In einem
früheren Artikel habe ich über unsere große Lasttestinfrastruktur gesprochen. Im Durchschnitt erstellen wir ungefähr 100 Server für die Lastversorgung und ungefähr 150 Server für unseren Service. Alle diese Server müssen erstellt, gelöscht, konfiguriert und ausgeführt werden. Zu diesem Zweck verwenden wir dieselben Werkzeuge wie auf dem Produkt, um den manuellen Arbeitsaufwand zu reduzieren:
- So erstellen und löschen Sie eine Testumgebung: Terraform-Skripte;
- So konfigurieren, aktualisieren und ausführen - Ansible-Skripte;
- Für dynamische Skalierung je nach Auslastung - selbst geschriebene Python-Skripte.
Dank der Skripte Terraform und Ansible werden alle Vorgänge vom Erstellen von Instanzen bis zum Starten des Servers mit nur sechs Befehlen ausgeführt:
# aws ansible-playbook deploy-config.yml # ansible-playbook start-application.yml # ansible-playbook update-test-scenario.yml --ask-vault-pass # Jmeter , infrastructure-aws-cluster/jmeter_clients:~# terraform apply # jmeter ansible-playbook start-jmeter-server-cluster.yml # jmeter ansible-playbook start-stress-test.yml #
Dynamische Serverskalierung
Zur Hauptverkehrszeit in der Produktion haben wir mehr als 20.000 Online-Benutzer gleichzeitig, und zu anderen Zeiten können es 6.000 sein. Es macht keinen Sinn, ständig das gesamte Servervolumen beizubehalten. Daher richten wir die automatische Skalierung für die Board-Server ein, auf denen die Boards zum Zeitpunkt der Benutzereingabe geöffnet sind, sowie für API-Server, die API-Anforderungen verarbeiten. Jetzt werden Server erstellt und bei Bedarf gelöscht.
Dieser Mechanismus ist beim Auslastungstest sehr effektiv: Standardmäßig können wir die Mindestanzahl von Servern haben, und zum Zeitpunkt des Tests steigen diese automatisch in der richtigen Menge an. Zu Beginn können wir 4 Board-Server haben und in der Spitze bis zu 40. Gleichzeitig werden neue Server nicht sofort erstellt, sondern erst, nachdem die aktuellen Server geladen wurden. Das Kriterium zum Erstellen neuer Instanzen kann beispielsweise 50% der CPU-Auslastung sein. Auf diese Weise können Sie das Wachstum virtueller Benutzer im Skript nicht verlangsamen und keine unnötigen Server erstellen.
Ein Bonus dieses Ansatzes ist, dass wir dank der dynamischen Skalierung lernen, wie viel Kapazität wir für eine andere Anzahl von Benutzern benötigen, die wir noch nicht im Verkauf hatten.
Sammlung von Metriken wie auf Prod
Es gibt viele Ansätze und Werkzeuge zur Überwachung von Stresstests, aber wir sind unseren eigenen Weg gegangen.
Wir überwachen die Produktion mit einem Standardstapel: Logstash, Elasticsearch, Kibana, Prometheus und Grafana. Unser Testcluster ähnelt dem Produkt, daher haben wir uns entschieden, dieselbe Überwachung wie das Produkt mit denselben Metriken durchzuführen. Dafür gibt es zwei Gründe:
- Sie müssen kein Überwachungssystem von Grund auf neu erstellen, wir haben es bereits vollständig und sofort.
- Wir testen zusätzlich die Überwachung des Umsatzes: Wenn wir während der Überwachung des Tests verstehen, dass wir nicht über genügend Daten verfügen, um das Problem zu analysieren, reichen diese nicht für die Produktion aus, wenn dort ein solches Problem auftritt.
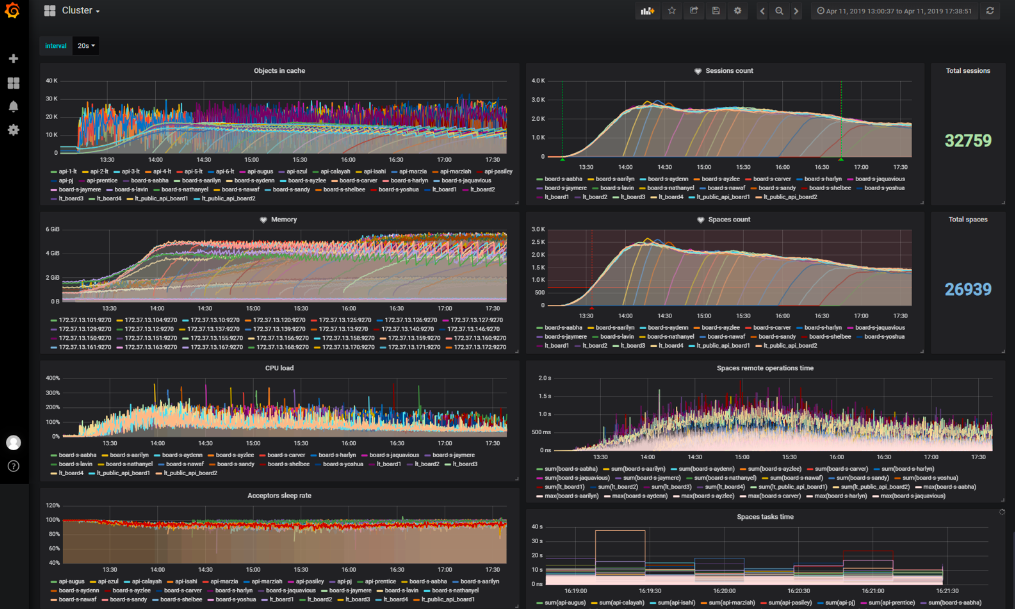
Was wir in den Berichten zeigen
- Technische Eigenschaften des Standes;
- Das Skript selbst, in Worten beschrieben, nicht Code;
- Ein Ergebnis, das für alle Teammitglieder, sowohl Entwickler als auch Manager, verständlich ist.
- Diagramme des allgemeinen Standzustands;
- Diagramme, die einen Engpass anzeigen oder von der im Test überprüften Optimierung betroffen sind.
Es ist wichtig, dass alle Ergebnisse an einem Ort gespeichert werden. Daher ist es praktisch, sie von Start zu Start miteinander zu vergleichen.
Wir erstellen Berichte in unserem Produkt
(Beispiel eines Whiteboards mit einem Bericht) :
Das Erstellen eines Berichts nimmt viel Zeit in Anspruch. Daher planen wir, die Erfassung allgemeiner Informationen mithilfe
unserer öffentlichen API automatisch
durchzuführen .
Infrastruktur als Code
Wir sind für die Qualität des Produkts verantwortlich, nicht für QS-Ingenieure, sondern für das gesamte Team. Stresstests sind eines der Instrumente zur Qualitätssicherung. Cool, wenn das Team versteht, dass es wichtig ist, die vorgenommenen Änderungen unter Last zu überprüfen. Um darüber nachzudenken, muss sie für die Produktion verantwortlich werden. Hier helfen uns die Prinzipien der DevOps-Kultur, die wir in unserer Arbeit umzusetzen begannen.
Es ist jedoch nur der erste Schritt, über die Durchführung von Stresstests nachzudenken. Das Team kann keine Tests durchdenken, ohne das Produktionsgerät zu verstehen. Wir sind auf ein solches Problem gestoßen, als wir damit begannen, Lasttests in Teams durchzuführen. Zu diesem Zeitpunkt hatten die Teams keine Möglichkeit, das Produktionsgerät herauszufinden, so dass es für sie schwierig war, an der Gestaltung der Tests zu arbeiten. Es gab mehrere Gründe: das Fehlen aktueller Unterlagen oder eine Person, die das ganze Bild des Verkaufs in meinem Kopf behalten hätte; Mehrfachwachstum des Entwicklungsteams.
Um den Teams das Verständnis der Vertriebsarbeit zu erleichtern, kann der Infrastrukturansatz als Code verwendet werden, den wir im Entwicklungsteam verwendet haben.
