Neulich fand das Moscow Python Meetup # 66 statt - die Community diskutiert weiterhin relevante Tools, die die Sprache verbessern und an verschiedene Umgebungen anpassen. Einschließlich des Treffens wurde mein Bericht erstellt. Mein Name ist Nail, ich mache Yandex.Connect.

Die Geschichte, die ich vorbereitet habe, handelte von uWSGI. Dies ist ein multifunktionaler Webanwendungsserver, und jede moderne Anwendung wird von Metriken begleitet. Ich habe versucht zu zeigen, wie die Funktionen von uWSGI beim Sammeln von Metriken helfen können.
- Hallo allerseits, ich freue mich, Sie alle an den Wänden von Yandex begrüßen zu dürfen. Es ist schön, dass so viele Leute gekommen sind, um meine und andere Berichte zu sehen, dass so viele Leute interessiert sind und in Python leben. Worum geht es in meinem Bericht? Es heißt "uWSGI zur Unterstützung von Metriken". Ich werde dir ein wenig über mich erzählen. Ich bin seit sechs Jahren mit Python beschäftigt. Ich habe im Yandex.Connect-Team gearbeitet. Wir schreiben eine Geschäftsplattform, die Yandex-Dienste bereitstellt, die intern für Drittbenutzer entwickelt wurden, dh für alle. Jede Person oder Organisation kann die von Yandex entwickelten Produkte für sich selbst für ihre eigenen Zwecke verwenden.
Wir werden über Metriken sprechen, wie man diese Metriken erhält, wie wir in unserem Team uWSGI als Werkzeug verwenden, um Metriken zu erhalten, wie es uns hilft. Dann erzähle ich Ihnen eine kleine Optimierungsgeschichte.
Ein paar Worte zu Metriken. Wie Sie wissen, ist die Entwicklung einer modernen Anwendung ohne Tests nicht möglich. Es ist seltsam, wenn jemand seine Anwendungen ohne Tests entwickelt. Gleichzeitig scheint mir der Betrieb einer modernen Anwendung ohne Metriken nicht möglich zu sein. Unsere Anwendung ist ein lebender Organismus. Eine Person kann einige Metriken wie Druck, Herzfrequenz verwenden. Die Anwendung enthält auch Indikatoren, an denen wir interessiert sind und die wir beobachten möchten. Im Gegensatz zu einer Person, die diese wichtigen Kennzahlen normalerweise verwendet, wenn sie sich schlecht fühlt, können wir sie im Fall einer Anwendung immer verwenden.

Warum nehmen wir Metriken? Wer verwendet übrigens Metriken? Ich hoffe, dass es nach meinem Bericht mehr Hände geben wird und die Leute interessiert sind und anfangen, Metriken zu sammeln. Sie werden verstehen, dass dies notwendig und nützlich ist.
Warum brauchen wir also Metriken? Zunächst sehen wir, was mit dem System passiert, wir heben einige normative Indikatoren für unser System hervor und verstehen, ob wir während des Bewerbungsprozesses über diese Indikatoren hinausgehen oder nicht. Sie können ein abnormales Verhalten des Systems feststellen, z. B. eine Zunahme der Anzahl von Fehlern, verstehen, was mit dem System vor unseren Benutzern nicht stimmt, und Nachrichten über Vorfälle nicht von Benutzern, sondern vom Überwachungssystem erhalten. Basierend auf Metriken können wir Benachrichtigungen einrichten und SMS, Briefe und Anrufe empfangen, wie Sie möchten.

Was sind in der Regel Metriken? Dies sind einige Zahlen, vielleicht ein Zähler, der monoton wächst. Zum Beispiel die Anzahl der Anfragen. Einige Zeitwerte, die sich mit der Zeit ändern, nehmen zu oder ab. Ein Beispiel ist die Anzahl der Aufgaben in einer Warteschlange. Oder Histogramme - Werte, die in bestimmte Intervalle fallen, die sogenannten Körbe. In der Regel ist es zweckmäßig, diese zeitbezogenen Daten zu lesen und herauszufinden, in welches Zeitintervall wie viele Werte passen.

Welche Art von Metriken können wir verwenden? Ich werde mich auf die Entwicklung von Webanwendungen konzentrieren, da diese näher bei mir liegen. Zum Beispiel können wir die Anzahl der Anforderungen, unsere Endpunkte, die Antwortzeit unserer Endpunkte und die Antwortcodes der zugehörigen Dienste erfassen, wenn wir zu ihnen gehen und über eine Microservice-Architektur verfügen. Wenn wir den Cache verwenden, können wir verstehen, wie effizient der Miss- oder Hit-Cache ist, die Verteilung der Antwortzeiten beider Server von Drittanbietern und beispielsweise der Datenbank verstehen. Aber um die Metriken zu sehen, müssen Sie sie irgendwie sammeln.

