Wir haben vor einem Jahr darüber nachgedacht, die Infrastruktur für Tests mit großer Last aufzubauen, als wir die Marke von 12.000 Online-Benutzern erreichten, die gleichzeitig in
unserem Service arbeiten. Für 3 Monate haben wir die erste Version des Tests gemacht, die die Grenzen des Dienstes zeigte.
Die Ironie des Schicksals ist, dass wir zur gleichen Zeit, als der Test gestartet wurde, die Grenzen des Produkts erreichten, wodurch der Service um 2 Stunden sank. Dies ermutigte uns außerdem, von der Durchführung von Tests von Fall zu Fall zur Schaffung einer effektiven tragenden Infrastruktur überzugehen. Mit Infrastruktur meine ich alle Tools für die Arbeit mit der Last: Tools zum Starten und Autostarten, ein Cluster zum Laden der Last, ein Cluster, ein ähnliches Produkt, Services zum Sammeln von Metriken und zum Erstellen von Berichten, Code zum Verwalten all dieser und Services zum Skalieren.
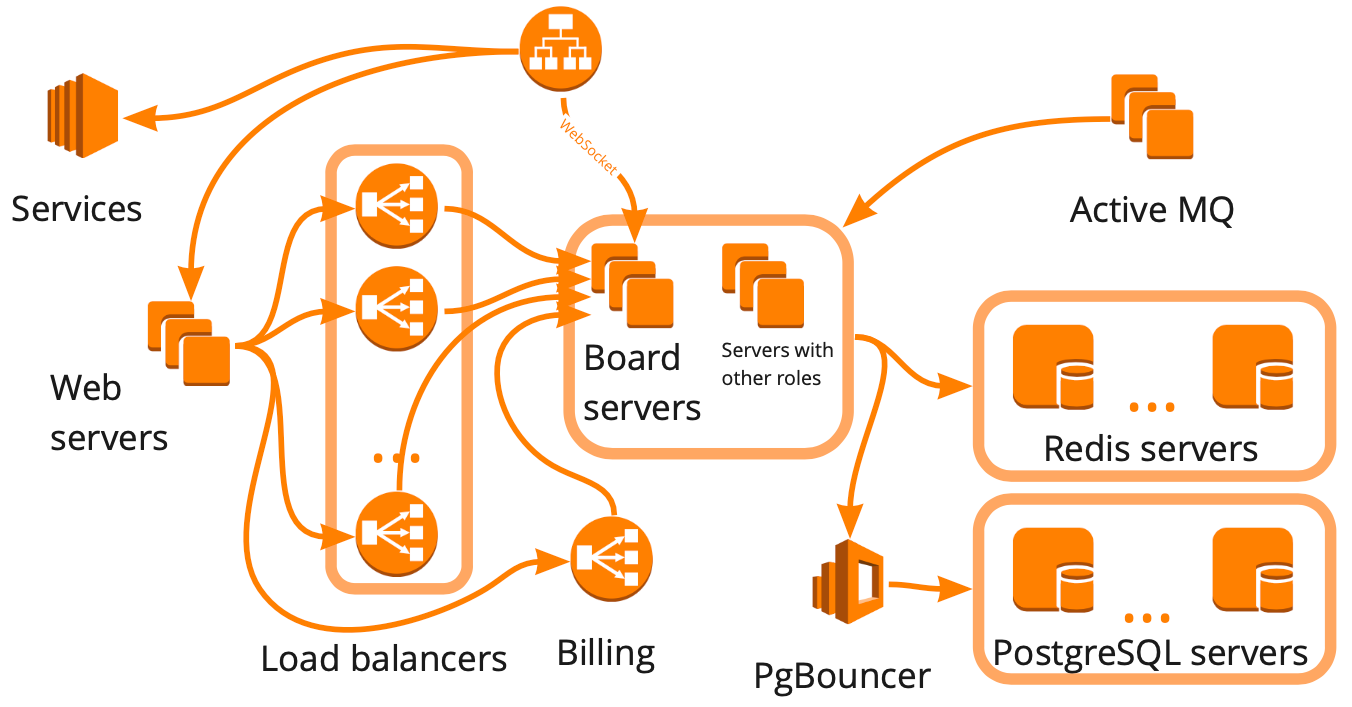
So vereinfacht sieht das miro.com-Schema aus: Es gibt viele verschiedene Server, die irgendwie miteinander interagieren, und jeder führt bestimmte Aufgaben aus. Es scheint, dass es für den Aufbau der Infrastruktur für Auslastungstests ausreichte, ein solches Schema zu zeichnen, alle Beziehungen zu berücksichtigen und jeden Block nacheinander mit Skripten abzudecken. Dieser Ansatz ist gut, aber es würde viele Monate dauern, was für uns aufgrund des schnellen Wachstums nicht geeignet war. In den letzten sechs Monaten sind wir von 12.000 auf 20.000 Online-Benutzer gewachsen, die gleichzeitig im Dienst arbeiten. Darüber hinaus wussten wir nicht, wie die Infrastruktur unseres Dienstes auf eine Zunahme der Last reagieren wird: Welcher der Blöcke wird zu einem Engpass und welcher kann linear skaliert werden.
Aus diesem Grund haben wir uns entschlossen, den Service mit virtuellen Benutzern zu testen und ihre realistische Arbeit zu simulieren, dh einen Produktionsklon zu erstellen und einen großen Test durchzuführen.
- Laden Sie einen Cluster, dessen Struktur mit der Produktion identisch ist, dessen Leistung jedoch voraus ist.
- Geben Sie uns alle Daten, um Entscheidungen zu treffen.
- wird zeigen, dass die gesamte Infrastruktur der richtigen Last standhalten kann;
- wird die Grundlage für Stresstests sein, die wir möglicherweise in Zukunft benötigen.
Das einzige Minus eines solchen Tests ist sein Selbstkostenpreis, denn dafür brauchen wir eine Umgebung, die größer ist als die Produktionsumgebung.
In diesem Artikel werde ich Ihnen erklären, wie Sie ein realistisches Szenario erstellen, Plugins - WS, Stress-Client, Stier, - Cluster laden, Cluster verkaufen und Beispiele für die Verwendung von Tests zeigen.
Der nächste Artikel befasst sich mit der Verwaltung von Hunderten von Servern für einen Auslastungstest.
Erstellen Sie ein realistisches Szenario
Um ein realistisches Szenario zu erstellen, benötigen wir:
- Analysieren Sie die Arbeit der Benutzer am Produkt und bestimmen Sie dazu die für uns wichtigen Metriken, sammeln Sie sie regelmäßig und analysieren Sie die Sprünge.
- Erstellen Sie bequeme benutzerdefinierte Blöcke, mit denen wir den erforderlichen Teil der Geschäftslogik effizient laden können.
- Überprüfen Sie den Skriptrealismus mit Servermetriken.
Nun mehr zu jedem Artikel.
Analyse der Benutzerarbeit an prodIn unserem Service können Benutzer Boards erstellen und mit verschiedenen Inhalten daran arbeiten: Fotos, Texte, Mocapas, Aufkleber, Diagramme usw. Die erste Metrik, die wir sammeln müssen, ist die Anzahl der Boards und die Verteilung der Inhalte darauf.
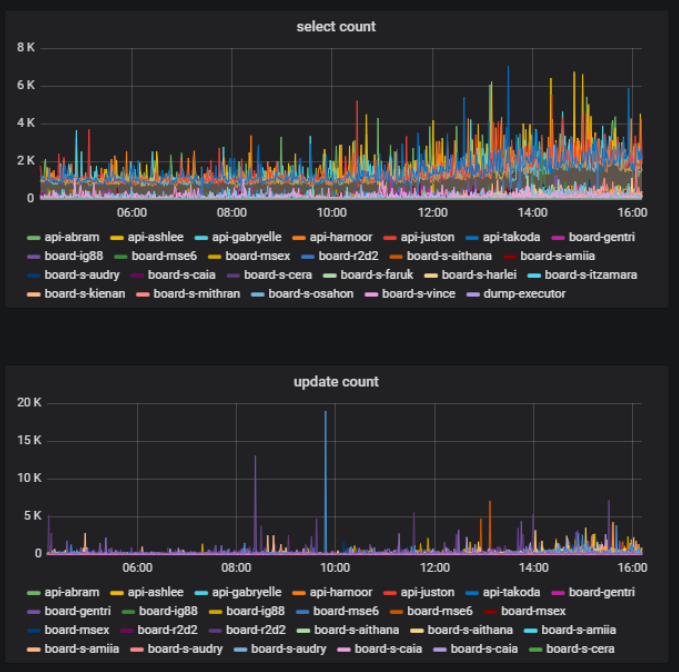
Auf demselben Board können einige Benutzer zum gleichen Zeitpunkt aktiv etwas tun - erstellen, löschen, bearbeiten - und andere können einfach das erstellte Material anzeigen. Dies ist auch eine wichtige Messgröße - das Verhältnis der Anzahl der Benutzer, die den Inhalt des Boards ändern, zur Gesamtzahl der Benutzer eines Boards. Dies können wir auf der Grundlage von Statistiken über die Arbeit mit der Datenbank erhalten.
In unserem Backend verwenden wir den Komponentenansatz. Komponenten, die wir Modelle nennen. Wir teilen unseren Code in Modelle auf, sodass für jeden Teil der Geschäftslogik ein bestimmtes Modell verantwortlich ist. Wir können die Anzahl der Datenbankaufrufe berechnen, die in jedem Modell auftreten, und verstehen, welcher Teil der Logik die Datenbank am meisten lädt.
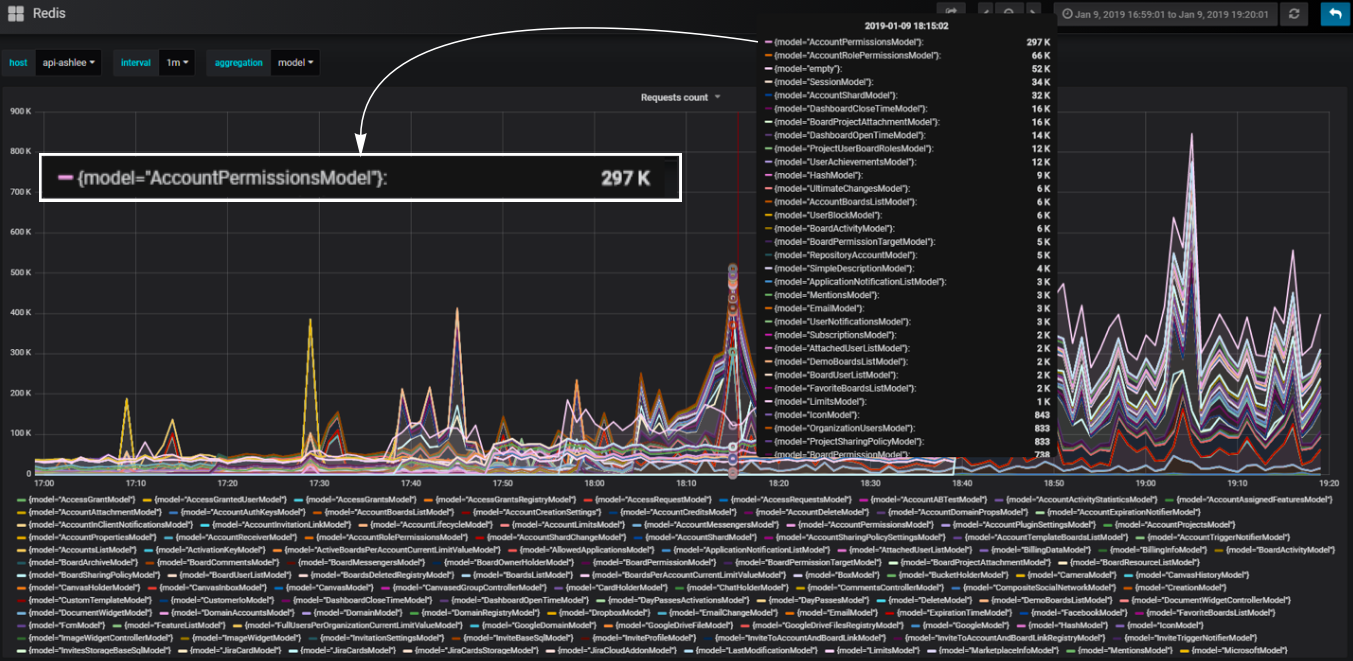 Praktische benutzerdefinierte Blöcke
Praktische benutzerdefinierte BlöckeZum Beispiel müssen wir dem Skript einen Block hinzufügen, der unseren Service genauso lädt, wie es passiert, wenn Sie eine Dashboard-Seite mit einer Liste von Benutzer-Boards öffnen. Während des Ladens dieser Seite werden http-Anfragen mit einer großen Datenmenge gesendet: die Anzahl der Boards, die Konten, auf die der Benutzer Zugriff hat, alle Benutzer des Kontos usw.

