In diesem Artikel werden wir uns mit der Datenausrichtung befassen und auch die 17. Aufgabe von der Site
pwnable.kr lösen .
OrganisationsinformationenSpeziell für diejenigen, die etwas Neues lernen und sich in einem der Bereiche Informations- und Computersicherheit entwickeln möchten, werde ich über die folgenden Kategorien schreiben und sprechen:
- PWN;
- Kryptographie (Krypto);
- Netzwerktechnologien (Netzwerk);
- Reverse (Reverse Engineering);
- Steganographie (Stegano);
- Suche und Ausnutzung von WEB-Schwachstellen.
Darüber hinaus werde ich meine Erfahrungen in den Bereichen Computerforensik, Analyse von Malware und Firmware, Angriffe auf drahtlose Netzwerke und lokale Netzwerke, Durchführung von Pentests und Schreiben von Exploits teilen.
Damit Sie sich über neue Artikel, Software und andere Informationen informieren können, habe ich
in Telegram einen
Kanal und eine
Gruppe eingerichtet, um alle Probleme im Bereich ICD
zu diskutieren . Außerdem werde ich Ihre persönlichen Anfragen, Fragen, Vorschläge und Empfehlungen
persönlich prüfen
und alle beantworten .
Alle Informationen werden nur zu Bildungszwecken bereitgestellt. Der Autor dieses Dokuments übernimmt keine Verantwortung für Schäden, die jemandem durch die Verwendung von Kenntnissen und Methoden entstehen, die durch das Studium dieses Dokuments erworben wurden.
Datenausrichtung
Das Ausrichten von Daten im Direktzugriffsspeicher des Computers ist eine spezielle Anordnung von Daten im Speicher für einen schnelleren Zugriff. Bei der Arbeit mit dem Speicher verwenden Prozesse das Maschinenwort als Haupteinheit. Verschiedene Arten von Prozessoren können unterschiedliche Größen haben: eins, zwei, vier, acht usw. Bytes. Beim Speichern von Objekten im Speicher kann es vorkommen, dass ein Feld diese Wortgrenzen überschreitet. Einige Prozessoren können länger mit nicht ausgerichteten Daten arbeiten als mit ausgerichteten Daten. Und nicht hoch entwickelte Prozessoren können im Allgemeinen nicht mit nicht ausgerichteten Daten arbeiten.
Um sich ein Modell ausgerichteter und nicht ausgerichteter Daten besser vorstellen zu können, betrachten Sie ein Beispiel für das folgende Objekt - die Datenstruktur.
struct Data{ int var1; void* mas[4]; };
Da die Größe einer int-Variablen in x32- und x64-Prozessoren nicht 4 Byte beträgt und der Wert einer void * -Variable 4 bzw. 8 Byte beträgt, wird diese Struktur für x32- und x64-Prozessoren wie folgt im Speicher dargestellt.

X64-Prozessoren mit einer solchen Struktur funktionieren nicht, da die Daten nicht ausgerichtet sind. Für die Datenausrichtung muss der Struktur ein weiteres 4-Byte-Feld hinzugefügt werden.
struct Data{ int var1; int addition; void* mas[4]; };
Somit werden die Datenstrukturdaten für x64-Prozessoren im Speicher ausgerichtet.

Memcpy Joblösung
Wir klicken auf das memcpy-Signatursymbol und erfahren, dass wir uns über SSH mit dem Passwort-Gast verbinden müssen.
Sie bieten auch Quellcode. 
Wenn verbunden, sehen wir das entsprechende Banner.
Lassen Sie uns herausfinden, welche Dateien sich auf dem Server befinden und welche Rechte wir haben.

Wir haben eine Readme-Datei. Nach dem Lesen erfahren wir, dass das Programm auf Port 9022 ausgeführt wird.

Stellen Sie eine Verbindung zu Port 9022 her. Wir erhalten ein Experiment - vergleichen Sie die langsame und schnelle Version von memcpy. Dann gibt das Programm in einem bestimmten Intervall eine Zahl ein und gibt einen Bericht über den Vergleich der langsamen und schnellen Versionen der Funktion aus. Es gibt eine Sache: Experimente 10 und Berichte - 5.
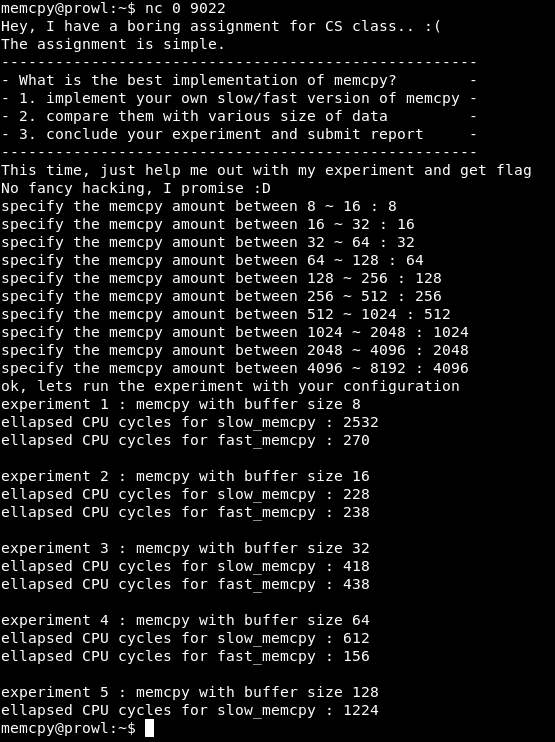
Lassen Sie uns aufräumen, warum. Suchen Sie die Stelle im Code, um die Ergebnisse zu vergleichen.
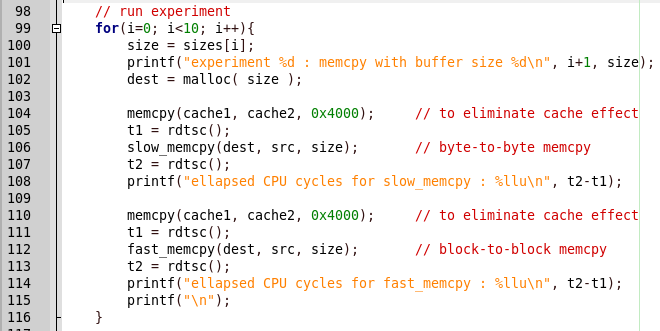
Alles ist einfach, zuerst wird slow_memcpy aufgerufen, dann fast_memcpy. Im Programmbericht gibt es jedoch eine Schlussfolgerung über die langsame Freigabe der Funktion, und wenn die schnelle Implementierung aufgerufen wird, stürzt das Programm ab. Sehen wir uns den schnellen Implementierungscode an.
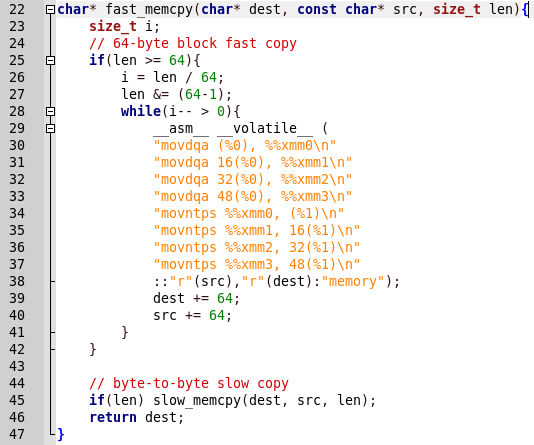
Das Kopieren erfolgt mit Assembler-Funktionen. Wir bestimmen durch Befehle, dass dies SSE2 ist. Wie
hier gesagt: SSE2 verwendet acht 128-Bit-Register (xmm0 bis xmm7), die in der x86-Architektur mit der Einführung der SSE-Erweiterung enthalten sind, von denen jedes als zwei aufeinanderfolgende Gleitkommawerte mit doppelter Genauigkeit behandelt wird. Darüber hinaus arbeitet dieser Code mit ausgerichteten Daten.


Wenn Sie mit nicht ausgerichteten Daten arbeiten, kann das Programm abstürzen. Die Ausrichtung erfolgt mit 128 Bits, dh jeweils 16 Bytes, was bedeutet, dass die Blöcke gleich 16 sein müssen. Wir müssen herausfinden, wie viele Bytes sich bereits im ersten Block auf dem Heap befinden (sei X), dann müssen wir dem Programm jeweils so viele Bytes (sei Y) übertragen, dass ( X + Y)% 16 war 0.
Da alle Operationen Heap-Blöcke belegen, die ein Vielfaches von zwei sind, iterieren Sie über X als 2, 4, 8 usw. bis 16.
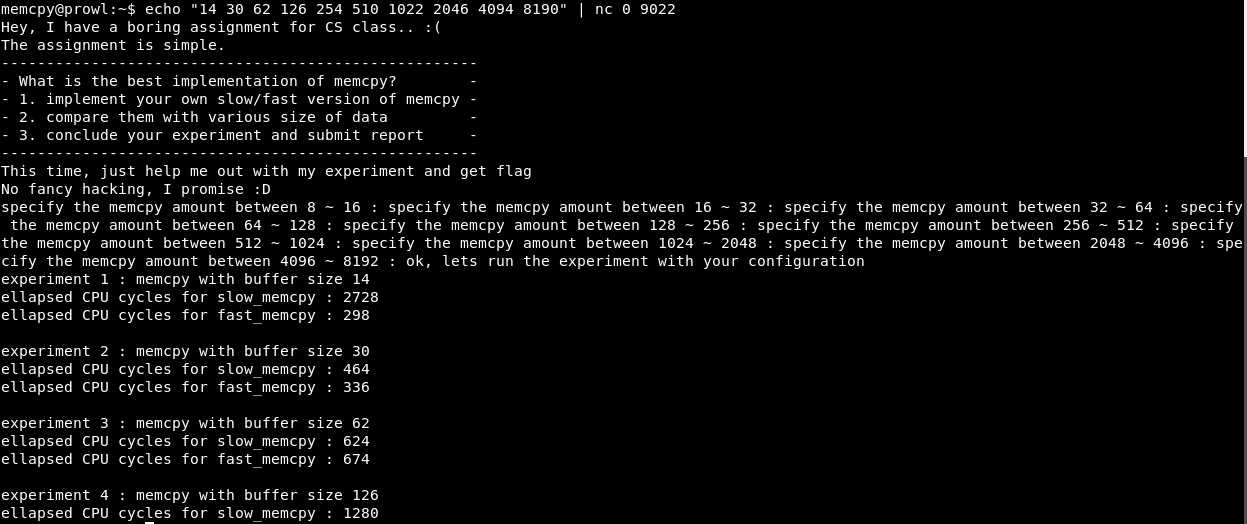
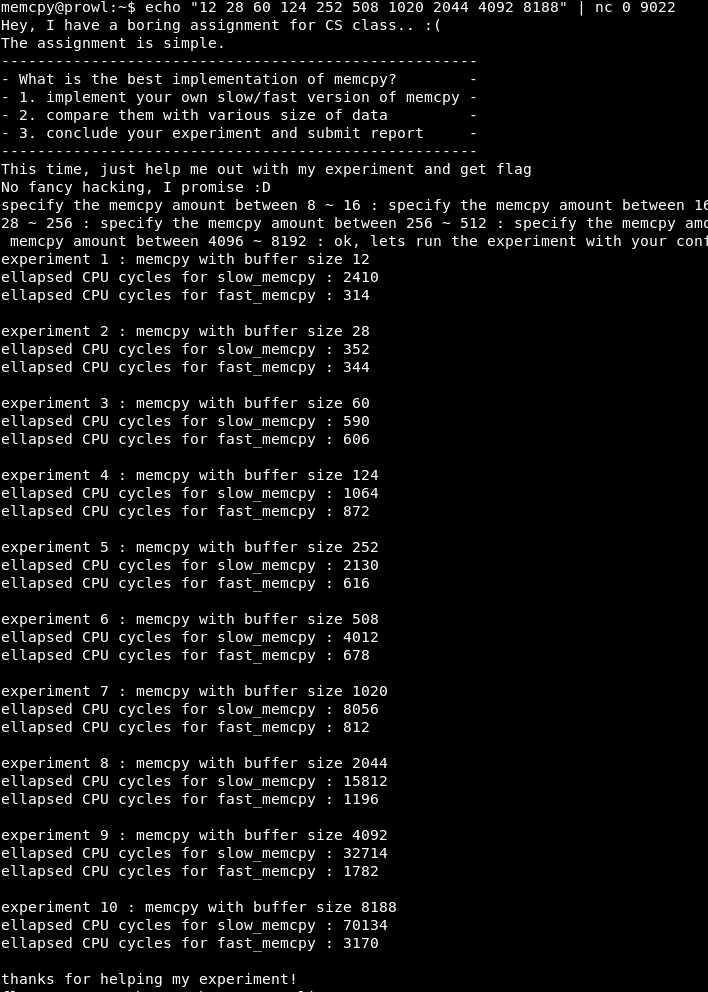
Wie Sie sehen, wird das Programm mit X = 4 erfolgreich ausgeführt.

Wir bekommen die Muschel, lesen die Flagge, bekommen 10 Punkte.
Sie können sich uns
per Telegramm anschließen . Das nächste Mal werden wir uns mit dem Heap-Überlauf befassen.