Die Idee des Artikels entstand spontan aus einer Diskussion in den Kommentaren zum Artikel
„Etwas über Inode“ .
Tatsache ist, dass die internen Besonderheiten unserer Dienste die Speicherung einer großen Anzahl kleiner Dateien sind. Im Moment haben wir ungefähr Hunderte von Terabyte solcher Daten. Und wir stießen auf einige offensichtliche und nicht sehr Rechen und gingen erfolgreich auf ihnen.
Deshalb teile ich unsere Erfahrungen, vielleicht wird sich jemand als nützlich erweisen.
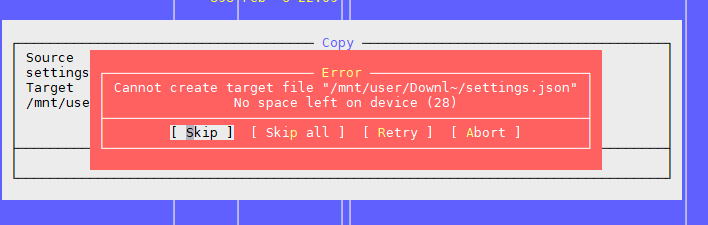
Problem Eins: "Kein Platz mehr auf dem Gerät"
Wie im obigen Artikel erwähnt, besteht das Problem darin, dass das Dateisystem freie Blöcke enthält, der Inode jedoch beendet ist.
Sie können die Anzahl der verwendeten und freien Inodes mit dem
df -ih :
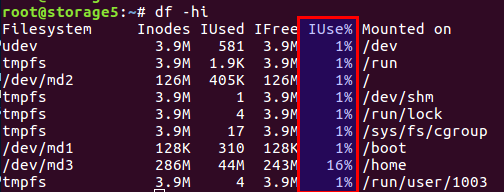
Ich werde den Artikel nicht nacherzählen, kurz gesagt, es gibt sowohl Blöcke für Daten direkt auf der Festplatte als auch Blöcke für Metainformationen, sie sind auch Inodes (Indexknoten). Ihre Anzahl wird während der Initialisierung des Dateisystems festgelegt (es handelt sich um ext2 und seine Nachkommen) und ändert sich nicht weiter. Das Gleichgewicht von Datenblöcken und Inodes wird aus den durchschnittlichen Daten berechnet. In unserem Fall sollte sich das Gleichgewicht bei vielen kleinen Dateien in Richtung der Anzahl der Inodes verschieben - es sollten mehr vorhanden sein.
Linux hat bereits Optionen mit unterschiedlichen Salden bereitgestellt, und alle diese vorberechneten Konfigurationen befinden sich in der Datei
/etc/mke2fs.conf .
Daher können Sie bei der Erstinitialisierung des Dateisystems über mke2fs das gewünschte Profil angeben.
Hier einige Beispiele aus der Datei:
small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } big = { inode_ratio = 32768 } largefile = { inode_ratio = 1048576 blocksize = -1 }
Sie können den gewünschten Anwendungsfall mit der Option -T auswählen, wenn Sie mke2fs aufrufen. Sie können die erforderlichen Parameter auch manuell einstellen, wenn keine fertige Lösung vorhanden ist.
Weitere Details finden Sie in den Handbüchern für
mke2fs.conf und
mke2fs .
Eine Funktion, die im oben genannten Artikel nicht erwähnt wird - Sie können die Größe des Datenblocks festlegen. Für große Dateien ist es natürlich sinnvoll, eine größere Blockgröße zu haben, für kleine Dateien - in einer kleineren.
Es lohnt sich jedoch, ein so interessantes Merkmal wie die Prozessorarchitektur in Betracht zu ziehen.
