Bevor Sie mit der Implementierung einer neuen Funktion beginnen, müssen Sie sich den Kopf zerbrechen.
Die Entwicklung komplexer Funktionen erfordert eine genaue Koordination der Bemühungen eines Ingenieurteams.
Und einer der wichtigsten Punkte ist das Problem der Parallelisierung von Aufgaben.
Ist es möglich, Frontsoldaten davor zu bewahren, auf eine Back-End-Implementierung warten zu müssen? Gibt es eine Möglichkeit, die Entwicklung einzelner Fragmente der Benutzeroberfläche zu parallelisieren?
Das Thema Aufgabenparallelisierung in der Webentwicklung wird in diesem Artikel behandelt.
Das Problem
Beginnen wir also damit, das Problem zu identifizieren. Stellen Sie sich vor, Sie haben ein erfahrenes Produkt (Internet-Service), in dem einige verschiedene Microservices gesammelt werden. Jeder Microservice in Ihrem System ist eine Art Mini-Anwendung, die in die allgemeine Architektur integriert ist und ein bestimmtes Problem des Servicebenutzers löst. Stellen Sie sich vor, heute Morgen (am letzten Tag des Sprints) hat der Product Owner Vasily Sie angerufen und angekündigt: „Im nächsten Sprint beginnen wir mit dem Datenimport, wodurch die Servicebenutzer noch glücklicher werden. Dadurch kann der Benutzer den Service sofort mit einem Stopizot von Dofigalliard-Positionen aus füllen dichtes 1C! ".
Stellen Sie sich vor, Sie sind Manager oder Teamleiter und hören nicht all diese begeisterten Beschreibungen glücklicher Benutzer aus geschäftlicher Sicht. Sie schätzen, wie viel Arbeit dies alles erfordert. Als guter Manager bemühen Sie sich, den Appetit von Vasily auf Bewertungsaufgaben für MVP (im Folgenden: Minimum Viable Product) zu verringern. Gleichzeitig können die beiden Hauptanforderungen für MVP - die Fähigkeit des Importsystems, einer großen Last standzuhalten und im Hintergrund zu arbeiten - nicht verworfen werden.
Sie verstehen, dass der herkömmliche Ansatz, wenn alle Daten innerhalb derselben Benutzeranforderung verarbeitet werden, nicht funktioniert. Hier muss man den Garten aller Hintergrundarbeiter umzäunen. Sie müssen sich an den Event Bus binden und überlegen, wie der Load Balancer, die verteilte Datenbank usw. funktionieren. Im Allgemeinen alle Freuden der Microservice-Architektur. Infolgedessen kommen Sie zu dem Schluss, dass sich die Entwicklung des Backends für diese Funktion in die Länge zieht. Gehen Sie nicht zu Wahrsagern.
Es stellt sich automatisch die Frage: "Was werden die Frontsoldaten die ganze Zeit tun, wenn es keine API gibt?".
Außerdem stellt sich heraus, dass die Daten nicht sofort importiert werden dürfen. Sie müssen sie zuerst validieren und den Benutzer alle gefundenen Fehler korrigieren lassen. Auch im Frontend stellt sich ein schlauer Workflow heraus. Und es ist notwendig, die Funktion wie üblich "gestern" zu sprengen. Folglich müssen die Kriegsveteranen irgendwie koordiniert sein, damit sie nicht in einer Rübe drängeln, keine Konflikte verursachen und ruhig jedes Stück davon sehen (siehe KDPV am Anfang des Artikels).
In einer anderen Situation könnten wir von hinten nach vorne sägen. Implementieren Sie zuerst das Backend und stellen Sie sicher, dass es die Last hält, und hängen Sie dann das Frontend ruhig daran. Der Haken ist jedoch, dass Spezifikationen das neue Feature allgemein beschreiben, Lücken und kontroverse Punkte in Bezug auf die Benutzerfreundlichkeit aufweisen. Was aber, wenn sich am Ende der Front-Implementierung herausstellt, dass die Funktion in dieser Form den Benutzer nicht zufriedenstellt? Änderungen der Benutzerfreundlichkeit können Änderungen am Datenmodell erforderlich machen. Wir müssen sowohl die Vorder- als auch die Rückseite wiederholen, was sehr teuer sein wird.
Agile versucht uns zu helfen.
