Hallo an alle. Wir teilen die Übersetzung des letzten Teils des Artikels, der speziell für Studenten des
Data Engineer- Kurses vorbereitet wurde. Der erste Teil ist hier zu finden.
Apache Beam und DataFlow für Echtzeit-Pipelines
Google Cloud-Setup
Hinweis: Ich habe Google Cloud Shell verwendet, um die Pipeline zu starten und die Benutzerprotokolldaten zu veröffentlichen, da ich Probleme beim Ausführen der Pipeline in Python 3 hatte. Google Cloud Shell verwendet Python 2, das besser mit Apache Beam kompatibel ist.
Um den Förderer zu starten, müssen wir uns ein wenig mit den Einstellungen befassen. Für diejenigen unter Ihnen, die GCP noch nicht verwendet haben, müssen Sie die folgenden 6 Schritte auf dieser
Seite ausführen .
Danach müssen wir unsere Skripte in Google Cloud Storage hochladen und in unser Google Cloud Shel kopieren. Das Hochladen in den Cloud-Speicher ist recht trivial (eine Beschreibung finden Sie
hier ). Um unsere Dateien zu kopieren, können Sie Google Cloud Shel über die Symbolleiste öffnen, indem Sie auf das erste Symbol links in Abbildung 2 unten klicken.
 Abbildung 2
Abbildung 2Die Befehle, die wir zum Kopieren von Dateien und Installieren der erforderlichen Bibliotheken benötigen, sind unten aufgeführt.
Erstellen unserer Datenbank und Tabelle
Nachdem wir alle Konfigurationsschritte abgeschlossen haben, müssen wir als Nächstes ein Dataset und eine Tabelle in BigQuery erstellen. Es gibt verschiedene Möglichkeiten, dies zu tun. Am einfachsten ist es jedoch, die Google Cloud-Konsole zu verwenden, indem Sie zuerst ein Dataset erstellen. Sie können die Schritte unter dem folgenden
Link ausführen , um eine Tabelle mit einem Schema zu erstellen. Unsere Tabelle enthält
7 Spalten , die den Komponenten jedes Benutzerprotokolls entsprechen. Der Einfachheit halber definieren wir alle Spalten mit Ausnahme der zeitlichen Variablen als Zeichenfolgen (Typ Zeichenfolge) und benennen sie gemäß den zuvor generierten Variablen. Das Layout unserer Tabelle sollte wie in Abbildung 3 aussehen.
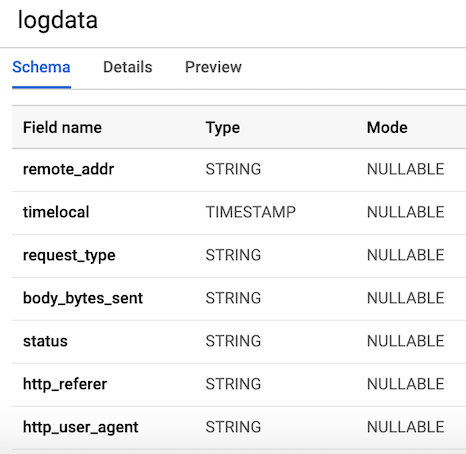 Abbildung 3. Tabellenlayout
Abbildung 3. TabellenlayoutVeröffentlichen Sie Benutzerprotokolldaten
Pub / Sub ist eine wichtige Komponente unserer Pipeline, da mehrere unabhängige Anwendungen miteinander interagieren können. Insbesondere fungiert es als Vermittler, der es uns ermöglicht, Nachrichten zwischen Anwendungen zu senden und zu empfangen. Als erstes müssen wir ein Thema erstellen. Gehen Sie einfach in der Konsole zu Pub / Sub und drücken Sie CREATE TOPIC.
Der folgende Code ruft unser Skript auf, um die oben definierten Protokolldaten zu generieren. Anschließend werden die Protokolle verbunden und an Pub / Sub gesendet. Wir müssen lediglich ein
PublisherClient- Objekt erstellen, den Pfad zum Thema mithilfe der
topic_path Methode
topic_path und die
publish Funktion mit
topic_path und data
topic_path . Bitte beachten Sie, dass wir
generate_log_line aus unserem
stream_logs Skript importieren.
stream_logs daher sicher, dass sich diese Dateien im selben Ordner befinden. Andernfalls wird ein
stream_logs . Dann können wir dies über unsere Google-Konsole ausführen, indem wir:
python publish.py
from stream_logs import generate_log_line import logging from google.cloud import pubsub_v1 import random import time PROJECT_ID="user-logs-237110" TOPIC = "userlogs" publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path(PROJECT_ID, TOPIC) def publish(publisher, topic, message): data = message.encode('utf-8') return publisher.publish(topic_path, data = data) def callback(message_future):
Sobald die Datei gestartet wird, können wir die Ausgabe der Protokolldaten an die Konsole beobachten, wie in der folgenden Abbildung gezeigt. Dieses Skript funktioniert so lange, bis wir
STRG + C verwenden , um es zu vervollständigen.
