen verwenden, sowohl in neuen als auch in vorhandenen Berichten. Die Anreicherung des Datenmodells schadet der aktuellen Arbeit der Analysten in keiner Weise: Alle erstellten Berichte funktionieren weiterhin, Sie müssen sie nicht wiederholen oder irgendwie ändern.
Für relativ kleine Verzeichnisse gibt es noch eine Möglichkeit: Natürlich keine vollständig industrielle Version, aber sie kann auch nützlich sein. Es geht darum, CSV-, XLSX- und DBF-Dateien über eine grafische Oberfläche direkt in das Datenmodell zu laden. Das Verfahren bleibt genau das gleiche wie oben beschrieben, nur dass anstelle der Datenbanktabellen eine im Voraus vorbereitete Datei verwendet wird, die mit der Schaltfläche Daten importieren geladen wird.
CA-Tabelle: ProzessinstanzreferenzDas vorherige Gespräch über Nachschlagewerke begann mit der Tatsache, dass sie optional sind. Sie können ganz aus dem Datenmodell weggelassen und auf eine Ereignistabelle beschränkt werden. Das ist fast wahr.
Eine obligatorische Referenz existiert. Dies sollte eine Tabelle sein, die mit dem Status „CA-Tabelle“ gekennzeichnet ist. Zertifizierungsstellen sind Ereignisketten. Und Sie haben es erraten, der Schlüssel in diesem Verzeichnis ist "CASE_ID" - die eindeutige Kennung der Prozessinstanz. Eine solche Referenz beschreibt die statischen Eigenschaften einzelner Prozessinstanzen. Ein Beispiel von ITSM: der Autor der Beschwerde, ein Unternehmensdienstleister, der Stichtag oder der Mitarbeiter, der den Vorfall erfolgreich gelöst hat, ein Zeichen von Massencharakter usw.
 Abbildung 7. Beispiel einer CA-Tabelle
Abbildung 7. Beispiel einer CA-TabelleUnd doch habe ich dich nicht viel getäuscht. Wenn Sie aus irgendeinem Grund das erforderliche Verzeichnis nicht zum Datenmodell hinzufügen, generiert das System es selbst. Das Ergebnis seiner Arbeit kann auf der Registerkarte Status angezeigt werden: Wenn Ihre Ereignistabelle beispielsweise "ITSM_EVENTS" heißt, wird in Verbindung damit die Tabelle "ITSM_EVENTS_CASES" generiert, wie in Abbildung 8 dargestellt.
Abbildung 8. Automatisch generierte Ereigniskettentabelle (CA)Eine automatisch generierte CA-Tabelle ist eine sehr einfache Beschreibung der Prozessinstanzen: Schlüssel, Anzahl der Ereignisse, Prozessdauer (als hätten Sie eine Ereignistabelle nach einer Prozesskennung gruppiert, die Anzahl der Zeilen und die Differenz zwischen dem Zeitpunkt des ersten und des letzten Schritts berechnet). Daher ist es sinnvoll, eine eigene, interessantere Version der CA-Tabelle zu erstellen. Es kann jederzeit zum Datenmodell hinzugefügt werden. Gleichzeitig wird das vom System generierte Verzeichnis (in unserem Fall "ITSM_EVENTS_CASES") automatisch aus dem Datenmodell gelöscht, sobald Sie Ihre CA-Tabelle zum Modell hinzufügen.
Warum ist die „CA-Tabelle“ interessant? Sie wird in der grafischen Oberfläche als Prozessdetail angezeigt. Wenn der Analyst während der Arbeit mit dem Datenmodell etwas Interessantes in dem Prozess gefunden hat und auf einzelne spezifische Beispiele eingehen möchte, verwendet er den Bericht „CA anzeigen“, dh Details. Nachdem Sie einen solchen Bericht geöffnet haben, finden Sie darin ein Verzeichnis des Prozesses (natürlich kombiniert mit einer Ereignistabelle). Fügen Sie daher der „CA-Tabelle“ alles hinzu, was der Analyst verwenden kann, um die Eigenschaften des Prozesses und die Bedingungen seines Verlaufs zu verstehen.
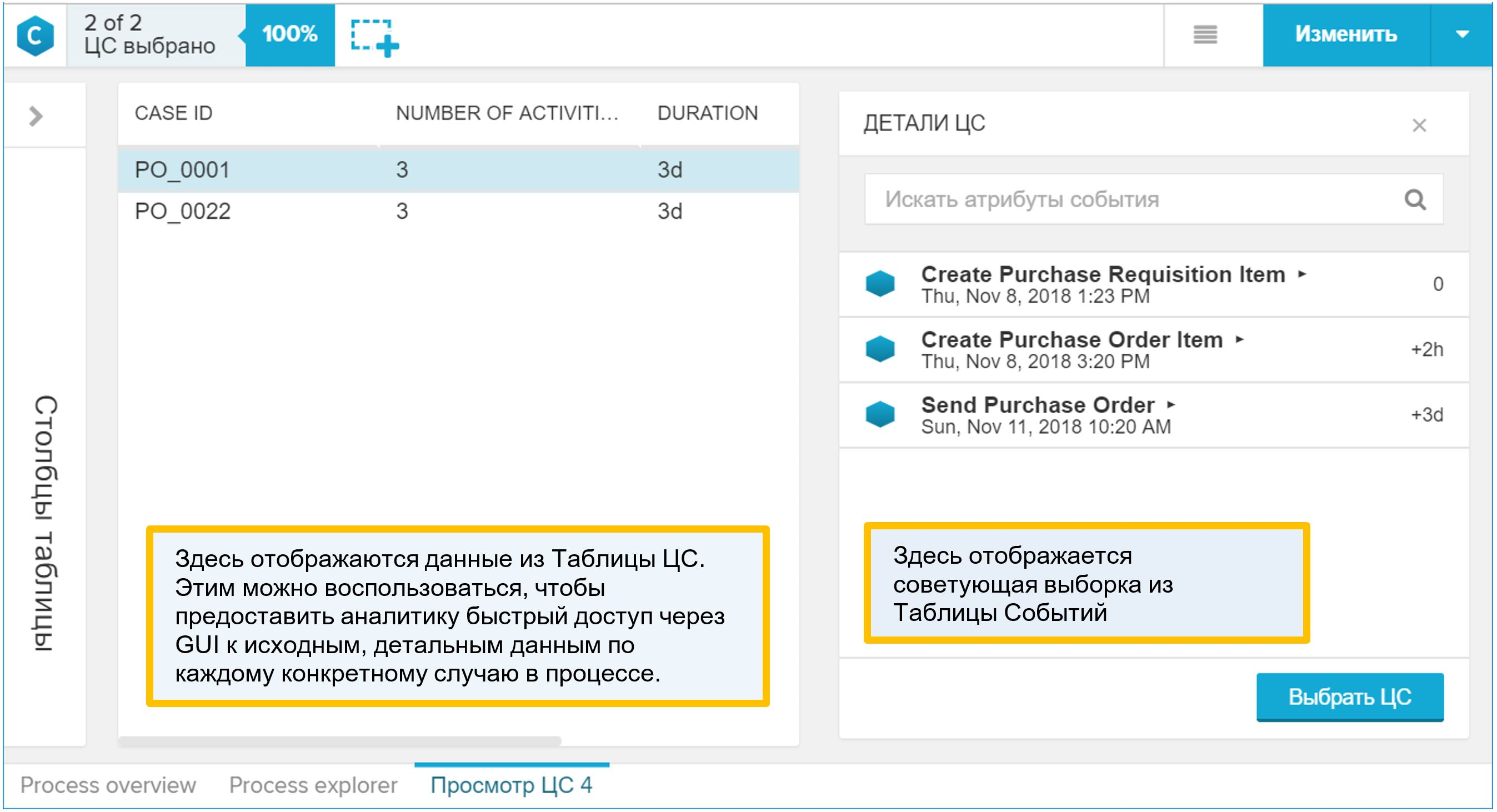 Abbildung 9. Synthetischer Beispielbericht „CA anzeigen“
Abbildung 9. Synthetischer Beispielbericht „CA anzeigen“So fügen Sie Ihre Prozessreferenz zum Datenmodell hinzu:
- In SAP HANA wird eine Tabelle erstellt.
- Die Tabelle wird dem allgemeinen Datenmodell über die Schaltfläche "Daten importieren" hinzugefügt.
- In der grafischen Oberfläche müssen Sie in den Eigenschaften der Tabelle die Rolle "Tabelle mit Zertifizierungsstelle" festlegen.
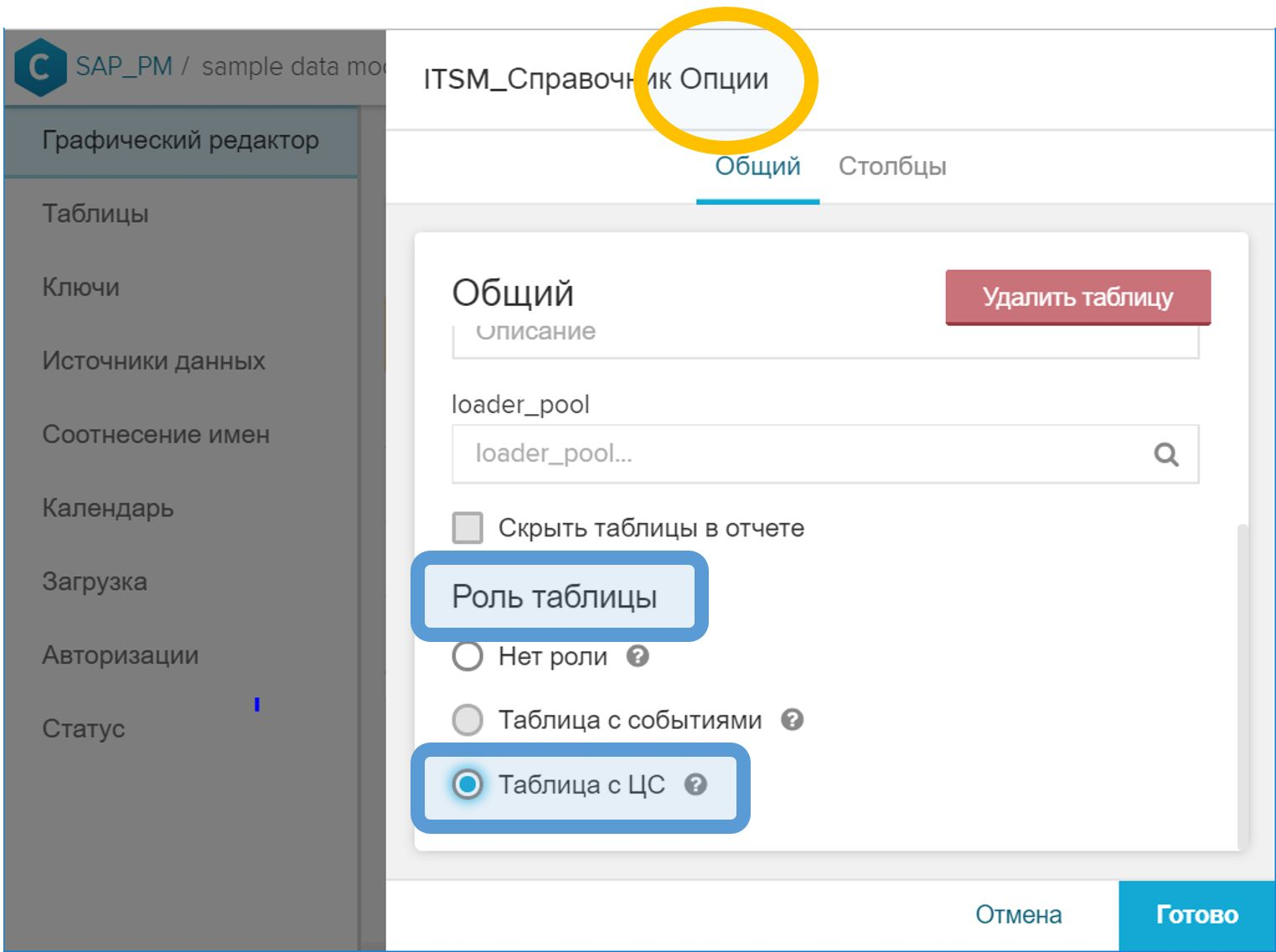
Abbildung 10. Die Rolle von "Tabelle mit Zertifizierungsstelle" zur Angabe des Verzeichnisses der Prozessinstanzen - Verknüpfen Sie in der GUI die CA-Tabelle anhand der Prozess-ID mit der Ereignistabelle. Dieser Schritt erfolgt auf die gleiche Weise wie bei einem regulären Verzeichnis - mit dem Schlüsselsymbol Schlüssel ( ) gegenüber dem entsprechenden Feld.
