CleverDATA entwickelt eine Plattform für die Arbeit mit Big Data. Insbesondere ist es auf unserer Plattform möglich, mit Informationen aus Online-Einkaufsschecks zu arbeiten. Unsere Aufgabe war es zu lernen, wie man die Textdaten von Schecks verarbeitet und daraus Schlussfolgerungen über Verbraucher zieht, um die entsprechenden Merkmale für den Datenaustausch zu erstellen. Es war natürlich, sich mit maschinellem Lernen zu befassen, um dieses Problem zu lösen. In diesem Artikel möchten wir auf die Probleme eingehen, die bei der Klassifizierung von Texten von Online-Schecks aufgetreten sind.
QuelleUnser Unternehmen entwickelt Lösungen für die Monetarisierung von Daten. Eines unserer Produkte ist der 1DMC-Datenaustausch, mit dem Sie Daten aus externen Quellen anreichern können (mehr als 9000 Quellen, das tägliche Publikum umfasst etwa 100 Millionen Profile). Die Aufgaben, bei deren Lösung 1DMC hilft, sind Marketingfachleuten bekannt: Aufbau ähnlicher Segmente, breit angelegte Medienunternehmen, gezielte Werbekampagnen für ein hochspezialisiertes Publikum usw. Wenn Ihr Verhalten dem Verhalten der Zielgruppe eines Geschäfts nahe kommt, fallen Sie wahrscheinlich in das ähnliche Segment. Wenn Informationen über Ihre Abhängigkeit von einem Interessengebiet aufgezeichnet wurden, können Sie an einer hochspezialisierten gezielten Werbekampagne teilnehmen. Gleichzeitig werden alle Gesetze zu personenbezogenen Daten umgesetzt, Sie erhalten Werbung, die für Ihre Interessen relevanter ist, und Unternehmen setzen ihr Budget effektiv ein, um Kunden anzulocken.
Informationen zu Profilen werden im Austausch in Form verschiedener vom Menschen interpretierter Attribute gespeichert:
Dies kann eine Information sein, dass eine Person eine Motorausrüstung besitzt, beispielsweise einen Motorrad-Hubschrauber. Oder dass eine Person ein Interesse an Lebensmitteln einer bestimmten Art hat, zum Beispiel ein Vegetarier.
Problemstellung und Lösungswege
Vor kurzem hat 1DMC Daten von einem der Steuerdatenbetreiber erhalten. Um sie in Form von Austauschprofilattributen darzustellen, wurde es notwendig, mit Prüftexten in Rohform zu arbeiten. Hier ist ein typischer Schecktext für einen der Kunden:
Daher besteht die Aufgabe darin, die Prüfung mit den Attributen abzugleichen. Wenn man maschinelles Lernen anzieht, um das beschriebene Problem zu lösen, besteht zunächst der Wunsch,
Lehrmethoden ohne Lehrer auszuprobieren (unbeaufsichtigtes Lernen). Der Lehrer informiert über die richtigen Antworten, und da wir diese Informationen nicht haben, könnten Unterrichtsmethoden ohne Lehrer gut zum zu lösenden Fall passen. Eine typische Unterrichtsmethode ohne Lehrer ist das Clustering, bei dem die Trainingsstichprobe in stabile Gruppen oder Cluster unterteilt wird. In unserem Fall müssen wir nach dem Gruppieren von Texten nach den Wörtern die resultierenden Cluster mit Attributen vergleichen. Die Anzahl der eindeutigen Attribute ist ziemlich groß, daher war es wünschenswert, manuelles Markup zu vermeiden. Ein anderer Ansatz für den Unterricht ohne Lehrer für Texte ist die Themenmodellierung, mit der Sie die Hauptthemen in nicht platzierten Texten identifizieren können. Nach der Verwendung der thematischen Modellierung müssen die erhaltenen Themen mit Attributen verglichen werden, die ich ebenfalls vermeiden wollte. Darüber hinaus ist es möglich, die semantische Nähe zwischen dem Text der Prüfung und der Textbeschreibung des Attributs basierend auf einem beliebigen Sprachmodell zu verwenden. Die Experimente haben jedoch gezeigt, dass die Qualität von Modellen, die auf semantischer Nähe basieren, für unsere Aufgaben nicht geeignet ist. Aus geschäftlicher Sicht müssen Sie sicher sein, dass eine Person Jujitsu mag und deshalb Sportartikel kauft. Es ist rentabler, keine Zwischen-, kontroversen und zweifelhaften Schlussfolgerungen zu ziehen. Daher sind unbeaufsichtigte Lernmethoden leider nicht für die Aufgabe geeignet.