 Abbildung 4. Ausgabe von
Abbildung 4. Ausgabe von publish_logs.py
Code für unsere Pipeline schreiben
Nachdem wir alles vorbereitet haben, können wir mit dem interessantesten Teil fortfahren - dem Schreiben des Codes unserer Pipeline mit Beam und Python. Um eine Beam-Pipeline zu erstellen, müssen Sie ein Pipeline-Objekt erstellen (p). Nachdem wir das Pipeline-Objekt erstellt haben, können wir mit dem Operator
pipe (|) mehrere Funktionen nacheinander anwenden. Im Allgemeinen sieht der Workflow wie im Bild unten aus.
[Final Output PCollection] = ([Initial Input PCollection] | [First Transform] | [Second Transform] | [Third Transform])
In unserem Code erstellen wir zwei benutzerdefinierte Funktionen. Die Funktion
regex_clean , die Daten scannt und die entsprechende Zeile basierend auf der PATTERNS-Liste mithilfe der Funktion
re.search . Die Funktion gibt eine durch Kommas getrennte Zeichenfolge zurück. Wenn Sie kein Experte für reguläre Ausdrücke sind, empfehle ich Ihnen, dieses
Tutorial zu lesen und im Editor zu üben, um den Code zu überprüfen. Danach definieren wir eine benutzerdefinierte ParDo-Funktion namens
Split , eine Variation der Beam-Transformation für die parallele Verarbeitung. In Python geschieht dies auf besondere Weise - wir müssen eine Klasse erstellen, die von der DoFn Beam-Klasse erbt. Die Split-Funktion übernimmt eine analysierte Zeichenfolge aus der vorherigen Funktion und gibt eine Liste von Wörterbüchern mit Schlüsseln zurück, die den Spaltennamen in unserer BigQuery-Tabelle entsprechen. Diese Funktion hat etwas Bemerkenswertes: Ich musste die
datetime in die Funktion importieren, damit sie funktioniert. Ich habe am Anfang der Datei einen Importfehler erhalten, der seltsam war. Diese Liste wird dann an die
WriteToBigQuery- Funktion übergeben, die einfach unsere Daten zur Tabelle hinzufügt. Der Code für den Batch DataFlow-Job und den Streaming DataFlow-Job wird unten angezeigt. Der einzige Unterschied zwischen Batch- und Stream-Code besteht darin, dass wir bei der Batch-Verarbeitung CSV aus
src_path mithilfe der
ReadFromText Funktion von Beam lesen.
Batch DataFlow Job (Paketverarbeitung)
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import bigquery import re import logging import sys PROJECT='user-logs-237110' schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' src_path = "user_log_fileC.txt" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'status': element[3], 'body_bytes_sent': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(): p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.textio.ReadFromText(src_path) | "clean address" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) p.run() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Streaming von DataFlow-Job
from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import pubsub_v1 from google.cloud import bigquery import apache_beam as beam import logging import argparse import sys import re PROJECT="user-logs-237110" schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' TOPIC = "projects/user-logs-237110/topics/userlogs" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'body_bytes_sent': element[3], 'status': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(argv=None): parser = argparse.ArgumentParser() parser.add_argument("--input_topic") parser.add_argument("--output") known_args = parser.parse_known_args(argv) p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.ReadFromPubSub(topic=TOPIC).with_output_types(bytes) | "Decode" >> beam.Map(lambda x: x.decode('utf-8')) | "Clean Data" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) result = p.run() result.wait_until_finish() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Förderstart
Wir können die Pipeline auf verschiedene Arten starten. Wenn wir wollten, konnten wir es einfach lokal vom Terminal aus ausführen und uns remote bei GCP anmelden.
python -m main_pipeline_stream.py \ --input_topic "projects/user-logs-237110/topics/userlogs" \ --streaming
Wir werden es jedoch mit DataFlow starten. Wir können dies mit dem folgenden Befehl tun, indem wir die folgenden erforderlichen Parameter einstellen.
project - Die ID Ihres GCP-Projekts.runner ist ein Pipeline- runner , der Ihr Programm analysiert und Ihre Pipeline erstellt. Um in der Cloud ausgeführt zu werden, müssen Sie einen DataflowRunner angeben.staging_location - Der Pfad zum Cloud Dataflow-Cloud-Speicher zum Indizieren der von den Prozesshandlern benötigten Codepakete.temp_location - Der Pfad zum Cloud-Datenfluss zum Speichern temporärer temp_location die während des Betriebs der Pipeline erstellt wurden.streaming
python main_pipeline_stream.py \ --runner DataFlow \ --project $PROJECT \ --temp_location $BUCKET/tmp \ --staging_location $BUCKET/staging --streaming
Während dieser Befehl ausgeführt wird, können wir in der Google-Konsole zur Registerkarte DataFlow wechseln und unsere Pipeline anzeigen. Wenn Sie auf die Pipeline klicken, wird etwas Ähnliches wie in Abbildung 4 angezeigt. Für Debugging-Zwecke kann es sehr nützlich sein, zu den Protokollen und dann zu Stackdriver zu gehen, um detaillierte Protokolle anzuzeigen. Dies hat mir in einigen Fällen geholfen, Probleme mit der Pipeline zu lösen.
