Stellen Sie sich vor. 5 Katzen sind im Raum eingesperrt, und um den Besitzer aufzuwecken, müssen sich alle einig sein, da sie die Tür nur öffnen können, indem sie sich auf fünf von ihnen stützen. Wenn eine der Katzen eine Schrödinger-Katze ist und die anderen Katzen nichts über ihre Lösung wissen, stellt sich die Frage: "Wie können sie das tun?"
In diesem Artikel werde ich Ihnen in einer einfachen Sprache die theoretische Komponente der Welt der verteilten Systeme und die Prinzipien ihrer Funktionsweise erläutern. Und auch oberflächlich die Hauptidee betrachten, die Paxos'a zugrunde liegt.
Wenn Entwickler Cloud-Infrastrukturen verwenden, arbeiten verschiedene Datenbanken in Clustern von einer großen Anzahl von Knoten aus, sind sie sicher, dass die Daten vollständig, sicher und immer zugänglich sind. Aber wo sind die Garantien?
In der Tat sind die Garantien, die wir haben, die Garantien des Lieferanten. Sie werden in der Dokumentation ungefähr folgendermaßen beschrieben: "Dieser Dienst ist ziemlich zuverlässig, er hat eine vordefinierte SLA, keine Sorge, alles wird wie erwartet auf verteilte Weise funktionieren."
Wir neigen dazu, an das Beste zu glauben, weil kluge Onkel großer Unternehmen uns versichert haben, dass alles gut wird. Wir fragen uns nicht: Warum kann es überhaupt funktionieren? Gibt es eine formale Rechtfertigung für den ordnungsgemäßen Betrieb solcher Systeme?
Ich habe kürzlich eine
Schule für verteilte Computer besucht und war von diesem Thema sehr inspiriert. Die Vorlesungen an der Schule ähnelten eher Klassen in mathematischer Analyse als etwas, das mit Computersystemen zu tun hatte. Aber genau so wurden die wichtigsten Algorithmen, die wir jeden Tag verwenden, ohne es zu wissen, auf einmal bewiesen.
Die meisten modernen verteilten Systeme verwenden den Paxos-Konsensalgorithmus und seine verschiedenen Modifikationen. Das Coolste ist, dass die Gültigkeit und im Prinzip die Möglichkeit der Existenz dieses Algorithmus einfach mit Stift und Papier bewiesen werden kann. In der Praxis wird der Algorithmus jedoch in großen Systemen verwendet, die auf einer großen Anzahl von Knoten in den Clouds arbeiten.
Leichte Illustration dessen, was weiter diskutiert wird: die Aufgabe zweier GeneräleWerfen wir einen Blick
auf die Aufgabe der beiden Generäle , sich aufzuwärmen.
Wir haben zwei Armeen - rot und weiß. Weiße Truppen sind in der belagerten Stadt stationiert. Rote Truppen, angeführt von den Generälen A1 und A2, befinden sich auf zwei Seiten der Stadt. Die Aufgabe der Rothaarigen ist es, die weiße Stadt anzugreifen und zu gewinnen. Die Armee jedes rothaarigen Generals ist jedoch kleiner als die Truppen der Weißen.
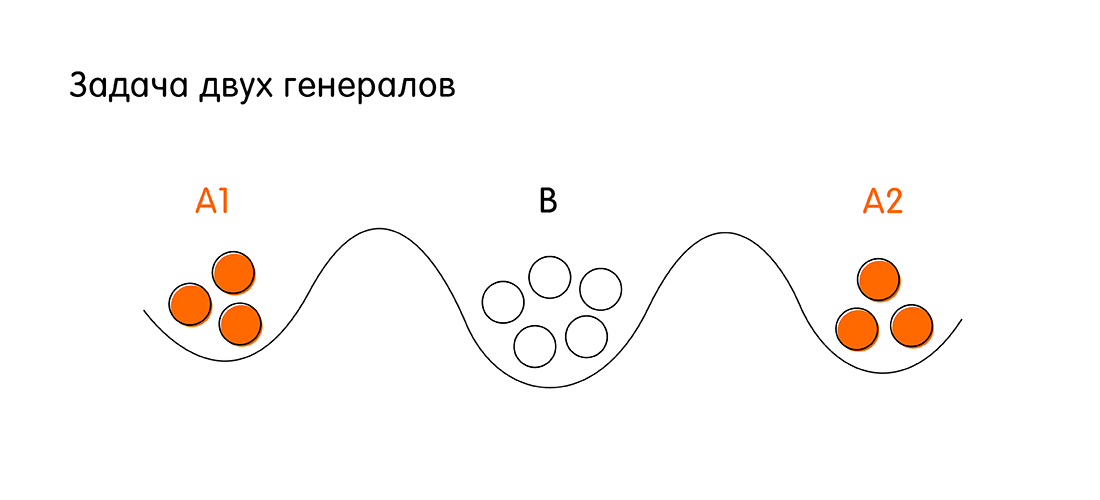
Siegbedingungen für Rothaarige: Beide Generäle müssen gleichzeitig angreifen, um einen numerischen Vorteil gegenüber Weißen zu erzielen. Dazu müssen sich die Generäle A1 und A2 einig sein. Wenn jeder einzeln angreift, verlieren die Rothaarigen.