- Klicken Sie im Menü "Status" auf die Schaltfläche "Von Quelle neu laden".
Wichtiger Hinweis: Die Spalte "CASE_ID" (in jedem Fall kann sie auch anders aufgerufen werden) in der CA-Tabelle, die die Prozesskennung enthält und zur Zuordnung zur Ereignistabelle verwendet wird, sollte nur eindeutige Werte enthalten. Das ist ziemlich logisch. Wenn dies aus irgendeinem Grund nicht der Fall ist, wird beim Laden des Datenmodells in Schritt (5) der entsprechende Fehler generiert (über die Unmöglichkeit, die Operation "JOIN" für die Ereignistabelle und die CA-Tabelle auszuführen).
Erstellen eines Datenmodells aus dem Änderungsverlauf
In der Praxis stoßen wir auf sehr unterschiedliche Datenquellen für Process Mining. Ihre Zusammensetzung wird durch den ausgewählten Geschäftsprozess und die vom Kunden festgelegten Standards bestimmt.
Einer der häufigsten Fälle sind Daten aus dem IT-Service-Management-System (ITSM, IT-Service-Management). Daher haben wir uns entschlossen, dieses Beispiel zuerst zu analysieren. Tatsächlich gibt es bei diesem Ansatz keine enge Bindung speziell an ITSM. Es kann in anderen Geschäftsprozessen angewendet werden, in denen die Datenquelle ein Änderungsverlauf oder ein Überwachungsprotokoll ist.
Was kann man von der IT verlangen?Wenn Sie kein IT-Mitarbeiter oder Spezialist sind, der die ITSM-Basis bedient, sollten Sie darauf vorbereitet sein, dass Sie aufgefordert werden, eine genaue Antwort auf die Frage „Was entladen Sie?“ Zu formulieren. oder "was willst du von uns?"
Und das ist nicht immer bekannt - was genau benötigt wird. Die Analyse des Geschäftsprozesses ist eine Studie, eine Suche nach Mustern und die Suche nach "Einsichten". Wenn wir im Voraus wüssten, nach welcher Art von „Einsicht“ wir suchen, wäre dies keine „Einsicht“ mehr. Tatsächlich möchte ich "alles" bekommen: Attribute, Beziehungen, Änderungen. Wie die Praxis zeigt, war es jedoch nie möglich, eine zu genaue Antwort auf eine zu allgemeine Frage zu erhalten.
Es gibt zwei mögliche Antworten auf die Frage „Was entladen Sie?“.
Die Option ist falsch: Bitten Sie die Basis, alle Änderungen im Anwendungsstatus sowie eine Reihe offensichtlicher Attribute (z. B. Priorität, Künstler, Arbeitsgruppe usw.) zu entladen. Erstens erhalten Sie eine begrenzte Anzahl von Analysten: Sie wissen bereits, was Sie im Prozess messen werden (hier stammt der Satz von Attributen), sodass Process Mining zu einem Tool zur Berechnung des Prozess-KPI wird (sehr praktisch, muss ich sagen, ein Tool, aber ich möchte es trotzdem mehr).
Zweitens interpretiert jede einzelne IT-Abteilung die Anforderung unterschiedlich, um dem Upload zusätzliche Anforderungsattribute hinzuzufügen. Nehmen Sie zum Beispiel Priorität: Sie kann sich während der Arbeit an einem Anruf ändern. Die Beschwerde wird mit einer Priorität registriert, dann vom Spezialisten der Arbeitsgruppe geändert und mit einem anderen Status abgeschlossen. Und jetzt lautet die Frage: Welcher Moment entspricht beim von Ihnen angeforderten Entladen der Priorität? Zunächst scheint es, dass der Prioritätswert der Spalte „Datum und Uhrzeit des Ereignisses“ entsprechen sollte. In der Realität stellt sich jedoch häufig heraus, dass nur der Anforderungsstatus dem angegebenen Datum und der angegebenen Uhrzeit entspricht und alle anderen Spalten die Werte zum Zeitpunkt des Entladens oder zum Zeitpunkt des Schließens der Anforderung sind. Und davon werden Sie nicht sofort erfahren.
Es scheint mir, dass es eine bessere Option gibt. Sie können Daten in Form der folgenden Tabelle anfordern:
- Die Nummer der Beschwerde, des Vorfalls, der Aufgabe (SD *, IM *, RT *, ...) ist die Kennung des Objekts im ITSM-System (NVARCHAR).