Wie können wir sie sammeln? Es gibt mehrere Möglichkeiten. Ich möchte Ihnen von der ersten Option erzählen - einem Push-Schema. Woraus besteht es?
Angenommen, wir erhalten eine Anfrage von einem Benutzer. Vor Ort installieren wir mit unserer Anwendung eine Art, normalerweise einen Push-Agenten. Nehmen wir an, wir haben einen Docker, darin befindet sich eine Anwendung, und ein Push-Agent steht immer noch parallel. Der Push-Agent empfängt den Wert von Metriken lokal von uns, puffert sie irgendwie, erstellt Stapel und sendet sie an das Metrikspeichersystem.
Was ist der Vorteil von Push-Schemata? Wir können einige Metriken von der Anwendung direkt an das Metriksystem senden, aber gleichzeitig erhalten wir eine Art Netzwerkinteraktion, Latenz und Overhead, um Metriken zu erfassen. Im Fall eines lokalen Push-Clients wird dies ausgeglichen.
Eine weitere Option ist ein Pull-Schema. Mit dem Pull-Schema haben wir das gleiche Szenario. Eine Anfrage des Benutzers kommt zu uns, wir behalten sie irgendwie zu Hause. Und dann kommt das Metrik-Erfassungssystem mit einer bestimmten Häufigkeit - einmal pro Sekunde, einmal pro Minute, wie es Ihnen passt - zu einem speziellen Endpunkt unserer Anwendung und verwendet diese Indikatoren.

Eine weitere Option sind die Protokolle. Wir alle schreiben Protokolle und schicken sie irgendwohin. Nichts hindert uns daran, diese Protokolle zu übernehmen, sie irgendwie zu verarbeiten und Metriken basierend auf den Protokollen abzurufen.
Zum Beispiel schreiben wir die Tatsache einer Benutzeranforderung in das Protokoll und nehmen dann die Protokolle, Hop-Hop, gezählt. Ein typisches Beispiel ist ELK (Elasticsearch, Logstash, Kibana).

Wie funktioniert das bei uns? Yandex verfügt über eine eigene Infrastruktur und ein eigenes System zur Erfassung von Metriken. Sie erwartet eine standardisierte Antwort für einen Griff, der ein Pull-Schema implementiert. Außerdem haben wir eine interne Cloud, in der wir unsere Anwendung starten. Und das alles in einem einzigen System integriert. Beim Hochladen in die Cloud geben wir einfach an: "Gehen Sie zu diesem Stift und holen Sie sich die Metriken."

