
In diesem Artikel möchte ich eine Alternative zum traditionellen Testdesignstil unter Verwendung der funktionalen Programmierkonzepte von Scala anbieten. Der Ansatz wurde von den vielen Monaten des Schmerzes inspiriert, die durch die Unterstützung von Dutzenden und Hunderten von Falltests und dem brennenden Wunsch entstanden waren, sie einfacher und verständlicher zu machen.
Trotz der Tatsache, dass der Code in Scala geschrieben ist, sind die vorgeschlagenen Ideen für Entwickler und Tester in allen Sprachen relevant, die das Paradigma der funktionalen Programmierung unterstützen. Einen Link zu Github mit einer vollständigen Lösung und einem Beispiel finden Sie am Ende des Artikels.
Das Problem
Wenn Sie sich jemals mit Tests befasst haben (es spielt keine Rolle - Komponententests, Integration oder Funktionstests), wurden sie höchstwahrscheinlich als sequentielle Anweisungen geschrieben. Z.B:
Dies ist die bevorzugte Methode zur Beschreibung von Tests, die keine Entwicklung erfordert. Unser Projekt umfasst etwa 1000 Tests auf verschiedenen Ebenen (Komponententests, Integrationstests, End-to-End-Tests), die bis vor kurzem alle in einem ähnlichen Stil geschrieben wurden. Als das Projekt wuchs, verspürten wir mit der Unterstützung solcher Tests erhebliche Probleme und eine Verlangsamung: Die Reihenfolge der Tests dauerte nicht weniger als das Schreiben von geschäftsrelevantem Code.
Beim Schreiben neuer Tests musste man immer von Grund auf überlegen, wie die Daten vorbereitet werden sollen. Oft Kopieren-Einfügen-Schritte aus benachbarten Tests. Als sich das Datenmodell in der Anwendung änderte, brach das Kartenhaus zusammen und musste in jedem Test auf eine neue Weise gesammelt werden: im besten Fall nur eine Änderung der Helferfunktionen, im schlimmsten Fall ein tiefes Eintauchen in den Test und ein Umschreiben.
Wenn der Test ehrlich abstürzte - das heißt, aufgrund eines Fehlers in der Geschäftslogik und nicht aufgrund von Problemen im Test selbst - war es unmöglich zu verstehen, wo etwas schief gelaufen ist, ohne zu debuggen. Aufgrund der Tatsache, dass es lange gedauert hat, die Tests zu verstehen, war niemand vollständig über die Anforderungen informiert - wie sich das System unter bestimmten Bedingungen verhalten sollte.
All dieser Schmerz ist das Symptom für zwei tiefere Probleme dieses Entwurfs:
- Der Inhalt des Tests ist in zu lockerer Form zulässig. Jeder Test ist einzigartig, wie eine Schneeflocke. Die Notwendigkeit, die Details des Tests zu lesen, nimmt viel Zeit in Anspruch und demotiviert. Nicht wichtige Details lenken von der Hauptsache ab - den durch den Test verifizierten Anforderungen. Kopieren Einfügen wird zur Hauptmethode zum Schreiben neuer Testfälle.
- Tests helfen dem Entwickler nicht, Fehler zu lokalisieren, sondern signalisieren nur ein Problem. Um den Status zu verstehen, in dem der Test durchgeführt wird, müssen Sie ihn in Ihrem Kopf wiederherstellen oder eine Verbindung mit einem Debugger herstellen.
Modellierung
Können wir es besser machen? (Spoiler: Wir können.) Schauen wir uns an, woraus dieser Test besteht.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Der getestete Code wartet in der Regel auf die Eingabe einiger expliziter Parameter - Bezeichner, Größen, Volumes, Filter usw. Außerdem werden häufig Daten aus der realen Welt benötigt - wir sehen, dass sich die Anwendung auf die Menüs und Menüvorlagen bezieht Datenbank. Für eine zuverlässige Testausführung benötigen wir eine Vorrichtung - den Zustand, in dem sich das System und / oder die Datenanbieter befinden sollten, bevor der Test beginnt, und die Eingabeparameter, die häufig mit dem Zustand zusammenhängen.
