Im Code verschiedener Projekte muss man oft pünktlich arbeiten - zum Beispiel, um die Benutzerlogik der Anwendung an die aktuelle Zeit zu binden. Victor Khomyakov, Victor-
homyakov, leitender Schnittstellenentwickler, beschrieb die typischen Fehler, die er in Projekten in Java, C # und JavaScript von verschiedenen Autoren hatte. Sie standen vor denselben Aufgaben: Abrufen des aktuellen Datums und der aktuellen Uhrzeit, Messen von Intervallen oder asynchrones Ausführen von Code.
- Vor Yandex habe ich bei anderen Lebensmittelunternehmen gearbeitet. Das ist nicht wie ein Freiberufler - ich habe geschrieben, bestanden und vergessen. Die Arbeit mit einer Codebasis dauert sehr lange. Und ich habe tatsächlich viel Code in verschiedenen Sprachen gesehen, gelesen, geschrieben und viele interessante Dinge gesehen. Als Ergebnis wurde mir das Thema dieser Geschichte geboren.
Ich habe zum Beispiel gesehen, dass in verschiedenen Projekten in verschiedenen Sprachen dieselben oder sehr ähnliche Aufgaben auftreten - Arbeiten mit Datum und Uhrzeit. Zusätzlich zu dieser Arbeit selbst kann es sich um Popup-Vorgänge im Code mit Datums- und Zeitobjekten handeln.

Es stellt sich heraus, dass Sie unabhängig davon, ob Sie das Front-End oder das Back-End sind, ähnliche Aufgaben für die Arbeit mit asynchronem Code haben. Wenn Sie sich im Backend befinden, handelt es sich um Abfragen an die Datenbank, Remote-Aufrufe. Wenn das Frontend - Sie haben natürlich AJAX. Unterschiedliche Menschen in unterschiedlichen Projekten lösen diese Probleme fast gleich, das ist die Essenz des Menschen. Mit einer ähnlichen Aufgabe treffen Sie eine ähnliche Entscheidung, unabhängig von der Sprache, die Sie denken. Und es ist logisch, dass Sie - wir, ich - gleichzeitig sehr ähnliche Fehler machen.
Worüber möchte ich am Ende sprechen? Über diese sich wiederholenden Muster, die unabhängig von der Sprache auftreten, in der Sie schreiben, über Fehler, die leicht zu machen sind, und darüber, wie man sie nicht macht.
Der erste Teil ist in der Tat der Zeit gewidmet. Wie Sie wissen, bewegt sich die Zeit. Beispiel: Sie müssen einen Bericht für gestern für den gesamten letzten Tag schreiben. Wenn Sie eine Anfrage an die Datenbank stellen, müssen Sie alle Datensätze abrufen, deren Datum größer oder gleich gestern und kleiner als heute ist. Das heißt, Sie beginnen mit dem Datum „heute minus einen Tag“ und bis zum heutigen Datum, ohne es einzuschließen.

Sie schreiben also im Allgemeinen linear Code. Startdatum - heute minus ein Tag, Enddatum - heute. Es scheint, dass alles funktioniert, aber genau um Mitternacht haben Sie eine seltsame Sache. Ihr Starttermin ist hier. Startdatum minus einen Tag - das stellt sich heraus. Danach ist das Enddatum des Berichts aus irgendeinem Grund völlig anders.

Sie, oder besser gesagt Ihr Chef, erhalten einen Bericht für zwei Tage anstelle von einem. Der technische Manager und der Manager kommen, beschweren sich und bieten Ihnen höflich an, in sechs Monaten zu einem anderen Team zu wechseln.

Aber dann werden Sie mit neuem Wissen bereichert. Sie verstehen, dass die Zeit nicht stehen bleibt. Wenn Sie Date.now () zweimal aufrufen oder neues Date () erhalten, hoffen Sie nicht, denselben Wert zu erhalten. Es kann manchmal dasselbe sein, aber es kann nicht dasselbe sein. Wenn Sie also eine Methode haben, eine beliebige Logik, sollte es höchstwahrscheinlich nur einen Aufruf von Date.now () geben oder ein neues Date (), den aktuellen Zeitpunkt.
Oder gehen wir auf die andere Seite: Im Datenverarbeitungsdatenstrom müssen alle bedeutungsbezogenen Werte - Anfang und Ende des Berichts - streng aus einem Objekt berechnet werden. Zum Beispiel nicht von zwei ähnlichen, sondern von genau einem. Sie werden mit diesem neuen Wissen bereichert, wechseln Sie in ein neues Team. Dort sind die Leute mehr besorgt über die Geschwindigkeit und Leistung des Codes.

Außerdem wird Ihnen angeboten, den Code mit der Protokollierung zu überlagern, um zu messen, wie viel Zeit ein Vorgang benötigt. Wenn dies ein schwieriger Vorgang ist, ist es wichtig, dass er den Client nicht verlangsamt. Wenn Sie etwas im Backend oder auf Node schreiben, ist es auch eine schwierige Transaktion. Dann werden Sie gefragt: "Bitte schreiben Sie in das Protokoll, wie lange es dauert, und dann berechnen wir, wie sich unsere Kunden abhängig vom Benutzeragenten verhalten."
Dann kommen zwei bereits neue Chefs zu Ihnen und zeigen Ihnen einen Eintrag im Protokoll, in dem Sie plötzlich negative Zeiten protokollieren. Und sie bieten Ihnen auch höflich an, in sechs Monaten zu einem anderen Team zu wechseln.