Hier ist eine Beispielantwort für das Pull-Schema, das unser Metrik-Erfassungssystem erwartet.
Für uns im Team haben wir uns entschieden, einen für uns geeigneteren Weg zu wählen, um verschiedene Kriterien hervorzuheben, anhand derer wir die beste Option für uns auswählen. Effizienz ist, wie schnell wir im metrischen System eine Anzeige der Tatsache einer Aktion erhalten können. Abhängigkeit - ob wir zusätzliche Tools installieren oder die Infrastruktur irgendwie konfigurieren müssen, um die Metrik zu erhalten. Und Vielseitigkeit - wie diese Methode für verschiedene Arten von Anwendungen geeignet ist.
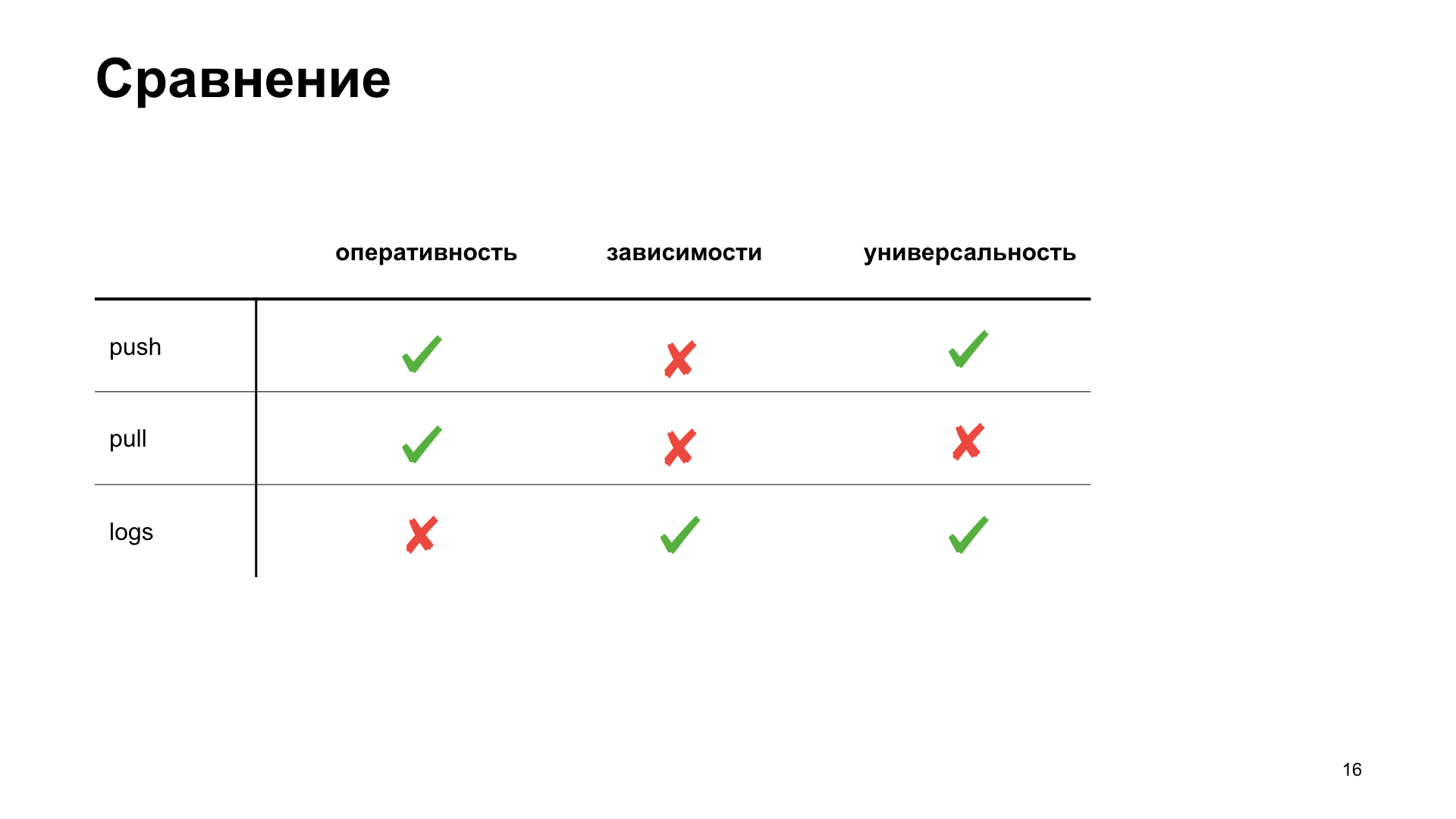
Das haben wir am Ende bekommen. Obwohl nach den Kriterien der Effizienz und Vielseitigkeit das Push-Schema gewinnen wird. Wir entwickeln jedoch eine Webanwendung, und unsere Cloud verfügt bereits über eine vorgefertigte Infrastruktur für die Arbeit mit dieser Aufgabe. Daher haben wir uns für ein Pull-Schema entschieden. Wir werden über sie reden.
Um dem Pull-Schema etwas zu geben, müssen wir es irgendwo voraggregieren und speichern. Unser Überwachungssystem wird alle fünf Sekunden in Zuggriffe eingesetzt. Wo können wir sparen? Lokal in Ihrem Speicher oder in einem Speicher eines Drittanbieters.

Wenn wir lokal speichern, ist dies in der Regel für den Fall mit einem Prozess geeignet. Und wir führen in unserem uWSGI mehrere Prozesse parallel aus. Oder wir können eine Art gemeinsam genutzten Speicher verwenden. Was fällt uns mit dem Wort „Shared Storage“ ein? Dies ist eine Art Redis, Memcached, relationale oder nicht relationale Datenbanken oder sogar eine Datei.

Über uWSGI. Ich möchte Sie an diejenigen erinnern, die es nur selten oder selten verwenden: uWSGI ist ein Anwendungswebserver, mit dem Sie Python-Anwendungen unter Ihnen ausführen können. Es implementiert die Schnittstelle, das uWSGI-Protokoll. Dieses Protokoll ist in PEP 333 beschrieben, die interessiert sind, können Sie lesen.

Es wird uns auch helfen, die beste Yandex.Tank-Lösung auszuwählen. Dies ist ein Lasttest-Tool, mit dem Sie unsere Anwendung mit verschiedenen Lastprofilen schälen und wunderschöne Grafiken erstellen können. Oder es funktioniert in der Konsole, wie Sie möchten.

Die Experimente. Wir werden eine synthetische Anwendung für unsere synthetischen Tests erstellen, wir werden sie mit einem Tank schälen. Die uWSGI-Anwendung hat einen einfachen Konflikt mit 10 Arbeitern.

