 TL; DR
TL; DR : Client-Server-Architektur unseres internen Konfigurationsmanagement-Tools QControl.
Im Untergeschoss befindet sich ein zweischichtiges Transportprotokoll, das mit gzip-komprimierten Nachrichten ohne Dekomprimierung zwischen Endpunkten arbeitet. Verteilte Router und Endpunkte erhalten die Konfigurationsaktualisierungen, und das Protokoll selbst ermöglicht die Installation von lokalisierten Zwischenrelais. Es basiert auf einem
differenziellen Backup -Design („kürzlich stabil“, weiter unten erläutert) und verwendet die JMESpath-Abfragesprache und Jinja-Vorlagen für das Rendern der Konfiguration.
Qrator Labs betreibt ein global verteiltes Schadensbegrenzungsnetzwerk und unterhält es. Unser Netzwerk ist Anycast, basierend auf der Ankündigung unserer Subnetze über BGP. Als BGP-Anycast-Netzwerk, das sich physisch in mehreren Regionen der Erde befindet, können wir illegitimen Datenverkehr näher am Internet-Backbone verarbeiten und filtern - Tier-1-Betreiber.
Ein geografisch verteiltes Netzwerk zu sein, birgt jedoch seine Schwierigkeiten. Die Kommunikation zwischen den Network Points of Presence (PoP) ist für einen Sicherheitsanbieter unerlässlich, um eine kohärente Konfiguration für alle Netzwerkknoten zu erhalten und diese zeitnah und zusammenhängend zu aktualisieren. Um den Kunden den bestmöglichen Service bieten zu können, mussten wir einen Weg finden, um die Konfigurationsdaten zwischen verschiedenen Kontinenten zuverlässig zu synchronisieren.
Am Anfang gab es das Wort ..., das schnell zu einem Kommunikationsprotokoll wurde, das aktualisiert werden musste.
Der Eckpfeiler der Existenz von QControl und der Hauptgrund dafür, viel Zeit und Mühe in die Erstellung eines solchen Protokolls zu investieren, ist die Notwendigkeit, eine maßgebliche Quelle für die Konfiguration zu erhalten und schließlich unsere PoPs damit zu synchronisieren. Speicher war nur eine von mehreren erforderlichen Funktionen der QControl-Entwicklung. Darüber hinaus brauchten wir auch die Integration in die bestehende und zukünftige Peripherie, intelligente (und anpassbare) Datenvalidierungen und Zugriffsdifferenzierung. Darüber hinaus wollten wir, dass dieses System die Dinge durch Befehle verwaltet, nicht durch manuelle Dateimodifikationen. Vor QControl wurden Daten mehr oder weniger manuell an die Präsenzpunkte gesendet. Wenn ein PoP im Moment nicht verfügbar war und wir vergessen haben, es später zu aktualisieren, wurde die Konfiguration desynchronisiert und eine zeitaufwändige Fehlerbehebung war erforderlich, um es wieder synchron zu machen.
Hier ist das System, das wir uns ausgedacht haben:
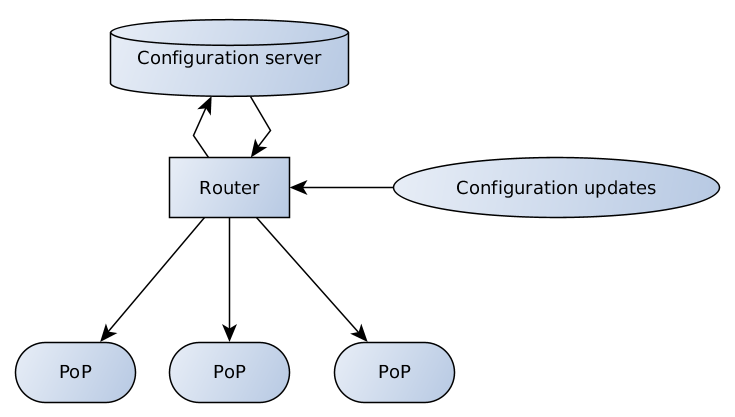
Der Konfigurationsserver ist für die Datenüberprüfung und -speicherung verantwortlich. Der Router verfügt über verschiedene Endpunkte zum Empfangen und Weiterleiten von Konfigurationsaktualisierungen von Clients und Supportteams an Server und von Server an PoPs.
Die Qualität der Internetverbindung ist auf der ganzen Welt immer noch sehr unterschiedlich. Um dies zu veranschaulichen, stellen wir uns eine einfache Traceroute von Prag, der Tschechischen Republik nach Singapur und Hongkong vor.