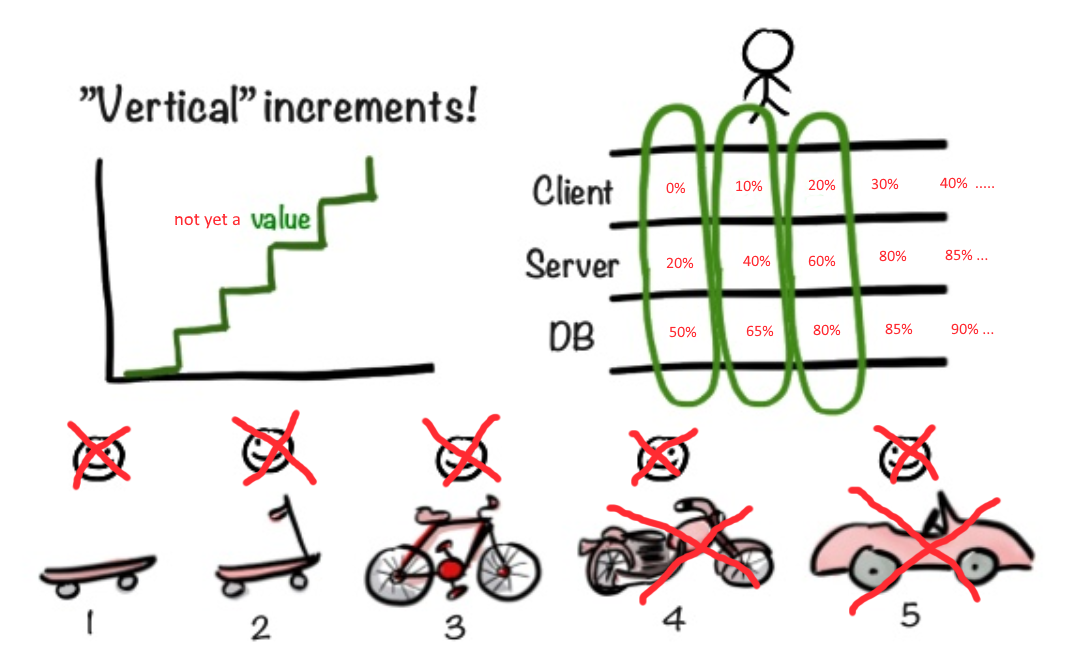
Flexible Methoden bieten kluge Ratschläge. "Beginnen Sie mit dem Skateboard und zeigen Sie es dem Benutzer. Plötzlich wird es ihm gefallen. Wenn es Ihnen gefällt, fahren Sie auf die gleiche Weise fort und schrauben Sie neue Chips."
Was aber, wenn der Benutzer sofort mindestens ein Motorrad benötigt und dies in zwei bis drei Wochen? Was ist, wenn Sie, um mit der Arbeit an der Fassade des Motorrads zu beginnen, zumindest die Abmessungen des Motors und die Größe des Fahrgestells festlegen müssen?
Wie kann sichergestellt werden, dass die Umsetzung der Fassade nicht verzögert wird, bis die anderen Schichten der Anwendung sicher sind?
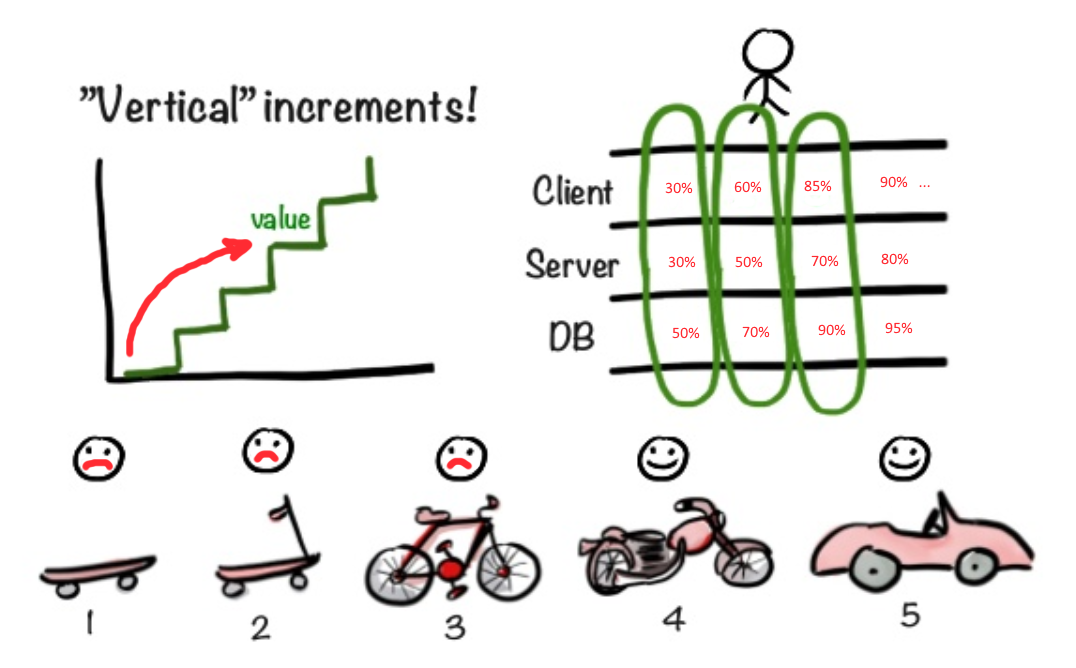
In unserer Situation ist es besser, einen anderen Ansatz zu verwenden. Es ist besser, sofort mit der Erstellung einer Fassade (Vorderseite) zu beginnen, um sicherzustellen, dass die ursprüngliche Idee von MVP korrekt ist. Auf der einen Seite scheint es ein Betrug zu sein, eine dekorative Fassade an Product Owner Vasily zu schieben, hinter der sich nichts befindet. Auf der anderen Seite erhalten wir auf diese Weise sehr schnell Feedback zu dem Teil der Funktionalität, auf den der Benutzer überhaupt stoßen wird. Sie haben vielleicht eine unglaublich coole Architektur, aber wenn es keine Benutzerfreundlichkeit gibt, wird die gesamte Anwendung über den Rand der App geworfen, ohne die Details zu verstehen. Daher erscheint es mir wichtiger, so schnell wie möglich die funktionsfähigste Benutzeroberfläche bereitzustellen, anstatt den Fortschritt der Front mit dem Backend zu synchronisieren. Es macht keinen Sinn, eine unvollendete Benutzeroberfläche und eine Sicherung zum Testen herauszugeben, deren Funktionalität die Hauptanforderungen nicht erfüllt. Gleichzeitig kann sich die Ausgabe von 80% der erforderlichen UI-Funktionen, jedoch ohne funktionierendes Back-End, als rentabel herausstellen.
