Hallo an alle. Ich werde Ihnen etwas über Microservices erzählen, aber aus einem etwas anderen Blickwinkel als Vadim Madison im Beitrag "Was wissen wir über Microservices?" . Im Allgemeinen betrachte ich mich als Datenbankentwickler. Was haben Microservices damit zu tun? Avito verwendet: Vertica, PostgreSQL, Redis, MongoDB, Tarantool, VoltDB, SQLite ... Insgesamt haben wir mehr als 456 Datenbanken für mehr als 849 Dienste. Und irgendwie musst du damit leben.
In diesem Beitrag werde ich Ihnen erzählen, wie wir die Datenerkennung in der Microservice-Architektur implementiert haben. Dieser Beitrag ist eine kostenlose Abschrift meines Berichts mit Highload ++ 2018 , das Video kann hier angesehen werden .

Jeder sollte wissen, wie eine Microservice-Architektur in Bezug auf Basen aufgebaut werden sollte. Hier ist das Muster, mit dem normalerweise jeder beginnt. Es gibt eine gemeinsame Basis zwischen den Diensten. Auf der Folie sind die orangefarbenen Rechtecke Dienste, zwischen denen gibt es eine gemeinsame Basis.
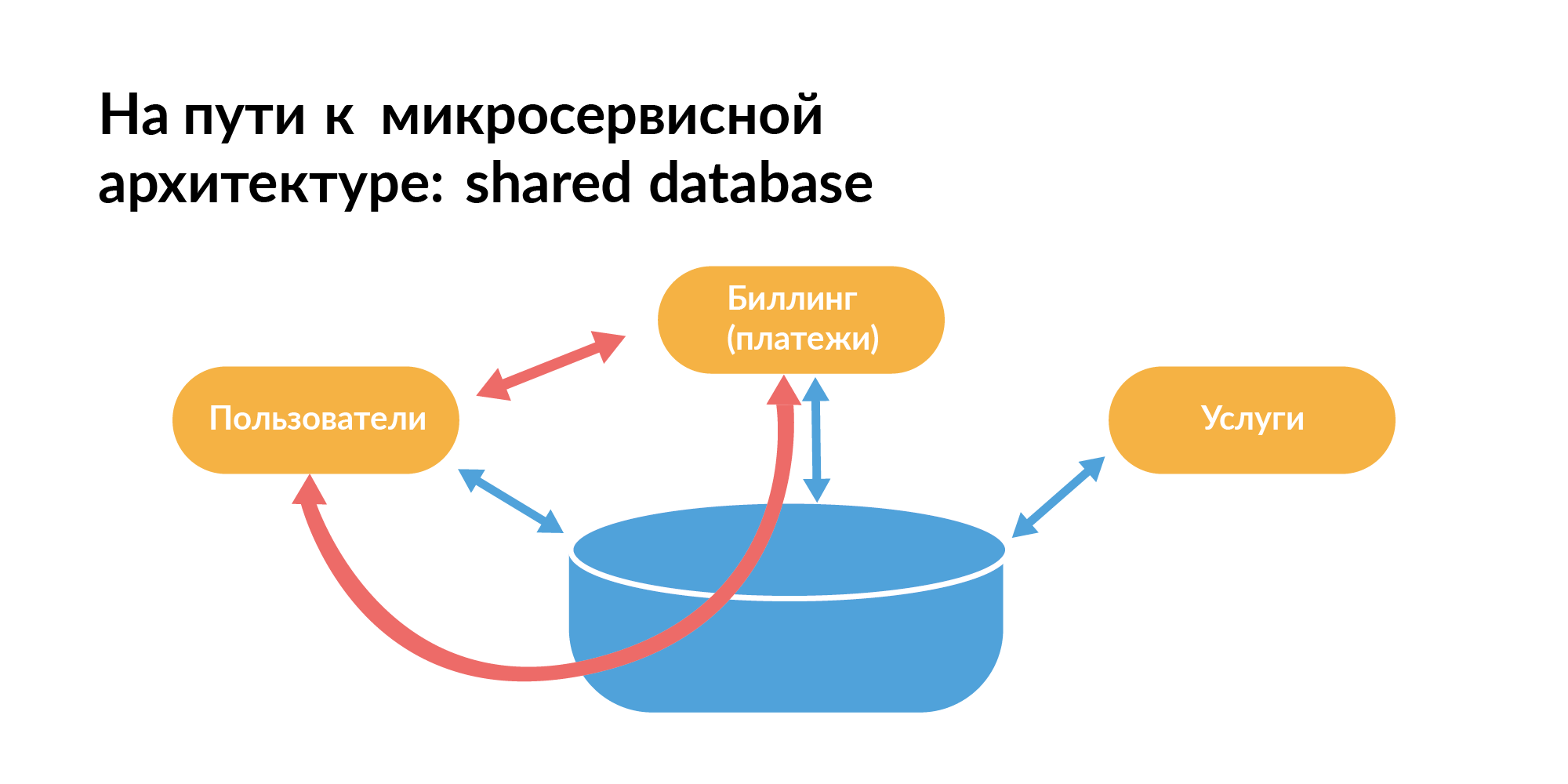
Sie können nicht so leben, da Sie Dienste nicht isoliert testen können, wenn neben der direkten Kommunikation zwischen ihnen auch die Kommunikation über die Datenbank erfolgt. Eine Dienstanforderung kann einen anderen Dienst verlangsamen. Das ist schlecht.

Unter dem Gesichtspunkt der Arbeit mit Datenbanken für die Microservice-Architektur sollte das DataBase-per-Service-Muster verwendet werden - jeder Service verfügt über eine eigene Datenbank. Wenn die Datenbank viele Shards enthält, sollte die Basis gemeinsam genutzt werden, damit sie synchronisiert werden. Dies ist eine Theorie, aber in Wirklichkeit ist es nicht so.

In realen Unternehmen verwenden sie nicht nur Microservices, sondern auch einen Monolithen. Es sind Dienste richtig geschrieben. Und es gibt alte Dienste, die immer noch ein gemeinsames Basismuster verwenden.
Vadim Madison zeigte bei seiner Präsentation dieses Bild mit Verbundenheit. Nur er zeigte es ohne eine Komponente, und das Netzwerk darin war einheitlich. In diesem Netzwerk in der Mitte gibt es einen Punkt, der mit vielen Punkten verbunden ist (Microservices). Dies ist ein Monolith. Es ist klein im Diagramm. Tatsächlich ist der Monolith jedoch groß. Wenn wir über ein echtes Unternehmen sprechen, müssen Sie die Nuancen der Koexistenz von Mikroservice, geborener und aufgeschlossener, aber immer noch wichtiger monolithischer Architektur verstehen.
Wie schreibt ein Monolith auf Planungsebene in eine Microservice-Architektur um? Dies ist natürlich eine Domänenmodellierung. Überall heißt es, dass Sie eine Domänenmodellierung durchführen müssen. Zum Beispiel haben wir in Avito mehrere Jahre lang Microservices ohne Domänenmodellierung erstellt. Dann habe ich es und die Datenbankentwickler aufgenommen. Uns sind vollständige Datenströme bekannt. Dieses Wissen hilft beim Entwerfen eines Domänenmodells.

Die Datenermittlung hat eine klassische Interpretation - so wird mit Daten gearbeitet, die über verschiedene Speicher verteilt sind, um zu aggregierten Schlussfolgerungen zu führen und korrekte Schlussfolgerungen zu ziehen. Das ist eigentlich alles Marketing-Bullshit. In diesen Definitionen wird beschrieben, wie alle Daten von Microservices in den Speicher heruntergeladen werden. Darüber hatte ich vor einigen Jahren Berichte, wir werden nicht weiter darauf eingehen.
Ich erzähle Ihnen von einem anderen Prozess, der dem Prozess der Umstellung auf Microservices näher kommt. Ich möchte einen Weg zeigen, wie Sie die Komplexität eines sich ständig weiterentwickelnden Systems in Bezug auf Daten und Mikrodienste verstehen können. Wo kann man das ganze Bild von Hunderten von Diensten, Stützpunkten, Teams und Menschen sehen? Tatsächlich ist diese Frage die Hauptidee des Berichts.

Um in dieser Microservice-Architektur nicht zu sterben, benötigen Sie einen digitalen Zwilling. Ihr Unternehmen ist die Gesamtheit von allem, was die technologische Infrastruktur bereitstellt. Sie müssen ein angemessenes Bild all dieser Schwierigkeiten erstellen, auf dessen Grundlage Sie Probleme schnell lösen können. Und dies ist kein analytisches Repository.

