Unit-Tests sind großartig, aber einer reicht nicht aus. Oft möchten Sie zusätzlich sicherstellen, dass die laufende Anwendung funktioniert. Integrationstests helfen. Es wird zunehmend zum Testen von Diensten verwendet, und mit Docker können Sie Ihre Testumgebung bequem verwalten. Aber wie immer sind die Dinge nicht so einfach, wenn es viel mehr Microservices und Abhängigkeiten gibt.
Yuri Badalyants von RIT ++ erzählte, wie sie in 2GIS eine Reihe von Diensten und einen ganzen Technologiezoo testen. Im Rahmen der Kürzung wird eine Version dieses Berichts unter sorgfältiger Aufsicht des Redners ergänzt und aktualisiert: Welche Optionen haben Sie ausprobiert, worauf sind Sie gekommen, welche Probleme müssen Sie jetzt nicht lösen. Es geht um Docker, Testcontainer und auch um Scala.
Über den Sprecher: Yuri Badalyants (@
LMnet ) begann seine Karriere 2011 als Webentwickler und arbeitete mit PHP, JavaScript und Java. Jetzt schreibt er in 2GIS über Scala.
Casino
2GIS bietet seit 20 Jahren praktische Stadtpläne und Firmenverzeichnisse an. Vor kurzem haben wir eine
neue Version mit einer unbegrenzten Karte von Russland. Ich erzähle Ihnen von den Erfahrungen, die ich während meiner Arbeit im Casino-Team gesammelt habe. Dieses Team ist in drei Hauptbereiche involviert:
- Werbung - Welche Werbetreibenden sollen angezeigt, welche ausgeblendet, welche angehoben und wie die Bewertung gesenkt werden?
- BigData bezieht sich auf Werbung und deren Personalisierung sowie auf die Erstellung von Analysen und Metriken.
- Crawler ist ein Programm, das im Internet nach Organisationen sucht, um diese automatisch zur Datenbank hinzuzufügen.
Diese drei Bereiche sind die Hauptaufgaben, die wiederum eine große Anzahl von Unteraufgaben haben. Derzeit sind mehr als 25 Microservices in Scala geschrieben. Dies ist ausschließlich unser Code, wir verwenden jedoch auch Systeme von Drittanbietern, z. B. PostgreSQL, Cassandra und Kafka. Wir speichern die Daten in Hadoop und verarbeiten sie in Spark. Darüber hinaus verwenden wir die vom Data Science-Team bereitgestellten Methoden des maschinellen Lernens.
Infolgedessen haben wir eine große Anzahl von Diensten und Mikrodiensten, eine große Anzahl von Abhängigkeiten, und natürlich muss all dies auf irgendeine Weise getestet werden.
Natürlich schreiben wir Unit-Tests. Selbst wenn alle Tests grün sind, bedeutet dies nicht, dass alles funktioniert. Während der Integrationsphase von Komponenten oder Microservices kann ein Fehler auftreten. Deshalb schreiben wir Integrationstests.
Integrationstests
Jeder vom Casino-Team entwickelte Microservice löst sein Geschäftsproblem und befindet sich in einem separaten Repository in GitLab. Dieser Artikel konzentriert sich auf Integrationstests in einem solchen Repository (Microservice) mit gesperrten Abhängigkeiten, für die die Entwickler selbst verantwortlich sind. Das QA-Team testet die Interaktion von Microservices, und ich werde dieses Thema nicht ansprechen.
Als ich Ende 2016 zum ersten Mal ins Team kam, gab es ungefähr das folgende Integrationstestschema:
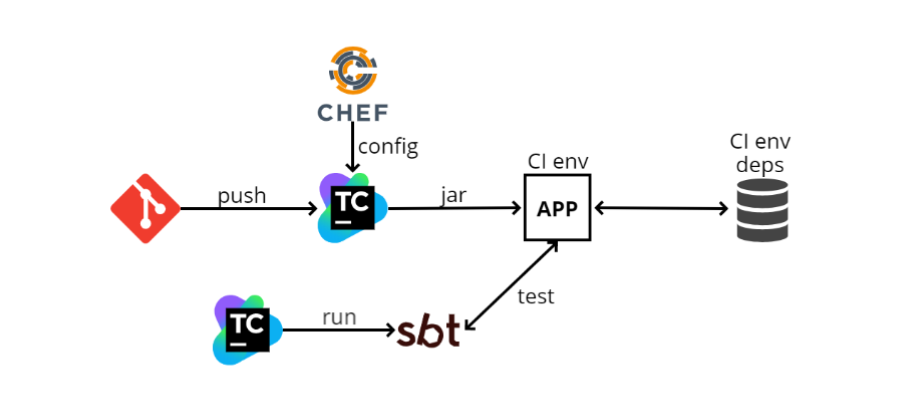
- Der Entwickler schiebt seinen Code in GIT, woraufhin der Microservice-Code in TeamCity eingeht. TeamCity beginnt mit dem Erstellen von Code und dem Ausführen von Tests.
- TeamCity übernimmt die Konfigurationsdatei (config) von Chef (ein Ansible-ähnliches Konfigurationsverwaltungssystem, das nur in Ruby geschrieben wurde). Chefkoch dient auch zur Automatisierung der Bereitstellung. Wenn ich 100 Maschinen habe, möchte ich nicht zu jeder Maschine gehen und das, was ich brauche, auf SSH installieren. Chef kann mir dies automatisieren.
- TeamCity sammelt die JAR-Datei (da wir in Scala schreiben, ist das von uns veröffentlichte Artefakt das JAR) und wird dann vom Programm in die CI-Umgebung geladen. Unsere Anwendung wird dort bereitgestellt, es gibt auch einige Abhängigkeiten. Im Diagramm ist eine der Abhängigkeiten als Datenbank dargestellt. Es kann so viele solche Abhängigkeiten wie möglich geben, und dank Chef kennt unsere Anwendung sie und beginnt mit ihnen zu interagieren.
- Als nächstes startet TeamCity SBT (dies ist unser Build-System, in dem Kompilierung und Tests ausgeführt werden) und führt die Tests selbst aus. Sie sind Unit-Tests relativ ähnlich, arbeiten jedoch hauptsächlich nach diesem Prinzip: Gehen Sie über http zu einer bestimmten Adresse, überprüfen Sie eine Methode und sehen Sie, was sie zurückgibt. oder bereiten Sie sich vor und prüfen Sie, ob das, was benötigt wird, zurückgekehrt ist.
Was kann über ein solches Schema gesagt werden? Am wichtigsten ist, dass es funktioniert. Wenn alles eingerichtet ist, ist das Ausführen von Tests einfach, da sie wie Komponententests aussehen. Aber die Pluspunkte enden dort.
Und die Nachteile beginnen.
Die CI-Umgebung ist immer aktiv , und dies ist eine zusätzliche Verschwendung von Ressourcen. Da Chef eine statische Konfiguration ist, sollten Sie immer eine Art Computer haben, auf dem alle Abhängigkeiten konfiguriert werden und auf dem die Anwendungen unabhängig voneinander bereitgestellt werden. Eine solche Maschine verbraucht zusätzliche Ressourcen, da von Zeit zu Zeit Tests ausgeführt werden und die Maschine jederzeit bereit sein muss. Darüber hinaus ist die CI-Umgebung in allen Abhängigkeiten enthalten.
Es ist nicht möglich, Tests für zwei Zweige gleichzeitig durchzuführen . Dies folgt aus dem vorherigen Absatz: Da wir eine Umgebung haben, können wir sie einfach nicht parallel ausführen.
Es ist nicht möglich, Start, Stopp und Neustart zu testen . Ich werde erklären, warum dies notwendig ist: Alle unsere Anwendungen folgen der Logik des sogenannten
ordnungsgemäßen Herunterfahrens , dh wenn wir SIGTERM erhalten, stoppen wir den Prozess nicht in der Mitte, sondern fangen dieses Signal ab und verstehen, dass wir das Programm ausschalten müssen. Zu diesem Zeitpunkt ist eine bestimmte Logik aktiviert, z. B. werden die HTTP-Anforderungen verarbeitet, die sich "im Flug" befinden, oder wenn wir mit Kafka arbeiten, legen wir alle Offs fest. Mit anderen Worten, wir führen bestimmte Aktionen aus, damit wir die Arbeit sicher abschließen können Wenn alles erledigt ist, schalten Sie es aus.
Diese Logik ist nicht immer einfach, und Sie können sie mit einem solchen Schema nur manuell testen, da wir anhand der Tests den Anwendungslebenszyklus nicht steuern. Es stellt sich heraus, dass TeamCity etwas über Chef bereitgestellt hat, während sich die Tests in einem anderen Stadium befinden und nicht wissen, wie die Anwendung bereitgestellt wird.
Das nächste Minus ist, dass es sehr
schwierig ist, all dies lokal zu konfigurieren . Das heißt, es gibt viele Abhängigkeiten, sie haben ihre eigenen Konfigurationen, sie müssen auf dem lokalen Computer ausgelöst werden. Die Anwendung selbst hat auch eine eigene Konfigurationsdatei, in der es viele Werte gibt. Die Tests selbst haben eine Konfiguration, die mit der Anwendungskonfiguration abgeglichen werden muss, und es kann auch mehr als einen Konfigurationswert geben. Es scheint, dass all dies nicht so beängstigend klingt, wie "Gehen Sie und reparieren Sie die Konfigurationen an drei Orten", aber in Wirklichkeit kann es Stunden dauern, bis neue Mitarbeiter dies tun.