Wie lade ich ein Dashboard effektiv? Bei der Analyse des Produktionsverhaltens wurden beim Öffnen des Dashboards eines großen Kontos Lastspitzen in der Datenbank festgestellt. Wir können ein identisches Konto neu erstellen und die Intensität der Verwendung seiner Daten im Skript ändern, wodurch ein Dashboard mit einer geringen Anzahl von Treffern effektiv geladen wird. Wir können auch eine ungleichmäßige Last für mehr Realismus schaffen.
Gleichzeitig ist es uns wichtig, dass die Anzahl der virtuellen Benutzer und die von ihnen erzeugte Last den Benutzern und der Produktionslast so ähnlich wie möglich sind. Zu diesem Zweck erstellen wir im Test auch die Hintergrundlast des durchschnittlichen Dashboards neu. Daher arbeiten die meisten virtuellen Benutzer mit kleinen durchschnittlichen Dashboards, und nur wenige Benutzer verursachen eine katastrophale Last, wie dies in der Produktion der Fall ist.
Anfangs wollten wir nicht jede Serverrolle und jede Beziehung mit einem separaten Skript behandeln. Dies ist im Beispiel mit dem Dashboard zu sehen - wir wiederholen einfach während des Tests, was passiert, wenn das Dashboard auf dem Produkt geöffnet wird, wenn der Benutzer es öffnet, und wir behandeln nicht, was es mit synthetischen Skripten beeinflusst. Auf diese Weise können Sie standardmäßig Nuancen testen, die wir nicht einmal erwartet haben. Daher nähern wir uns der Erstellung eines Infrastrukturtests von der Seite der Geschäftslogik.
Wir haben diese Logik verwendet, um alle anderen Blöcke des Dienstes effektiv zu laden. Gleichzeitig ist jeder einzelne Block unter dem Gesichtspunkt der Logik der Verwendung der Funktion möglicherweise nicht realistisch. Es ist wichtig, dass die Server realistisch belastet werden. Und dann können wir aus diesen Blöcken ein Skript erstellen, das die eigentliche Arbeit der Benutzer imitiert.

Daten sind Teil des Skripts.
Beachten Sie, dass Daten auch Teil des Skripts sind und die Logik des Codes selbst stark von den Daten abhängt. Wenn Sie eine große Datenbank für den Test erstellen - und diese sollte natürlich für einen großen Infrastrukturtest groß sein -, müssen Sie lernen, wie Sie Daten erstellen, die während der Ausführung des Skripts keine Rolle spielen. Wenn Sie Junk-Daten sammeln, kann sich das Skript als unrealistisch herausstellen, und eine große Datenbank ist schwer zu reparieren. Aus diesem Grund haben wir begonnen, die Rest-API zu verwenden, um Daten auf die gleiche Weise wie unsere Benutzer zu erstellen.
Um beispielsweise Karten mit den verfügbaren Daten zu erstellen, führen wir API-Anforderungen aus, um Karten aus der Sicherung zu laden. Als Ergebnis erhalten wir ehrliche reale Daten - verschiedene Boards unterschiedlicher Größe. Gleichzeitig wird die Datenbank ziemlich schnell gefüllt, da wir Anforderungen im Skript multithreaded abrufen. In der Geschwindigkeit ist dies vergleichbar mit der Erzeugung von Mülldaten.
Ergebnisse für diesen Teil
- Verwenden Sie realistische Szenarien, wenn Sie alles auf einmal überprüfen möchten.
- Analysieren Sie das tatsächliche Benutzerverhalten, um die Skriptstruktur zu entwerfen.
- Erstellen Sie sofort praktische Blöcke zur Anpassung.
- Konfigurieren Sie anhand realer Servermetriken und nicht anhand von Nutzungsanalysen.
- Denken Sie daran, dass Daten Teil des Skripts sind.