Einige technische Details
Daher habe ich bereits kurz beschrieben, welche Funktion wir implementieren werden. Fügen Sie einige technische Details hinzu.
Der Benutzer sollte in der Lage sein, eine große Datendatei in den Dienst hochzuladen. Der Inhalt dieser Datei muss in einem bestimmten Format vorliegen (z. B. CSV). Die Datei muss eine bestimmte Datenstruktur haben und es gibt Pflichtfelder, die nicht leer sein dürfen. Mit anderen Worten, nach dem Entladen im Backend müssen Sie die Daten validieren. Die Validierung kann eine beträchtliche Zeit dauern. Sie können die Verbindung zum Backend nicht offen halten (sie wird durch das Timeout unterbrochen). Daher müssen wir die Datei schnell akzeptieren und mit der Hintergrundverarbeitung beginnen. Am Ende der Validierung müssen wir den Benutzer darüber informieren, dass er mit der Bearbeitung der Daten beginnen kann. Der Benutzer muss die während der Validierung festgestellten Fehler korrigieren.
Nachdem alle Fehler behoben wurden, klickt der Benutzer auf die Schaltfläche Importieren. Korrigierte Daten werden an das Backend zurückgesendet. um den Importvorgang abzuschließen. Wir müssen das Frontend über den Fortschritt aller Importphasen informieren.
Der effektivste Weg, um zu alarmieren, ist WebSockets. Von vorne werden über Websocket mit einem bestimmten Zeitraum Anforderungen gesendet, um den aktuellen Status der Hintergrunddatenverarbeitung zu erhalten. Für die Hintergrunddatenverarbeitung benötigen wir Hintergrundhandler, eine verteilte Befehlswarteschlange, einen Ereignisbus usw.
Der Datenfluss wird wie folgt angezeigt (als Referenz):
- Über die Dateibrowser-API bitten wir den Benutzer, die gewünschte Datei von der Festplatte auszuwählen.
- Über AJAX senden wir die Datei an das Backend.
- Wir warten auf den Abschluss der Validierung und Analyse der Datendatei (wir fragen den Status der Hintergrundoperation über Websocket ab).
- Nach Abschluss der Validierung laden wir die für den Import vorbereiteten Daten und rendern sie in die Tabelle auf der Importseite.
- Benutzer bearbeitet Daten, korrigiert Fehler. Durch Klicken auf die Schaltfläche unten auf der Seite senden wir die korrigierten Daten an das Backend.
- Auch hier führen wir auf der Clientseite eine regelmäßige Abfrage des Hintergrundoperationsstatus durch.
- Bis zum Ende des aktuellen Imports sollte der Benutzer keinen neuen Import starten können (auch nicht im benachbarten Browserfenster oder auf dem benachbarten Computer).
Entwicklungsplan
Mocap UI vs. Prototyp-Benutzeroberfläche

Lassen Sie uns sofort den Unterschied zwischen Wireframe, Mockup und Prototype hervorheben.
Das Bild oben zeigt das Drahtmodell. Dies ist nur eine Zeichnung (in Zahlen oder auf Papier - das spielt keine Rolle). Die beiden anderen Konzepte sind komplizierter.
Mocap ist eine Präsentationsform der zukünftigen Oberfläche, die nur als Präsentation verwendet wird und anschließend vollständig ersetzt wird. Dieses Formular wird in Zukunft als Beispiel archiviert. Die eigentliche Benutzeroberfläche wird mit anderen Tools erstellt. Ein Mocap kann in einem Vektoreditor mit ausreichenden Designdetails erstellt werden, aber dann legen Front-End-Entwickler es einfach beiseite und betrachten es als Modell. Mocap kann sogar in spezialisierten Browser-Konstruktoren erstellt werden und ist nur eingeschränkt interaktiv. Aber sein Schicksal ist unverändert. Er wird ein Model im Design Guide Album.