GitLab CI + Docker
Im Laufe der Zeit hat sich dieses Schema in ein anderes verwandelt:
GitLab CI und
Docker . Dies geschah nicht, weil das vorherige Schema nicht ideal war, sondern weil das Unternehmen seinen Kurs in Bezug auf die Verwaltungsorganisation geringfügig geändert hatte.
Zuvor hatte jedes Team und wir viele von ihnen, wie wir wollten oder wie wir konnten, und setzte seine Arbeit ein. Zum Beispiel hatten wir TeamCity, Chef und andere Teams konnten Jenkins oder Ansible verwenden.
Jetzt bewegen wir uns in Richtung der lokalen Cloud und Kubernetes, und es gibt ein separates Team, das all dies verwaltet, sowohl GitLab CI als auch Kubernetes. Andere Teams nutzen dies nur als Service. Dies ist viel praktischer, da Sie dies alles nicht manuell verwalten müssen.
Mit Kubernetes haben wir das folgende Schema bereitgestellt:

- Anstelle von TeamCity wird jetzt Gitlab CI verwendet.
- GitLab CI erstellt ein Docker-Image und stellt es in Kubernetes bereit. Die Konfiguration wird jetzt direkt im Repository und nicht separat in Chef gespeichert, sodass Sie für die Bereitstellung nicht mit einem Konfigurationsdienst eines Drittanbieters arbeiten müssen.
- Abhängigkeiten werden im Voraus auch in Kubernetes angesprochen.
- Anschließend startet GitLab CI SBT und testet in einem separaten Schritt.
Alles ist dem vorherigen Schema ziemlich ähnlich und unterscheidet sich nicht grundlegend davon, das heißt, selbst die Vor- und Nachteile werden genau gleich sein, aber Docker erscheint.
Mit Docker können Sie verschiedene lustige Dinge machen, und eine davon ist Docker-Compose.
Docker-Compose
Dies ist eine Art "Overlay" in Docker, mit dem Sie mehrere Docker-Images als eine Einheit ausführen können.
Ein gutes Beispiel, wo Docker-Compose wirklich hilft, ist Kafka. Sie braucht ZooKeeper, um zu rennen. Wenn Sie Kafka und ZooKeeper ohne Docker-Compose anheben, müssen Sie ZooKeeper separat im Docker anheben - Kafka - und diese beiden Docker-Container konsistent halten. Dies ist nicht sehr praktisch, und mit Docker-Compose können Sie beide Container in einer Datei docker-compose.yml beschreiben und mit dem einfachen
docker-compose run Kafka docker
docker-compose run Kafka Kafka und ZooKeeper auslösen.
Sie können Integrationstests auf Docker-Compose erstellen. Mal sehen, wie es aussehen wird.

- Schieben Sie erneut alles in GitLab.
- GitLab CI startet Docker-Compose.
- In Docker-Compose wird die Anwendung hochgefahren, alle Abhängigkeiten und SBT werden hochgefahren, und der SBT steuert die Tests für diese Anwendung - alles geschieht in Docker-Compose.
Dank dieses Schemas müssen keine separate Umgebung und Abhängigkeiten beibehalten werden, da alles direkt an den GitLab CI-Runner geht, wo Docker und Docker-Compose nur sein müssen. Während des Starts pumpt er die erforderlichen Bilder auf und führt sie aus.
Außerdem können Sie verschiedene Zweige gleichzeitig testen, da alles auf dem Läufer passiert.
Jetzt ist
es einfacher, die Umgebung
lokal zu konfigurieren , aber Sie müssen immer noch mehrere Orte koordinieren. Der Punkt ist, dass wir jetzt, wenn wir die lokale Konfiguration durchführen, nicht alles auf dem lokalen Computer ablegen müssen, sondern alles in die Datei docker-compose.yml geschrieben ist. Sie müssen also an zwei verschiedenen Stellen konfigurieren - dies ist docker-compose.yml und die Konfiguration unserer Tests.
Was die Minuspunkte betrifft, ist
es immer noch unmöglich, Start, Stopp und Neustart zu testen , da wir von SBT aus Tests den Anwendungslebenszyklus nicht steuern. Es wird von Docker-Compose ausgeführt, es wird SBT ausgeführt und Tests werden innerhalb von SBT ausgeführt. Daher gibt es kein vollwertiges Lebenszyklusmanagement der Anwendung. Es gibt auch Schwierigkeiten beim Start, über die ich gerne mehr sprechen möchte.
Docker-Compose 2
In den Tagen von Docker-Compose 2, Docker-Compose.yml sah die Datei folgendermaßen aus:
version: '2.1' services: web: build: . depends_on: db: condition: service_healthy redis: condition: service_started redis: image: redis db: image: db healthcheck: test: "some test here"
Hier werden Dienste registriert, das heißt, was wir im Rahmen dieser Docker-Komposition erheben werden. In diesem Fall habe ich nur ein Beispiel aus der Docker-Compose-Dokumentation genommen. Es gibt drei Dienste: Web, Redis und DB (Datenbank).
