 TL; DR
TL; DR : Beschreibung der Client-Server-Architektur unseres internen Netzwerkkonfigurationsmanagementsystems QControl. Es basiert auf einem zweistufigen Transportprotokoll, das mit gzip-gepackten Nachrichten ohne Dekomprimierung zwischen Endpunkten funktioniert. Verteilte Router und Endpunkte erhalten Konfigurationsaktualisierungen, und das Protokoll selbst ermöglicht die Installation lokalisierter Zwischenrelais. Das System basiert auf dem Prinzip der
differenziellen Sicherung („kürzlich stabil“, siehe unten) und verwendet die JMESpath-Abfragesprache zusammen mit der Jinja-Vorlagen-Engine zum Rendern von Konfigurationsdateien.
Qrator Labs verwaltet ein global verteiltes Netzwerk zur Abwehr von Angriffen. Unser Netzwerk arbeitet nach dem Prinzip des Anycasts und Subnetze werden über BGP angekündigt. Als BGP-Anycast-Netzwerk, das sich physisch in mehreren Regionen der Erde befindet, können wir illegitimen Verkehr verarbeiten und herausfiltern, der näher am Kern des Internets liegt - Tier-1-Betreiber.
Andererseits ist es nicht einfach, ein geografisch verteiltes Netzwerk zu sein. Die Kommunikation zwischen Netzwerkpräsenzpunkten ist für einen Sicherheitsdienstanbieter von entscheidender Bedeutung, um eine konsistente Konfiguration aller Netzwerkknoten zu erhalten und diese rechtzeitig zu aktualisieren. Um den Verbrauchern ein Höchstmaß an Basisdiensten bieten zu können, mussten wir daher einen Weg finden, Konfigurationsdaten zwischen Kontinenten zuverlässig zu synchronisieren.
Am Anfang war das Wort. Es wurde schnell zu einem Kommunikationsprotokoll, das aktualisiert werden musste.
Der Eckpfeiler der Existenz von QControl und gleichzeitig der Hauptgrund für den erheblichen Zeit- und Ressourcenaufwand für die Erstellung eines solchen Protokolls ist die Notwendigkeit, eine einzige maßgebliche Konfigurationsquelle zu erhalten und letztendlich unsere Präsenzpunkte damit zu synchronisieren. Das Repository selbst war nur eine von mehreren Anforderungen während der Entwicklung von QControl. Darüber hinaus benötigten wir die Integration in vorhandene und geplante Dienste an den Punkten der Präsenz (TP), intelligente (und benutzerdefinierte) Methoden zur Datenvalidierung sowie Zugriffskontrolle. Darüber hinaus wollten wir ein solches System auch mit Befehlen verwalten, anstatt Änderungen an den Dateien vorzunehmen. Vor QControl wurden Daten im fast manuellen Modus an Präsenzpunkte gesendet. Wenn einer der Präsenzpunkte nicht verfügbar war und wir vergessen haben, ihn später zu aktualisieren, stellte sich heraus, dass die Konfiguration nicht synchron war. Sie mussten Zeit aufwenden, um sie wieder in Betrieb zu nehmen.
Als Ergebnis haben wir das folgende Schema entwickelt:
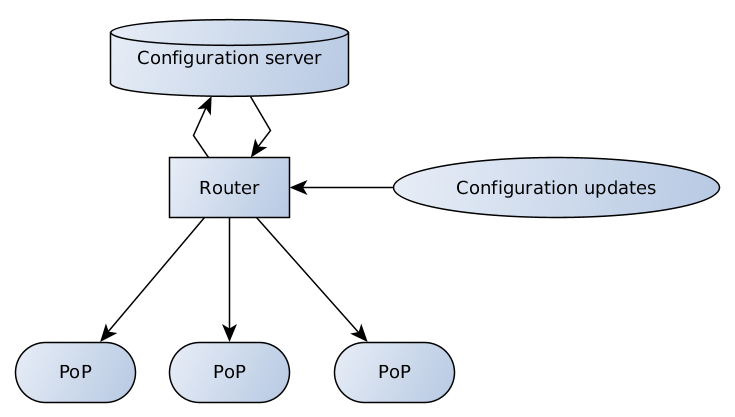
Der Konfigurationsserver ist für die Datenüberprüfung und -speicherung verantwortlich. Der Router verfügt über mehrere Endpunkte, die Konfigurationsaktualisierungen von Clients und Supportteams an den Server und vom Server an Präsenzpunkte empfangen und senden.
Die Qualität der Internetverbindung ist in verschiedenen Teilen der Welt immer noch sehr unterschiedlich. Um diese These zu veranschaulichen, betrachten wir eine einfache MTR von Prag, der Tschechischen Republik nach Singapur und Hongkong.