- Zeitstempel (TIMESTAMP)
- Attributname (NVARCHAR)
- Alter Wert (NVARCHAR)
- Neuer Wert (NVARCHAR)
- Wer hat sich verändert (NVARCHAR)
Tatsächlich ist dies nichts weiter als eine Historie von Änderungen an Attributen. In den Schnittstellen von ITSM-Systemen sehen Sie eine solche Tabelle auf den Registerkarten mit dem Namen "Verlauf" oder "Journal".
Die Vorteile dieses Ansatzes liegen auf der Hand:
- Einfaches und klares Upload-Format. Er ist IT-Fachleuten mit der grafischen Oberfläche des Systems selbst vertraut. Sollte keine Fragen von der Basis verursachen.
- Wir erhalten eine Liste aller möglichen Attribute mit allen möglichen Werten. Ja, es wird viele von ihnen geben, höchstwahrscheinlich mehrere hundert. Das Heraussuchen des Unnötigen und Uninteressanten ist jedoch sehr einfach, aber jedes Mal, wenn zusätzliche Entladungen angefordert werden, ist es nicht immer einfach und immer lang (insbesondere, wenn Sie nicht wissen, welche Attribute überhaupt im System vorhanden sind).
- Dies ist ein zuverlässiges Datenmodell. Es ist schwierig, es zu verderben, es sei denn, Sie machen absichtlich falsche Informationen.
- Wir wissen genau, was jedes Attribut zu jedem Zeitpunkt hatte. Dies ist wichtig, da wir uns selbst testen und sicherstellen, dass das Modell korrekt ist. Während der Analyse können wir dem Modell Zwischenschritte hinzufügen („Vergrößern“) und zu allen weiteren Zeitpunkten die richtigen Attributwerte ermitteln.
Die Nachteile der zweiten Option liegen ebenfalls auf der Hand. Und sie können meines Erachtens gelöst werden (im Gegensatz zum Problem unvollständiger Daten):
- Das SQL-Skript zum Vorbereiten der Daten wird etwas komplizierter - im Vergleich zu der Option, dass das IT-Basisteam die Daten teilweise für Sie aufbereitet (siehe die erste Version der obigen Abfrage), ohne es zu ahnen. Ja, er (das Drehbuch) ist komplizierter, aber er ist allein. Ich denke, es wäre eine schlechte Idee, die Datenvorbereitung zwischen dem ITSM-Team und dem Process Mining-Team zu teilen. Process Mining, , , . .
- . : 10-30 / . HANA . , «» , ETL/ELT HANA (, HANA Smart Data Integration), .
Ich möchte nicht sagen, dass dies der einzig richtige Weg ist, um Daten aus dem ITSM-System für Process Mining-Aufgaben abzurufen. Gegenwärtig bin ich jedoch der Ansicht, dass dies das bequemste Format für diese Aufgabe ist. Es gibt wahrscheinlich viel mehr interessante Ansätze, und ich werde sehr gerne alternative Ideen diskutieren, wenn Sie sie mit mir teilen.Generierung von Ereignistabellen
Am Ausgang haben wir also einen Verlauf von Änderungen an den Attributen von Anforderungen, Vorfällen, Aufrufen, Aufgaben und anderen ITSM-Objekten. Aus einer solchen Tabelle können beide Schlüsselkomponenten des Process Mining-Datenmodells generiert werden: eine Ereignistabelle und eine CA-Tabelle.Gehen Sie wie folgt vor, um Ereignisse basierend auf dem Änderungsverlauf zu generieren:- Sammeln Sie im Änderungsverlauf alle eindeutigen Werte der Spalte "Attributname" (bedingt).
- Bestimmen Sie die Änderung, welche Attribute im Prozessdiagramm angezeigt werden sollen. Was ist für uns ein „Ereignis“?
- Erstellen Sie eine geeignete Berechnungsansicht oder schreiben Sie ein SQL-Skript, das die ausgewählten Zeilen aus dem Änderungsverlauf filtert und eine Ereignistabelle generiert.
Angenommen, die Änderungstabelle lautet wie folgt:CREATE COLUMN TABLE "SAP_PM"."ITSM_HISTORY" ( "CASE_ID" NVARCHAR(256), "ATTRIBUTE" NVARCHAR(256), "VALUE_OLD" NVARCHAR(1024), "VALUE_NEW" NVARCHAR(1024), "TS" TIMESTAMP, "USER" NVARCHAR(256) );
Schauen Sie sich zunächst die Liste aller vorhandenen Attribute an. Dies kann im Menü „Open Data Preview“ oder mit einer einfachen SQL-Abfrage wie der folgenden erfolgen:
SELECT DISTINCT "ATTRIBUTE" FROM "SAP_PM"."ITSM_HISTORY";
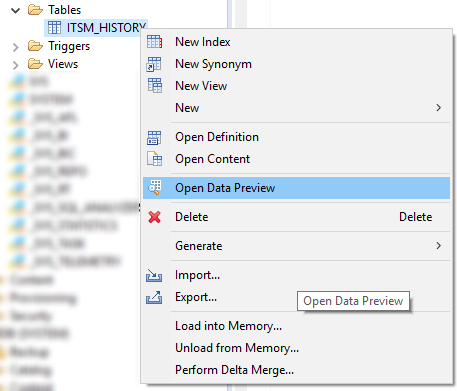 Abbildung 11. Kontextmenü mit dem Befehl Open Data Preview in SAP HANA Studio
Abbildung 11. Kontextmenü mit dem Befehl Open Data Preview in SAP HANA StudioDann bestimmen wir die Zusammensetzung der Attribute, deren Änderung für uns ein Ereignis im Prozess ist. Hier ist eine Liste offensichtlicher Kandidaten für eine solche Liste:
- Status
- Wurde zur Arbeit gebracht
- Kategorie wurde geändert
- Frist verletzt
- Reaktionszeit wird verletzt
- Die Anfrage wurde zur Überarbeitung zurückgesandt.