Sie erhalten wertvolles Wissen darüber, dass die Methoden zum Abrufen des Datums und der Uhrzeit, die Sie verwenden, nur zeigen, was Sie in der Uhr Ihres Betriebssystems haben. Sie garantieren auch keine gleichmäßige Veränderung. Das heißt, in Ihrer Sekunde in Echtzeit kann Date.now () sowohl für eine Sekunde als auch für etwas mehr - etwas weniger springen. Und im Prinzip garantieren sie im Allgemeinen nicht die Monotonie des Wandels. Das heißt, wie in diesem Beispiel kann es plötzlich abnehmen, der Wert von Date.now () kann plötzlich abnehmen.
Was ist der Grund? In der Zeitsynchronisation. Auf Linux-ähnlichen Systemen gibt es einen NTP-Daemon, der die Uhr Ihres Betriebssystems mit der genauen Uhr im Internet synchronisiert. Und wenn Sie eine Verzögerung oder einen Vorsprung haben, kann dies Ihre Uhr entweder künstlich verlangsamen oder beschleunigen, oder wenn Sie eine sehr große Zeitlücke haben, wird er verstehen, dass er nicht in der Lage sein wird, die richtige Zeit mit unauffälligen Schritten und nur mit einem Sprung zu erfassen ändert es. Infolgedessen erhalten Sie eine Lücke in den Messwerten Ihrer Uhr.
Oder Sie können es sehr komplizieren: Der Benutzer selbst, der die Kontrolle über die Uhr hat, möchte möglicherweise auch nur die Uhr ändern. Er wollte es wirklich. Und wir haben kein Recht, ihn aufzuhalten. Und in den Protokollen bekommen wir Pausen. Dementsprechend gibt es auch bereits eine Lösung für dieses Problem. Es ist ganz einfach: Es gibt Zeitlieferanten. Wenn Sie sich in einem Browser befinden, ist dies performance.now (). Wenn Sie in Node schreiben, gibt es einen hochauflösenden Timer, die beide die Eigenschaften Einheitlichkeit und Monotonie aufweisen. Das heißt, diese Anbieter von Zeitstempeln nehmen immer nur zu und gleichzeitig gleichmäßig in einer Sekunde in Echtzeit zu.
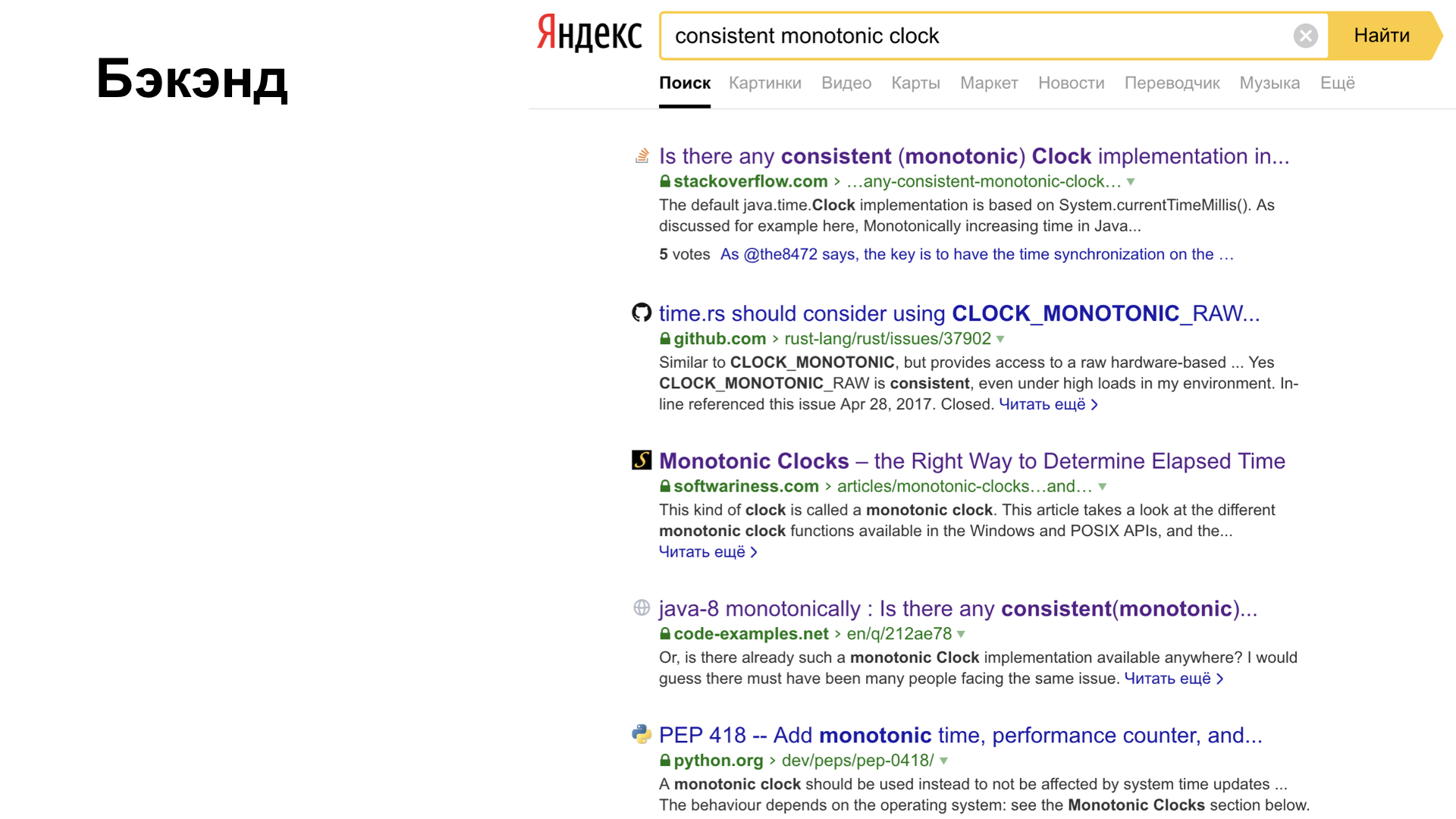
Das Backend hat das gleiche Problem. Es spielt keine Rolle, welche Sprache Sie schreiben. Zum Beispiel können Sie nach einer monotonen konsistenten Uhr suchen, und das Problem gibt Ihnen, in dem fast alle Sprachen dargestellt werden. In Rust gibt es das gleiche Problem. Es gibt auch den Schmerz eines Programmierers, der in Python, Java und anderen Sprachen ist. In diesen Sprachen sind die Leute auch auf einen Rechen getreten, dieses Problem ist bekannt, es gibt eine Lösung. Für Java gibt es beispielsweise einen Aufruf mit denselben Eigenschaften wie Einheitlichkeit und Monotonie.
