 Bild: Pexels
Bild: PexelsFür E-Commerce-Aggregator-Websites ist es wichtig, die Informationen auf dem neuesten Stand zu halten. Andernfalls verschwindet ihr Hauptvorteil - die Fähigkeit, die relevantesten Daten an einem Ort zu sehen.
Um dieses Problem zu lösen, müssen Sie die Web-Scraping-Technik verwenden. Dies bedeutet, dass spezielle Software erstellt wird - der Crawler, der die erforderlichen Sites aus der Liste umgeht, Informationen von ihnen analysiert und auf die Aggregator-Site hochlädt.
Das Problem ist, dass die Eigentümer der Websites, von denen diese Aggregatoren Daten beziehen, ihnen häufig keinen so einfachen Zugriff gewähren möchten. Dies kann verstanden werden - wenn die Preisinformationen im Online-Shop auf die Website des Aggregators gelangen und höher sind als die der dort präsentierten Wettbewerber, verliert das Unternehmen Kunden.
Anti-Scraping-Methoden
Daher lehnen die Eigentümer solcher Websites häufig das Scraping ab, dh das Herunterladen ihrer Daten. Sie können Anforderungen identifizieren, die Crawler-Bots anhand der IP-Adresse senden. Typischerweise verwendet eine solche Software die sogenannte Server-IP, die einfach zu berechnen und zu blockieren ist.
Anstatt Anforderungen zu blockieren, wird häufig eine andere Methode verwendet - den erkannten Bots werden irrelevante Informationen angezeigt. Zum Beispiel überschätzen oder unterschätzen sie den Preis von Waren oder ändern ihre Beschreibungen.
Ein Beispiel, das in diesem Zusammenhang häufig angeführt wird, ist der Flugpreis. In der Tat können Fluggesellschaften und Reisebüros je nach IP-Adresse häufig unterschiedliche Ergebnisse für dieselben Flüge anzeigen. Der eigentliche Fall: Eine Flugsuche von Miami nach London am selben Tag von einer IP-Adresse in Osteuropa und Asien liefert unterschiedliche Ergebnisse.
Bei einer IP-Adresse in Osteuropa sieht der Preis folgendermaßen aus:

Und für eine IP-Adresse aus Asien wie diese:
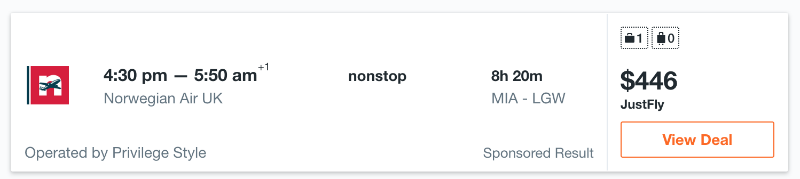
Wie Sie sehen können, ist der Preis für denselben Flug erheblich unterschiedlich - der Unterschied beträgt 76 US-Dollar, was wirklich sehr viel ist. Für eine Aggregator-Site gibt es nichts Schlimmeres als diese - wenn falsche Informationen darauf angezeigt werden, werden Benutzer sie nicht verwenden. Wenn ein bestimmtes Produkt auf dem Aggregator denselben Preis hat und sich auf der Website des Verkäufers ändert, ändert sich dies ebenfalls. Dies wirkt sich auch negativ auf die Reputation des Projekts aus.
Lösung: Verwenden Sie residente Proxys
Sie können Probleme vermeiden, wenn Sie Daten für residente Proxys für die Anforderungen ihrer Aggregation verschrotten. Server-IPs werden von Hosting-Anbietern bereitgestellt. Das Identifizieren der Adresse, die zum Pool eines bestimmten Anbieters gehört, ist recht einfach - jede IP hat eine ASN-Nummer, die diese Informationen enthält.
Es gibt viele Dienste zum Analysieren von ASN-Nummern. Oft integrieren sie sich in Anti-Bot-Systeme, die den Zugriff auf die Crawler blockieren oder die als Antwort auf ihre Anforderungen zurückgegebenen Daten jonglieren.
Residente IP-Adressen helfen dabei, solche Systeme zu umgehen. Solche IP-Anbieter geben an Hausbesitzer mit entsprechenden Markierungen in allen zugehörigen Datenbanken aus. Es gibt spezielle Dienste für gebietsansässige Proxys, mit denen Sie gebietsansässige Adressen verwenden können.
Infatica ist so ein Service.
Anforderungen, die Crawler von Aggregator-Sites von residenten IPs senden, scheinen von regulären Benutzern aus einer bestimmten Region zu stammen. Und niemand blockiert normale Besucher - bei Online-Shops sind dies potenzielle Kunden.
Die Verwendung von gedrehten Proxys von Infatica ermöglicht es Aggregator-Sites, garantiert genaue Daten zu erhalten und Blockaden und Schwierigkeiten beim Parsen zu vermeiden.
Weitere Artikel zur Verwendung gebietsansässiger Stimmrechtsvertreter für Unternehmen: