Vor ein paar Monaten stieß ich auf ein Problem, mein Modell, das auf Algorithmen für maschinelles Lernen basiert, funktionierte einfach nicht. Ich habe lange darüber nachgedacht, wie ich dieses Problem lösen kann, und irgendwann wurde mir klar, dass mein Wissen sehr begrenzt und meine Ideen knapp sind. Ich kenne ein paar Dutzend Modelle, und dies ist ein sehr kleiner Teil dieser Arbeiten, die sehr nützlich sein können.
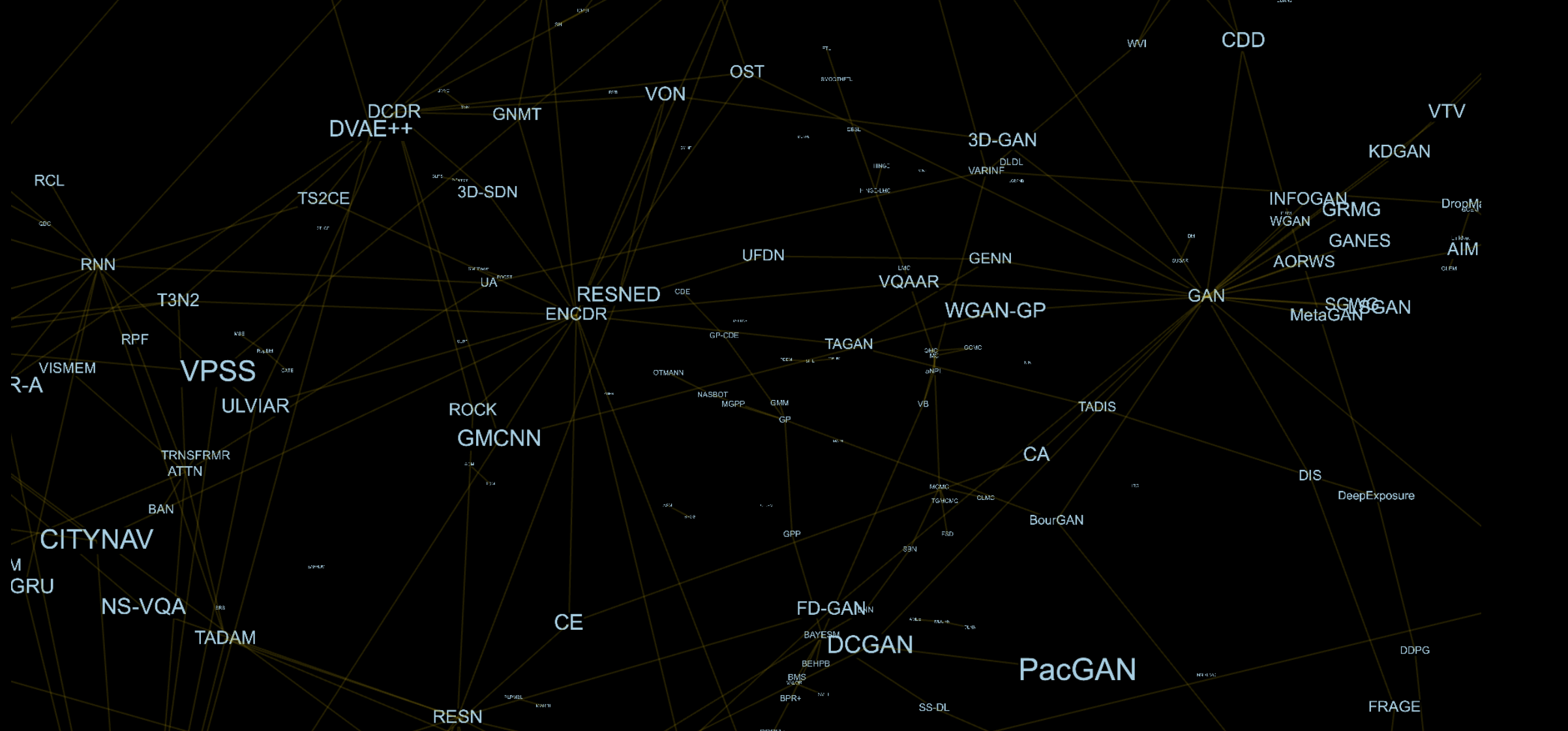
Der erste Gedanke, der mir in den Sinn kam, ist, dass meine Qualitäten als Forscher und Ingenieur insgesamt zunehmen werden, wenn ich mehr Modelle kenne und verstehe. Diese Idee veranlasste mich, Artikel von kürzlich abgehaltenen Konferenzen zum maschinellen Lernen zu studieren. Die Strukturierung solcher Informationen ist ziemlich schwierig und es ist notwendig, die Abhängigkeiten und Beziehungen zwischen den Methoden aufzuzeichnen. Ich wollte die Abhängigkeiten nicht in Form einer Tabelle oder einer Liste darstellen, aber ich wollte etwas Natürlicheres. Als Ergebnis wurde mir klar, dass es ziemlich interessant ist, ein dreidimensionales Diagramm mit Kanten zwischen Modellen und ihren Komponenten für mich zu haben.
