Zeitreihendaten oder Zeitreihen sind Daten, die sich im Laufe der Zeit ändern. Währungskurse, Telemetrie von Transportbewegungen, Statistiken des Serverzugriffs oder der CPU-Auslastung sind Zeitreihendaten. Zum Speichern sind spezielle Tools erforderlich - temporäre Datenbanken. Es gibt Dutzende von Tools, zum Beispiel InfluxDB oder ClickHouse. Aber auch die besten Zeitreihen-Speicherlösungen haben Nachteile. Alle Zeitreihenspeicher sind auf niedrigem Niveau und nur für Zeitreihendaten geeignet. Das Ausführen und Injizieren in den aktuellen Stapel ist teuer und schmerzhaft.

Wenn Sie jedoch einen PostgreSQL-Stack haben, können Sie InfluxDB und alle anderen temporären Datenbanken vergessen. Installieren Sie zwei Erweiterungen, TimescaleDB und PipelineDB, und speichern, verarbeiten und analysieren Sie Zeitreihendaten direkt im PostgreSQL-Ökosystem. Ohne die Einführung von Lösungen von Drittanbietern, ohne die Nachteile von Zeitspeichern und ohne die Probleme, diese einzuführen. Was sind diese Erweiterungen, was sind ihre Vorteile und Fähigkeiten, wird
Ivan Muratov ( binakot ) - dem Leiter der Entwicklungsabteilung in der "First Monitoring Company" - sagen.
Was sind Zeitreihendaten oder Zeitreihen?
Dies sind Daten über den Prozess, die an verschiedenen Punkten in seinem Leben gesammelt werden.
Zum Beispiel der Standort des Autos: Geschwindigkeit, Koordinaten, Richtung oder die Verwendung von Ressourcen auf dem Server mit Daten zur Belastung der CPU, verwendetem RAM und freiem Speicherplatz.
Zeitreihen haben mehrere Funktionen.
- In einem Befestigungsgurt . Jeder Zeitreihendatensatz enthält ein Feld mit einem Zeitstempel, in dem der Wert aufgezeichnet wurde.
- Die Eigenschaften des Prozesses, die als Ebenen der Serie bezeichnet werden : Geschwindigkeit, Koordinaten, Lastdaten.
- Fast immer arbeiten sie mit solchen Daten im Nur-Anhängen-Modus . Dies bedeutet, dass die neuen Daten die alten nicht ersetzen. Es werden nur veraltete Daten gelöscht.
- Einträge werden nicht getrennt voneinander betrachtet . Daten werden nur gemeinsam für Zeitfenster, Intervalle oder Zeiträume verwendet.
Beliebte Speicherlösungen
Die Grafik, die ich von
db-engines.com aufgenommen habe, zeigt die Beliebtheit verschiedener Speichermodelle in den letzten zwei Jahren.
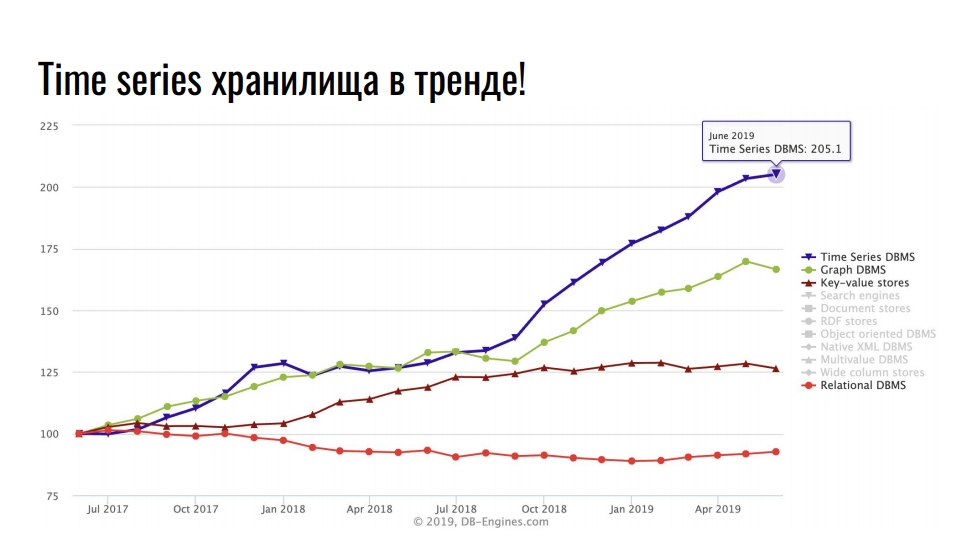
Die führende Position nehmen Zeitreihenspeicher ein, zweitens - Graphendatenbanken, dann - Schlüsselwert- und relationale Datenbanken. Die Popularität spezialisierter Repositories ist mit einem intensiven Wachstum bei der Integration von Informationstechnologien verbunden: Big Data, soziale Netzwerke, IoT, Überwachung der Hochlastinfrastruktur. Neben nützlichen Geschäftsdaten beanspruchen auch Protokolle und Metriken eine enorme Menge an Ressourcen.
Beliebte Speicherlösungen für Zeitreihendaten
Die Grafik zeigt spezielle Lösungen zum Speichern von Zeitreihendaten. Die Skala ist logarithmisch.