Welche Aufgaben können wir für einen solchen digitalen Zwilling stellen? Schließlich begann alles mit der einfachsten Datenerkennung.
Fragen:
- Welche Dienste speichern wichtige Daten?
- In welchen personenbezogenen Daten sind keine Daten gespeichert?
- Sie haben Hunderte von Basen. Welche persönlichen Daten gibt es? Und in welchem nicht?
- Wie fließen wichtige Daten zwischen Diensten?
- Zum Beispiel hatte der Dienst keine persönlichen Daten, und dann fing er an, den Bus zu hören, und sie erschienen. Wo werden die Daten kopiert, wenn sie gelöscht werden?
- Wer kann mit welchen Daten arbeiten?
- Wer kann direkt über den Dienst zugreifen, einige über die Datenbank, andere über den Bus?
- Wer kann über einen anderen Dienst das API-Handle (Anfrage) abrufen und etwas herunterladen?
Die Antwort auf diese Fragen ist fast immer ein Diagramm der Elemente, ein Diagramm der Beziehungen. Dieses Diagramm muss mit neuen Daten gefüllt, aktualisiert und gepflegt werden. Wir haben uns entschlossen, dieses Diagramm Persistent Fabric (in Übersetzung - Erinnerung an Fabric) zu nennen. Hier ist seine Visualisierung.
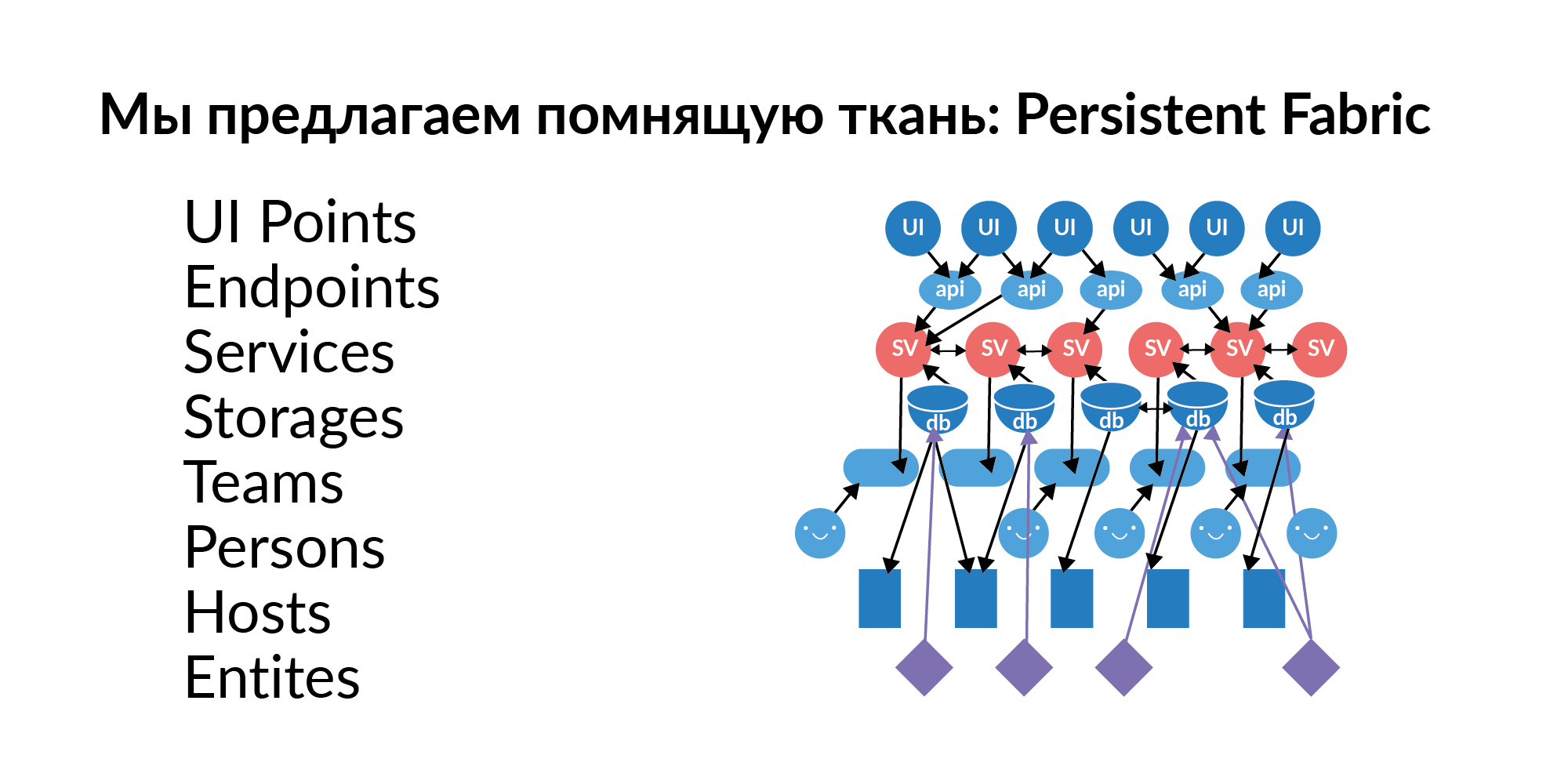
Mal sehen, was in diesem Erinnerungsstoff sein kann.
Schnittstellenpunkte . Dies sind Elemente der Benutzerinteraktion mit der grafischen Oberfläche. Auf einer Seite können sich mehrere UI-Punkte befinden. Dies sind relativ gesehen benutzerdefinierte Schlüsselaktionen.
Endpunkte . UI-Punkte ruckeln Endpunkte. In der russischen Tradition nennt man dies Stifte. Handles von Dienstleistungen. Endpunkte ziehen Dienste.
Dienstleistungen Hunderte von Dienstleistungen. Dienste sind miteinander verbunden. Wir verstehen, welcher Dienst den Dienst ziehen kann. Wir wissen, welcher Aufruf von UI-Punkten welche Dienste in der Kette aufrufen kann.
Grundlagen (im logischen Sinne) . Die Basis als Speicherbegriff klingt schlecht, da sich dieser Begriff auf etwas Analytisches bezieht. Nun betrachten wir die Datenbank als Speicher. Zum Beispiel Redis, PostgreSQL, Tarantool. Wenn ein Dienst eine Datenbank verwendet, werden normalerweise mehrere Datenbanken verwendet.
- Zur langfristigen Datenspeicherung beispielsweise PostgreSQL.
- Redis wird als Cache verwendet.
- Tarantool, das schnell etwas im Datenstrom berechnen kann.
Gastgeber Die Datenbank verfügt über eine Bereitstellung für Hosts. Eine Basis, ein Redis kann tatsächlich auf 16 Maschinen (Master Ring) und ein weiterer 16 Live Slave leben. Dies gibt Aufschluss darüber, auf welche Server Sie den Zugriff beschränken müssen, damit einige wichtige Daten nicht verloren gehen.
Entitäten . Entitäten werden in den Datenbanken gespeichert. Beispiele für Entitäten: Benutzer, Ankündigung, Zahlung. Entitäten können in mehreren Datenbanken gespeichert werden. Und hier ist es wichtig, nicht nur zu wissen, dass diese Entität da ist. Es ist wichtig zu wissen, dass diese Entität einen Speicher hat, der Golden Source ist. Goldene Quelle ist die Basis, auf der eine Entität erstellt und bearbeitet wird. Alle anderen Basen sind funktionale Caches. Ein wichtiger Punkt. Wenn eine Entität, Gott bewahre, zwei goldene Quellen hat, ist eine mühsame Koordination der getrennten Quellen notwendig. Die Entitäten in der Datenbank müssen Zugriff auf den Dienst erhalten, wenn wir diesen Dienst mit neuen Funktionen erweitern möchten.
Teams . Teams, denen die Dienste gehören. Ein Dienst, der nicht zu Teams gehört, ist ein schlechter Dienst. Es fällt ihm schwer, jemanden zu finden, der dafür verantwortlich ist.
Jetzt werde ich stark mit dem Bericht von Vadim Madison korrelieren, weil er erwähnte, dass die Person, die als letzte dort begangen hat, sich in den Diensten widerspiegelt. Dies ist ein guter Ausgangspunkt. Aber auf lange Sicht ist das schlecht, weil die Person, die zuletzt dort begangen hat, kündigen kann.
Daher müssen Sie das Team, die Personen in ihnen und ihre Rolle kennen. Wir haben ein so einfaches Diagramm, in dem sich auf jeder Ebene mehrere hundert Elemente befinden. Kennen Sie ein System, in dem all dies gespeichert werden kann?
Der entscheidende Punkt. Damit dieser beständige Stoff lebt, muss er sich nicht nur einmal füllen. Dienste werden erstellt, sie sterben, Speicher wird zugewiesen, sie bewegen sich auf den Servern, Teams werden erstellt, kaputt gemacht, Personen wechseln zu anderen Teams. Entitäten sind neu, werden zu neuen Diensten hinzugefügt und gelöscht. Endpunkte werden erstellt, registriert und Benutzertrajektorien aus Sicht der GUI werden ebenfalls erneuert. Das Wichtigste ist nicht, dass Sie es irgendwo technisch aufbewahren müssen. Das Wichtigste ist, dass jede Schicht aus beständigem Stoff frisch und aktuell ist. Dass es aktualisiert wird.
Ich schlage vor, durch die Schichten zu gehen. Ich werde veranschaulichen, wie wir es machen. Ich werde zeigen, wie dies auf der Ebene einzelner Ebenen möglich ist.

Informationen über das Team können der Organisationsstruktur von 1C entnommen werden. Hier möchte ich veranschaulichen, dass Persistent Fabric nicht das gesamte riesige Diagramm ausfüllen muss, um es zu füllen. Jede Schicht muss korrekt gefüllt sein.