Cluster laden
Schema der Werkzeuge zum Aufbringen der Last:
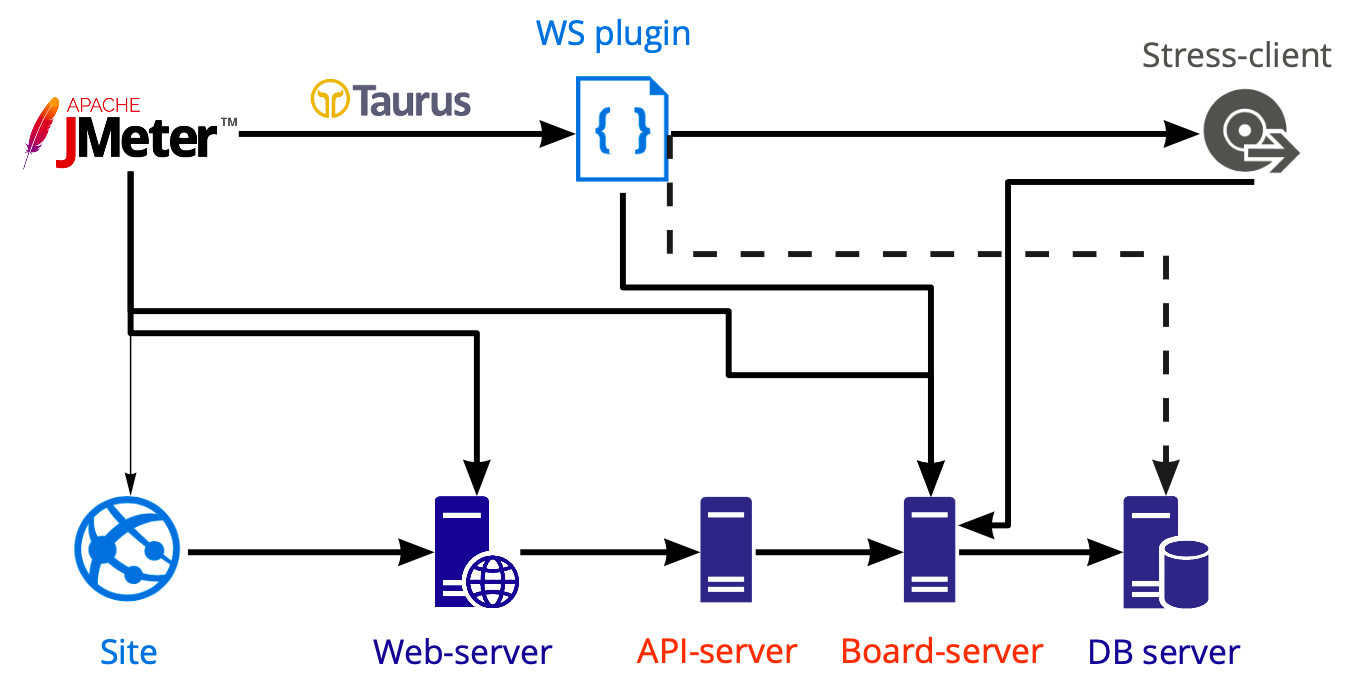
In Jmeter erstellen wir ein Skript, das wir mit Taurus starten und damit verschiedene Server laden: Web-, API- und Board-Server. Wir führen Datenbanktests separat mit Postgresql und nicht mit Jmeter durch, daher zeigt das Diagramm eine gestrichelte Linie.
Benutzerdefinierte Arbeit in Web-Socket
Die Arbeit an der Karte erfolgt innerhalb der WS-Verbindung, und an der Karte ist Mehrbenutzerarbeit möglich. In der Jmeter-Box im Plug-In-Manager befinden sich jetzt mehrere Plug-Ins für die Arbeit mit dem Web-Socket. Die Logik ist überall gleich - Plugins öffnen einfach eine Web-Socket-Verbindung, aber alle Aktionen, die darin ausgeführt werden, müssen Sie auf jeden Fall selbst schreiben. Warum? Da wir nicht wie bei http-Anfragen arbeiten können, können wir kein Skript schreiben, dynamische Werte mit Extraktoren abrufen und weiter überspringen.
Die Arbeit innerhalb des Web-Sockets ist normalerweise sehr benutzerdefiniert: Sie rufen bestimmte Methoden mit bestimmten benutzerdefinierten Daten auf und müssen dementsprechend selbst verstehen, ob die Anforderung korrekt ausgeführt wurde und wie lange die Ausführung gedauert hat. Der Listener in diesem Plugin ist ebenfalls unabhängig geschrieben, wir haben keine gute vorgefertigte Lösung gefunden.
Stress-Klient
Wir möchten so einfach wie möglich wiederholen, was echte Benutzer tun. Wir wissen jedoch nicht, wie wir aufzeichnen und wiedergeben sollen, was im Browser in WS geschieht. Wenn wir alles in WS von Grund auf neu schreiben, erhalten wir einen neuen Client und nicht den, den echte Benutzer verwenden. Ich habe keine Lust, einen neuen Kunden zu schreiben, wenn wir bereits einen haben.
Aus diesem Grund haben wir uns entschlossen, unseren Kunden in Jmeter zu platzieren. Und mit einer Reihe von Schwierigkeiten konfrontiert. Zum Beispiel ist das Ausführen von js in Jmeter eine separate Geschichte Dies ist eine absolut
spezifische Version der unterstützten Funktionen. Und wenn Sie Ihren vorhandenen Client-Code verwenden möchten, werden Sie höchstwahrscheinlich keinen Erfolg haben, da Konstruktionen mit neuen Reißzähnen hier nicht gestartet werden können. Sie müssen neu geschrieben werden.
Die zweite Schwierigkeit besteht darin, dass wir nicht den gesamten Client-Code für Auslastungstests unterstützen möchten. Daher haben wir alles Überflüssige vom Client entfernt und nur die Client-Server-Interaktion belassen. Dies ermöglichte es uns, Client-Server-Methoden zu verwenden und alles zu tun, was unser Client tun kann. Das Plus ist, dass sich die Client-Server-Interaktion äußerst selten ändert, was bedeutet, dass Codeunterstützung innerhalb des Skripts selten erforderlich ist. Zum Beispiel habe ich in den letzten sechs Monaten nie Änderungen am Code vorgenommen, weil er großartig funktioniert.
Die dritte Schwierigkeit - das Erscheinen großer Skripte erschwert das Skript erheblich. Erstens kann es zu einem Engpass im Test werden. Zweitens werden wir höchstwahrscheinlich nicht in der Lage sein, eine große Anzahl von Threads von einer Maschine aus zu starten. Jetzt können wir nur noch 730 Threads starten.