MTR von Prag nach Singapur

Gleicher zweiter Screenshot mit Traceroute nach Hong Kong
Hohe Latenzzeiten bedeuten schlechte Geschwindigkeit. Es gibt auch einen hohen Paketverlust. Bandbreitennummern kompensieren dieses Problem nicht, das beim Aufbau dezentraler Netzwerke immer berücksichtigt werden sollte.
Die vollständige PoP-Konfiguration ist ein ziemlich bedeutender Datenblock und muss über unzuverlässige Verbindungen an viele verschiedene Empfänger übertragen werden. Obwohl sich die Konfiguration häufig ändert, ändert sie sich glücklicherweise in kleinen Schritten.
Neuestes stabiles Design
Es ist eine recht einfache Entscheidung, ein verteiltes Netzwerk basierend auf inkrementellen Updates aufzubauen. Obwohl es einige Probleme mit den Diffs gibt, sind sie schwer richtig zu erstellen: Wir müssen alle Diffs zwischen Referenzpunkten irgendwo speichern, um sie erneut senden zu können, wenn jemand etwas verloren hat. Jedes Ziel sollte sie kohärent anwenden. Wenn es mehrere Ziele gibt, kann dies im gesamten Netzwerk viel Zeit in Anspruch nehmen. Der Adressat sollte auch in der Lage sein, fehlende Teile anzufordern, und natürlich muss der zentrale Teil diese Anfrage genau beantworten und nur die fehlenden Daten senden.
Was wir am Ende gebaut haben, ist eine ziemliche Sache - wir haben nur eine Referenzschicht, die feste „stabile“ und nur ein Diff, „neu“ dafür. Jede aktuelle Version basiert auf dem neuesten Stable und reicht aus, um Konfigurationsdaten neu zu erstellen. Wenn ein neuer Neuzugang das Ziel erreicht, ist der alte verfügbar.
Es macht uns manchmal die Notwendigkeit, eine neue stabile Konfiguration zu senden, weil die jüngsten zu groß werden. Ein wichtiger Hinweis hierbei ist auch, dass wir all dies durch Senden / Multicasting-Updates erreichen können, ohne uns Gedanken über den Empfang von Zielen machen zu müssen, die die Teile zusammenbauen können. Sobald wir überprüfen, ob jeder den richtigen Stall hat, werden alle nur mit dem frischen Neugeborenen gefüttert. Sollen wir sagen, dass es funktioniert? Es tut. Stables werden auf dem Konfigurationsserver und den Empfängern zwischengespeichert, wobei die zuletzt erstellten bei Bedarf neu erstellt werden.
Zweischichtige Transportarchitektur
Warum genau haben wir unseren Transport aus zwei Schichten aufgebaut? Die Antwort ist ziemlich einfach: Wir wollten das Routing von der Anwendung trennen und uns vom OSI-Modell mit seinen Transport- und Anwendungsebenen inspirieren lassen. Daher haben wir das Transportprotokoll (Thrift) vom Serialisierungsformat für Befehle auf hoher Ebene (msgpack) getrennt. Aus diesem Grund schaut ein Router (der Multicast / Broadcast / Relay ausführt) weder in das msgpack, noch extrahiert oder komprimiert er die Nutzdaten und führt nur die Übertragung durch.
Sparsamkeits-
Wiki :
Mit Apache Thrift können Sie Datentypen und Dienstschnittstellen in einer einfachen Definitionsdatei definieren. Ausgehend von dieser Datei generiert der Compiler Code, mit dem auf einfache Weise RPC-Clients und -Server erstellt werden können, die nahtlos über Programmiersprachen hinweg kommunizieren. Anstatt eine Menge Boilerplate-Code zu schreiben, um Ihre Objekte zu serialisieren und zu transportieren und Remote-Methoden aufzurufen.Wir haben das Thrift-Framework aufgrund seines RPC und der gleichzeitigen Unterstützung mehrerer Sprachen verwendet. Wie immer sind die einfachen Teile einfach zu erstellen: der Client und der Server. Der Router war jedoch ziemlich hart zu knacken, was teilweise auf das Fehlen einer gebrauchsfertigen Lösung zu diesem Zeitpunkt zurückzuführen war.

Es gibt einige andere Optionen, wie den Protobuf / gRPC. Als wir mit unserem Projekt begannen, war der gRPC jedoch noch nicht ausgereift und wir zögerten, ihn zu verwenden.