Um zuzustimmen, können die Generäle A1 und A2 sich gegenseitig Boten durch das Gebiet der weißen Stadt schicken. Ein Bote kann erfolgreich zu einem verbündeten General gelangen oder von einem Gegner abgefangen werden. Frage: Gibt es eine solche Kommunikationssequenz zwischen den roten Generälen (die Sequenz des Sendens von Boten von A1 nach A2 und umgekehrt von A2 nach A1), in der sie sich garantiert auf einen Angriff zur Stunde X einigen. Hier wird unter den Garantien verstanden, dass beide Generäle eine eindeutige Bestätigung haben werden dass ein Verbündeter (ein anderer General) zum festgelegten Zeitpunkt X genau angreift.
Angenommen, A1 sendet einen Boten an A2 mit der Nachricht: "Lass uns heute um Mitternacht angreifen!" General A1 kann nicht ohne Bestätigung von General A2 angreifen. Wenn der Messenger A1 erreicht hat, sendet General A2 eine Bestätigung mit der Nachricht: "Ja, lassen Sie uns heute die Weißen füllen." Aber jetzt weiß General A2 nicht, ob sein Bote angekommen ist oder nicht, er hat keine Garantie, ob der Angriff gleichzeitig stattfinden wird. Jetzt muss General A2 erneut bestätigt werden.
Wenn wir ihre Kommunikation weiter planen, stellt sich Folgendes heraus: Unabhängig von der Anzahl der Nachrichtenzyklen kann nicht garantiert werden, dass beide Generäle über den Empfang ihrer Nachrichten informiert werden (vorausgesetzt, jeder der Messenger kann abgefangen werden).
Die Aufgabe von zwei Generälen ist ein hervorragendes Beispiel für ein sehr einfaches verteiltes System, bei dem es zwei Knoten mit unzuverlässiger Kommunikation gibt. Wir haben also keine 100% ige Garantie dafür, dass sie synchronisiert sind. Über ähnliche Probleme erst später in größerem Umfang im Artikel.
Wir führen das Konzept verteilter Systeme ein
Ein verteiltes System ist eine Gruppe von Computern (im Folgenden als Knoten bezeichnet), die Nachrichten austauschen können. Jeder einzelne Knoten ist eine autonome Einheit. Ein Knoten kann Aufgaben unabhängig verarbeiten. Um jedoch mit anderen Knoten interagieren zu können, muss er Nachrichten senden und empfangen.
Wie spezifisch Nachrichten implementiert werden, welche Protokolle verwendet werden - das interessiert uns in diesem Zusammenhang nicht. Es ist wichtig, dass die Knoten eines verteilten Systems durch Senden von Nachrichten Daten miteinander austauschen können.
Die Definition selbst sieht nicht sehr kompliziert aus, aber Sie müssen berücksichtigen, dass ein verteiltes System eine Reihe von Attributen aufweist, die für uns wichtig sind.
Verteilte Systemattribute
- Parallelität - die Möglichkeit gleichzeitiger oder konkurrierender Ereignisse im System. Darüber hinaus werden wir berücksichtigen, dass die Ereignisse, die auf zwei verschiedenen Knoten aufgetreten sind, potenziell wettbewerbsfähig sind, solange wir keine klare Reihenfolge für das Auftreten dieser Ereignisse haben. Und in der Regel haben wir es nicht.
- Das Fehlen einer globalen Uhr . Wir haben keine klare Reihenfolge der Ereignisse, da es keine globale Uhr gibt. In der gewöhnlichen Welt der Menschen sind wir daran gewöhnt, dass wir absolut Stunden und Zeit haben. Bei verteilten Systemen ändert sich alles. Selbst ultrapräzise Atomuhren haben eine Drift, und es kann Situationen geben, in denen wir nicht sagen können, welches der beiden Ereignisse früher passiert ist. Deshalb können wir uns auch nicht auf die Zeit verlassen.