Informationen über Personen können aus LDAP entnommen werden. Eine Person kann in verschiedenen Teams unterschiedliche Rollen übernehmen. Das ist absolut normal. Jetzt haben wir das Avito People-System erstellt und daraus die Bindung von Personen an Teams und deren Rollen. Das Wichtigste ist, dass solche einfachen Daten so gespeichert werden, dass sie zumindest Links zu den Enden der Links enthalten, sodass die Teamnamen den Teams aus der 1C-Organisationsstruktur entsprechen.
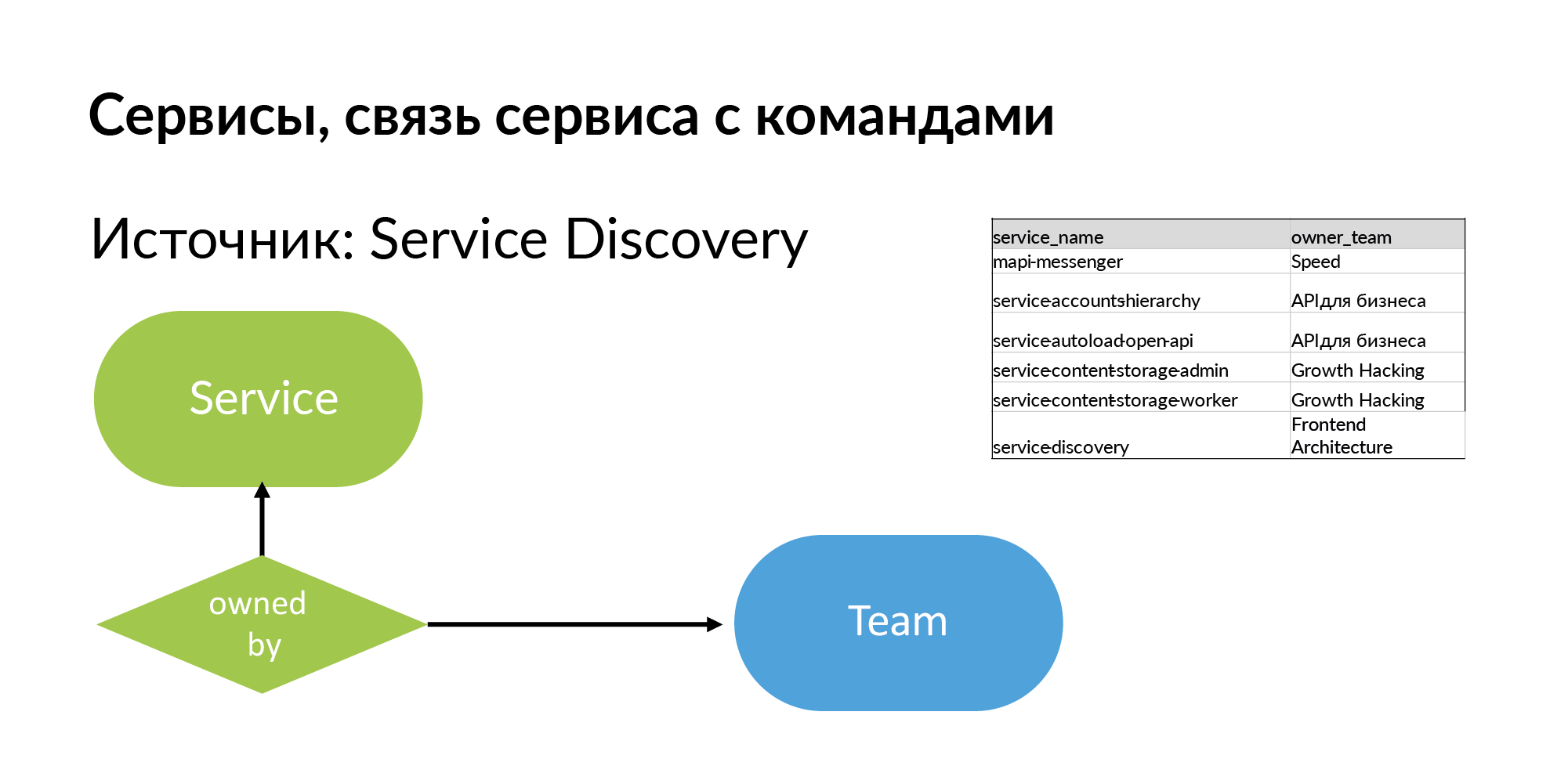
Dienstleistungen Für den Service benötigen Sie den Namen und das Team, dem er gehört. Die Quelle ist Service Discovery. Dies ist das System, das Vadim Madison unter dem Namen Atlas erwähnte. Atlas ist ein allgemeines Dienstleistungsregister.
Es ist hilfreich zu verstehen, dass fast alle Systeme wie Atlas Informationen über 95% der Dienste speichern. 5% der Dienste in solchen Systemen fehlen, weil alte Dienste ohne Registrierung in Atlas erstellt. Und wenn Sie anfangen, mit diesem Schema zu arbeiten, spüren Sie, was Ihnen fehlt.