Wenn Sie ein verteiltes System haben, beispielsweise modische Mikrodienste, ist dies noch komplizierter. Es gibt N verschiedene Dienste auf N verschiedenen Maschinen, die Uhr, auf der im Allgemeinen im Prinzip niemals eine Anzeige konvergieren kann, auf die es nicht einmal zu hoffen gibt.
Und wenn Sie Probleme beim Protokollieren von Aktionen haben, können Sie nur einen Zeitvektor protokollieren. Es stellt sich heraus, dass Sie N-mal von N Systemen protokollieren, die an der Verarbeitung einer Anforderung beteiligt sind. Oder Sie gehen einfach zum abstrakten Zähler, der sich einfach erhöht: 1, 2, 3, 4, 5, bei dieser Operation tickt er auf jeder Maschine gleichmäßig. Und Sie schreiben solche Zähler, um all diese Phasen der Verarbeitung Ihrer Anforderungen auf verschiedenen Computern zu verknüpfen und sich ein Bild davon zu machen, wann, was in welcher Reihenfolge passiert.
Vergessen Sie auch nicht: Wenn Sie Front-End oder Back-End sind, die mit dem Front-End in enger Verbindung arbeiten, dann ist unser Front-End plus Back-End auch ein verteiltes System. Und wenn Sie auch an einer schwierigen Sitzung der Arbeit des Kunden interessiert sind, versuchen Sie bitte zunächst, diese nicht zu verwechseln, wenn Sie in den Protokollen nachsehen, wann Sie Folgendes sehen: „Hier ist die Aufzeichnung, dass dieser Vorgang so oft stattgefunden hat "- sehen Sie Serverzeit oder Clientzeit?" Und zweitens versuchen Sie, beide Male zu sammeln, denn wie gesagt, die Zeiten können in verschiedene Richtungen gehen.
Genug der Zeit. Der zweite Teil ist unberechenbarer.
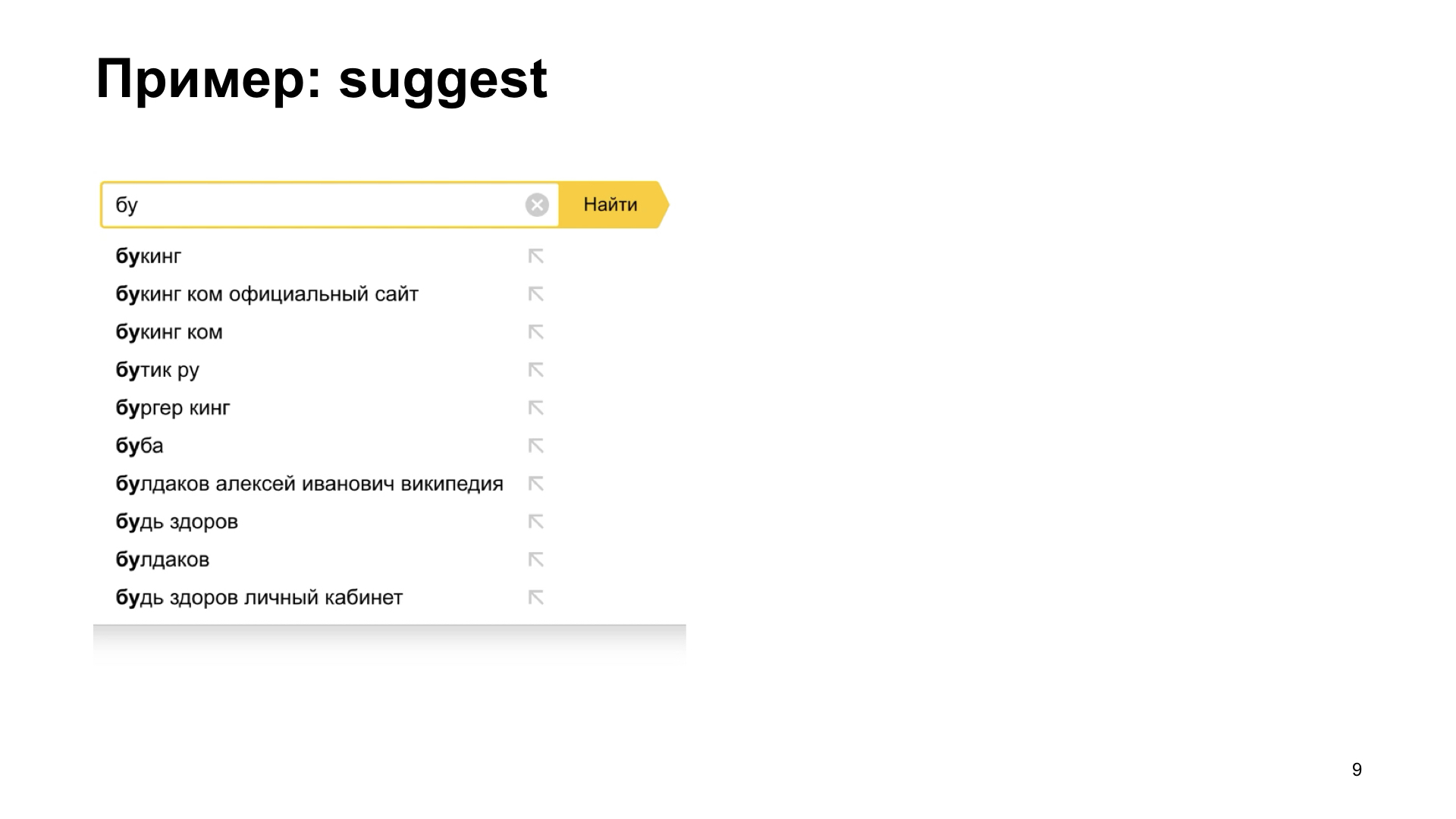
Hier ist ein Beispiel. Es gibt ein sehr nützliches Schnittstellenelement, wenn der Benutzer nicht genau weiß, was er will. Dies wird als Vorschlagen oder automatische Vervollständigung bezeichnet. Wir können ihm Optionen mitteilen, um die Anfrage fortzusetzen. Das heißt, für den Benutzer ist dies ein sehr großer Vorteil. Es ist für ihn viel bequemer zu arbeiten, wenn wir ihm sofort zeigen, dass wir wissen, was wir weiter rekrutieren können.
Wenn wir jedoch ein etwas langsames Netzwerk erhalten oder wenn das Backend, das Antworten und Optionen für die Fortsetzung bietet, langsamer wird, können wir solche interessanten Effekte erzielen. Die Benutzertypen, Typen, dann kommt die richtige Antwort, wir sehen es, und dann bricht alles zusammen. Aus irgendeinem Grund sehen wir überhaupt nicht, was wir sehen wollten. Hier sehen wir die richtige Antwort und sofort einen Unsinn in eine Art Zwischenzustand. Wieder schiere Schmerzen und Leiden. Unsere Chefs kommen zu uns und bitten uns, diesen Fehler zu beheben.