Web ist unsere Anwendung, und redis und db sind eine Art von Abhängigkeiten.
Es gibt ein Element im
depends_on Namen
depends_on . Dies deutet darauf hin, dass die Webanwendung von einigen anderen Containern abhängt und im Folgenden beschrieben wird: aus der Datenbank und Redis.
Es gibt auch eine
condition . Für redis ist dies
service_started bedeutet, dass der Container bis zum Start von
service_started nicht versucht, die Webanwendung zu starten.
Der Zustand der Datenbank lautet
service_healthy , und der Healthcheck wird unten beschrieben. Das heißt, wir müssen nicht nur den Docker-Container starten, sondern auch einen bestimmten Healthcheck ausführen. Es kann eine beliebige benutzerdefinierte Logik sein.
Zum Beispiel verwenden wir PostgreSQL, das die PostGIS-Erweiterung verwendet, und die Initialisierung benötigt einige Zeit. Wenn wir den Docker-Container starten, können wir nicht sofort mit der Postgis-Erweiterung arbeiten. Wir müssen warten, bis die Erweiterung initialisiert ist. Daher
SELECT PostGIS_Version(); wir nur
SELECT PostGIS_Version(); Abfragen an
SELECT PostGIS_Version(); . Bis die Erweiterung initialisiert ist, gibt die Anforderung einen Fehler aus. Wenn die Erweiterung initialisiert wird, wird die Version zurückgegeben. Dies ist sehr praktisch und logisch -
zuerst werden alle Abhängigkeiten und dann die Anwendung erhöht .
Docker-Compose 3
Als Docker-Compose 3 herauskam, haben wir damit begonnen.
In der Dokumentation dazu wurde jedoch ein Element zum Ändern der abhängigen Logik angezeigt. Die Docker-Entwickler entschieden, dass eine Beschreibung des Abhängigkeitsgraphen ausreichend war. Dies bedeutet, dass beim Starten des
docker-compose run web sowohl die Anwendung selbst als auch die Datenbank, von der sie abhängt, gleichzeitig gestartet werden.

Der nächste Absatz in der Dokumentation besagt, dass abhängige_on keine Bedingung mehr ist.
Wenn Sie also immer noch die Funktionalität erhalten möchten, die in der zweiten Version verwendet wurde, müssen Sie alles selbst in die Hand nehmen.
Die Seite
Controlling Startup Order bietet verschiedene Lösungen. Die erste Option ist die Verwendung von
wait-for-it.sh .
Jetzt sieht docker-compose.yml etwas anders aus:
version: '3' services: web: build: . depends_on: [ db, redis ] redis: image: redis command: [ "./wait-for-it.sh", ... ] db: image: redis command: [ "./wait-for-db.sh", ... ]
depends_on ist nur ein Array, es gibt keine Bedingungen.
In unseren Abhängigkeiten definieren wir den Befehl neu, dh in Docker-Compose können Sie einen Befehl anhängen, mit dem der Docker-Container startet.
Dort sollten wir wait-for-it.sh und etwas anderes schreiben. Anstelle der drei Punkte im obigen Beispiel sollten wir schreiben, was wir warten müssen, sowie den ursprünglichen Befehl, der den Docker-Container startet.
Dazu müssen Sie die Docker-Datei suchen, den Befehl für redis von dort kopieren und einfügen. Gleiches gilt für die Datenbank. Ein großes Minus ist, dass die
Abstraktion zusammenbricht - ich möchte nicht wissen, welcher Befehl den Docker-Container startet. Diese Befehle können nicht trivial und recht komplex sein, aber ich möchte mich nicht darum kümmern, sondern nur den
docker run eingeben und
docker run .
Ich persönlich mag diese Lösung nicht wirklich, aber wir hatten einige Dienste, die so funktionieren.
Skript über Docker-Compose
Dann entschied ich, dass die Zeit für "Fahrradbau" gekommen war und ich hatte
docker-compose-run.sh :
version: '3' services: postgres: ... my_service: depends_on: [ postgres ] ... sbt: depends_on: [ my_service ] ...
Lassen Sie mich ein semi-realistisches Beispiel geben: Es gibt postgres in docker-compose.yml, es gibt die Anwendung my_service, die von postgres abhängt, und SBT, in der Tests ausgeführt werden und die von meinem Service abhängt.
Ich führe das Programm nicht über
docker run , sondern über das Skript Docker-Compose-Run.sh.