Speicher sind generische Repositories. Es kann PostgreSQL, MongoDB, Memcache, Vertica sein. Wir haben mehrere Quellen für die Speichererkennung. NoSQL-Datenbanken verwenden ihre eigene Hälfte des Atlas. Für Informationen zu PostgreSQL-Datenbanken wird Yaml-Parsing verwendet. Sie möchten jedoch ihre Speichererkennung korrekter gestalten.
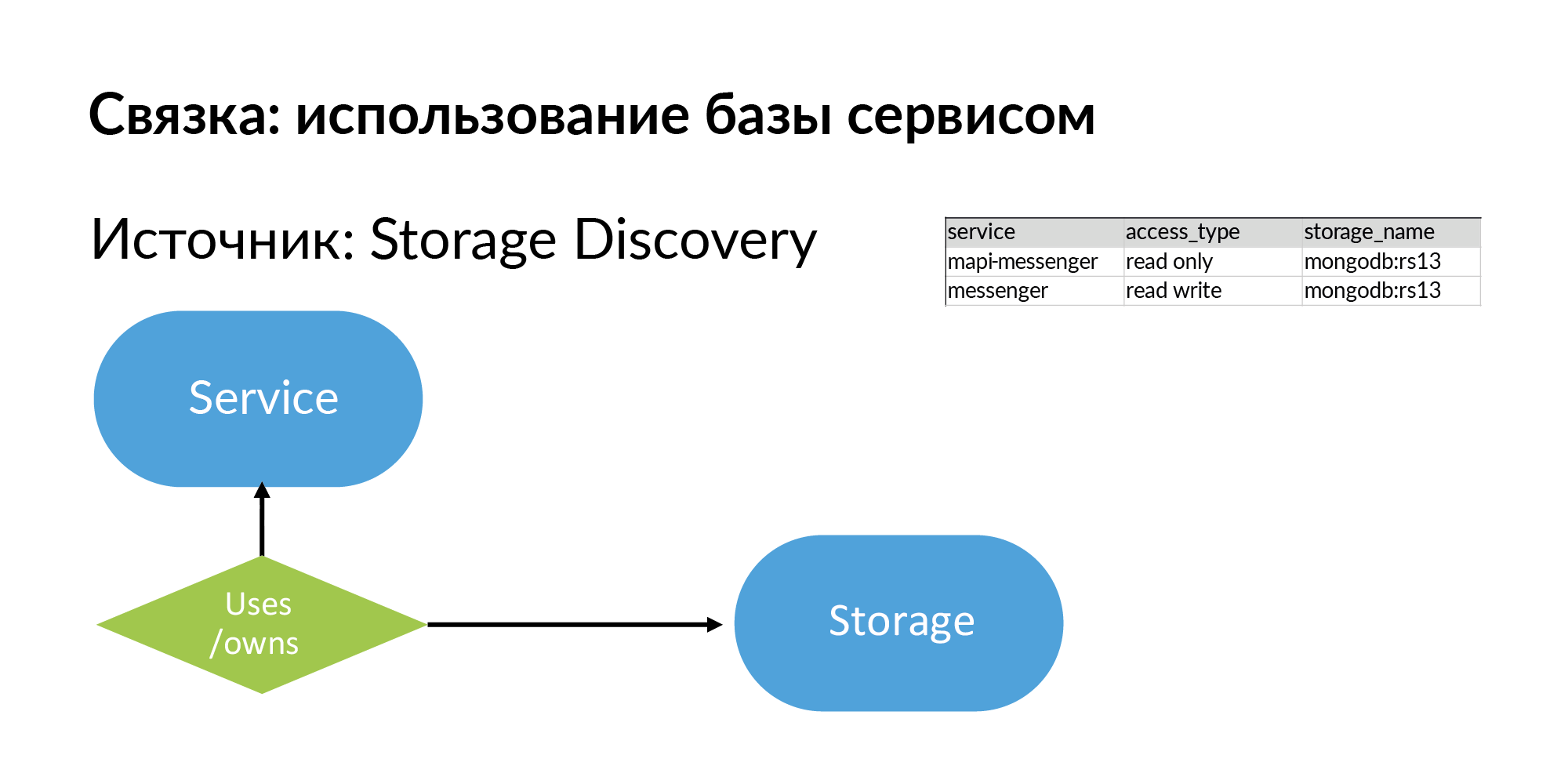
Speicher und Informationen darüber, was der Dienst verwendet, gut oder besitzt (dies sind verschiedene Arten) Speicher. Alles, was ich beschrieben habe, ist im Prinzip recht einfach und kann sogar in Google Sheets ausgefüllt werden.
Was kann man damit machen? Stellen wir uns vor, dies ist eine Grafik. Wie arbeite ich mit dem Diagramm? Fügen Sie es der Diagrammbasis hinzu. Zum Beispiel in Neo4j. Dies sind bereits Beispiele für reale Abfragen und Beispiele für die Ergebnisse dieser Abfragen.
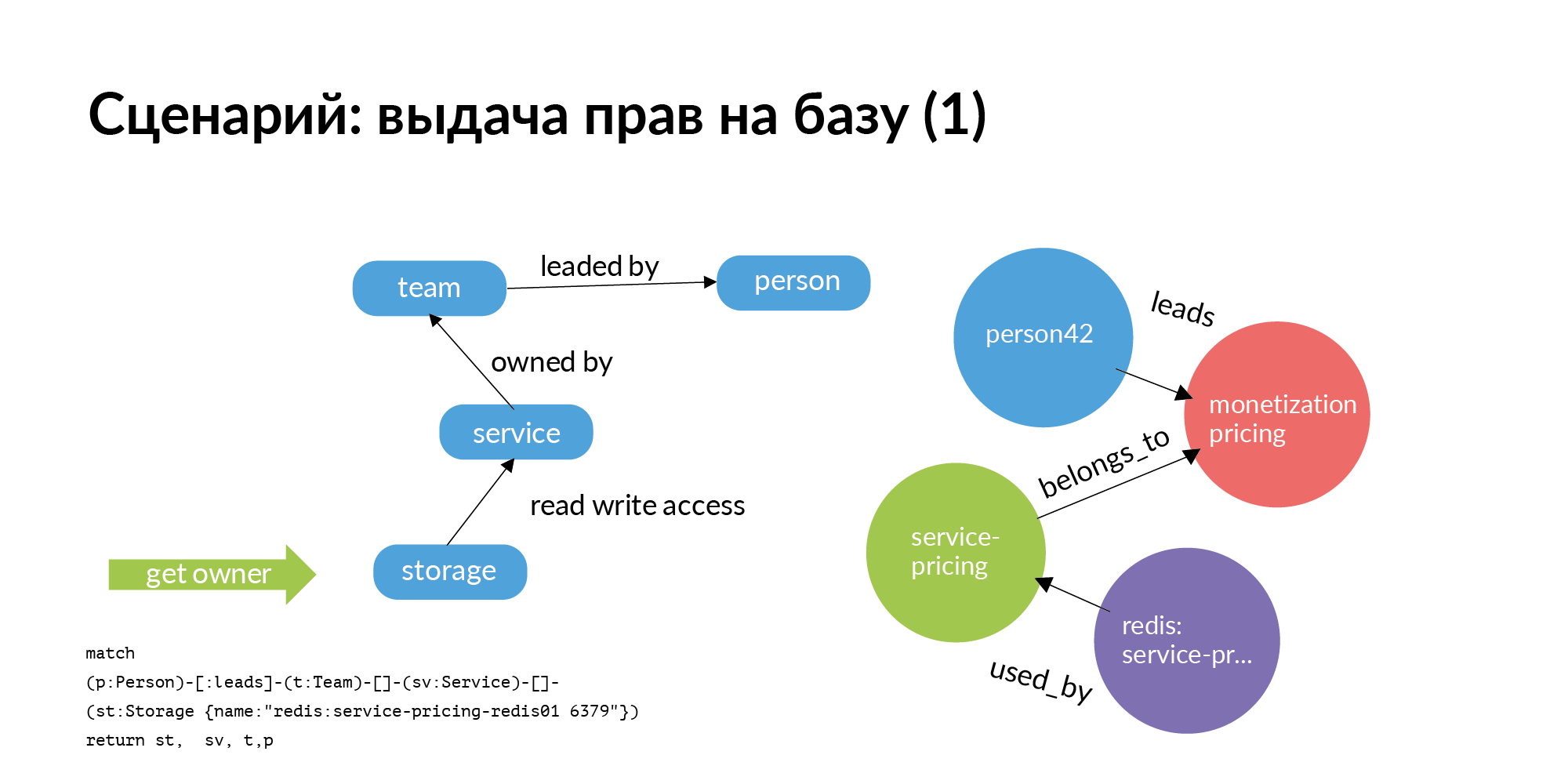
Das erste Szenario. Wir müssen der Basis Rechte erteilen. Die Basis sollte ausschließlich in Betrieb sein. Es sollte nur diesen Service und nur Mitglieder des Teams enthalten, dem der Service gehört. Aber wir leben in der realen Welt. Sehr oft finden es andere Teams nützlich, zur Basis eines anderen Dienstes zu gehen. Frage: Wen soll man nach der Gewährung von Rechten fragen? Das wirklich große Problem ist, dass Hunderte von Stützpunkten verstehen, wer verantwortlich ist. Trotz der Tatsache, dass derjenige, der es erstellt hat, vor langer Zeit gekündigt oder in eine andere Position versetzt wurde oder sich überhaupt nicht daran erinnert, wer damit arbeitet.
Und hier ist die einfachste Grafikabfrage (Neo4j). Sie benötigen Zugriff auf den Speicher. Sie wechseln vom Speicher zum Dienst, dem es gehört. Gehen Sie zu dem Team, dem der Service gehört. Für den Service erfahren Sie, wen dieses TechLead-Team hat. In Avito haben Produktteams einen technischen Manager und einen Produktmanager, die bei den Grundlagen nicht helfen können. Nur die Hälfte der Anfrage wird tatsächlich auf der Folie angezeigt. Der Zugriff auf Speicher ist keine atomare Operation. Um auf den Speicher zuzugreifen, müssen Sie auf die Server zugreifen, auf denen er installiert ist. Dies ist eine ziemlich interessante separate Aufgabe.
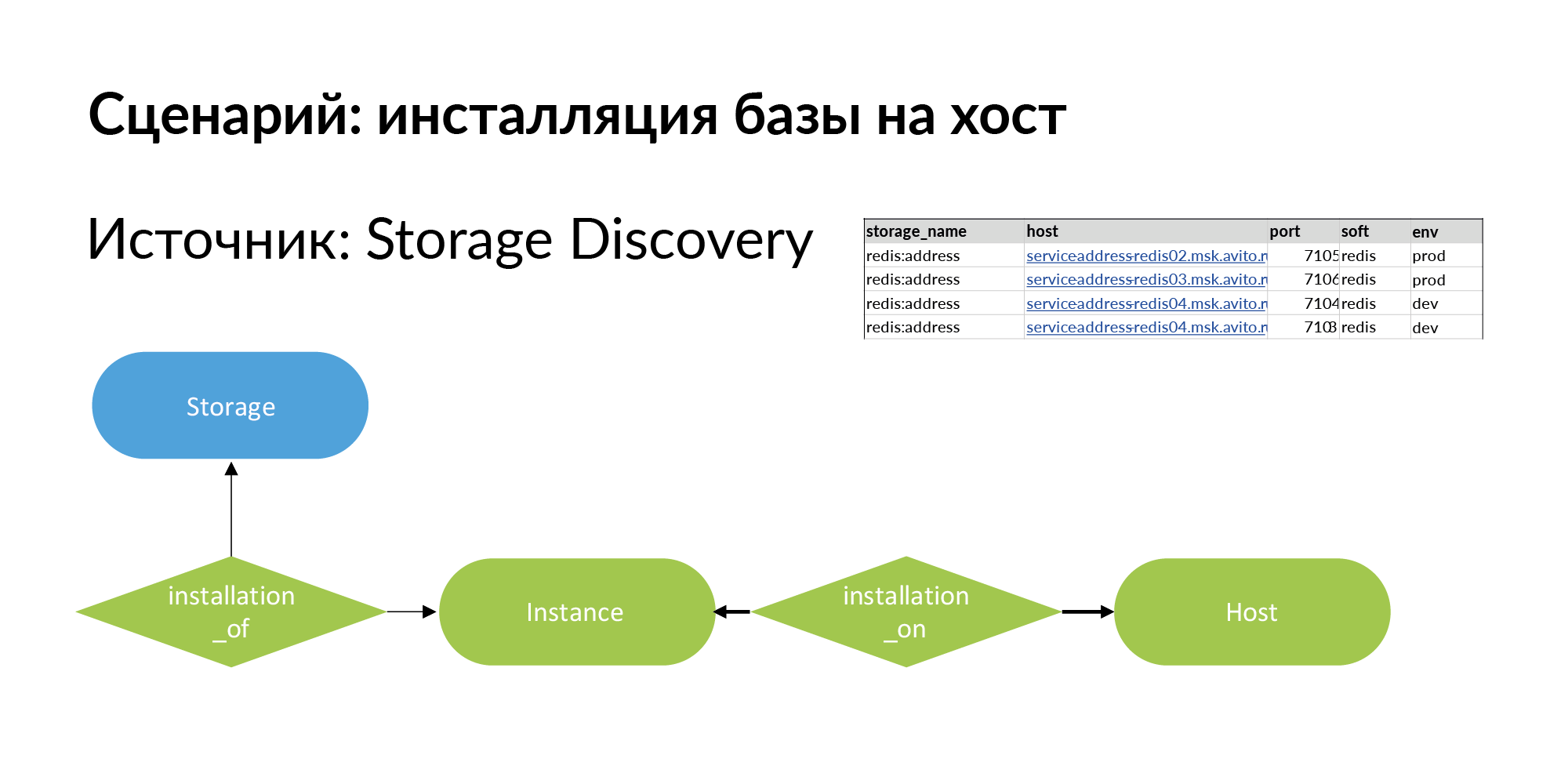
Um dies zu lösen, fügen wir eine neue Entität hinzu. Dies ist eine Installation. Hier ist das terminologische Problem. Es gibt Speicher, zum Beispiel Redis Base (Redis: Adresse). Es gibt einen Host - es kann sich um eine physische Maschine, einen lxc-Container oder Kubernetes handeln. Die Installation des Speichers auf dem Host wird als Instanz bezeichnet.
Es kann vier Installationen auf drei Hosts haben, wie im obigen Beispiel gezeigt. Es ist ratsam, Speicher für die Produktion auf separaten physischen Maschinen zu installieren, um die Leistung zu steigern. In einer Entwicklungsumgebung müssen Sie lediglich auf einem Host installieren und Redis verschiedene Ports zuweisen.

