Wir alle lieben und nutzen die erstaunlichen Funktionen der Verfügbarkeitsgruppe für sekundäre Replikate wie Integritätsprüfungen, Sicherungen usw.
Tatsächlich bereitet die Unfähigkeit, diese Informationen in einer Datenbank auf einem Replikat zu speichern, immer noch Kopfschmerzen (und denken Sie an Dinge wie CDC, um noch mehr Unbehagen zu verursachen).
Aber hör auf dich zu beschweren, hier ist die Hauptidee: Lieber Microsoft, lass uns unsere Replikate verwenden, um Statistiken zu aktualisieren ... nun, und viel mehr daran tun.
Es gibt immer einen Weg oder so etwas
*fast immerLassen Sie uns die bekannten grundlegenden Details einer möglichen Lösung in Enterprise Edition MS SQL Server auflisten:
- Wir können Replikate lesbar machen und Daten daraus lesen (nicht, dass Sie dies immer tun mussten, aber wenn Sie wirklich wissen, was Sie tun ...);
- Wir können unsere Objekte nach Tempdb (ja, Ihre Multi-Terabyte-Tabellen sind für eine solche Operation wahrscheinlich nicht sehr geeignet) oder in eine andere beschreibbare Datenbank kopieren.
- Wir können die Ergebnisse in einen freigegebenen Ordner schreiben, auf den beide Replikate zugreifen können (sei es eine Textdatei in einer Dateifreigabe).
- Wir können Statistiken als Blob von SQL Server exportieren.
- Wir können den heruntergeladenen Blob in die Statistik importieren.
Lass es uns tun
Ich habe eine Test-AG auf zwei virtuellen Maschinen mit SQL Server 2017 (Sie können jede Version verwenden) und ich werde eine einfache Tabelle erstellen, in der ich die Statistiken aktualisieren möchte.
Hier ist ein Skript zum Erstellen einer Tabelle und zum Einfügen einer Million Zeilen:
DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT t.RN, t.RN FROM ( SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Erstellen wir nun die ST_SampleDataTable_C2-Statistik für Spalte c2
CREATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2);
Und dann werde ich 1000 Zeilen einfügen, was sehr wichtig sein wird und weshalb ich die Statistiken wirklich aktualisieren muss.
set nocount on; INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT 10000000 + t.RN, 999999999 FROM ( SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Jetzt habe ich 1000 Einträge, in denen in Spalte C2 der Wert 999999999 lautet. Und dies bedeutet definitiv das Problem mit dem aufsteigenden Schlüssel, und ich muss die Statistiken wirklich aktualisieren ... auf dem Replikat, damit ich den Hauptserver nicht mit Berechnungen und belastete hinderte ihn daran, Kunden zu bedienen.
Lassen Sie uns mit dem guten alten Befehl DBCC SHOW_STATISTICS unsere Statistiken untersuchen.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
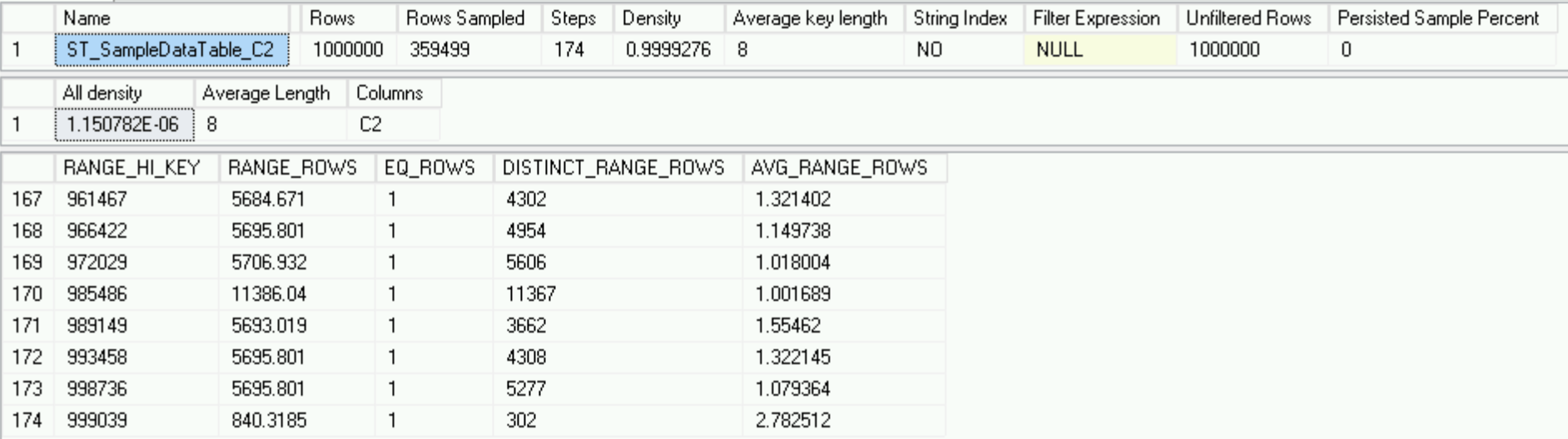
In unserem Königreich ist alles perfekt und unsere Statistiken sind in perfekter Reihenfolge, obwohl nur 1 Million Zeilen berücksichtigt werden und es keine schädlichen tausend Zeilen gibt, die letztendlich Teil dieser Statistiken werden sollten.