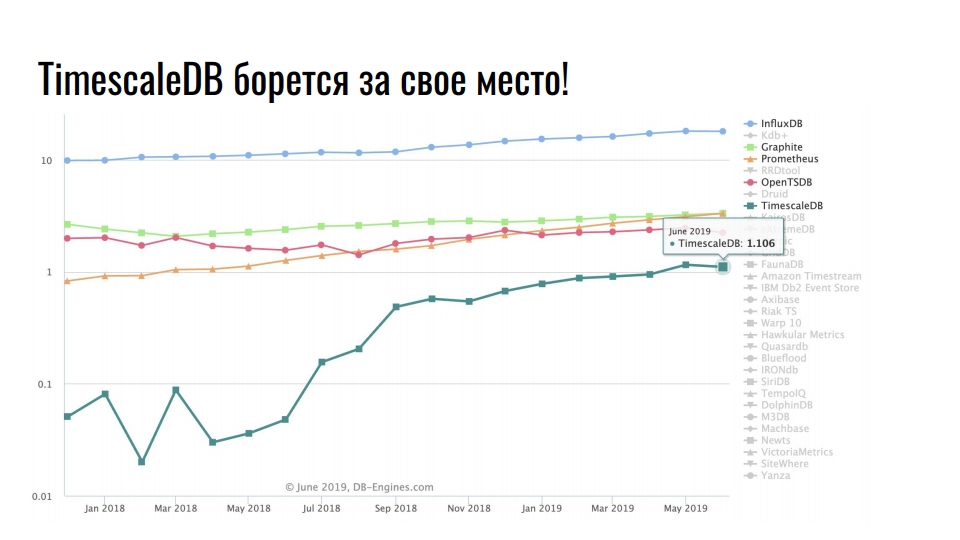
Stabiler Anführer InfluxDB. Jeder, der auf Zeitreihendaten gestoßen ist, hat von diesem Produkt gehört. Die Grafik zeigt jedoch eine Verzehnfachung von TimescaleDB - eine Erweiterung des relationalen DBMS kämpft um einen Platz unter der Sonne unter den Produkten, die ursprünglich im Rahmen der Zeitreihen entwickelt wurden.
PostgreSQL ist nicht nur eine gute Datenbank, sondern auch eine erweiterbare Plattform für die Entwicklung spezialisierter Lösungen.
Postgres, Postgis und TimescaleDB
Die First Monitoring Company überwacht die Bewegung von Fahrzeugen mithilfe von Satelliten. Wir verfolgen 20.000 Fahrzeuge und speichern zwei Jahre lang Bewegungsdaten. Insgesamt verfügen wir über 10 TB aktuelle Telemetriedaten. Im Durchschnitt sendet jedes Fahrzeug während der Fahrt 5 Telemetrie-Aufzeichnungen pro Minute. Die Daten werden über Navigationsgeräte an unsere Telematikserver gesendet. Sie erhalten 500 Navigationspakete pro Sekunde.
Vor einiger Zeit haben wir beschlossen, die Infrastruktur global zu aktualisieren und von einem Monolithen auf Microservices umzusteigen. Wir haben das neue System Waliot genannt und es ist bereits in Produktion - 90% aller Fahrzeuge werden darauf übertragen.
In der Infrastruktur hat sich viel geändert, aber die zentrale Verbindung ist unverändert geblieben - dies ist die PostgreSQL-Datenbank. Jetzt arbeiten wir an Version 10 und bereiten die Umstellung auf 11 vor. Zusätzlich zu PostgreSQL als Hauptspeicher verwenden wir PostGIS für Geodaten im Stack und TimescaleDB zum Speichern einer großen Anzahl von Zeitreihendaten.
Warum PostgreSQL?
Warum versuchen wir, eine relationale Datenbank zum Speichern von Zeitreihen zu verwenden, anstatt
ClickHouse- Speziallösungen für diesen Datentyp? Vor dem Hintergrund des gesammelten Fachwissens und der Eindrücke der Arbeit mit PostgreSQL möchten wir keine unbekannte Lösung als Hauptspeicher verwenden.
Der Wechsel zu einer neuen Lösung ist ein Risiko.
Es gibt viele spezielle Lösungen zum Speichern und Verarbeiten von Zeitreihendaten. Dokumentation ist nicht immer genug und eine große Auswahl an Lösungen ist nicht immer gut. Es scheint, dass die Entwickler jedes neuen Produkts alles von Grund auf neu schreiben möchten, da in der vorherigen Lösung etwas nicht angenehm war. Um zu verstehen, was genau nicht gefallen hat, müssen Sie nach Informationen suchen, analysieren und vergleichen. Eine Vielzahl von
Tops ,
Bewertungen und
Vergleichen sind eher beängstigend als motivierend, etwas auszuprobieren. Sie müssen viel Zeit aufwenden, um alle Lösungen selbst auszuprobieren. Wir können es uns nicht leisten, mehrere Monate lang nur eine Lösung anzupassen. Dies ist eine schwierige Aufgabe, und die aufgewendete Zeit wird sich nie auszahlen. Aus diesem Grund haben wir Erweiterungen für PostgreSQL ausgewählt.
Während der Entwicklungsphase der Waliot-Infrastruktur betrachteten wir InfluxDB als das Haupt-Telemetrie-Repository. Aber als ich auf TimescaleDB stieß und Tests daran durchführte, gab es keine Fragen zur Auswahl. Mit PostgreSQL mit der Erweiterung TimescaleDB können Sie andere Erweiterungen im selben PostGIS- oder PipelineDB-Speicher verwenden. Wir müssen keine Daten abrufen, transformieren, Analysen durchführen und über das Netzwerk übertragen. Alles liegt auf einem Server oder in einem Clustersystem - Daten müssen nicht gezogen werden. Alle Berechnungen werden auf derselben Ebene durchgeführt.
Kürzlich veröffentlichte
Nikolay Samokhvalov , der Autor des Postgresmen-Kontos,
einen Link zu einem interessanten Artikel über die Verwendung von SQL für die Streaming-Datenverarbeitung. Fünf von sechs Autoren des Artikels sind an der Entwicklung verschiedener Apache-Produkte beteiligt und arbeiten mit der Stream-Verarbeitung. Daher werden in dem Artikel Apache Spark, Apache Flink, Apache Beam, Apache Calcite und KSQL von Confluent erwähnt.
Aber nicht der Artikel selbst ist interessant, sondern das
Thema in den Hacker News , in dem es diskutiert wird. Der Autor des Themas schreibt, dass er basierend auf dem Artikel fast alle Ideen basierend auf PostgreSQL 11 implementiert hat. Er verwendete CitusDB-Erweiterungen für horizontale Skalierung und Sharding, PipelineDB für Stream-Computing und materialisierte Ansichten, TimescaleDB für die Speicherung von Zeitreihendaten und Schnitte. Er verwendet auch mehrere Foreign Data Wrapper.