Wir beginnen zu verstehen. Was bekommen wir? Wenn der Benutzer seinen Text eingibt, werden sequentielle asynchrone Anforderungen generiert. Das, was er eingegeben hat, senden wir an das Backend. Er wählt weiter, wir senden eine zweite Anfrage für das Backend, und niemand hat uns jemals garantiert, dass unsere Rückrufe in genau derselben Reihenfolge aufgerufen werden.
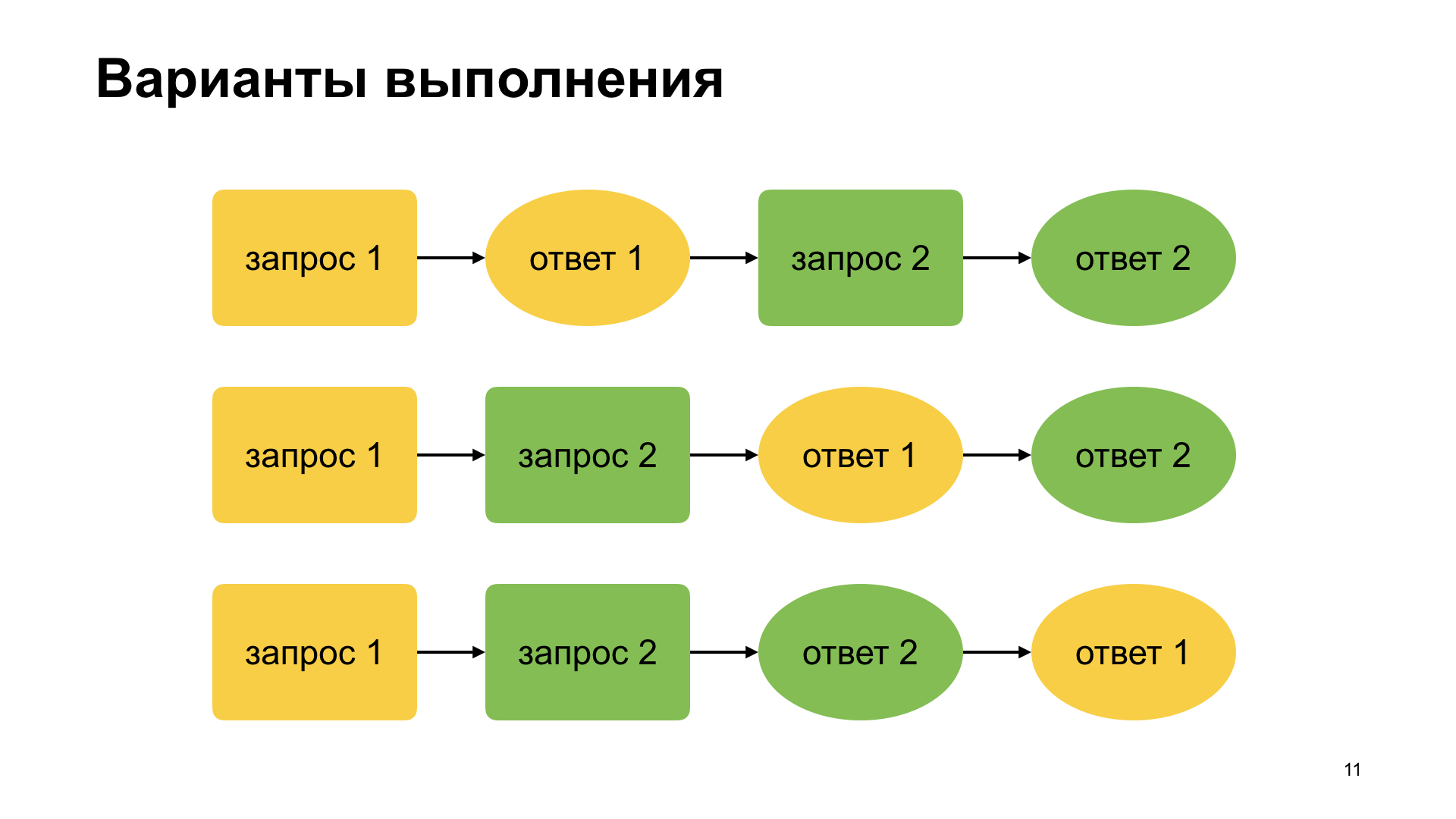
Dies sind die möglichen Abfrage- und Rückrufoptionen. Das offensichtlichste, wenn wir schreiben, denken wir: Sie haben die erste Anfrage gesendet, die erste Antwort erhalten, die zweite Anfrage gesendet, die Antwort erhalten. Wenn der Benutzer sehr schnell tippt, können wir uns die zweite Option ausdenken, mit der wir die erste Anfrage gesendet haben. Der Benutzer hat etwas eingegeben, bevor er die erste Antwort erhalten hat. Dann kam die erste Antwort, die zweite Antwort. Und hier ist, was wir im Video gesehen haben: Wenn der Vorschlag nicht richtig funktioniert hat, ist dies die dritte Option, die oft vergessen wird, dass niemand die Reihenfolge der Antworten im Allgemeinen garantiert.