Wir können den Statistikstrom auch mit dem Parameter STATS_STREAM des Befehls DBCC SHOW_STATISTICS anzeigen:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

Es ist nur ein Zeichensatz, über den Blogs seit Jahren schreiben, aber ich bin mir immer noch nicht sicher, ob dies eine vollständig dokumentierte Funktion ist (obwohl sie die Leute nie davon abgehalten hat, sie zu verwenden).
Auf das Stichwort
Kopieren wir unsere Tabelle auf einem Replikat nach tempdb (obwohl sich meine AG im synchronen Modus befindet, kann dasselbe asynchron gemacht werden, nur die Daten können mit einer leichten Verzögerung kommen).
use TempDB; DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable SELECT C1, C2 FROM AvGroupDb.dbo.SampleDataTable;
Jetzt können wir die Statistiken mit einem vollständigen Scan in tempdb auf dem Replikat aktualisieren.
use TempDB; UPDATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2) WITH FULLSCAN;
(
Anmerkung des Übersetzers - Nico hat vergessen, Statistiken zu erstellen, und verwendet die falsche Syntax der Operation UPDATE STATISTICS. Anstelle von UPDATE sollte sie CREATE sein, d. H. Die Statistiken werden nicht aktualisiert, sondern erstellt. )
Gehen Sie zurück zu DBCC SHOW_STATISTICS und sehen Sie es sich an:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
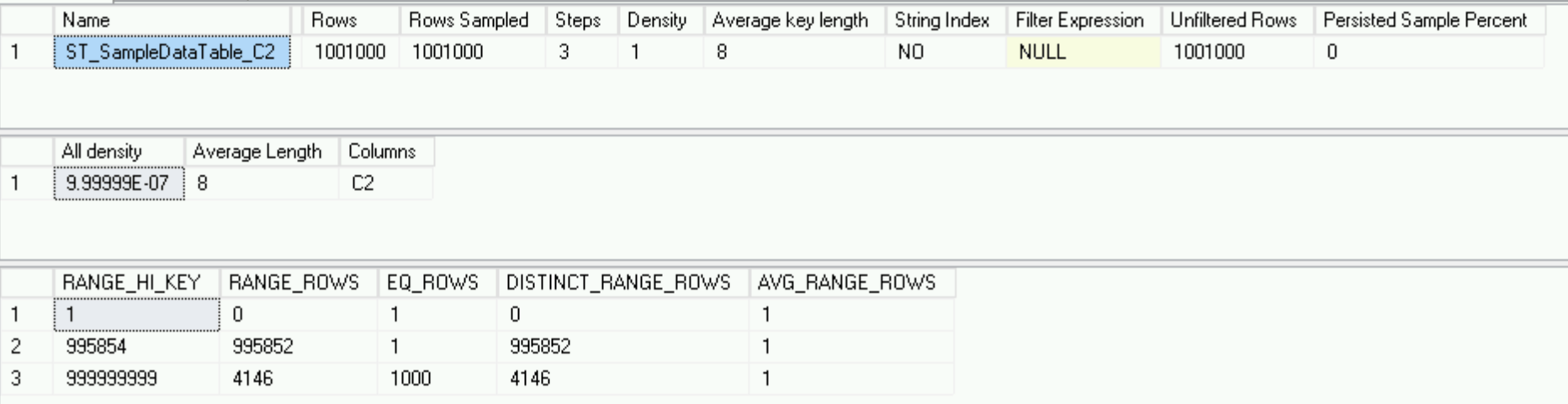
Es sieht völlig anders aus als auf dem Hauptserver - nur 3 Zeilen gegenüber 178, aber es beschreibt die Daten perfekt - wir haben eine Million eindeutige Zeilen und 1000 Zeilen mit demselben C2-Spaltenwert - das Histogramm ist so gut wie möglich .
Schauen wir uns den Statistikfluss an:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

Sie müssen kein Genie sein, um zu bemerken, dass der Stream völlig anders aussieht - wir sehen die 5689A0C6-Zeichen im aktualisierten Stream, während wir im Original zwischen all diesen Nullen EDF10EB4 sahen.
Konzentrieren wir uns darauf, diese Daten in eine Textdatei außerhalb von SQL Server zu exportieren, und tun dies mithilfe des wunderbaren BCP-Befehls, für den CMDSHELL aktiviert sein muss (Hinweis: Sie möchten dies wahrscheinlich nicht auf Ihrem Produktionsserver).
EXEC xp_cmdshell 'BCP "DBCC SHOW_STATISTICS(''AvGroupDb.dbo.SampleDataTable'', ''ST_SampleDataTable_C2'') WITH STATS_STREAM" queryout \\SharedServer\Tempdb\stats.txt -c -T';
Und hier ist, wie groß die Datei stats.txt in unserem Ball sein wird:

Nur ein paar Kilobyte! Einfach zu übertragen, einfach zu verwalten.
Zurück zum Hauptserver
Auf dem Hauptserver müssen wir eine temporäre Tabelle erstellen, in der der Statistikstrom gespeichert wird, bevor wir Statistiken daraus in unserer Haupttabelle SampleDataTable aktualisieren können (in der Praxis können wir diese Tabelle für viele Datenbanken, Tabellen und Statistiken erweitern).
CREATE TABLE dbo.TempStats( Stats_Stream VARBINARY(MAX), Rows BIGINT, DataPages BIGINT );
Importieren wir die Daten aus unserer Textdatei in unsere neue temporäre Tabelle und sehen, was wir importiert haben:
BULK INSERT dbo.TempStats FROM '\\SharedServer\Tempdb\stats.txt' SELECT * FROM dbo.TempStats;

Wir können dieselben Daten sehen, die wir auf dem Replikat berechnet haben, aber diese Daten befinden sich bereits auf unserem Hauptserver. Wir müssen nur noch unsere Statistiken in der Tabelle aktualisieren. Diese Operation kann mit der Operation UPDATE STATISTICS mit dem Parameter WITH STATS_STREAM = ... ausgeführt werden
DECLARE @script NVARCHAR(MAX) SELECT @script = 'UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = ' + CONVERT(nvarchar(max), [Stats_Stream],1) FROM dbo.TempStats PRINT @script; EXECUTE sp_executesql @script;
Dieses Skript liest den oben importierten Wert (ja, ich weiß - ich habe dieses Beispiel für eine Tabelle erstellt und mich nicht mit mehreren Statistiken, Tabellen, Datenbanken usw. befasst), generiert eine UPDATE STATISTICS-Anweisung, zeigt sie auf dem Bildschirm an und am Ende erfüllt es.
Folgendes bekomme ich in der Ausgabe:
UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM =
Wenn ich DBCC SHOW_STATISTICS auf dem Hauptserver ausführe, erhalte ich genau das Ergebnis, auf das ich gehofft habe - genau wie auf dem Replikat. Der Kreis ist geschlossen.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2');
Der wirklich großartige Teil dieser Geschichte ist, dass die Größe des Objekts mit Statistiken sehr klein ist und wir es sehr einfach / sofort auf den Hauptserver übertragen können.
Nicht so einfaches Szenario.
Wenn Sie mehrere AGs zwischen denselben Replikaten haben, wobei ein Replikat das Hauptreplikat in einem AG und das andere das Hauptreplikat in dem zweiten ist, können Sie BLOB-Daten in den Datenstrom zwischen den Replikaten einfügen und eine winzige Datenbank mit den übertragenen Daten hinzufügen.