- Unabhängiger Ausfall von Systemknoten . Es gibt noch ein anderes Problem: Etwas ist möglicherweise nicht so einfach, weil unsere Knoten nicht ewig sind. Die Festplatte fällt möglicherweise aus, die virtuelle Maschine in der Cloud wird neu gestartet, das Netzwerk blinkt möglicherweise und Nachrichten gehen verloren. Darüber hinaus sind Situationen möglich, in denen die Knoten arbeiten, aber gleichzeitig gegen das System arbeiten. Die letztere Klasse von Problemen erhielt sogar einen eigenen Namen: das Problem der byzantinischen Generäle . Das beliebteste Beispiel für ein verteiltes System mit einem solchen Problem ist Blockchain. Aber heute werden wir diese spezielle Klasse von Problemen nicht berücksichtigen. Wir werden an Situationen interessiert sein, in denen nur ein oder mehrere Knoten ausfallen können.
- Kommunikationsmodelle (Messaging-Modelle) zwischen Knoten . Wir haben bereits herausgefunden, dass Knoten über Messaging kommunizieren. Es gibt zwei bekannte Messaging-Modelle: synchron und asynchron.
Kommunikationsmodelle zwischen Knoten in verteilten Systemen
Synchrones Modell - Wir wissen mit Sicherheit, dass es ein endliches bekanntes Zeitdelta gibt, für das eine Nachricht garantiert von einem Knoten zum anderen gelangt. Wenn diese Zeit vergangen ist, die Nachricht jedoch nicht eingetroffen ist, können wir mit Sicherheit sagen, dass der Knoten ausgefallen ist. In einem solchen Modell haben wir eine vorhersehbare Wartezeit.
Asynchrones Modell - In asynchronen Modellen glauben wir, dass die Wartezeit endlich ist, aber es gibt keine solche Deltazeit, nach der garantiert werden kann, dass der Knoten nicht in Ordnung ist. Das heißt, Die Wartezeit für eine Nachricht vom Knoten kann beliebig lang sein. Dies ist eine wichtige Definition, über die wir weiter sprechen werden.
Das Konzept des Konsenses in verteilten Systemen
Bevor wir das Konzept des Konsenses formell definieren, betrachten wir ein Beispiel für die Situation, in der wir es benötigen, nämlich die
Replikation von Zustandsmaschinen .
Wir haben ein verteiltes Protokoll. Wir möchten, dass es konsistent ist und identische Daten auf allen Knoten eines verteilten Systems enthält. Wenn einer der Knoten einen neuen Wert findet, den er in das Protokoll schreiben wird, besteht seine Aufgabe darin, diesen Wert allen anderen Knoten anzubieten, damit das Protokoll auf allen Knoten aktualisiert wird und das System in einen neuen konsistenten Zustand wechselt. Es ist wichtig, dass die Knoten untereinander übereinstimmen: Alle Knoten stimmen darin überein, dass der vorgeschlagene neue Wert korrekt ist, alle Knoten akzeptieren diesen Wert, und nur in diesem Fall kann jeder einen neuen Wert in das Protokoll schreiben.
Mit anderen Worten: Keiner der Knoten hat Einwände gegen relevantere Informationen erhoben, und der vorgeschlagene Wert ist falsch. Die Übereinstimmung zwischen den Knoten und die Vereinbarung über einen einzelnen korrekten akzeptierten Wert ist Konsens in einem verteilten System. Weiter werden wir über Algorithmen sprechen, die es einem verteilten System ermöglichen, einen Konsens mit Garantie zu erzielen.

Formal können wir einen Konsensalgorithmus (oder nur einen Konsensalgorithmus) als eine Funktion definieren, die ein verteiltes System von Zustand A in Zustand B überträgt. Darüber hinaus wird dieser Zustand von allen Knoten akzeptiert und alle Knoten können ihn bestätigen. Wie sich herausstellt, ist diese Aufgabe keineswegs so trivial, wie es auf den ersten Blick scheint.
Eigenschaften des Konsensalgorithmus
Der Konsensalgorithmus muss drei Eigenschaften haben, damit das System weiterhin existiert und beim Übergang von Zustand zu Zustand Fortschritte erzielt werden:
- Übereinstimmung - Alle korrekt funktionierenden Knoten müssen denselben Wert annehmen (in Artikeln wird diese Eigenschaft auch als Sicherheitseigenschaft gefunden). Alle Knoten, die jetzt funktionieren (nicht außer Betrieb und haben den Kontakt zum Rest nicht verloren), sollten eine Einigung erzielen und eine endgültige allgemeine Bedeutung annehmen.
