Das Parsen von Text beginnt immer mit der lexikalischen Analyse oder dem Tokenisieren. Es gibt eine einfache Möglichkeit, dieses Problem für fast jede Sprache mit regulären Ausdrücken zu lösen. Eine andere Verwendung des guten alten regulären Ausdrucks.
Ich habe oft die Aufgabe, Texte zu analysieren. Für einfache Aufgaben wie das Analysieren eines vom Benutzer eingegebenen Werts ist die grundlegende Funktionalität für reguläre Ausdrücke ausreichend. Für komplexe und schwere Aufgaben wie das Schreiben eines Compilers oder die Analyse statischen Codes können Sie spezielle Tools (AntLR, JavaCC, Yacc) verwenden. Aber ich stoße oft auf Aufgaben mittlerer Ebene, wenn es nicht genügend reguläre Ausdrücke gibt, aber ich keine Lust habe, schwere Werkzeuge in das Projekt zu ziehen. Darüber hinaus arbeiten diese Tools normalerweise zur Kompilierungsphase und erlauben zur Laufzeit keine Änderung der Analyseparameter (z. B. Erstellen einer Liste von Schlüsselwörtern aus einer Datei oder Datenbanktabelle).
Als Beispiel gebe ich eine Aufgabe an, die beim Beschleunigen von SQL-Abfragen entstanden ist . Wir haben die Protokolle unserer SQL-Abfragen analysiert und wollten nach bestimmten Regeln "schlechte" Abfragen finden. Zum Beispiel Abfragen, bei denen dasselbe Feld mit ODER auf eine Reihe von Werten überprüft wird
name = 'John' OR name = 'Michael' OR name = 'Bob'
Wir wollten solche Anfragen durch ersetzen
name IN ('John', 'Michael', 'Bob')
Reguläre Ausdrücke kommen nicht mehr zurecht, aber ich wollte auch keinen vollwertigen SQL-Parser mit AntLR erstellen. Es wäre möglich, den Anforderungstext in Token aufzuteilen und einfachen Code zu verwenden, um das Parsen ohne spezielle Tools durchzuführen.
Dieses Problem kann mit der Grundfunktionalität regulärer Ausdrücke gelöst werden. Versuchen wir, die SQL-Abfrage in Token aufzuteilen. Wir werden uns eine vereinfachte Version von SQL ansehen, um den Text nicht mit Details zu überladen. Um einen vollwertigen SQL-Lexer zu erstellen, müssen Sie etwas komplexere reguläre Ausdrücke schreiben.
Hier ist eine Reihe von Ausdrücken für grundlegende SQL-Sprachtoken:
1. keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b 2. id : [A-Za-z][A-Za-z0-9]* 3. real_number : [0-9]+\.[0-9]* 4. number : [0-9]+ 5. string : '[^']*' 6. space : \s+ 7. comment : \-\-[^\n\r]* 8. operation : [+\-\*/.=\(\)]
Ich möchte auf den regulären Ausdruck für das Schlüsselwort achten
keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b
Es hat zwei Funktionen.
- Der \ b-Operator wird beispielsweise am Anfang und am Ende verwendet, um das oder das Präfix der Wortorganisation, die ein Schlüsselwort ist und die einige Regex-Engines ohne Verwendung des \ b-Operators in ein separates Token trennen, nicht abzuschneiden.
- Alle Wörter werden in nicht erfassenden Klammern (? :) gruppiert, die die Übereinstimmung nicht erfassen. Dies wird in Zukunft verwendet, um die Indizierung von regulären Teilausdrücken innerhalb des allgemeinen Ausdrucks nicht zu verletzen.
Jetzt können Sie alle diese Ausdrücke mithilfe der Gruppierung und des Operators | zu einem Ganzen kombinieren
(\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b)|([A-Za-z][A-Za-z0-9]*)|([0-9]+\.[0-9]*)|([0-9]+)|('[^']*')|(\s+)|(\-\-[^\n\r]*)|([+\-\*/.=\(\)])
Jetzt können Sie versuchen, diesen Ausdruck auf einen SQL-Ausdruck anzuwenden, beispielsweise auf einen solchen
SELECT count(id)
Hier ist das Ergebnis des Regex-Testers. Durch Klicken auf den Link können Sie mit dem Ausdruck und dem Ergebnis der Analyse herumspielen. Es ist ersichtlich, dass beispielsweise SELECT unmittelbar einer 1-Gruppe entspricht, die dem Schlüsselworttyp entspricht .