Bei Front-End-Anbietern tritt dieses Problem häufig auf, wenn Sie Schnittstellen entwickeln. Insbesondere das Beispiel mit suggerieren, mit Autocomplete, das wir gerade gesehen haben. Das heißt, es gibt einen Strom von Anforderungen und einen Strom von Antworten, die asynchron ankommen.
Wenn Sie Registerkarten haben. Heben Sie Ihre Hände, wer auf GitHub hat jemals mindestens eine Pull-Anfrage gestellt? Sie erinnern sich, dass dort tatsächlich die Oberfläche mit Registerkarten basiert, dh es gibt eine Registerkarte, auf der eine Folge von Kommentaren vorhanden ist, eine Registerkarte mit Commits und eine Registerkarte mit dem Code selbst. Dies ist eine solche Oberfläche mit Registerkarten. Wenn Sie zu einer benachbarten Registerkarte wechseln, wird deren Inhalt zum ersten Mal asynchron geladen.
Wenn Sie schnell auf verschiedene Registerkarten klicken, stellt sich möglicherweise heraus, dass Sie sie aktiviert haben, und dann wird das Laden des Inhalts blinkt. Und am Ende ist es keine Tatsache, dass Sie den Inhalt der richtigen Registerkarte sehen. Wenn Sie richtig sind, schreiben Sie natürlich keine eigenen.
Zum Beispiel, wenn Sie ein Geschäft haben, wenn Sie Waren schnell in den Warenkorb ziehen. Ein schneller, scharfer Benutzer schleppte zehn Waren, und dann sieht er, wie sein Preis blinkt und relativ gesehen 100 Rubel, 10 Rubel, 50 Rubel, 75 Rubel und bleibt bei einem Rubel stehen. Er glaubt dir nicht, er denkt, dass du schlecht schreibst, du willst ihn täuschen und verlässt deinen Laden, ohne etwas zu kaufen.
Ein Beispiel. Wenn Sie eine Art Scrum oder Kanban oder etwas anderes haben und elektronische Bretter zum Ziehen und Ablegen von Karten verwenden, haben Sie die Karten wahrscheinlich mindestens einmal verpasst, als Sie sie gezogen und in die falsche Spalte gelegt haben. Ist das passiert? Natürlich fängst du dich und packst es sofort scharf und ziehst es dorthin, wo es sein sollte. In diesem Fall generieren Sie sehr schnell zwei Abfragen. Und in verschiedenen Systemen treten unmittelbar danach Fehler auf. Sie haben es in die richtige Spalte gezogen - die Antwort auf die erste Anfrage kommt an und die Karte springt erneut in die Spalte, in die Sie sie übertragen haben. Es stellt sich als sehr hässlich heraus.