Es ist wichtig zu verstehen, dass die Knoten in dem verteilten System, die wir in Betracht ziehen, zustimmen möchten. Das heißt, wir sprechen jetzt über Systeme, die möglicherweise ausfallen (z. B. um einen Knoten auszufallen), aber dieses System hat definitiv keine Knoten, die absichtlich gegen andere arbeiten (die Aufgabe der byzantinischen Generäle). Aufgrund dieser Eigenschaft bleibt das System konsistent. - Integrität - Wenn alle korrekt funktionierenden Knoten den gleichen Wert von v bieten, muss jeder korrekt funktionierende Knoten diesen Wert von v akzeptieren.
- Beendigung - Alle korrekt funktionierenden Knoten nehmen irgendwann einen Wert an (Liveness-Eigenschaft), wodurch der Algorithmus Fortschritte im System erzielen kann. Jeder einzelne Knoten, der korrekt funktioniert, muss früher oder später den endgültigen Wert akzeptieren und dies bestätigen: "Für mich ist dieser Wert wahr, ich stimme dem gesamten System zu."
Beispiel für einen Konsensalgorithmus
Bisher sind die Eigenschaften des Algorithmus möglicherweise nicht ganz klar. Daher veranschaulichen wir anhand eines Beispiels, welche Phasen der einfachste Konsensalgorithmus in einem System mit einem synchronen Messaging-Modell durchläuft, in dem alle Knoten wie erwartet funktionieren, Nachrichten nicht verloren gehen und nichts kaputt geht (passiert das wirklich?).
- Alles beginnt mit einem Heiratsantrag (Propose). Angenommen, ein Client hat eine Verbindung zu einem Knoten namens "Knoten 1" hergestellt und eine Transaktion gestartet, wobei ein neuer Wert an den Knoten O übergeben wurde. Von nun an werden wir "Knoten 1" als Antragsteller bezeichnen . Als Antragsteller sollte "Knoten 1" nun das gesamte System über neue Daten informieren und Nachrichten an alle anderen Knoten senden: "Look! Ich habe den Wert "O" und möchte ihn aufschreiben! Bitte bestätigen Sie, dass Sie auch "O" in Ihr Protokoll schreiben. "
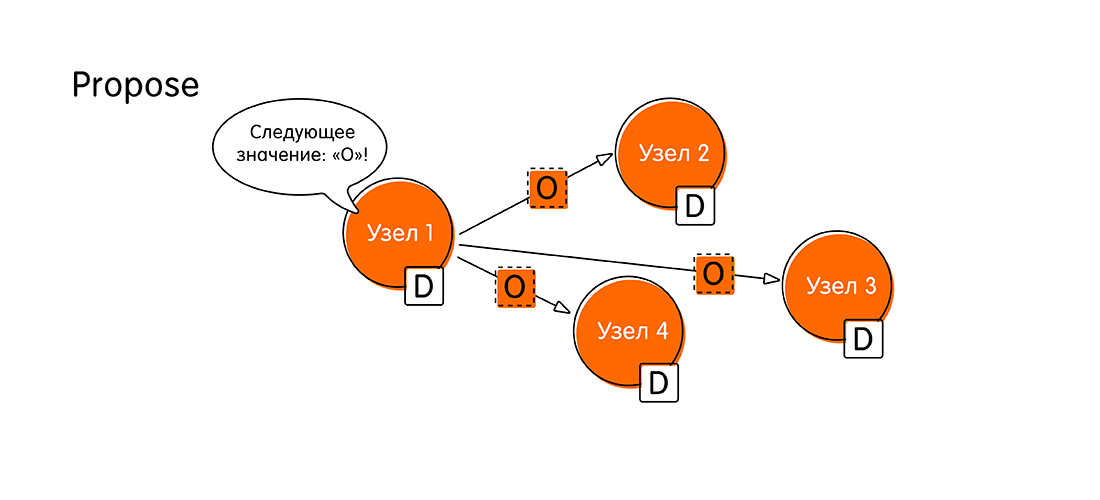
- In der nächsten Phase wird über den vorgeschlagenen Wert abgestimmt (Abstimmung). Wofür ist es? Es kann vorkommen, dass andere Knoten neuere Informationen erhalten haben und Daten zu derselben Transaktion haben.