Unser Beispiel für eine Amazon-Instanz Jmeter server AWS: m5.large ($0.06 per Hour) vCPU: 2 Mem (GiB): 8 Dedicated EBS Bandwidth (Mbps): Up to 3,500 Network Performance (Gbps): Up to 10 → ~730
Wo man Hunderte von Servern bekommt und wie man spart
Als nächstes stellt sich die Frage: 730 Threads von einer Maschine, aber wir wollen 50K. Wo kann man so viele Server anheben? Wir erstellen eine Cloud-Lösung, daher erscheint es seltsam, Server zum Testen einer Cloud-Lösung zu kaufen. Außerdem ist es beim Kauf von neuem Eisen immer eine gewisse Langsamkeit. Daher müssen wir sie auch in der Cloud erhöhen, sodass wir uns letztendlich zwischen Cloud-Anbietern und Cloud-Load-Tools entschieden haben.
Wir haben keine Cloud-Load-Tools wie Blazemeter und RedLine13 verwendet, da sie Nutzungsbeschränkungen haben, die nicht zu uns passen. Wir haben verschiedene Teststandorte, daher wollten wir eine universelle Lösung finden, mit der 90% der Entwicklungen verwendet werden können, auch in lokalen Tests.
Aus diesem Grund haben wir uns zwischen Cloud-Anbietern entschieden.
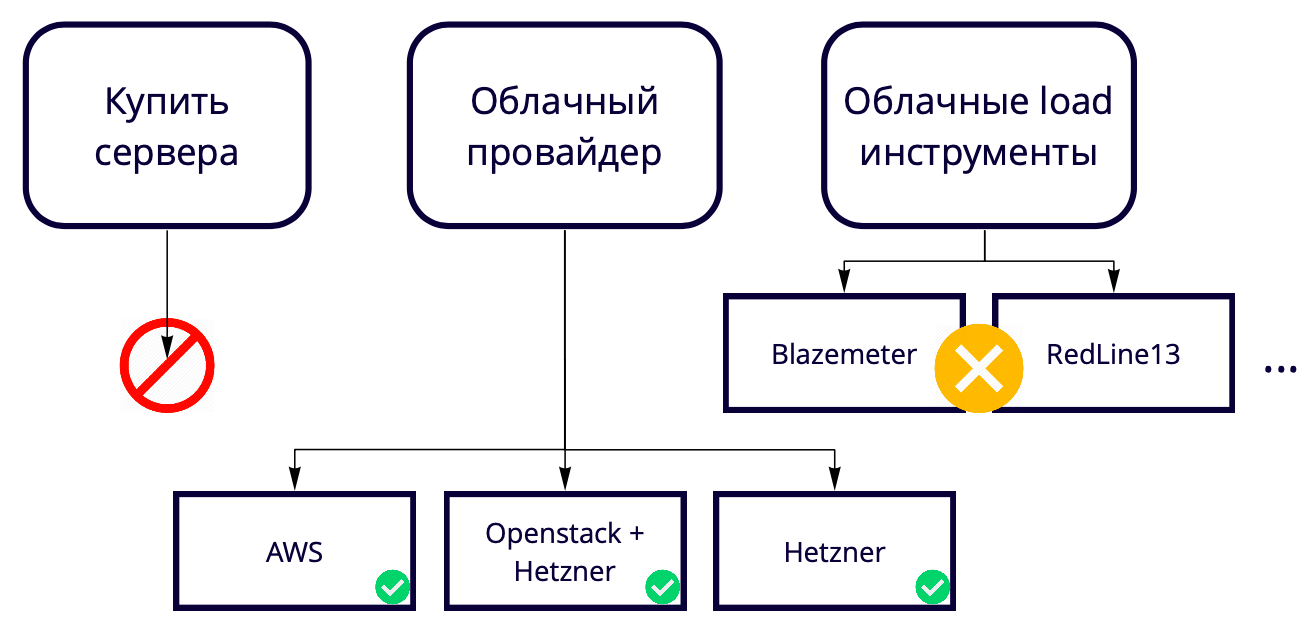
Unsere Produktion erfolgt auf AWS, daher testen wir hauptsächlich dort und möchten, dass der Prüfstand der Produktion so ähnlich wie möglich ist. Amazon verfügt über viele kostenpflichtige Funktionen, von denen einige im Produkt verwendet werden, z. B. Balancer. Wenn diese Funktionen in AWS nicht benötigt werden, können Sie sie in Hetzner 17-mal günstiger verwenden. Oder Sie können den Server in Hetzner behalten, Openstack verwenden und Balancer und andere Funktionen selbst schreiben, da Sie mit Openstack die gesamte Infrastruktur wiederholen können. Wir haben es geschafft.
Das Testen von 50.000 Benutzern mit 69 Instanzen in AWS kostet uns ungefähr 3.000 USD pro Monat. Wie speichere ich? Beispielsweise verfügt AWS über temporäre Instanzen - Spot-Instanzen. Ihre Coolness ist, dass wir sie nicht ständig behalten, sondern nur für die Dauer der Tests erhöhen und sie viel weniger kosten. Die Nuance ist, dass jemand anderes sie zum Zeitpunkt unseres Tests zu einem höheren Preis kaufen kann. Glücklicherweise ist dies noch nie passiert, aber wir sparen bereits mindestens 60% der Kosten auf ihre Kosten.
Cluster laden
Wir verwenden das Jmeter-Box-Cluster. Es funktioniert großartig, es muss in keiner Weise modifiziert werden. Es gibt mehrere Startoptionen. Wir verwenden die einfachste Methode, wenn ein Assistent N Instanzen startet, von denen es möglicherweise Hunderte gibt.
