Mein Name ist Oleg Ermakov, ich arbeite im Backend-Entwicklungsteam der Yandex.Taxi-Anwendung. Es ist üblich, dass wir täglich Stand-Ups durchführen, bei denen jeder von uns über die Aufgaben spricht, die während des Tages erledigt werden. So passiert es ...
Die Namen der Mitarbeiter können sich ändern, aber die Aufgaben sind sehr real!Um 12:45 Uhr versammelt sich das gesamte Team im Besprechungsraum. Das erste Wort stammt von Ivan, einem angehenden Entwickler.
Ivan:
Ich arbeitete an der Aufgabe, alle möglichen Optionen für die Beträge anzuzeigen, die der Passagier dem Fahrer zu bekannten Reisekosten geben konnte. Die Aufgabe ist bekannt - sie heißt "Wechsel der Münzen". Unter Berücksichtigung der Besonderheiten fügte er dem Algorithmus mehrere Optimierungen hinzu. Ich habe die Poolanfrage für die Überprüfung vorgestern gestellt, aber seitdem habe ich die Kommentare korrigiert.
Durch Annas zufriedenes Lächeln wurde klar, wessen Bemerkungen Ivan korrigiert.
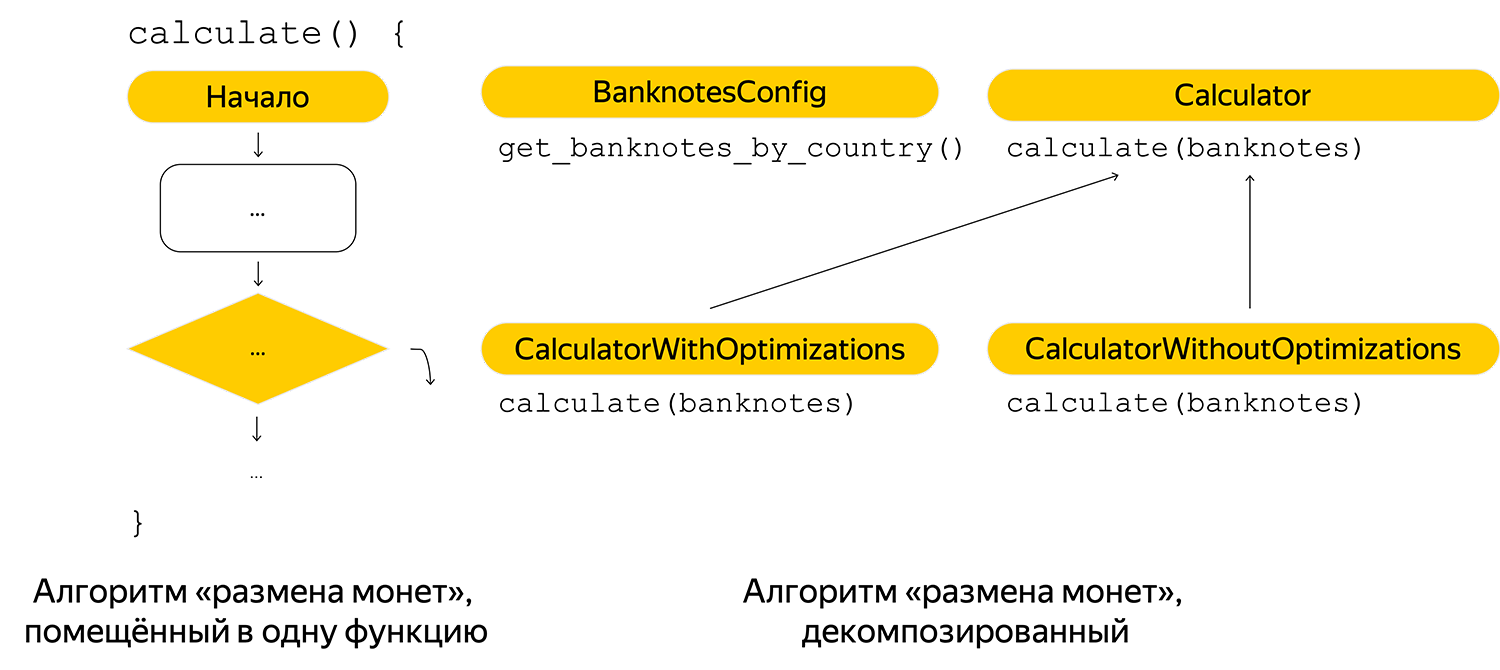
Zunächst nahm er die minimale Zerlegung des Algorithmus vor und erhielt geschickt Banknoten. In der ersten Implementierung wurden mögliche Banknoten im Code registriert, daher wurden sie nach Ländern in die Konfiguration übernommen.