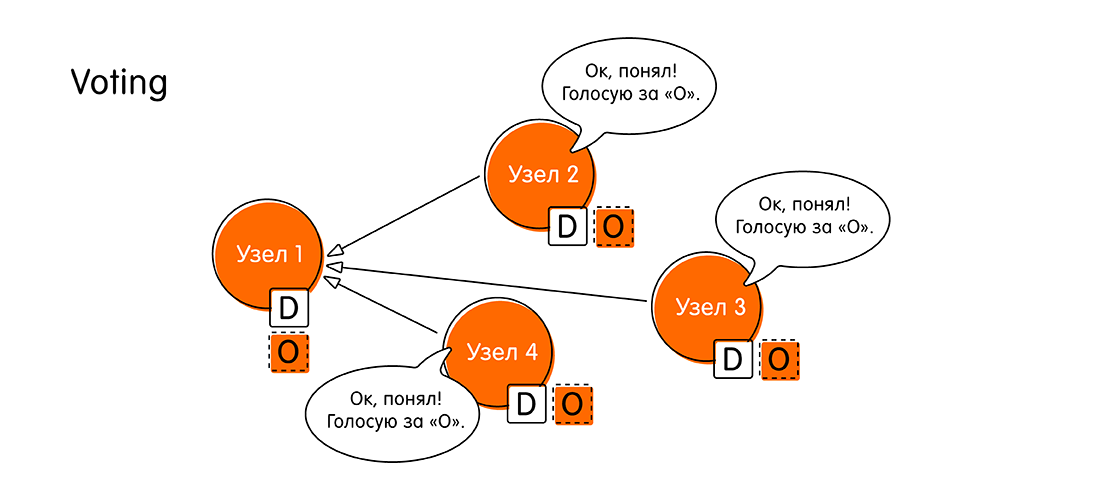
Wenn der Knoten „Knoten 1“ eine eigene Nachricht sendet, überprüfen die verbleibenden Knoten die Daten für dieses Ereignis in ihren Protokollen. Wenn es keine Widersprüche gibt, melden die Knoten: „Ja, ich habe keine weiteren Daten zu diesem Ereignis. Der Wert "O" ist die neueste Information, die wir verdienen. "
In jedem anderen Fall können die Knoten mit „Knoten 1“ antworten: „Hören! Ich habe neuere Daten zu dieser Transaktion. Nicht "Oh", sondern etwas Besseres. "
In der Phase der Abstimmung treffen die Knoten eine Entscheidung: Entweder nimmt jeder den gleichen Wert an oder einer von ihnen stimmt dagegen, was darauf hinweist, dass er über neuere Daten verfügt. - Wenn die Abstimmungsrunde erfolgreich war und alle dafür waren, bewegt sich das System in eine neue Phase - die Akzeptanz des Wertes (Akzeptieren). "Knoten 1" sammelt alle Antworten anderer Knoten und meldet: "Alle stimmten dem Wert" O "zu! Jetzt erkläre ich offiziell, dass "O" unsere neue Bedeutung ist, die für alle gleich ist! Schreiben Sie sich in eine Broschüre, vergessen Sie nicht. Schreiben Sie in Ihr Protokoll! "
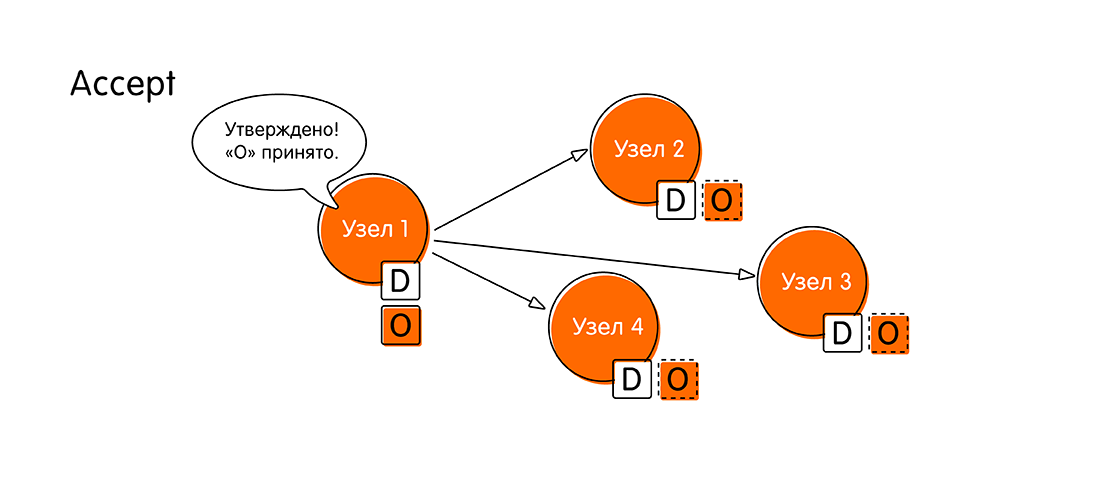
- Die verbleibenden Knoten senden eine Bestätigung (Akzeptiert), dass sie den Wert "O" notiert haben und in dieser Zeit nichts Neues tun konnten (eine Art zweiphasiges Festschreiben). Nach diesem bedeutsamen Ereignis glauben wir, dass die verteilte Transaktion abgeschlossen ist.