Beispielsweise besteht GAN [1] architektonisch aus einem Generator (GEN) und einem Diskriminator (DIS), Adversarial Auto-Encoder (AAE) [2] aus Auto-Encoder (AE) [3] und DIS ,. Jede Komponente ist ein separater Scheitelpunkt in diesem Diagramm. Für AAE haben wir also eine Kante mit AE und DIS.
Schritt für Schritt analysierte ich die Artikel, schrieb auf, aus welchen Methoden sie bestehen, in welchem Themenbereich sie angewendet werden, auf welche Daten sie getestet wurden und so weiter. Dabei wurde mir klar, wie viele sehr interessante Lösungen unbekannt bleiben und ihre Anwendung nicht finden.
Maschinelles Lernen ist in Themenbereiche unterteilt, in denen jeder Bereich versucht, ein bestimmtes Problem mit bestimmten Methoden zu lösen. In den letzten Jahren wurden die Grenzen fast gelöscht, und es ist praktisch schwierig, die Komponenten zu identifizieren, die nur in einem bestimmten Gebiet verwendet werden. Dieser Trend führt im Allgemeinen zu verbesserten Ergebnissen, aber das Problem ist, dass mit der Zunahme der Anzahl der Artikel viele interessante Methoden unbemerkt bleiben. Dafür gibt es viele Gründe, und die Popularisierung nur bestimmter Bereiche durch große Unternehmen spielt dabei eine wichtige Rolle. Als die Grafik dies erkannte, wurde sie öffentlich und offen.
Natürlich habe ich recherchiert und versucht, Analoga zu dem zu finden, was ich tat. Es gibt genügend Dienste, mit denen Sie die Entstehung neuer Artikel in diesem Bereich überwachen können. Alle diese Methoden zielen jedoch in erster Linie darauf ab, den Erwerb von Wissen zu vereinfachen und nicht dazu beizutragen, neue Ideen zu entwickeln. Kreativität ist wichtiger als Erfahrung, und Werkzeuge, mit denen Sie in verschiedene Richtungen denken und ein vollständigeres Bild sehen können, sollten meiner Meinung nach ein wesentlicher Bestandteil des Forschungsprozesses werden.
Wir haben Tools, die das Experimentieren, Starten und Bewerten von Modellen erleichtern, aber wir haben keine Methoden, mit denen wir schnell Ideen generieren und bewerten können.
In nur wenigen Monaten habe ich ungefähr 250 Artikel von der letzten NeurIPS-Konferenz und ungefähr 250 andere Artikel, auf denen sie basieren, aussortiert. Die meisten Bereiche waren mir völlig unbekannt, es dauerte mehrere Tage, um sie zu verstehen. Manchmal konnte ich einfach nicht die richtige Beschreibung für die Modelle finden und aus welchen Komponenten sie bestehen. Ausgehend davon bestand der zweite logische Schritt darin, den Autoren die Möglichkeit zu geben, Methoden im Diagramm selbst hinzuzufügen und zu ändern, da niemand außer den Autoren des Artikels weiß, wie sie ihre Methode am besten analysieren und beschreiben können.
Ein Beispiel dafür, was als Ergebnis passiert ist, wird hier vorgestellt.
Ich hoffe, dass dieses Projekt für jemanden nützlich sein wird, schon allein deshalb, weil es vielleicht jemandem ermöglicht, Assoziationen zu finden, die zu einer neuen interessanten Idee führen können. Ich war überrascht, als ich hörte, wie die Idee generativer Wettbewerbsnetzwerke basiert. Beim MIT Machine Intelligence Podcast [4] sagte Yan Goodfellow, dass die Idee von gegnerischen Netzwerken mit den „positiven“ und „negativen“ Phasen des Boltzman Machine Learning [5] verbunden ist.
Dieses Projekt ist Community-orientiert. Ich möchte es weiterentwickeln und mehr Menschen motivieren, dort Informationen über ihre Methoden hinzuzufügen oder das bereits Erstellte zu bearbeiten. Ich glaube, dass genauere Methodeninformationen und bessere Visualisierungstechnologien wirklich dazu beitragen werden, dass dies ein nützliches Werkzeug ist.
Es gibt viel Raum für die Entwicklung des Projekts, angefangen bei der Verbesserung der Visualisierung selbst bis hin zur Möglichkeit, ein individuelles Diagramm mit der Möglichkeit zu erstellen, Empfehlungen für Verbesserungsmethoden zu erhalten.
Einige technische
Details finden Sie hier .
[1] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville und Yoshua Bengio. Generative gegnerische Netze.[2] Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow und Brendan Frey. Gegnerische Autoencoder.[3] Dana H. Ballard. Autoencoder.[4] Ian J. Goodfellow: Podcast über künstliche Intelligenz am MIT.[5] Ruslan Salakhutdinov, Geoffrey Hinton. Tiefboltzmann-Maschinen