Ich dachte einmal, ich brauche eine größere Blockgröße für große Fotodateien. Es war zu Hause, auf dem Home-Dateinamen WD in der ARM-Architektur. Ohne zu zögern habe ich die Blockgröße entweder auf 8k oder 16k anstelle der Standardgröße von 4k eingestellt, nachdem ich zuvor die Einsparungen gemessen hatte. Und alles war wunderbar, genau bis zu dem Moment, als der Speicher selbst nicht ausfiel, während die Festplatte am Leben war. Nachdem ich die Festplatte in einen normalen Computer mit einem normalen Intel-Prozessor eingelegt hatte, bekam ich eine Überraschung: nicht unterstützte Blockgröße. Gesegelt. Es gibt Daten, alles ist in Ordnung, aber unmöglich zu lesen. Prozessoren i386 und dergleichen wissen nicht, wie sie mit Blockgrößen arbeiten sollen, die nicht der Größe der Speicherseite entsprechen, aber es sind genau 4 KB. Im Allgemeinen endete der Fall mit der Verwendung von Dienstprogrammen aus dem Benutzerbereich, alles war langsam und traurig, aber die Daten wurden gespeichert. Wen kümmert es - googeln Sie den Namen des Dienstprogramms
fuseext2 . Moral: Denken Sie entweder alle Fälle im Voraus durch oder bauen Sie keinen Superhelden und verwenden Sie die Standardeinstellungen für Hausfrauen.
UPD Gemäß der Bemerkung des Benutzers stellt
berez klar, dass für i386 die Blockgröße 4k nicht überschreiten sollte, aber nicht genau 4k sein muss, d. H. gültig 1k und 2k.
Also, wie wir die Probleme gelöst haben.
Erstens ist ein Problem aufgetreten, als eine Multi-Terabyte-Festplatte voller Daten war und wir die Dateisystemkonfiguration nicht wiederholen konnten.
Zweitens war die Entscheidung dringend.
Infolgedessen kamen wir zu dem Schluss, dass wir das Gleichgewicht ändern müssen, indem wir die Anzahl der Dateien reduzieren.
Um die Anzahl der Dateien zu verringern, wurde beschlossen, die Dateien in einem gemeinsamen Archiv abzulegen. In Anbetracht unserer Besonderheiten haben wir alle Dateien für einen bestimmten Zeitraum in einem Archiv abgelegt und die Cron-Aufgabe täglich nachts archiviert.
Ein Zip-Archiv ausgewählt. In den Kommentaren zum vorherigen Artikel wurde tar vorgeschlagen, aber es gibt eine Komplikation: Es gibt kein Inhaltsverzeichnis und die Dateien sind darin eingefädelt (aus einem Grund ist "tar" eine Abkürzung für "Tape Archive", ein Vermächtnis von Bandlaufwerken), d. H. . Wenn Sie die Datei am Ende des Archivs lesen müssen, müssen Sie das gesamte Archiv lesen, da für jede Datei keine Offsets relativ zum Anfang des Archivs vorhanden sind. Und deshalb ist es eine lange Operation. In zip ist alles viel besser: Es hat das gleiche Inhaltsverzeichnis und die gleichen Datei-Offsets im Archiv, und die Zugriffszeit auf jede Datei hängt nicht von ihrem Speicherort ab. In unserem Fall war es möglich, die Komprimierungsoption auf "0" zu setzen, da alle Dateien bereits zuvor in gzip komprimiert worden waren.
Clients führen Dateien über nginx, und gemäß der alten API wird nur der Dateiname angegeben, beispielsweise wie folgt:
http://www.server.com/hydra/20170416/0453/3bd24ae7-1df4-4d76-9d28-5b7fcb7fd8e5
Um Dateien im laufenden Betrieb zu entpacken, haben wir das Modul nginx-unzip-module (
https://github.com/youzee/nginx-unzip-module ) gefunden und verbunden und zwei Upstreams eingerichtet.
Das Ergebnis ist diese Konfiguration:

Zwei Hosts in den Einstellungen sahen folgendermaßen aus:
server { listen *:8081; location / { root /home/filestorage; } }
server { listen *:8082; location ~ ^/hydra/(\d+)/(\d+)/(.*)$ { root /home/filestorage; file_in_unzip_archivefile "/home/filestorage/hydra/$1/$2.zip"; file_in_unzip_extract "$2/$3"; file_in_unzip; } }
Und die Upstream-Konfiguration auf dem Upstream-Nginx:
upstream storage { server server.com:8081; server server.com:8082; }
Wie es funktioniert:
- Client geht zu Front Nginx
- Front Nginx versucht, die Datei vom ersten Upstream zu geben, d. H. direkt aus dem Dateisystem
- Wenn keine Datei vorhanden ist, wird versucht, sie vom zweiten Upstream zu geben, der versucht, die Datei im Archiv zu finden
Das zweite Problem: wieder "Kein Platz mehr auf dem Gerät"
Dies ist das zweite Problem, auf das wir gestoßen sind, wenn sich viele Dateien im Verzeichnis befinden.