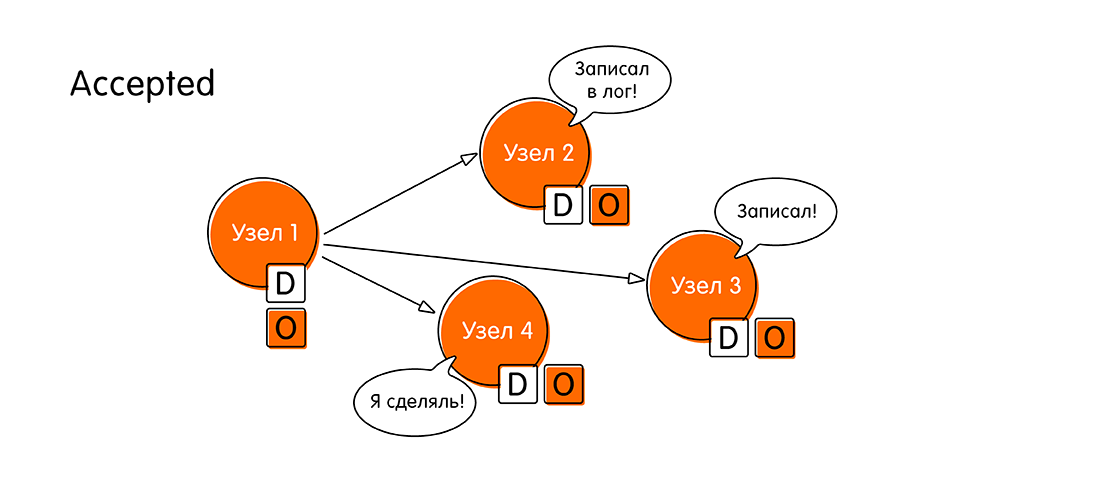
Somit besteht der Konsensalgorithmus im einfachen Fall aus vier Schritten: Vorschlagen, Abstimmen, Akzeptieren, Bestätigen der Akzeptanz.
Wenn wir irgendwann keine Einigung erzielen konnten, wird der Algorithmus neu gestartet, wobei die Informationen der Knoten berücksichtigt werden, die sich geweigert haben, den vorgeschlagenen Wert zu bestätigen.
Konsensalgorithmus in einem asynchronen System
Vorher war alles reibungslos, da es sich um ein synchrones Messaging-Modell handelte. Aber wir wissen, dass wir in der modernen Welt daran gewöhnt sind, alles asynchron zu machen. Wie funktioniert ein ähnlicher Algorithmus in einem System mit einem asynchronen Messaging-Modell, in dem wir glauben, dass die Wartezeit auf eine Antwort von einem Knoten beliebig lang sein kann (der Ausfall eines Knotens kann übrigens auch als Beispiel angesehen werden, wenn ein Knoten beliebig lange antworten kann). )
Nachdem wir nun wissen, wie der Konsensalgorithmus im Grunde funktioniert, stellt sich die Frage für diejenigen neugierigen Leser, die diesen Punkt erreicht haben: Wie viele Knoten in einem System von N Knoten mit einem asynchronen Nachrichtenmodell können ausfallen, damit das System immer noch einen Konsens erreichen kann?
Die richtige Antwort und Begründung hinter dem Spoiler.Die richtige Antwort ist
0 . Wenn mindestens ein Knoten im asynchronen System ausfällt, kann das System keinen Konsens erzielen. Diese Behauptung wird in dem in bestimmten Kreisen bekannten FLP-Theorem bewiesen (1985, Fischer, Lynch, Paterson, Link zum Original am Ende des Artikels): „Die Unfähigkeit, einen verteilten Konsens zu erzielen, wenn mindestens ein Knoten ausfällt“.