Eine verrückte Mischung aus PostgreSQL und seinen Erweiterungen bestätigt erneut, dass PostgreSQL nicht nur ein DBMS ist, sondern eine Plattform.
Und wann der steckbare Speicher geliefert wird ... Ugh!
Ironischerweise fanden wir bei der Erforschung der Lösungen
Outflux , die Entwicklung des TimescaleDB-Teams, die am 1. April veröffentlicht wurde. Was glaubst du, macht sie? Dies ist ein Dienstprogramm für die Migration von InfluxDB zu TimescaleDB in einem Befehl ...
Postgres Hype!
Unterschätzen Sie nicht die Macht des Hype! Wir scherzen oft, dass „Entwicklung von Hype getrieben wird“, weil dies unsere Wahrnehmung von Tuning- und Infrastrukturkomponenten beeinflusst. Bei
HighLoad ++ diskutieren wir viel über PostgreSQL, ClickHouse, Tarantool - das sind Hype-Entwicklungen. Sagen Sie nur nicht, dass dies keine Auswirkungen auf Ihre Vorlieben und die Auswahl der Lösungen für die Infrastruktur hat ... Natürlich ist dies nicht der Hauptfaktor, aber gibt es irgendwelche Auswirkungen?
Ich arbeite seit 5 Jahren mit PostgreSQL. Ich mag diese Lösung. Er löst fast alle meine Aufgaben mit einem Knall. Jedes Mal, wenn mit dieser Basis etwas schief ging, waren meine krummen Hände schuld. Daher war die Wahl vorbestimmt.
TimescaleDB VS PipelineDB
Fahren wir mit den Erweiterungen TimescaleDB und PipelineDB fort. Was sagen ihre Schöpfer über Erweiterungen?
TimescaleDB ist eine Open-Source-
Zeitreihendatenbank , die für schnelles Einfügen und komplexe Abfragen optimiert ist.
PipelineDB ist eine leistungsstarke Erweiterung, mit der fortlaufende SQL-Abfragen
für Zeitreihendaten ausgeführt werden können .
Sie arbeiten nicht nur mit Zeitreihendaten, sondern haben auch eine ähnliche Geschichte. Timescale wurde 2015 und Pipeline 2013 gegründet. Die ersten Arbeitsversionen erschienen 2017 bzw. 2015. Es dauerte zwei Jahre, bis die Teams die Mindestfunktionalität freigegeben hatten. Die Produktionsfreigaben beider Erweiterungen erfolgten im vergangenen Oktober mit einem Unterschied von einer Woche. Anscheinend in Eile nacheinander.
GitHub hat eine Reihe von Sternen und Gabeln, die wie üblich kein einziges Commit sind. So funktioniert Open Source, es gibt nichts zu tun. Aber es gibt viele Sterne,
TimescaleDB hat mehr als
PipelineDB und sogar mehr als PostgreSQL selbst.
Erweiterungen scheinen ähnlich zu sein, aber sie positionieren sich anders.
TimescaleDB behauptet, Millionen von Datensätzen pro Sekunde eingefügt und Hunderte von Milliarden Zeilen und Dutzende Terabyte Daten gespeichert zu haben. Die Erweiterung ist schneller als InfluxDB, Cassandra, MongoDB oder Vanilla PostgreSQL. Unterstützt Streaming-Replikations- und Sicherungstools. TimescaleDB ist eine Erweiterung, keine Abzweigung von PostgreSQL.
PipelineDB speichert nur das Ergebnis von Streaming-Berechnungen, ohne dass Rohdaten für ihre Berechnungen gespeichert werden müssen. Die Erweiterung kann kontinuierlich über Echtzeitdatenströme aggregiert und mit herkömmlichen Tabellen für Berechnungen im Kontext einer Domänendomäne kombiniert werden. PipelineDB ist eine Erweiterung, keine Abzweigung, aber ursprünglich war es eine Abzweigung.
Timescaledb
Nun im Detail zu den Erweiterungen. Beginnen wir mit TimescaleDB. Ich arbeite seit fast 2 Jahren mit ihm. Zog es vor der Release-Version in die Produktion. Schauen wir uns Beispiele für die Anwendung an.
Speicher für Infrastrukturmetriken . Wir haben Docker-Container-Ressourcenverbrauchsmetriken, Metrik-Festschreibungszeit, Container-ID und Ressourcenverbrauchsfelder, z. B. freien Speicher. Wir müssen Statistiken für alle Container mit einer durchschnittlichen Anzahl von freien Speicherfenstern für 10 Sekunden anzeigen. Die angezeigte Abfrage löst dieses Problem, und TimescaleDB kann als Repository für Infrastrukturmetriken verwendet werden.
SELECT time_bucket('10 seconds', time) AS period, container_id, avg(free_mem) FROM metrics WHERE time < now() - interval '10 minutes' GROUP BY period, container_id ORDER BY period DESC, container_id;
period | container_id | avg -----------------------+--------------+--- 2019-06-24 12:01:00+00 | 16 | 72202 2019-06-24 12:01:00+00 | 73 | 837725 2019-06-24 12:01:00+00 | 96 | 412237 2019-06-24 12:00:50+00 | 16 | 1173393 2019-06-24 12:00:50+00 | 73 | 90104 2019-06-24 12:00:50+00 | 96 | 784596
Für Berechnungen . Wir müssen die Anzahl der Lastwagen, die Krasnodar verlassen haben, und ihre Gesamttonnage in Tagen berechnen.