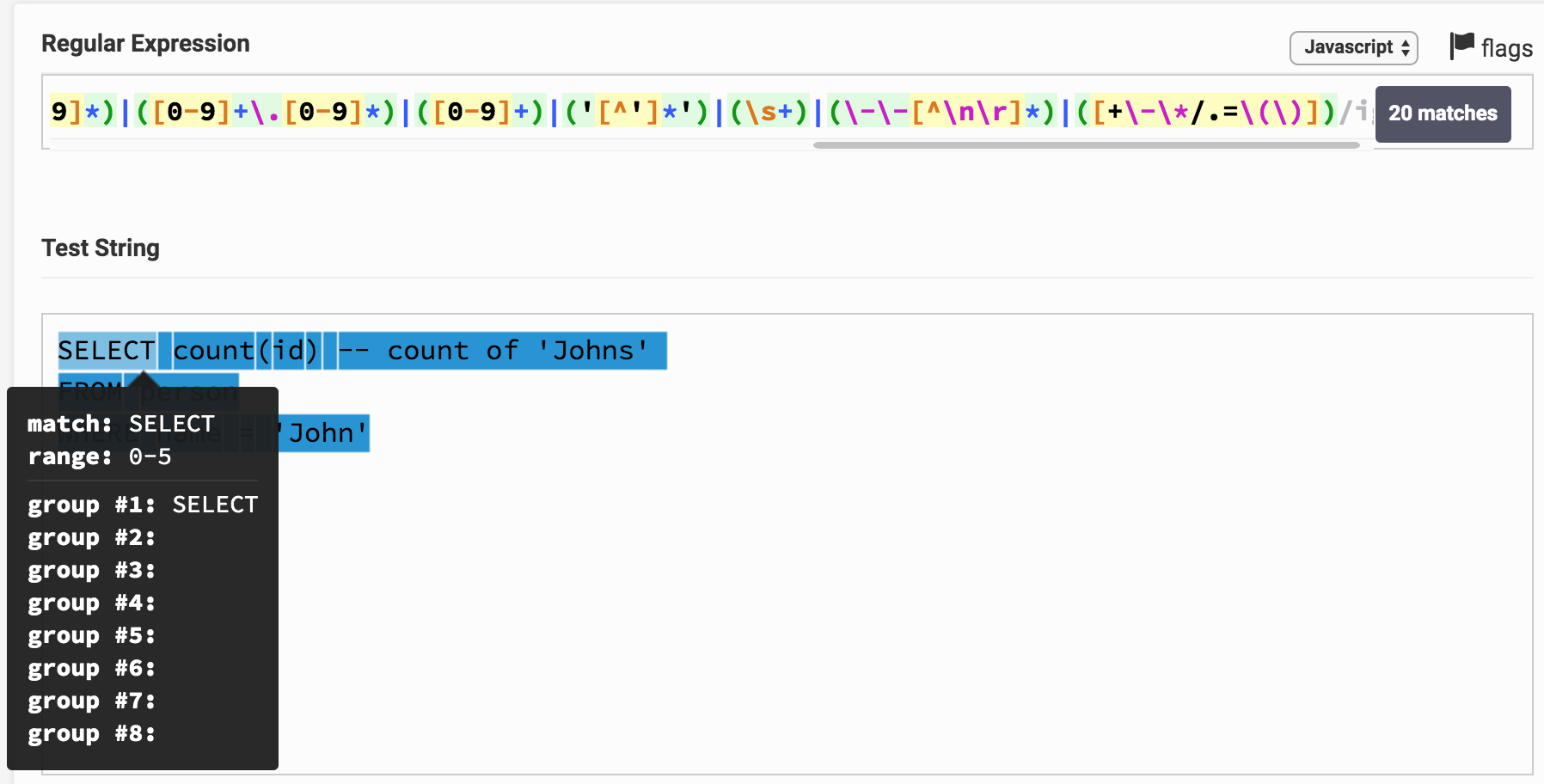
Möglicherweise stellen Sie fest, dass der gesamte Text der Anforderung in Teilzeichenfolgen unterteilt ist und jeweils einer bestimmten Gruppe entspricht. Anhand der Gruppennummer können Sie diese mit dem Token-Typ (Token) korrelieren.
Es ist nicht schwierig, den angegebenen Algorithmus in ein Programm in einer beliebigen Programmiersprache zu verwandeln, die reguläre Ausdrücke unterstützt. Hier ist eine kleine Klasse, die dies in Java implementiert.