- Fehler in der ersten Zeile
- Arbeitsgruppe
- Priorität
Die Hauptereignisse hier sind natürlich die Übergänge zwischen den Status der Aufgabe Berufung / Vorfall \ Antrag \. Der Wert des Attributs „Status“ (VALUE_NEW) selbst ist für uns der Name des Prozessschritts. Dementsprechend könnte das Erstellen einer Ereignistabelle als erste Annäherung folgendermaßen aussehen:
CREATE COLUMN TABLE "SAP_PM"."ITSM_EVENTS" ( "CASE_ID" NVARCHAR(256) ,"EVENT" NVARCHAR(1024) ,"TS" TIMESTAMP ,"USER" NVARCHAR(256) ,"VALUE_OLD" NVARCHAR(1024) ,"VALUE_NEW" NVARCHAR(1024) ); INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"VALUE_NEW" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' ;
Das Ändern der restlichen Attribute sind unsere zusätzlichen Schritte, die die Erforschung des Prozesses noch interessanter machen. Ihre Zusammensetzung wird auf Anfrage eines Geschäftsanalysten festgelegt und kann sich mit der Entwicklung der Process Mining-Praxis im Unternehmen ändern.
INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"ATTRIBUTE" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "VALUE_OLD" IS NOT NULL AND "ATTRIBUTE" IN ( ' ' ,' ' ,' ' ,' ' ,' ' ,' 1- ' ,' ' ,'') );
Wenn Sie die Liste der Attribute im Filter WHERE "ATTRIBUTE" IN (.....) erweitern, erhöhen Sie die Anzahl der Schritte, die im Prozessdiagramm angezeigt werden. Es ist erwähnenswert, dass eine Vielzahl von Schritten nicht immer ein Segen ist. Manchmal erschweren zu detaillierte Details nur den Prozess. Ich denke, dass Sie nach der ersten Iteration bestimmen werden, welche Schritte erforderlich sind und welche aus dem Datenmodell ausgeschlossen werden sollten (und die Freiheit, solche Entscheidungen zu treffen und sich schnell an sie anzupassen, ist ein weiteres Argument für die Übertragung der Arbeit zur Transformation von Daten auf die Seite des Process Mining-Teams). .
Der Filter "VALUE_OLD" ist NICHT NULL. Höchstwahrscheinlich werden Sie ihn durch etwas ersetzen, das für Ihre Bedingungen und die ausgewählten Attribute besser geeignet ist. Ich werde versuchen, die Bedeutung dieses Filters zu erklären. In einigen gängigen Implementierungen von ITSM-Systemen werden zum Zeitpunkt der Registrierung (Eröffnung) eines Rechtsbehelfs Informationen über die Initialisierung aller Attribute des Objekts in das Journal eingegeben. Das heißt, alle Felder sind mit einigen Standardwerten markiert. In diesem Moment enthält VALUE_NEW denselben Initialisierungswert, und VALUE_OLD enthält nichts - schließlich gab es bis zu diesem Moment keinen Verlauf. Wir brauchen diese Aufzeichnungen dabei absolut nicht. Sie sollten mit einem Filter entfernt werden, der Ihren spezifischen Bedingungen entspricht. Ein solcher Filter kann sein:
- "VALUE_OLD" IST NICHT NULL
- "VALUE_NEW" = 'Ja'
- Sie können sich auf den Zeitstempel konzentrieren (nehmen Sie nur die Ereignisse auf, die nach der Registrierung des Objekts aufgetreten sind).
- Sie können sich auf das Feld "USER" konzentrieren, wenn das Systemkonto initialisiert wird.
- Alle anderen Bedingungen, die Sie sich ausgedacht haben.
CA-Tabellengenerierung
Dieselbe Änderungshistorie, die uns als Ereignisquelle diente, ist auch nützlich, um ein Verzeichnis von Prozessinstanzen (CA-Tabellen) zu erstellen. Algorithmus ähnlich:
1. Definieren Sie eine Liste von Attributen, die:
a. Ändern Sie während der Arbeit an der Bewerbung nicht, z. B. den Verfasser der Beschwerde und seine Abteilung, die Einschätzung des Benutzers zu den Ergebnissen der Arbeit, die Flagge der Fristverletzung.
b. Sie können sich ändern, aber wir sind nur an bestimmten Punkten an den Werten interessiert: zum Zeitpunkt der Registrierung, des Abschlusses, bei der Einstellung, des Wechsels von der 2. zur 1. Zeile usw.
c. Sie können sich ändern, aber wir sind nur an aggregierten Werten (Maximum, Minimum, Menge usw.) interessiert.
2. Erstellen Sie eine Diagonaltabelle mit den gewünschten Spalten. Jedes für uns interessante Attribut generiert einen eigenen Satz von Zeilen (entsprechend der Anzahl der Prozessinstanzen), in denen nur eine Spalte einen Wert hat und der Rest leer ist (NULL).
3. Wir reduzieren die Diagonaltabelle mithilfe der Gruppierung nach Prozesskennung in das endgültige Verzeichnis.
Beispiele für Attribute, deren Einfügen in die CA-Tabelle sinnvoll ist (in der Praxis kann diese Liste viel länger sein):
- Service
- IT-System
- Der Autor
- Autorenorganisation
- Benutzerbewertung der Lösungsqualität
- Anzahl der Rückkehr zur Arbeit
- Wann wurde zur Arbeit gebracht
- Erstellt von
- Wer hat geschlossen?
- Gelöst durch Zeile 1
- Ungültige Klassifizierung / Weiterleitung
- Frist
- Fristverletzung
Das gleiche Attribut kann entweder die Quelle eines Ereignisses in einem Prozess oder eine Eigenschaft einer Prozessinstanz sein. Zum Beispiel das Attribut "Priorität". Einerseits interessiert uns seine Bedeutung zum Zeitpunkt der Registrierung der Beschwerde, andererseits können alle Fakten zu Änderungen dieses Attributs als unabhängige Schritte an das Prozessdiagramm übermittelt werden.