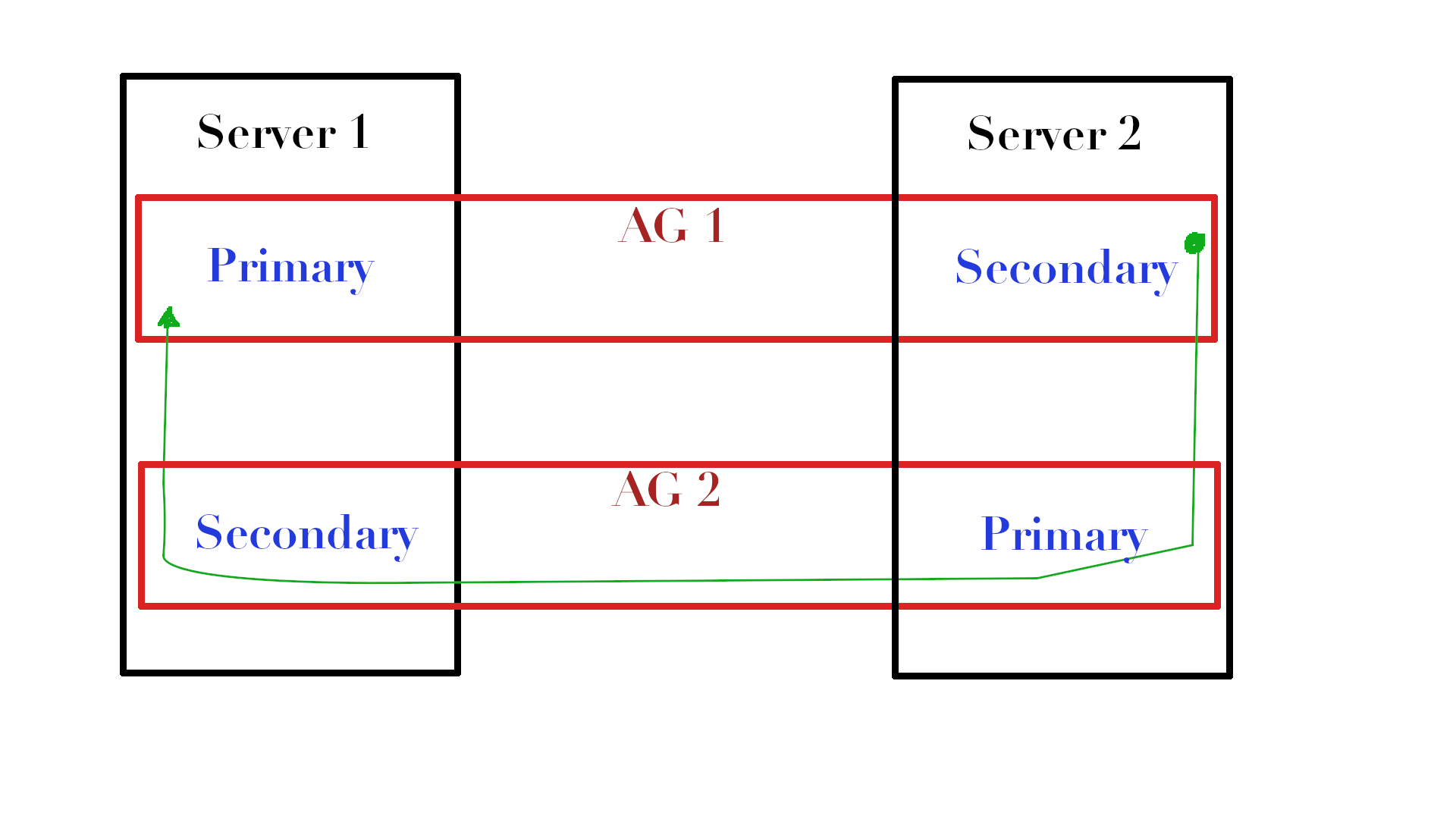
Schau dir das Bild an. Wenn wir zwei AGs (AG1 & AG2) haben, die sich auf verschiedenen Servern befinden, und wir eine bestimmte Tabelle auf Server1 in AG1 haben, für die wir Statistiken aktualisieren möchten, können wir diese Tabelle auf Server2 kopieren (nennen wir sie dbo.MyTable ) In tempdb, aktualisieren und mit AG2 senden Sie das Objekt mit dem Statistik-Stream zurück an Server1, wo Sie einfach Statistiken aus diesem Stream in die benötigten Statistiken importieren.
Ja, ich weiß, es klingt verwirrend, aber stellen Sie es sich einfach als einen Feedback-Kanal vor, über den die Ergebnisse geliefert werden, anstatt sie auf Dateibälle zu legen.
Platz für Zweifel
Sie können einige Einwände haben, zum Beispiel:
- Warum sollte ich dies auf einem Replikat tun, wenn ich es sicher auf dem Hauptserver tun kann? (Nun, die Idee ist, den Hauptserver auszulagern)
- Laden wir das Replikat jedoch möglicherweise nicht (ja, aber wenn es inaktiv ist, möchten wir seine Leistung nutzen).
- und wir können irgendwie nicht auf dem Hauptserver agieren? (Nein, wir lesen nur die Daten aus dem Replikat und senden ein paar Kilobyte zurück, was in unserem Jahrhundert Gigabyte und Terabyte wie "shtoa?" klingt.) ( Hinweis Übersetzer - im Allgemeinen, nur im Fall einer lesbaren Replik AG, können wir )
- Was ist, wenn der Hauptserver mitten im Prozess beginnt, die Statistiken selbst zu aktualisieren? (In diesem Fall kann entweder der zweite Prozess unterbrochen oder mit den aktualisierten Daten neu gestartet werden.)
AG Feedback Kanal
Dies ist ein Kanal mit Rückmeldung vom Replikat an den Hauptserver. Nachdem wir die Transaktion in der synchronen AG zugesagt haben, wartet der Hauptserver auf die Bestätigung durch das Replikat. Ich denke, dass dieser Kanal zur Implementierung dieser Verbesserung verwendet werden kann. Schauen Sie sich das Bild an, das in einem Beitrag von
Simon Su aufgenommen wurde .
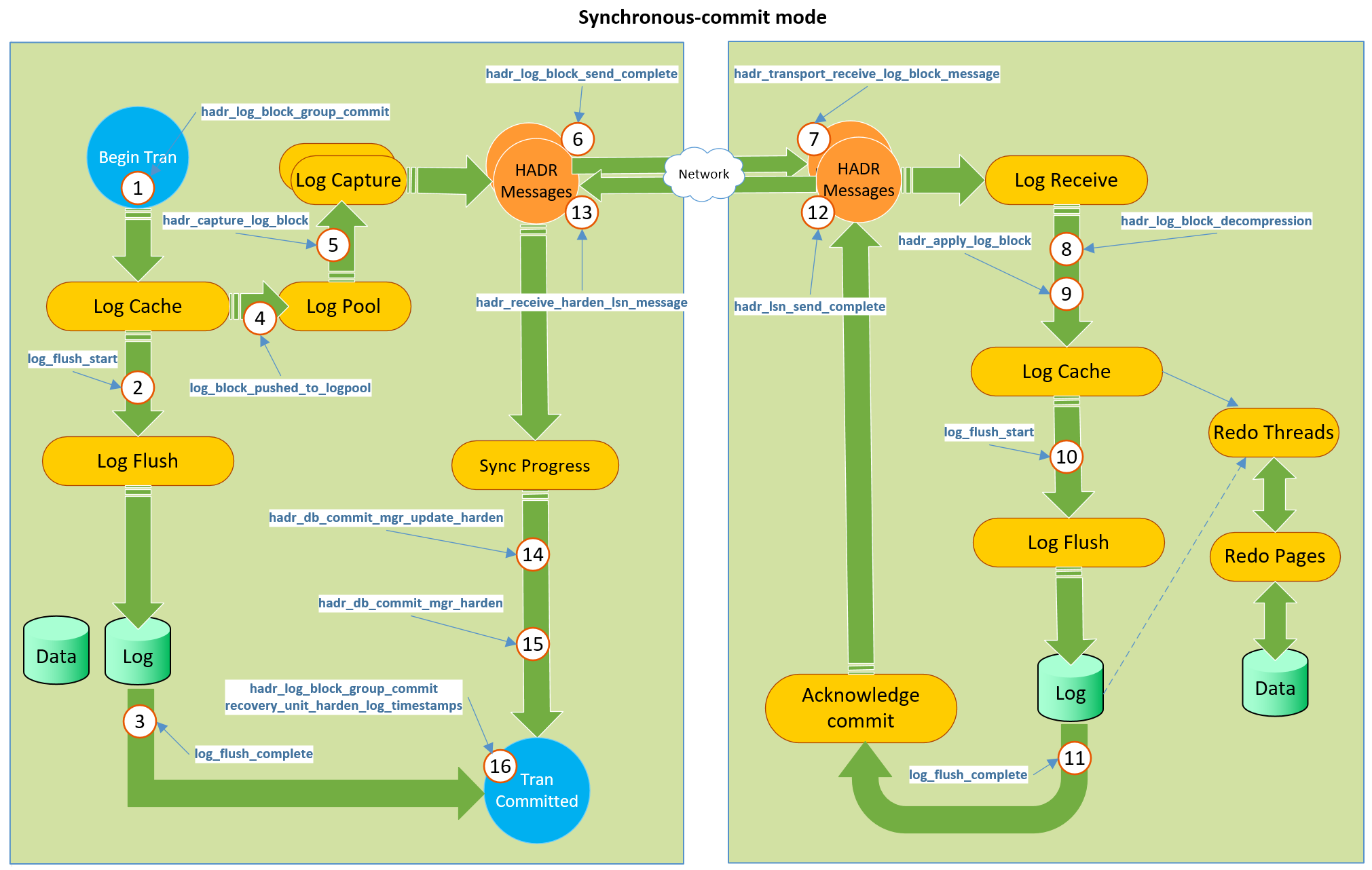
Welches den gesamten Mechanismus des vorhandenen Rückkopplungskanals darstellt. Das Replikat bestätigt in Schritt 12 und anschließend dem Primärserver, dass die Informationen gespeichert wurden. Der gleiche Kanal kann verwendet werden, um ein Statistikflussobjekt nach dem Nachzählen auf einem Replikat zu senden. Natürlich müssen wir für diesen Zweck kein Tempdb verwenden, sondern ein In-Memory-Objekt in der Datenbank erstellen, das nicht dauerhaft gespeichert werden soll (sehen Sie sich Ihre In-Memory-OLTP-Schema-Only-Tabellen an oder denken Sie an NOLOGGING-Tabellen in Oracle) sollte am Ende der Operation entfernt werden - das wäre wirklich cool.
Allgemeine Gedanken
Dies sollte nicht davon abhängen, ob das synchrone Replikat - die meisten Zeitstatistiken werden nicht alle paar Sekunden aktualisiert, und dies führt uns zum zweiten Teil der Idee - einen Aufruf zum Aktualisieren der Statistiken auf dem Hauptserver mit einem Parameter wie z
UPDATE STATISTICS dbo.MyAwesomeTable(HugeImportantStatOnC17) WITH FULLSCAN, SECONDARY
Dabei gibt der Parameter SECONDARY an, wo die Operation ausgeführt werden soll.
Und genau wie bei Sicherungen sollten wir in der Lage sein, das bevorzugte Replikat anzugeben, um UPDATE STATISTICS (oder einen anderen Vorgang in der Zukunft) in den Einstellungen auszuführen.
Ich bin sicher, dass diese Funktion viele Enterprise Edition-Benutzer dazu ermutigen wird, auf die neue Version von SQL Server zu migrieren, mit der schwere Vorgänge zwischen Replikaten verteilt werden können.
Was die aktuelle Situation betrifft, sehe ich genau, wie Sie diese Lösung mit Powershell automatisieren können.
Microsoft, Sie sind dran! ;)
Stimmen Sie hier für die vorgeschlagene Funktion
ab .
Anmerkung des Übersetzers: Vorschläge und Kommentare zu Übersetzung und Styling sind wie gewohnt willkommen.
Normalerweise habe ich das primäre Replikat in der Übersetzung "primärer Server" und das sekundäre Replikat - einfach ein Replikat - genannt. Vielleicht ist das nicht ganz richtig, aber mein Ohr tut weniger weh als die "primären" und "sekundären" Repliken auf msdn.