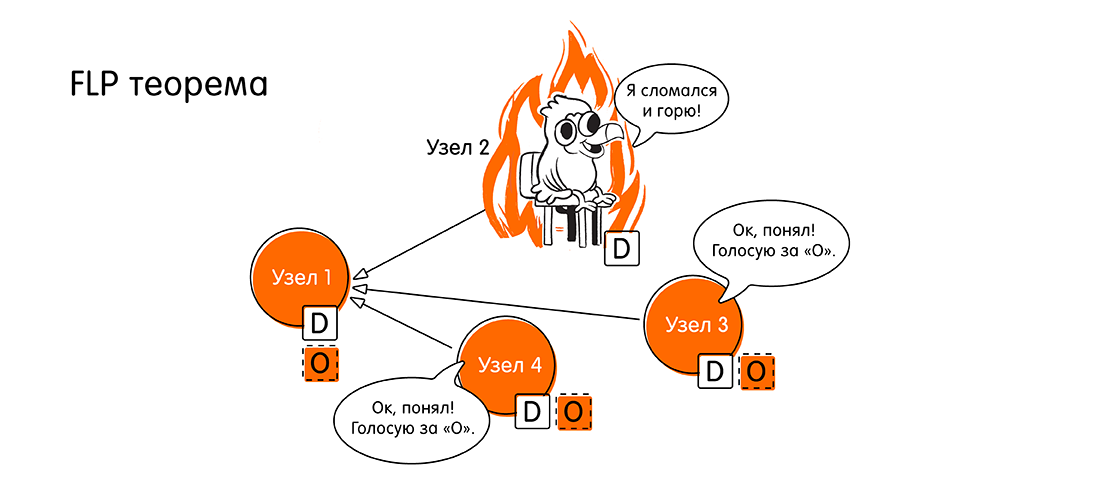
Leute, dann haben wir ein Problem, wir sind daran gewöhnt, dass alles mit uns asynchron ist. Und hier ist es. Wie kann man weiter leben?
Wir sprechen jetzt über Theorie, über Mathematik. Was bedeutet es, dass "kein Konsens erzielt werden kann", wenn man von einer mathematischen Sprache in unsere übersetzt - Ingenieurwesen? Dies bedeutet, dass "nicht immer erreicht werden kann", d.h. Es gibt einen Fall, in dem kein Konsens erzielt werden kann. Und was ist das?
Dies ist nur eine Verletzung der oben beschriebenen Lebendigkeitseigenschaft. Wir haben keine allgemeine Vereinbarung, und das System kann nicht fortschreiten (kann nicht in einer begrenzten Zeit abgeschlossen werden), wenn wir nicht von allen Knoten eine Antwort haben. Da wir in einem asynchronen System keine vorhersehbare Antwortzeit haben und nicht wissen können, ob der Knoten ausgefallen ist oder nur eine lange Antwortzeit benötigt.
In der Praxis können wir jedoch eine Lösung finden. Lassen Sie unseren Algorithmus bei Fehlern lange arbeiten (er kann möglicherweise endlos funktionieren). In den meisten Situationen, in denen die meisten Knoten ordnungsgemäß funktionieren, haben wir Fortschritte im System.
In der Praxis handelt es sich um teilweise synchrone Kommunikationsmodelle. Partielle Synchronität wird wie folgt verstanden: Im allgemeinen Fall haben wir ein asynchrones Modell, aber formal führen wir ein bestimmtes Konzept der „globalen Stabilisierungszeit“ eines bestimmten Zeitpunkts ein.
Dieser Zeitpunkt kann nicht so lange kommen, wie Sie möchten, aber eines Tages muss er kommen. Ein virtueller Alarm ertönt und von nun an können wir das Zeitdelta vorhersagen, für das Nachrichten erreicht werden. Ab diesem Moment wechselt das System von asynchron zu synchron. In der Praxis haben wir es mit genau solchen Systemen zu tun.
Der Paxos-Algorithmus löst Konsensprobleme
Paxos ist eine Familie von Algorithmen, die das Konsensproblem für teilweise synchrone Systeme lösen, vorausgesetzt, einige Knoten können ausfallen. Der Autor von Paxos ist
Leslie Lamport . Er schlug 1989 einen formalen Beweis für die Existenz und Richtigkeit des Algorithmus vor.
Aber der Beweis war keineswegs trivial. Die erste Veröffentlichung wurde erst 1998 (33 Seiten) mit einer Beschreibung des Algorithmus veröffentlicht. Wie sich herausstellte, war es äußerst schwer zu verstehen, und 2001 wurde eine Erklärung für den Artikel veröffentlicht, der 14 Seiten umfasste. Die Bände der Veröffentlichungen sollen zeigen, dass das Problem des Konsenses in der Tat überhaupt nicht einfach ist und solche Algorithmen der enormen Arbeit der klügsten Leute unterliegen.
Es ist interessant, dass Leslie Lamport selbst in seinem Vortrag feststellte, dass es in der zweiten Artikelerklärung eine Aussage gibt, eine Zeile (nicht angegeben, welche), die unterschiedlich interpretiert werden kann. Aus diesem Grund funktionieren viele moderne Paxos-Implementierungen nicht richtig.