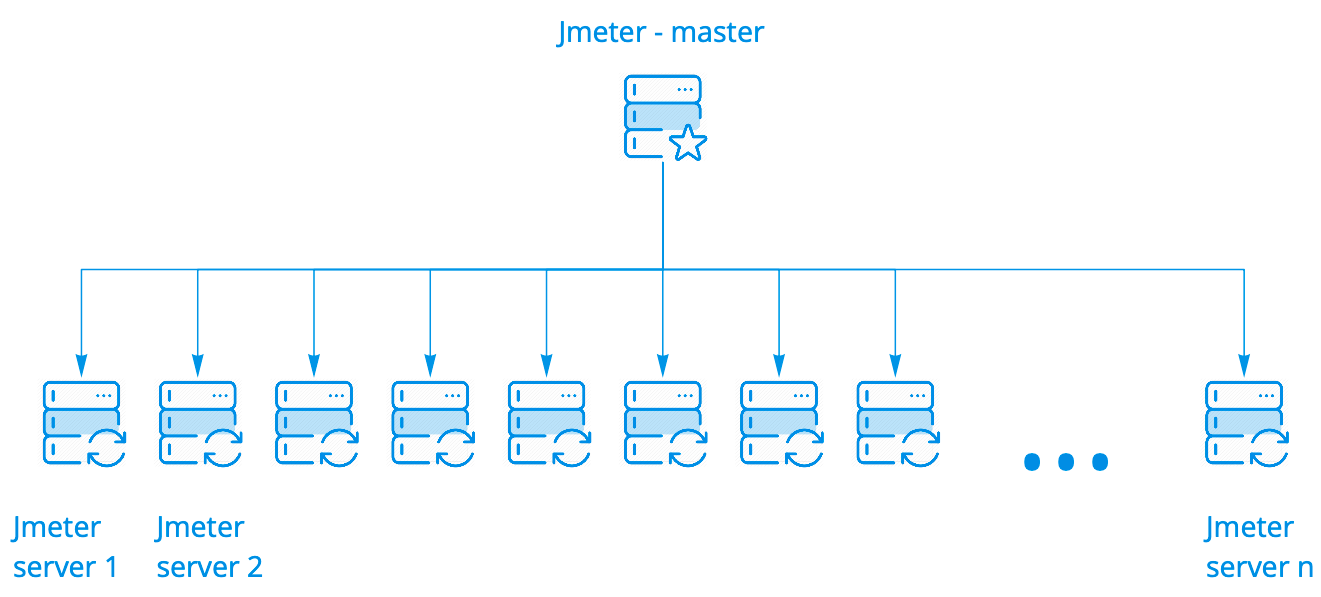
Der Assistent führt das Skript auf Jmeter-Servern aus, während er mit ihnen in Kontakt bleibt, sammelt allgemeine Statistiken aller Instanzen in Echtzeit und zeigt sie in der Konsole an. All dies sieht genauso aus wie das Ausführen des Skripts auf einem Server, obwohl wir die Ergebnisse des Starts auf hundert Servern sehen.
Für eine detaillierte Analyse der Ergebnisse der Skriptausführung in allen Instanzen verwenden wir Kibana. Parsim-Protokolle mit Filebeat.

Ein Prometheus Listener für Apache JMeter
Jmeter verfügt über ein
Plugin für die Arbeit mit Prometheus , das sofort alle Statistiken zur Verwendung von JVM und Threads im Test enthält. Auf diese Weise können Sie sehen, wie oft sich Benutzer anmelden, abmelden usw. Das Plugin kann angepasst werden, um Daten des Skripts an Prometheus zu senden und sie in Echtzeit in Grafana anzuzeigen.
Stier
Wir möchten eine Reihe aktueller Probleme mit Taurus lösen, haben uns aber noch nicht damit befasst:
- Konfigurationen anstelle von Skriptklonen. Wenn Sie auf Jmeter getestet haben, mussten Sie wahrscheinlich Skripte mit verschiedenen Sätzen von Quellparametern ausführen, für die Sie deren Klone erstellen mussten. In Taurus ist es möglich, ein Szenario zu haben und mithilfe von Konfigurationen die Startparameter zu steuern.
- Konfigurationen zum Verwalten von Jmeter-Servern bei der Arbeit mit einem Cluster;
- Ein Online-Ergebnisanalysator, mit dem Sie Ergebnisse getrennt von Jmeter-Threads erfassen und das Skript selbst nicht belasten können.
- Bequeme Integration mit CI;
- Die Fähigkeit, ein verteiltes System zu testen.
Die Ergebnisse dieses Teils
- Wenn wir den Code in Jmeter verwenden, ist es besser, sofort über seine Leistung nachzudenken, da wir sonst Jmeter testen können, nicht unser Produkt.
- Das Jmeter-Cluster ist eine wunderbare Sache: Es ist einfach zu konfigurieren, die Überwachung lässt sich leicht daran anschließen.
- Ein großer Cluster kann vor Ort gehalten werden, es ist viel billiger;
- Seien Sie vorsichtig mit Listenern im Jmeter, damit das Skript die Arbeit auf einer großen Anzahl von Servern nicht verlangsamt.
Beispiele für die Verwendung von Infrastrukturtests
In der gesamten obigen Geschichte geht es hauptsächlich darum, ein realistisches Szenario für einen Service-Limit-Test zu erstellen. Die folgenden Beispiele zeigen, wie Sie die Infrastruktur von Auslastungstests wiederverwenden können, um lokale Probleme zu lösen. Ich werde im Detail über zwei Tests sprechen, aber im Allgemeinen führen wir regelmäßig etwa 10 Arten von Belastungstests durch.
Datenbanktests
Was können wir Test in die Datenbank laden? Schwere Abfragen sind unwahrscheinlich, da wir sie im Single-Thread-Modus testen können, wenn wir uns nur die Abfragepläne ansehen.
Eine interessante Situation ist, wenn wir den Test ausführen und die Last auf der Festplatte sehen. Die Grafik zeigt, wie iowait steigt.
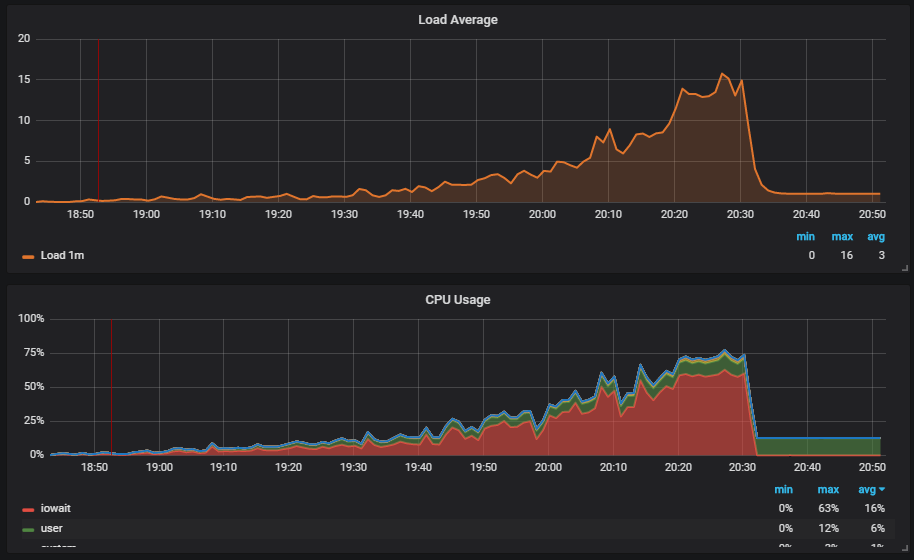
Weiter sehen wir, dass dies Benutzer betrifft.
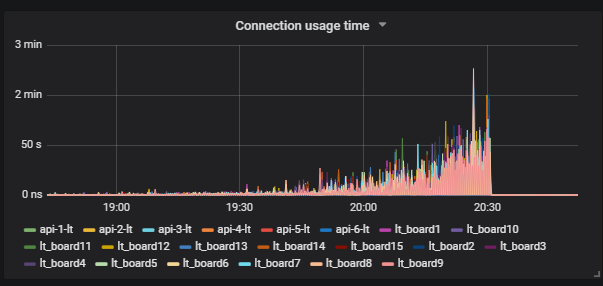
Wir verstehen den Grund: Vakuum hat nicht funktioniert und keine Mülldaten aus der Datenbank gelöscht. Wenn Sie noch nicht mit Postgresql gearbeitet haben, ist Vacuum genau wie der Garbage Collector in Java.

Weiter sehen wir, dass
Checkpoint anfing, außerhalb des Zeitplans zu arbeiten. Für uns ist dies ein Signal dafür, dass Postgresql-Konfigurationen nicht der Intensität der Arbeit mit der Datenbank entsprechen.
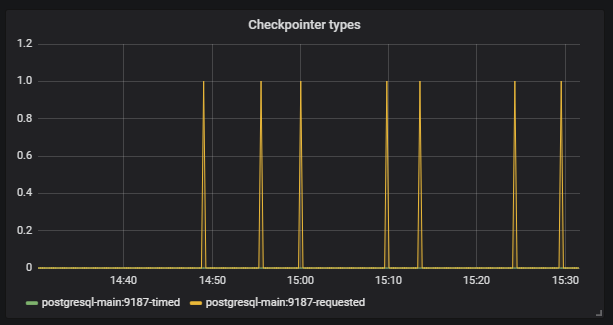
Unsere Aufgabe ist es, die Datenbank richtig zu konfigurieren, damit solche Situationen nicht erneut auftreten. Das gleiche Postgresql hat viele Einstellungen. Für die Feinabstimmung müssen Sie in kurzen Iterationen arbeiten: Die Konfiguration korrigiert, gestartet, überprüft, die Konfiguration korrigiert, gestartet, überprüft. Dazu müssen Sie natürlich eine gute Last auf die Basis aufbringen, aber dafür benötigen Sie nur große Infrastrukturtests.
Die Besonderheit ist, dass das Übertakten langwierig sein sollte, damit der Test normal beschleunigt und nicht dorthin fällt, wo er nicht benötigt wird. Der Test dauert ungefähr drei Stunden, und dies sieht nicht mehr nach kurzen Iterationen aus.
Wir suchen nach einer Lösung. Wir finden eines der Postgresql-Tools -
Pg_replay . Er kann mehrere Threads genau reproduzieren, was in den Protokollen geschrieben ist und genau so, wie es zum Zeitpunkt ihrer Aufzeichnung geschehen ist. Wie können wir es effektiv nutzen? Wir reduzieren den Datenbankspeicherauszug, protokollieren dann alles, was nach dem Speichern in den Protokollen mit der Datenbank passiert, und haben dann die Möglichkeit, den Speicherauszug bereitzustellen und alles abzuspielen, was mit dem Multithread-Datenbankprogramm passiert ist.
Wo schreibe ich Protokolle? Eine beliebte Lösung zum Aufzeichnen von Protokollen besteht darin, sie auf dem Produkt zu sammeln, da dies das realistischste reproduzierbare Skript ergibt. Es gibt jedoch eine Reihe von Problemen:
- Für den Test müssen Sie die Verkaufsdaten verwenden, was nicht immer möglich ist.
- Der Prozess verwendet eine teure Syslog-Operation.
- Die Festplatte wird geladen.
Unser Ansatz für große Tests hilft uns hier. Wir machen einen Dump in einer Testumgebung, führen einen großen Test durch und zeichnen die Protokolle von allem auf, was zum Zeitpunkt der Ausführung des realistischen Skripts passiert. Als nächstes verwenden wir unser eigenes
Marucy- Tool, um die Datenbank zu testen:
- Eine Instanz wird in AWS erstellt.
- Der Dump, den wir benötigen, wird bereitgestellt.
- Pg_replay wird gestartet und spielt die erforderlichen Protokolle ab.
- Wir verwenden unsere Überwachung, um das Ergebnis von Prometheus + Grafana zu analysieren. Es gibt Beispiele für Dashboards im Repository.
Wenn wir marucy starten, können wir eine kleine Anzahl von Parametern übergeben, die geändert werden können, z. B. die Intensität des Skripts.
Daher verwenden wir unser realistisches Skript, um einen Test zu erstellen, und spielen den Test dann ohne Verwendung eines großen Clusters ab. Es ist wichtig zu berücksichtigen, dass das Skript zum Testen einer SQL-Datenbank ungleichmäßig sein muss, da sich sonst die Datenbank selbst anders verhält als das Produkt.