Wir werden Abhängigkeiten mit diesem Gerät vorbereiten - füllen Sie die Datenbank (Warteschlange, externer Dienst usw.). Mit der vorbereiteten Abhängigkeit initialisieren wir die getestete Klasse (Dienste, Module, Repositorys usw.).
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
Durch Ausführen des Testcodes für einige Eingabeparameter erhalten wir ein geschäftsrelevantes Ergebnis ( Ausgabe ) - sowohl explizit (von der Methode zurückgegeben) als auch implizit - eine Änderung des berüchtigten Status: Datenbank, externer Dienst usw.
result shouldBe 90
Schließlich überprüfen wir, ob die Ergebnisse genau den Erwartungen entsprechen, und fassen den Test mit einer oder mehreren Aussagen zusammen .
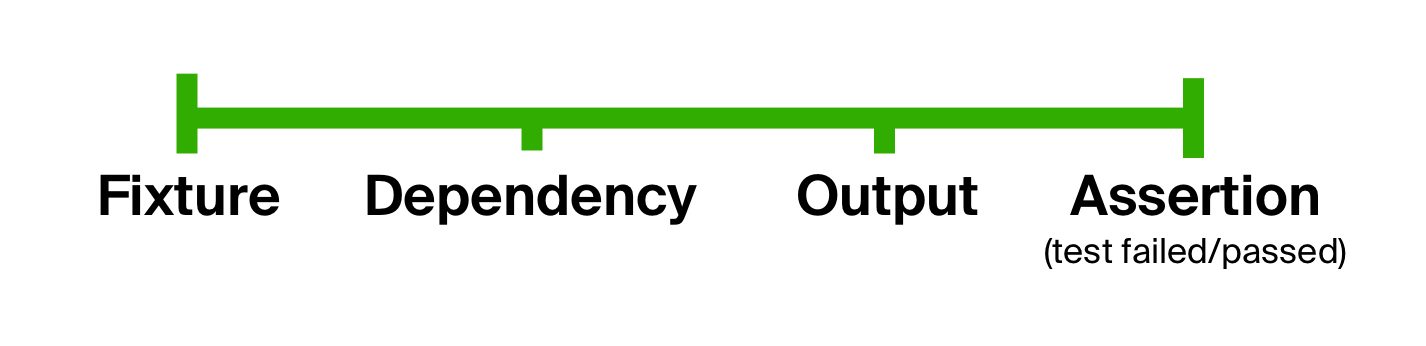
Es kann gefolgert werden, dass der Test im Allgemeinen aus denselben Phasen besteht: Vorbereiten von Eingabeparametern, Ausführen des Testcodes auf diesen und Vergleichen der Ergebnisse mit den erwarteten. Wir können diese Tatsache nutzen, um das erste Problem im Test zu beseitigen - eine zu lockere Form, die den Test klar in Stufen unterteilt. Diese Idee ist nicht neu und wird seit langem in Tests im BDD-Stil ( verhaltensgesteuerte Entwicklung ) verwendet.
Was ist mit Erweiterbarkeit? Jeder der Schritte im Testprozess kann so viele Zwischenschritte enthalten, wie Sie möchten. Mit Blick auf die Zukunft könnten wir ein Fixture bilden, indem wir zuerst eine Art von lesbarer Struktur erstellen und sie dann in Objekte konvertieren, die die Datenbank füllen. Der Testprozess ist unendlich erweiterbar, aber letztendlich kommt es immer auf die Hauptphasen an.

Ausführen von Tests
Lassen Sie uns versuchen, die Idee der Aufteilung des Tests in Stufen zu verwirklichen, aber zuerst bestimmen wir, wie wir das Endergebnis sehen möchten.
Im Allgemeinen möchten wir das Schreiben und Unterstützen von Tests zu einem weniger arbeitsintensiven und unterhaltsamen Prozess machen. Je weniger explizite, nicht eindeutige (an anderer Stelle wiederholte) Anweisungen im Testkörper, desto weniger Änderungen müssen an den Tests vorgenommen werden, nachdem Verträge geändert oder umgestaltet wurden, und desto weniger Zeit wird zum Lesen des Tests benötigt. Das Design des Tests sollte die Wiederverwendung häufig verwendeter Codeteile fördern und ein gedankenloses Kopieren verhindern. Es wäre schön, wenn die Tests ein einheitliches Aussehen hätten. Vorhersagbarkeit verbessert die Lesbarkeit und spart Zeit - stellen Sie sich vor, wie viel Zeit Physikstudenten benötigen würden, um jede neue Formel zu beherrschen, wenn sie nicht in mathematischer Sprache, sondern in Freiformwörtern beschrieben würden.