Der Prototyp wird mit denselben Tools wie die zukünftige Benutzeroberfläche erstellt (z. B. React). Der Prototypcode wird im allgemeinen Anwendungsrepository gehostet. Es wird nicht ersetzt, wie dies bei mocap der Fall ist. Zunächst wird das Konzept getestet (Proof of Concept, PoC). Wenn es den Test besteht, wird es entwickelt und schrittweise in eine vollwertige Benutzeroberfläche umgewandelt.
Jetzt näher am Punkt ...
Stellen Sie sich vor, Kollegen aus dem Design-Workshop präsentierten uns Artefakte ihres kreativen Prozesses: Modelle der zukünftigen Benutzeroberfläche. Unsere Aufgabe ist es, die Arbeit so zu planen, dass die Parallelarbeit von Veteranen so schnell wie möglich möglich wird.
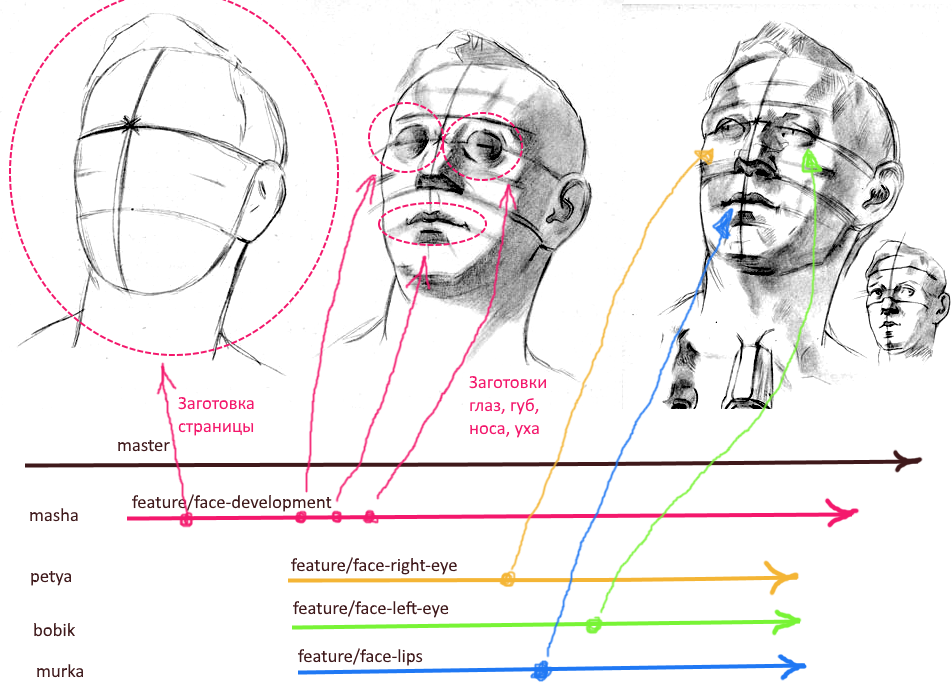
Da die Kompilierung des Algorithmus mit einem Flussdiagramm beginnt, beginnen wir mit der Erstellung eines Prototyps mit einem minimalistischen Drahtmodell (siehe Abbildung oben). In diesem Wireframe teilen wir zukünftige Funktionen in große Blöcke auf. Das Hauptprinzip hierbei ist die Fokussierung der Verantwortung. Sie sollten eine Funktionalität nicht in verschiedene Blöcke unterteilen. Fliegen gehen zu einem Block und Schnitzel zu einem anderen.
Als Nächstes müssen Sie so schnell wie möglich eine leere Seite (Dummy) erstellen, das Routing konfigurieren und einen Link zu dieser Seite in das Menü einfügen. Anschließend müssen Sie Leerzeichen für die Basiskomponenten erstellen (eines für jeden Block im Prototyp Wireframe). Und um diesen besonderen Rahmen in den Entwicklungszweig eines neuen Features einzubringen.
Wir erhalten die folgende Hierarchie von Zweigen in Git:
master ---------------------- > └ feature/import-dev ------ >
Der Zweig "import-dev" wird für das gesamte Feature die Rolle des Entwicklungsbrunchs spielen. Es ist ratsam, eine verantwortliche Person (Betreuer) in dieser Niederlassung zu beauftragen, die atomare Änderungen von allen Kollegen vornimmt, die parallel an der Funktion arbeiten. Es ist auch ratsam, keine direkten Commits für diesen Zweig vorzunehmen, um die Wahrscheinlichkeit von Konflikten und unerwarteten Änderungen zu verringern, wenn in diesem Zweig Fusionen von atomaren Pull-Anforderungen stattfinden.
