
Die Jahrestagung der Vereinigung für Computerlinguistik (ACL) ist die wichtigste Konferenz zur Verarbeitung natürlicher Sprache. Es ist seit 1962 organisiert. Nach Kanada und Australien kehrte sie nach Europa zurück und marschierte in Florenz. So war es in diesem Jahr bei europäischen Forschern beliebter als EMNLP ähnlich.
In diesem Jahr wurden 660 Artikel von 2900 eingereichten Artikeln veröffentlicht. Eine riesige Menge. Es ist kaum möglich, eine objektive Überprüfung der Konferenz vorzunehmen. Deshalb werde ich meine subjektiven Gefühle von diesem Ereignis erzählen.
Ich kam zur Konferenz, um in einer Postersession
unsere Entscheidung des Kaggle-Wettbewerbs über Googles
Gendered Pronoun Resolution zu zeigen . Unsere Lösung stützte sich stark auf die Verwendung von vorgefertigten
BERT-Modellen . Und wie sich herausstellte, waren wir damit nicht allein.
Bertologie

Es gab so viele Arbeiten, die auf BERT basierten, seine Eigenschaften beschrieben und als Keller nutzten, dass sogar der Begriff Bertologie auftauchte. In der Tat haben sich die BERT-Modelle als so erfolgreich erwiesen, dass selbst große Forschungsgruppen ihre Modelle mit dem BERT vergleichen.
Anfang Juni erschien die Arbeit über
XLNet . Und kurz vor der Konferenz -
ERNIE 2.0 und
RoBERTaFacebook RoBERTa
Als das XLNet-Modell erstmals vorgestellt wurde, schlugen einige Forscher vor, dass es nicht nur aufgrund seiner Architektur und seiner Trainingsprinzipien bessere Ergebnisse erzielt. Sie studierte auch an einem größeren Körper (fast 10 Mal) als BERT und länger (4 Mal mehr Iterationen).
Forscher bei Facebook haben gezeigt, dass BERT sein Maximum noch nicht erreicht hat. Sie präsentierten einen optimierten Ansatz für die Vermittlung des BERT-Modells - RoBERTa (Robust optimierter BERT-Ansatz).
Sie änderten nichts an der Architektur des Modells und änderten das Trainingsverfahren:
- Wir haben den Körper für das Training, die Größe der Charge, die Länge der Sequenz und die Zeit des Trainings erhöht.
- Die Aufgabe, den nächsten Satz vorherzusagen, wurde aus dem Training genommen.
- Sie begannen, dynamisch MASK-Token zu generieren (Token, die das Modell während des Vortrainings vorherzusagen versucht).
ERNIE 2.0 von Baidu
Wie alle gängigen neueren Modelle (BERT, GPT, XLM, RoBERTa, XLNet) basiert ERNIE auf dem Konzept eines Transformators mit Selbstaufmerksamkeitsmechanismus. Was es von anderen Modellen unterscheidet, sind die Konzepte des Multi-Task-Lernens und des kontinuierlichen Lernens.
ERNIE lernt in verschiedenen Aufgaben und aktualisiert ständig die interne Darstellung seines Sprachmodells. Diese Aufgaben haben wie andere Modelle selbstlernende (selbstüberwachte und schwach überwachte) Ziele. Beispiele für solche Aufgaben:
- Stellen Sie die richtige Wortreihenfolge in einem Satz wieder her.
- Großschreibung von Wörtern.
- Definition von maskierten Wörtern.
Bei diesen Aufgaben lernt das Modell nacheinander und kehrt zu den Aufgaben zurück, für die es zuvor trainiert wurde.
RoBERTa gegen ERNIE
In Veröffentlichungen werden RoBERTa und ERNIE nicht miteinander verglichen, da sie fast gleichzeitig auftraten. Sie werden mit BERT und XLNet verglichen. Aber hier ist es nicht so einfach, einen Vergleich anzustellen. Zum Beispiel wird
GLUE XLNet im beliebten
Benchmark durch ein Ensemble von Modellen dargestellt. Und Forscher aus Baidu sind mehr daran interessiert, einzelne Modelle zu vergleichen. Da Baidu ein chinesisches Unternehmen ist, sind sie außerdem daran interessiert, die Ergebnisse der Arbeit mit der chinesischen Sprache zu vergleichen. In jüngerer Zeit ist ein neuer Benchmark erschienen:
SuperGLUE . Es gibt noch nicht viele Lösungen, aber RoBERTa steht hier an erster Stelle.