Unser Ziel ist es daher, alles ablenkend und überflüssig zu verbergen und nur die Informationen zu belassen, die für das Verständnis der Anwendung entscheidend sind: Was wird getestet, was wird am Eingang erwartet und was wird am Ausgang erwartet.
Kehren wir zum Modell des Testgeräts zurück. Technisch gesehen kann jeder Punkt in diesem Diagramm durch einen Datentyp dargestellt werden und von einem zum anderen übergehen - Funktionen. Sie können vom ursprünglichen zum endgültigen Datentyp wechseln, indem Sie die folgende Funktion nacheinander auf das Ergebnis des vorherigen anwenden. Mit anderen Worten: Verwenden einer Funktionszusammensetzung : Vorbereiten von Daten (nennen wir sie prepare ), Ausführen des Testcodes ( execute ) und Überprüfen des erwarteten Ergebnisses ( check ). Wir werden den ersten Punkt des Diagramms, Fixture, an die Eingabe dieser Komposition übergeben. Die resultierende Funktion höherer Ordnung wird als Testlebenszyklusfunktion bezeichnet .
Lebenszyklusfunktion def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
Die Frage ist, woher kommen die internen Funktionen? Wir werden die Daten auf eine begrenzte Anzahl von Arten vorbereiten - um die Datenbank zu füllen, nass zu werden usw. - daher sind die Optionen für die Vorbereitungsfunktion allen Tests gemeinsam. Infolgedessen wird es einfacher sein, spezielle Lebenszyklusfunktionen zu erstellen, die die spezifische Implementierung der Datenaufbereitung verbergen. Da die Methoden zum Aufrufen des zu überprüfenden und zu überprüfenden Codes für jeden Test relativ eindeutig sind, werden execute und check explizit bereitgestellt.
Lebenszyklusfunktion angepasst für Integrationstests in der Datenbank Indem wir alle administrativen Nuancen an die Lebenszyklusfunktion delegieren, erhalten wir die Möglichkeit, den Testprozess zu erweitern, ohne in einen bereits schriftlichen Test einzusteigen. Aufgrund der Zusammensetzung können wir überall im Prozess infiltrieren, dort Daten extrahieren oder hinzufügen.
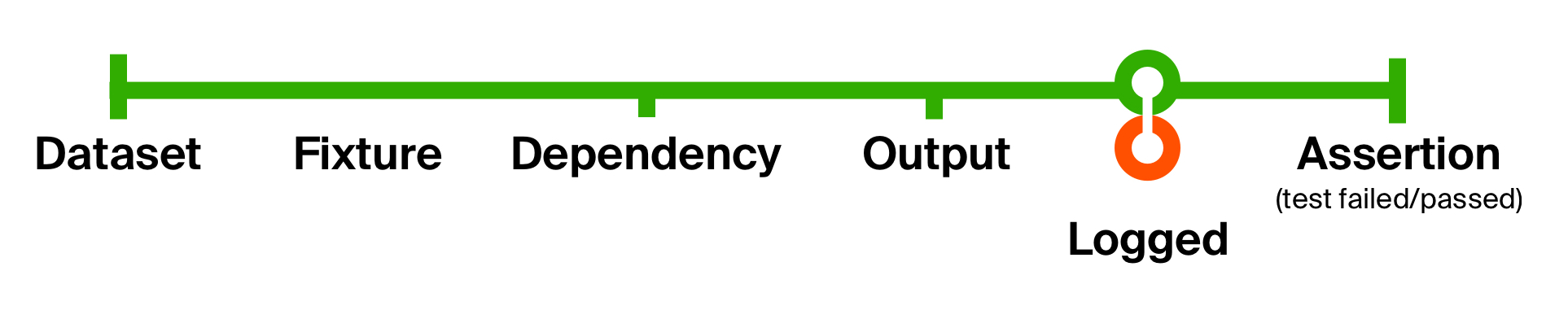
Um die Möglichkeiten dieses Ansatzes besser zu veranschaulichen, werden wir das zweite Problem unseres ersten Tests lösen - den Mangel an unterstützenden Informationen zur Lokalisierung von Problemen. Fügen Sie die Protokollierung hinzu, wenn Sie eine Antwort von der getesteten Methode erhalten. Unsere Protokollierung ändert nicht den Datentyp, sondern erzeugt nur einen Nebeneffekt - das Anzeigen einer Nachricht auf der Konsole. Daher werden wir es nach dem Nebeneffekt so zurückgeben, wie es ist.