Wenn wir unbeaufsichtigte Lernmethoden aufgeben, ist es logisch, sich überwachten Lernmethoden und insbesondere der Klassifizierung zuzuwenden. Der Lehrer informiert über die wahren Klassen, und ein typischer Ansatz besteht darin, eine Klassifizierung in mehreren Klassen durchzuführen. In diesem Fall wird die Aufgabe jedoch durch die Tatsache erschwert, dass wir zu viele Klassen erhalten (durch die Anzahl der eindeutigen Attribute). Es gibt noch eine weitere Funktion: Attribute können in mehreren Gruppen an denselben Texten arbeiten, d. H. Die Klassifizierung sollte multilabel sein. Beispielsweise können Informationen, dass eine Person eine Abdeckung für ein Smartphone gekauft hat, Attribute enthalten wie: Eine Person, die ein Gerät wie Samsung mit einem Galaxy-Telefon besitzt, die Attribute einer Deppa Sky-Hülle kauft und im Allgemeinen Zubehör für Telefone kauft. Das heißt, mehrere Attribute einer bestimmten Person sollten gleichzeitig im Profil aufgezeichnet werden.
Um die Aufgabe in die Kategorie "Ausbildung mit einem Lehrer" zu übersetzen, benötigen Sie ein Markup. Wenn Menschen auf ein solches Problem stoßen, stellen sie Gutachter ein und erhalten im Austausch für Geld und Zeit ein gutes Markup und erstellen Vorhersagemodelle aus dem Markup. Dann stellt sich oft heraus, dass das Markup falsch war und die Prüfer verbunden werden müssen, um regelmäßig zu arbeiten, weil Neue Attribute und neue Datenanbieter werden angezeigt. Eine alternative Möglichkeit ist die Verwendung von Yandex. Toloki. Sie können damit die Kosten für Prüfer senken, garantieren jedoch keine Qualität.
Es gibt immer eine Option, um einen neuen Ansatz zu finden, und es wurde beschlossen, diesen Weg zu gehen. Wenn es eine Reihe von Texten für ein Attribut gäbe, wäre es möglich, ein binäres Klassifizierungsmodell zu erstellen. Texte für jedes Attribut können aus Suchanfragen abgerufen werden. Für die Suche können Sie die Textbeschreibung des Attributs verwenden, die sich in der Taxonomie befindet. In dieser Phase stoßen wir auf das folgende Merkmal: Die Ausgabetexte sind nicht so vielfältig, dass sie ein starkes Modell daraus bilden, und um eine Vielzahl von Texten zu erhalten, ist es sinnvoll, auf die Texterweiterung zurückzugreifen.
Texterweiterung
Für die Texterweiterung ist es logisch, das Sprachmodell zu verwenden. Das Ergebnis der Arbeit des Sprachmodells sind Einbettungen - dies ist eine Abbildung vom Raum der Wörter in den Raum der Vektoren einer bestimmten festen Länge, und die Vektoren, die Wörtern entsprechen, deren Bedeutung nahe beieinander liegt, befinden sich nebeneinander im neuen Raum und weit entfernt in der Bedeutung. Für die Aufgabe der Texterweiterung ist diese Eigenschaft der Schlüssel, da in diesem Fall nach Synonymen gesucht werden muss. Für eine zufällige Menge von Wörtern im Namen eines Taxonomieattributs wird eine zufällige Teilmenge ähnlicher Elemente aus dem Textrepräsentationsraum abgetastet.