Insgesamt schneiden RoBERTa und ERNIE jedoch besser als XLNet und deutlich besser als BERT ab. RoBERTa wiederum arbeitet etwas besser als ERNIE.
Diagramme des Wissens
Es wurde viel Arbeit darauf verwendet, zwei Ansätze zu kombinieren: vorgefertigte Netzwerke und die Verwendung von Regeln in Form von Wissensgraphen (Knowledge Graphs, KG).
Zum Beispiel:
ERNIE: Verbesserte Sprachrepräsentation mit informativen Einheiten . In diesem Artikel wird die Verwendung von Wissensdiagrammen über dem BERT-Sprachmodell hervorgehoben. Auf diese Weise können Sie bessere Ergebnisse bei Aufgaben wie der Bestimmung des Entitätstyps erzielen (
Entitätstypisierung) und Beziehungsklassifizierung .
Im Allgemeinen führt die Mode, Namen für Models anhand der Namen von Charakteren aus der Sesamstraße zu wählen, zu lustigen Konsequenzen. Zum Beispiel hat diese ERNIE nichts mit Baidus ERNIE 2.0 zu tun, über das ich oben geschrieben habe.

Eine weitere interessante Arbeit zur Generierung neuen Wissens:
COMET: Commonsense-Transformatoren für die automatische Erstellung von Wissensgraphen . Das Papier prüft die Möglichkeit, neue Architekturen auf Basis von Transformatoren für das Training wissensbasierter Netzwerke zu verwenden. Wissensbasen in vereinfachter Form sind viele Dreifache: Subjekt, Haltung, Objekt. Sie nahmen zwei Wissensdatenbank-Datensätze: ATOMIC und ConceptNet. Und sie trainierten ein Netzwerk, das auf dem GPT-Modell (Generative Pre-trained Transformer) basiert. Das Subjekt und die Haltung wurden eingegeben und versucht, das Objekt vorherzusagen. So erhielten sie ein Modell, das Objekte durch Eingabe von Subjekten und Beziehungen generiert.
Metriken
Ein weiteres interessantes Thema der Konferenz war die Auswahl von Metriken. Es ist oft schwierig, die Qualität eines Modells bei der Verarbeitung natürlicher Sprache zu bewerten, was den Fortschritt in diesem Bereich des maschinellen Lernens verlangsamt.
In einem Artikel zur
Bewertung von Zusammenfassungsbewertungsmetriken im Artikel "
Angemessener Bewertungsbereich" erläutert Maxim Peyar die Verwendung verschiedener Metriken in einem Textzusammenfassungsproblem. Diese Metriken korrelieren nicht immer gut miteinander, was den objektiven Vergleich verschiedener Algorithmen stört.
Oder hier ist ein interessanter Job:
Automatische Auswertung für Texte mit mehreren Sätzen . Darin präsentieren die Autoren eine Metrik, die BLEU und ROUGE bei Aufgaben ersetzen kann, bei denen Sie Texte aus mehreren Sätzen bewerten müssen.
Die BLEU-Metrik kann als Präzision dargestellt werden - wie viele Wörter (oder n-Gramm) aus der Antwort des Modells sind im Ziel enthalten. ROUGE ist Recall - wie viele Wörter (oder n-Gramm) vom Ziel in der Antwort des Modells enthalten sind.
Die im Artikel vorgeschlagene Metrik basiert auf der WMD-Metrik (Word Mover's Distance) - der Entfernung zwischen zwei Dokumenten. Sie entspricht dem Mindestabstand zwischen Wörtern in zwei Sätzen im Raum der Vektordarstellung dieser Wörter. Weitere Informationen zu Massenvernichtungswaffen finden Sie im Tutorial, in dem
Massenvernichtungswaffen von Word2Vec und
GloVe verwendet werden .
