Die Essenz der Geschichte über den beliebtesten Paketmanager für Kubernetes könnte mit Hilfe von Emoji dargestellt werden:
- Die Box ist Helm (dies ist die am besten geeignete Box in der neuesten Version von Emoji).
- Schloss - Sicherheit;
- Der Mensch ist die Lösung des Problems.

Tatsächlich wird alles etwas komplizierter und die Geschichte enthält viele technische Details,
wie Helm sicher gemacht werden kann .
- Kurz gesagt, was ist Helm, wenn Sie es nicht wussten oder vergessen. Welche Probleme löst es und wo befindet es sich im Ökosystem?
- Betrachten Sie die Architektur von Helm. Kein einziges Gespräch über Sicherheit und wie ein Tool oder eine Lösung sicherer gemacht werden kann, kann ohne Verständnis der Architektur der Komponente auskommen.
- Lassen Sie uns die Helmkomponenten diskutieren.
- Das brennendste Problem ist die Zukunft - die neue Version von Helm 3.
Alles in diesem Artikel bezieht sich auf Helm 2. Diese Version ist jetzt in Produktion und höchstwahrscheinlich sind Sie es, die sie jetzt verwenden, und dort gibt es Sicherheitsrisiken.
Über den Sprecher: Alexander Khayorov (
allexx ) entwickelt sich seit 10 Jahren, hilft bei der Verbesserung des Inhalts von
Moscow Python Conf ++ und ist dem
Helm Summit Committee beigetreten. Derzeit bei Chainstack in der Entwicklungsleiterposition tätig - dies ist eine Mischung aus dem Entwicklungsmanager und der Person, die für die Lieferung der endgültigen Releases verantwortlich ist. Das heißt, es befindet sich an der Stelle der Feindseligkeiten, an der alles von der Erstellung des Produkts bis zu seinem Betrieb geschieht.
Chainstack ist ein kleines, aktiv wachsendes Startup, dessen Aufgabe es ist, Kunden die Möglichkeit zu geben, die Infrastruktur und die Schwierigkeiten beim Betrieb dezentraler Anwendungen zu vergessen. Das Entwicklungsteam befindet sich in Singapur. Bitten Sie Chainstack nicht, Kryptowährung zu verkaufen oder zu kaufen, sondern bieten Sie an, über Blockchain-Frameworks für Unternehmen zu sprechen, und diese werden Ihnen gerne antworten.
Helm
Dies ist der Paketmanager (Diagramme) für Kubernetes. Die intuitivste und vielseitigste Möglichkeit, Anwendungen in den Kubernetes-Cluster zu bringen.

Hier geht es natürlich um einen strukturelleren und industrielleren Ansatz als das Erstellen eigener YAML-Manifeste und das Schreiben kleiner Dienstprogramme.
Helm ist derzeit der beste verfügbare und beliebteste.
Warum das Ruder? In erster Linie, weil es von CNCF unterstützt wird. Cloud Native - eine große Organisation, ist die Muttergesellschaft für die Projekte Kubernetes, etcd, Fluentd und andere.
Eine weitere wichtige Tatsache ist, dass Helm ein sehr beliebtes Projekt ist. Als ich im Januar 2019 gerade darüber sprechen wollte, wie Helm sicher gemacht werden kann, hatte das Projekt auf GitHub tausend Sterne. Bis Mai waren es 12 Tausend.
Viele Menschen interessieren sich für Helm, daher benötigen Sie Kenntnisse über seine Sicherheit, auch wenn Sie ihn immer noch nicht verwenden.
Sicherheit ist wichtig.Das Kernteam von Helm wird von Microsoft Azure unterstützt. Daher ist dies im Gegensatz zu vielen anderen ein ziemlich stabiles Projekt. Die Veröffentlichung von Helm 3 Alpha 2 Mitte Juli zeigt, dass eine ganze Reihe von Menschen an dem Projekt arbeiten und den Wunsch und die Kraft haben, Helm zu entwickeln und zu verbessern.
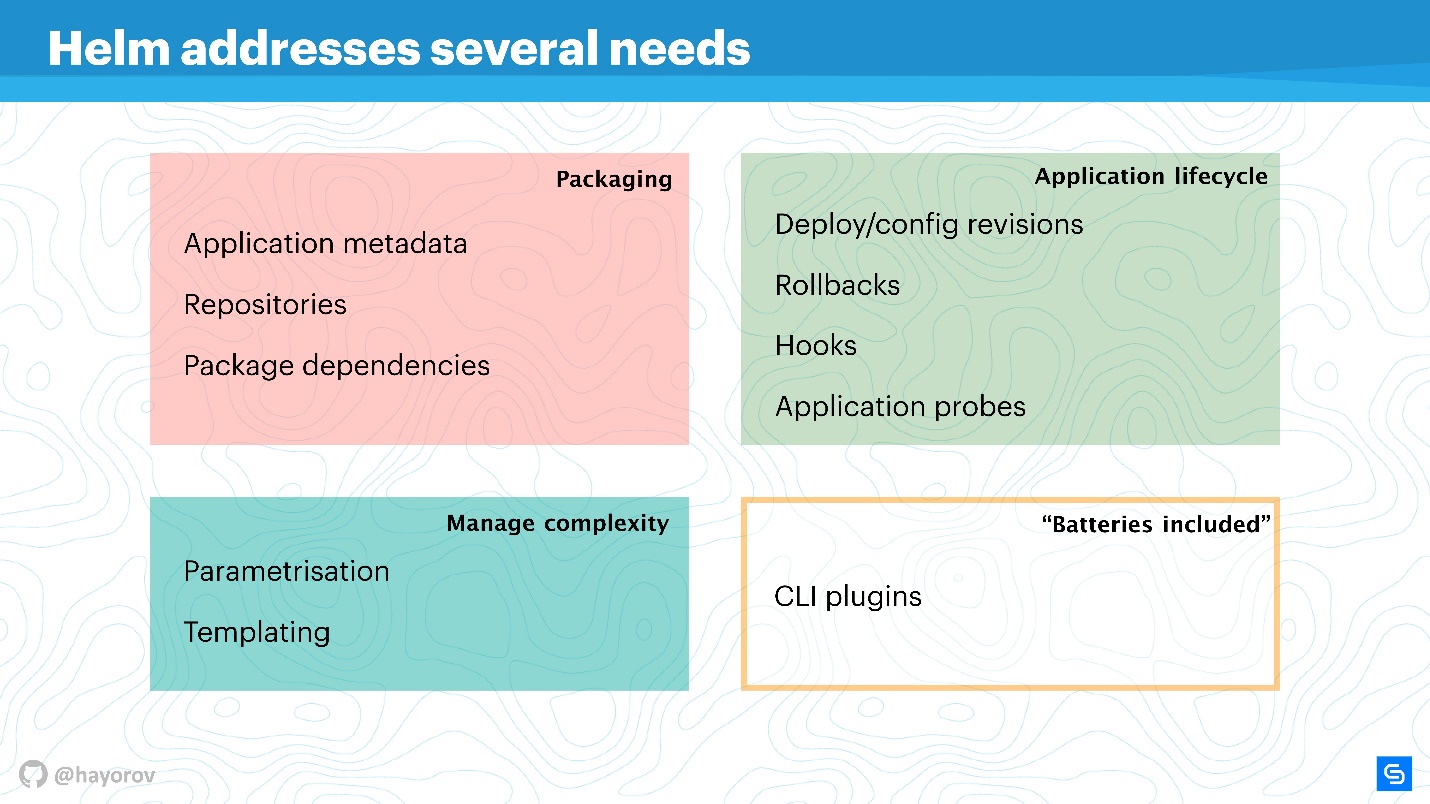
Helm löst mehrere Probleme bei der Verwaltung von Root-Anwendungen in Kubernetes.
- Anwendungsverpackung. Sogar eine Anwendung wie "Hello, World" in WordPress besteht bereits aus mehreren Diensten, und ich möchte sie zusammenpacken.
- Verwaltung der Komplexität, die bei der Verwaltung dieser Anwendungen entsteht.
- Ein Lebenszyklus, der nach der Installation oder Bereitstellung der Anwendung nicht endet. Es lebt weiter, es muss aktualisiert werden, und Helm hilft dabei und versucht, die richtigen Maßnahmen und Richtlinien dafür zu finden.
Das Packen ist verständlich organisiert: Es gibt Metadaten, die der Arbeit eines regulären Paketmanagers für Linux, Windows oder MacOS entsprechen. Das heißt, ein Repository, abhängig von verschiedenen Paketen, Metainformationen für Anwendungen, Einstellungen, Konfigurationsfunktionen, Indizierung von Informationen usw. Mit diesem Helm können Sie Anwendungen abrufen und verwenden.
Komplexitätsmanagement . Wenn Sie viele ähnliche Anwendungen haben, müssen Sie parametrisieren. Daraus ergeben sich Vorlagen. Um jedoch keine eigene Methode zum Erstellen von Vorlagen zu finden, können Sie das, was Helm bietet, sofort verwenden.
Application Lifecycle Management - meiner Meinung nach ist dies das interessanteste und ungelöste Problem. Deshalb bin ich rechtzeitig zu Helm gekommen. Wir mussten den Anwendungslebenszyklus überwachen und wollten unsere CI / CD- und Anwendungszyklen auf dieses Paradigma übertragen.
Mit Helm können Sie:
- Bereitstellung verwalten, Einführung in das Konzept der Konfiguration und Überarbeitung;
- erfolgreiches Rollback;
- Verwenden Sie Hooks für verschiedene Ereignisse.
- Fügen Sie zusätzliche Anwendungsprüfungen hinzu und reagieren Sie auf deren Ergebnisse.
Darüber hinaus
verfügt Helm über „Batterien“ - eine große Anzahl leckerer Dinge, die in Form von Plug-Ins enthalten sein können, um Ihr Leben zu vereinfachen. Plugins können unabhängig voneinander geschrieben werden, sie sind ziemlich isoliert und erfordern keine schlanke Architektur. Wenn Sie etwas implementieren möchten, empfehle ich, es als Plugin zu verwenden, und es ist dann möglich, es in den Upstream aufzunehmen.
Helm basiert auf drei Hauptkonzepten:
- Chart Repo - Beschreibung und Array der Parametrisierung für Ihr Manifest möglich.
- Config - das sind die Werte, die angewendet werden (Text, numerische Werte usw.).
- Release bringt die beiden obersten Komponenten zusammen und zusammen werden sie zu Release. Releases können versioniert werden, wodurch die Organisation des Lebenszyklus erreicht wird: klein zum Zeitpunkt der Installation und groß zum Zeitpunkt des Upgrades, Downgrades oder Rollbacks.