Hier ist unsere Flask App. Mit der Nutzlast, die unsere Anwendung ausführt, emulieren wir eine leere Schleife.

Wir feuern und Yandex.Tank gibt uns eine dieser Grafiken. Was zeigt er? Perzentile der Antwortzeiten. Die schräge Linie ist der RPS, der wächst, und die Histogramme sind die Perzentile, in die unser Webserver unter einer solchen Last passt.
Wir werden diese Option als Referenz verwenden und untersuchen, wie sich verschiedene Optionen zum Speichern von Metriken auf die Leistung auswirken.

Die einfachste Option ist die Verwendung von PostgreSQL. Da wir mit PostgreSQL arbeiten, haben wir es. Verwenden wir das, was bereits fertig ist.
Angenommen, wir haben eine Bezeichnung in PostgreSQL, in der wir einfach den Zähler erhöhen.

Bereits bei kleinen RPS-Mengen sehen wir einen starken Leistungsabfall. Es kann nur riesig gesagt werden.

Die nächste Option ist Redis. Aber hier machen wir es schlauer: Wir installieren es lokal und gehen nicht über das Netzwerk, sondern über den Unix-Socket dorthin. Erhöhen Sie auch den Zähler.
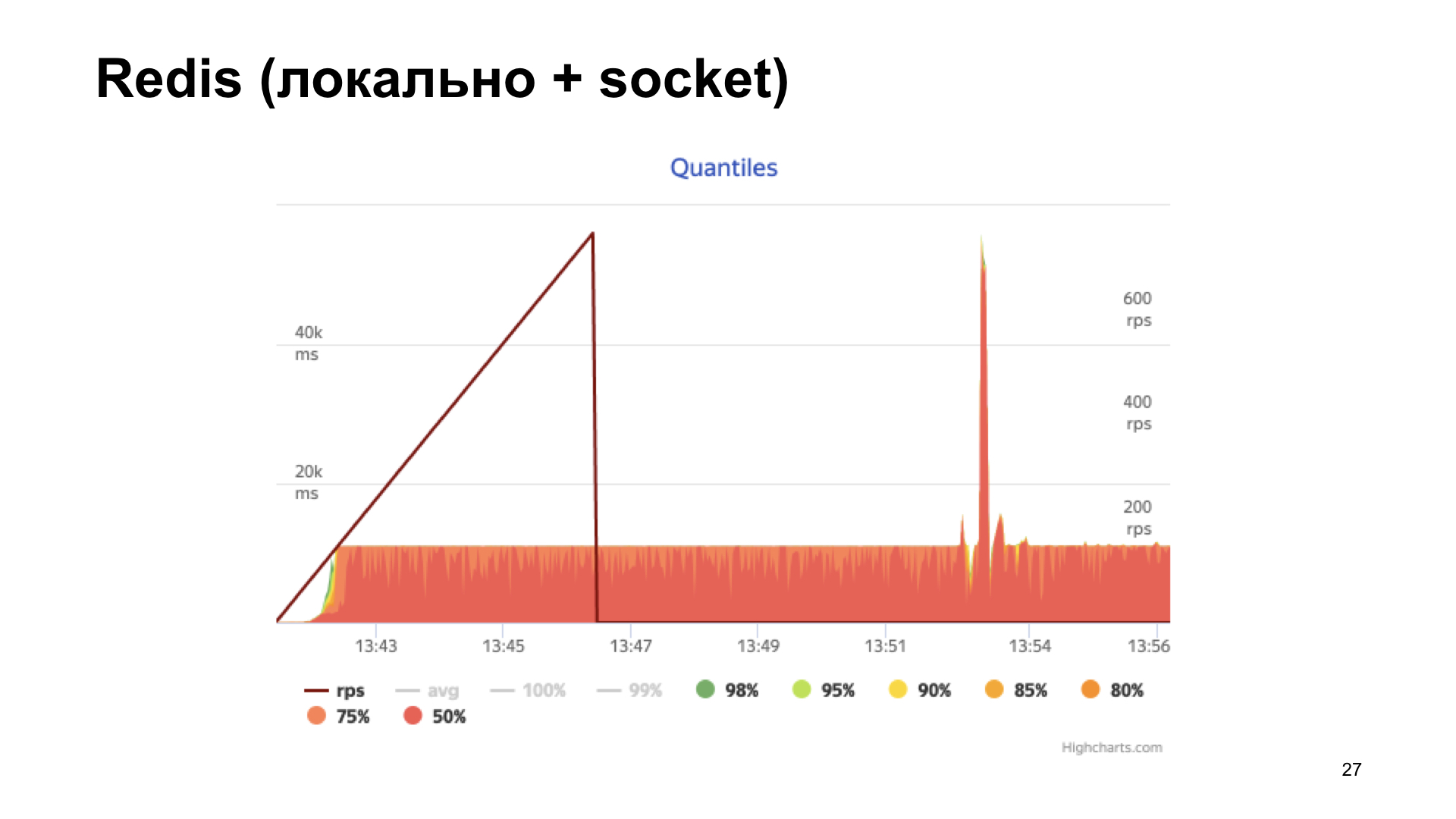
Wir erhalten das Histogramm der Antwortzeiten am Ausgang. Wir sehen, dass die Dinge hier besser sind, aber irgendwann stoßen wir auf ein Regal, und dann wächst die Produktivität nicht mehr. Diese Option scheint optimaler zu sein, aber wir wollen es noch besser machen.