RegexTokenizer.java (+ noch ein paar Klassen) package org.example; import java.util.ArrayList; import java.util.Enumeration; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.stream.Collectors; public class RegexTokenizer implements Enumeration<Token> {
In dieser Klasse wird der Algorithmus unter Verwendung benannter Gruppen implementiert, die nicht in allen Engines vorhanden sind. Mit dieser Funktion können Sie nicht nach Index, sondern nach Namen auf Gruppen zugreifen. Dies ist etwas praktischer als der Zugriff nach Index.
Auf meinem I7 mit 2,3 GHz zeigt diese Klasse eine Analysegeschwindigkeit von 5 bis 20 MB pro Sekunde (abhängig von der Komplexität der Ausdrücke). Der Algorithmus kann parallelisiert werden, indem mehrere Dateien gleichzeitig analysiert werden, wodurch die Gesamtarbeitsgeschwindigkeit erhöht wird.
Ich habe mehrere ähnliche Algorithmen im Netzwerk gefunden, bin jedoch auf Optionen gestoßen, die keinen gemeinsamen regulären Ausdruck bilden, aber konsistent reguläre Ausdrücke für jeden Token-Typ auf den Zeilenanfang anwenden, dann das gefundene Token vom Zeilenanfang verwerfen und erneut versuchen, alle regulären Ausdrücke anzuwenden. Dies funktioniert etwa 10 bis 20 Mal langsamer, erfordert mehr Speicher und der Algorithmus ist komplizierter. Ich habe eine höhere Arbeitsgeschwindigkeit nur mit meiner Implementierung regulärer Ausdrücke erreicht, die auf DFA ( deterministic finite state machine) basiert. In Regex-Motoren wird normalerweise NKA verwendet (eine nicht deterministische Finite-State-Maschine). DFA ist 2-3 mal schneller, aber reguläre Ausdrücke sind aufgrund einer begrenzten Anzahl von Operatoren schwieriger zu schreiben.
In meinem Beispiel für SQL habe ich reguläre Ausdrücke ein wenig vereinfacht, und der resultierende Tokenizer kann nicht als vollwertiger lexikalischer Analysator für SQL-Abfragen betrachtet werden. Der Zweck des Artikels besteht jedoch darin, das Prinzip aufzuzeigen und keinen echten SQL-Tokenizer zu erstellen. Ich habe diesen Ansatz in meiner Praxis verwendet und vollwertige lexikalische Analysatoren für SQL, Java, C, XML, HTML, JSON, Pascal und sogar COBOL erstellt (ich musste daran basteln).
Hier sind einige einfache Regeln zum Schreiben regulärer Ausdrücke für die lexikalische Analyse.
- Wenn dasselbe Token verschiedenen Typen zugewiesen werden kann (z. B. kann jedes Schlüsselwort als Bezeichner erkannt werden), muss zu Beginn ein engerer Typ definiert werden. Dann wird zuerst der reguläre Ausdruck dafür angewendet und der Typ des Tokens bestimmt. In meinem Beispiel werden die Schlüsselwörter beispielsweise vor der ID definiert, und das Auswahl- Token wird als Schlüsselwort und nicht als ID erkannt
- Definieren Sie zuerst längere und dann kürzere Token. Beispielsweise müssen Sie zuerst <= , > = definieren und dann trennen > , < , = In diesem Fall wird der Text <= korrekt als ein einzelnes Token des Operators kleiner oder gleich erkannt und nicht als zwei separate Token < und =
- Lernen Sie, Lookahead und Lookbehind zu verwenden . Beispielsweise hat das Zeichen * in SQL die Bedeutung eines Multiplikationsoperators und aller Felder in der Tabelle. Mit einem einfachen Lookbehind können Sie diese beiden Fälle trennen, z. B. hier regexp (? <=. \ S | select \ s ) * findet das Zeichen * nur im Wert "alle Felder der Tabelle".
- Es ist manchmal nützlich, reguläre Ausdrücke für Fehler zu definieren, die im Text auftreten. Wenn Sie beispielsweise die Syntax hervorheben, können Sie den Typ des unfertigen Zeichenfolgentokens als
'[^\n\r]* . Während der Bearbeitung von Text hat der Benutzer möglicherweise keine Zeit, das Anführungszeichen in der Zeichenfolge zu schließen. Ihr Tokenizer kann diese Situation jedoch korrekt erkennen und hervorheben.
Mit diesen Regeln und der Anwendung dieses Algorithmus können Sie den Text für fast jede Sprache schnell in Token aufteilen.