Helm Architektur
Das Diagramm spiegelt konzeptionell die übergeordnete Architektur von Helm wider.
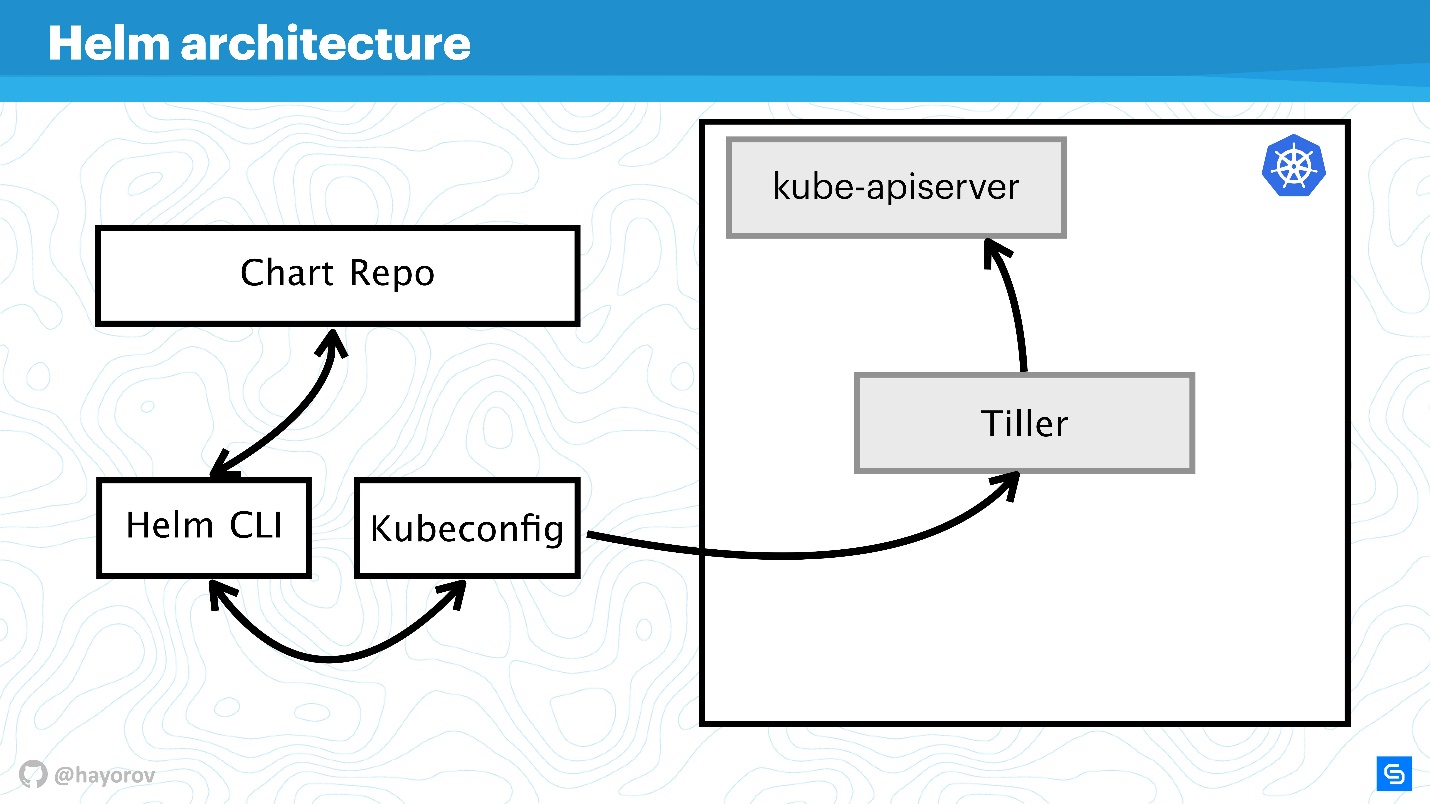
Ich möchte Sie daran erinnern, dass Helm etwas ist, das mit Kubernetes verbunden ist. Daher können wir nicht auf Kubernetes-Cluster (Rechteck) verzichten. Die kube-apiserver-Komponente befindet sich im Assistenten. Ohne Helm haben wir Kubeconfig. Helm bringt sozusagen eine kleine Binärdatei mit, das Helm CLI-Dienstprogramm, das auf einem Computer, Laptop oder Mainframe installiert ist - für alles.
Das reicht aber nicht. Helm hat eine Pinnenserverkomponente. Er repräsentiert Helm innerhalb eines Clusters, es ist dieselbe Anwendung innerhalb eines Kubernetes-Clusters wie jede andere.
Die nächste Komponente von Chart Repo ist das Chart-Repository. Es gibt ein offizielles Repository und möglicherweise ein privates Repository eines Unternehmens oder Projekts.
Interaktion
Lassen Sie uns sehen, wie Architekturkomponenten interagieren, wenn wir eine Anwendung mit Helm installieren möchten.
- Wir sagen,
Helm install , gehen Sie zum Repository (Chart Repo) und holen Sie sich ein Helm-Diagramm.
- Das Helm-Dienstprogramm (Helm-CLI) interagiert mit Kubeconfig, um herauszufinden, welcher Cluster kontaktiert werden soll.
- Nachdem das Dienstprogramm diese Informationen erhalten hat, wendet es sich bereits als Anwendung an Tiller, das sich in unserem Cluster befindet.
- Tiller fordert Kube-apiserver auf, Aktionen in Kubernetes auszuführen und einige Objekte (Dienste, Pods, Replikate, Geheimnisse usw.) zu erstellen.
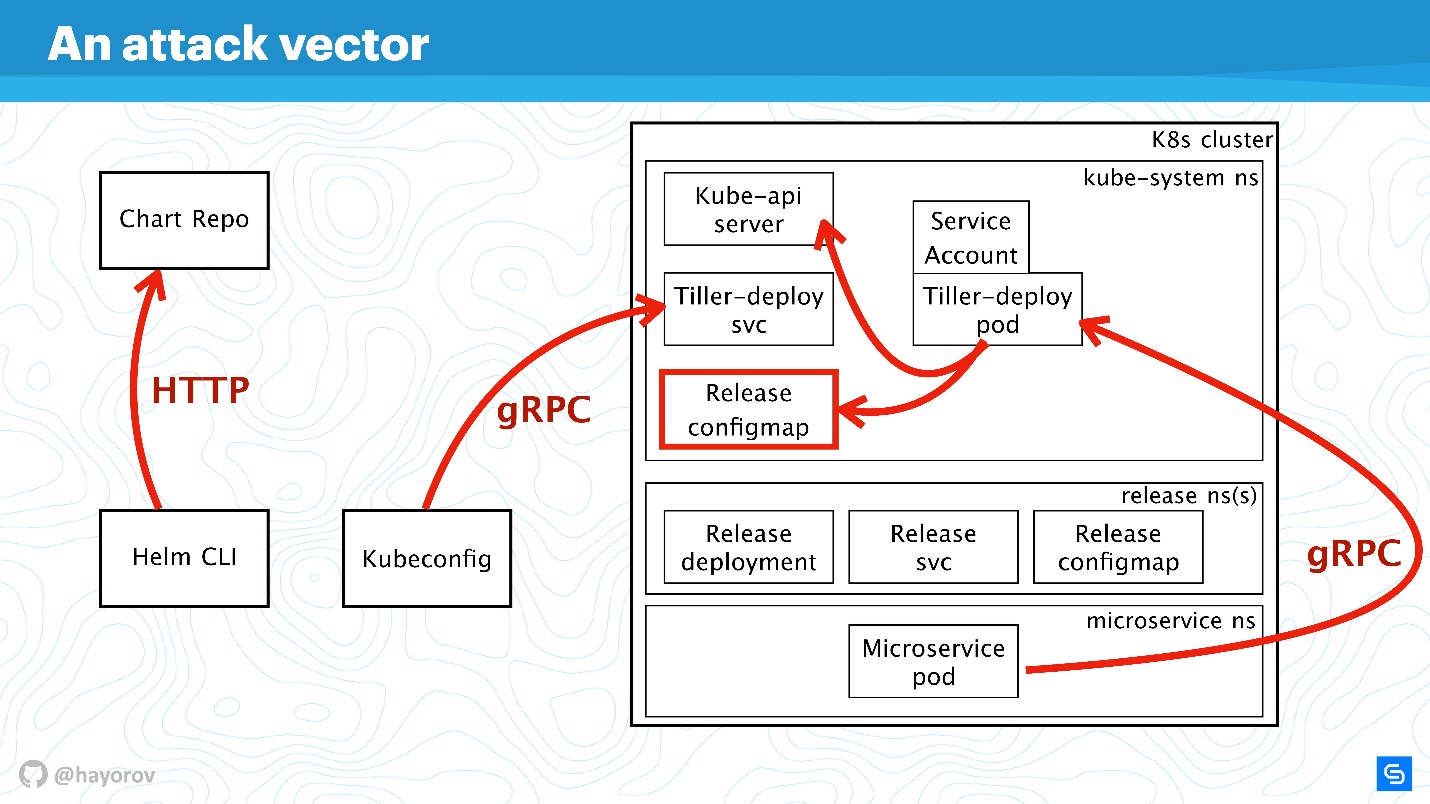
Außerdem werden wir das Schema komplizieren, um den Angriffsvektor zu sehen, dem die gesamte Helm-Architektur als Ganzes ausgesetzt werden kann. Und dann werden wir versuchen, sie zu beschützen.
Angriffsvektor
Der erste potenziell schwache Punkt ist die
privilegierte Benutzer- API . Als Teil des Programms ist dies ein Hacker, der Administratorzugriff auf Helm CLI erhalten hat.
Ein nicht privilegierter API-Benutzer kann auch gefährlich sein, wenn er sich in der Nähe befindet. Ein solcher Benutzer hat einen anderen Kontext, z. B. kann er in den Einstellungen von Kubeconfig in einem Namespace des Clusters festgelegt werden.
Der interessanteste Angriffsvektor ist möglicherweise der Prozess, der sich innerhalb des Clusters in der Nähe von Tiller befindet und auf den zugegriffen werden kann. Dies kann ein Webserver oder ein Microservice sein, der die Netzwerkumgebung des Clusters erkennt.
Chart Repo ist eine exotische, aber immer beliebter werdende Angriffsoption. Ein Diagramm, das von einem skrupellosen Autor erstellt wurde, kann eine unsichere Ressource enthalten, und Sie werden es ausführen, indem Sie es auf Glauben setzen. Oder es kann das Diagramm ersetzen, das Sie aus dem offiziellen Repository heruntergeladen haben, und beispielsweise eine Ressource in Form von Richtlinien erstellen und Ihren Zugriff eskalieren.