Ein weiteres Beispiel ist Deadline. Dies ist eine offensichtliche Referenzeigenschaft des Prozesses, aber Sie können daraus einen virtuellen Schritt im Prozessdiagramm machen: Eine Operation wie die „Frist“ ist im Prozess nicht vorhanden. Wenn wir jedoch den entsprechenden Eintrag zur Ereignistabelle hinzufügen, erstellen wir ihn künstlich und können den Standort relativ zu visualisieren Ausführungszeit anderer Schritte direkt im Prozessdiagramm. Dies ist praktisch für eine schnelle Analyse.
Wenn wir Prozesseigenschaften basierend auf dem Verlauf von Attributänderungen erstellen, kann die Quelle nützlicher Informationen für uns im Allgemeinen sein:
- Attributwert selbst (Beispiel: "Benutzerbewertung")
- Benutzer, der es geändert hat
- Zeit ändern
- Die Zeit, zu der das Attribut einen bestimmten Wert angenommen hat (Beispiel: Das Attribut "Frist verletzt" ist nicht am Attributwert selbst interessiert, sondern an der Zeit, zu der es sich in das Äquivalent des angezeigten Flags ändert - zum Beispiel "Ja" oder "1").
- Die Tatsache, dass das Attribut in der Geschichte vorhanden ist (Beispiel: "Massenvorfall" mit dem Wert "Ja")
Diese Liste kann natürlich mit anderen Ideen zur Verwendung von Attributen und allem, was damit verbunden ist, fortgesetzt werden.
Nachdem wir uns bereits für die Liste der interessierenden Eigenschaften entschieden haben, schauen wir uns eines der möglichen Szenarien zum Generieren der CA-Tabelle an. Erstellen Sie zunächst die Tabelle selbst mit den Spalten, die wir oben für uns selbst definiert haben:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES" ( "CASE_ID" NVARCHAR(256) NOT NULL ,"CATEGORY" NVARCHAR(256) DEFAULT NULL ,"AUTHOR" NVARCHAR(256) DEFAULT NULL ,"RESOLVER" NVARCHAR(256) DEFAULT NULL ,"RAITING" INTEGER DEFAULT NULL ,"OPEN_TIME" TIMESTAMP DEFAULT NULL ,"START_TIME" TIMESTAMP DEFAULT NULL ,"DEADLINE" TIMESTAMP DEFAULT NULL );
Wir benötigen außerdem eine temporäre Tabelle "ITSM_CASES_STAGING", mit der wir eine flache Liste von Attributen für die erforderlichen Eigenschaftsspalten im Verzeichnis der Prozessinstanzen sortieren können:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES_STAGING" LIKE "SAP_PM"."ITSM_CASES" WITH NO DATA;
Dies ist eine diagonale Tabelle - in jeder Zeile haben nur zwei Felder einen Wert: "CASE_ID", d.h. Prozesskennung und ein einzelnes Feld mit einer Prozesseigenschaft. Die verbleibenden Felder in der Zeile sind leer (NULL). Im Endstadium können wir die Diagonalen durch einfache Aggregation leicht in Zeilen zusammenfassen und so die Tabelle der CAs erhalten, die wir benötigen.
Ein Beispiel für eine Behandlungskategorie:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "CATEGORY") SELECT "CASE_ID", LAST_VALUE("VALUE_NEW" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' GROUP BY "CASE_ID" ;
Angenommen, der Autor ist der erste Nicht-Systembenutzer in der Geschichte der Beschwerde, der Beschwerden registriert (in Ihrem speziellen Fall ist das Kriterium möglicherweise genauer):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "AUTHOR") SELECT "CASE_ID", FIRST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "USER" != 'SYSTEM' GROUP BY "CASE_ID" ;
Wenn wir glauben, dass der Handler, der den letzten Status "Lösungsvorschlag" festgelegt hat (und die Lösung wiederholt angeboten werden könnte, aber nur die letzte behoben ist), das Problem erfolgreich gelöst hat, kann diese Eigenschaft der Prozessinstanz wie folgt formuliert werden:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RESOLVER") SELECT "CASE_ID", LAST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' AND "VALUE_NEW" = ' ' GROUP BY "CASE_ID" ;
Nutzerbewertung (seine Zufriedenheit mit der Entscheidung):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RAITING") SELECT "CASE_ID", TO_INTEGER(LAST_VALUE("VALUE_NEW" ORDER BY "TS")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND "VALUE_NEW" IS NOT NULL GROUP BY "CASE_ID" ;
Der Zeitpunkt der Registrierung (Erstellung) ist einfach die früheste Aufzeichnung in der Geschichte der Verbreitung:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "OPEN_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" GROUP BY "CASE_ID" ;
Die Reaktionszeit ist ein wichtiges Merkmal für die Qualität der Dienstleistungen. Um dies zu berechnen, müssen Sie wissen, wann die Flagge „Wurde zur Arbeit gebracht“ zum ersten Mal gehisst wurde:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "START_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' = '' GROUP BY "CASE_ID" ;
Die Frist wird verwendet, um KPIs für die rechtzeitige Reaktion auf Beschwerden oder die Lösung von Vorfällen zu berechnen. Dabei kann sich die Frist wiederholt ändern. Um KPIs zu berechnen, müssen wir die neueste Version dieses Attributs kennen. Wenn wir explizit verfolgen möchten, wie sich die Frist geändert hat, dh um solche Fälle im Prozessdiagramm anzuzeigen, sollten wir dieses Attribut auch verwenden, um einen Eintrag in der Ereignistabelle zu generieren. Dies ist ein Beispiel für ein Attribut, das gleichzeitig als Eigenschaft des Prozesses und als Quelle des Ereignisses dient.