SELECT time_bucket('1 day', time) AS day, count(*) AS trucks_exiting, sum(weight) / 1000 AS tonnage FROM vehicles INNER JOIN cities ON cities.name = 'Krasnodar' WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326)) AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326)) GROUP BY day ORDER BY day DESC LIMIT 3;
Es verwendet auch Funktionen aus der PostGIS-Erweiterung, um den Transport zu berechnen, der die Stadt verlassen hat, anstatt sich nur darin zu bewegen.
Währungskursüberwachung . Das dritte Beispiel betrifft Kryptowährungen. Mit der Anfrage können Sie anzeigen, wie sich der Preis von Ethereum im Vergleich zu Bitcoin und dem US-Dollar in den letzten 2 Wochen pro Tag verändert hat.
SELECT time_bucket('14 days', c.time) AS period, last(c.closing_price, c.time) AS closing_price_btc, last(c.closing_price, c.time) * last(b.closing_price, c.time) filter (WHERE b.currency_code = 'USD') AS closing_price_usd FROM crypto_prices c JOIN btc_prices b ON time_bucket('1 day', c.time) = time_bucket('1 day', b.time) WHERE c.currency_code = 'ETH' GROUP BY period ORDER BY period DESC;
Dies ist alles klar und bequem für uns SQL.
Was ist so cool an TimescaleDB?
Warum nicht die integrierten Tabellenpartitionierungstools verwenden? Und warum sich die Mühe machen, Tische zu brechen? Die offensichtliche Antwort ist die
Einfügegeschwindigkeit in solche Datenbanken . Die Grafik zeigt die tatsächlichen Messungen der Einfügungsrate der Anzahl der Zeilen pro Sekunde zwischen der regulären Vanilletabelle PostgreSQL 10 ohne Schnitt und der Hypertabelle TimescaleDB.
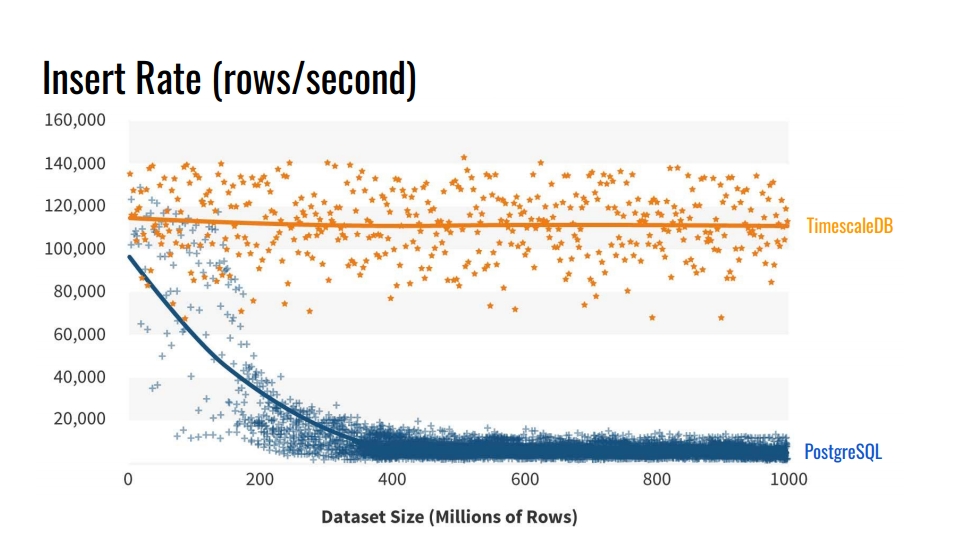
Dieser Benchmark schreibt 1 Milliarde Zeilen auf einen Computer und simuliert ein Szenario zum Sammeln von Metriken aus der Infrastruktur. Der Datensatz enthält die Zeit, die Kennung der Infrastrukturkomponente und 10 Metriken. Der Benchmark wurde auf Azure VM mit 8 Kernen und 28 Gigabyte RAM sowie Netzwerk-SSD-Laufwerken ausgeführt. Das Einfügen wurde in Chargen von 10 Tausend Datensätzen durchgeführt.
Woher kommt eine solche Verschlechterung der PostgreSQL-Leistung? Denn beim Einfügen müssen Sie auch die Tabellenindizes aktualisieren. Wenn sie nicht in den Cache passen, beginnen wir, Festplatten zu laden. Die Partitionierung löst dieses Problem, wenn die Indizes des Abschnitts, in den wir die Daten einfügen, im RAM abgelegt werden.
Schauen wir uns die folgende Tabelle an. Dies vergleicht das in PostgreSQL 10 integrierte deklarative Partitionierungssystem und die TimescaleDB-Hypertabelle. Auf der horizontalen Achse die Anzahl der Abschnitte.
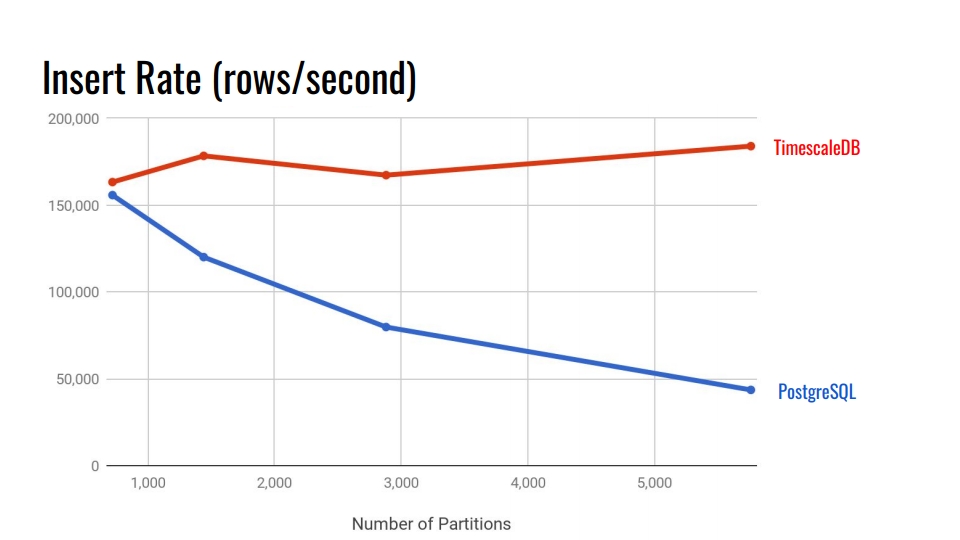
In TimescaleDB ist die Verschlechterung mit zunehmenden Abschnitten vernachlässigbar. Erweiterungsentwickler behaupten, dass sie mit 10.000 Abschnitten in einer einzelnen PostgreSQL-Instanz gut zurechtkommen.