Erstens beginnt die tiefste Abhängigkeit zuerst, in meinem Fall sind es Postgres. Das Skript startet die Abhängigkeit im "Daemon" -Modus, dh es blockiert das Terminal nicht:
docker-compose up -d postgres
Dann warte ich, bis die Bedingung wait_until die Bedingung erfüllt. Dies ist fast das Gleiche wie wait-for-it.sh, nur sozusagen in einem imperativen Stil. Während der Initialisierung von PostGIS wird das Terminal blockiert, dh das Programm wartet ebenfalls. Wenn es nicht wartet, wird ein Fehler ausgegeben und die Tests funktionieren nicht mehr.
wait_until 10 2 docker-compose exec -T postgres psql
Wenn PostGIS initialisiert ist, fahren Sie mit dem nächsten Schritt fort und machen Sie dasselbe mit dem Dienst. Für ihn ist der Test etwas einfacher: Port 80 sollte gebunden sein.
docker-compose up -d my_service wait_until 10 2 docker-compose exec -T \ my_service sh -c "netstat -ntlp | grep 80 || exit 1"
Der letzte Schritt besteht darin, SBT über den Befehl run auszuführen, in dem Tests ausgeführt werden.
docker-compose run sbt down $?
Somit wird alles in der richtigen Reihenfolge ausgelöst, jedoch manuell.
Am Ende wird die
down Funktion aufgerufen, die das Ergebnis des vorherigen Befehls akzeptiert. Wenn es "0" ist, sind die Tests bestanden und wir schalten Docker-Compose einfach aus. Andernfalls „spucken“ wir zuerst die Protokolle aus, um herauszufinden, was schief gelaufen ist, und deaktivieren dann erst Docker-Compose.
function down { echo "Exiting with code $1" if [[ $1 -eq 0 ]]; then docker-compose down exit $1 else docker-compose logs -t postgres my_service docker-compose down exit $1 fi }
Ein solches Schema funktioniert, lässt sich aber nicht gut skalieren. Jeder Dienst muss seine docker-compose-run.sh mit seiner eigenen Logik beschreiben. Außerdem erstreckt sich die Startkonfiguration zwischen docker-compose-run.sh und docker-compose.yml. Im Allgemeinen sieht es so aus, als würden wir Docker-Compose nicht verwenden, aber mit seinen Mängeln kämpfen.
Docker aus Code ausführen
Als das vorherige Schema erstellt wurde, dachte ich: Wenn ich bereits alles im Docker habe, warum nicht aus dem Code ausführen? Ich suchte nach einer Lösung und fand mehrere Möglichkeiten.
Die erste Möglichkeit besteht darin, einfach
den Docker-Client zu verwenden . In der JVM-Welt gibt es zwei Haupt-Docker-Clients:
Docker-Java und
Spotify-Docker-Client .
Mit dem Docker-Client können Sie Docker-Befehle mithilfe der API direkt aus dem Code ausführen. Das heißt, anstatt Zeichenfolgen zu verketten, um Befehle wie
`docker run ...` zu erstellen, können Sie einfach einen solchen Befehl im Code bilden und ausführen. Es ist viel bequemer.
Diese Methode funktioniert gut und sie können mit Sicherheit alles, dies ist jedoch ein sehr niedriges Niveau. Ich müsste mein eigenes Docker-Compose-Analogon erstellen, was eine sehr große Aufgabe ist.
Die nächste Option ist die
Docker-it-Scala-Bibliothek , die beide Clients umschließt und es Ihnen ermöglicht, das zu verwendende Backend auszuwählen. Sie kann die Container laufen lassen, die Sie brauchen.
Das Minus dieser Bibliothek ist jedoch, dass sie keine sehr flexible API hat und keine Lebenszykluskontrolle gibt.
Diese Option hat mir auch nicht gefallen, ich habe weiter gesucht und
Testcontainer gefunden. Ich möchte Ihnen mehr darüber erzählen.
Testcontainer
Dies ist eine Art Java-Bibliothek zum Starten und Testen von Docker-Containern. Es gibt eine Scala-Fassade, Testcontainer-Scala. Standardmäßig gibt es eine Reihe beliebter Dienste, z. B. PostgreSQL, MySQL, Nginx, Kafka, Selenium. Sie können beliebige andere Container ausführen. Die Bibliothek verfügt über eine recht einfache und flexible API, auf die ich noch näher eingehen werde.
Vordefinierte Container
So arbeiten Sie mit vordefinierten Containern, die sich in der Bibliothek befinden: Tatsächlich ist alles recht einfach, da Container als Objekte dargestellt werden:
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6") pgContainer.start() val pgUrl: String = pgContainer.jdbcUrl val pgPort: Int = pgContainer.mappedPort(5432) pgContainer.stop()
In diesem Fall erstellen wir
PostgreSQLContainer , wir können es starten und damit arbeiten. Als nächstes erhalten wir
jbdcUrl , mit dem Sie eine Verbindung zu PostgreSQL herstellen können. Danach bekommen wir
mappedPort .
Dies bedeutet, dass PostgreSQL sich vom Docker-Port 5432 abhebt und Testcontainer diesen Port erkennt und automatisch einem zufälligen Port zuweist. Das heißt, aus den Tests sehen wir beispielsweise 32422. Die Zuweisung erfolgt automatisch.
Benutzerdefinierter Container
Die folgende Ansicht, der sogenannte benutzerdefinierte Container, ist ebenfalls recht einfach:
class GenericContainer( imageName: String, exposedPorts: Seq[Int] = Seq(), env: Map[String, String] = Map(), command: Seq[String] = Seq(), classpathResourceMapping: Seq[(String, String, BindMode)] = Seq(), waitStrategy: Option[WaitStrategy] = None ) ...
Es gibt einen
GenericContainer von dem Sie eine Reihe von Feldern erben und überschreiben müssen.
imageName Sie sicher, dass Sie nur
imageName Dies ist der Name des Containers, den Sie erstellen möchten.
Sie können
exposedPorts Ports
exposedPorts : die Ports, aus denen der Container herausragt. In env können Sie Umgebungsvariablen festlegen und den
command zum Ausführen festlegen.
classpathResourceMapping können Sie Ressourcen aus dem Klassenpfad in den Docker-Container werfen. Dies ist beispielsweise sehr praktisch, wenn sich die Anwendungskonfiguration direkt in den Testressourcen befindet. Sie ordnen sie einfach zu, und die Anwendung im Docker erhält Zugriff auf diese Konfiguration.
waitStrategy ist eine sehr praktische Sache, die in Docker-Compose 3 fehlte, tatsächlich ist es HealthCheck. Es gibt mehrere vordefinierte
waitStrategy . Sie können beispielsweise warten, bis eine
waitStrategy auftritt, oder eine bestimmte http-Methode gibt 200 zurück. Sie können jedoch einen beliebigen HealthCheck schreiben.
Da Sie HealthCheck einfach in Ihren Code schreiben, können Sie zum einen eine normale Sprache verwenden, nicht Bash, und zum anderen alle Bibliotheken, die in Ihrem Code verfügbar sind: Wenn Sie einen benutzerdefinierten HealthCheck in Cassandra erstellen möchten, nehmen Sie den Treiber und schreiben Sie jeder HealthCheck.
Ausführen von Tests
Und jetzt ein wenig darüber, wie man Tests durchführt:
class PostgresqlSpec extends FlatSpec with ForAllTestContainer { override val container = PostgreSQLContainer() "PostgreSQL container" should "be started" in { Class.forName(container.driverClassName) val connection = DriverManager .getConnection(container.jdbcUrl, container.username, container.password) // test some stuff } }
Ich werde über
ScalaTest sprechen, den De-facto-Standard für Tests in der Scala-Welt.
Zum Beispiel möchten wir Tests für Postgres schreiben. Erstellen Sie einen
PostgresqlSpec Test und erben Sie ihn von
ForAllTestContainer . Dies ist eine Eigenschaft, die von der Bibliothek bereitgestellt wird. Die erforderlichen Container werden vor allen Tests gestartet und nach allen Tests gestoppt. Oder Sie können
ForeachTestContainer , dann beginnen die Container vor jedem Test und stoppen nach jedem von ihnen.
Dann müssen Sie den Container neu definieren. Dies kann durch Überschreiben der
container . In meinem Fall verwende ich
PostgreSQLContainer .
Dann schreiben wir Tests. Im Beispiel erstelle ich eine Verbindung, nehme jdbcUrl, Benutzername, Passwort, schreibe bestimmte Tests, sende Anfragen.
In der Regel erfordern Integrationstests mehrere Container. Ich kann sie mit
MultipleContainers erstellen:
val pgContainer = PostgreSQLContainer() val myContainer = MyContainer() override val container = MultipleContainers(pgContainer, myContainer)
Das heißt, ich erstelle Container, füge sie
MultipleContainers und verwende sie als
container .
Das Schema zum Ausführen von Tests mit Testcontainern lautet wie folgt:

- Schieben Sie den Code in GitLa.
- GitLab CI Runner startet SBT.
- SBT führt Tests durch. Innerhalb der Tests werden unsere Anwendung und Abhängigkeiten gestartet.
Die Vorteile dieses Schemas:
- Sie müssen keine separate Umgebung und Abhängigkeiten beibehalten, alles geschieht auf dem Läufer.
- Sie können verschiedene Zweige gleichzeitig testen.
- Sie können Start, Stopp und Neustart testen, da wir den Lebenszyklus der Anwendung steuern können (alles beginnt direkt im Testcode).
- Es gibt flexible HealthChecks, die schmerzlich fehlten.
- Es befinden sich keine * .sh-Dateien im Repository. Sie können Tests in der Anwendung so flexibel konfigurieren, wie Sie möchten.