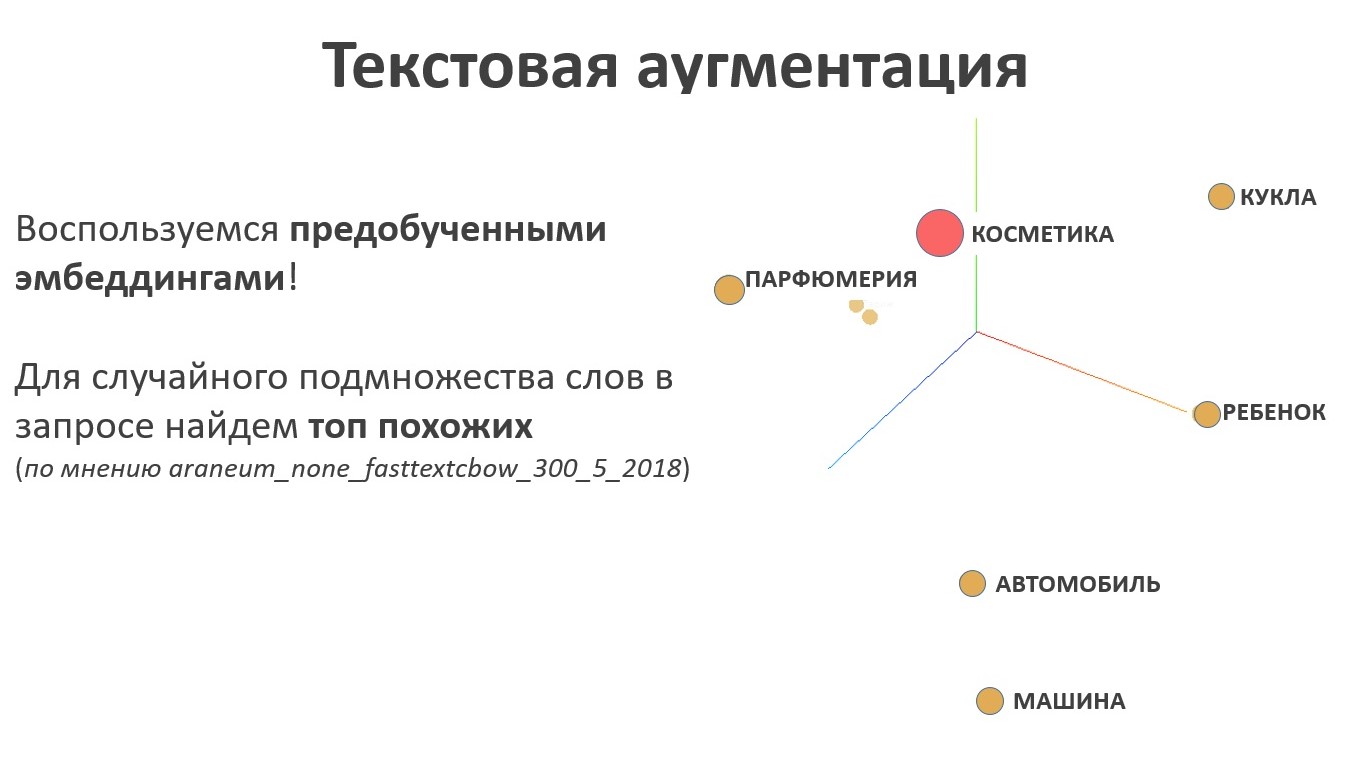
Schauen wir uns die Erweiterung anhand eines Beispiels an. Eine Person interessiert sich für das mystische Genre des Kinos. Wir probieren das Beispiel aus, erhalten verschiedene Texte, die an den Crawler gesendet werden können, und sammeln Suchergebnisse. Dies ist eine positive Stichprobe für das Klassifizierertraining.
Und wir wählen das negative Sample einfacher aus, wir probieren die gleiche Anzahl von Attributen, die nicht mit dem Filmthema zusammenhängen:
Modelltraining
Wenn Sie den TF-IDF-Ansatz (hier zum Beispiel) mit einem Filter nach Häufigkeit und logistischer Regression verwenden, können Sie bereits hervorragende Ergebnisse erzielen: Anfangs wurden sehr unterschiedliche Texte an den Crawler gesendet, und das Modell kommt gut zurecht. Natürlich ist es notwendig, den Betrieb des Modells anhand realer Daten zu überprüfen. Im Folgenden wird das Ergebnis des Modellbetriebs anhand des Attributs „Interesse am Kauf von AEG-Geräten“ dargestellt.