In PostgreSQL verschlechtert sich die native Implementierung nach 3.000 erheblich. Im Allgemeinen ist die deklarative Partitionierung in PostgreSQL ein großer Fortschritt, funktioniert jedoch nur für Tabellen mit weniger Last. Zum Beispiel für Waren, Käufer und andere Domain-Einheiten, die nicht so intensiv in das System eintreten wie Metriken.
In 11 und 12 Versionen von PostgreSQL wird die native Partitionierungsunterstützung angezeigt, und Sie können versuchen, Vergleichstests für Zeitreihendaten mit neuen Versionen durchzuführen. Aber es scheint mir, dass TimescaleDB immer noch besser ist. Alle Benchmarks von TimescaleDB finden Sie auf ihrem
Github und probieren Sie es aus.
Hauptmerkmale
Ich hoffe, Sie haben bereits Interesse an der Erweiterung. Lassen Sie uns die Hauptfunktionen von TimescaleDB durchgehen, um dieses Gefühl zu festigen.
Partitionierung durch Hypertabellen . TimescaleDB verwendet den Begriff "hypertable" für Tabellen, auf die die Funktion create_hypertable () angewendet wurde. Danach wird die Tabelle zum übergeordneten Element für alle geerbten Abschnitte - Chunks. Die übergeordnete Tabelle selbst enthält keine Daten, ist jedoch ein Einstiegspunkt für alle Abfragen und eine Vorlage, wenn automatisch neue Abschnitte erstellt werden. Alle Abschnitte werden nicht im Hauptschema Ihrer Daten gespeichert, sondern in einem speziellen Schema. Dies ist praktisch, da im Datenschema nicht Tausende dieser Abschnitte angezeigt werden.
Die Erweiterung ist in den Scheduler und den Query Executor integriert . Durch spezielle Hooks in PostgreSQL versteht TimescaleDB, wann es auf eine Hypertabelle zugreift. TimescaleDB analysiert die Abfrage und leitet die Abfragen nur an die erforderlichen Abschnitte weiter, basierend auf den im SQL-Aufruf selbst angegebenen Bedingungen. Auf diese Weise können Sie die Arbeit während der Extraktion einer erheblichen Datenmenge mit Abschnitten parallelisieren.
Durch die Erweiterung werden SQL keine Einschränkungen auferlegt . Sie können Gewerkschaften, Aggregate, Fensterfunktionen, CTEs und zusätzliche Indizes frei verwenden. Wenn Sie die Liste der Einschränkungen für das integrierte Partitionierungssystem gesehen haben, sollte dies Ihnen gefallen.
Zusätzliche nützliche Funktionen für Zeitreihendaten:
- "Time_bucket" - "date_trun" einer gesunden Person;
- Histogramme - Ausfüllen der fehlenden Intervalle durch Interpolation oder den letzten bekannten Wert;
- Hintergrundarbeiter - Dienste, mit denen Sie Hintergrundvorgänge ausführen können: Bereinigen alter Abschnitte, Neuorganisation.
Mit TimescaleDB können Sie im leistungsstarken PostgreSQL-Ökosystem bleiben . Diese Erweiterung unterbricht PostgreSQL nicht, daher funktionieren alle Hochverfügbarkeitslösungen, Sicherungssysteme und Überwachungstools weiterhin. TimescaleDB ist mit Grafana, Periscope, Prometheus, Telegraf, Zabbix, Kubernetes, Kafka, Seeq und JackDB befreundet.
Grafana unterstützt TimescaleDB bereits nativ als Datenquelle. Grafana versteht sofort, dass PostscreSQL über TimescaleDB verfügt. Der Abfrage-Generator in Grafana in Dashboards versteht zusätzliche TimescaleDB-Funktionen wie "time_bucket", "first", "last". Mit diesen Zeitreihenfunktionen können Sie Diagramme direkt aus der relationalen Datenbank ohne gigantische Abfragen erstellen.
Prometheus verfügt über einen Adapter, mit dem Sie Daten zusammenführen und TimescaleDB als zuverlässiges Data Warehouse verwenden können. Verwenden Sie einen Adapter, um Daten jahrelang nicht in Prometheus zu speichern.
Es gibt auch ein
Telegraf-Plugin . Mit der Lösung können Sie Prometheus vollständig entfernen. Infrastrukturdaten werden sofort an TimescaleDB übertragen und durch Telegraf gelesen.
Lizenzen und Neuigkeiten
Vor nicht allzu langer Zeit hat das Unternehmen auf ein neues Lizenzmodell umgestellt. Der größte Teil des Codes ist unter Apache 2.0 lizenziert. Ein kleiner Teil kann kostenlos verwendet werden, ist jedoch unter TSL lizenziert.
Es gibt eine Enterprise-Version mit einer kommerziellen Lizenz. Keine Sorge, nicht alle Extras in der Enterprise-Version. Grundsätzlich gibt es Automatisierungen wie das automatische Entfernen veralteter Brocken, die durch ein einfaches "Cron" und ähnliche Dinge erfolgen können.
Jetzt arbeitet das Unternehmen aktiv an einer Clusterlösung. Vielleicht fällt es in die Enterprise-Version. Es gibt auch eine Cloud-Version für Startups, die den Markteintritt schaffen möchten, bevor den Anlegern das Geld ausgeht.
Aus den Nachrichten:
- eine Million Downloads in den letzten anderthalb Jahren;
- Investition von 31 Millionen US-Dollar;
- Aktive Zusammenarbeit mit MS Azure in Bezug auf IoT-Lösungen.
Zusammenfassend
TimescaleDB dient zum Speichern von Zeitreihendaten. Dies ist ein leistungsstarkes Partitionierungssystem mit minimalen Einschränkungen im Vergleich zu nativen in PostgreSQL.
Leider hat die Erweiterung noch keine Multinode-Version. Wenn Sie einen Multimaster oder Shard möchten, müssen Sie beispielsweise mit CitusDB herumspielen. Wenn Sie eine logische Replikation wünschen, tut dies weh. Aber es tut ihr immer weh.
Pipelinedb
Lassen Sie uns nun über die zweite Erweiterung sprechen. Leider konnten wir es im Kampf nicht richtig testen. Jetzt durchläuft es die Phase der Anpassung in unserem System. Es stimmt, es gibt ein Problem, über das ich näher am Ende sprechen werde.
Wie im vorherigen Fall beginnen wir mit realen Beispielen. Es ist einfacher, die Vorteile der Erweiterung und die Motivation zu verstehen, sie zu verwenden.
Statistiksammlung . Stellen Sie sich vor, wir sammeln Statistiken über Besuche auf unserer Website. Wir benötigen eine Analyse der beliebtesten Seiten, die Anzahl der eindeutigen Benutzer und eine Vorstellung von Ressourcenverzögerungen. All dies sollte in Echtzeit aktualisiert werden. Wir möchten jedoch nicht jedes Mal die Datentabelle berühren und eine Abfrage erstellen oder die Ansicht oben auf der Tabelle aktualisieren.
CREATE CONTINUOUS VIEW v AS SELECT url::text, count(*) AS total_count, count(DISTINCT cookie::text) AS uniques, percentile_cont(0.99) WITHIN GROUP (ORDER BY latency::integer) AS p99_latency FROM page_views GROUP BY url;
url | total_count | uniques | p99_latency -----------+-------------+---------+------------ some/url/0 | 633 | 51 | 178 some/url/1 | 688 | 37 | 139 some/url/2 | 508 | 88 | 121 some/url/3 | 848 | 36 | 59 some/url/4 | 126 | 64 | 159
Die Streaming-Verarbeitung und die PipelineDB-Erweiterung helfen dabei. Die Erweiterung fügt die Abstraktion CONTINUES VIEW hinzu. In der russischen Version mag dies wie eine „kontinuierliche Präsentation“ klingen. Diese Ansicht wird automatisch aktualisiert, wenn sie mit den Aufzeichnungen der Besuche in die Tabelle eingefügt wird, und zwar nur auf der Grundlage neuer Daten, ohne dass das bereits zuvor aufgezeichnete Lesen erfolgt.
Datenstrom . PipelineDB ist nicht nur auf den neuen Ansichtstyp beschränkt. Angenommen, wir führen A / B-Tests durch und sammeln Echtzeitanalysen zur Effektivität einer neuen Geschäftslösung. Wir möchten die Daten jedoch nicht selbst auf Benutzeraktionen speichern. Wir sind nur am Ergebnis interessiert - welche Gruppe hat die meisten Conversions.
Um die direkte Speicherung von Rohdaten für das Streaming-Computing zu vermeiden, benötigen wir eine Abstraktion wie
Streams - Data Stream . PipelineDB führt diese Funktion ein. Sie können Streams wie normale Tabellen erstellen. Unter der Haube wird es "FOREIGN TABLE" sein, basierend auf der ZeroMQ-Warteschlange, die die Erweiterung von uns unmerklich verwendet. Daten werden in die interne ZeroMQ-Warteschlange eingegeben und lösen eine Aktualisierung der fortlaufenden Ansicht aus.
CREATE STREAM ab_event_stream ( name text, ab_group text, event_type varchar(1), cookie varchar(32) ); CREATE CONTINUOUS VIEW ab_test_monitor AS SELECT name, ab_group, sum(CASE WHENevent_type = 'v' THEN 1 ELSE 0 END) AS view_count, sum(CASE WHENevent_type = 'c' THEN 1 ELSE 0 END) AS conversion_count, count(DISTINCT cookie) AS uniques FROM ab_event_stream GROUP BY name, ab_group;
Dann erstellen wir "CONTINUOUS VIEW" basierend auf Daten aus einem zuvor erstellten Stream. Wenn die Daten im Stream ankommen, wird die Ansicht basierend auf diesen Daten aktualisiert. Danach werden die Daten einfach verworfen, nirgendwo gespeichert und belegen keinen Speicherplatz. Auf diese Weise können Sie Analysen für eine nahezu unbegrenzte Datenmenge erstellen, diese in den PipelineDB-Datenstrom laden und das Berechnungsergebnis aus einer kontinuierlichen Ansicht lesen.
Stream Computing Nachdem wir den Datenstrom und die kontinuierliche Ansicht erstellt haben, können wir mit Stream Computing arbeiten. Es sieht so aus.
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie) SELECT round(random() * 2) AS name, round(random() * 4) AS ab_group, (CASE WHENrandom() > 0.4 THEN 'v' ELSE 'c' END) AS event_type, md5(random()::text) AS cookie FROM generate_series(0, 100000); SELECT ab_group, uniques FROM ab_test_monitor; SELECT ab_group, view_count * 100 / (conversion_count + view_count) AS conversion_rate FROM ab_test_monitor;
Das erste "SELECT" gibt die Gruppe "ab" und die Anzahl der eindeutigen Besucher an. Die zweite - gibt das Verhältnis zwischen den Gruppen an - Umwandlung. Das ist alles A / B-Testen bei fünf SQL-Aufrufen in einer relationalen Datenbank.
Die Ansicht wird dynamisch aktualisiert. Sie können nicht auf die Verarbeitung des gesamten Datenarrays warten, sondern bereits verarbeitete Zwischenergebnisse lesen. Ansichten werden wie normales PostgreSQL gelesen. Sie können eine Ansicht auch mit Tabellen oder sogar anderen Ansichten kombinieren. Es gibt keine Einschränkungen.