MTR von Prag nach Singapur

Das Gleiche gilt für Hongkong
Hohe Verzögerungen bedeuten weniger Geschwindigkeit. Zusätzlich gibt es einen Paketverlust. Die Breite der Kanäle gleicht dieses Problem nicht aus, das beim Aufbau dezentraler Systeme immer berücksichtigt werden sollte.
Eine vollständige Point-of-Presence-Konfiguration ist eine erhebliche Datenmenge, die über nicht vertrauenswürdige Verbindungen an viele Empfänger gesendet werden muss. Obwohl sich die Konfiguration ständig ändert, geschieht dies glücklicherweise in kleinen Portionen.
Neuestes stabiles Design
Wir können sagen, dass der Aufbau eines verteilten Netzwerks nach dem Prinzip inkrementeller Aktualisierungen eine ziemlich offensichtliche Lösung ist. Aber es gibt viele Probleme mit Unterschieden. Wir müssen alle Unterschiede zwischen den Kontrollpunkten beibehalten und sie senden können, falls jemand einige Daten verpasst hat. Jedes Ziel muss sie in einer genau definierten Reihenfolge anwenden. In der Regel kann ein solcher Vorgang bei mehreren Zielen lange dauern. Der Empfänger sollte auch in der Lage sein, die fehlenden Teile anzufordern, und natürlich sollte der zentrale Teil auf eine solche Anfrage korrekt reagieren und nur die fehlenden Daten senden.
Als Ergebnis kamen wir zu einer ziemlich interessanten Lösung - wir haben nur eine Unterstützungsschicht, die fixiert ist, nennen wir sie stabil, und nur ein Unterschied dafür ist neu. Jeder aktuelle Wert basiert auf dem zuletzt gebildeten Stall und reicht aus, um die Konfigurationsdaten neu zu erstellen. Sobald ein neuer Neuzugang an seinem Ziel ankommt, wird der alte nicht mehr benötigt.
Es bleibt nur von Zeit zu Zeit, eine neue stabile Konfiguration zu senden, zum Beispiel aufgrund der Tatsache, dass die jüngste zu groß geworden ist. Hierbei ist es auch wichtig, dass wir alle diese Updates im Broadcast- / Multicast-Modus versenden, ohne uns um einzelne Empfänger und deren Fähigkeit, Daten zusammen zu sammeln, Gedanken zu machen. Sobald wir davon überzeugt sind, dass jeder den richtigen Stall hat, senden wir nur neue, aktuelle. Lohnt es sich zu klären, dass dies funktioniert? Es funktioniert. Stable wird auf dem Konfigurationsserver und den Empfängern zwischengespeichert, die letzten werden nach Bedarf erstellt.
Zweistufige Transportarchitektur
Warum haben wir unseren Transport auf zwei Ebenen gebaut? Die Antwort ist ganz einfach: Wir wollten das Routing von der Logik auf hoher Ebene trennen und uns dabei vom OSI-Modell mit seiner Transport- und Anwendungsschicht inspirieren lassen. Wir haben Thrift als Transportprotokoll und das msgpack-Serialisierungsformat für das übergeordnete Kontrollnachrichtenformat verwendet. Aus diesem Grund schaut der Router (der Multicast / Broadcast / Relay ausführt) nicht in msgpack, entpackt nicht und packt den Inhalt nicht zurück und führt nur die Datenübertragung durch.
Thrift (aus dem Englischen - "Thrift", ausgesprochen [θrift]) ist eine Schnittstellenbeschreibungssprache, mit der Dienste für verschiedene Programmiersprachen definiert und erstellt werden. Es ist ein Framework für Remote Procedure Call (RPC). Es kombiniert eine Software-Pipeline mit einer Code-Generierungs-Engine zur Entwicklung von Diensten, die bis zu dem einen oder anderen Grad effizient und einfach zwischen Sprachen arbeiten.Wir haben das Thrift-Framework aufgrund von RPC und Unterstützung für viele Sprachen verwendet. Wie üblich sind Client und Server die einfachen Teile. Der Router erwies sich jedoch als harte Nuss, was teilweise auf das Fehlen einer vorgefertigten Lösung während unserer Entwicklung zurückzuführen war.

Es gibt andere Optionen, wie z. B. protobuf / gRPC. Als wir unser Projekt starteten, war gRPC jedoch noch recht jung und wir wagten es nicht, es an Bord zu nehmen.