Jede Zeile enthält die Wörter AEG, das Modell ohne falsch positive Ergebnisse. Wenn wir jedoch einen komplizierteren Fall betrachten, beispielsweise ein GAZ-Auto, stoßen wir auf ein Problem: Das Modell konzentriert sich auf Schlüsselwörter und verwendet keinen Kontext.
Fehlerbehandlung
Wir werden auf einem Modell des Interesses an Weiterbildung aufbauen - berufliche Umschulungskurse.
Der Verlauf des Zauberunterrichts für eine gewöhnliche Katze ist ebenfalls ein schwieriger Fall, der für eine Person irreführend sein kann.
Um falsch positive Ergebnisse herauszufiltern, verwenden wir Einbettungen: Wir berechnen die Mitte der positiven Probe im Einbettungsraum und messen den Abstand dazu für jede Linie.
Der Unterschied in der Entfernung zwischen den Kursen des Zauberunterrichts und dem Erwerb von Abstracts ist mit bloßem Auge sichtbar.
Ein weiteres Beispiel: Audi Markeninhaber. Der Abstand im Raum der Einbettungen spart in diesem Fall auch vor Fehlalarmen.
Skalierbarkeitsproblem
Bis heute werden beim Datenaustausch etwa 30.000 Attribute verwendet, und es werden regelmäßig neue Attribute angezeigt. Die Notwendigkeit der Automatisierung des Trainings neuer Modelle und des Markierens mit neuen Attributen liegt auf der Hand. Die Reihenfolge der Schritte zum Erstellen eines Modells eines neuen Attributs lautet wie folgt:
- Nehmen Sie den Attributnamen aus der Taxonomie.
- Erstellen Sie eine Liste mit Abfragen an die Suchmaschine mithilfe der Texterweiterung.
- kraulim Textauswahl;
- Wir trainieren das Klassifizierungsmodell an der erhaltenen Stichprobe.
- Nehmen wir an, ein trainiertes Modell enthält Rohkaufdaten.
- Filtern Sie das Ergebnis mit word2vec in die Mitte der positiven Klasse.
Der oben beschriebene Algorithmus weist eine Reihe von Schwachstellen auf:
- Es ist schwierig, den Korpus von hockenden Texten zu kontrollieren
- schwierig, die Qualität der Trainingsprobe zu kontrollieren;
- Es gibt keine Möglichkeit festzustellen, ob ein gut ausgebildetes Modell seine Arbeit erledigt.
Es ist wichtig zu verstehen, dass klassische Metriken nicht für die Qualitätskontrolle eines trainierten Modells geeignet sind, weil fehlende Informationen zu echten Klassen in Prüftexten. Lernen und Vorhersage finden an verschiedenen Daten statt, die Qualität des Modells kann an einer Trainingsstichprobe gemessen werden, und es gibt kein Markup auf dem Haupttext, was bedeutet, dass Sie nicht die üblichen Methoden zur Bewertung der Qualität verwenden können.
Bewertung der Modellqualität
Um die Qualität des trainierten Modells zu beurteilen, nehmen wir zwei Populationen: Eine bezieht sich auf Objekte unterhalb des Schwellenwerts der Modellantwort, die zweite bezieht sich auf Objekte, bei denen das Modell über dem Schwellenwert bewertet wurde.
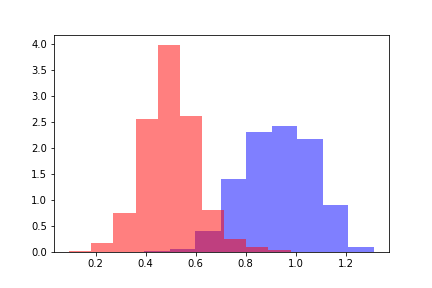
Für jede der Populationen berechnen wir den Abstand word2vec zum Zentrum der positiven Trainingsstichprobe. Wir erhalten zwei Entfernungsverteilungen, die so aussehen.