Natürlich könnten (und sollten!) Wir ein eigenes Rad schaffen. Es wäre einfacher, ein benutzerdefiniertes Protokoll für das zu erstellen, was wir zusammen mit dem Router benötigen, da der Client-Server einfacher zu programmieren ist als ein funktionierender Router mit Thrift. Es gibt jedoch eine traditionelle Negativität gegenüber benutzerdefinierten Protokollen und Implementierungen beliebter Bibliotheken, und es gibt immer die Frage, wie wir sie anschließend in andere Sprachen portieren können. Also beschlossen wir, die Wheely-Ideen fallen zu lassen.
Msgpack
Beschreibung :
MessagePack ist ein effizientes binäres Serialisierungsformat. Sie können damit Daten zwischen mehreren Sprachen wie JSON austauschen. Aber es ist schneller und kleiner. Kleine Ganzzahlen werden in ein einzelnes Byte codiert, und typische kurze Zeichenfolgen erfordern zusätzlich zu den Zeichenfolgen selbst nur ein zusätzliches Byte.Auf der ersten Ebene haben wir eine Sparsamkeit mit den Mindestinformationen, die der Router zum Senden einer Nachricht benötigt. Auf der zweiten Ebene haben wir msgpack-Strukturen komprimiert.
Wir haben für das msgpack gestimmt, weil es im Vergleich zu JSON schneller und kompakter ist. Noch wichtiger ist jedoch, dass benutzerdefinierte Datentypen unterstützt werden, die einige aufregende Funktionen wie „White-Outs“ und die Übertragung von Rohdaten ermöglichen.
JmespathJMESPath ist eine Abfragesprache für JSON.Dies ist die einzige Beschreibung, die wir aus der offiziellen JMESPath-Dokumentation erhalten, aber tatsächlich ist es viel mehr als nur das. Mit JMESPath können beliebige baumartige Strukturen gesucht und gefiltert und sogar Datentransformationen im laufenden Betrieb angewendet werden. Wir verwenden diese Abfragesprache, um relevante Informationen aus dem großen Konfigurations-Blob abzurufen.
Während die gesamte Konfiguration eine baumartige Struktur aufweist, extrahieren wir die relevanten Unterbäume für verschiedene Konfigurationsziele.
Es ist auch flexibel genug, um den Unterbaum unabhängig von einer Konfigurationsvorlage oder anderen Konfigurations-Plugins zu ändern. Um es noch besser zu machen, ist JMES Path leicht erweiterbar und ermöglicht das Schreiben von benutzerdefinierten Filtern und Datentransformationsroutinen. Es braucht jedoch etwas Brainpower, um zu verstehen.
JinjaFür einige Ziele müssen wir die Konfiguration in Dateien rendern, daher brauchten wir eine Vorlagen-Engine, bei der Jinja eine offensichtliche Wahl ist. Jinja generiert eine Konfigurationsdatei aus der Vorlage und den am Zielpunkt empfangenen Daten.
Zum Rendern der Konfigurationsdatei benötigen wir eine jmespath-Anforderung, eine Vorlage für die Pfad- und Zieldatei sowie eine Vorlage für die Konfiguration selbst. An dieser Stelle sollten Sie auch die Dateizugriffsrechte angeben. All dies wurde glücklicherweise in einer Datei zusammengefasst - vor der Konfigurationsvorlage haben wir einen YAML-Header eingefügt, der den Rest beschreibt. Zum Beispiel:
---
selector: "[@][?@.fft._meta.version == `42`] | items([0].fft_config || `{}`)"
destination_filename: "fft/{{ match[0] }}.json"
file_mode: 0644
reload_daemons: [fft]
...
{{ dict(match[1]) | json(indent=2, sort_keys=True) }}
Um die Konfiguration für eine neue Peripherie vorzunehmen, fügen wir eine neue Vorlagendatei hinzu. Es sind keine Änderungen am Quellcode und keine PoP-Software-Updates erforderlich.
Was hat sich nach der Implementierung des QControl-Konfigurationsmanagement-Tools geändert?
In erster Linie haben wir in unserem gesamten Netzwerk kohärente und zuverlässige Konfigurationsaktualisierungen erhalten.
Zweitens geben wir ein leistungsstarkes Tool zur Validierung und Änderung der Konfiguration in die Hände unseres Supportteams und unserer Kunden.
Wir haben dies erreicht, indem wir ein kürzlich stabiles Design verwendet haben, um die Kommunikation zwischen dem Konfigurationsserver und den Konfigurationsempfängern zu vereinfachen, ein zweischichtiges Kommunikationsprotokoll zur Unterstützung von Nutzlast-unabhängigen Routern zu verwenden und die Jinja-basierte Konfigurations-Rendering-Engine zu implementieren, um eine Vielzahl zu unterstützen von Konfigurationsdateien für unsere vielfältige Peripherie.