Weil In diesem Moment haben wir bereits Komponenten für die Hauptblöcke auf der Seite erstellt. Anschließend können Sie sofort separate Zweige für jeden UI-Block erstellen. Die endgültige Hierarchie könnte folgendermaßen aussehen:
master ----------------------- > └ feature/import-dev ------- > ├ feature/import-head ---- > ├ feature/import-filter -- > ├ feature/import-table --- > ├ feature/import-pager --- > └ feature/import-footer -- >
Hinweis: Es spielt keine Rolle, zu welchem Zeitpunkt diese atomaren Brunchs erstellt werden, und die oben dargestellte Namenskonvention ist nicht die einzige geeignete. Brunch kann unmittelbar vor Arbeitsbeginn erstellt werden. Und die Namen der Brunchs sollten allen Teilnehmern an der Entwicklung klar sein. Der Name sollte so kurz wie möglich sein und gleichzeitig explizit angeben, für welchen Teil der Funktionalität der Zweig verantwortlich ist.
Durch den oben beschriebenen Ansatz stellen wir den konfliktfreien Betrieb mehrerer UI-Entwickler sicher. Jedes UI-Fragment hat ein eigenes Verzeichnis in der Projekthierarchie. Der Fragmentkatalog enthält die Hauptkomponente, ihre Stile und ihre eigenen untergeordneten Komponenten. Jedes Fragment kann auch einen eigenen Statusmanager haben (MobX-, Redux-, VueX-Parteien). Möglicherweise verwenden die Komponenten des Fragments einige globale Stile. Das Ändern globaler Stile beim Entwickeln eines Fragments einer neuen Seite ist jedoch untersagt. Es lohnt sich auch nicht, das Standardverhalten und den Standardstil des allgemeinen Entwurfsatoms zu ändern.
Hinweis: „Design Atom“ bezeichnet ein Element aus dem Satz von Standardkomponenten unseres Service - siehe Atomic Design ; In unserem Fall wird davon ausgegangen, dass das Atomic Design-System bereits implementiert wurde.
Also haben wir die Frontsoldaten physisch voneinander getrennt. Jetzt kann jeder von ihnen ruhig arbeiten, ohne Angst vor Konflikten mit der Fusion zu haben. Außerdem kann jeder jederzeit eine Pull-Anfrage aus seiner Filiale in feature / import-dev erstellen. Bereits jetzt ist es möglich, statische Inhalte in aller Ruhe zu werfen und sogar interaktiv zu gestalten.
Aber wie können wir die Möglichkeit der Interaktion zwischen UI-Fragmenten sicherstellen?
Wir müssen die Verbindung zwischen den Fragmenten implementieren. Der JS-Dienst, der als Gateway für den Datenaustausch mit dem Backing fungiert, eignet sich für die Rolle einer Verbindung zwischen Fragmenten. Über denselben Dienst können Sie die Benachrichtigung über Ereignisse implementieren. Durch das Abonnieren bestimmter Ereignisse enthalten die Fragmente implizit den gesamten Lebenszyklus des Mikrodienstes. Änderungen an Daten in einem Fragment machen es erforderlich, den Status eines anderen Fragments zu aktualisieren. Mit anderen Worten, wir haben die Integration von Fragmenten durch Daten und ein Ereignismodell durchgeführt.
Um diesen Service zu erstellen, benötigen wir einen weiteren Zweig in git:
master --------------------------- > └ feature/import-dev ----------- > ├ feature/import-js-service -- > ├ feature/import-head -------- > ├ feature/import-filter ------ > ├ feature/import-table ------- > ├ feature/import-pager ------- > └ feature/import-footer ------ >
Hinweis: Haben Sie keine Angst vor der Anzahl der Filialen und zögern Sie nicht, Filialen zu produzieren. Mit Git können Sie effizient mit einer großen Anzahl von Zweigen arbeiten. Wenn sich eine Gewohnheit entwickelt, wird es leicht, sich zu verzweigen:
$/> git checkout -b feature/import-service $/> git commit . $/> git push origin HEAD $/> git checkout feature/import-dev $/> git merge feature/import-service
Dies wird einigen spannend erscheinen, aber der Gewinn der Minimierung von Konflikten ist bedeutender. Während Sie der ausschließliche Eigentümer der Niederlassung sind, können Sie außerdem -f sicher drücken, ohne das Risiko einzugehen, dass die lokale Commit-Historie einer Person beschädigt wird.
Gefälschte Daten
In der vorherigen Phase haben wir den Integrations-JS-Dienst (importService) und die UI-Fragmente vorbereitet. Ohne Daten funktioniert unser Prototyp jedoch nicht. Außer statischen Dekorationen wird nichts gezeichnet.