Protokollierung der Lebenszyklusfunktion def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
Mit einer so einfachen Bewegung haben wir in jedem Test die Protokollierung des zurückgegebenen Ergebnisses und den Status der Datenbank hinzugefügt. Der Vorteil dieser kleinen Funktionen besteht darin, dass sie leicht zu verstehen, leicht zur Wiederverwendung zusammenzustellen und leicht zu entfernen sind, wenn sie nicht mehr benötigt werden.

Infolgedessen sieht unser Test folgendermaßen aus:
val fixture: SomeMagicalFixture = ???
Der Testkörper ist knapp geworden, Fixtures und Checks können in anderen Tests wiederverwendet werden, und wir bereiten die Datenbank nirgendwo anders manuell vor. Es bleibt nur ein Problem ...
Gerätevorbereitung
Im obigen Code haben wir die Annahme verwendet, dass das Gerät von einem vorgefertigten Ort stammt und nur in die Lebenszyklusfunktion übertragen werden muss. Da Daten ein wesentlicher Bestandteil einfacher und unterstützter Tests sind, können wir nur darauf eingehen, wie sie erstellt werden sollen.
Angenommen, unser Testspeicher verfügt über eine typische mittelgroße Datenbank (der Einfachheit halber ein Beispiel mit 4 Tabellen, in Wirklichkeit können es jedoch Hunderte sein). Ein Teil enthält Hintergrundinformationen, ein Teil - direktes Geschäft, und alles in allem kann es zu mehreren vollwertigen logischen Entitäten verbunden werden. Tabellen sind durch Schlüssel ( Fremdschlüssel ) miteinander verbunden. Um eine Bonus Entität zu erstellen, benötigen Sie die Package Entität und damit den User . Usw.

Umstände von Schaltungsbeschränkungen und allerlei Hacks führen zu Inkonsistenzen und damit zu Testinstabilität und stundenlangem aufregendem Debuggen. Aus diesem Grund werden wir die Datenbank ehrlich füllen.
Wir könnten militärische Methoden zum Füllen verwenden, aber selbst bei einer oberflächlichen Untersuchung dieser Idee stellen sich viele schwierige Fragen. Was bereitet die Daten in Tests für diese Methoden selbst vor? Muss ich die Tests neu schreiben, wenn sich der Vertrag ändert? Was ist, wenn die Daten von einer nicht getesteten Anwendung geliefert werden (z. B. von einer anderen Person importiert)? Wie viele verschiedene Abfragen müssen durchgeführt werden, um eine von vielen anderen abhängige Entität zu erstellen?
Füllen Sie die Basis im ersten Test insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Verstreute Hilfsmethoden wie im ursprünglichen Beispiel sind das gleiche Problem, jedoch mit einer anderen Sauce. Sie übertragen uns die Verantwortung für die Verwaltung abhängiger Objekte und ihrer Beziehungen, und wir möchten dies vermeiden.
Im Idealfall hätte ich gerne diese Art von Daten, von denen ein Blick ausreicht, um allgemein zu verstehen, in welchem Zustand sich das System während des Tests befindet. Einer der guten Kandidaten für die Statusvisualisierung ist eine Tabelle (a la Datasets in PHP und Python), in der nichts überflüssig ist, außer für Felder, die für die Geschäftslogik kritisch sind. Wenn sich die Geschäftslogik in einem Feature ändert, wird die gesamte Testunterstützung auf die Aktualisierung der Zellen im Dataset reduziert. Zum Beispiel:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
Aus unserer Tabelle generieren wir Schlüssel- Entitäts-Beziehungen nach ID. In diesem Fall wird ein Schlüssel für die Abhängigkeit gebildet, wenn die Entität von einer anderen abhängt. Es kann vorkommen, dass zwei verschiedene Entitäten eine Abhängigkeit mit demselben Bezeichner generieren, was zu einer Verletzung der Einschränkung des Primärschlüssels der Datenbank ( Primärschlüssel ) führen kann. In dieser Phase ist die Deduplizierung der Daten jedoch äußerst kostengünstig. Da die Schlüssel nur Bezeichner enthalten, können wir sie in eine Sammlung einfügen, die beispielsweise in Set eine Deduplizierung ermöglicht. Wenn sich dies als unzureichend herausstellt, können wir immer eine intelligentere Deduplizierung in Form einer zusätzlichen Funktion durchführen, die in eine Lebenszyklusfunktion kompiliert wird.