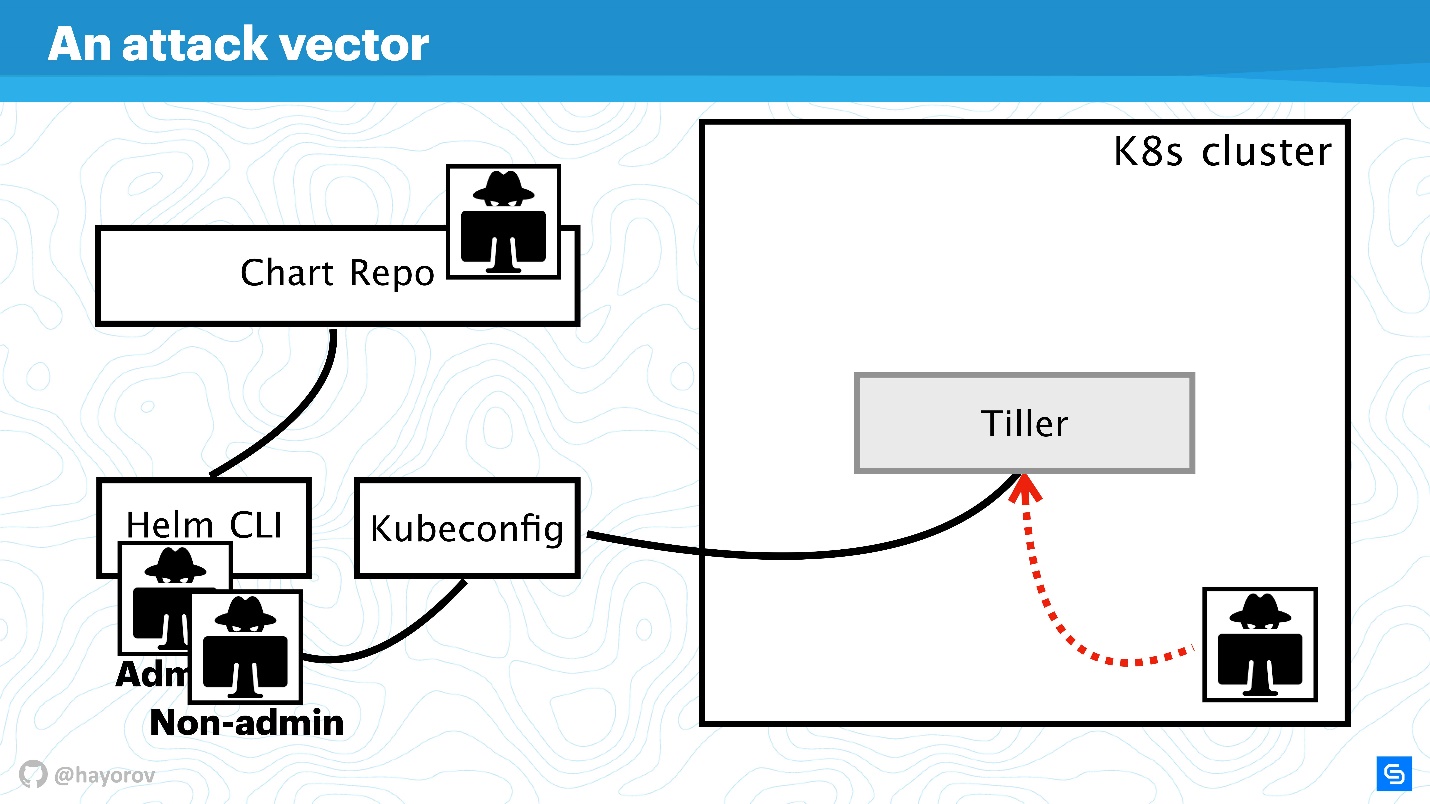
Versuchen wir, Angriffe von all diesen vier Seiten abzuwehren und herauszufinden, wo es Probleme in der Helm-Architektur gibt und wo dies möglicherweise nicht der Fall ist.
Lassen Sie uns das Schema vergrößern, weitere Elemente hinzufügen, aber alle grundlegenden Komponenten beibehalten.
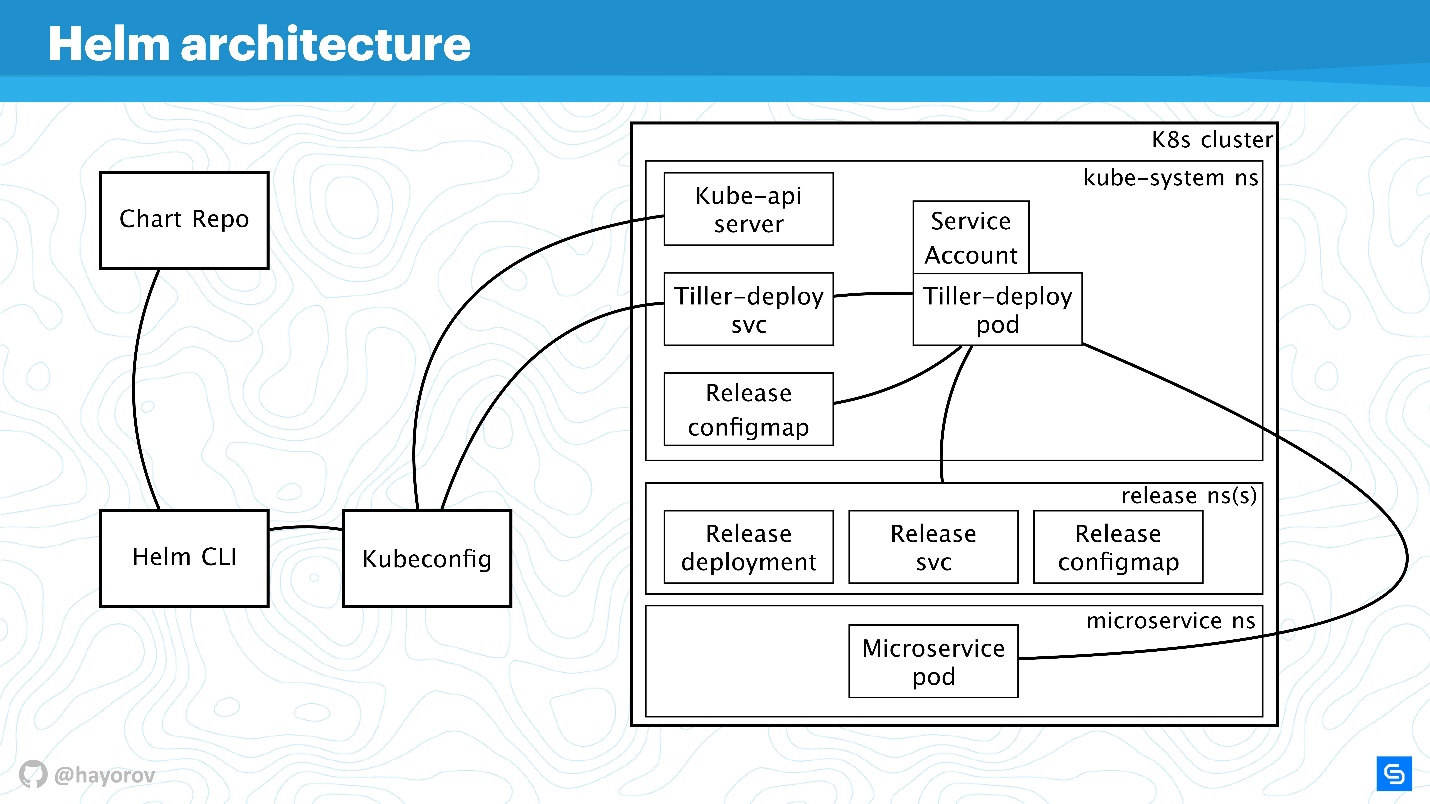
Helm CLI kommuniziert mit Chart Repo, interagiert mit Kubeconfig, die Arbeit wird in der Pinnenkomponente auf den Cluster übertragen.
Pinne wird durch zwei Objekte dargestellt:
- Tiller-deploy svc, das einen bestimmten Dienst verfügbar macht;
- Tiller-Deployment-Pod (im Diagramm in einer einzelnen Kopie in einem Replikat), der die gesamte Last ausführt, die auf den Cluster zugreift.
Für die Interaktion werden verschiedene Protokolle und Schemata verwendet. Aus Sicherheitsgründen sind wir am meisten interessiert an:
- Der Mechanismus, über den die Helm-CLI auf das Chart-Repo zugreift: Welches Protokoll, ob eine Authentifizierung vorliegt und was dagegen getan werden kann.
- Das Protokoll, über das Helm CLI mit kubectl mit Tiller kommuniziert. Dies ist ein im Cluster installierter RPC-Server.
- Tiller selbst ist für Microservices verfügbar, die sich in einem Cluster befinden und mit Kube-Apiserver interagieren.
Wir werden alle diese Richtungen der Reihe nach besprechen.