Jetzt müssen wir uns für ein ungefähres Datenmodell entscheiden und diese Daten in Form von JSON- oder JS-Dateien erstellen (die Wahl zugunsten der einen oder anderen hängt von den Importeinstellungen in Ihrem Projekt ab; ist json-loader konfiguriert). Unser importService sowie seine Tests (wir werden später darüber nachdenken) importieren aus diesen Dateien die Daten, die zur Simulation von Antworten aus einem echten Backend erforderlich sind (es wurde noch nicht implementiert). Wo diese Daten abgelegt werden sollen, ist nicht wichtig. Die Hauptsache ist, dass sie einfach in importService selbst importiert und in unserem Microservice getestet werden können.
Es ist ratsam, das Datenformat und die Feldbenennungskonvention sofort mit den Entwicklern der Rückseite zu besprechen. Sie können beispielsweise zustimmen, ein Format zu verwenden, das der OpenAPI-Spezifikation entspricht . Unabhängig von den Spezifikationen für das Sicherungsformat erstellen wir gefälschte Daten genau in Übereinstimmung mit dem Sicherungsdatenformat.
Hinweis: Haben Sie keine Angst, einen Fehler mit dem gefälschten Datenmodell zu machen. Ihre Aufgabe ist es, einen Entwurf des Datenvertrags zu erstellen, der dann noch mit den Backend-Entwicklern vereinbart wird.
Verträge
Gefälschte Daten können als guter Ausgangspunkt für die Arbeit an der Spezifikation der zukünftigen API im Back-End dienen. Und hier spielt es keine Rolle, wer und wie qualitativ der Entwurf des Modells umgesetzt wird. Entscheidend ist die gemeinsame Diskussion und Koordination unter Beteiligung von Front- und Back-Entwicklern.
Sie können spezielle Tools verwenden, um Verträge zu beschreiben (API-Spezifikationen). Zum Beispiel OpenAPI / Swagger . Bei der Beschreibung einer API mit einem solchen Tool müssen nicht alle Entwickler anwesend sein. Dies kann von einem Entwickler (Spezifikationseditor) durchgeführt werden. Das Ergebnis einer gemeinsamen Diskussion über die neue API waren einige Artefakte wie MFU (Meeting Follow Up), nach denen der Spezifikationseditor auch eine Referenz für die zukünftige API erstellt.
Am Ende des Spezifikationsentwurfs sollte es nicht lange dauern, bis die Richtigkeit überprüft wurde. Jeder Teilnehmer an der kollektiven Diskussion kann unabhängig von den anderen eine flüchtige Prüfung durchführen, um zu überprüfen, ob seine Meinung berücksichtigt wurde. Wenn etwas nicht stimmt, können Sie dies anhand der Editor-Spezifikationen (normale Arbeitskommunikation) klären. Wenn alle mit der Spezifikation zufrieden sind, kann sie veröffentlicht und als Dokumentation für den Service verwendet werden.
Unit Testing
Hinweis: Für mich ist der Wert von Unit-Tests ziemlich niedrig. Hier stimme ich David Heinemeier Hansson @ RailsConf zu . "Unit-Tests sind eine großartige Möglichkeit, um sicherzustellen, dass Ihr Programm das tut, was Sie können ... wie erwartet." Aber ich gebe Sonderfälle zu, in denen Unit-Tests viel Nutzen bringen.
Nachdem wir uns für die gefälschten Daten entschieden haben, können wir mit dem Testen der Grundfunktionalität beginnen. Zum Testen von Front-End-Komponenten können Sie Tools wie Karma, Scherz, Mokka, Chai, Jasmin verwenden. Normalerweise wird die gleichnamige Datei mit dem Postfix "spec" oder "test" neben der zu testenden JS-Ressource platziert:
importService ├ importService.js └ importService.test.js
Der spezifische Wert des Postfix hängt von den Einstellungen des JS-Paketkollektors in Ihrem Projekt ab.
Natürlich ist es in einer Situation, in der sich der Rücken in einem „empfängnisverhütenden“ Zustand befindet, sehr schwierig, alle möglichen Fälle mit Unit-Tests abzudecken. Der Zweck von Unit-Tests ist jedoch etwas anders. Sie dienen zum Testen der Funktionsweise einzelner Logikelemente.
Zum Beispiel ist es gut, verschiedene Arten von Helfern mit Komponententests abzudecken, durch die Logikelemente oder bestimmte Algorithmen zwischen JS-Komponenten und -Diensten gemeinsam genutzt werden. Diese Tests können auch das Verhalten in den Komponenten und Speichern von MobX, Redux, VueX als Reaktion auf Änderungen der Benutzerdaten abdecken.
Integration und E2E-Test
Integrationstests bedeuten, das Verhalten des Systems auf Übereinstimmung mit der Spezifikation zu überprüfen. Das heißt, Es wird überprüft, ob der Benutzer genau das Verhalten sieht, das in den Spezifikationen beschrieben ist. Dies ist ein höheres Testniveau im Vergleich zu Unit-Tests.