In ihrem Artikel bieten sie eine neue Metrik an: WMS (Word Mover's Similarity).
WMS(A, B) = exp(−WMD(A, B))
Anschließend definieren sie SMS (Satzbewegungsähnlichkeit). Es wird ein ähnlicher Ansatz wie bei WMS verwendet. Als Vektordarstellung des Satzes nehmen sie den gemittelten Vektor von Satzwörtern.
Bei der Berechnung von WMS werden Wörter anhand ihrer Häufigkeit im Dokument normalisiert. Bei der Berechnung werden SMS-Sätze durch die Anzahl der Wörter im Satz normalisiert.
Schließlich ist die S + WMS-Metrik eine Kombination aus WMS und SMS. In ihrem Artikel weisen sie darauf hin, dass ihre Metriken besser mit der manuellen Bewertung einer Person korrelieren.
Chatbots
Der nützlichste Teil der Konferenz waren meiner Meinung nach Postersessions. Nicht alle Berichte waren interessant, aber wenn Sie anfingen, einige anzuhören, werden Sie in der Mitte des Berichts nicht zu einem anderen gehen. Plakate sind eine andere Sache. Es gibt mehrere Dutzend von ihnen bei der Postersession. Sie wählen die aus, die Ihnen gefallen, und können in der Regel direkt mit dem Entwickler über technische Details sprechen. Übrigens gibt es eine interessante Seite mit
Postern von Konferenzen . Zwar gibt es dort Poster von zwei Konferenzen, und es ist nicht bekannt, ob die Website aktualisiert wird.
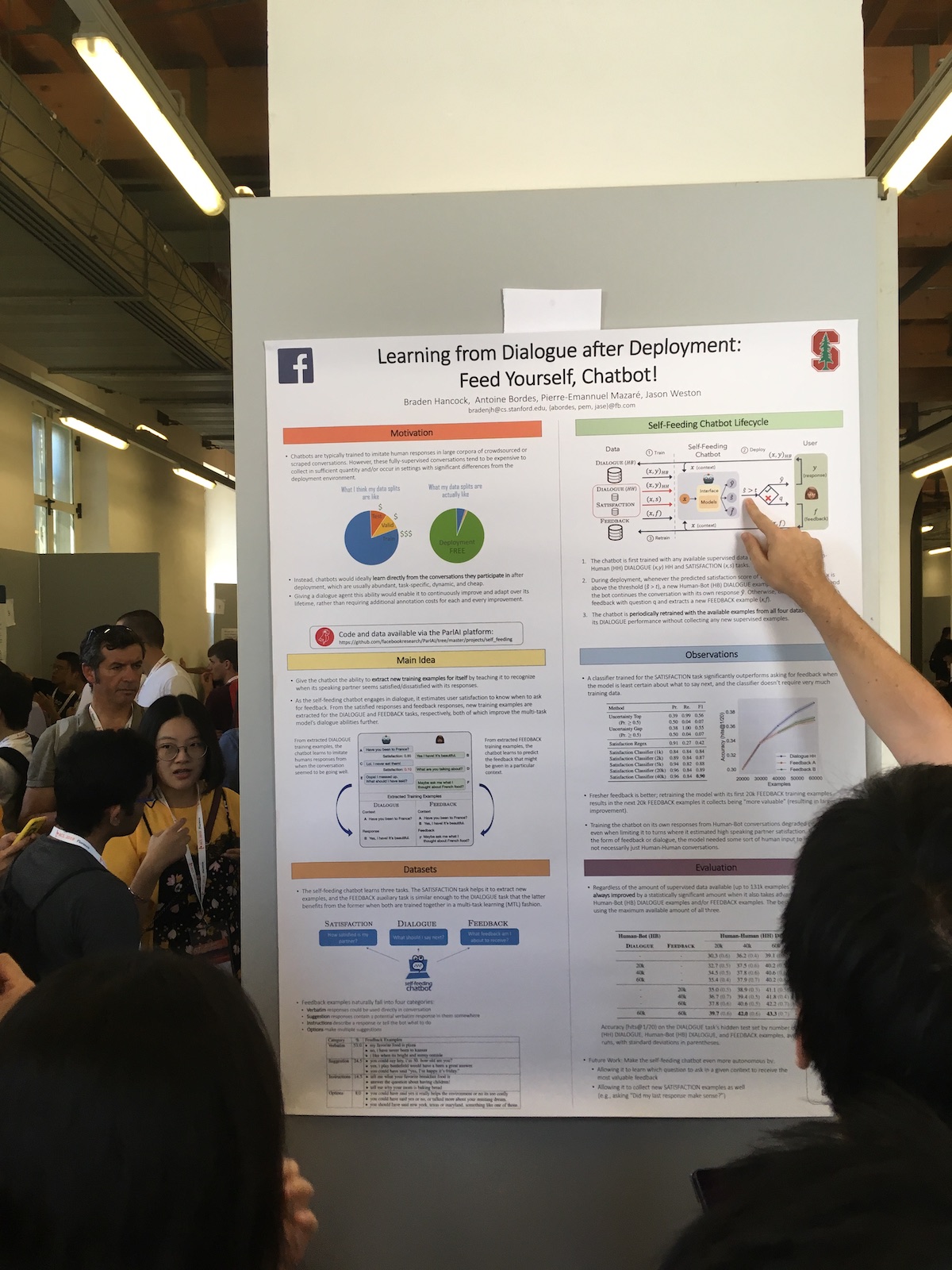
In Postersessions präsentierten große Unternehmen oft interessante Arbeiten. Hier ist zum Beispiel ein Facebook-Artikel
Lernen aus dem Dialog nach der Bereitstellung: Füttern Sie sich selbst, Chatbot! .
Die Besonderheit ihres Systems ist die erweiterte Verwendung von Benutzerantworten. Sie haben einen Klassifikator, der bewertet, wie zufrieden der Benutzer mit dem Dialog ist. Sie verwenden diese Informationen für verschiedene Aufgaben:
- Verwenden Sie ein Maß für die Zufriedenheit als Maß für die Qualität.
- Sie trainieren das Modell und wenden so den Ansatz des kontinuierlichen Lernens (Continuous Learning) an.
- Verwenden Sie direkt im Dialog. Drücken Sie eine menschliche Reaktion aus, wenn der Benutzer zufrieden ist. Oder sie fragen, was falsch ist, wenn der Benutzer nicht zufrieden ist.
Aus den Berichten ging eine interessante Geschichte über den chinesischen Chatbot von Microsoft hervor.
Das Design und die Implementierung von XiaoIce, einem einfühlsamen sozialen ChatbotChina ist bereits führend bei der Einführung künstlicher Intelligenz. Aber oft ist das, was in China passiert, in Europa nicht bekannt. Und XiaoIce ist ein erstaunliches Projekt. Es existiert bereits seit fünf Jahren. Derzeit arbeiten nicht viele Chatbots in diesem Alter. Im Jahr 2018 hatte es bereits 660 Millionen Nutzer.
Das System verfügt sowohl über einen Chit-Chat-Bot als auch über ein Skill-System. Der Bot hat bereits 230 Fertigkeiten, das heißt, sie fügen ungefähr eine Fertigkeit pro Woche hinzu.
Um die Qualität des Chit-Chat-Bots zu beurteilen, verwenden sie die Dauer des Dialogs. Und nicht in Minuten, wie es oft gemacht wird, sondern in der Anzahl der Replikate in einem Gespräch. Sie nennen diese Metrik Conversation-Turns Per Session (CPS) und schreiben, dass ihr Durchschnittswert derzeit 23 beträgt, was der beste Indikator unter ähnlichen Systemen ist.
Im Allgemeinen ist das Projekt in China sehr beliebt. Neben dem Bot selbst schreibt das System Gedichte, zeichnet Bilder,
veröffentlicht eine Sammlung von Kleidern und singt Lieder.
Maschinelle Übersetzung
Von allen Reden, an denen ich teilnahm, war der
Simultanübersetzungsbericht von Liang Huang, der Baidu Research vertrat, der lebhafteste.
Er sprach über solche Schwierigkeiten bei der modernen Simultanübersetzung:
- Es gibt weltweit nur 3.000 zertifizierte Simultandolmetscher.