Was ist die Moral? Angenommen, Sie haben eine Quelle für dieselbe Art von Anforderung. Wenn die nächste Anforderung eintrifft, unterbrechen Sie nach Möglichkeit alle unvollständigen Anforderungen, um keine Ressourcen zu verschwenden, damit das Backend weiß, dass Sie sie nicht mehr benötigen.
So steuern Sie bei der Verarbeitung von Antworten auch alles. Und wenn eine Antwort auf eine frühere Anfrage eingeht, die Sie nicht benötigen, ignorieren Sie sie ebenfalls explizit.

Dementsprechend besteht das Problem schon lange und die Lösung existiert auch schon. Zum Beispiel in der RxJS-Bibliothek. Dies ist direkt ein Beispiel aus der Dokumentation, richtig Hallo Welt, wie man die richtige Autovervollständigung schreibt. Es gibt sofort eine solche Missachtung von Antworten auf ältere falsche Anfragen.

Wenn Sie auf Redux und Redux-Saga schreiben, ist dies im Allgemeinen auch der Fall, und alles ist auch in der Dokumentation geschrieben. Aber dort ist es tief vergraben, und es wird eindeutig nicht gesagt, dass es sich um einen solchen Fehler handelt, und wir beheben ihn so. Nur eine Beschreibung ist.
Da wir zu React übergegangen sind, werden wir uns dem nähern.

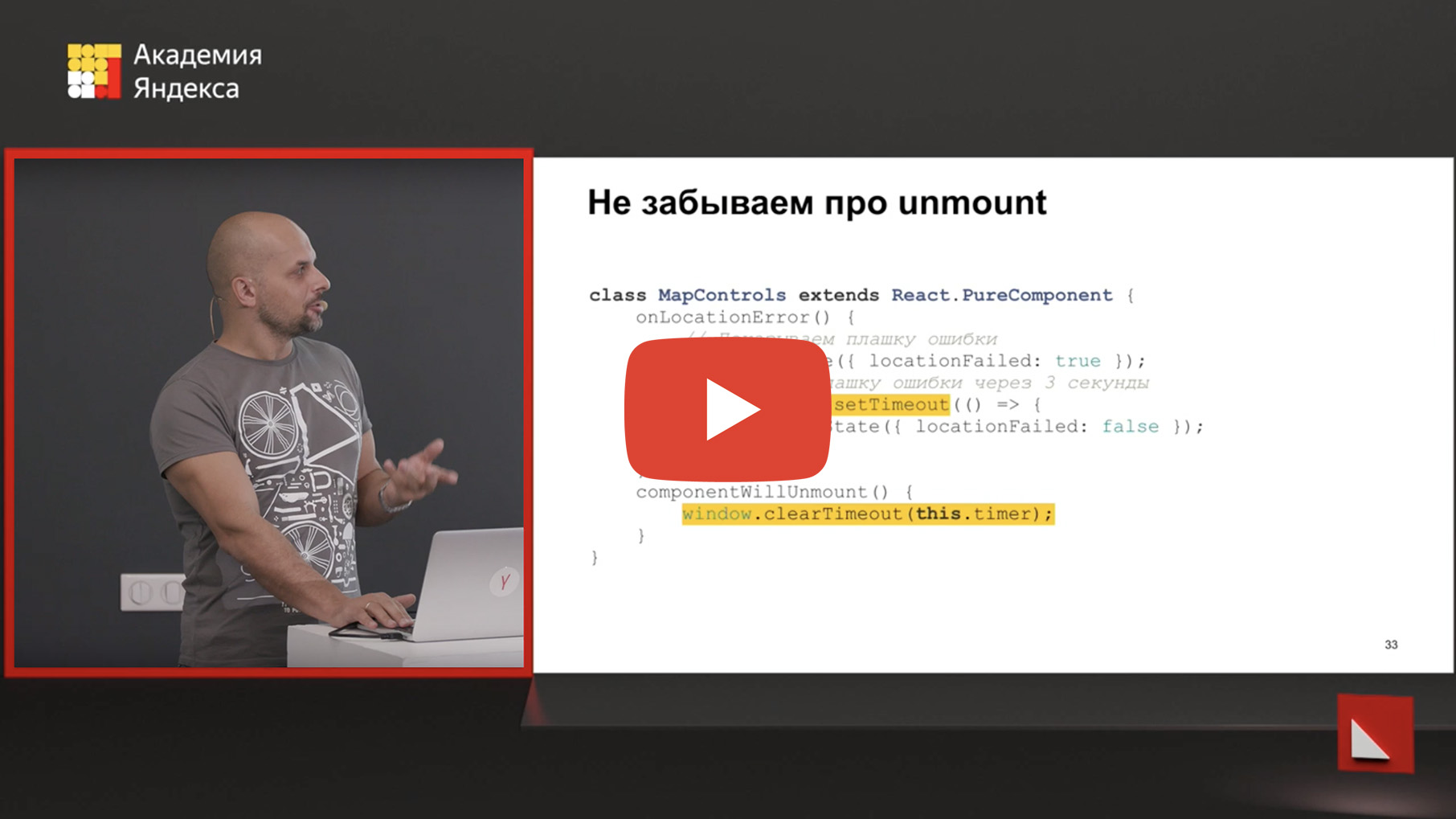
Dies ist ein Stück echten Codes, den wir in unserem Repository hatten. Jemand zieht Karten mit uns. Und bitte, wenn Sie eine Karte erhalten, ist es sehr ratsam, eine Markierung darauf zu zeigen, wo sich der Benutzer befindet. Dies geschieht jedoch alles im Browser. Wenn Sie die Geolokalisierung aktiviert haben, können wir Ihre Koordinaten abrufen und direkt angeben, wo Sie sich auf der Karte befinden.
Wenn die Geolokalisierung nicht zulässig ist oder dort ein Fehler aufgetreten ist, ist es ratsam, eine Art Würfel mit einem Fehler anzuzeigen. Das heißt, hier zeigen wir den Würfel, dass wir nicht zeigen konnten, wo Sie sind, Mann, und nach drei Sekunden entfernen wir ihn, diesen Würfel. Sie haben es wahrscheinlich geschafft zu lesen. Darüber hinaus zieht ein sich bewegendes Objekt, wie ein einziehbarer Würfel und das Verschwinden, sofort die Aufmerksamkeit auf sich, und Sie werden es sofort bemerken, lesen Sie es.
Wenn Sie sich jedoch genau ansehen, was in diesem Code passiert, ändern wir den Status unserer Komponente nach drei Sekunden. In diesen drei Sekunden kann alles passieren. Einschließlich des Benutzers kann diese Karte für eine lange Zeit geschlossen werden, und Ihre Komponente wird abmontiert, bereinigen Sie ihren Zustand.