Der erste Antrag auf Erteilung von Rechten an der Basis ging an den Kopf. Der Leiter bestätigte, dass die Rechte gewährt werden können.
Als nächstes kommt der zweite Teil der Anfrage. Die zweite Anforderung vom Speicher geht an die Instanz und den Host. Diese Anforderung berücksichtigt alle Installationen für die entsprechende Umgebung. Auf der Folie befindet sich ein Beispiel für eine Produktionsumgebung. Auf dieser Grundlage werden bereits Rechte zum Herstellen einer Verbindung zu bestimmten Hosts und bestimmten Ports erteilt. Dies war ein Beispiel für eine Zuschussanfrage für einen Mitarbeiter außerhalb des Teams.

Stellen Sie sich ein Beispiel vor, wenn ein Team einen neuen Mitarbeiter einstellen muss. Er muss Zugriff (für den Anfang - schreibgeschützt) auf alle Dienste und auf alle Speicher dieses Befehls erhalten. Auf der Folie das echte Team mit einer unvollständigen Auswahl. Grüne Kreise sind Teamleiter. Rosa Kreise sind Teams. Gelb sind Dienstleistungen. Einige gelbe Dienste haben blauen Speicher. Graue sind Gastgeber. Violett ist die Installation von Speicher auf Hosts. Dies ist ein Beispiel für eine kleine Einheit. Es gibt jedoch viele Einheiten, deren Dienste nicht 7, sondern 27 sind. Für solche Einheiten ist das Bild groß. Wenn Sie Persistent Fabric verwenden, können Sie darin Anforderungen stellen und Antworten in einer Liste erhalten.

Lassen Sie uns weiterhin unseren intelligenten Stoff füllen und über Geschäftseinheiten sprechen. Entitäten in Avito sind Ankündigungen, Benutzer, Zahlungen usw. Aus meinen Veröffentlichungen ( HP Vertica, Entwerfen eines Data Warehouse, Big Data , Vertica + Anchor Modeling = Fangen Sie an, Ihren Pilz zu züchten) über Data Warehouses wissen Sie, dass es in Avito Hunderte dieser Entitäten gibt. Tatsächlich müssen nicht alle protokolliert werden. Woher bekomme ich eine Liste der Entitäten? Aus dem Analyse-Repository. Sie können Informationen darüber hochladen, woher diese Entität stammt. In der ersten Phase reicht dies aus.
Dieses Wissen entwickeln wir weiter: Für jede Entität erstellen wir eine Liste der Repositorys, in denen sie sich befinden. Wir weisen auch darauf hin, dass der Speicher die Entität als Cache speichert oder der Speicher die Entität als goldene Quelle speichert, dh, es ist ihre primäre Quelle.

Wenn Sie diese Spalte ausfüllen, haben Sie die Möglichkeit, Anfragen zu stellen. Sie haben eine Entität, und Sie müssen verstehen: In welchen Diensten lebt die Entität, wo spiegelt sie sich wider, in welchem Speicher, auf welchen Hosts ist sie installiert? Wenn Sie beispielsweise personenbezogene Daten verarbeiten, müssen Sie Protokolldateien zerstören. Dazu ist es sehr wichtig zu verstehen, auf welchen physischen Computern die Protokolldateien verbleiben können.
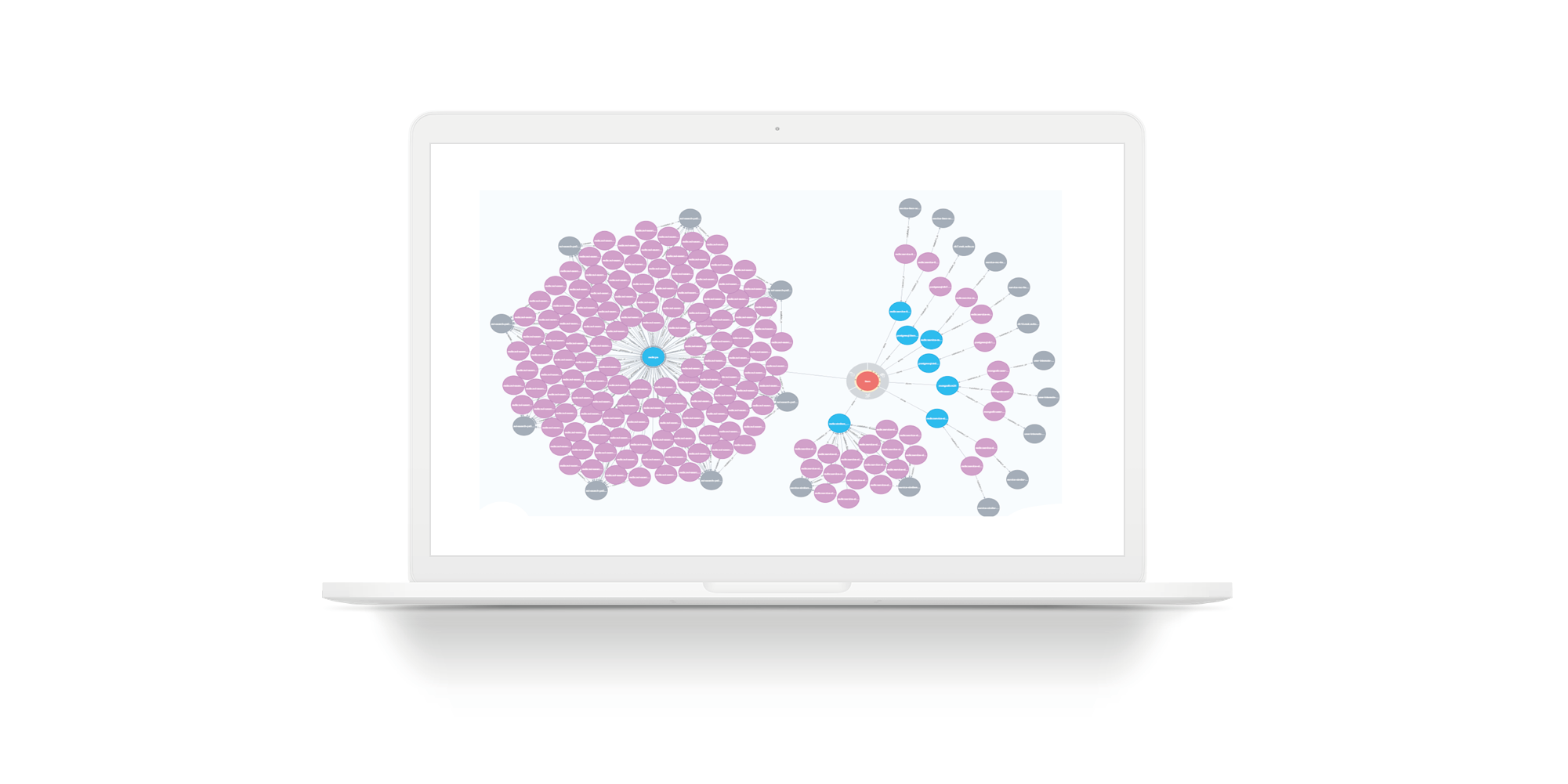
Die Folie zeigt eine einfache Abfrage für eine imaginäre Entität. Der Speicherplatz wird reduziert, sodass das Diagramm auf die Folie passt. Rote Kreise sind Einheiten. Blaue Kreise sind die Basen, auf denen sich diese Entität befindet. Der Rest ist wie auf den vorherigen Folien: Graue Kreise sind Hosts, lila Kreise sind Speicherinstallationen auf Hosts.
Wenn Sie PCI DSS verwenden möchten, müssen Sie den Zugriff auf bestimmte Entitäten beschränken. Dazu müssen Sie den Zugriff auf die grauen Kreise einschränken. Wenn Sie einen Echtzeitzugriff benötigen, schließen wir den Zugriff auf die lila Kreise. Dies sind statische Informationen.
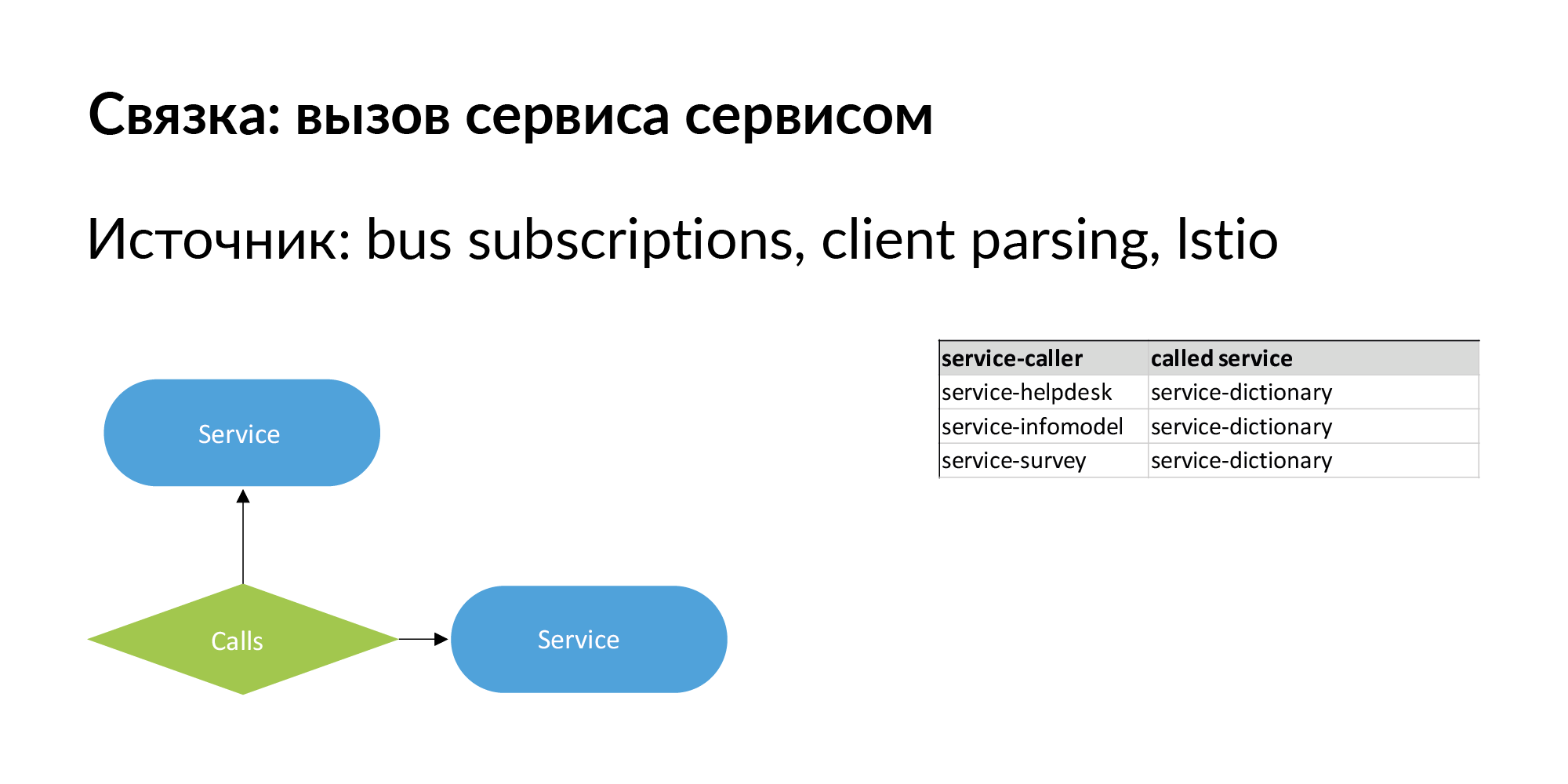
Wenn wir über Microservice-Architektur sprechen, ist das Wichtigste, dass sie sich ändert. Es ist wichtig, nicht nur eine hierarchische Beziehung zwischen Entitäten zu haben, sondern auch Geschwisterbeziehungen. Eine Reihe von Diensten ist ein Beispiel für einstufige Verbindungen, die wir gut gepumpt und genutzt haben. Ein Bündel des Formulars "Service ruft Service an". Es gibt Informationen zu direkten Aufrufen - der Dienst ruft die API eines anderen Dienstes auf.
Es sollten auch Informationen zur Verbindung des Formulars vorhanden sein: Dienst Nr. 1 sendet Ereignisse an den Bus (Warteschlange), und Dienst Nr. 2 hat dieses Ereignis abonniert. Dies ist wie eine asynchrone langsame Verbindung, die über einen Bus verläuft. Diese Beziehung ist auch im Hinblick auf die Datenbewegung wichtig. Über solche Links können Sie den Betrieb von Diensten überprüfen, wenn sich die Version des Dienstes, für den sie abonniert sind, geändert hat.
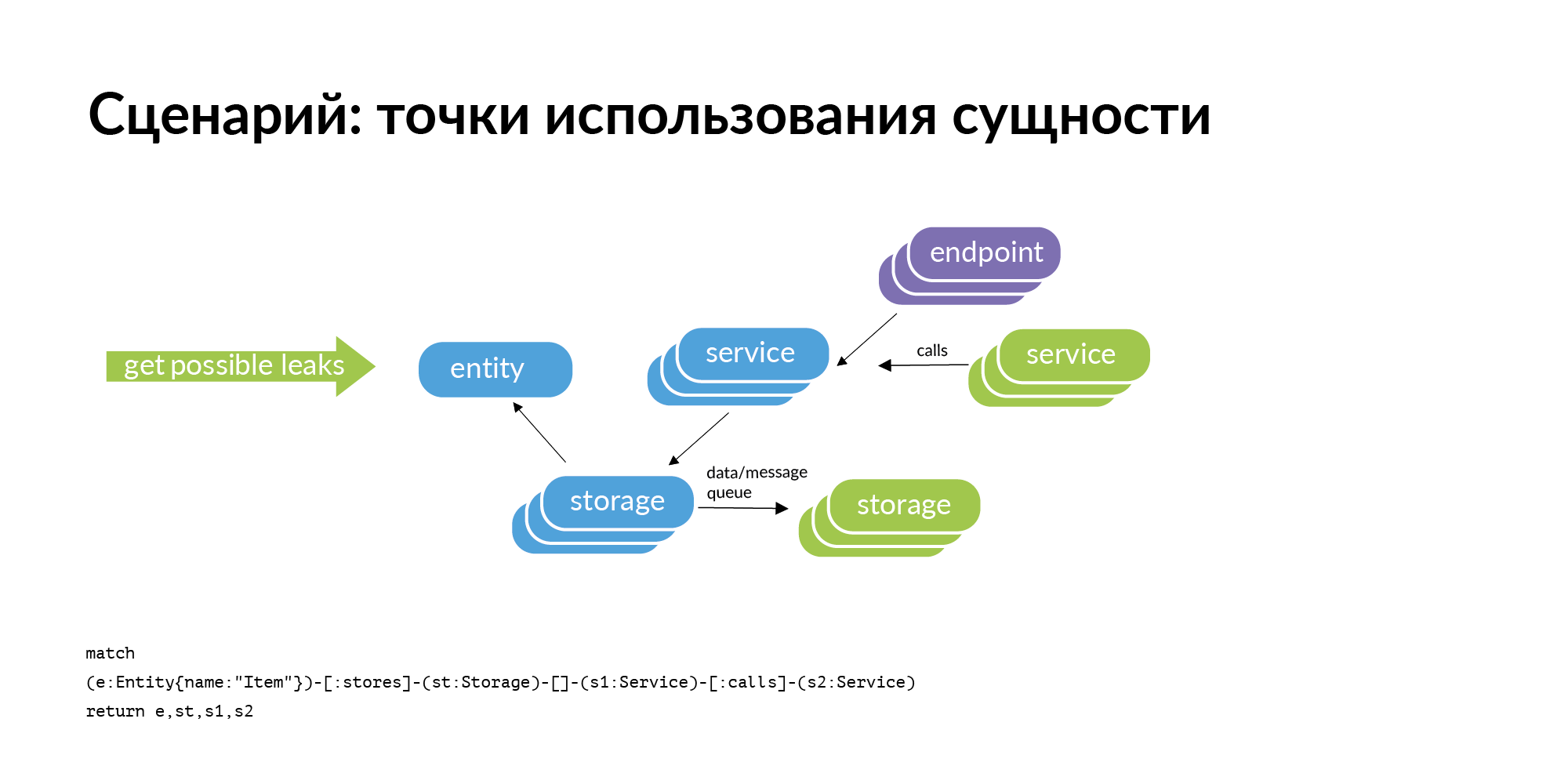
Es gibt eine Entität und wir wissen, dass sie in einem bestimmten Speicher gespeichert ist. Wenn wir das Problem betrachten, Punkte für die Verwendung der Entität zu finden, ist die offensichtliche Abfrage, die bei uns auftritt, die Perimeterprüfung. Speicher gehören zu einigen Diensten. Wo kann diese Entität aus dem Umkreis austreten (kopiert werden)? Es kann durch Serviceanrufe auslaufen. Der Dienst kontaktierte, empfing und behielt den Benutzer. Es kann durch die Reifen lecken. Reifen können Sie mit RabbitMQ, Londiste, miteinander verbinden. Auf der Londiste-Folie haben wir sie noch nicht geladen. Die Anrufe sind aber bereits geladen.
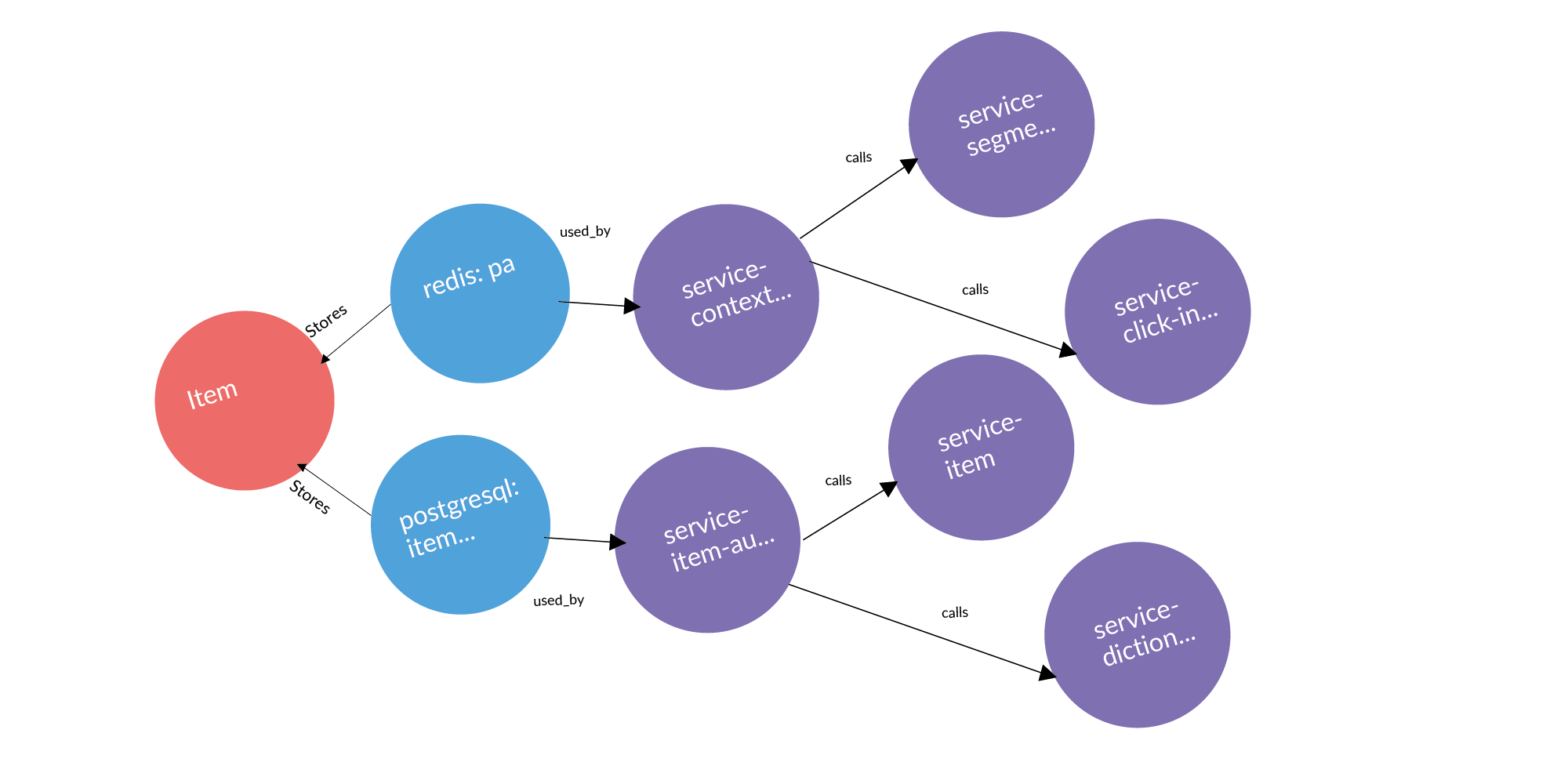
Hier ist ein Beispiel für eine echte Anfrage: eine Anzeige, zwei Datenbanken, in denen sie gespeichert ist, zwei Dienste, denen diese Datenbanken gehören. Nach drei Spalten stehen Dienste, die mit Diensten arbeiten, denen diese Entität gehört. Dies sind potenzielle Leckstellen, die hinzugefügt werden sollten.