Hier hilft uns uWSGI, ein echter Mähdrescher. Es gibt viele verschiedene Module. Mule zum Ausführen von Unterprozessen, Caching-Framework, Cron, Metrik-Subsystem und Warnsystem. "Subsystem Metrics System" - klingt vielversprechend.

Sie weiß, wie man Metriken hinzufügt, den Zähler erhöht, den Zähler verringert, multipliziert, dividiert - was auch immer Ihr Herz begehrt.
Das einzige Metrik-Subsystem kann nicht genau die darin enthaltenen Metriken angeben.
Warum ist uns das wichtig? Wie Sie bereits gesehen haben, haben wir ein Handle zum Bereitstellen von Statistiken in einem bestimmten Format, und mehrere Mitarbeiter werden ausgeführt. Wir wissen nicht, welcher der Mitarbeiter die Anfrage erhalten wird, aber um alle Metriken zurückzugeben, müssen wir eine Art Namensregister erstellen und sie irgendwie zwischen den Prozessen verschlüsseln. Das ist eine große Sache, ich möchte das vermeiden. Was haben wir noch?

Natürlich Cache-Subsystem. Und hier sehen wir: Er kann fast das Gleiche tun und auch die Namen der im Cache gespeicherten Schlüssel angeben. Das brauchen Sie.

Das Cache-Subsystem ist ein in uWSGI integrierter Cache. Ein schnelles und threadsicheres Modul, bei dem es sich um einen normalen Schlüsselwertspeicher handelt.

Da es sich jedoch um einen Cache handelt, gibt es ein bekanntes zweites Problem: Wie benennt man eine Variable und wie macht man den Cache ungültig? In unserem Fall sehen wir uns die Standard-Cache-Einstellungen an. Die Länge des Schlüssels ist begrenzt. In unserem Fall ist dies der Name der Metrik. Der Standardwert beträgt 2048 Byte. Und Sie können die Konfiguration bei Bedarf erhöhen. Die Anzahl der Elemente, die standardmäßig gespeichert werden, beträgt 65.536. Dieser Wert sollte anscheinend für alle ausreichen. Es ist unwahrscheinlich, dass jemand eine solche Anzahl von Metriken aus seiner Anwendung sammelt.
Und ttl ist standardmäßig 0. Das heißt, die Werte der gespeicherten Caches sind nicht zeitlich ungültig. Wir können sie also aus dem Cache abrufen und an das Metriksystem senden.

