
Vor einigen Jahren haben wir bei Badoo begonnen, den MVI-Ansatz für die Android-Entwicklung zu verwenden. Es sollte eine komplexe Codebasis vereinfachen und das Problem falscher Zustände vermeiden: In einfachen Szenarien ist es einfach, aber je komplexer das System ist, desto schwieriger ist es, es in der richtigen Form zu halten und desto leichter ist es, einen Fehler zu übersehen.
In Badoo sind alle Anwendungen asynchron - nicht nur aufgrund der umfangreichen Funktionalität, die dem Benutzer über die Benutzeroberfläche zur Verfügung steht, sondern auch aufgrund der Möglichkeit, dass Einwegdaten vom Server gesendet werden. Bei Verwendung des alten Ansatzes in unserem Chat-Modul stießen wir auf einige seltsame, schwer zu reproduzierende Fehler, für deren Beseitigung wir viel Zeit aufwenden mussten.
Unser Kollege Zsolt Kocsi (
Medium ,
Twitter ) vom Londoner Büro erklärte, wie wir mit MVI unabhängige Komponenten erstellen, die einfach wiederzuverwenden sind, welche Vorteile wir erhalten und welche Nachteile wir bei diesem Ansatz festgestellt haben.
Dies ist der dritte Artikel in einer Reihe von Artikeln über die Badoo Android-Architektur. Links zu den ersten beiden:
- Moderne MVI-Architektur basierend auf Kotlin .
- Aufbau eines reaktiven Komponentensystems mit Kotlin .
Verweilen Sie nicht bei schlecht angeschlossenen Komponenten.
Eine schwache Konnektivität wird als besser als stark angesehen. Wenn Sie sich nur auf Schnittstellen und nicht auf bestimmte Implementierungen verlassen, ist es für Sie einfacher, Komponenten auszutauschen. Es ist einfacher, zu anderen Implementierungen zu wechseln, ohne den größten Teil des Codes neu zu schreiben, was das Einschließen von Komponententests vereinfacht.
Wir enden normalerweise hier und sagen, dass wir alles getan haben, was die Konnektivität betrifft.
Dieser Ansatz ist jedoch nicht optimal. Angenommen, Sie haben eine Klasse A, die die Funktionen von drei anderen Klassen nutzen muss: B, C und D. Selbst wenn Sie über Schnittstellen auf sie verweisen, wird Klasse A mit jeder dieser Klassen schwieriger:
- Er kennt alle Methoden in allen Schnittstellen, ihre Namen und Rückgabetypen, auch wenn er sie nicht verwendet.
- Wenn Sie A testen, müssen Sie mehr Mocks konfigurieren ( Mock-Objekt ).
- Es ist schwieriger, A wiederholt in anderen Kontexten zu verwenden, in denen wir B, C und D nicht haben oder nicht haben wollen.
Natürlich muss genau die Klasse A den dafür erforderlichen Mindestsatz an Schnittstellen bestimmen (Prinzip der Schnittstellentrennung von
SOLID ). In der Praxis mussten wir uns jedoch alle mit Situationen befassen, in denen der Einfachheit halber ein anderer Ansatz gewählt wurde: Wir haben eine vorhandene Klasse verwendet, die einige Funktionen implementiert, alle öffentlichen Methoden in die Schnittstelle extrahiert und diese Schnittstelle dann dort verwendet, wo die erwähnte Klasse benötigt wurde. Das heißt, die Schnittstelle wurde nicht auf der Grundlage dessen verwendet, was diese Komponente benötigt, sondern auf der Grundlage dessen, was eine andere Komponente bieten kann.
Mit diesem Ansatz verschlechtert sich die Situation im Laufe der Zeit. Jedes Mal, wenn wir neue Funktionen hinzufügen, werden unsere Klassen in einem Netz neuer Schnittstellen verknüpft, über die sie Bescheid wissen müssen. Die Klassen werden immer größer und das Testen wird immer schwieriger.