RBAC
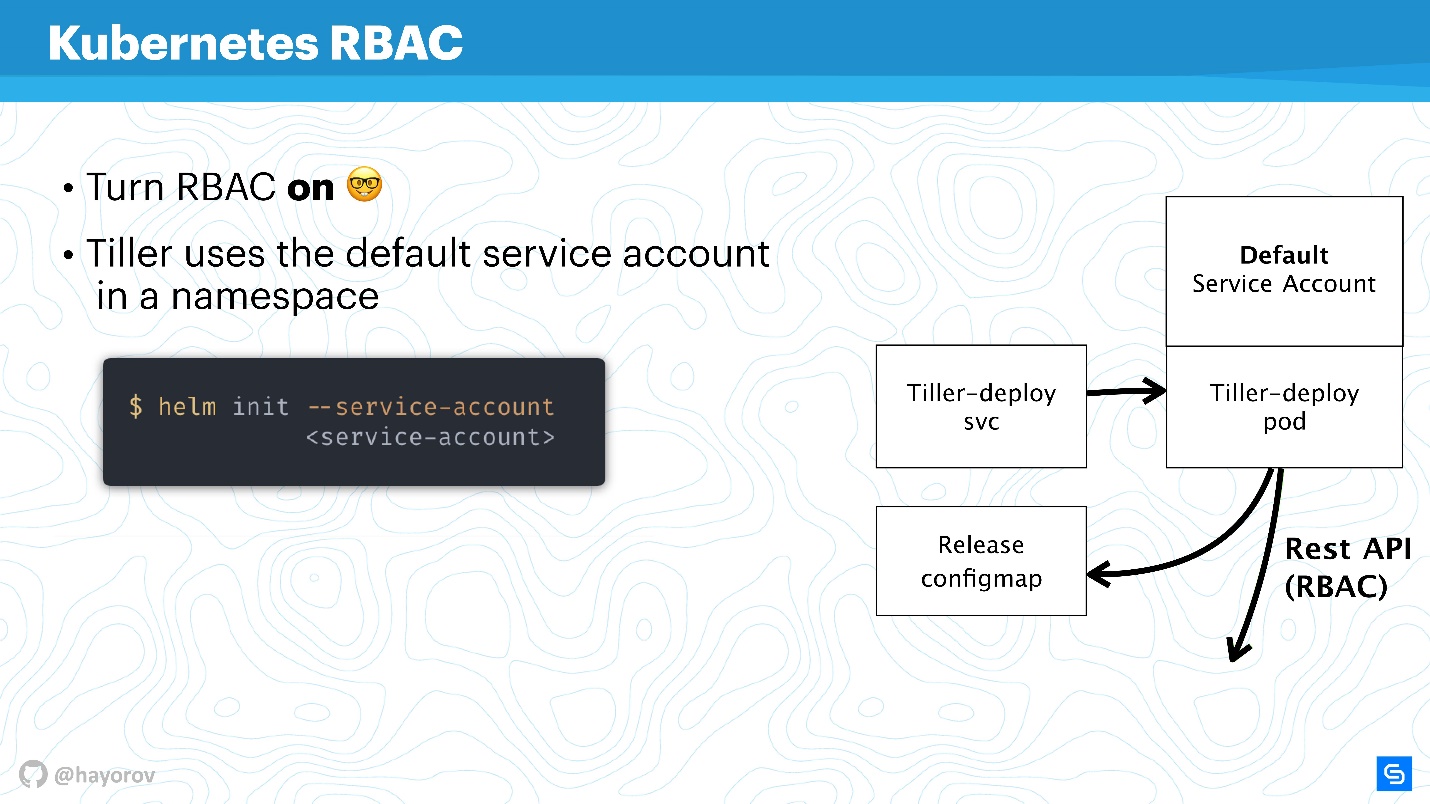
Es ist sinnlos, über die Sicherheit von Helm oder einem anderen Dienst innerhalb des Clusters zu sprechen, wenn RBAC nicht aktiviert ist.
Es scheint, dass dies selbst keine neue Empfehlung ist, aber ich bin sicher, dass viele RBAC bisher nicht einmal in die Produktion aufgenommen haben, da dies viel Aufhebens macht und es viel zu konfigurieren gibt. Trotzdem fordere ich dies dringend auf.
 https://rbac.dev/
https://rbac.dev/ ist eine Anwaltsseite für RBAC. Es wurden eine Vielzahl interessanter Materialien gesammelt, die beim Aufbau von RBAC helfen, zeigen, warum es gut ist und wie man im Prinzip damit in der Produktion leben kann.
Ich werde versuchen zu erklären, wie Tiller und RBAC funktionieren. Pinne arbeitet in einem Cluster unter einem bestimmten Dienstkonto. Wenn RBAC nicht konfiguriert ist, ist dies normalerweise der Superuser. In der Grundkonfiguration ist Tiller der Administrator. Aus diesem Grund wird häufig gesagt, dass Tiller ein SSH-Tunnel zu Ihrem Cluster ist. Dies ist tatsächlich der Fall, sodass Sie anstelle des Standarddienstkontos in der obigen Abbildung ein separates dediziertes Dienstkonto verwenden können.
Wenn Sie Helm initialisieren, installieren Sie es zuerst auf dem Server. Sie können das Dienstkonto mit
--service-account . Auf diese Weise können Sie den Benutzer mit den minimal erforderlichen Rechten verwenden. Richtig, Sie müssen eine solche "Girlande" erstellen: Rolle und Rollenbindung.
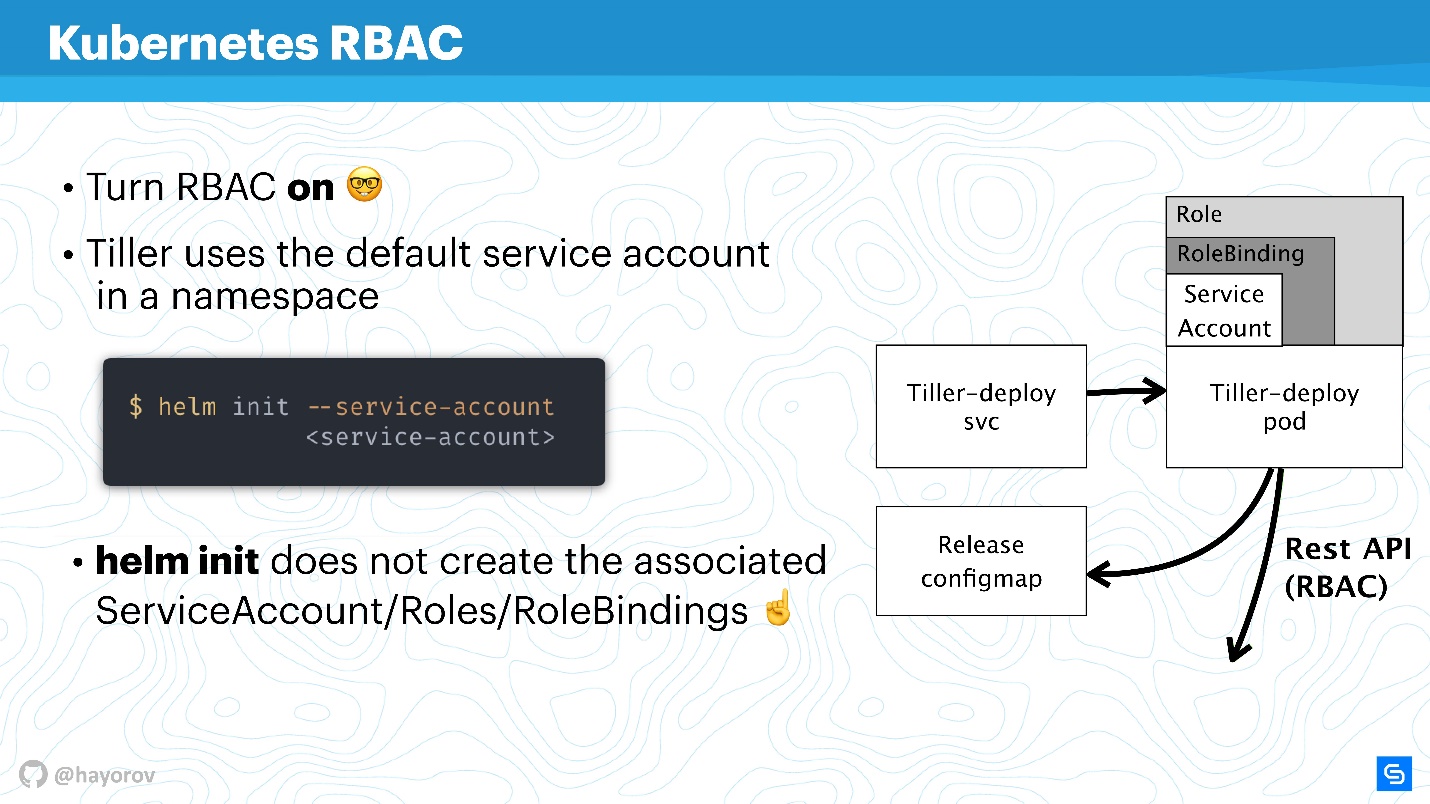
Leider wird Helm dies nicht für Sie tun. Sie oder Ihr Kubernetes-Clusteradministrator müssen im Voraus eine Reihe von Rollen und Rollenbindungen für das Dienstkonto vorbereiten, um Helm übertragen zu können.
Die Frage ist - was ist der Unterschied zwischen Rolle und ClusterRole? Der Unterschied besteht darin, dass ClusterRole für alle Namespaces gültig ist, im Gegensatz zu regulären Role- und RoleBinding-Funktionen, die nur für spezialisierte Namespaces funktionieren. Sie können Richtlinien für den gesamten Cluster und alle Namespaces konfigurieren sowie für jeden Namespace separat personalisieren.
Es ist erwähnenswert, dass RBAC ein weiteres großes Problem löst. Viele beklagen, dass Helm leider keine Mandantenfähigkeit hat (unterstützt keine Mandantenfähigkeit). Wenn mehrere Teams einen Cluster verwenden und Helm verwenden, ist es im Prinzip unmöglich, Richtlinien zu konfigurieren und ihren Zugriff innerhalb dieses Clusters zu differenzieren, da es ein Dienstkonto gibt, unter dem Helm arbeitet, und alle Ressourcen im Cluster daraus erstellt manchmal sehr unangenehm. Dies ist wahr - als Binärdatei selbst hat
Helm Tiller als Prozess
keine Ahnung von Multitenancy .
Es gibt jedoch eine großartige Möglichkeit, Tiller mehrmals in einem Cluster auszuführen. Dies ist kein Problem. Tiller kann in jedem Namespace ausgeführt werden. So können Sie RBAC, Kubeconfig als Kontext verwenden und den Zugriff auf den speziellen Helm einschränken.
Es wird wie folgt aussehen.