Natürlich konnten (und es hat sich gelohnt) unser eigenes Fahrrad zu bauen. Es wäre einfacher, ein Protokoll für das zu erstellen, was wir benötigen, da die Client-Server-Architektur im Vergleich zum Aufbau eines Routers auf Thrift relativ einfach zu implementieren ist. Auf die eine oder andere Weise gibt es eine traditionelle Vorurteilshaltung gegenüber selbstgeschriebenen Protokollen und Implementierungen populärer Bibliotheken (nicht umsonst). Außerdem wirft die Diskussion immer die Frage auf: "Wie werden wir sie auf andere Sprachen portieren?" Deshalb haben wir sofort Ideen über das Fahrrad rausgeschmissen.
Msgpack ist ein Analogon von JSON, aber schneller und weniger. Dies ist ein Binärdatenserialisierungsformat, das den Datenaustausch zwischen mehreren Sprachen ermöglicht.Auf der ersten Ebene haben wir Thrift mit den minimalen Informationen, die der Router benötigt, um die Nachricht weiterzuleiten. Auf der zweiten Ebene befinden sich gepackte msgpack-Strukturen.
Wir haben uns für msgpack entschieden, weil es im Vergleich zu JSON schneller und kompakter ist. Noch wichtiger ist jedoch, dass es benutzerdefinierte Datentypen unterstützt, sodass wir coole Funktionen wie das Übertragen von Roh-Binärdateien oder speziellen Objekten verwenden können, die auf den Mangel an Daten hinweisen, was für unser kürzlich stabiles Schema wichtig war.
JmespathJMESPath ist eine JSON-Anforderungssprache.Genau so sieht die Beschreibung aus, die wir aus der offiziellen JMESPath-Dokumentation erhalten, aber tatsächlich gibt sie viel mehr. Mit JMESPath können Sie Teilbäume in einer beliebigen Baumstruktur suchen und filtern sowie Änderungen im laufenden Betrieb auf Daten anwenden. Außerdem können Sie spezielle Filter und Datenkonvertierungsverfahren hinzufügen. Obwohl es natürlich Gehirnspannung erfordert, um zu verstehen.
JinjaFür einige Verbraucher müssen wir die Konfiguration in eine Datei umwandeln - daher verwenden wir die Template-Engine und Jinja ist die offensichtliche Wahl. Mit seiner Hilfe generieren wir eine Konfigurationsdatei aus der Vorlage und den am Ziel empfangenen Daten.
Zum Generieren der Konfigurationsdatei benötigen wir eine JMESPath-Anforderung, eine Vorlage für den Dateispeicherort im FS, eine Vorlage für die Konfiguration selbst. Auch in diesem Stadium ist es hilfreich, die Dateiberechtigungen zu klären. All dies wurde erfolgreich in einer Datei kombiniert - vor dem Start der Konfigurationsvorlage haben wir den Header in das YAML-Format gestellt, das den Rest beschreibt.
Zum Beispiel:
---
selector: "[@][?@.fft._meta.version == `42`] | items([0].fft_config || `{}`)"
destination_filename: "fft/{{ match[0] }}.json"
file_mode: 0644
reload_daemons: [fft]
...
{{ dict(match[1]) | json(indent=2, sort_keys=True) }}
Um eine Konfigurationsdatei für einen neuen Dienst zu erstellen, fügen wir nur eine neue Vorlagendatei hinzu. Es sind keine Änderungen am Quellcode oder an der Software an den vorhandenen Stellen erforderlich.
Was hat sich seit der Einführung von QControl geändert? Das erste und wichtigste ist die konsistente und zuverlässige Bereitstellung von Konfigurationsaktualisierungen auf allen Knoten im Netzwerk. Die zweite Möglichkeit besteht darin, ein leistungsstarkes Tool zur Überprüfung der Konfiguration zu erhalten und Änderungen daran durch unser Support-Team sowie durch die Verbraucher des Dienstes vorzunehmen.
All dies ist uns mithilfe des zuletzt stabilen Aktualisierungsschemas gelungen, um die Kommunikation zwischen dem Konfigurationsserver und den Konfigurationsempfängern zu vereinfachen. Verwenden eines zweischichtigen Protokolls zur Unterstützung einer inhaltsunabhängigen Datenroutingmethode. Erfolgreiche Integration der Jinja-basierten Konfigurationsgenerierungs-Engine in ein verteiltes Filternetzwerk. Dieses System unterstützt eine Vielzahl von Konfigurationsmethoden für unsere verteilten und vielfältigen Peripheriegeräte.
Vielen Dank für das Schreiben von Material dank
VolanDamrod ,
Gelassenheit ,
NoN .
Englische Version des Beitrags.