Wenn Sie sie in einem anderen Kontext verwenden müssen, ist es daher fast unmöglich, sie ohne all dieses Gewirr, mit dem sie verbunden sind, zu verschieben, selbst über Schnittstellen. Sie können eine Analogie ziehen: Sie möchten eine Banane verwenden, die sich in den Händen eines Affen befindet, der an einem Baum hängt. Wenn Sie also die Banane beladen, erhalten Sie ein ganzes Stück des Dschungels. Kurz gesagt, der Übertragungsprozess nimmt viel Zeit in Anspruch, und bald fragen Sie sich, warum es in der Praxis so schwierig ist, den Code wiederzuverwenden.
Black-Box-Komponenten
Wenn die Komponente einfach und wiederverwendbar sein soll, müssen wir dazu nicht zwei Dinge wissen:
- darüber, wo es sonst verwendet wird;
- über andere Komponenten, die nicht mit der internen Implementierung zusammenhängen.
Der Grund ist klar: Wenn Sie nichts über die Außenwelt wissen, werden Sie nicht mit ihr verbunden sein.
Was wir wirklich von der Komponente wollen:
- Definieren Sie Ihre eigenen Eingabe- (Eingabe) und Ausgabedaten (Ausgabe).
- Denken Sie nicht darüber nach, woher diese Daten stammen oder wohin sie gehen.
- Es muss autark sein, damit wir die interne Struktur der Komponente für ihre Verwendung nicht kennen müssen.
Sie können die Komponente als Black Box oder integrierte Schaltung betrachten. Sie hat Eingangs- und Ausgangskontakte. Sie löten sie - und die Mikroschaltung wird Teil eines Systems, von dem sie nichts weiß.

Bisher wurde angenommen, dass es sich um bidirektionale Datenströme handelt: Wenn Klasse A etwas benötigt, extrahiert sie eine Methode über die Schnittstelle B und empfängt das Ergebnis in Form des von der Funktion zurückgegebenen Werts.

Aber dann weiß A über B Bescheid und wir wollen dies vermeiden.
Natürlich ist ein solches Schema für Implementierungsfunktionen auf niedriger Ebene sinnvoll. Wenn wir jedoch eine wiederverwendbare Komponente benötigen, die wie eine in sich geschlossene Black Box funktioniert, müssen wir sicherstellen, dass sie nichts über externe Schnittstellen, Methodennamen oder Rückgabewerte weiß.
Wir gehen zur Unidirektionalität über
Aber ohne Schnittstellennamen und Methoden können wir nichts aufrufen! Alles, was bleibt, ist die Verwendung eines unidirektionalen Datenstroms, in dem wir einfach Eingaben erhalten und Ausgaben generieren:

Auf den ersten Blick mag dies wie eine Einschränkung aussehen, aber eine solche Lösung hat viele Vorteile, auf die weiter unten eingegangen wird.
Aus dem
ersten Artikel wissen wir, dass Features (Feature) ihre eigenen Eingabedaten (Wish) und ihre eigenen Ausgabedaten (State) definieren. Daher spielt es für sie keine Rolle, woher der Wunsch kommt oder wohin der Staat geht.
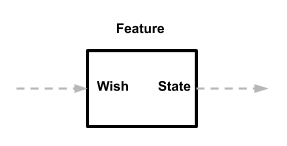
Das brauchen wir! Features können überall dort verwendet werden, wo Sie sie eingeben können, und mit der Ausgabe können Sie tun, was Sie wollen. Und da Funktionen nicht direkt mit anderen Komponenten kommunizieren, handelt es sich um eigenständige und nicht verwandte Module.
Nehmen Sie nun die Ansicht und gestalten Sie sie so, dass sie auch ein eigenständiges Modul ist.
Erstens sollte die Ansicht so einfach wie möglich sein, damit sie nur ihre internen Aufgaben ausführen kann.
Welche Art von Aufgaben? Es gibt zwei davon:
- Rendern von ViewModel (Eingabe);
- Auslösen von ViewEvents abhängig von Benutzeraktionen (Ausgabe).
Warum ViewModel verwenden? Warum nicht direkt den Status des Features zeichnen?
- Das (Nicht-) Anzeigen einer Funktion auf dem Bildschirm ist nicht Teil der Implementierung. View sollte sich selbst rendern können, wenn die Daten aus mehreren Quellen stammen.
- Die Komplexität des Status in der Ansicht muss nicht berücksichtigt werden. Das ViewModel sollte nur die anzeigefertigen Informationen enthalten, die erforderlich sind, um es einfach zu halten.
View sollte sich auch nicht für Folgendes interessieren:
- Woher kommen all diese ViewModels?
- Was passiert, wenn das ViewEvent ausgelöst wird?
- jede Geschäftslogik;
- analytisches Tracking;
- Journaling
- andere Aufgaben.
All dies sind externe Aufgaben, und View sollte nicht mit ihnen verbunden sein. Lassen Sie uns anhalten und die Einfachheit der Ansicht zusammenfassen:
interface FooView : Consumer<ViewModel>, ObservableSource<Event> { data class ViewModel( val title: String, val bgColor: Int ) sealed class Event { object ButtonClicked : Event() data class TextFocusChanged(val hasFocus: Boolean) : Event() } }
Eine Android-Implementierung sollte:
- Finden Sie Android-Ansichten anhand ihrer ID.
- Implementieren Sie die accept-Methode der Consumer-Schnittstelle, indem Sie den Wert im ViewModel festlegen.
- Stellen Sie Listener (ClickListener) so ein, dass sie mit der Benutzeroberfläche interagieren, um bestimmte Ereignisse zu generieren.
Ein Beispiel:
class FooViewImpl @JvmOverloads constructor( context: Context, attrs: AttributeSet? = null, defStyle: Int = 0, private val events: PublishRelay<Event> = PublishRelay.create<Event>() ) : LinearLayout(context, attrs, defStyle), FooView,
Wenn nicht auf Funktion und Ansicht beschränkt, sieht jede andere Komponente mit diesem Ansatz folgendermaßen aus:
interface GenericBlackBoxComponent : Consumer<Input>, ObservableSource<Output> { sealed class Input sealed class Output }
Jetzt ist alles klar mit dem Muster!

Vereinigt euch, vereint euch, vereint euch!
Aber was ist, wenn wir unterschiedliche Komponenten haben und jede ihre eigene Eingabe und Ausgabe hat? Wir werden sie verbinden!
Glücklicherweise kann dies leicht mit Hilfe von Binder durchgeführt werden, was auch dazu beiträgt, den richtigen Bereich zu erstellen, wie wir aus dem
zweiten Artikel wissen:
Der erste Vorteil: einfach ohne Änderungen zu erweitern
Durch die Verwendung nicht verwandter Komponenten in Form von Blackboxes, die nur vorübergehend verbunden sind, können wir neue Funktionen hinzufügen, ohne vorhandene Komponenten zu ändern.
Nehmen Sie ein einfaches Beispiel:

Hier werden Features (F) und View (V) einfach miteinander verbunden.
Die entsprechenden Bindungen sind:
bind(feature to view using stateToViewModelTransformer) bind(view to feature using uiEventToWishTransformer)
Angenommen, wir möchten diesem System die Verfolgung einiger UI-Ereignisse hinzufügen.
internal object AnalyticsTracker : Consumer<AnalyticsTracker.Event> { sealed class Event { object ProfileImageClicked: Event() object EditButtonClicked : Event() } override fun accept(event: AnalyticsTracker.Event) {
Die gute Nachricht ist, dass wir dies einfach tun können, indem wir den vorhandenen Ausgabeansichtskanal wiederverwenden:

Im Code sieht es so aus:
bind(feature to view using stateToViewModelTransformer) bind(view to feature using uiEventToWishTransformer)
Neue Funktionen können mit nur einer zusätzlichen Bindungszeile hinzugefügt werden. Jetzt können wir nicht nur eine einzelne Codezeile nicht ändern, sondern wissen auch nicht, dass die Ausgabe zur Lösung eines neuen Problems verwendet wird.
Jetzt fällt es uns natürlich leichter, zusätzliche Sorgen und unnötig komplizierte Komponenten zu vermeiden. Sie bleiben einfach. Sie können dem System Funktionen hinzufügen, indem Sie einfach Komponenten mit vorhandenen verbinden.
Zweiter Vorteil: einfach wiederholt zu bedienen
Am Beispiel von Feature und Ansicht ist deutlich zu erkennen, dass wir mit nur einer Zeile mit Bindung eine neue Eingabequelle oder einen neuen Konsumenten von Ausgabedaten hinzufügen können. Dies erleichtert die Wiederverwendung von Komponenten in verschiedenen Teilen der Anwendung erheblich.
Dieser Ansatz ist jedoch nicht auf Klassen beschränkt. Diese Art der Verwendung von Schnittstellen ermöglicht es uns, in sich geschlossene reaktive Komponenten jeder Größe zu beschreiben.
Indem wir uns auf bestimmte Eingabe- und Ausgabedaten beschränken, müssen wir nicht mehr wissen, wie alles unter der Haube funktioniert, und vermeiden daher leicht, versehentlich die Interna von Komponenten mit anderen Teilen des Systems zu verknüpfen. Und ohne Bindung können Sie Komponenten einfach und einfach wiederholt verwenden.
Wir werden in einem der folgenden Artikel darauf zurückkommen und Beispiele für die Verwendung dieser Technik zum Verbinden übergeordneter Komponenten betrachten.
Erste Frage: Wo sollen die Bindungen platziert werden?
- Wählen Sie die Abstraktionsebene. Abhängig von der Architektur kann dies eine Aktivität, ein Fragment oder ein ViewController sein. Ich hoffe, Sie haben noch eine gewisse Abstraktionsebene in den Teilen, in denen es keine Benutzeroberfläche gibt. Zum Beispiel in einigen Bereichen des DI-Kontextbaums.
- Erstellen Sie eine separate Klasse für die Bindung auf derselben Ebene wie dieser Teil der Benutzeroberfläche. Wenn es sich um FooActivity, FooFragment oder FooViewController handelt, können Sie FooBindings daneben platzieren.
- Stellen Sie sicher, dass Sie FooBindings in dieselben Komponenteninstanzen einbetten, die Sie in der Aktivität, im Fragment usw. verwenden.
- Verwenden Sie die Aktivität oder den Fragmentlebenszyklus, um den Umfang der Bindungen zu bestimmen. Wenn diese Schleife nicht an Android gebunden ist, können Sie Trigger manuell erstellen, z. B. beim Erstellen oder Zerstören eines DI-Bereichs. Weitere Beispiele für den Umfang sind im zweiten Artikel beschrieben .
Zweite Frage: Testen
Da unsere Komponente nichts über andere weiß, benötigen wir normalerweise keine Stubs. Die Tests werden vereinfacht, um die korrekte Reaktion der Komponente auf die Eingabedaten zu überprüfen und die erwarteten Ergebnisse zu erzielen.
Im Fall von Feature bedeutet dies:
- die Fähigkeit zu testen, ob bestimmte Eingabedaten den erwarteten Zustand (Ausgabe) erzeugen.
Und im Fall von View:
- Wir können testen, ob ein bestimmtes ViewModel (Eingabe) zum erwarteten Status der Benutzeroberfläche führt.
- Wir können testen, ob die Simulation der Interaktion mit der Benutzeroberfläche zu einer Initialisierung im erwarteten ViewEvent (Ausgabe) führt.
Natürlich verschwinden Wechselwirkungen zwischen Komponenten nicht auf magische Weise. Wir haben diese Aufgaben gerade aus den Komponenten selbst extrahiert. Sie müssen noch getestet werden. Aber wo?
In unserem Fall sind Bindemittel für den Anschluss der Komponenten verantwortlich:
Unsere Tests sollten Folgendes bestätigen:
1. Transformatoren (Mapper).
Einige Verbindungen haben Mapper, und Sie müssen sicherstellen, dass sie Elemente korrekt konvertieren. In den meisten Fällen reicht hierfür ein sehr einfacher Unit-Test aus, da die Mapper meist auch sehr einfach sind:
@Test fun testCase1() { val transformer = Transformer() val testInput = TODO() val actualOutput = transformer.invoke(testInput) val expectedOutput = TODO() assertEquals(expectedOutput, actualOutput) }
2. Kommunikation.
Sie müssen sicherstellen, dass die Verbindungen korrekt konfiguriert sind. Was ist der Sinn der Arbeit einzelner Komponenten und Mapper, wenn aus irgendeinem Grund die Verbindung zwischen ihnen nicht hergestellt wurde? All dies kann getestet werden, indem die Bindungsumgebung mit Stubs, Initialisierungsquellen eingerichtet und überprüft wird, ob die erwarteten Ergebnisse auf der Clientseite empfangen werden:
class BindingEnvironmentTest { lateinit var component1: ObservableSource<Component1.Output> lateinit var component2: Consumer<Component2.Input> lateinit var bindings: BindingEnvironment @Before fun setUp() { val component1 = PublishRelay.create() val component2 = mock() val bindings = BindingEnvironment(component1, component2) } @Test fun testBindings() { val simulatedOutputOnLeftSide = TODO() val expectedInputOnRightSide = TODO() component1.accept(simulatedOutputOnLeftSide) verify(component2).accept(expectedInputOnRightSide) } }
Und obwohl Sie zum Testen ungefähr die gleiche Menge an Code schreiben müssen wie bei anderen Ansätzen, erleichtern autarke Komponenten das Testen einzelner Teile, da die Aufgaben klar voneinander getrennt sind.
Denkanstöße
Obwohl die Beschreibung unseres Systems in Form eines Diagramms von Black Boxes für das allgemeine Verständnis gut ist, funktioniert dies nur, solange die Größe des Systems relativ klein ist.
Fünf bis acht Bindungslinien sind akzeptabel. Aber wenn man mehr verbunden hat, wird es ziemlich schwierig sein zu verstehen, was passiert:
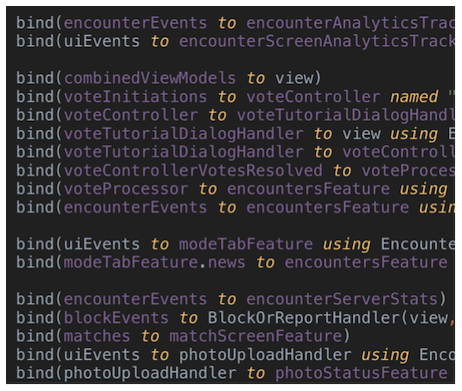

Wir wurden mit der Tatsache konfrontiert, dass mit zunehmender Anzahl von Links (es gab sogar mehr als im vorgestellten Codefragment) die Situation noch komplizierter wurde. Der Grund lag nicht nur in der Anzahl der Zeilen - eine Art von Bindungen konnte für verschiedene Methoden gruppiert und extrahiert werden -, sondern auch darin, dass es immer schwieriger wurde, alles im Blick zu behalten. Und das ist immer ein schlechtes Zeichen. Befinden sich Dutzende verschiedener Komponenten auf derselben Ebene, können sich nicht alle möglichen Wechselwirkungen vorstellen.
Der Grund ist die Verwendung von Komponenten - Black Boxes oder etwas anderes?
Wenn der von Ihnen beschriebene Bereich anfangs komplex ist, werden Sie durch keinen Ansatz vor dem genannten Problem bewahrt, bis Sie das System in kleinere Teile aufteilen. Es wird auch ohne eine riesige Liste von Bindungen kompliziert sein, es wird einfach nicht so offensichtlich sein. Darüber hinaus ist es viel besser, wenn die Komplexität explizit ausgedrückt und nicht verborgen wird. Es ist besser, eine wachsende Liste einzeiliger Verknüpfungen zu sehen, die Sie daran erinnert, wie viele separate Komponenten Sie haben, als nicht über die Links zu wissen, die in Klassen in verschiedenen Methodenaufrufen versteckt sind.
Da die Komponenten selbst einfach sind (sie sind Black Boxes und zusätzliche Prozesse fließen nicht in sie ein), ist es einfacher, sie zu trennen, was bedeutet, dass dies ein Schritt in die richtige Richtung ist. Wir haben die Schwierigkeit an einen Ort verschoben - auf die Liste der Bindungen, mit einem Blick können wir die allgemeine Situation bewerten und darüber nachdenken, wie wir aus diesem Chaos herauskommen können.
Die Suche nach einer Lösung hat viel Zeit in Anspruch genommen und dauert noch an. Wir planen, in den folgenden Artikeln darüber zu sprechen, wie dieses Problem gelöst werden kann. Bleib in Kontakt!