Auch hier ist die Option eine Anwendung, die die uWSGI-Box verwendet.
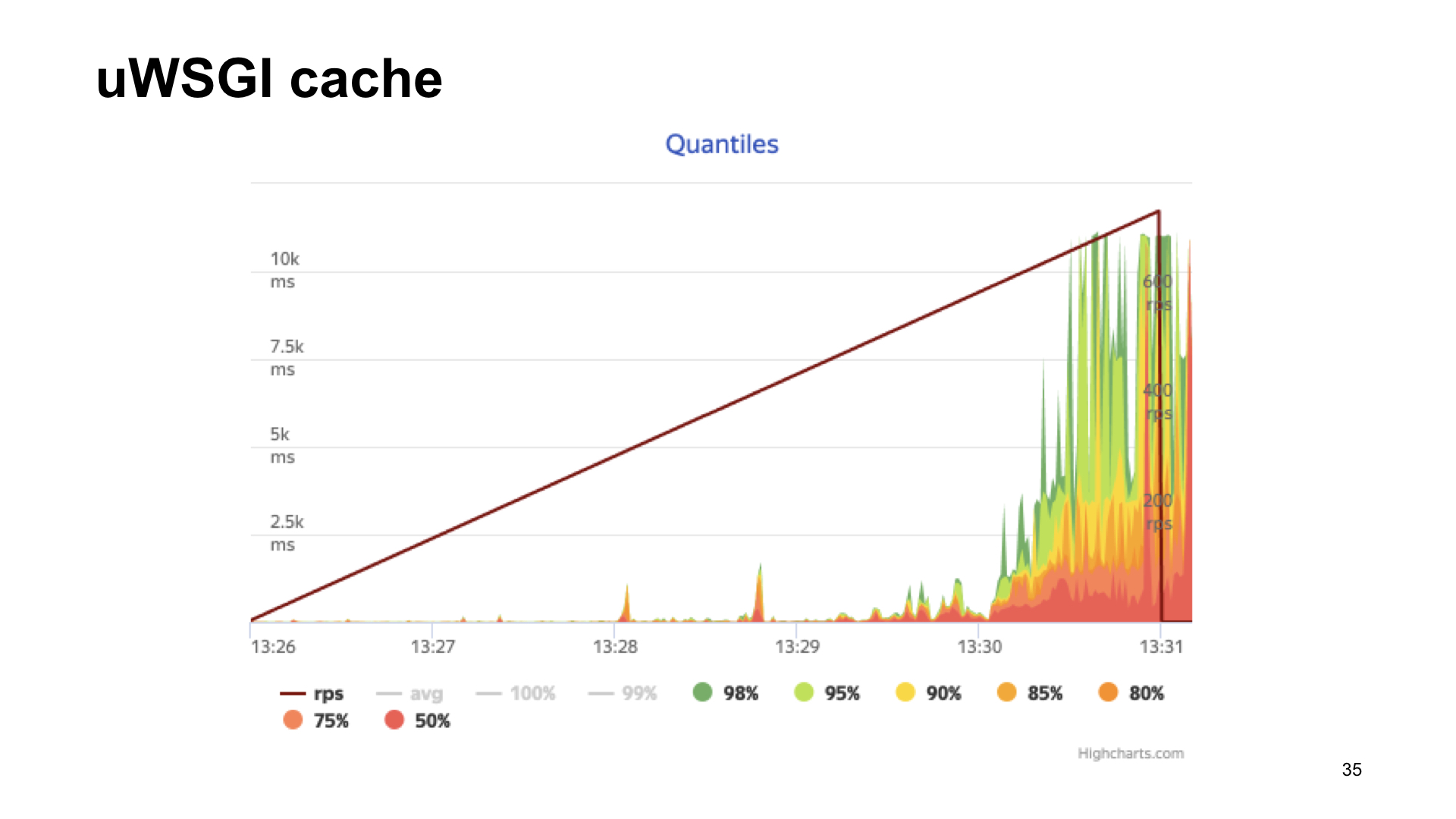
Hier sind die Ergebnisse des Beschusses dieser Anwendung.