Zum Beispiel ein Test, der unter dem erforderlichen Feld nach einem Fehler sucht, wenn der Benutzer den gesamten Text gelöscht hat. Oder ein Test, der überprüft, ob beim Speichern ungültiger Daten ein Fehler generiert wird.
E2E-Tests (End-to-End) arbeiten auf einem noch höheren Niveau. Sie überprüfen, ob das Verhalten der Benutzeroberfläche korrekt ist. Wenn Sie beispielsweise überprüfen, ob dem Benutzer nach dem Senden der Datendatei an den Dienst eine Wendung angezeigt wird, die einen fortlaufenden asynchronen Prozess signalisiert. Oder überprüfen Sie, ob die Visualisierung der Standardkomponenten des Dienstes mit den Anleitungen der Designer übereinstimmt.
Diese Art von Test funktioniert mit einigen UI-Automatisierungsframeworks. Zum Beispiel könnte es Selen sein . Solche Tests werden zusammen mit Selenium WebDriver in einigen Browsern ausgeführt (normalerweise Chrome mit "Headless-Modus"). Sie arbeiten lange, entlasten aber die QS-Spezialisten und führen einen Rauchtest für sie durch.
Das Schreiben dieser Art von Tests ist ziemlich zeitaufwändig. Je früher wir anfangen, sie zu schreiben, desto besser. Trotz der Tatsache, dass wir kein vollwertiges Backup haben, können wir bereits mit der Beschreibung von Integrationstests beginnen. Wir haben bereits eine Spezifikation.
Mit einer Beschreibung des E2E gibt es noch weniger Hindernistests. Wir haben bereits die Standardkomponenten aus der Bibliothek der Designatome skizziert. Implementierte bestimmte Teile der Benutzeroberfläche. In importService wurden einige interaktive Daten zusätzlich zu gefälschten Daten und APIs erstellt. Zumindest in einfachen Fällen hindert Sie nichts daran, die Automatisierung der Benutzeroberfläche zu starten.
Wenn Sie diese Tests schreiben, können Sie einzelne Entwickler erneut verwirren, wenn es keine verwirrten Personen gibt. Um die Tests zu beschreiben, können Sie einen separaten Zweig erstellen (wie oben beschrieben). In den Zweigen für Tests müssen Updates aus dem Zweig " feature / import-dev " regelmäßig aktualisiert werden.
Die allgemeine Reihenfolge der Zusammenführungen lautet wie folgt:
- Beispielsweise hat ein Entwickler aus dem Zweig " Feature / Import-Filter " eine PR erstellt. Diese PR wird in der Vorschau angezeigt, und der Betreuer des Zweigs " feature / import-dev " injiziert diese PR.
- Der Maintainer gibt bekannt, dass das Update veröffentlicht wurde.
- Der Entwickler in der Verzweigung " feature / import-tests-e2e " zieht beim Zusammenführen aus der Verzweigung " -dev " extreme Änderungen.
CI- und Testautomatisierung
Front-End-Tests werden mithilfe von Tools implementiert, die über die CLI funktionieren. In package.json werden Befehle geschrieben, um verschiedene Arten von Tests auszuführen. Diese Befehle werden nicht nur von Entwicklern in der lokalen Umgebung verwendet. Sie werden auch benötigt, um Tests in der CI-Umgebung (Continuous Integration) auszuführen.
Wenn wir jetzt den Build in CI ausführen und keine Fehler vorliegen, wird unser lang erwarteter Prototyp an die Testumgebung geliefert (80% der Funktionen an der Vorderseite mit einem noch nicht implementierten Back-End). Wir können Vasily das ungefähre Verhalten des zukünftigen Mikrodienstes zeigen. Vasiliy tritt gegen diesen Prototyp und wird vielleicht einige Bemerkungen machen (vielleicht sogar ernsthafte). Zu diesem Zeitpunkt sind Anpassungen nicht teuer. In unserem Fall erfordert die Unterlage ernsthafte architektonische Änderungen, sodass die Arbeit langsamer als auf der Vorderseite erfolgen kann. Solange die Unterstützung nicht abgeschlossen ist, werden Änderungen am Plan für seine Entwicklung keine katastrophalen Folgen haben. Falls erforderlich, ändern Sie zu diesem Zeitpunkt etwas. Wir werden Sie bitten, Anpassungen an der API-Spezifikation vorzunehmen (in swagger). Danach werden die oben beschriebenen Schritte wiederholt. Front-Line-Mitarbeiter sind immer noch nicht auf Backends angewiesen. Einzelne Frontend-Spezialisten sind unabhängig voneinander.
Backend. Stub-Controller
Ausgangspunkt für die Entwicklung der API im Backend ist die genehmigte API-Spezifikation ( OpenAPI / Swagger ). Wenn es eine Spezifikation gibt, lässt sich das Backing auch leichter parallelisieren. Die Analyse der Spezifikation sollte Entwickler dazu veranlassen, über die Grundelemente der Architektur nachzudenken. Welche allgemeinen Komponenten / Dienste müssen Sie erstellen, bevor Sie mit der Implementierung einzelner API-Aufrufe fortfahren können? Und auch hier können Sie den Ansatz wie bei Leerzeichen für die Benutzeroberfläche anwenden.