Topologie
Kafka empfängt Telemetrie, das Thema in Kafka sendet diese Daten an PostgreSQL und wir aggregieren sie weiter. Zum Beispiel kombinieren wir mit einer gewöhnlichen Tabelle und leiten die Daten in den Stream um. Ferner provoziert er die Aktualisierung der entsprechenden fortlaufenden Präsentation, aus der die Datenbankclients bereits die fertigen Daten lesen können.
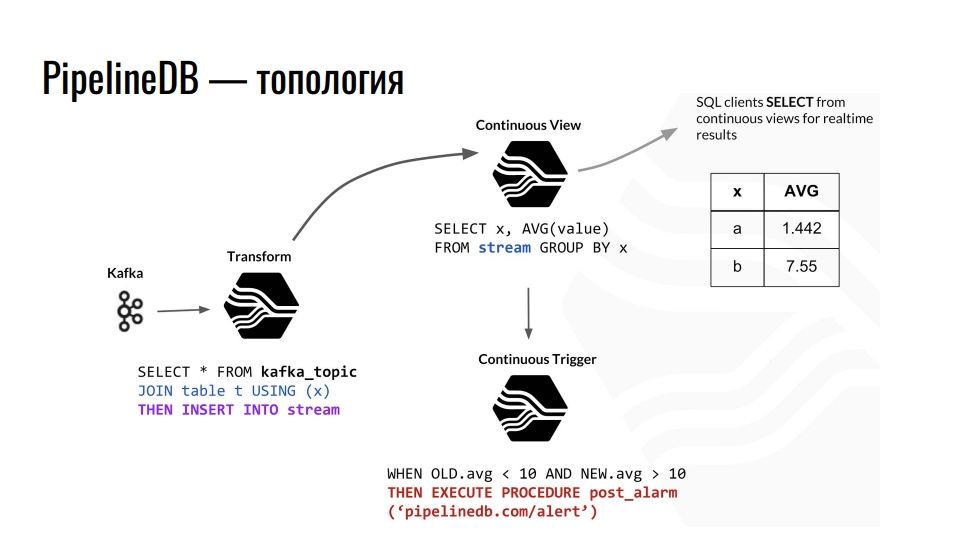 Ein Beispiel für die Topologie von PipelineDB-Komponenten in PostgreSQL. Die Strecke ist einer Präsentation von Derek Nelson entlehnt.
Ein Beispiel für die Topologie von PipelineDB-Komponenten in PostgreSQL. Die Strecke ist einer Präsentation von Derek Nelson entlehnt.Neben Streams und Ansichten bietet die Erweiterung auch eine Abstraktion von "Transform" - Konvertern oder Mutatoren. Diese Ansicht zielte jedoch darauf ab, den eingehenden Datenstrom in eine modifizierte Ausgabe umzuwandeln. Mit diesen Mutatoren können Sie die Darstellung der Daten ändern oder filtern. Vom Mutator fällt alles in die Ansicht CONTINUOUS VIEW. Wir stellen bereits geschäftliche Anfragen. Jeder, der mit funktionaler Programmierung vertraut ist, sollte die Idee verstehen.
In PipelineDB können wir einen Auslöser an unsere Ansichten hängen und Aktionen ausführen, z. B. "Warnung". Bei all diesen Berechnungen speichern wir die Rohdaten niemals selbst, auf deren Grundlage wir sie alle berechnen. Dies können Terabyte sein, die wir nacheinander auf einen Server mit einer 100-Gigabyte-Festplatte hochladen. Schließlich interessiert uns nur das Ergebnis von Berechnungen.
Hauptmerkmale
Die PipelineDB-Erweiterung ist schwieriger zu erlernen als TimescaleDB. In TimescaleDB erstellen wir eine Tabelle, teilen ihr mit, dass sie eine Hypertabelle ist, und genießen das Leben mit mehreren zusätzlichen Funktionen, die die Erweiterung bietet.
PipelineDB löst das Problem des Streaming Computing in relationalen Datenbanken . Die Aufgabe der Streaming-Datenverarbeitung ist hinsichtlich Integration und Verwendung komplizierter als die Partitionierung. Allerdings hat nicht jeder riesige Datenmengen und Milliarden von Zeilen. Warum die Infrastruktur komplizieren, wenn es PipelineDB gibt? Die Erweiterung bietet eigene Implementierungen von Darstellungen, Streams, Konvertern und Aggregaten für die Stream-Verarbeitung. Es ist auch
in den Abfrageplaner integriert und der Abfrage-Executor ermöglicht die Implementierung des Konzepts des Stream Computing in einer relationalen Datenbank.
Wie bei TimescaleDB gelten für die PipelineDB-Erweiterung
in PostgreSQL keine SQL-Einschränkungen . Es gibt verschiedene Funktionen, z. B. können Sie nicht zwei Streams kombinieren, dies ist jedoch nicht erforderlich.
Unterstützung für probabilistische Datenstrukturen und Algorithmen . Die Erweiterung verwendet den Bloom-Filter für SELECT DISTINCT, HyperLogLog für COUNT (DISTINCT) und T-Digest für Percentile_count () direkt in SQL. Dies verbessert die Produktivität.
Ökosystem Mit der Erweiterung können Sie mit den üblichen Hochverfügbarkeitslösungen, Überwachungstools und allem anderen, was in PostgreSQL bekannt ist, arbeiten.
Aufgrund der Besonderheiten des Streaming Computing verfügt PipelineDB über
Integrationen mit Apache Kafka und mit Amazon Kinesis, einem Echtzeit-Analysedienst. Da PipelineDB keine Abzweigung mehr ist, sondern eine Erweiterung, sollte die Integration mit dem Rest des Zoos ebenfalls sofort möglich sein. Ein Muss, aber wir leben nicht in einer idealen Welt, und alles ist eine Überprüfung wert.
Lizenzen und Neuigkeiten
Der gesamte Code ist unter Apache 2.0 lizenziert. Es gibt ein kostenpflichtiges Abonnement für die Unterstützung verschiedener Schießbuden sowie eine Cluster-Version mit einer kommerziellen Lizenz. Basierend auf PipelineDB bietet das Unternehmen einen Stride-Analysedienst an.
Bevor ich über die Erweiterung sprach, sagte ich, dass es ein "aber" gibt. Es ist Zeit, über ihn zu sprechen. Am 1. Mai 2019 gab das PipelineDB-Team bekannt, dass es nun Teil von Confluent ist. Dies ist das Unternehmen, das KSQL entwickelt - eine Engine zum Streamen von Daten in Kafka mit SQL-Syntax. Jetzt arbeitet dort Victor Gamov, Mitbegründer des Podcasts Debriefing.
Was folgt daraus? PipelineDB ist in Version 1.0.0 eingefroren. Neben der Behebung kritischer Fehler ist nichts geplant. Aufgrund der Übernahme erwarten wir die Uber-Integration von Kafka in PostgreSQL. Vielleicht ist es Confluent, das auf steckbarem Speicher basiert und etwas Cooles bewirkt.
Was zu tun ist? Gehen Sie zu TimescaleDB. In der neuesten Version haben sie ihre "CONTINUOUS VIEW" mit Blackjack gemacht. Natürlich ist die Funktionalität jetzt nicht mehr so cool wie in PipelineDB, aber es ist eine Frage der Zeit.
Zusammenfassend
PipelineDB wurde für die Hochleistungs-Streaming-Datenverarbeitung entwickelt. Sie können Berechnungen für große Datenmengen durchführen, ohne die Daten selbst speichern zu müssen.
Wenn wir mit PipelineDB einen Datenstrom in einem Stream an PostgreSQL senden, betrachten wir ihn als virtuell. Wir speichern keine Daten, sondern aggregieren, berechnen und verwerfen. Sie können einen 200-Gigabyte-Server erstellen und Terabyte an Daten über Streams austreiben. Wir werden das Ergebnis erhalten, aber die Daten selbst werden verworfen.
Wenn Ihnen aus irgendeinem Grund die "CONTINUOUS VIEW" von TimescaleDB nicht ausreicht, versuchen Sie es mit PipelineDB. Dies ist ein Open Source-Projekt unter der Apache-Lizenz. Es wird nirgendwo hingehen, obwohl es nicht mehr aktiv entwickelt wird. Aber die Dinge können sich ändern, Confluent hat noch nicht über Expansionspläne geschrieben.
Verwenden von TimescaleDB und PipelineDB
Mit PostgreSQL und zwei Erweiterungen können
wir große Arrays von Zeitreihendaten speichern und verarbeiten . Sie können an viele Anwendungen denken. Schauen wir uns ein Beispiel aus meinem Themenbereich an - Fahrzeugüberwachung.

Navigationsgeräte senden kontinuierlich Telemetrie-Aufzeichnungen an unsere Server. Sie analysieren verschiedene Text- und Binärprotokolle in einem gemeinsamen Format und senden in einem speziellen Thema Daten an Kafka. Von dort gelangen sie durch die Integration mit PipelineDB in den Telemetriedatenstrom in PostgreSQL. Dieser Stream aktualisiert die Ansicht für den aktuellen Status von Fahrzeugen und die gesamte Flottenanalyse und provoziert auf der Grundlage des Auslösers die Aufzeichnung von Telemetriedatensätzen in der TimescaleDB-Hypertabelle.
Mit Erweiterungen haben wir drei Vorteile.
- Echtzeitanalyse.
- Speicherzeitreihendaten.
- Verringerung des Volumens der gespeicherten Telemetrie. Mit dem PipelineDB-Mutator aggregieren wir Daten beispielsweise um eine Minute und berechnen Durchschnittswerte.
Grafana bietet integrierte Unterstützung für TimescaleDB-Funktionen. Daher ist es möglich, Diagramme nach Geschäftsmetriken direkt von der Box bis zu den Spuren auf der Karte nach Koordinaten zu erstellen. Die Analytikabteilung wird sich freuen.
Um alles selbst zu "berühren", schauen Sie sich
die Demo auf GitHub an und führen Sie das
Docker-Image aus - innerhalb der Assembly aus den neuesten PostgreSQL-, TimescaleDB- und PipelineDB-Versionen.
Insgesamt
Mit PostgreSQL können Sie verschiedene Erweiterungen kombinieren und eigene Datentypen und Funktionen hinzufügen, um bestimmte Probleme zu lösen. In unserem Fall deckt die Verwendung der Erweiterungen TimescaleDB und PostGIS den Bedarf für die Speicherung von Zeitreihendaten und Geodatenberechnungen fast vollständig ab. Mit der PipelineDB-Erweiterung können wir kontinuierliche Berechnungen für verschiedene Analysen und Statistiken durchführen. Durch die Verwendung von JSONB-Spalten können wir schwach strukturierte Daten in einer relationalen Datenbank speichern. Open Source-Lösungen reichen mit dem Kopf aus - wir verwenden keine kommerziellen Lösungen.
Diese Erweiterungen stellen praktisch keine Einschränkungen für das Ökosystem rund um PostgreSQL dar, wie z. B. Hochverfügbarkeitslösungen, Sicherungssysteme, Überwachungs- und Protokollanalysetools. Wir brauchen MongoDB nicht, wenn es JSONB-Spalten gibt, und wir brauchen InfluxDB nicht, wenn es TimescaleDB gibt.
Magst du die Geschichte von Ivan und möchtest etwas Ähnliches teilen? Bewerben Sie sich vor dem 7. September bei HighLoad ++ in Moskau. Das Programm füllt sich allmählich. Neben Datenbankfällen wird über Architektur, Optimierung und natürlich hohe Lasten berichtet. , !