Welche Probleme haben wir bereits mit diesem Ansatz zu lösen begonnen:
- Alles muss in Skripten geschrieben sein und kann jederzeit ausgelöst werden. Dies verkürzt die Wiederherstellungszeit für Verkäufe im Falle eines Rechenzentrumsunfalls erheblich und ermöglicht es Ihnen, die richtige Menge relevanter Testumgebungen beizubehalten
- Angemessene Einsparungen: Wir stellen Umgebungen auf Openstack bereit, wenn diese teure Plattformen wie AWS ersetzen können.
- Die Teams selbst erstellen Stresstests, weil sie verstehen, dass sich das Gerät verkauft.
- Der Code ersetzt die Dokumentation, sodass sie nicht endlos aktualisiert werden muss. Sie ist immer vollständig und aktuell.
- Sie benötigen keinen separaten Experten auf engstem Raum, um normale Probleme zu lösen. Jeder Ingenieur kann den Code herausfinden.
- Mit einer klaren Verkaufsstruktur ist es viel einfacher, Forschungstests wie Chaos-Affentests oder Tests auf lange Speicherlecks zu planen.
Ich möchte diesen Ansatz nicht nur auf die Schaffung von Infrastrukturen, sondern auch auf die Unterstützung verschiedener Tools ausweiten. Zum Beispiel haben wir beim Datenbanktest, über den ich
in einem früheren Artikel gesprochen habe , vollständig in Code umgewandelt. Aus diesem Grund verfügen wir anstelle einer vorbereiteten Site über eine Reihe von Skripten, mit denen wir in 7 Minuten die konfigurierte Umgebung in einem vollständig leeren AWS-Konto abrufen und den Test starten können. Aus dem gleichen Grund prüfen wir nun sorgfältig
Gatling , das die Entwickler als Werkzeug für „Lasttest als Code“ positionieren.
Die Herangehensweise an die Infrastruktur als Code beinhaltet eine ähnliche Herangehensweise an das Testen der Infrastruktur und der Skripte, die das Team schreibt, um die Infrastruktur mit neuen Funktionen zu erweitern. All dies sollte durch Tests abgedeckt werden. Es gibt auch verschiedene Test-Frameworks wie
Molecule . Es gibt Tools für das Testen von Chaosaffen, für AWS gibt es kostenpflichtige Tools, für Docker gibt es
Pumba usw. Mit ihnen können Sie verschiedene Arten von Aufgaben lösen:
- So überprüfen Sie, ob eine der Instanzen in AWS abstürzt, um zu überprüfen, ob die Last auf den verbleibenden Servern neu verteilt wird und ob der Dienst von einer derart scharfen Umleitung von Anforderungen überlebt;
- So simulieren Sie den langsamen Betrieb des Netzwerks, seinen Ausfall und andere technische Probleme, nach denen die Logik der Dienstinfrastruktur nicht unterbrochen werden sollte.
Die Lösung solcher Probleme in unseren unmittelbaren Plänen.
Schlussfolgerungen
- Es lohnt sich nicht, die Testinfrastruktur manuell zu orchestrieren . Es ist besser, diese Aktionen zu automatisieren, um alle Umgebungen, einschließlich Produkte, zuverlässiger zu verwalten.
- Die dynamische Skalierung reduziert die Kosten für die Aufrechterhaltung des Umsatzes und einer großen Testumgebung erheblich und reduziert auch den menschlichen Faktor bei der Skalierung.
- Sie können kein separates Überwachungssystem für Tests verwenden, sondern es vom Markt nehmen.
- Es ist wichtig, dass Stresstestberichte automatisch an einem einzigen Ort gesammelt werden und eine einheitliche Ansicht haben. Auf diese Weise können sie Änderungen leicht vergleichen und analysieren.
- Stresstests werden zu einem Prozess im Unternehmen, wenn sich die Teams für den Verkauf verantwortlich fühlen.
- Lasttests - Infrastrukturtests. Wenn der Auslastungstest erfolgreich war, wurde er möglicherweise nicht korrekt kompiliert. Die Validierung der Richtigkeit des Tests erfordert ein tiefes Verständnis des Umsatzes. Teams sollten die Möglichkeit haben, das Verkaufsgerät unabhängig zu verstehen. Wir lösen dieses Problem mithilfe der Infrastruktur als Code-Ansatz.
- Infrastrukturvorbereitungsskripte müssen wie jeder andere Code getestet werden.