Wir können von oben beginnen, d.h. von der äußeren Schicht unseres Rückens (von Controllern). In dieser Phase beginnen wir mit Routing, Controller-Leerzeichen und gefälschten Daten. Die Schicht von Diensten (BL) und Datenzugriff (DAL) haben wir noch nicht. Wir übertragen einfach die Daten von JS an das Backend und programmieren die Controller so, dass sie die erwarteten Antworten für die Grundfälle implementieren und Teile aus den gefälschten Daten ausgeben.
Nach Abschluss dieser Phase sollten Frontsoldaten ein funktionierendes Backend für statische Testdaten erhalten. Darüber hinaus schreiben die Frontsoldaten genau die Integrationstests. Im Prinzip sollte es derzeit nicht schwierig sein, das JS-Gateway (importService) auf die Verwendung von Controller-Leerzeichen im Hintergrund umzustellen.
Der Antwortteil für Anforderungen über Websocket unterscheidet sich konzeptionell nicht von Web-API-Controllern. Wir machen diese "Antwort" auch auf Testdaten und verbinden importService mit dieser Vorbereitung.
Letztendlich müssen alle JS übertragen werden, um mit einem echten Server zu arbeiten.
Backend. Finalisierung der Controller. DAO Stubs
Jetzt ist es an der Zeit, die externe Trägerschicht fertigzustellen. Für Steuerungen werden Dienste einzeln in BL implementiert. Jetzt arbeiten Dienste mit gefälschten Daten. Der Zusatz in dieser Phase ist, dass wir in Services bereits echte Geschäftslogik implementieren. In dieser Phase ist es ratsam, neue Tests gemäß der Geschäftslogik der Spezifikationen hinzuzufügen. Es ist wichtig, dass kein Integrationstest fällt.
Hinweis: Wir sind immer noch nicht davon abhängig, ob das Datenschema in der Datenbank implementiert ist.
Backend. Finalisieren Sie DAO. Echt db
Nachdem das Datenschema in der Datenbank implementiert wurde, können wir die Testdaten aus den vorherigen Schritten darauf übertragen und unsere rudimentäre DAL auf die Arbeit mit dem realen Datenbankserver umstellen. Weil Wir übertragen die für die Front erstellten Anfangsdaten in die Datenbank, alle Tests sollten relevant bleiben. Wenn einer der Tests fällt, ist ein Fehler aufgetreten und Sie müssen verstehen.
Hinweis: Im Allgemeinen gibt es bei einer sehr hohen Wahrscheinlichkeit, mit dem Datenschema in der Datenbank zu arbeiten, wenig für eine neue Funktion. Möglicherweise werden Änderungen an der Datenbank gleichzeitig mit der Implementierung von Diensten in BL vorgenommen.
Am Ende dieser Phase erhalten wir eine vollständige Alpha-Version des Mikroservices. Diese Version kann bereits internen Benutzern (Product Owner, einem Produkttechnologen oder einer anderen Person) zur Bewertung als MVP angezeigt werden.
Die Standarditerationen von Agile zur Behebung von Fehlern, zur Implementierung zusätzlicher Chips und zum endgültigen Polieren werden fortgesetzt.
Fazit
Ich denke, Sie sollten das oben Gesagte nicht blind als Leitfaden für Maßnahmen verwenden. Zuerst müssen Sie anprobieren und sich an Ihr Projekt anpassen. Der oben beschriebene Ansatz kann einzelne Entwickler voneinander trennen und ihnen ermöglichen, unter bestimmten Bedingungen parallel zu arbeiten. Alle Gesten mit Brunch und Datenübertragung, die Implementierung von Leerzeichen für gefälschte Daten scheinen ein erheblicher Aufwand zu sein. Der Gewinn aus diesem Overhead ergibt sich aus der erhöhten Parallelität. Wenn das Entwicklungsteam besteht eineinhalb Bagger Zwei Full Stacks oder ein Freotovik mit einem Backend, dann wird dieser Ansatz wahrscheinlich viel Gewinn bringen. Obwohl in dieser Situation einige Punkte die Wirksamkeit der Entwicklung durchaus erhöhen können.
Der Gewinn dieses Ansatzes zeigt sich, wenn wir zu Beginn schnell Werkstücke implementieren, die einer zukünftigen realen Implementierung so nahe wie möglich kommen, und die Arbeit an verschiedenen Teilen auf Dateistrukturebene im Projekt und auf der Ebene des Code-Management-Systems (git) physisch trennen.
Ich hoffe, Sie fanden diesen Artikel hilfreich.
Vielen Dank für Ihre Aufmerksamkeit!