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "DEADLINE") SELECT "CASE_ID", MAX(TO_DATE("VALUE_NEW")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' IS NOT NULL GROUP BY "CASE_ID" ;
Alle obigen Beispiele sind vom gleichen Typ. In Analogie zu ihnen kann die CA-Tabelle mit beliebigen Attributen erweitert werden, die Sie interessieren. Darüber hinaus kann dies bereits nach Projektstart erfolgen. Mit dem System können Sie das Datenmodell während des Betriebs erweitern.
Wenn unsere temporäre Diagonaltabelle mit den Eigenschaften der Prozessinstanzen gefüllt ist, müssen Sie nur noch die Aggregation durchführen und die endgültige CA-Tabelle abrufen:
INSERT INTO "SAP_PM"."ITSM_CASES" SELECT "CASE_ID" ,MAX("CATEGORY") ,MAX("AUTHOR") ,MAX("RESOLVER") ,MAX("RAITING") ,MAX("OPEN_TIME") ,MAX("START_TIME") ,MAX("DEADLINE") FROM "SAP_PM"."ITSM_CASES_STAGING" GROUP BY "CASE_ID" ;
Danach brauchen wir die Daten in der temporären Tabelle nicht mehr. In der Tabelle selbst kann der obige Vorgang regelmäßig wiederholt werden, um das Datenmodell in Process Mining zu aktualisieren:
DELETE FROM "SAP_PM"."ITSM_CASES_STAGING";
Tipps zum Vorbereiten und Bereinigen von CSV-Dateien für ein Pilotprojekt
Sie werden Ihre Bekanntschaft mit der Disziplin Process Mining wahrscheinlich mit einem Pilotprojekt beginnen. In diesem Fall kann kein direkter Zugriff auf die Datenquelle gewährt werden. Sowohl IT-Mitarbeiter als auch Informationssicherheitsbeauftragte werden sich dem widersetzen. Dies bedeutet, dass wir im Rahmen des Pilotprojekts Daten aus Unternehmenssystemen in CSV-Dateien exportieren und dann in SAP HANA importieren müssen, um ein Datenmodell zu erstellen.
In einer Industrieanlage werden keine Exporte nach CSV durchgeführt. Stattdessen werden SAP-HANA-Integrationstools verwendet, insbesondere: Smart Data Integration (SDI), Smart Data Access (SDA) oder SAP Landscape Transformation Replication Server (SLT). Zum Testen und Kennenlernen der Technologie ist das Exportieren in CSV-Textdateien eine organisatorisch einfachere Methode. Daher ist es hilfreich, Ihnen einige Tipps zur Vorbereitung von Daten in CSV für den schnellen und erfolgreichen Import in die Datenbank mitzuteilen.
Empfohlene Formatanforderungen für die Datei selbst beim Exportieren:
- Dateiformat: CSV
- Codierung: UTF8
- Feldtrennzeichen: jedes für Sie passende Zeichen. Zum Beispiel "|" oder "^" oder "~". Die Logik der Auswahl ist einfach - wir müssen versuchen, die Situation zu vermeiden, in der die „Aufteilung“ in den Daten selbst enthalten ist.
- Das Trennzeichen muss aus dem Wert der Felder entfernt werden. Ja, man könnte sagen, dass es dafür tatsächlich Anführungszeichen gibt. Aber wie die Erfahrung zeigt, treten auch bei Anführungszeichen viele Probleme auf. Im Allgemeinen entfernen (oder ersetzen) wir einfach das Trennzeichen aus den Feldwerten. Ihr Pilotprojekt wird nicht sehr unter solchen Ungenauigkeiten leiden, aber die Zeit für die Datenaufbereitung wird spürbar gespart.
- Anführungszeichen: Entfernen Sie alle Anführungszeichen aus dem Feldwert. Anführungszeichen finden sich häufig in Firmennamen - beispielsweise Kalinka LLC. Aber es gibt solche Optionen: MPZ Kalinka LLC. Und jetzt ist das eine große Schwierigkeit. Die Anführungszeichen in den Feldwerten müssen entweder mit dem Symbol "\" versehen oder entfernt und durch etwas anderes ersetzt werden. Es ist am zuverlässigsten, es einfach zu entfernen. Der Feldwert wird darunter nicht viel leiden.
- Wagenübertragungen: Entfernen Sie alle Zeichen CHAR (10) und CHAR (13) aus den Feldwerten. Andernfalls ist ein Import aus CSV nicht möglich.
Wenn wir die Punkte (4) + (5) + (6) berücksichtigen, ist es sinnvoll, bei der Auswahl die folgende Konstruktion zu verwenden:
REPLACE(REPLACE(REPLACE(REPLACE("COLUMN", '|', ';'), '"', ''), CHAR(13), ' '), CHAR(10), ' ') as "COLUMN"
Wenn die CSV-Dateien fertig sind, müssen sie in einem Ordner, der für den Import von Dateien als sicher deklariert ist (z. B. / usr / sap / HDB / import), auf den HANA-Server kopiert werden. Das Importieren von Daten aus einer lokalen CSV-Datei in HANA ist ein relativ schneller Vorgang, vorausgesetzt, die Datei ist "sauber":
- Jede Zeile der zukünftigen Tabelle befindet sich in einer und nur einer Zeile der Datei.
- Die Anzahl der Spalten in allen Zeilen ist gleich.
- Anführungszeichen sind entweder gepaart oder fehlen überhaupt;
- Anführungszeichen in den Feldwerten begleiten entweder das "Escape" -Symbol "\" oder fehlen ganz
- UTF-8-Codierung (und nicht UTF8-Stückliste, wie dies beim Exportieren auf Windows-Systeme der Fall ist).