Eine detaillierte Analyse der Arbeit von Paxos wird mehr als einen Artikel enthalten, daher werde ich versuchen, die Hauptidee des Algorithmus sehr kurz zu vermitteln. In den Links am Ende meines Artikels finden Sie Materialien zum weiteren Eintauchen in dieses Thema.
Rollen in Paxos
Paxos hat ein Rollenkonzept. Betrachten wir drei Hauptmerkmale (es gibt Änderungen mit zusätzlichen Rollen):
- Antragsteller (Begriffe können auch verwendet werden: Leiter oder Koordinatoren) . Dies sind die Leute, die vom Benutzer etwas über neue Bedeutungen lernen und die Rolle des Leiters übernehmen. Ihre Aufgabe ist es, eine Runde von Vorschlägen von neuer Bedeutung zu starten und weitere Aktionen der Knoten zu koordinieren. Darüber hinaus ermöglicht Paxos die Anwesenheit mehrerer Führungskräfte in bestimmten Situationen.
- Akzeptoren (Wähler) . Dies sind die Knoten, die für die Annahme oder Ablehnung eines bestimmten Werts stimmen. Ihre Rolle ist sehr wichtig, da die Entscheidung von ihnen abhängt: In welchem Zustand wird das System nach der nächsten Stufe des Konsensalgorithmus gehen (oder nicht).
- Lernende . Knoten, die den neuen akzeptierten Wert einfach akzeptieren und aufzeichnen, wenn sich der Status des Systems geändert hat. Sie treffen keine Entscheidungen, sie empfangen einfach Daten und können diese dem Endbenutzer geben.
Ein Knoten kann mehrere Rollen in verschiedenen Situationen kombinieren.
Quorum-Konzept
Wir nehmen an, dass wir ein System von
N Knoten haben. Und von ihnen können maximal
F Knoten ausfallen. Wenn F-Knoten ausfallen, müssen mindestens
2F + 1- Akzeptorknoten im Cluster vorhanden sein.
Dies ist notwendig, damit wir auch in der schlimmsten Situation immer eine „gute“, korrekt funktionierende Knotenmehrheit haben. Das heißt,
F + 1 "gute" Knoten, die vereinbart wurden, und der endgültige Wert wird akzeptiert. Andernfalls kann es vorkommen, dass verschiedene lokale Gruppen unterschiedliche Bedeutungen annehmen und sich nicht einigen können. Deshalb brauchen wir eine absolute Mehrheit, um die Abstimmung zu gewinnen.
Die allgemeine Idee des Paxos-Konsensalgorithmus
Der Paxos-Algorithmus umfasst zwei große Phasen, die wiederum in zwei Schritte unterteilt sind:
- Phase 1a: Vorbereiten . In der Vorbereitungsphase informiert der Leiter (Antragsteller) alle Knoten: „Wir beginnen eine neue Abstimmungsphase. Wir haben eine neue Runde. Die Nummer dieser Runde ist n. Jetzt werden wir anfangen zu wählen. “ Derzeit wird lediglich der Beginn eines neuen Zyklus gemeldet, jedoch kein neuer Wert. Die Aufgabe dieser Phase ist es, eine neue Runde einzuleiten und jedem seine eindeutige Nummer mitzuteilen. Die runde Zahl ist wichtig, sie muss größer sein als alle vorherigen Abstimmungszahlen aller vorherigen Führer. Da es genau der runden Zahl zu verdanken ist, werden andere Knoten im System verstehen, wie frisch der Leiter Daten hat. Andere Knoten haben wahrscheinlich bereits Abstimmungsergebnisse aus viel späteren Runden und sie werden dem Anführer einfach sagen, dass er hinter der Zeit ist.
- Phase 1b: Versprechen . Wenn die Akzeptorknoten die Nummer der neuen Abstimmungsstufe erhalten haben, sind zwei Ergebnisse möglich:
- n , , acceptor. acceptor , , n. acceptor - (.. - ), , .
- , acceptor , .
- Phase 2a: Accept . ( ) , , :
- acceptor' , . c . x, : «Accept (n, x)», – Propose, – , .. , , .
- acceptor' , , , , . y. : «Accept (n, y)», .
- Phase 2b: Accepted . , -acceptor', «Accept(...)», ( , ) , - () n' > n , .
, , . Hurra! , , .
Paxos. , , , .
, Paxos — , , ,
Raft ,
.
«»:
« »:
- Impossibility of Distributed Consensus with One Faulty Process (FLP impossibility) , Fischer, Lynch and Paterson, research paper, 1985
- The Part-Time Parliament , Leslie Lamport, research paper, 1998
- Paxos made simple , Leslie Lamport, research paper, 2001