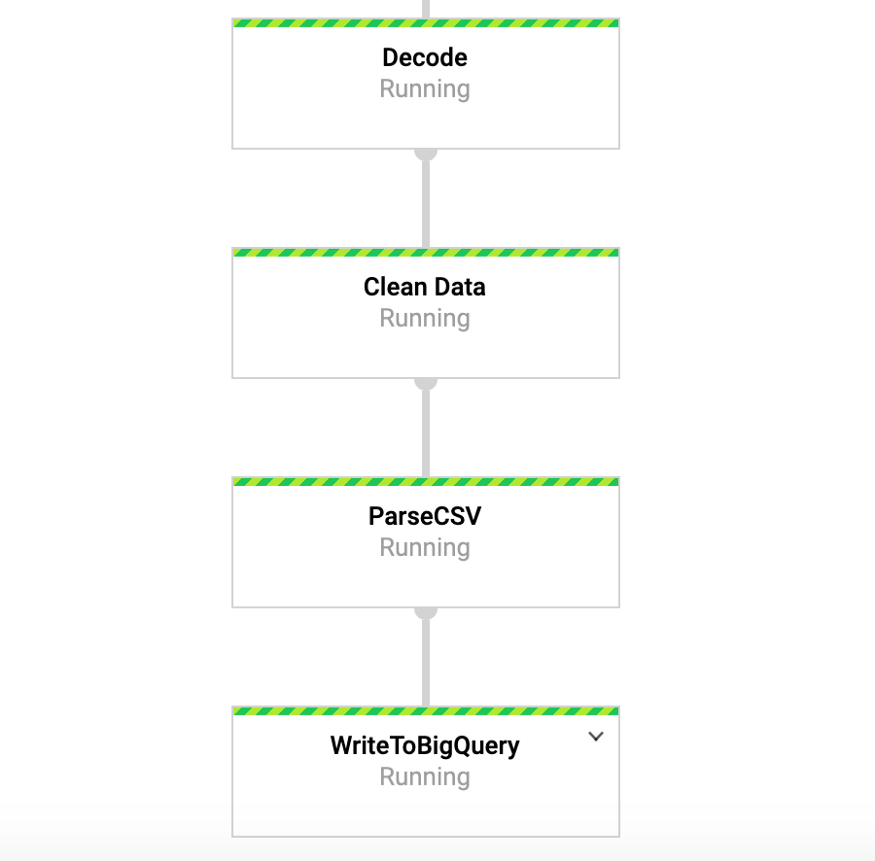 Abbildung 4: Strahlförderer
Abbildung 4: StrahlfördererGreifen Sie in BigQuery auf unsere Daten zu
Wir hätten die Pipeline also bereits mit den Daten starten sollen, die in unsere Tabelle eingehen. Um dies zu testen, können wir zu BigQuery gehen und die Daten anzeigen. Nachdem Sie den folgenden Befehl verwendet haben, sollten Sie die ersten Zeilen des Datensatzes sehen. Nachdem wir die Daten in BigQuery gespeichert haben, können wir weitere Analysen durchführen, Daten mit Kollegen teilen und geschäftliche Fragen beantworten.
SELECT * FROM `user-logs-237110.userlogs.logdata` LIMIT 10;
 Abbildung 5: BigQuery
Abbildung 5: BigQueryFazit
Wir hoffen, dass dieser Beitrag als nützliches Beispiel für die Erstellung einer Streaming-Datenpipeline sowie für die Suche nach Möglichkeiten zum besseren Zugriff auf Daten dient. Das Speichern von Daten in diesem Format bietet uns viele Vorteile. Jetzt können wir wichtige Fragen beantworten, zum Beispiel, wie viele Menschen unser Produkt verwenden. Wächst die Benutzerbasis im Laufe der Zeit? Mit welchen Aspekten des Produkts interagieren die Menschen am meisten? Und gibt es Fehler, wo sie nicht sein sollten? Dies sind Themen, die für die Organisation von Interesse sind. Basierend auf den Ideen, die sich aus den Antworten auf diese Fragen ergeben, können wir das Produkt verbessern und das Interesse der Benutzer erhöhen.
Beam ist für diese Art von Übung sehr nützlich und hat auch eine Reihe anderer interessanter Anwendungsfälle. Sie können beispielsweise die Daten von Exchange-Ticks in Echtzeit analysieren und basierend auf der Analyse Transaktionen durchführen. Möglicherweise verfügen Sie über Sensordaten von Fahrzeugen und möchten die Berechnung des Verkehrsaufkommens berechnen. Sie können beispielsweise auch ein Spieleunternehmen sein, das Benutzerdaten sammelt und daraus Dashboards zur Verfolgung wichtiger Kennzahlen erstellt. Okay, meine Herren, dieses Thema ist bereits für einen anderen Beitrag gedacht, danke fürs Lesen und für diejenigen, die den vollständigen Code sehen möchten, ist unten ein Link zu meinem GitHub.
https://github.com/DFoly/User_log_pipeline
Das ist alles.
Lesen Sie den ersten Teil .