Dementsprechend schießen Sie sich in das Bein und schießen auf einer ballistischen Flugbahn, die in drei Sekunden endet. Und was soll getan werden? Vergessen Sie nicht, dass Sie bei ausstehenden Vorgängen diese beim Aufheben der Bereitstellung korrekt bereinigen können. In anderen Frameworks mit anderen Lebenszyklusmethoden ist dies logisch. Wenn Sie eine Art Zerstörung, Zerstörung, etwas anderes oder Unmontage haben, müssen Sie richtig daran denken, solche Dinge zu reinigen.

Wo im Browser kann Ihr Code so zurückgestellt werden? Es gibt Dinge wie Gas geben und entprellen. Sie haben setTimeout, setInterval unter der Haube, etwas, über das ich bereits gezeigt habe. Es gibt immer noch requestAnimationFrame, es gibt immer noch requestIdleCallback. Und AJAX-Anforderungen auch - AJAX-Anforderungsrückrufe können als zurückgestellt bezeichnet werden. Vergessen Sie sie auch nicht, sie müssen auch gereinigt werden.
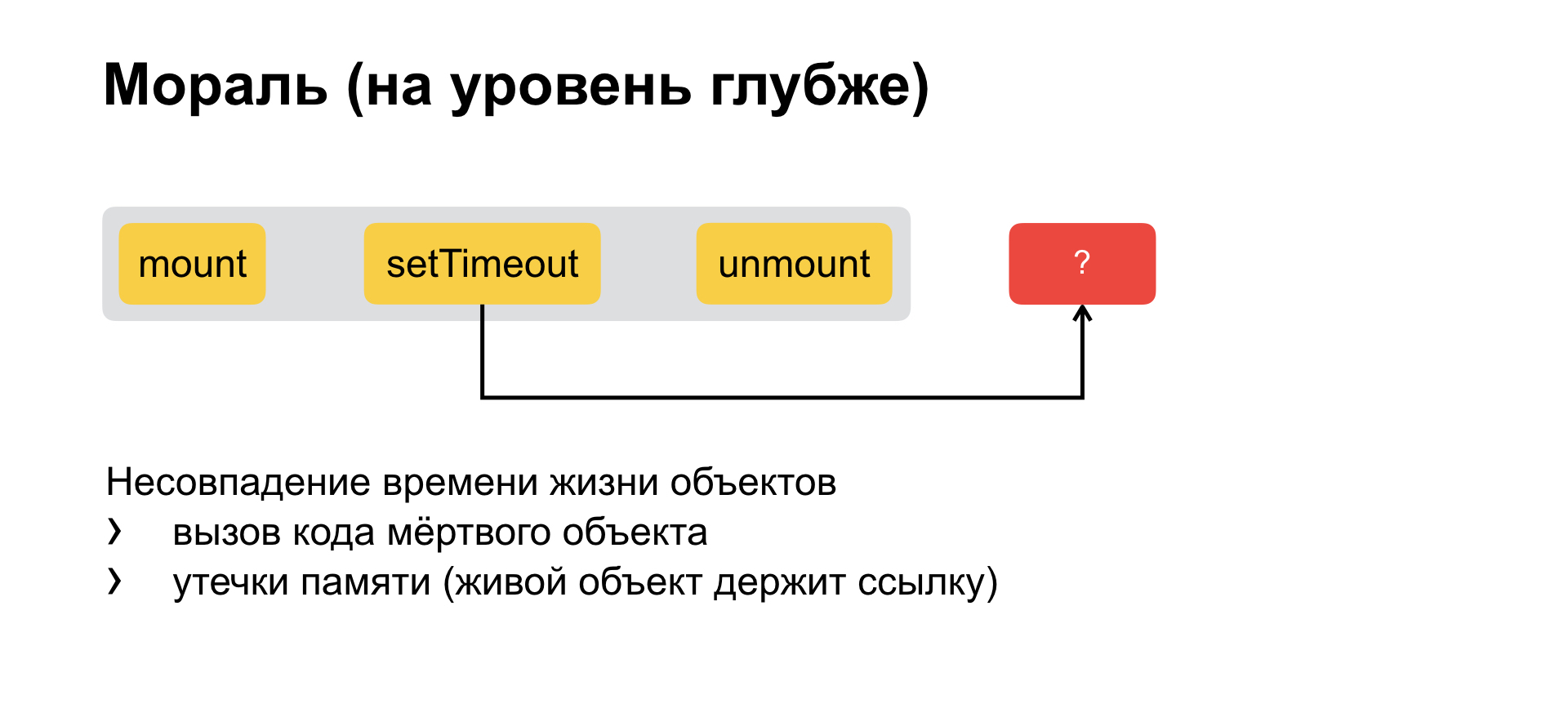
Und wenn wir noch eine Ebene weiter tauchen, werden wir verstehen, dass das gesamte Problem zunächst so abstrahiert ist, dass wir eine Komponente mit einem bestimmten Lebenszyklus haben und den Anruf abbrechen. Wir erschaffen in einem langlebigen Objekt, das eine längere Lebensdauer hat als das ursprüngliche. Das heißt, es gibt zwei Objekte mit einem nicht übereinstimmenden Lebenszyklus und einer nicht übereinstimmenden Lebensdauer. Und daraus fließen sofort zwei Käfer.
Das erste ist das, was wir jetzt haben: Ein langlebiges Objekt enthält eine Verknüpfung zu Ihrer Funktion und ruft sie auf, obwohl Sie bereits gestorben sind. Und das zweite ist der Verlust des zugehörigen Speichers. Das heißt, ein langlebiges Objekt enthält einen Link zu Ihrem Code und ermöglicht nicht, dass dieser bereinigt und aus dem Speicher gesammelt wird.
Der dritte Teil ist das Gegenteil des zweiten. Im Gegenteil, es geht um Synchronisation.