Wir versuchen eine Datei zu erstellen, das System schwört, dass kein Speicherplatz vorhanden ist. Ändern Sie den Dateinamen und versuchen Sie erneut, ihn zu erstellen.
Es stellt sich heraus.
Es sieht ungefähr so aus:

Das Überprüfen von Inodes ergab nichts - viele davon sind kostenlos.
Das Überprüfen des Ortes ist das gleiche.
Wir dachten, dass sich möglicherweise zu viele Dateien im Verzeichnis befinden, aber dies ist begrenzt, aber auch nicht: Maximale Anzahl von Dateien pro Verzeichnis: ~ 1,3 × 10 ^ 20
Ja, und Sie können eine Datei erstellen, wenn Sie den Namen ändern.
Die Schlussfolgerung ist ein Problem im Dateinamen.
Weitere Suchen ergaben, dass das Problem beim Erstellen des Verzeichnisindex im Hashing-Algorithmus liegt. Bei einer großen Anzahl von Dateien kommt es zu Kollisionen mit allen sich daraus ergebenden Konsequenzen. Weitere Details finden Sie hier:
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Hash_Tree_DirectoriesSie können diese Option deaktivieren, aber ... die Suche nach einer Datei nach Namen kann beim Durchsuchen aller Dateien unvorhersehbar lang werden.
tune2fs -O "^dir_index" /dev/sdb3
Im Allgemeinen, wie eine Problemumgehung funktionieren könnte.
Moral: Viele Dateien in einem Verzeichnis sind normalerweise schlecht. Dies ist nicht erforderlich.
Normalerweise erstellen sie in solchen Fällen Unterverzeichnisse, nach den ersten Buchstaben des Dateinamens oder nach einigen anderen Parametern, z. B. nach Datum. In den meisten Fällen wird dies gespeichert.
Aber die Gesamtzahl der kleinen Dateien ist immer noch schlecht, auch wenn sie in Verzeichnisse unterteilt sind - dann sehen Sie das erste Problem.
Das dritte Problem: wie man die Liste der Dateien sieht, wenn es viele davon gibt
In unserer Situation, in der wir auf die eine oder andere Weise viele Dateien haben, standen wir vor dem Problem, wie der Inhalt des Verzeichnisses angezeigt werden soll.
Die Standardlösung ist der
ls .
Ok, mal sehen, was mit den 4772098-Dateien passiert:
$ time ls /home/app/express.repository/offercache/ >/dev/null real 0m30.203s user 0m28.327s sys 0m1.876s
30 Sekunden ... es wird zu viel sein. Und die meiste Zeit wird benötigt, um Dateien im Benutzerbereich und überhaupt nicht im Kernel zu verarbeiten.
Aber es gibt eine Lösung:
$ time find /home/app/express.repository/offercache/ >/dev/null real 0m3.714s user 0m1.998s sys 0m1.717s
3 Sekunden 10 mal schneller.
Hurra!
UPDEine noch schnellere Lösung für den
berez- Benutzer besteht darin, die Sortierung zu deaktivieren
time ls -U /home/app/express.repository/offercache/ >/dev/null real 0m2.985s user 0m1.377s sys 0m1.608s
Das vierte Problem: großes LA beim Arbeiten mit Dateien
In regelmäßigen Abständen tritt eine Situation auf, in der Sie eine Reihe von Dateien von einem Computer auf einen anderen kopieren müssen. Gleichzeitig wächst LA oft unrealistisch, da alles von der Leistung der Festplatten selbst abhängt.
Am vernünftigsten ist es, eine SSD zu verwenden. Wirklich cool. Die Frage ist nur die Kosten für Multi-Terabyte-SSDs.