Abbauüberwachung
Für Degradationstests verwenden wir unser realistisches Szenario. Die Idee ist, dass wir sicherstellen müssen, dass der Dienst nach der nächsten Version nicht langsamer arbeitet. Wenn unsere Entwickler den Code ändern, was zu einer Verlängerung der Ausführungszeit von Anforderungen führt, können wir die neuen Werte mit den Referenzwerten vergleichen und signalisieren, ob der Build einen Fehler aufweist. Für Referenzwerte nehmen wir die aktuellen Werte, die zu uns passen.
Die Steuerung der Ausführungszeit von Abfragen ist nützlich, aber wir sind noch weiter gegangen. Wir wollten sehen, dass die Reaktionszeit während der Arbeit von echten Benutzern nach der Veröffentlichung nicht länger wurde. Wir dachten, dass wir zum Zeitpunkt der Belastungstests wahrscheinlich etwas überprüfen können, aber dies werden nur Dutzende von Fällen sein. Es ist effizienter, vorhandene Funktionstests durchzuführen und gleichzeitig tausend Fälle zu sehen.

Wie funktioniert das bei uns? Es gibt einen Meister, der nach der Montage auf einem Prüfstand eingesetzt wird. Parallel zu den Belastungstests werden dann automatisch Funktionstests durchgeführt. Dann erhalten wir in Allure einen Bericht darüber, wie die Funktionstests unter Last verlaufen sind.
In diesem Bericht sehen wir beispielsweise, dass ein Vergleichstest mit einem Referenzwert gefallen ist.
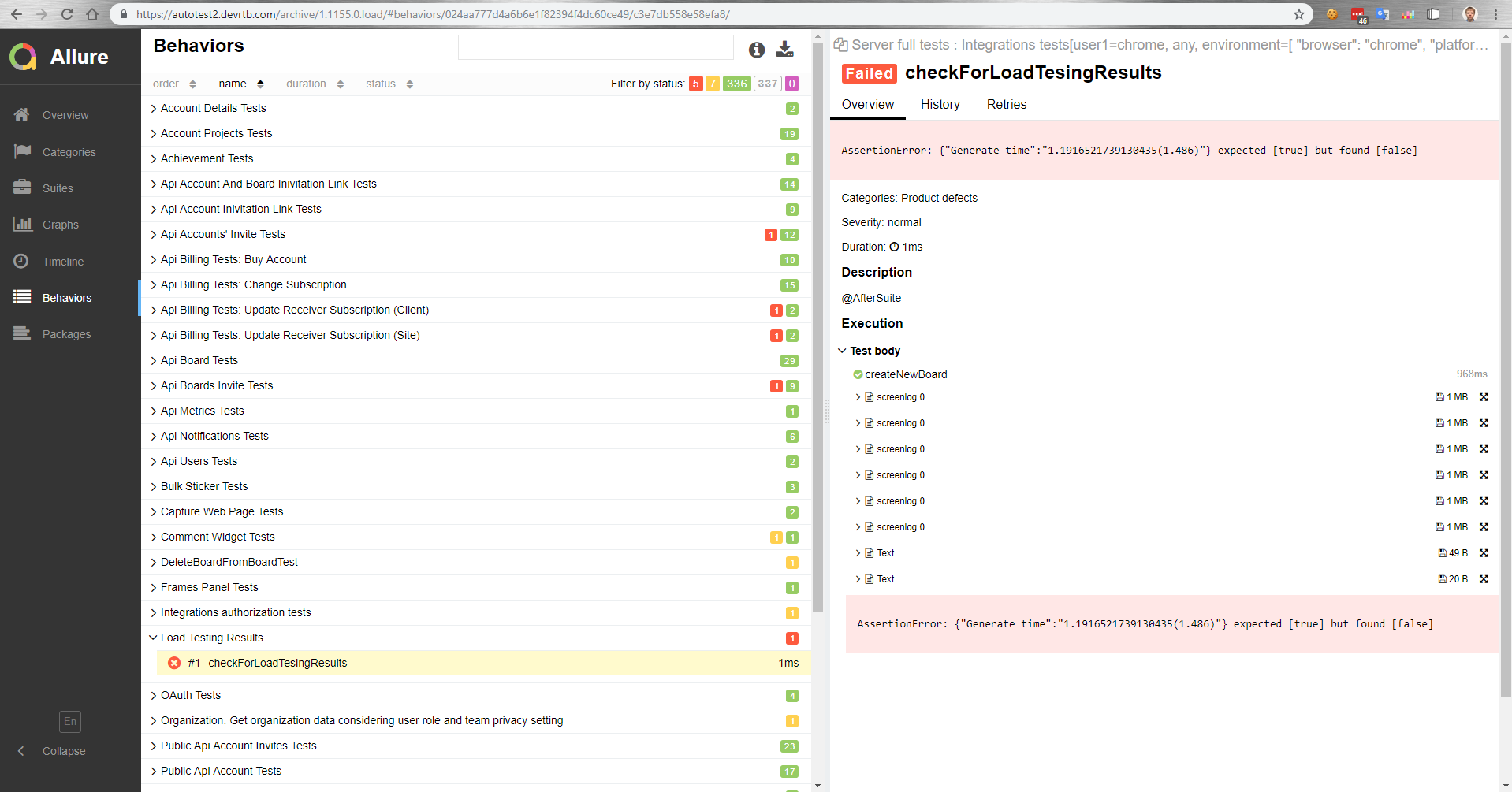
Auch in Funktionstests können wir die Ausführungszeit eines Vorgangs in einem Browser messen. Oder ein Funktionstest ist einfach nicht erfolgreich, da die Zeit, die zum Abschließen des Vorgangs unter Last benötigt wird, länger ist, da der Client eine Zeitüberschreitung aufweist.
Ergebnisse für diesen Teil
- Mit einem realistischen Test können Sie die Datenbank kostengünstig testen und einfach konfigurieren.
- Funktionsprüfung unter Last ist möglich.
Der
nächste Artikel befasst sich mit der Verwaltung von Hunderten von Servern für einen Auslastungstest.