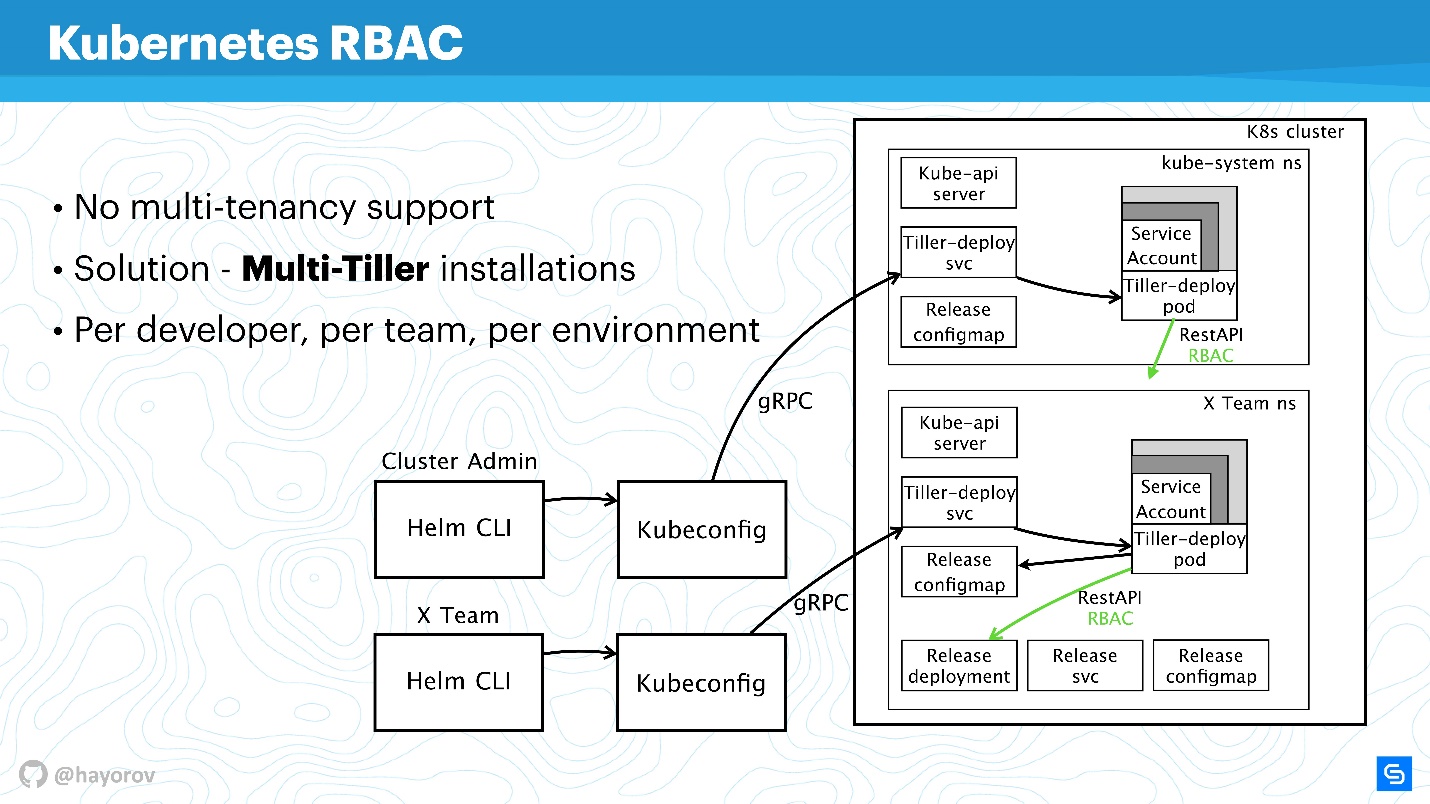
Beispielsweise gibt es zwei Kubeconfig mit Kontext für verschiedene Teams (zwei Namespace): X Team für das Entwicklungsteam und den Administratorcluster. Der Admin-Cluster verfügt über eine eigene breite Pinne, die sich im Kube-System-Namespace bzw. einem erweiterten Dienstkonto befindet. Als separater Namespace für das Entwicklungsteam können sie ihre Services in einem speziellen Namespace bereitstellen.
Dies ist ein funktionierender Ansatz. Tiller ist nicht so gefräßig, dass er Ihr Budget stark beeinträchtigen könnte. Dies ist eine der schnellen Lösungen.
Sie können Tiller auch separat konfigurieren und Kubeconfig einen Kontext für das Team, einen bestimmten Entwickler oder die Umgebung bereitstellen: Dev, Staging, Production (es ist zweifelhaft, dass sich alles auf demselben Cluster befindet, dies ist jedoch möglich).
Setzen Sie unsere Geschichte fort, wechseln Sie von RBAC und sprechen Sie über ConfigMaps.
Configmaps
Helm verwendet ConfigMaps als Data Warehouse. Als wir über Architektur sprachen, gab es nirgendwo eine Datenbank, in der Informationen zu Releases, Konfigurationen, Rollbacks usw. gespeichert waren. Hierfür wird ConfigMaps verwendet.
Das Hauptproblem bei ConfigMaps ist bekannt - sie sind im Prinzip unsicher, es ist
unmöglich, vertrauliche Daten in ihnen
zu speichern . Wir sprechen über alles, was nicht über den Dienst hinausgehen sollte, zum Beispiel Passwörter. Der ursprünglichste Weg für Helm besteht nun darin, von der Verwendung von ConfigMaps zu Geheimnissen überzugehen.
Dies geschieht sehr einfach. Definieren Sie die Pinneneinstellung neu und geben Sie an, dass der Speicher geheim sein soll. Dann erhalten Sie für jede Bereitstellung keine ConfigMap, sondern ein Geheimnis.
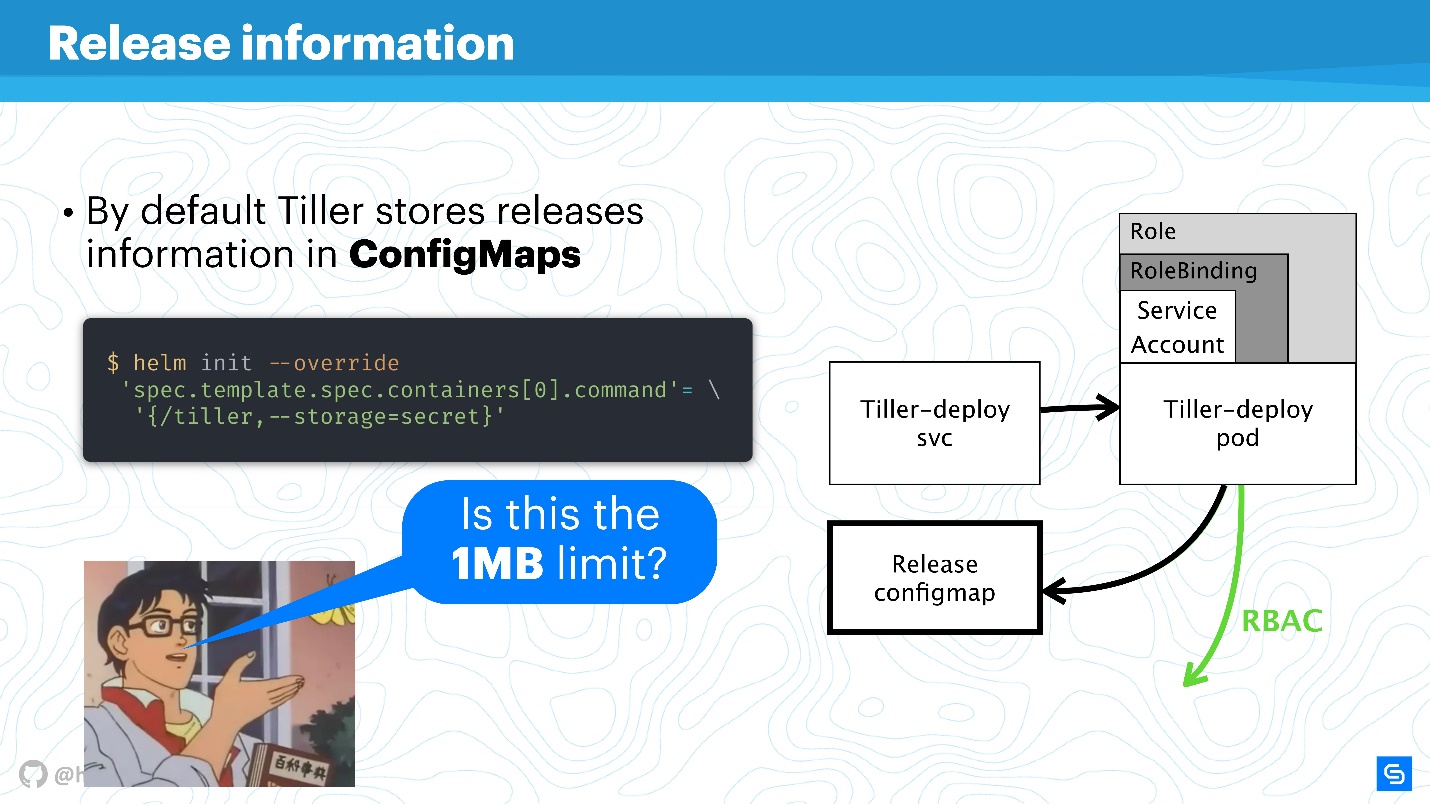
Sie können argumentieren, dass die Geheimnisse selbst ein seltsames Konzept sind und es nicht sehr sicher ist. Es ist jedoch verständlich, dass die Entwickler von Kubernetes dies tun. Ab Version 1.10, d.h. Vor langer Zeit gab es zumindest in öffentlichen Clouds die Möglichkeit, den richtigen Speicher anzuschließen, um Geheimnisse zu speichern. Jetzt arbeitet das Team daran, den Zugang zu Geheimnissen, einzelnen Einsendungen oder anderen Entitäten noch besser zu verteilen.
Aufbewahrungshelm lässt sich besser in Geheimnisse übersetzen und sichert sich zentral.
Natürlich bleibt
die Datenspeicherung auf 1 MB begrenzt . Helm verwendet hier etcd als verteiltes Repository für ConfigMaps. Und dort dachten sie, es sei ein geeigneter Datenblock für Replikationen usw. Es gibt eine interessante Diskussion über Reddit darüber. Ich empfehle, diese lustige Lektüre für das Wochenende zu finden oder den Squeeze
hier zu lesen.
Chart Repos
Diagramme sind am sozialsten gefährdet und können zur Quelle von "Man in the Middle" werden, insbesondere wenn Sie die Aktienlösung verwenden. Zunächst geht es um Repositorys, die über HTTP verfügbar gemacht werden.
Auf jeden Fall müssen Sie Helm Repo über HTTPS verfügbar machen - dies ist die beste Option und kostengünstig.
Achten Sie auf den
Mechanismus der Diagrammsignaturen . Die Technologie ist einfach zu blamieren. Dies ist das gleiche, was Sie auf GitHub verwenden, dem üblichen PGP-Computer mit öffentlichen und privaten Schlüsseln. Richten Sie ein und stellen Sie sicher, dass Sie über die erforderlichen Schlüssel verfügen und alles signieren. Dies ist wirklich Ihr Diagramm.
Darüber hinaus unterstützt der
Helm-Client TLS (nicht im Sinne von HTTP von der Serverseite, sondern von gegenseitigem TLS). Sie können Server- und Client-Schlüssel verwenden, um zu kommunizieren. Ehrlich gesagt benutze ich einen solchen Mechanismus nicht, weil ich gegenseitige Zertifikate nicht mag. Im Prinzip unterstützt das
Chartmuseum - das wichtigste Helm Repo-Belichtungswerkzeug für Helm 2 - auch die grundlegende Authentifizierung. Sie können die Basisauthentifizierung verwenden, wenn sie bequemer und ruhiger ist.
Es gibt auch ein
helm-gcs-Plugin , mit dem Sie Chart Repos in Google Cloud Storage hosten können. Dies ist sehr praktisch, funktioniert hervorragend und ist sehr sicher, da alle beschriebenen Mechanismen verwendet werden.