Aber wenn die Festplatten normal sind, müssen Sie die Dateien kopieren, und dies ist auch ein Produktionssystem, bei dem Überlastung zu Kundenbeschwerden führt? Es gibt mindestens zwei nützliche Werkzeuge:
nice und
ionice .
nice - reduziert die Priorität des Prozesses, dementsprechend verteilt der Sheduler mehr Zeitscheiben an andere Prozesse mit höherer Priorität.
In unserer Praxis hat es geholfen, nett auf maximal zu setzen (19 ist die minimale Priorität, -20 (minus 20) ist das Maximum).
ionice - passt die Priorität der Eingabe / Ausgabe entsprechend an (E / A-Planung)
Wenn Sie RAID verwenden und plötzlich synchronisieren müssen (nach einem erfolglosen Neustart oder nach dem Ersetzen der Festplatte das RAID-Array wiederherstellen müssen), ist es in einigen Situationen sinnvoll, die Synchronisierungsgeschwindigkeit zu verringern, damit andere Prozesse mehr oder weniger ordnungsgemäß funktionieren. Dazu hilft dieser Befehl:
echo 1000 > /proc/sys/dev/raid/speed_limit_max
Das fünfte Problem: So synchronisieren Sie Dateien in Echtzeit
Wir haben alle die gleichen großen Mengen an Dateien, die auf einem zweiten Server gesichert werden müssen, um zu vermeiden ... Dateien werden ständig geschrieben. Um ein Minimum an Verlusten zu vermeiden, müssen Sie sie so schnell wie möglich kopieren.
Standardlösung: Rsync über SSH.
Dies ist eine gute Option, es sei denn, Sie müssen dies alle paar Sekunden einmal tun. Und es gibt viele Dateien. Selbst wenn Sie sie nicht kopieren, müssen Sie irgendwie verstehen, was sich geändert hat, und mehrere Millionen Dateien zu vergleichen, ist die Zeit und die Last auf den Datenträgern.
Das heißt, Wir müssen sofort wissen, was zu kopieren ist, ohne den Vergleich jedes Mal zu starten.
Erlösung -
lsyncd .
Lsyncd -
Live Syncing (Mirror) Daemon . Es funktioniert auch über rsync, überwacht jedoch zusätzlich das Dateisystem mithilfe von inotify und fsevents auf Änderungen und beginnt mit dem Kopieren nur für die Dateien, die angezeigt oder geändert wurden.
Das sechste Problem: Wie man versteht, wer die Festplatten lädt
Jeder weiß das wahrscheinlich, aber
iotop Vollständigkeit
iotop :
iotop Überwachung des Festplattensubsystems gibt es den Befehl
iotop - wie
top , zeigt aber die Prozesse an, die Festplatten am aktivsten verwenden.

Das gute alte Top macht übrigens auch deutlich, dass es Probleme mit den Festplatten gibt oder nicht.
Hierfür gibt es zwei am besten geeignete Parameter:
Load Average und
IOwait .
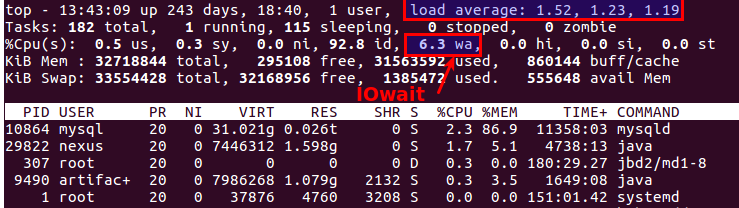
Der erste zeigt, wie viele Prozesse sich in der Servicewarteschlange befinden, normalerweise mehr als 2 - etwas läuft bereits schief. Beim aktiven Kopieren auf Sicherungsserver erlauben wir bis zu 6-8, wonach die Situation als abnormal angesehen wird.
Die zweite ist, wie viel der Prozessor mit Festplattenoperationen beschäftigt ist. IOwait> 10% gibt Anlass zur Sorge, obwohl es auf Servern mit einem bestimmten Lastprofil zu 40-50% stabil ist, und dies ist wirklich die Norm.
Ich werde hier enden, obwohl es wahrscheinlich viele Punkte gibt, mit denen wir uns nicht auseinandersetzen mussten, werde ich gerne auf Kommentare und Beschreibungen interessanter realer Fälle warten.