Das Ergebnis ohne Metriken, wenn mit uWSGI, mit einer Dehnung sieht es fast gleich aus.
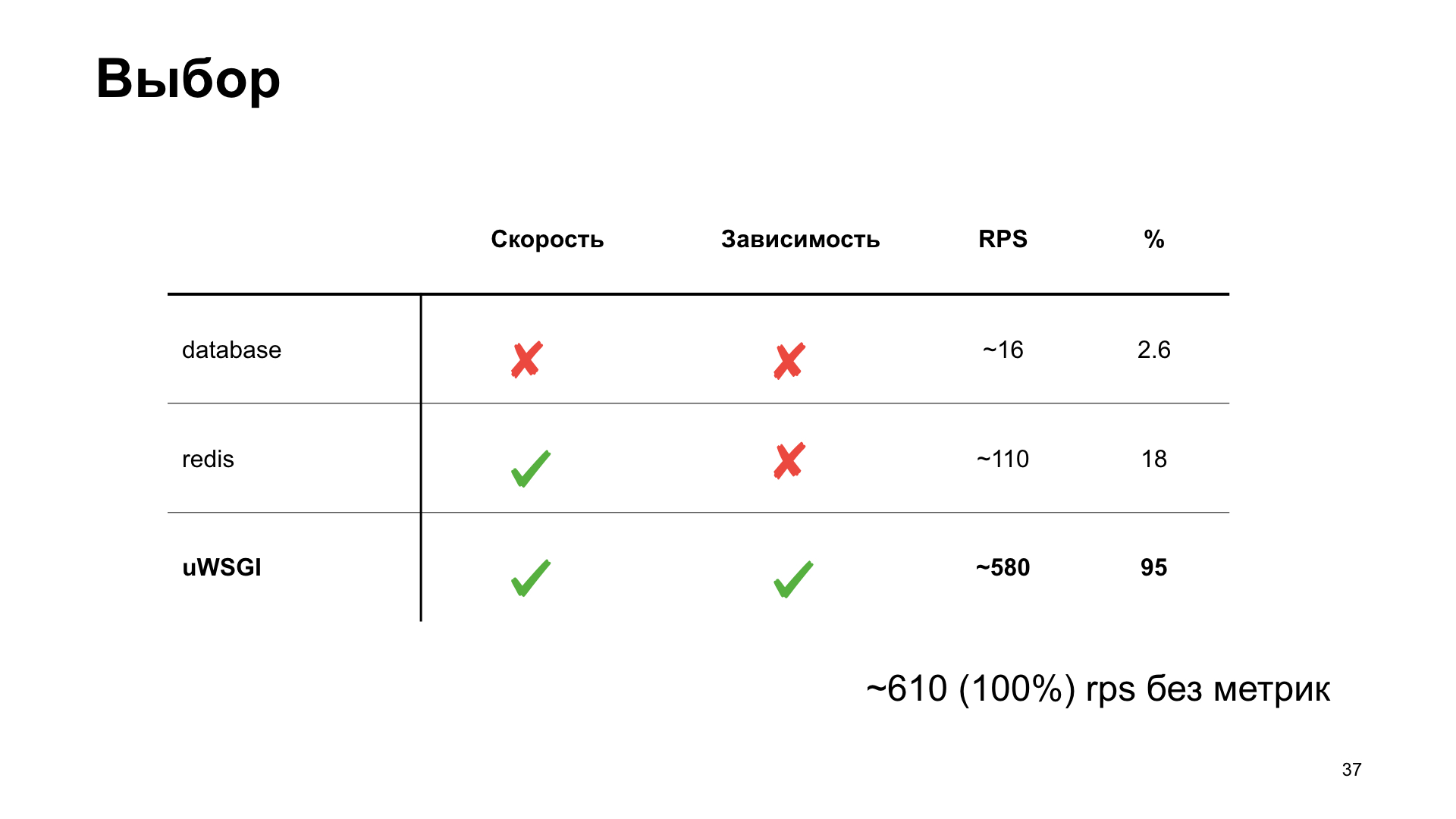
Wie Sie sehen, verlieren wir im Fall von uWSGI nur 5% der Leistung im Vergleich zur "Vanilla" -Version ohne Metriken. Andere Optionen haben einen ziemlich erheblichen Drawdown, und daher gewinnt uWSGI aufgrund der Zuschauerabstimmung.

Wie haben wir das angewendet? Wir haben eine kleine Bibliothek geschrieben, einen Wrapper um uWSGI. Zum Beispiel installieren wir eine Instanz unserer Bibliothek und fügen hier als Beispiel die Metrik „Datenbankabfragezeit“ hinzu.

Wir sind auch daran interessiert zu verfolgen, wie der Cache funktioniert. Wir definieren einfach die Methoden des Client-Memca neu, sparen Zeit für den Empfang von Daten, Zeit für das Herunterladen und die Anzahl der Cache-Treffer und Cache-Miss.