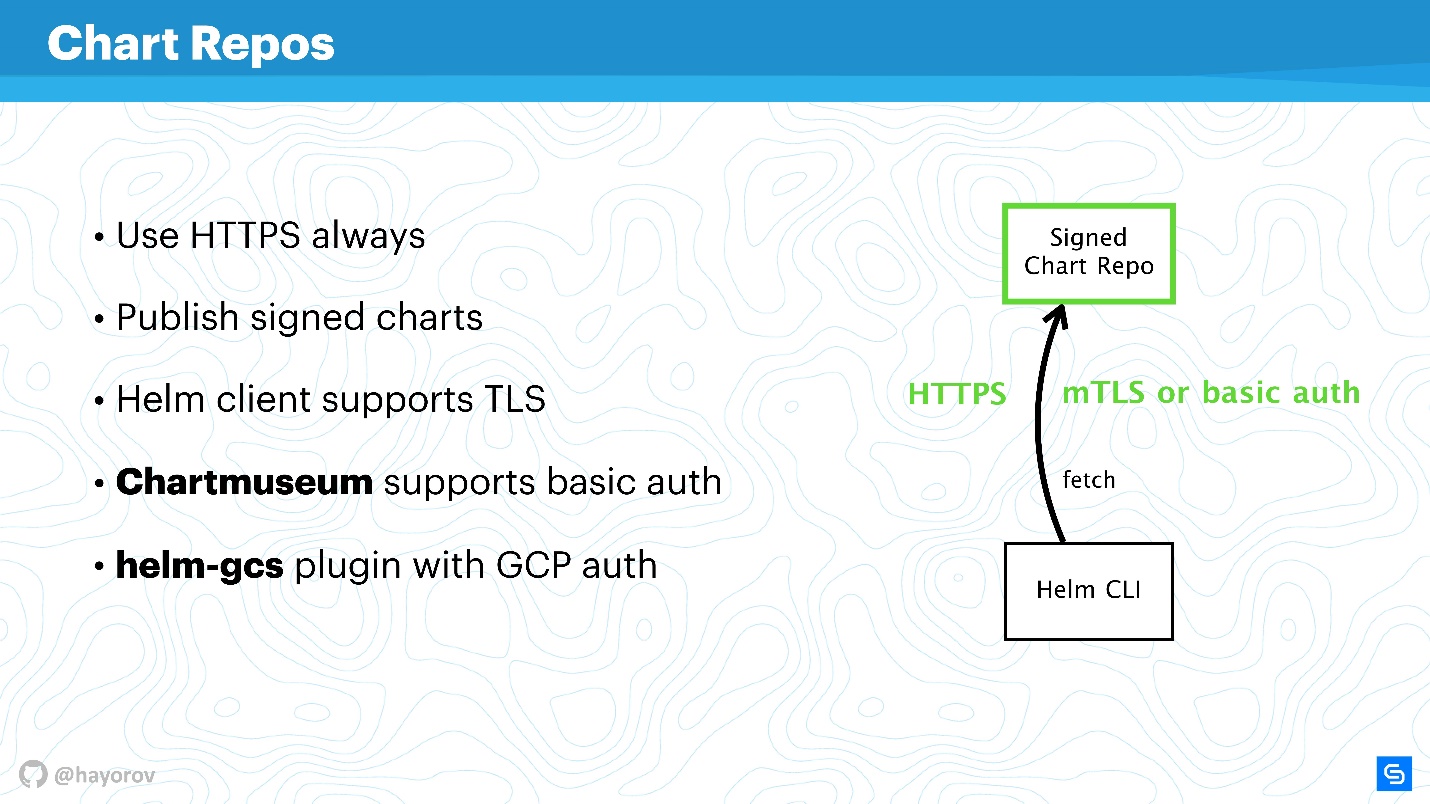
Wenn Sie HTTPS oder TLS aktivieren, mTLS verwenden, die Basisauthentifizierung verbinden, um die Risiken weiter zu reduzieren, erhalten Sie einen sicheren Kommunikationskanal Helm CLI und Chart Repo.
gRPC API
Der nächste Schritt ist sehr verantwortungsbewusst - um Tiller zu sichern, der sich im Cluster befindet und einerseits der Server ist, andererseits auf die anderen Komponenten zugreift und versucht, sich als jemand vorzustellen.
Wie gesagt, Tiller ist ein Dienst, der gRPC verfügbar macht. Ein Helm-Client kommt über gRPC dazu. Standardmäßig ist TLS natürlich deaktiviert. Warum dies getan wird, ist eine umstrittene Frage. Es scheint mir, das Setup zu Beginn zu vereinfachen.
Für die Produktion und sogar für das Staging empfehle ich, TLS auf gRPC zu aktivieren.
Meiner Meinung nach ist dies im Gegensatz zu mTLS für Diagramme hier angemessen und sehr einfach - generieren Sie eine PQI-Infrastruktur, erstellen Sie ein Zertifikat, starten Sie Tiller, übertragen Sie das Zertifikat während der Initialisierung. Danach können Sie alle Helm-Befehle ausführen, die als generiertes Zertifikat und privater Schlüssel erscheinen.
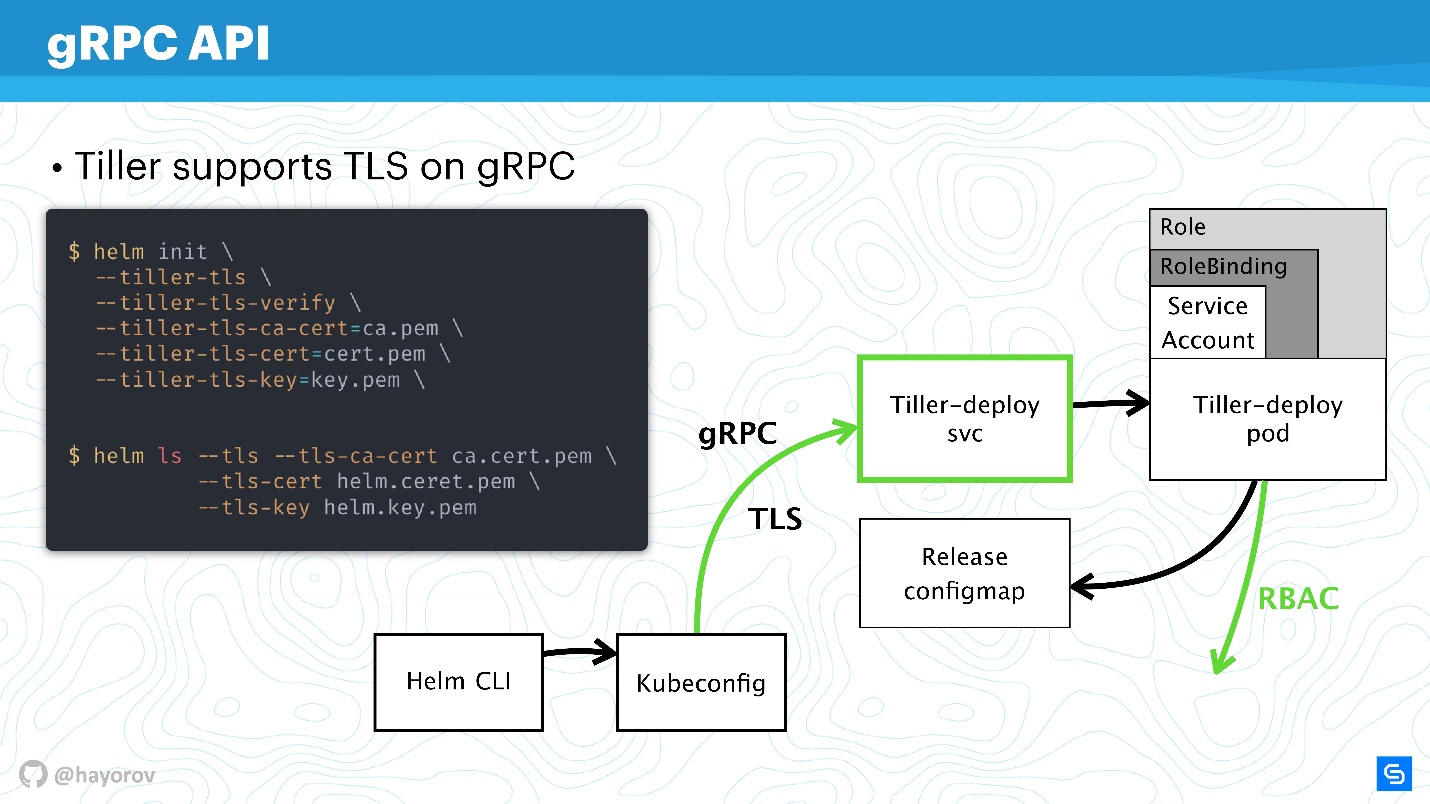
So schützen Sie sich vor allen Anfragen an Tiller von außerhalb des Clusters.
Also haben wir den Verbindungskanal zu Tiller gesichert, RBAC bereits besprochen und die Rechte von Kubernetes Apiserver angepasst, die Domain reduziert, mit der es interagieren kann.
Geschützter Helm
Schauen wir uns das endgültige Diagramm an. Dies ist dieselbe Architektur mit denselben Pfeilen.
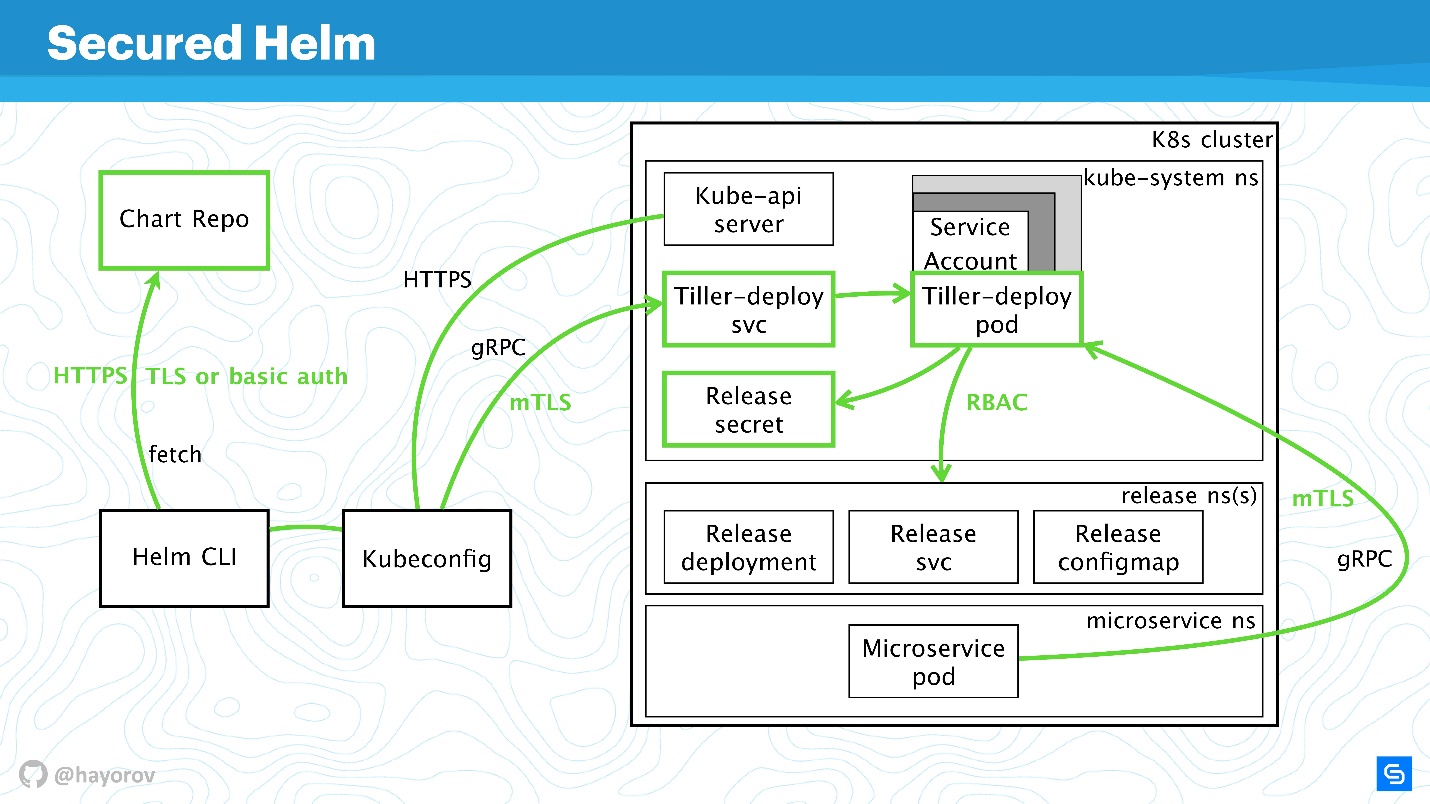
Alle Verbindungen können jetzt sicher grün gestrichen werden:
- Für Chart Repo verwenden wir TLS oder mTLS und Basic Auth.
- mTLS für Tiller, und es wird als gRPC-Dienst mit TLS verfügbar gemacht. Wir verwenden Zertifikate.
- Der Cluster verwendet ein spezielles Dienstkonto mit Role und RoleBinding.
Wir haben den Cluster deutlich gesichert, aber jemand, der klug ist, sagte:
"Es kann nur eine absolut sichere Lösung geben - der Computer ist ausgeschaltet, befindet sich in einer Betonbox und wird von Soldaten bewacht."
Es gibt verschiedene Möglichkeiten, Daten zu manipulieren und neue Angriffsmethoden zu finden. Ich bin jedoch zuversichtlich, dass diese Empfehlungen die Umsetzung eines grundlegenden Sicherheitsstandards für die Industrie ermöglichen werden.
Bonus
Dieser Teil steht nicht in direktem Zusammenhang mit der Sicherheit, ist aber auch nützlich. Ich werde Ihnen einige interessante Dinge zeigen, über die nur wenige Menschen Bescheid wissen. Zum Beispiel, wie man nach Charts sucht - offiziell und inoffiziell.
Das Repository von
github.com/helm/charts verfügt jetzt über ca. 300 Diagramme und zwei Streams: Stable und Inkubator. Der Mitwirkende weiß, wie schwierig es ist, vom Inkubator zum Stall zu gelangen, und wie einfach es ist, aus dem Stall zu fliegen. Dies ist jedoch nicht das beste Tool, um nach Charts für Prometheus zu suchen, und alles, was Sie aus einem einfachen Grund mögen, ist kein Portal, in dem Sie bequem nach Paketen suchen können.
Es gibt jedoch einen
hub.helm.sh- Dienst, mit dem es viel bequemer ist, Diagramme zu finden. Am wichtigsten ist, dass es viel mehr externe Repositories gibt und fast 800 Zeichen verfügbar sind. Außerdem können Sie Ihr Repository verbinden, wenn Sie Ihre Diagramme aus irgendeinem Grund nicht an Stable senden möchten.
Probieren Sie hub.helm.sh aus und lassen Sie es uns gemeinsam entwickeln. Dieser Service gehört zum Helm-Projekt, und Sie können sogar einen Beitrag zur Benutzeroberfläche leisten, wenn Sie ein Front-End-Anbieter sind und einfach das Erscheinungsbild verbessern möchten.
Ich möchte Ihre Aufmerksamkeit auch auf die
Open Service Broker API-Integration lenken. Es klingt umständlich und unverständlich, löst aber die Probleme, mit denen jeder konfrontiert ist. Ich werde es mit einem einfachen Beispiel erklären.
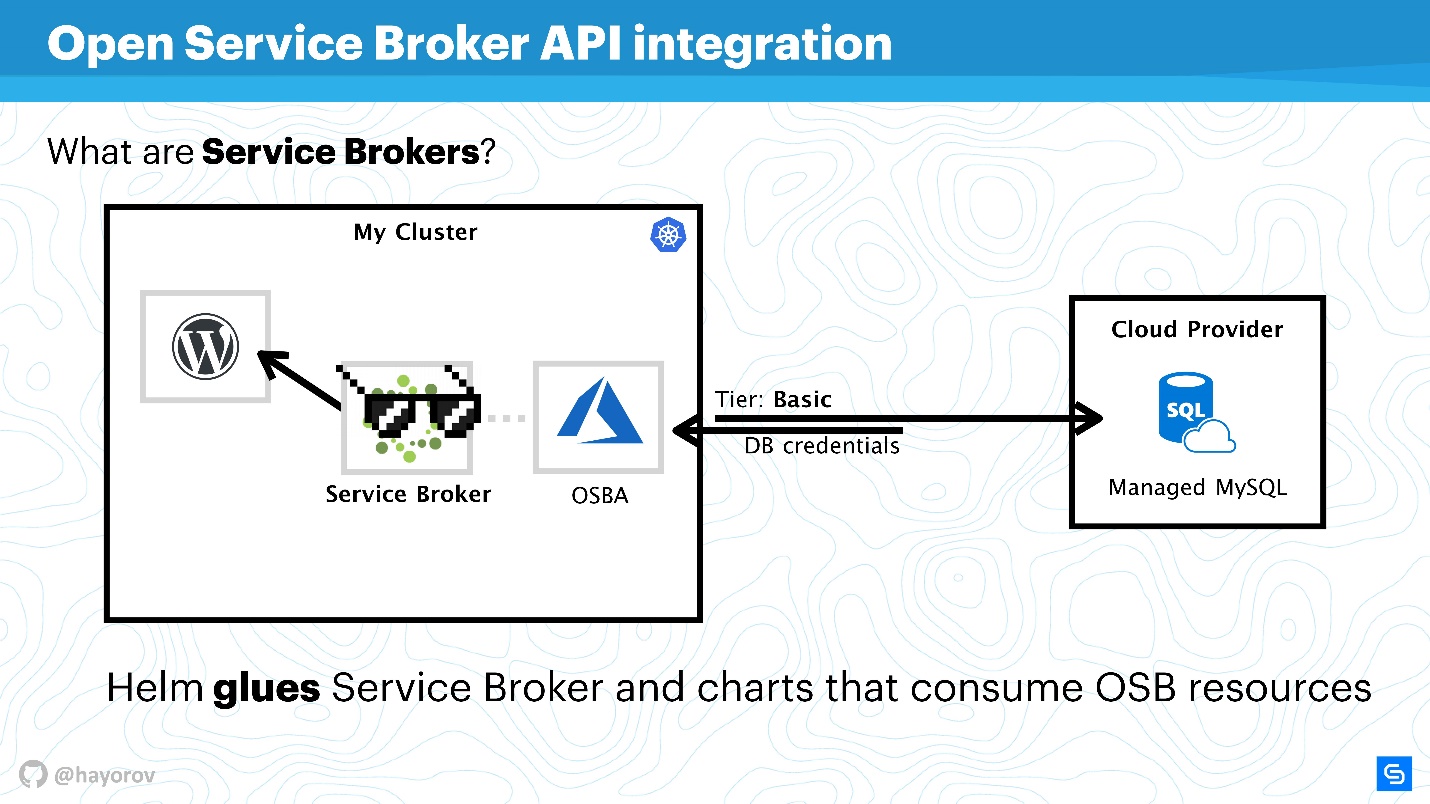
Es gibt einen Kubernetes-Cluster, in dem wir die klassische Anwendung - WordPress - ausführen wollen. Für die volle Funktionalität wird in der Regel eine Datenbank benötigt. Es gibt viele verschiedene Lösungen, zum Beispiel können Sie Ihren Statefull-Service starten. Dies ist nicht sehr praktisch, aber viele tun es.
Andere, wie wir bei Chainstack, verwenden verwaltete Datenbanken wie MySQL oder PostgreSQL für Server. Daher befinden sich unsere Datenbanken irgendwo in der Cloud.
Es tritt jedoch ein Problem auf: Sie müssen unseren Service mit der Datenbank verbinden, eine Flavour-Datenbank erstellen, Anmeldeinformationen übergeben und diese irgendwie verwalten. All dies wird normalerweise manuell vom Systemadministrator oder Entwickler durchgeführt. Und es gibt kein Problem, wenn es nur wenige Anwendungen gibt. Wenn es viele gibt, brauchen Sie einen Mähdrescher. Es gibt einen solchen Mähdrescher - das ist Service Broker. Sie können ein spezielles Plug-In für den öffentlichen Cloud-Cluster verwenden und Ressourcen über Broker beim Anbieter bestellen, als wäre es eine API. Hierfür können Sie die nativen Kubernetes-Tools verwenden.
Es ist sehr einfach. Sie können beispielsweise verwaltetes MySQL in Azure mit einer Basisebene abfragen (dies kann angepasst werden). Mithilfe der Azure-API wird die Basis erstellt und für die Verwendung vorbereitet. Sie müssen sich nicht einmischen, das Plugin ist dafür verantwortlich. Beispielsweise gibt OSBA (Azure-Plugin) Anmeldeinformationen an den Dienst zurück und übergibt sie an Helm. Sie können WordPress mit wolkigem MySQL verwenden, sich überhaupt nicht mit verwalteten Datenbanken befassen und sich keine Gedanken über die darin enthaltenen Statefull-Dienste machen.
Wir können sagen, dass Helm als Klebstoff fungiert, der es Ihnen einerseits ermöglicht, Dienste bereitzustellen, und andererseits die Ressourcen von Cloud-Anbietern verbraucht.
Sie können Ihr eigenes Plugin schreiben und diese gesamte On-Premise-Story verwenden. Dann haben Sie einfach Ihr eigenes Plugin für den Corporate Cloud-Anbieter. Ich empfehle Ihnen, diesen Ansatz auszuprobieren, insbesondere wenn Sie einen großen Umfang haben und schnell Entwickler, Staging oder die gesamte Infrastruktur für eine Funktion bereitstellen möchten. Dies erleichtert Ihren Operationen oder DevOps das Leben.
Ein weiterer Fund, den ich bereits erwähnt habe, ist das
helm-gcs-Plugin , mit dem Sie Google-Buckets (Objektspeicher) zum Speichern von Helm-Diagrammen verwenden können.

Es sind nur vier Befehle erforderlich, um es zu verwenden:
- installiere das Plugin;
- initiiere es;
- Setzen Sie den Pfad auf Bucket, das sich in gcp befindet.
- Veröffentlichen Sie Diagramme auf standardmäßige Weise.
Das Schöne ist, dass die native gcp-Methode für die Autorisierung verwendet wird. Sie können ein Dienstkonto, ein Entwicklerkonto - alles verwenden. Es ist sehr praktisch und kostet nichts zu bedienen. Wenn Sie, wie ich, eine Philosophie der Opsless befürworten, ist dies besonders für kleine Teams sehr praktisch.
Alternativen
Helm ist nicht die einzige Service-Management-Lösung. Es gibt viele Fragen an ihn, weshalb die dritte Version wahrscheinlich so schnell erschien. Natürlich gibt es Alternativen.
Dies können spezielle Lösungen sein, z. B. Ksonnet oder Metaparticle. Sie können Ihre klassischen Infrastrukturverwaltungstools (Ansible, Terraform, Chef usw.) für dieselben Zwecke verwenden, über die ich gesprochen habe.
Schließlich gibt es die
Operator Framework- Lösung, deren Popularität wächst.
Das Operator Framework ist die wichtigste Helm-Alternative, auf die Sie achten sollten.
Es ist nativer für CNCF und Kubernetes,
aber die Eintrittsschwelle ist viel höher . Sie müssen mehr programmieren und Manifeste weniger beschreiben.
Es gibt verschiedene Addons wie Draft, Scaffold. Sie vereinfachen das Leben erheblich. Entwickler vereinfachen beispielsweise den Zyklus des Sendens und Startens von Helm für die Bereitstellung einer Testumgebung. Ich würde sie als Extender of Opportunities bezeichnen.
Hier ist eine visuelle Grafik, wo sich was befindet.
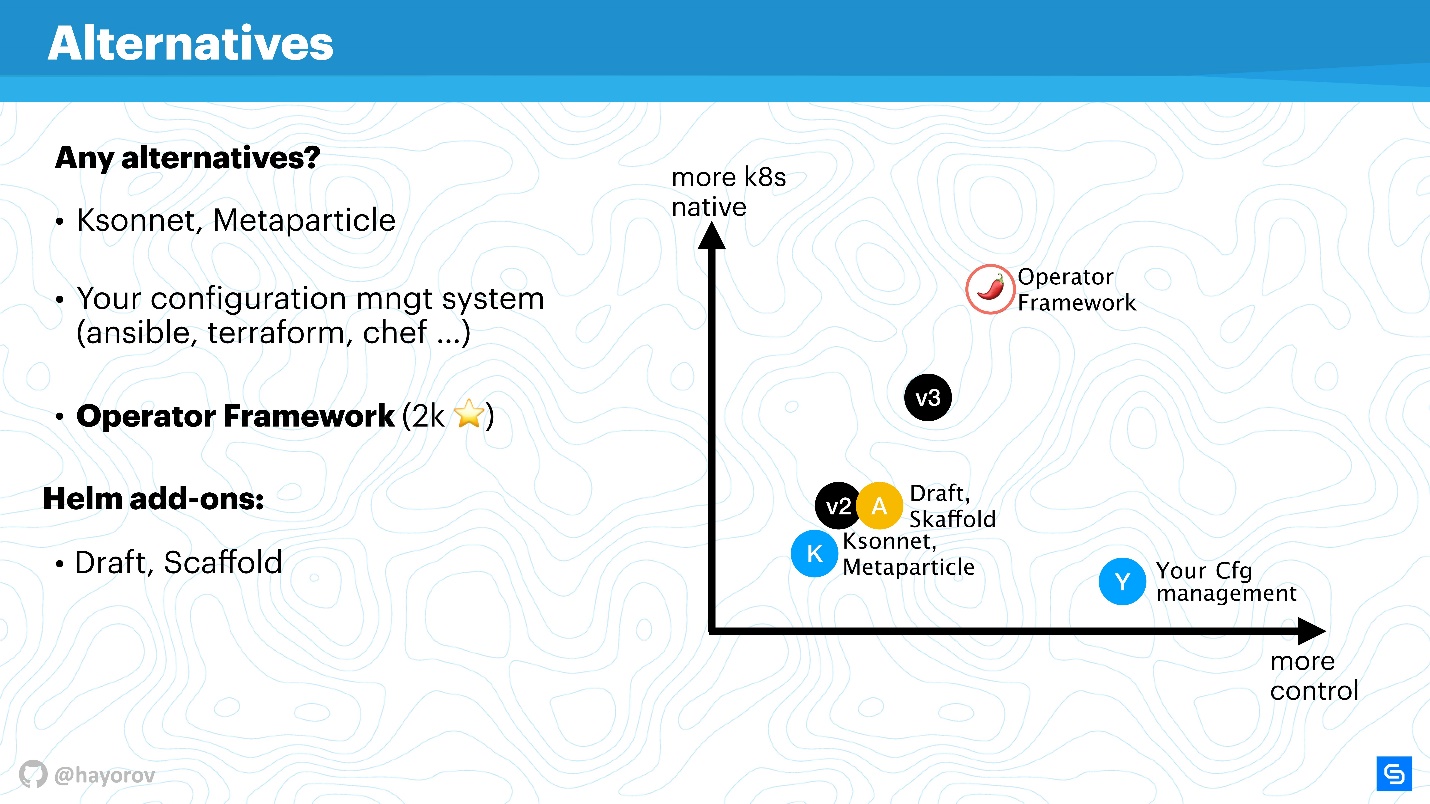
Auf der x-Achse die Ebene Ihrer persönlichen Kontrolle über das Geschehen, auf der y-Achse die Ebene der Kubernetes-Ursprünglichkeit. Helm Version 2 ist irgendwo in der Mitte. In Version 3 ist es nicht kolossal, aber sowohl die Kontrolle als auch der Grad der Ursprünglichkeit werden verbessert. Ksonnet-Lösungen sind selbst Helm 2 noch unterlegen. Sie sind jedoch einen Blick wert, um zu wissen, was es sonst noch auf dieser Welt gibt. Natürlich wird Ihr Konfigurationsmanager unter Ihrer Kontrolle sein, aber absolut nicht für Kubernetes nativ.
Das Operator Framework ist absolut in Kubernetes integriert und ermöglicht es Ihnen, es viel eleganter und sorgfältiger zu verwalten (aber denken Sie an die Einstiegsebene). Es eignet sich eher für eine spezielle Anwendung und die Erstellung eines Managements dafür als für einen Massenroder zum Verpacken einer großen Anzahl von Anwendungen mit Helm.
Extender verbessern einfach die Steuerung ein wenig, ergänzen den Workflow oder schneiden Ecken von CI / CD-Pipelines ab.
Die Zukunft von Helm
Die gute Nachricht ist, dass Helm 3 erscheint. Die Alpha-Version von Helm 3.0.0-alpha.2 wurde bereits veröffentlicht. Sie können es versuchen. Es ist ziemlich stabil, aber die Funktionalität ist immer noch begrenzt.
Warum brauchst du Helm 3? Zuallererst ist dies die Geschichte des
Verschwindens von Tiller als Bestandteil. Wie Sie bereits verstehen, ist dies ein großer Schritt nach vorne, da unter dem Gesichtspunkt der architektonischen Sicherheit alles vereinfacht wird.
Als Helm 2 erstellt wurde, das während Kubernetes 1.8 oder noch früher war, waren viele Konzepte unausgereift. Beispielsweise wird das Konzept der CRD aktiv umgesetzt, und Helm wird
die CRD zum Speichern von Strukturen verwenden. Es ist möglich, nur den Client zu verwenden und nicht die Serverseite zu behalten. Verwenden Sie daher native Kubernetes-Befehle, um mit Strukturen und Ressourcen zu arbeiten. Dies ist ein großer Schritt nach vorne.
Unterstützung für native OCI-Repositorys (Open Container Initiative) wird angezeigt. Dies ist eine große Initiative, und Helm ist vor allem für die Veröffentlichung seiner Charts interessant. Es kommt zu dem Punkt, dass beispielsweise der Docker Hub viele OCI-Standards unterstützt. Ich wundere mich nicht, aber vielleicht geben Ihnen die klassischen Anbieter von Docker-Repositories die Möglichkeit, ihre Helm-Charts für Sie zu platzieren.
Eine kontroverse Geschichte für mich ist
Luas Unterstützung als Template-Engine zum Schreiben von Skripten. Ich bin kein großer Fan von Lua, aber es wird eine völlig optionale Funktion sein. Ich habe es dreimal überprüft - die Verwendung von Lua ist nicht erforderlich. Daher kann jeder, der Lua benutzen möchte, jemand, der Go mag, sich unserem riesigen Camp anschließen und dafür go-tmpl verwenden.
Was mir definitiv fehlte, war das
Auftreten eines Schemas und die Validierung von Datentypen . int string, . JSONS-, values.
event-driven model . . Helm 3, , , , , .
Helm 3 , , Helm 2, Kubernetes . , Helm Kubernetes Kubernetes.
Eine weitere gute Nachricht ist, dass Alexander Khayorov Ihnen auf der DevOpsConf sagt , ob Container sicher sein können. Am 30. September und 1. Oktober findet in Moskau eine Konferenz zur Integration von Entwicklungs-, Test- und Betriebsprozessen statt . Bis zum 20. August können Sie noch einen Bericht einreichen und über Ihre Erfahrungen bei der Lösung einer der vielen Aufgaben des DevOps-Ansatzes sprechen .
Folgen Sie den Kontrollpunkten und Neuigkeiten der Konferenz im Newsletter und im Telegrammkanal .