Die rote Farbe zeigt die Verteilung der Entfernungen für Objekte an, die den Schwellenwert überschritten haben, und die blaue Farbe zeigt Objekte unterhalb des Schwellenwerts gemäß der Bewertung des Modells an. Verteilungen können geteilt werden, und um den Abstand zwischen Verteilungen abzuschätzen, ist es zunächst logisch, sich auf die Kullback-Leibler-Divergenz (DKL) zu beziehen. Eine DCL ist eine asymmetrische Funktion, bei der die Dreiecksungleichung nicht erfüllt ist. Diese Einschränkung erschwert die Verwendung von DCL als Metrik, kann jedoch verwendet werden, wenn sie die erforderliche Abhängigkeit widerspiegelt. In unserem Fall nahm DCL bei allen Modellen unabhängig von den Schwellenwerten konstante Werte an, sodass nach anderen Methoden gesucht werden musste.
Um die Abstände zwischen Verteilungen abzuschätzen, berechnen wir die Differenz zwischen den Durchschnittswerten der Verteilungen. Die resultierende Differenz ist in den Standardabweichungen der anfänglichen Distanzverteilung messbar. Bezeichnen Sie den erhaltenen Wert durch die Z-Metrik in Analogie zum Z-Wert, und der Wert der Z-Metrik ist eine Funktion des Schwellenwerts des Vorhersagemodells. Für jeden festen Schwellenwert des Modells gibt die Z-Metrik-Funktion die Differenz zwischen den Sigma-Verteilungen der anfänglichen Abstandsverteilung zurück.
Von den vielen getesteten Ansätzen war es die Z-Metrik, die die notwendige Abhängigkeit ergab, um die Qualität des konstruierten Modells zu bestimmen.
Betrachten Sie das Verhalten der Z-Metrik: Je größer die Z-Metrik, desto besser wird das Modell bewältigt, denn je größer der Abstand zwischen den Verteilungen ist, desto charakteristischer ist die qualitative Klassifizierung. Eine klar definierte Entscheidungsregel zur Bestimmung der qualitativen Klassifikation konnte jedoch nicht abgeleitet werden. Beispielsweise erhält ein Modell mit einer Z-Metrik in der unteren linken Ecke der Abbildung einen konstanten Wert von 10. Dieses Modell bestimmt das Interesse an Reisen nach Thailand. Das Trainingsmuster wurde überwiegend von verschiedenen Spas beworben, und das Modell wurde an Texten trainiert, die nicht in direktem Zusammenhang mit Reisen nach Thailand standen. Das Modell hat gut funktioniert, spiegelt jedoch nicht das Interesse an Reisen nach Thailand wider.
Z-Metic für eine Reihe von Vorhersagemodellen. Die Modelle in der rechten Bildhälfte sind gut und die fünf Modelle in der linken Bildhälfte sind schlecht.Bei Recherchen und Experimenten haben sich 160 Modelle mit Markup nach dem Kriterium „gut / schlecht“ angesammelt. Basierend auf den Vorzeichen der Z-Metrik wurde ein Metamodell basierend auf Gradientenverstärkung konstruiert, das die Qualität des konstruierten Modells bestimmt. Somit war es möglich, die Qualitätsüberwachung von Modellen zu konfigurieren, die im automatischen Modus gebaut wurden.
Zusammenfassung
Im Moment ist die Reihenfolge der Aktionen wie folgt:
- Nehmen Sie den Attributnamen aus der Taxonomie.
- Erstellen Sie eine Liste mit Abfragen an die Suchmaschine mithilfe der Texterweiterung.
- kraulim Textauswahl;
- Wir trainieren das Klassifizierungsmodell an der erhaltenen Stichprobe.
- Nehmen wir an, ein trainiertes Modell enthält Rohkaufdaten.
- Wir filtern das Ergebnis durch word2vec den Abstand zum Zentrum der positiven Klasse.
- Wir berechnen die Z-Metrik und bauen Vorzeichen für das Metamodell.
- Wir verwenden ein Metamodell und bewerten die Qualität des resultierenden Modells.