Wie machen wir das in der Bibliothek? Um die Werte zu versenden, erhalten wir die Namen der im Cache gespeicherten Schlüssel, durchlaufen sie und geben sie einfach im gewünschten Format an den Endpunkt weiter.
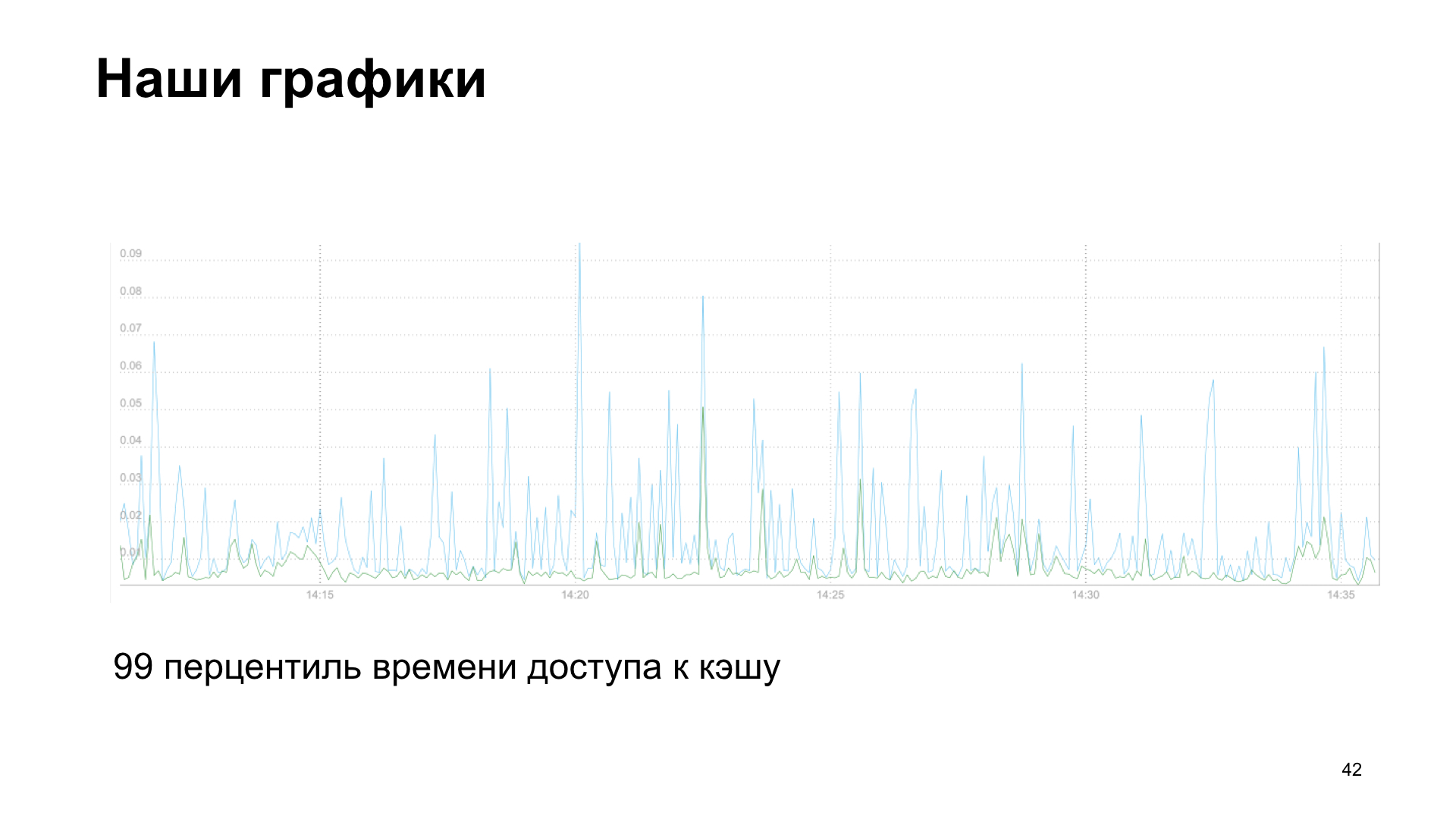
Als Ergebnis erhalten wir ein Diagramm. In diesem Fall ist es das 99. Perzentil der Cache-Zugriffszeit beim Lesen und Schreiben.

Oder optional die Anzahl der Serviceanfragen von Drittanbietern an unsere API.

Wir haben Geschichten über Misserfolg und Erfolg. Wir fügten immer mehr Metriken hinzu und sahen einen Leistungsabfall. Die Metriken selbst haben uns geholfen. Wenn Sie Metriken erfassen, können Sie feststellen, dass etwas nicht stimmt. Daher empfehle ich Ihnen auch, die Kennzahlen, die Sie in den Wochen, Monaten und sechs Monaten gesammelt haben, nachträglich zu betrachten. Und sehen Sie, welchen Trend Ihre Anwendung in welchen Indikatoren zeigt. Wir stellten fest, dass wir uns auf die Berechnung von Metriken stützten.

Profiling hat uns geholfen. Hier sehen Sie einen Flammengraphen, der uns visuell zeigt, wie viele Aufrufe verschiedener Funktionen während des Prozesses ausgeführt wurden, wobei die Aufrufe den größten zeitlichen Beitrag geleistet haben. Wir haben festgestellt, dass wir in der ersten Version mit Pickle nicht sehr gut abschneiden. In unserer Bibliothek verbrachte sie viel Zeit mit Beizen.

Wir lehnten das Beizen ab, übergaben es an cashe inc, maßen alles, es wurde schneller.

In der neuen Implementierung arbeiten wir die meiste Zeit mit dem Cache und nicht mit dem Beizen.

Warum erzähle ich dir das? Ich fordere Sie dringend auf, Metriken zu sammeln, Metriken zu beobachten und sich auf Metriken zu konzentrieren. Vergleichen Sie bei der Auswahl einer möglichen Option zur Erfassung von Metriken die Optionen, um herauszufinden, welche für Sie am besten geeignet ist. Und natürlich ist die Profilerstellung gut. Wenn Sie sehen, dass etwas nicht stimmt, verlangsamt sich etwas - Profil.
Danke an alle! Wie ich versprochen habe, Referenzen: