
Das World Wide Web ist ein Ozean von Daten. Hier sehen Sie fast alle Informationen, die Sie interessieren. Das "Abrufen" dieser Informationen aus dem Internet ist jedoch bereits schwieriger. Es gibt verschiedene Möglichkeiten, Daten abzurufen, und Web-Scraping ist eine davon.
Was ist Web Scraping? Kurz gesagt, es ist eine Technologie, mit der Sie Daten von HTML-Seiten abrufen können. Bei Verwendung von Scraping müssen die erforderlichen Informationen nicht kopiert, eingefügt oder vom Bildschirm auf den Editor übertragen werden. Die Informationen werden auf Ihrem Computer in einer für Sie geeigneten Form angezeigt.
Web-Scraping am Beispiel der Site Kinopoisk.ru
Es ist eine gute Idee, sich ein Ziel zu setzen, um nicht für das Schaben zu kratzen. Ich entschied, dass dies ein Vergleich der Filmbewertungen auf Kinopoisk.ru und IMDB.com sowie der durchschnittlichen Bewertungen von Filmen nach Genre sein würde . Für die Analyse wurden Filme aufgenommen, die von 2010 bis 2018 mit einer Stimmenzahl von mindestens 500 veröffentlicht wurden.
Laden Sie zunächst die benötigten Bibliotheken:
# library(rvest) library(selectr) library(xml2) library(jsonlite) library(tidyverse)
Als nächstes erhalte ich die Anzahl der Filme pro Jahr, die die Auswahlbedingung erfüllen (mehr als 500 Stimmen). Dies geschieht, um die Gesamtzahl der Seiten mit Daten zu ermitteln und Links zu diesen zu "generieren", weil Links sind ähnlich aufgebaut.
# 2018 url <- "https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
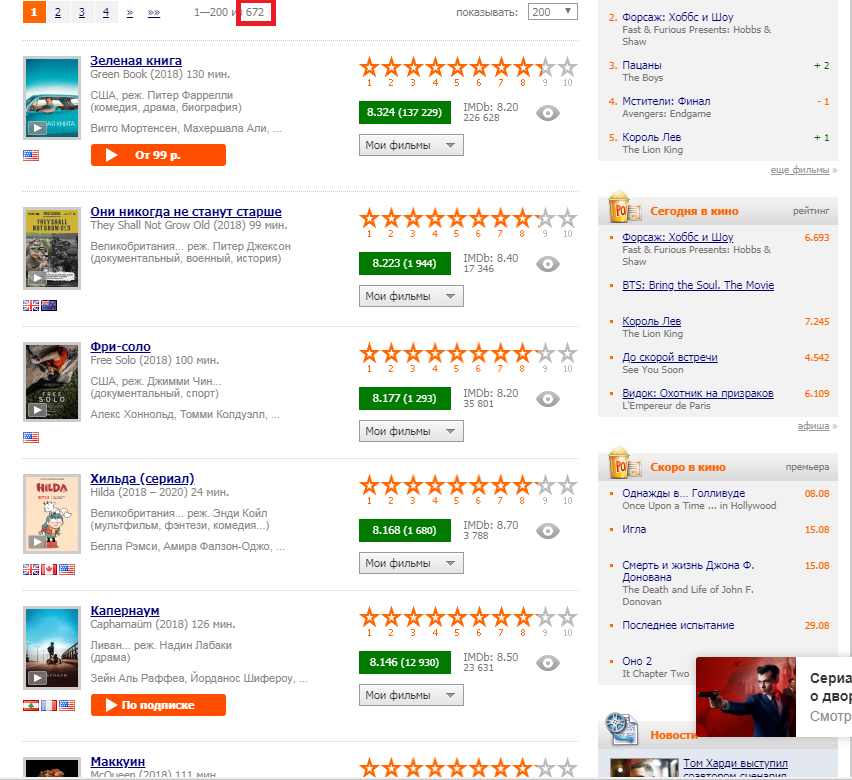
Unsere Aufgabe ist es, die Nummer 672 "herauszuziehen", die im Bild durch ein rotes Rechteck hervorgehoben ist. Dafür brauchen wir Web-Scraping.
Web-Scraping-Seiten der rvest -Website mit dem rvest Paket
Zuerst müssen wir die URL "lesen", die wir erhalten haben. Verwenden Sie dazu die Funktion read_html() des read_html() Pakets.
# XML HTML webpage <- read_html(url)
Und dann „extrahieren“ wir mit den Funktionen des rvest Pakets zuerst den Teil des HTML-Dokuments, den wir benötigen (die Funktion html_nodes() ), und extrahieren dann aus diesem Teil die Informationen, die wir benötigen, in einer für uns html_text() Form (die Funktionen html_text() , html_table() , html_attr() other)
Aber wie verstehen wir, welches Element wir extrahieren müssen? Dazu müssen wir den Mauszeiger über die Informationen halten, an denen wir interessiert sind, auf LMB klicken und "Code anzeigen" auswählen. In unserem Fall erhalten wir folgendes Bild:
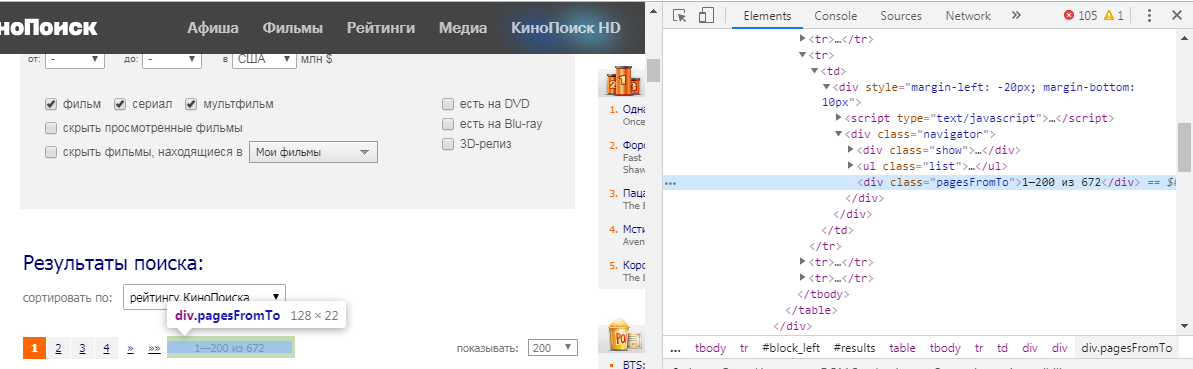
Die Funktion html_nodes() hat die Form html_nodes(x, css) . x ist die zuvor definierte Webseite, aber in CSS schreiben wir die ID- oder Elementklasse. In unserem Fall ist es:
number_html <- html_nodes(webpage, ".pagesFromTo")
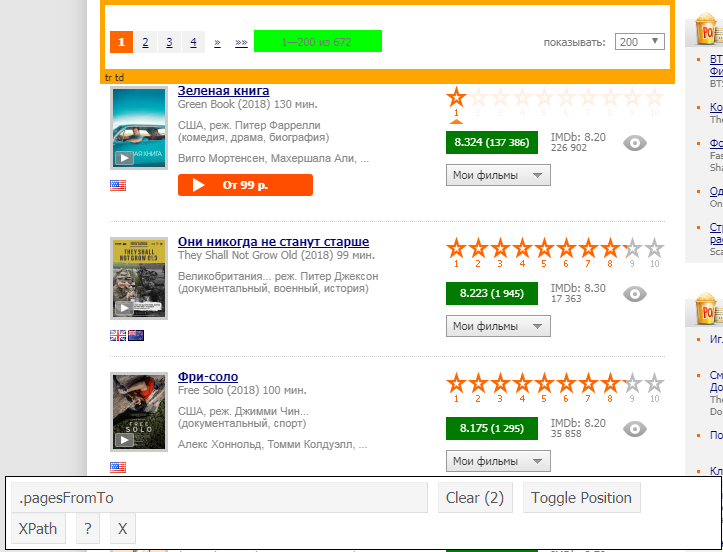
Um das gewünschte Element zu "erkennen", können Sie auch die selectorGadget- Erweiterung verwenden, die zeigt, was wir explizit eingeben müssen:
Als nächstes extrahieren wir mit der Funktion html_text den Textteil aus dem ausgewählten Element:
number <- html_text(number_html) [1] "1—50 672" "1—50 672"
Wir haben die Nummer, die wir brauchten, von der HTML-Seite von Kinopoisk erhalten, aber jetzt müssen wir sie "löschen". Dies ist ein Standardverfahren zum Schaben, da wir sehr selten das Element benötigen, das wir in der von uns benötigten Form benötigen.
Wir haben 2 identische Elemente erhalten, da die Gesamtzahl der Filme oben und unten auf der Seite angegeben ist und die CSS-Auswahl genau gleich ist. Daher entfernen wir zunächst das überschüssige Element:
number <- number[1] [1] "1—50 672"
Als nächstes müssen wir den Teil des Vektors entfernen, der bis zur Zahl 672 reicht. Sie können dies auf verschiedene Arten tun, aber die Basis aller Methoden ist das Schreiben eines regulären Ausdrucks. In diesem Fall "ersetze" ich den Teil "1-50 von" durch eine Leere (Sie können str_remove anstelle von str_replace ), entferne dann die zusätzlichen Leerzeichen ( str_trim Funktion) und übersetze den Vektor schließlich vom Zeichen in den numerischen Typ. Ich bekomme die Nummer 672 am Ausgang. Genau so viele Filme von 2018 haben mehr als 500 User-Stimmen auf Kinopoisk.
number <- str_replace(number, ".{2,}", "") number <- as.numeric(str_trim(number)) [1] 672
Was machen wir als nächstes? Wenn Sie die Seiten auf Kinopoisk durchsehen, werden Sie feststellen, dass die Adressen der Suchseiten dieselbe Struktur haben und sich nur in der Anzahl unterscheiden. Um die Seitenadresse nicht jedes Mal manuell einzugeben, berechnen wir die Anzahl der Seiten und "generieren" die erforderliche Anzahl von Adressen. Es wird so gemacht:
# page_number <- ceiling(number/50) # page <- sapply(seq(1:page_number), function(n){ list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results") })
Die Ausgabe umfasst 14 Adressen. Die ceiling in diesem Beispiel rundet eine Zahl auf eine GROSSE Ganzzahl.
Und dann verwenden wir die lapply Funktion, zu deren Eingabe die Adressen der Seiten eingegeben werden, und die Funktion "extrahiert" Informationen von den Seiten von Kinopoisk über den Namen, die Bewertung, die Anzahl der Stimmen und die Hauptgenres (maximal 3) des Films. Der Funktionscode befindet sich im Repository von Github .
Als Ergebnis erhalten wir einen Tisch mit 8111 Filmen.
Es ist erwähnenswert, dass die Funktion Sys.sleep verwendet wird. Damit können Sie die Verzögerungszeit zwischen Ausdrücken einstellen. Warum wird das benötigt? Wenn Sie Informationen zu einem Jahr erhalten möchten, besteht keine Notwendigkeit. Wenn Sie jedoch an einer großen Anzahl von Filmen / Jahren interessiert sind, betrachtet Kinopoisk Sie nach einer bestimmten Anzahl von Anfragen als Roboter und Sie erhalten eine leere Liste für Ihre Anfrage. Um dies zu vermeiden, müssen Sie die Verzögerungszeit eingeben.
Ebenso "verschrotten" Sie die Website IMDB.com.
Datenanalyse
Wir haben zwei Tabellen, eine Information über Filme mit IMDB, die andere von Kinopoisk. Jetzt müssen wir sie kombinieren. Wir werden uns gemäß den Spalten NAME und YEAR zusammenschließen. Um die Anzahl der Unstimmigkeiten in den Namen auch im Stadium des Schabens zu verringern, habe ich alle Satzzeichen gelöscht und die Buchstaben in Kleinbuchstaben umgewandelt. Als Ergebnis erhalten wir nach allen Verbindungen und Löschungen 3450 Filme, die die Informationen enthalten, die wir von beiden Websites benötigen.
Ich interessiere mich für den Unterschied in den Bewertungen von Filmen auf zwei Websites, daher werden wir die DELTA-Variable erstellen, die den Unterschied zwischen den Schätzungen von IMDB und Kinopoisk darstellt. Wenn DELTA positiv ist, ist der IMDB-Score höher, wenn negativ, niedriger.
Erstellen Sie zunächst ein Histogramm für den DELTA-Indikator:
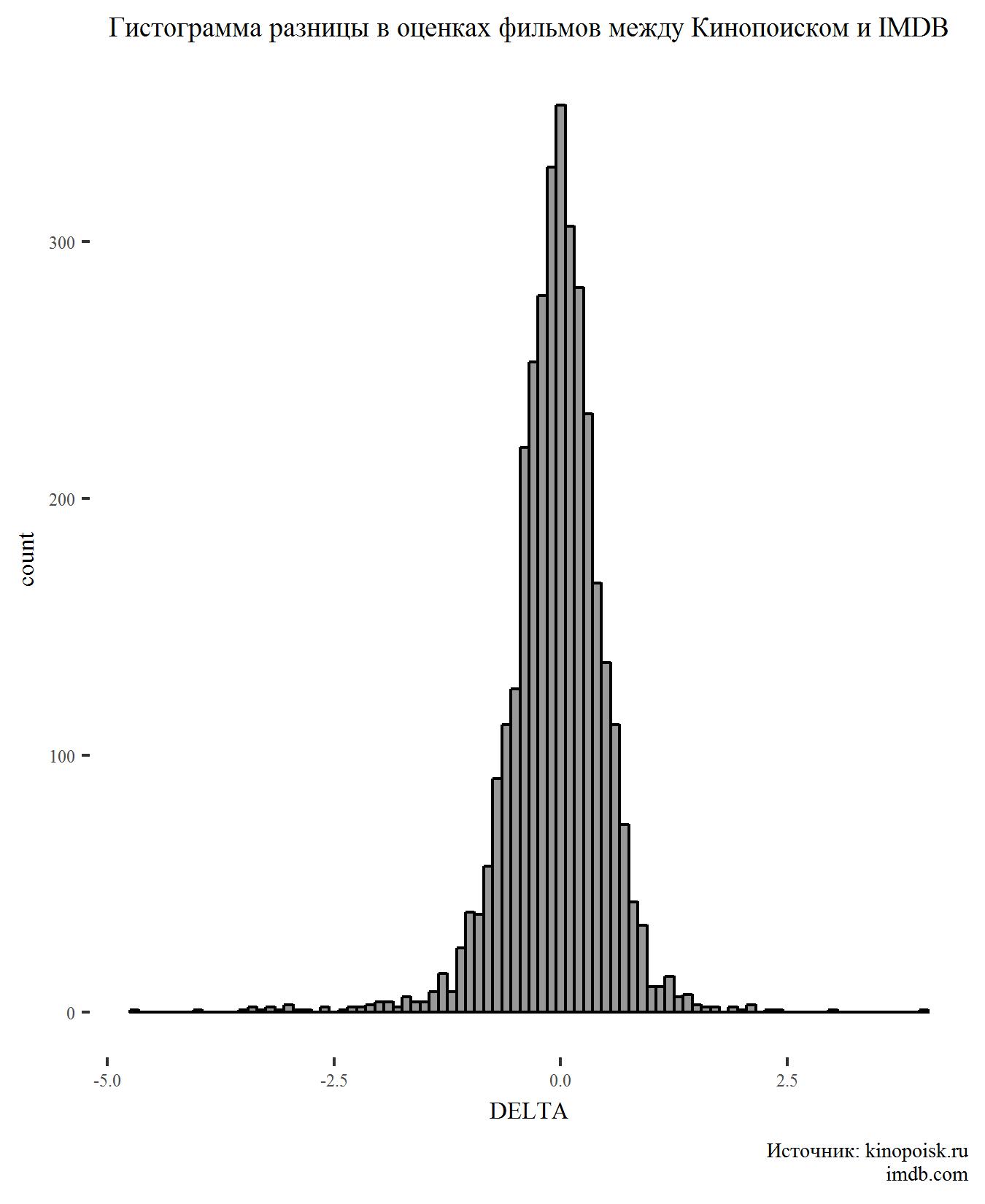
Es gibt nichts Überraschendes auf der Karte. Der Unterschied in den Bewertungen hat eine Normalverteilung und einen Spitzenwert im Bereich von Null, was darauf hindeutet, dass sich die Benutzer der beiden Websites normalerweise auf die Bewertung von Filmen einigen.
Konvergieren, aber nicht ganz. Der t-Test von zwei unabhängigen Proben erlaubt es uns zu sagen, dass die Bewertungen für Kinopoisk höher sind und dieser Unterschied statistisch signifikant ist (p-Wert <0,05).
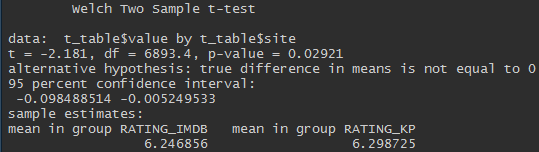
Obwohl der Unterschied signifikant ist, ist er sehr klein.
Als nächstes wollen wir sehen, wie der Unterschied in den Bewertungen von der Anzahl der Stimmen abhängt.
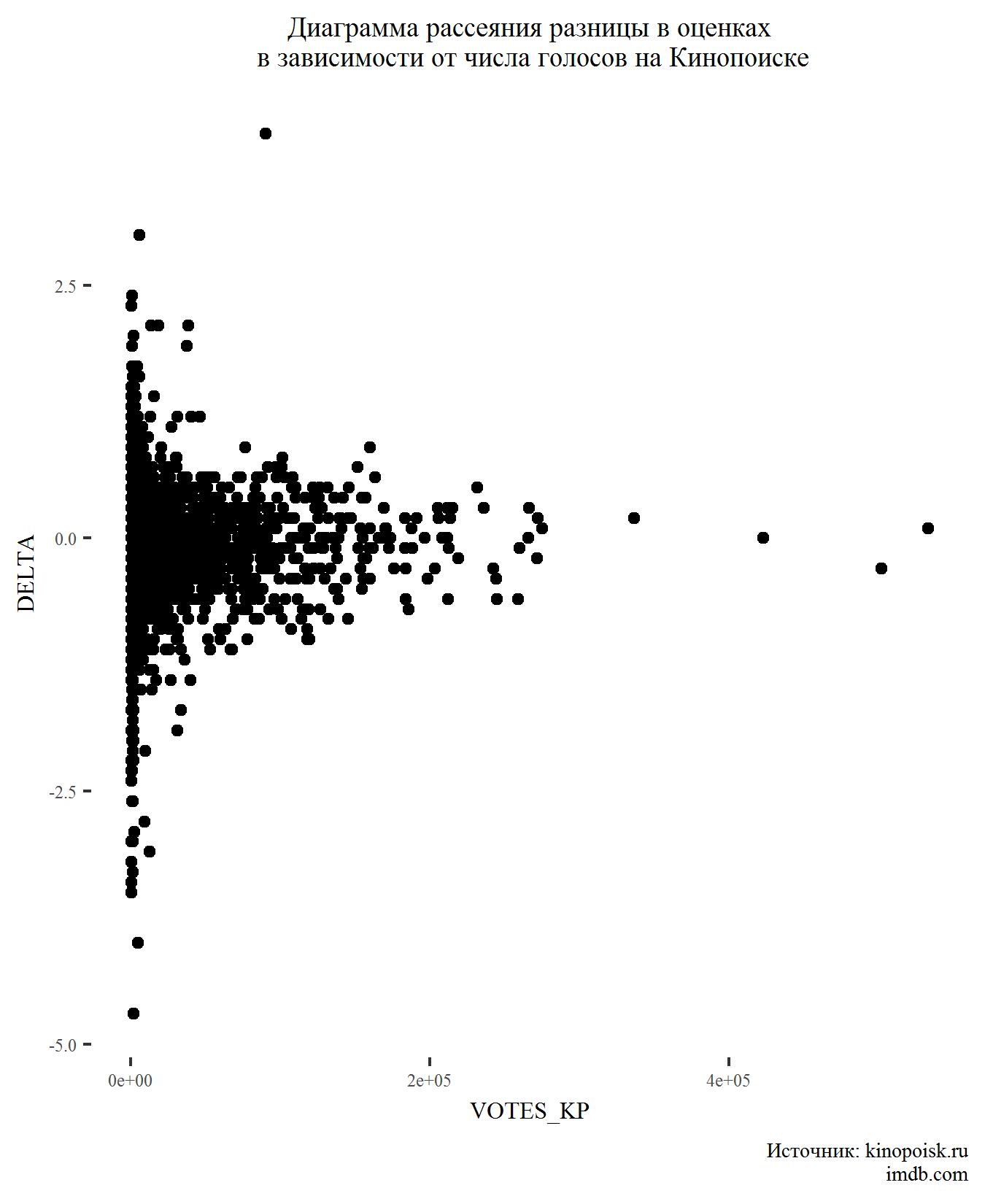
Auch hier nichts Unerwartetes. Filme mit einer großen Anzahl von Stimmen weisen normalerweise nur sehr geringe Bewertungsunterschiede auf.
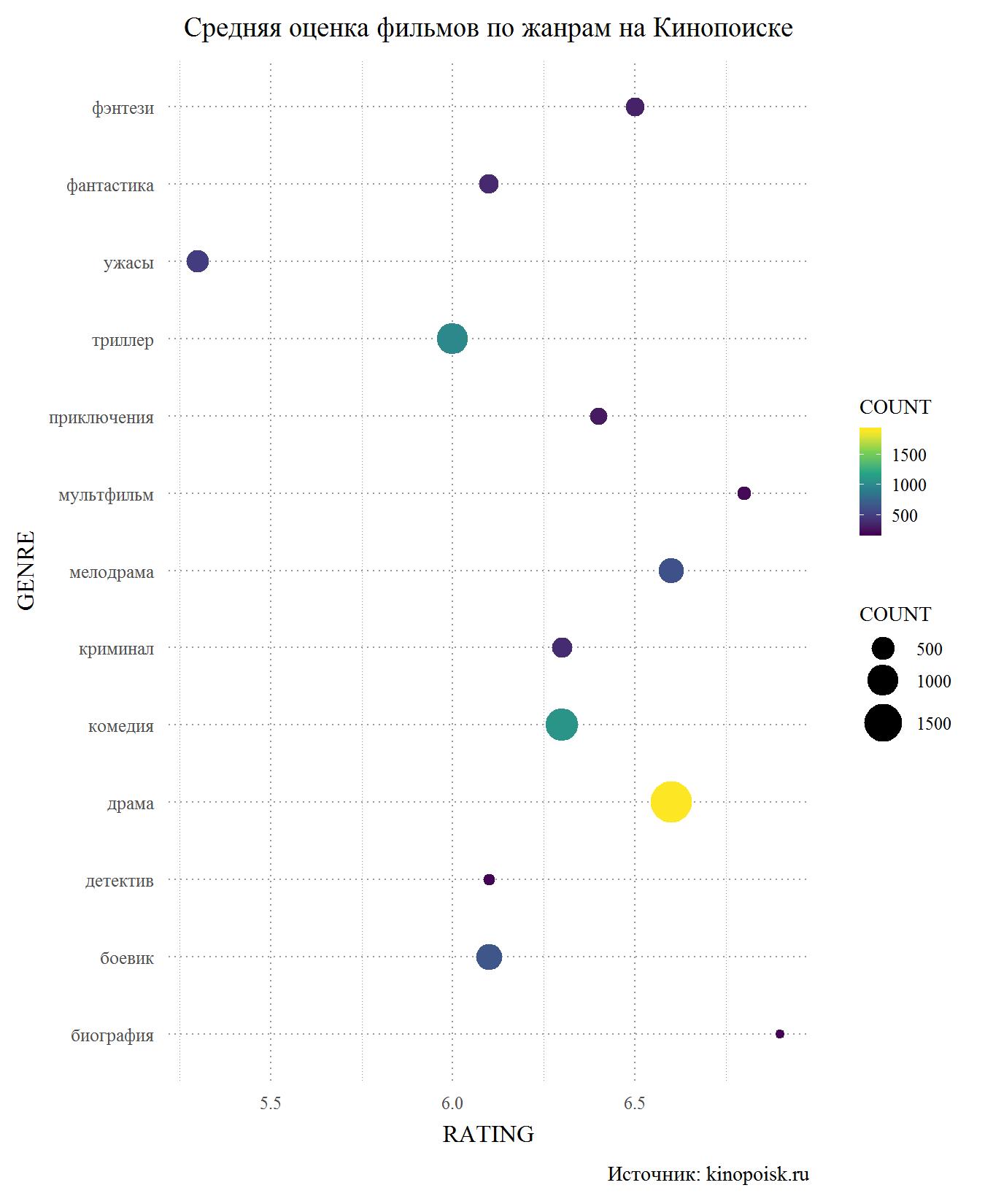
Kommen wir nun zur Bewertung von Filmen nach Genre. Es ist sofort erwähnenswert, dass ein Film bis zu drei Genres haben kann, aber nur eine Bewertung, so dass ein Film "in den Test" und Komödie und Melodram gehen kann.
Beginnen wir mit Kinopoisk. Unter den Genres mit mindestens 150 Auftritten in der Datenbank ist Horror ein offensichtlicher Außenseiter. Auch Low-User bewerten Thriller, Action-Detectives und, was mich überraschte, Science-Fiction. Auf der anderen Seite haben melodramatische Filme auf Kinopoisk einen Knall, mit einer durchschnittlichen Bewertung über 6,5 und nur an zweiter Stelle nach Cartoons und Biopics, die in der Datenbank viel kleiner sind
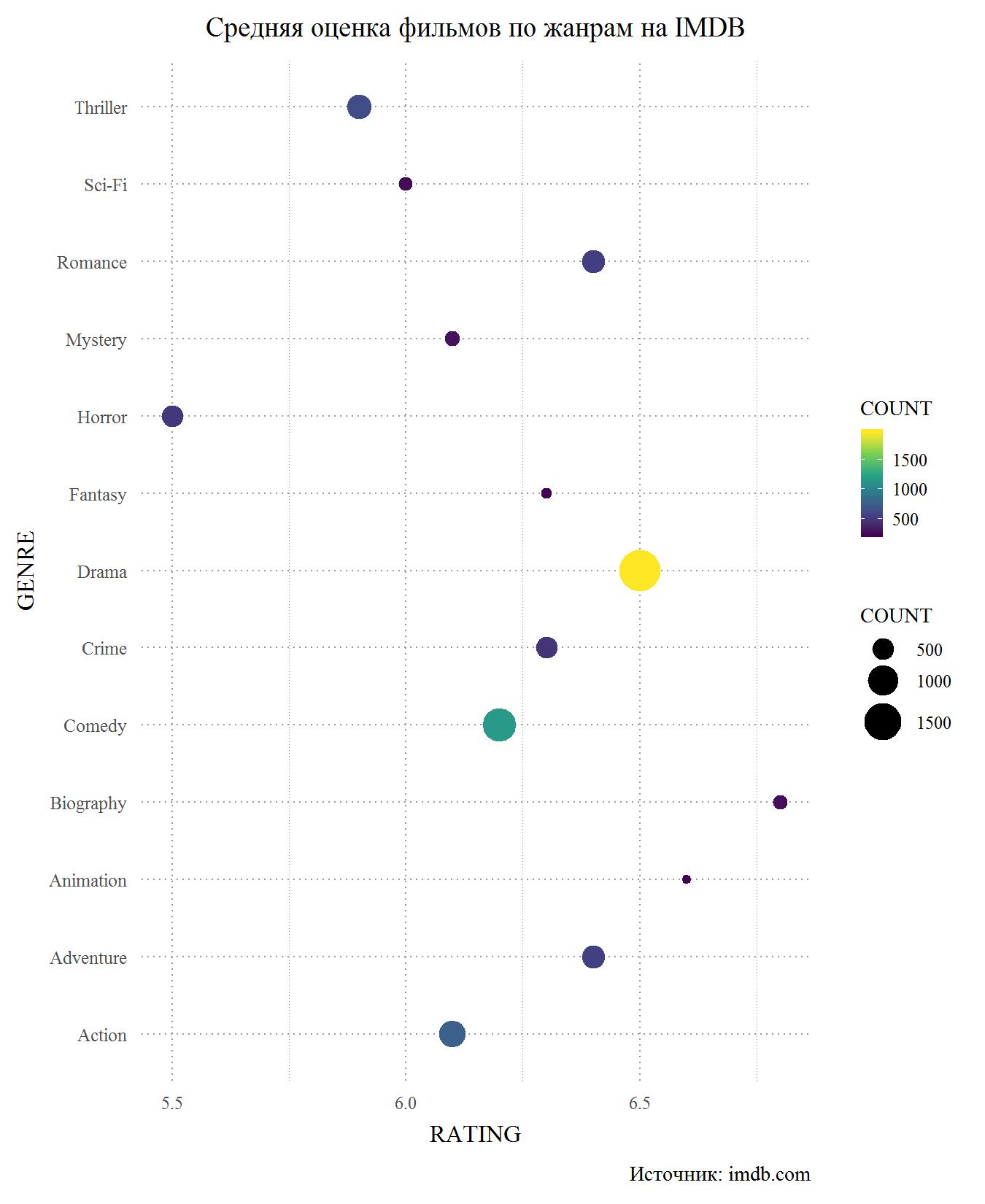
Betrachten Sie nun das gleiche Diagramm, jedoch für IMDB. Grundsätzlich bestätigt er erneut, dass der Unterschied in den Bewertungen zwischen den Standorten unbedeutend ist. Dies ist nicht überraschend, da viele Benutzer Konten auf beiden Websites haben und auf verschiedenen Websites wahrscheinlich keine unterschiedlichen Bewertungen abgeben. Wiederum ist der Hauptverlierer der Horror, und wir können sagen, dass sie das am schlechtesten bewertete Genre von Filmen sind. Es fällt mir schwer zu beurteilen, warum dies passiert, denn der einzige Horrorfilm, den ich in meinem Leben gesehen habe, ist Gremlins. Vielleicht sind es die Schrecken, die das Genre mit dem niedrigsten Budget sind, aus denen das schwache Spiel billiger Schauspieler und ehrlich gesagt schlechte Szenarien stammen. Thriller mit Science-Fiction und IMDB gehören zu den Nachzüglern, aber den Militanten geht es besser. Unter den Führenden sind wieder biografische Filme und Cartoons. Das Drama belegt den dritten Platz, aber die Punktzahl für Melodramen fiel unter 6,5 auf das Niveau von Abenteuerfilmen. Auch auf IMDB unter Komödien.
Fazit und ein wenig zu den "externen Faktoren"
Es gibt zwar einen Unterschied in den Schätzungen (auf Kinopoisk sind sie etwas höher), aber es ist das, ein wenig. Nach verschiedenen Genres ist der große Unterschied auch nicht wahrnehmbar. Blockbuster mit Dutzenden oder sogar Hunderttausenden von Stimmen, wenn sie Unterschiede haben, dann innerhalb von 0,5 Punkten.
Filme mit einer kleinen (insbesondere bei Kinopoisk) Stimmenzahl von bis zu 10.000 haben normalerweise einen großen Unterschied in den Bewertungen. Der größte Unterschied in der Bewertung zugunsten von IMDB ist jedoch der Film mit 30.000 Stimmen auf einer ausländischen Website und mehr als 90.000 auf Kinopoisk. Dies ist die Schöpfung von Alexei Pimanov "Crimea". Ist der Film bei ausländischen Zuschauern so beliebt? Kaum. Höchstwahrscheinlich verwendeten die Filmemacher in Bezug auf IMDB dieselbe "Marketingpolitik" wie in Kinopoisk. Es ist nur so, dass wenn Kinopoisk solche Schätzungen "bereinigt" hat, sie in der IMDB geblieben sind. Ich denke, deshalb gibt es auf der Krim einen "guten kleinen Kinchik".
Für Kommentare, Vorschläge und Beschwerden wäre ich dankbar
Github- Repository-Link
Mein Kreisprofil