- Dank der classpathResource-Zuordnung können Sie für beide Tests und die Anwendung dieselbe Konfiguration verwenden.
- Sie können Tests aus Code konfigurieren.
- All dies läuft sowohl auf CI als auch lokal gleich einfach, da es sich nur um Tests handelt, die als Komponententests aussehen und ausgeführt werden. Nur alles wird im Docker-Container angezeigt.
Es stellt sich heraus, dass alles verdächtig glatt und gut ist, aber dies ist nur auf den ersten Blick, tatsächlich sind wir auf eine Reihe von Problemen gestoßen.
Abhängige Container
Das erste Problem, auf das wir gestoßen sind, sind
abhängige Container . Nehmen wir an, es gibt eine Art Test:
class MySpec extends FlatSpec with ForAllTestContainer { val pgCont = PostgreSQLContainer() val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override val container = MultipleContainers(appCont, pgCont) // tests here }
Es werden Postgres und AppContainer ausgeführt. Dem appContainer von postgres wird jdbcUrl übergeben, der Benutzername und das Passwort für die Verbindung. Als Nächstes werden MultipleContainer erstellt und der Test selbst beschrieben.
Ich starte das Programm und sehe einen Fehler:
Exception encountered when invoking run on a nested suite - Mapped port can only be obtained after the container is started
Der Punkt ist, dass der zugewiesene Port nicht genommen werden kann, bis der Container gestartet wird. Warum passiert das?
Tatsache ist, dass
ForAllTestContainer oder
ForEachTestContainer Container direkt vor den Tests starten und nicht in dem Moment, in dem ich Containerinstanzen erstelle. Es stellt sich heraus, dass zum Zeitpunkt des Erstellens des AppContainers
PostgreSQLContainer noch nicht
jdbcUrl .
jdbcUrl bedeutet, dass ich den zugewiesenen Port nicht
jdbcUrl kann und er zur Bildung von
jdbcUrl benötigt
jdbcUrl .
Das Problem ist, dass das Wesen des Containers veränderlich ist: Es hat mehrere Zustände. Zum Beispiel kann es ein- und ausgeschaltet werden.
Wie kann man dieses Problem lösen? Die erste Methode würde ich "faul" nennen.
class MyTest extends FreeSpec with BeforeAndAfterAll { lazy val pgCont = PostgreSQLContainer() lazy val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() } // tests here }
Die Hauptidee besteht darin, Container mit
Lazy Val zu erstellen. Dann werden sie nicht sofort im Testkonstruktor initialisiert, sondern warten auf den ersten Aufruf. Wir werden die
afterAll beforeAll und
afterAll initialisieren, die das
BeforeAndAfterAll BeforeAndAfterAll von ScalaTest bereitstellt. In
beforeAll Container gestartet und in
afterAll werden sie ausgeschaltet. Da die Container als faul deklariert sind, werden sie zum Zeitpunkt des Aufrufs der Startmethode beforeAll erstellt, initialisiert und gestartet.
Es tritt jedoch immer noch ein Fehler auf, dass ich localhost nicht beitreten kann: 32787:
org.postgresql.util.PSQLException: Connection to localhost:32787 refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.
Es scheint, dass wir jdbcUrl verwendet haben. Warum erscheint localhost? Mal sehen, wie jdbcUrl funktioniert:
@Override public String getJdbcUrl() { return "jdbc:postgresql://" + getContainerIpAddress() + ":" + getMappedPort(POSTGRESQL_PORT) + "/" + databaseName; }
Es ist nur eine Zeichenfolgenverkettung. Mit Konstanten ist alles klar, sie können nicht brechen.
getMappedPort sollte auch funktionieren, da wir es bereits behoben haben.
databaseName ist eine fest codierte Konstante. Aber mit
getContainerIpAddress interessanter. Beim Namen können wir davon ausgehen, dass die IP-Adresse des Containers zurückgegeben werden soll. Wenn Sie diesen Code jedoch ausführen, stellt sich heraus, dass immer localhost zurückgegeben wird. Wie sich herausstellte, ist diese Methode nicht für die Interaktion zwischen Containern vorgesehen:
getContainerIpAddress bietet Interaktion aus Tests innerhalb des Containers .
Empfehlung des Testcontainer-Entwicklers:
Erstellen Sie ein benutzerdefiniertes Netzwerk für die Kommunikation zwischen Containern . Docker-Compose funktioniert ungefähr so: Es erstellt ein Netzwerk und löst alles selbst.
Sie müssen also ein Netzwerk erstellen.
class MyTest extends FreeSpec with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() network.close() } // tests here }
Jetzt müssen wir unsere jdbcUrl manuell konfigurieren. Wir müssen auch unsere Container im Netzwerk aktivieren und einen Alias für den PostgreSQLContainer festlegen, damit er über einen Domänennamen im Netzwerk zugänglich ist. Am Ende müssen Sie daran denken, das Netzwerk zu "töten".