Um die CSV-Dateien vor dem Import zu überprüfen und Problembereiche zu finden, falls vorhanden (und mit einer Wahrscheinlichkeit von 99%), können Sie die folgenden Befehle verwenden:
1. Überprüfen Sie das Stücklistenzeichen am Anfang der Datei:
Datei data.csv
Wenn das Ergebnis des Befehls wie folgt lautet: "UTF-8-Unicode-Text (mit Stücklisten)", bedeutet dies, dass die Codierung UTF8-Stückliste ist und Sie das Stücklistenzeichen aus der Datei entfernen müssen. Sie können es wie folgt entfernen:
sed -i '1s / ^ \ xEF \ xBB \ xBF //' data.csv
2. Die Anzahl der Spalten sollte für jede Zeile der Datei gleich sein:
cat data.csv
| awk -F »;" '{print NF}' | sort | uniqoder so:
für i in $ (ls * .csv); Echo $ i; cat $ i | awk -F ';' '{print NF}' | sortieren | uniq -c; Echo; erledigt;Ändern Sie ';' in Parameter F auf das Feldtrennzeichen in Ihrem Fall.
Als Ergebnis dieser Befehle erhalten Sie die Verteilung der Zeilen nach der Anzahl der Spalten in jeder Zeile. Idealerweise sollten Sie so etwas bekommen:
EKKO.csv
79536 200
Hier enthält die Datei 79536 Zeilen, und alle enthalten 200 Spalten. Es gibt keine Zeilen mit einer anderen Anzahl von Spalten. Es sollte so sein.
Und hier ist ein Beispiel für ein falsches Ergebnis:
LFA1.csv
73636 180
7 181
Hier sehen wir, dass die meisten Zeilen 180 Spalten enthalten (und wahrscheinlich ist dies die Anzahl der Spalten, die korrekt ist), aber es gibt Zeilen mit der 181. Spalte. Das heißt, eines der Felder enthält in seinem Wert ein Trennzeichen. Wir hatten Glück und es gibt nur 7 solcher Zeilen - sie können leicht manuell angezeigt und irgendwie korrigiert werden. Sie können die Zeilen sehen, in denen die Anzahl der Spalten ungleich 180 ist, wie folgt:
cat data.csv
| awk -F ";" '{if (NF! = 180) {print $ 0}}'Ein Hinweis zur Verwendung der obigen Befehle. Diese Befehle berücksichtigen keine Anführungszeichen. Wenn das Trennzeichen in dem in Anführungszeichen eingeschlossenen Feld enthalten ist (und dies bedeutet, dass hier aus Sicht des Imports in die Datenbank alles in Ordnung ist), zeigt die Überprüfung mit dieser Methode ein falsches Problem (zusätzliche Spalten) - dies sollte auch bei der Analyse der Ergebnisse berücksichtigt werden.
3. Wenn die Anführungszeichen ungepaart sind und dieses Problem nicht lösen können, können Sie alle Anführungszeichen aus der Datei löschen:
sed -i 's / "// g' data.csv
Die Gefahr dieses Ansatzes besteht darin, dass sich die Anzahl der Spalten in der Zeile ändert, wenn die Feldwerte ein Trennzeichen enthalten. Daher müssen die Trennzeichen in der Exportphase aus den Feldwerten entfernt werden (löschen oder durch ein anderes Zeichen ersetzen).
4. Leere Felder
Angesichts einer Situation, in der der erfolgreiche Import von Daten durch leere Feldwerte in dieser Form verhindert wurde:
; ""
Wo ";" Ist in diesem Fall das Vorzeichen des Feldtrennzeichens. Das heißt, das Feld besteht aus zwei doppelten Anführungszeichen (einfache leere Zeichenfolge). Wenn Sie die Daten plötzlich nicht mehr importieren können und vermuten, dass das Problem leere Felder sind, ersetzen Sie "" durch NULL
sed -i 's /; ”” /; NULL / g' data.csv
(Ersetzen Sie Ihre Trennoption durch ";")
5. Es kann nützlich sein, in den Daten nach „schmutzigen“ Zahlenformaten zu suchen:
; "0" (die Zahl enthält ein Leerzeichen)
; "100.10-" (das Zeichen "-" nach der Nummer)
Der Bugatti 3/4 "300-Kran - eine Zollabmessung wird durch ein doppeltes Anführungszeichen angezeigt - führt beim Exportieren automatisch zu ungepaarten Anführungszeichen.
Leider ist dies keine vollständige Liste möglicher Probleme mit ungünstigen Datenformaten für den Import in die Datenbank. Es wäre toll, Ihre Möglichkeiten aus der Praxis zu kennen: Auf welche merkwürdigen Fehler sind Sie gestoßen? Wie Sie sie erkannt und beseitigt haben. Teilen Sie in den Kommentaren.
Fazit
Im Allgemeinen ist das Datenmodell für Process Mining sehr einfach: eine Ereignistabelle sowie optional zusätzliche Nachschlagewerke. Aber wie es normalerweise passiert, scheint es erst dann einfach zu sein, wenn mindestens ein vollständiger Zyklus von Aufgaben abgeschlossen wurde - dann ist der gesamte Prozess in seiner Gesamtheit sichtbar und der Arbeitsplan ist klar. Ich hoffe, dieser Artikel hilft Ihnen, die Datenvorbereitung für Ihr erstes Process Mining-Projekt zu verstehen. Im Allgemeinen sieht der Vorbereitungsprozess folgendermaßen aus:
- Anfordern eines Änderungsverlaufs vom Dateneigentümer
- Überprüfen und Bereinigen des Uploads (Vorbereitung von CSV-Dateien)
- In SAP HANA importieren
- Ereignistabellenaufbau
- Erstellen einer CA-Tabelle (Prozessreferenz)
Tatsächlich beginnt hier die Erstellung des Datenmodells und der interessanteste Teil - Process Mining. Wenn Sie während der Implementierung des Process Mining-Projekts Fragen haben, schreiben Sie diese bitte in die Kommentare. Ich helfe Ihnen gerne weiter. Viel Glück!
Fedor Pavlov, Experte für SAP CIS-Plattformen