Kommentare für die Zukunft hinzugefügt, damit jeder Leser den Algorithmus schnell herausfinden kann:
for exception in self.exceptions[banknote]: exc_value = value + exception.delta if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value)
Natürlich habe ich den Rest der Zeit damit verbracht, den gesamten Code mit Tests abzudecken.
RUB = [1, 2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000] CUSTOM_BANKNOTES = [1, 3, 7, 11] @pytest.mark.parametrize( 'cost, banknotes, expected_changes', [
Zusätzlich zu den üblichen Tests, die bei jedem Build des Projekts ausgeführt werden, hat er einen Test geschrieben, der einen Algorithmus ohne Optimierungen verwendet (betrachten Sie ihn als vollständigen Fehlschlag). Das Ergebnis dieses Algorithmus für jede Rechnung aus den ersten 10 Tausend Fällen wurde in eine Datei geschrieben und separat auf dem Algorithmus mit Optimierungen ausgeführt, um sicherzustellen, dass er wirklich richtig funktioniert.
Nehmen wir uns einen Moment Zeit, um vom Aufstehen abzulenken und die lokalen Ergebnisse von allem, was Ivan sagt, zusammenzufassen. Beim Schreiben von Code besteht das Hauptziel darin, dessen Leistung sicherzustellen. Um dieses Ziel zu erreichen, müssen Sie die folgenden Aufgaben ausführen:
- Zerlegen Sie die Geschäftslogik in atomare Fragmente. Die Lesbarkeit ist kompliziert, wenn eine Zeichenfläche angezeigt wird, die in einer Funktion geschrieben wurde.
- Fügen Sie den "besonders komplexen" Teilen des Codes Kommentare hinzu. Unser Team verfolgt den folgenden Ansatz: Wenn Sie eine Frage zur Implementierung der Codeüberprüfung erhalten (um den Algorithmus zu erläutern), müssen Sie einen Kommentar hinzufügen. Besser noch, denken Sie im Voraus darüber nach und fügen Sie es selbst hinzu.
- Schreiben Sie Tests, die die Hauptzweige der Algorithmusausführung abdecken. Tests sind nicht nur eine Methode zur Überprüfung des Codezustands. Sie dienen weiterhin als Beispiel für die Verwendung Ihres Moduls.
Leider verwenden selbst Spezialisten mit langjähriger Erfahrung diese Ansätze nicht immer in ihrer Arbeit. An
der Backend-Entwicklungsschule , die wir gerade durchführen, erwerben die Schüler praktische Fähigkeiten beim Schreiben von architektonisch hochwertigem Code. Unser anderes Ziel ist die Verbreitung von Testabdeckungspraktiken für das Projekt.
Aber zurück zum Aufstehen. Nach Ivan spricht Anna.
Anna:
Ich entwickle einen Microservice für die Rückgabe von Werbebildern. Wie Sie sich erinnern, gab der Dienst zunächst statische Datenstubs aus. Dann haben die Tester darum gebeten, sie anzupassen, und ich habe sie in die Konfiguration eingefügt. Jetzt mache ich eine „ehrliche“ Implementierung mit der Rückgabe von Daten aus der Datenbank (PostgreSQL 10.9). Die ursprünglich festgelegte Zerlegung hat mir sehr geholfen, in deren Rahmen sich die Schnittstelle zum Empfangen von Daten in der Geschäftslogik nicht ändert und jede neue Quelle (ob es sich um eine Konfiguration, eine Datenbank oder einen externen Mikrodienst handelt) nur ihre eigene Logik implementiert.

Ich habe das geschriebene System unter Last überprüft. Tests haben gezeigt, dass der Griff stark bremst, wenn wir zur Datenbank gehen. Laut erklär habe ich gesehen, dass der Index nicht verwendet wird. Bis ich herausgefunden habe, wie ich das beheben kann.
Vadim:
Und welche Art von Anfrage?
Anya:
Zwei Bedingungen unter OP:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val' OR table_1.attr2 IN ('val1', 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
Die Abfrage EXPLAIN zeigte, dass keiner der Indizes für die Attribute attr1 von table_2 und attr2 von table_1 verwendet wird.
Vadim:
Angesichts eines ähnlichen Verhaltens in MySQL liegt das Problem genau in der Bedingung für OR, aufgrund derer nur ein Index verwendet wird, z. B. attr2. Und die zweite Bedingung verwendet seq scan - einen vollständigen Durchlauf durch die Tabelle. Die Anfrage kann in zwei unabhängige Anfragen unterteilt werden. Teilen und frieren Sie optional das Abfrageergebnis auf der Backend-Seite ein. Aber dann müssen Sie darüber nachdenken, diese beiden Anforderungen in eine Transaktion einzubinden oder sie mit UNION zu kombinieren - und zwar auf der Basisseite:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val') AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_1.attr2 IN ('val1' , 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
Anya:
Danke, ich werde es versuchen ^ _ ^
Um es noch einmal zusammenzufassen:
- Fast alle Produktentwicklungsaufgaben beziehen sich auf das Abrufen von Aufzeichnungen aus externen Quellen (Diensten oder Datenbanken). Sie müssen das Problem der Zerlegung von Klassen, die Daten entladen, sorgfältig angehen. Mit richtig gestalteten Klassen können Sie problemlos Tests schreiben und Datenquellen ändern.
- Um effektiv mit der Datenbank arbeiten zu können, müssen Sie die Funktionen der Abfrageausführung kennen, z. B. EXPLAIN verstehen.
Das Arbeiten mit Informationen und das Organisieren von Datenflüssen ist ein wesentlicher Bestandteil der Aufgaben eines jeden Backend-Entwicklers. Die Schule wird die Architektur der Interaktion von Diensten (und Datenquellen) vorstellen. Die Studierenden lernen, architektonisch und betrieblich mit Datenbanken zu arbeiten - Datenmigration und -tests.
Der letzte, der spricht, ist Vadim.
Vadim:
Ich war eine Woche im Dienst und habe die Abfolge der Vorfälle geklärt. Ein lächerlicher Fehler im Code hat sehr lange gedauert: Es gab keine Protokolle auf Anfrage im Produkt, obwohl ihre Erstellung im Code geschrieben wurde.
Durch das traurige Schweigen aller Anwesenden ist klar - jeder war schon irgendwie mit dem Problem konfrontiert .
Um alle Protokolle als Teil der Anforderung abzurufen, wird request_id verwendet, die in der folgenden Form in alle Datensätze geworfen wird:
log_extra ist ein Wörterbuch mit Metainformationen der Anforderung, deren Schlüssel und Werte in das Protokoll geschrieben werden. Ohne die Übergabe von log_extra an die Protokollierungsfunktion wird der Datensatz nicht allen anderen Protokollen zugeordnet, da er keine request_id enthält.
Ich musste den Fehler im Service beheben, ihn erneut ausrollen und mich erst dann mit dem Vorfall befassen. Dies ist nicht das erste Mal, dass dies passiert ist. Um dies zu verhindern, habe ich versucht, das Problem global zu beheben und log_extra zu entfernen.
Zuerst habe ich einen Wrapper über die Standardausführung der Anfrage geschrieben:
async def handle(self, request, handler): log_extra = request['log_extra'] log_extra_manager.set_log_extra(log_extra) return await handler(request)
Es musste entschieden werden, wie log_extra in einer einzelnen Anforderung gespeichert werden soll. Es gab zwei Möglichkeiten. Die erste besteht darin, task_factory für eventloop von asyncio zu ändern:
class LogExtraManager: __init__(self, context: Any, settings: typing.Optional[Dict[str, dict]], activations_parameters: list) -> None: loop = asyncio.get_event_loop() task_factory = loop.get_task_factory() if task_factory is None: task_factory = _default_task_factory @functools.wraps(task_factory) def log_extrad_factory(ev_loop, coro): child_task = task_factory(ev_loop, coro) parent_task = asyncio.Task.current_task(loop=ev_loop) log_extra = getattr(parent_task, LOG_EXTRA_CONTEXT_KEY, None) setattr(child_task, LOG_EXTRA_CONTEXT_KEY, log_extra) return child_task
Die zweite Option besteht darin, den Übergang zu Python 3.7 über den Infrastrukturbefehl zu "pushen", um Kontextvars zu verwenden:
log_extra_var = contextvars.ContextVar(LOG_EXTRA_CONTEXT_KEY) class LogExtraManager: def set_log_extra(log_extra: dict): log_extra_var.set(log_extra)
Nun und weiter war es notwendig, im Kontext von log_extra im Logger gespeichert weiterzuleiten.
class LogExtraFactory(logging.LogRecord):
Zusammenfassung:
- In Yandex.Taxi (und überall in Yandex) wird Asyncio aktiv verwendet. Es ist wichtig, es nicht nur nutzen zu können, sondern auch seine interne Struktur zu verstehen.
- Entwickeln Sie die Gewohnheit, die Änderungsprotokolle aller neuen Versionen der Sprache zu lesen, und überlegen Sie, wie Sie sich und Ihren Kollegen mithilfe von Innovationen das Leben erleichtern können.
- Haben Sie bei der Arbeit mit Standardbibliotheken keine Angst, in den Quellcode zu kriechen und das Gerät zu verstehen. Dies ist eine sehr nützliche Fähigkeit, mit der Sie die Funktionsweise des Moduls besser verstehen und neue Möglichkeiten bei der Implementierung von Funktionen eröffnen können.
Die Backend-Schullehrer aßen mehr als ein
Pfund Salz und füllten viele Zapfen im asynchronen Betrieb von Diensten. Sie werden die Schüler über die Funktionen der asynchronen Operation von Python informieren - sowohl auf praktischer Ebene als auch bei der Analyse von Paketinternalen.
Bücher und Links
Das Erlernen von Python kann Ihnen helfen:
- Drei Bücher: Python Cookbook , Diving Into Python 3 und Python Tricks .
- Videovorträge von Säulen der IT-Branche wie Raymond Hettinger und David Beasley. Aus den Videovorträgen des ersten kann der Bericht „Beyond PEP 8 - Best Practices für schönen verständlichen Code“ unterschieden werden. Beasley rät Ihnen, sich eine Aufführung über Asyncio anzusehen.
Lesen Sie die Bücher, um ein besseres Verständnis der Architektur zu erlangen:
- "Hoch geladene Anwendungen . " Hier werden die Probleme der Interaktion mit Daten ausführlich beschrieben (Datencodierung, Arbeiten mit verteilten Daten, Replikation, Partitionierung, Transaktionen usw.).
- „Microservices. Entwicklungs- und Refactoring-Muster . “ Das Buch zeigt die grundlegenden Ansätze der Microservice-Architektur und beschreibt die Mängel und Probleme, mit denen man beim Wechsel von einem Monolithen zu Microservices konfrontiert ist. Es gibt fast nichts in der Post über sie, aber ich rate Ihnen trotzdem, dieses Buch zu lesen. Sie werden beginnen, die Trends in Gebäudearchitekturen zu verstehen und die grundlegenden Praktiken der Code-Zerlegung zu lernen.
Eine weitere der wichtigsten Fähigkeiten, die Sie endlos in sich selbst entwickeln können, ist das Lesen des Codes eines anderen. Wenn Sie plötzlich feststellen, dass Sie selten den Code eines anderen lesen, empfehle ich Ihnen, die Gewohnheit zu entwickeln, regelmäßig neue beliebte
Repositories anzusehen .
Das Aufstehen endete, alle gingen zur Arbeit.