Endpunkte. Vadim erwähnte, dass Sie mithilfe der Dokumentation eine Registrierung von Endpunktdiensten erstellen können. Sie können diese Informationen auch über die Überwachung abrufen. Wenn Endpoint wichtig ist, werden es von den Entwicklern selbst zur Überwachung hinzugefügt. Wenn der Endpunkt nicht überwacht wird, benötigen wir ihn nicht.
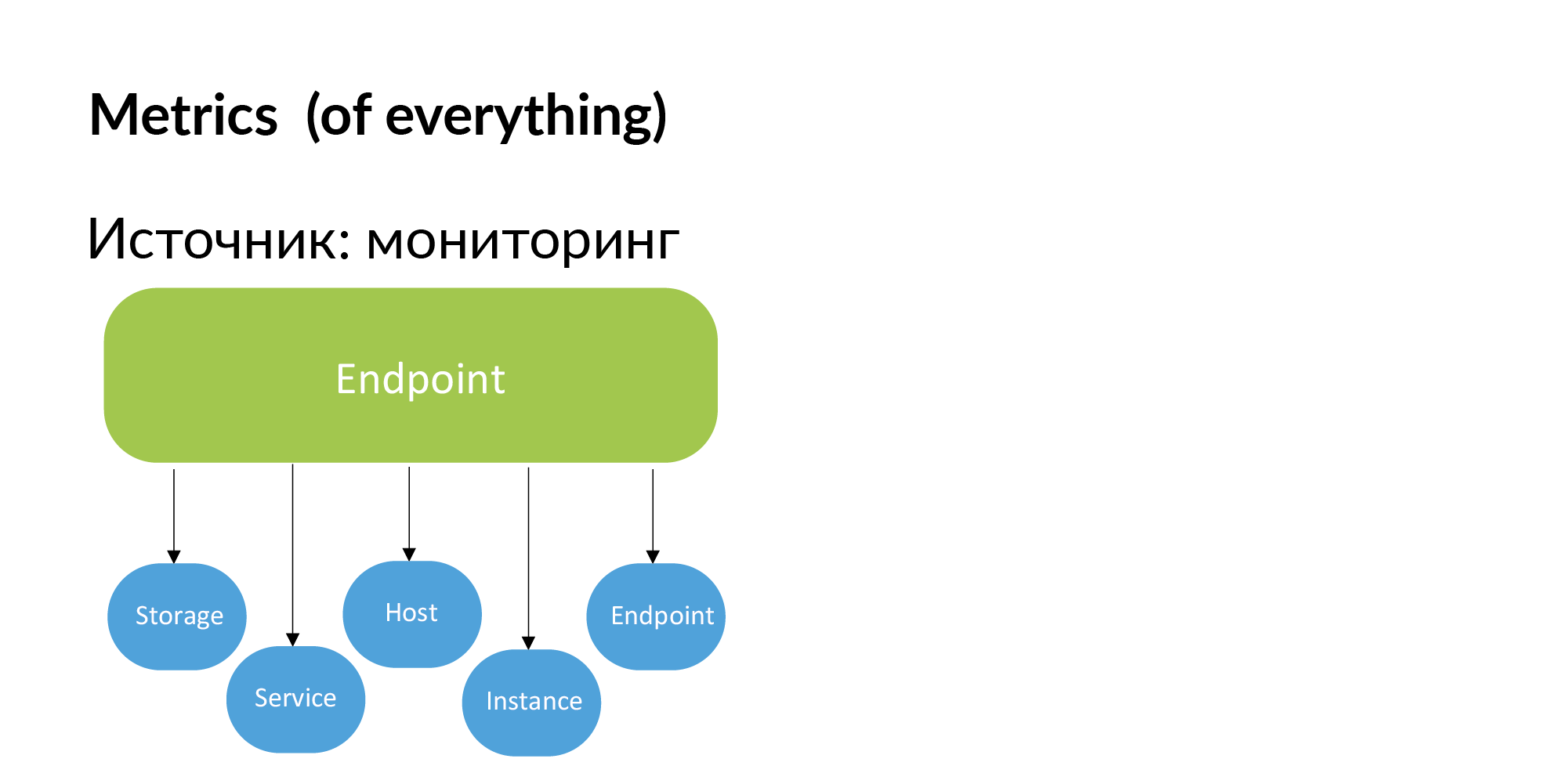
Dementsprechend können Metriken aus der Überwachung erhalten werden. Binden von Metriken an Speicher, Dienste, Hosts, Instanzen (Datenbank-Shards) und Endpunkte.