- Übersetzer können nur 15 bis 20 Minuten ununterbrochen arbeiten.
- Nur etwa 60% des Quelltextes werden übersetzt.
Die Übersetzung ganzer Sätze hat bereits ein gutes Niveau erreicht, aber für die Simultanübersetzung gibt es noch Verbesserungspotenzial. Als Beispiel führte er ihr Simultanübersetzungssystem an, das auf der Baidu-Weltkonferenz funktionierte. Die Verzögerung bei der Übersetzung im Jahr 2018 gegenüber 2017 wurde von 10 auf 3 Sekunden reduziert.
Dies tun nicht viele Teams, und es gibt nur wenige funktionierende Systeme. Wenn Google beispielsweise die online geschriebene Phrase übersetzt, wird die endgültige Phrase ständig neu erstellt. Und dies ist keine Simultanübersetzung, da wir bei Simultanübersetzung die bereits gesprochenen Wörter nicht ändern können.

In ihrem System verwenden sie die Präfixübersetzung - Teil einer Phrase. Das heißt, sie warten ein paar Worte und beginnen zu übersetzen, um zu erraten, was in der Quelle erscheinen wird. Die Größe dieser Verschiebung wird in Worten gemessen und ist adaptiv. Nach jedem Schritt entscheidet das System, ob sich das Warten lohnt oder ob es bereits übersetzt werden kann. Um diese Verzögerung zu bewerten, führen sie die folgende Metrik ein:
Metrik der durchschnittlichen Verzögerung
(AL) .
Die Hauptschwierigkeit bei der Simultanübersetzung ist die unterschiedliche Wortreihenfolge in Sprachen. Und der Kontext hilft, dies zu bekämpfen. Zum Beispiel müssen Sie häufig die Reden von Politikern übersetzen, und sie sind ziemlich stereotyp. Es gibt aber auch Probleme. Dann scherzte der Sprecher über Trump. Also, sagt er, wenn Bush nach Moskau geflogen ist, dann ist es sehr wahrscheinlich, dass er sich mit Putin trifft. Und wenn Trump geflogen ist, kann er sich treffen und Golf spielen. Im Allgemeinen kommen die Leute beim Übersetzen oft auf die Idee, etwas von sich selbst hinzuzufügen. Nehmen wir an, wenn Sie eine Art Witz übersetzen müssen und sie es nicht sofort tun können, können sie sagen: "Hier wurde ein Witz gesagt, lachen Sie einfach."
Es gab auch einen Artikel über maschinelle Übersetzung, der mit dem Preis „The Best Long Paper“ ausgezeichnet wurde:
Überbrückung der Lücke zwischen Training und Inferenz für neuronale maschinelle Übersetzung .
Es beschreibt ein solches Problem der maschinellen Übersetzung. Während des Lernprozesses generieren wir eine Wort-für-Wort-Übersetzung basierend auf dem Kontext bekannter Wörter. Bei der Verwendung des Modells stützen wir uns auf den Kontext der neu generierten Wörter. Es besteht eine Diskrepanz zwischen dem Training des Modells und seiner Verwendung.
Um diese Diskrepanz zu verringern, schlagen die Autoren vor, in der Phase des Trainings im Kontext die Wörter zu mischen, die vom Modell während des Trainings vorhergesagt werden. Der Artikel beschreibt die optimale Auswahl solcher generierten Wörter.
Fazit
Natürlich besteht eine Konferenz nicht nur aus Artikeln und Berichten. Es ist auch Kommunikation, Dating und andere Vernetzung. Darüber hinaus versuchen Konferenzorganisatoren, die Teilnehmer irgendwie zu unterhalten. In der ACL, auf der Hauptparty, gab es eine Aufführung von Tenören, schließlich Italien. Zusammenfassend gab es Ankündigungen der Organisatoren anderer Konferenzen. Die heftigste Reaktion unter den Teilnehmern wurde durch die Nachrichten der Organisatoren von EMNLP ausgelöst, dass die Hauptpartei in diesem Jahr in Hongkong Disneyland stattfinden wird und die Konferenz 2020 in der Dominikanischen Republik stattfinden wird.