Schlüsselbeispiel sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
Wir delegieren die Generierung von gefälschten Inhalten an Felder (z. B. Namen) an eine separate Klasse. Wenn wir dann auf die Hilfe dieser Klasse und die Regeln zum Konvertieren von Schlüsseln zurückgreifen, erhalten wir Zeichenfolgenobjekte, die direkt zum Einfügen in die Datenbank bestimmt sind.
Linienbeispiel object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Die standardmäßigen gefälschten Daten reichen in der Regel nicht aus, daher müssen wir in der Lage sein, bestimmte Felder neu zu definieren. Wir können Linsen verwenden - durchlaufen Sie alle erstellten Linien und ändern Sie nur die Felder der benötigten. Da die Linsen am Ende gewöhnliche Funktionen sind, können sie zusammengesetzt werden, und dies ist ihre Nützlichkeit.
Linsenbeispiel def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Dank der Zusammensetzung können wir innerhalb des gesamten Prozesses verschiedene Optimierungen und Verbesserungen anwenden - beispielsweise Gruppenzeilen in Tabellen, damit sie mit einer insert eingefügt werden können, wodurch die Testzeit verkürzt oder der endgültige Status der Datenbank gesichert wird, um das Auffangen von Problemen zu vereinfachen.
Vorrichtungsformungsfunktion def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Alles zusammen ergibt eine Einrichtung, die die Abhängigkeit für den Test ausfüllt - die Datenbank. Im Test selbst wird außer dem Originaldatensatz nichts Überflüssiges angezeigt - alle Details werden in der Zusammensetzung der Funktionen verborgen.

Unsere Testsuite sieht nun folgendermaßen aus:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) " -" - { "'customer'" - { " " - { "< 250 - " - { "(: )" in calculatePriceFor(dataTable, 1) "(: )" in calculatePriceFor(dataTable, 3) } ">= 250 " - { " - 10% " in calculatePriceFor(dataTable, 2) " - 10% " in calculatePriceFor(dataTable, 4) } } } "'vip' - 20% , " in calculatePriceFor(dataTable, 5) }
Ein Hilfecode:
Das Hinzufügen neuer Testfälle zur Tabelle wird zu einer trivialen Aufgabe, bei der Sie sich darauf konzentrieren können , die maximale Anzahl von Randbedingungen abzudecken , anstatt sich auf eine Kesselplatte zu konzentrieren.
Wiederverwendung des Vorrichtungsvorbereitungscodes für andere Projekte
Nun, wir haben viel Code für die Vorbereitung von Fixtures in einem bestimmten Projekt geschrieben und viel Zeit damit verbracht. Was ist, wenn wir mehrere Projekte haben? Sind wir dazu verdammt, das Rad jedes Mal neu zu erfinden und zu kopieren und einzufügen?
Wir können die Vorbereitung von Fixtures von einem bestimmten Domänenmodell abstrahieren. In der Welt von FP gibt es das Konzept einer Typklasse . Kurz gesagt, Typklassen sind keine Klassen aus OOP, sondern so etwas wie Schnittstellen, sie definieren ein Verhalten von Typgruppen. Der grundlegende Unterschied besteht darin, dass diese Gruppe von Typen nicht wie gewöhnliche Variablen durch Klassenvererbung, sondern durch Instanziierung bestimmt wird. Wie bei der Vererbung erfolgt das Auflösen von Instanzen von Typklassen (über Implizite ) statisch in der Kompilierungsphase. Der Einfachheit halber können Typklassen für unsere Zwecke als Erweiterungen von Kotlin und C # betrachtet werden .