- Wenn das Modell von akzeptabler Qualität ist, wird es dem verwendeten Modellsatz hinzugefügt. Andernfalls wird das Modell zur Überarbeitung zurückgegeben.
Entsprechend der Bewertung des Metamodells im automatischen Modus wird entschieden, es in die Produktion einzuführen oder zur Überarbeitung zurückzukehren. Eine Verfeinerung ist auf verschiedene Arten möglich, die für den Analysten abgeleitet wurden.
- Oft stören Modelle bestimmte Wörter, die mehrere Bedeutungen haben. Eine schwarze Liste mit irreführenden Wörtern erleichtert die Arbeit mit dem Modell.
- Ein anderer Ansatz besteht darin, eine Regel zu erstellen, um Objekte aus dem Trainingssatz auszuschließen. Dieser Ansatz hilft, wenn die erste Methode nicht funktioniert.
- Bei komplexen Texten und mehrwertigen Attributen wird ein bestimmtes Wörterbuch in das Modell übertragen, wodurch das Modell eingeschränkt wird, Sie jedoch Fehler kontrollieren können.
Aber was ist mit neuronalen Netzen?
Zunächst bestand der Wunsch, für die beschriebene Aufgabe neuronale Netze zu verwenden. Zum Beispiel könnte man Transformer an einer großen Anzahl von Texten trainieren und dann Learning Transfer an einer Reihe kleiner Trainingsbeispiele aus jedem Attribut durchführen. Leider musste die Verwendung eines solchen neuronalen Netzwerks aus folgenden Gründen aufgegeben werden.
- Wenn das Modell für ein Attribut nicht mehr ordnungsgemäß funktioniert, muss es für die verbleibenden Attribute ohne Verlust deaktiviert werden können.
- Wenn das Modell für ein Attribut nicht gut funktioniert, muss das Modell isoliert optimiert und optimiert werden, ohne dass das Ergebnis für andere Attribute beeinträchtigt wird.
- Wenn ein neues Attribut angezeigt wird, müssen Sie so schnell wie möglich ein Modell dafür erhalten, ohne alle Modelle (oder ein großes Modell) langfristig zu trainieren.
- Das Lösen des Qualitätskontrollproblems für ein Attribut ist schneller und einfacher als das Lösen des Qualitätskontrollproblems für alle Attribute gleichzeitig. Wenn ein großes Modell eines der Attribute nicht erfüllt, müssen Sie das gesamte große Modell optimieren und anpassen, was mehr Zeit und Aufmerksamkeit eines Spezialisten erfordert.
Ein Ensemble unabhängiger kleiner Modelle zur Lösung des Problems erwies sich daher als praktischer als ein großes und komplexes Modell. Darüber hinaus werden das Sprachmodell und die Einbettungen weiterhin zur Qualitätskontrolle und Texterweiterung verwendet, sodass es nicht möglich war, die Verwendung neuronaler Netze vollständig zu umgehen, und es gab keinen solchen Zweck. Die Verwendung neuronaler Netze ist auf die Aufgaben beschränkt, für die sie erforderlich sind.
Fortsetzung folgt
Die Arbeit am Projekt wird fortgesetzt: Es ist notwendig, die Überwachung zu organisieren, Modelle zu aktualisieren, mit Anomalien zu arbeiten usw. Einer der vorrangigen Bereiche für die weitere Entwicklung ist die Erfassung und Analyse der Fälle, die von keinem Modell des Ensembles klassifiziert wurden. Trotzdem sehen wir bereits jetzt die Ergebnisse unserer Arbeit: Etwa 60% der Prüfungen nach dem Anwenden der Modelle erhalten ihre Attribute. Offensichtlich gibt es einen erheblichen Anteil von Schecks, die keine Informationen über die Interessen der Eigentümer enthalten, so dass ein hundertprozentiges Niveau nicht erreichbar ist. Dennoch ist es ermutigend, dass das bisher erzielte Ergebnis bereits unsere Erwartungen übertrifft und wir weiterhin in diese Richtung arbeiten.
Dieser Artikel wurde zusammen mit
samy1010 geschrieben .