Wenn beispielsweise ein Fehler auftritt, gibt der Endpunkt einen HTTP-Code von 500 aus. Um die Ursache des Problems zu ermitteln, müssen Sie eine Anforderung für diesen Endpunkt stellen. Gehen Sie vom Endpunkt zum Dienst, zu den Diensten, die dieser Dienst aufruft, von den Diensten zum Speicher, vom Speicher zur Instanz und zu den Hosts.
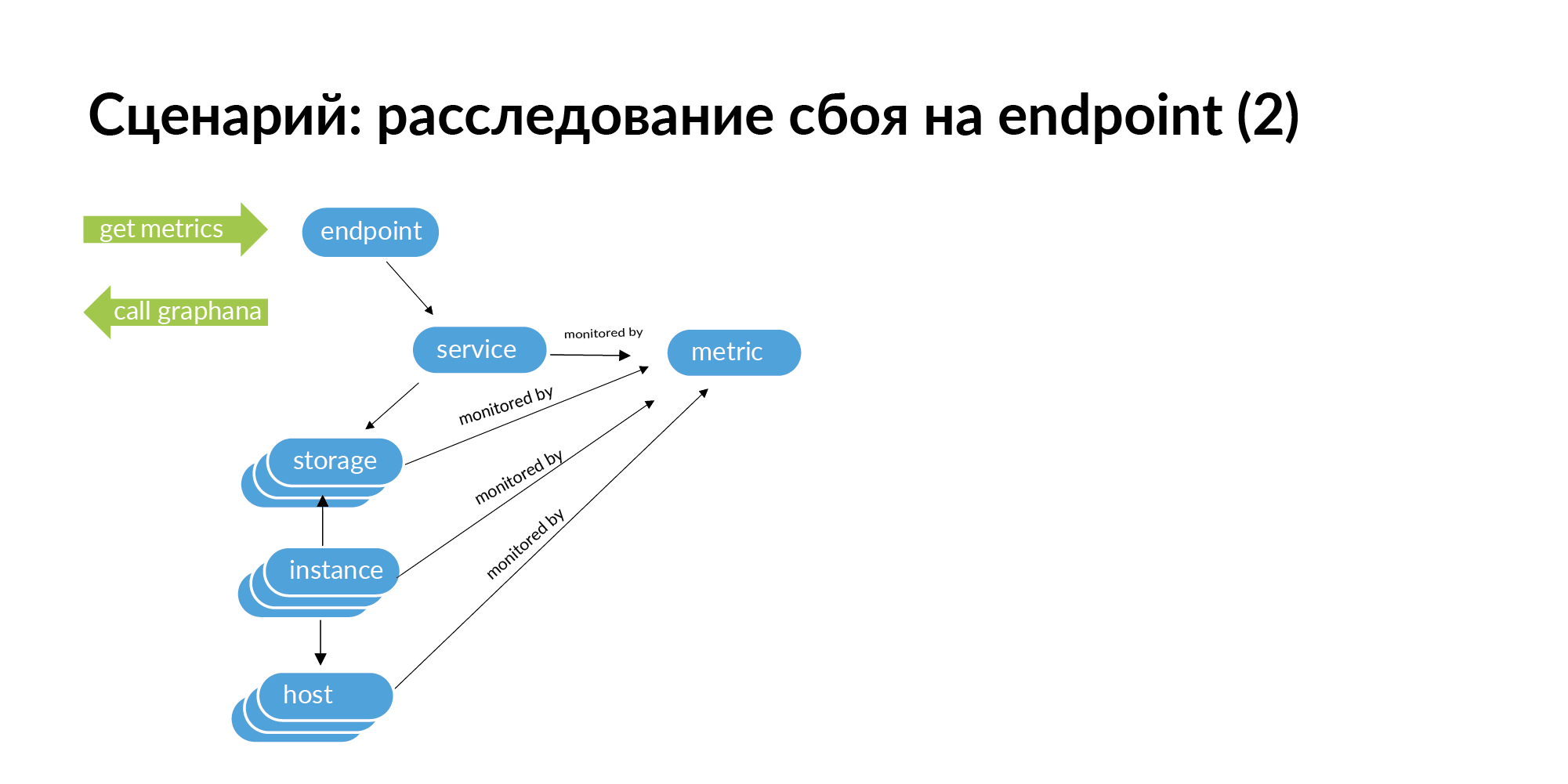
Wenn Sie dieses Diagramm durchgehen, können Sie auf seiner Grundlage eine Liste von Kennungen für die Überwachung erhalten. Sie können nach diesem Endpunkt in der gesamten Kette suchen, was zu einem Fehler führen kann. In der Microservice-Architektur kann ein Fehler am Endpunkt durch einen Netzwerkfehler auf einem Server verursacht werden, auf dem ein Datenbank-Shard bereitgestellt wird. Dies zeigt sich in der Überwachung, aber bei einer großen Servicestruktur ist es sehr mühsam, alle Services in der Überwachung zu überprüfen.

Testen. Um einen Microservice angemessen zu testen, müssen Sie den Service mit anderen Services überprüfen, die für die Arbeit erforderlich sind. Sie müssen in Ihrer Testumgebung die aufgerufenen Dienste erhöhen. Und für die angerufenen Dienste erhöhen Sie alle Basen. In unserem Erinnerungsstoff erhalten wir einen zusammenhängenden Untergraphen. In dieser Spalte werden nicht alle Verbindungen benötigt, einige können vernachlässigt werden. Dieser Teilgraph kann als vollständig geschlossenes System auf Last getestet werden.
Es wäre jetzt großartig, das Avito-Entitätsdiagramm zu zeigen, in dem isolierte Teilgraphen von Mikrodiensten, die unabhängig voneinander erstellt werden können, getestet und in der Produktion eingeführt werden können. Tatsächlich stellte sich heraus, dass der Anrufuntergraph von fast jedem Mikrodienst in den Monolithen eintritt und diesen verlässt. Dies ist ein Beispiel für die Tatsache, dass, wenn Sie Microservices entwickeln und nicht über solche Konsequenzen nachdenken, die Microservice-Architektur ohne Monolithen immer noch nicht funktioniert und keine isolierten Tests zulässt.
, . , . . .
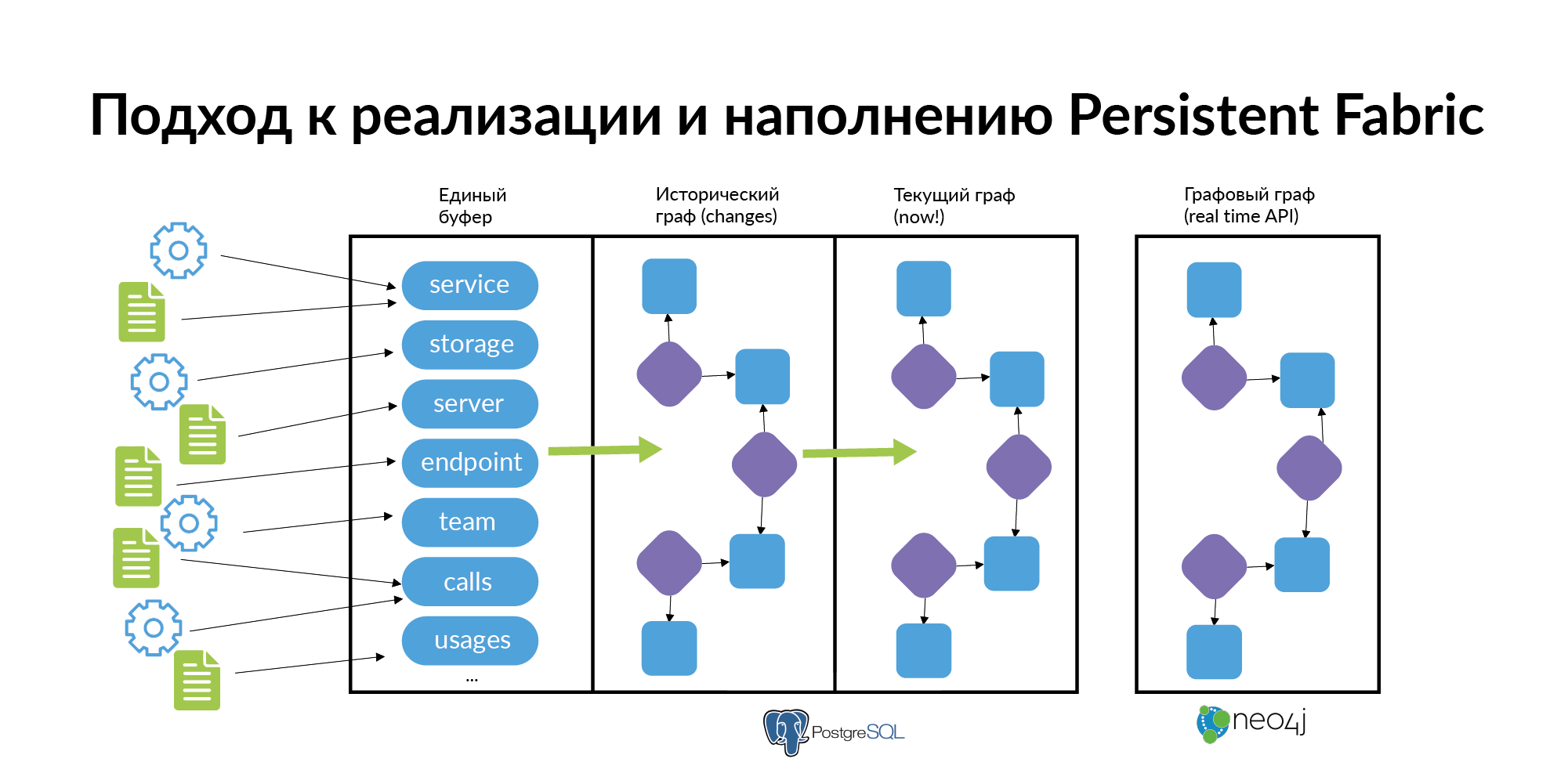
— , . .
- . . . . storage. — . endpoint. , , .. .
- . «» . , , , connection, connection , . , . ( , Anchor Modeling ). . « ». . Neo4j, .
- , . . , UI points frontend , backend , storage DBA, DevOps , .
in-progress
.
(Londiste, PGQ, RabbitMQ).
. UI points . . (Persistent Fabric), UI points, Endpoint, . , , , , .