Um ein Objekt zu verpfänden, müssen wir nicht wissen, was dieses Objekt enthält, welche Felder und Methoden es enthält. Für uns ist es nur wichtig, dass das log mit einer bestimmten Signatur dafür definiert wird. Es wäre Logged , in jeder Klasse eine bestimmte Logged Schnittstelle zu implementieren, und dies ist nicht immer möglich - beispielsweise in Bibliotheks- oder Standardklassen. Bei Typklassen ist alles viel einfacher. Wir können eine Instanz der protokollierten Logged beispielsweise für Fixtures erstellen und in lesbarer Form anzeigen. Erstellen Sie für alle anderen Typen eine Instanz für den Any Typ und verwenden Sie die Standard- toString Methode, um alle Objekte in ihrer internen Darstellung kostenlos zu protokollieren.
Ein Beispiel für die Tagged-Klasse und die dazugehörigen Instanzen trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
Zusätzlich zur Protokollierung können wir diesen Ansatz auf den gesamten Prozess der Vorbereitung von Vorrichtungen ausweiten. Die Testlösung bietet eigene Zeitklassen und die darauf basierende abstrakte Implementierung von Funktionen. Die Verantwortung des Projekts, das es verwendet, besteht darin, eine eigene Instanz von Typklassen für Typen zu schreiben.
Bei der Entwicklung des Vorrichtungsgenerators habe ich mich auf die Umsetzung der Prinzipien der Programmierung und des SOLID-Entwurfs als Indikator für seine Stabilität und Anpassungsfähigkeit an verschiedene Systeme konzentriert:
- Das Prinzip der Einzelverantwortung : Jede Typklasse beschreibt genau einen Aspekt des Typverhaltens.
- Das Open-Closed-Prinzip : Wir ändern den vorhandenen Kampftyp nicht für Tests, sondern erweitern ihn um Instanzen von Tymplass.
- Das Liskov-Substitutionsprinzip spielt in diesem Fall keine Rolle, da wir keine Vererbung verwenden.
- Das Prinzip der Schnittstellentrennung : Wir verwenden viele spezialisierte Zeitklassen anstelle einer einzigen globalen.
- Das Prinzip der Abhängigkeitsinversion : Die Implementierung des Fixture Generators hängt nicht von bestimmten Kampftypen ab, sondern von abstrakten Zeitklassen.
Nachdem sichergestellt wurde, dass alle Prinzipien erfüllt sind, kann argumentiert werden, dass unsere Lösung ausreichend unterstützt und erweiterbar erscheint, um sie in verschiedenen Projekten zu verwenden.
Nachdem wir die Funktionen des Lebenszyklus, die Generierung von Fixtures und die Konvertierung von Datensätzen in Fixtures sowie die Abstraktion von einem bestimmten Domänenmodell der Anwendung geschrieben haben, sind wir endlich bereit, unsere Lösung auf alle Tests zu skalieren.
Zusammenfassung
Wir sind vom traditionellen (schrittweisen) Stil des Testdesigns zum funktionalen übergegangen. Ein schrittweiser Stil ist in der Anfangsphase und bei kleinen Projekten insofern gut, als er keinen zusätzlichen Arbeitsaufwand erfordert und den Entwickler nicht einschränkt, aber zu verlieren beginnt, wenn viele Tests für das Projekt durchgeführt werden. Der Funktionsstil ist nicht darauf ausgelegt, alle Probleme beim Testen zu lösen, kann jedoch die Skalierung und Unterstützung von Tests in Projekten, deren Anzahl Hunderte oder Tausende beträgt, erheblich erleichtern. Funktionsstiltests sind kompakter und konzentrieren sich auf das, was wirklich wichtig ist (Daten, testbarer Code und erwartetes Ergebnis), und nicht auf Zwischenschritte.
Darüber hinaus haben wir uns ein lebendiges Beispiel dafür angesehen, wie leistungsfähig die Konzepte von Komposition und Typklassen in der funktionalen Programmierung sind. Mit ihrer Hilfe ist es einfach, Lösungen zu entwerfen, deren Erweiterbarkeit und Wiederverwendbarkeit ein wesentlicher Bestandteil sind.
, , , . , , , -. , . !
: Github