Es gibt wie immer eine Kette von Versprechen - dann, dann, dann etwas da. Und wenn Sie in diesem Code schauen, wenn Sie sauber schreiben, wenn Sie ein Unterstützer sind oder zumindest etwas über den funktionalen Ansatz, über reine Funktionen und über das Fehlen von Nebenwirkungen gehört haben, dann können Sie verstehen, dass in diesem Code etwas getan werden kann beschleunigen.
Da diese beiden Anforderungen asynchron sind, sind sie eindeutig unabhängig voneinander. Wenn Sie sich nicht sicher sind, bedeutet dies, dass Sie etwas Falsches schreiben, dh, Sie haben offensichtlich Nebenwirkungen, einen globalen Zustand und so weiter. Wenn Sie gut schreiben, wird es Ihnen sofort klar. Hier ist übrigens ein klarer Gewinn aus der Reinheit der Funktion, aus dem Fehlen von Nebenwirkungen. Denn genau hier, wenn Sie diesen Code lesen, verstehen Sie, dass sie parallelisiert werden können. Sie sind unabhängig voneinander. Und im Allgemeinen können sie höchstwahrscheinlich sogar getauscht werden.

Dies geschieht so. Wir führen zwei Abfragen parallel aus, warten, bis sie abgeschlossen sind, und führen dann den folgenden Code aus. Das heißt, Gewinn in was? Da unser Code erstens schneller ausgeführt wird, warten wir nicht darauf, dass eine Anforderung die zweite startet. Und wir werden schneller fallen. Wenn bei der zweiten Anforderung ein Fehler auftritt, verschwenden wir keine Zeit damit, auf die Ausführung der ersten Anforderung zu warten, um sofort auf die zweite zu fallen.

Was haben wir der Vollständigkeit halber noch in der Promise-API? Hier ist Promise.all (), das alle Anforderungen parallel ausführt und auf die Ausführung wartet. Es gibt Promise.race (), das darauf wartet, dass der erste von ihnen erfolgreich ist. Und im Allgemeinen enthält die Standard-API nichts anderes.

Wir verstehen bereits, dass wenn es ein Problem gibt, jemand es bereits für uns gelöst hat. Es gibt eine Async-Bibliothek mit einer ziemlich umfangreichen Auswahl für die Verwaltung asynchroner Aufgaben. Es gibt Methoden zum parallelen Ausführen asynchroner Aufgaben. Es gibt Methoden, die nacheinander ausgeführt werden. Es gibt Methoden zum Organisieren von asynchronen Iteratoren. Das heißt, Sie wissen, dass Sie beispielsweise ein Array haben, auf dem Sie forEach () ausführen können. Wenn Sie jedoch eine asynchrone Funktion in forEach () aufrufen müssen, haben Sie entweder sofort ein Problem und lehnen forEach () ab und schreiben selbst etwas oder verwenden eine vorgefertigte Bibliothek, die bereit ist, dieselben asynchronen Dinge zu verwenden. Sie verstehen, rufen Sie map () mit einer Art Iterator asynchron auf, rufen Sie forEach () auf - dort ist es bereits in der Box.

Eine weitere Alternative ist die Bluebird-Bibliothek. Es gibt, wie sie es nennen, das richtige Promise.any (). , , : N , N - , , . , , . .
Promise.race(), , promise , , , . . Promise.any() — reject. . reject , resolve , , . . promise — , .
, map, reduce, each, filter . API , Async JS, . promise . , , , promise. .
promise? , async/await.

. . . ,
«» . , webdriver. , , - , . . . webdriver.
, await. . , - . await, — , , ! .

— Promise.all(). , await.

: await , then . , .
, . : await, , — , .
, , :
, -, :
? , — Lodash, RxJS . . , . , - . . — , , . .