Schließlich wird ein solches Programm funktionieren.
In neueren Versionen von testcontainers-scala wird die verzögerte Containerinitialisierung sofort unterstützt:
class MyTest extends FreeSpec with ForAllTestContainer with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override val container = MultipleContainers(pgCont, appCont) override def afterAll(): Unit = { super.afterAll() network.close() } // tests here }
Sie können
ForAllTestContainer und
MultipleContainers wieder verwenden. In
beforeAll Startreihenfolge nicht mehr manuell
beforeAll . Jetzt können
MultipleContainers mit Lazy Val arbeiten und diese in der richtigen Reihenfolge ausführen und führen keine strikte Initialisierung unmittelbar nach der Erstellung durch. Gleichzeitig müssen Manipulationen mit dem benutzerdefinierten Netzwerk und jdbcUrl auch manuell durchgeführt werden.
Verspottet
Es gibt jedoch immer noch Probleme. Zum Beispiel Moki. Manchmal ist es nicht sehr praktisch, eine Abhängigkeit in einem Docker-Container zu erstellen. Wir verwenden den Spark JobServer, der Spark-Jobs erstellt und deren Lebenszyklus in Spark steuert. Wir verwenden zwei seiner Methoden: "erstellen" und "Status geben".
So führen Sie Spark JobServer im Docker aus Es ist notwendig, Spark zu erhöhen, und bis vor kurzem hatte es überhaupt keinen Docker-Container und es war notwendig, ihn selbst zusammenzubauen. Darüber hinaus verwendet Spark JobServer PostgreSQL zum Speichern von Status. Infolgedessen müssen Sie viel schwierige Arbeit leisten, wenn Sie wirklich nur zwei Methoden mit einer einfachen API benötigen.
Sie können jedoch einen Blick in die Implementierung des Spark JobServers werfen und ein Modell erstellen, das sich genauso verhält, jedoch nicht die Abhängigkeiten des ursprünglichen Spark JobServers erfordert.
Es sieht so aus (im Beispiel ein vereinfachter Pseudocode):
val hostIp = ??? AppContainer(sparkJobServerMockHost = hostIp) val sparkJobServerMock = new SparkJobServerMock() sparkJobServerMock.init(someData) val apiResult = appApi.callMethod() assert(apiResult == someData)
http- API Spark JobServer. - , . , , , mock.
- , . : «» config; , host.
SparkJobServerMock , host-, docker-, , , docker-.
? docker-, , gateway , docker-.
, Testcontainers API. , Testcontainers docker-java-, . «» docker-:
val client: com.github.dockerjava.api.DockerClient = DockerClientFactory .instance .client val networkInfo: com.github.dockerjava.api.model.Network = client .inspectNetworkCmd() .withNetworkId(network.getId) .exec() val hostIp: String = networkInfo .getIpam .getConfig .get(0) .getGateway
-,
DockerClient . Testcontainers
DockerClientFactory . c
inspectNetworkCmd . , info, gateway.
, , .
— . Docker : Windows, Mac, . Linux. , , Linux .
, Testcontainers . , docker-. :
Testcontainers.exposeHostPorts(sparkJobServerMockPort)
,
. docker-.
`host.testcontainers.internal` .
, :
val sparkJobServerMockHost = "host.testcontainers.internal" val sparkJobServerMockPort = 33333 Testcontainers.exposeHostPorts(sparkJobServerPort) AppContainer(sparkJobServerMockHost, sparkJobServerMockPort)
Testcontainers
, , Testcontainers , . Java-, Scala-. :
- . , testcontainers-java JUnit, testcontainers-scala ScalaTest, testcontainers-java . Scala- .
- Scala . . , . , predefined Java-. , .
- API . API, . , . , , .
Zusammenfassung
. Docker , , , , network gateway.
Testcontainers — , . API , .
Java-, . — . .
, docker-, .
— , , , . .?, .
— - ?Kubernetes, . end-to-end , , , , .
, , unit-, .
— Kubernetes ?-, , -, , , , Spark Kubernetes ; , .
, , unit-, , , break point , , .
, , , CI , .
, minicube — Mac, . , , , , .
— ? : master? , - , , 2.1, 2.2, ?ImageName, Postgres 9.6.
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6")
9.6, 10. [ ], .
Image tag — , — , . , latest .
— , ?, CI , GitLab CI , , Branch Name.
— , , , ? - , ? 20- , ?-, , . , , , , , .
- , , full-time , , , .
commit', , , , Android, iOS . . , , , , — .
, , -: - , - . , - .
Möchten Sie mehr über die Microservices selbst und nicht nur über Scala erfahren? Unser ScalaConf- Programm bietet Antworten auf verschiedene Fragen. Mehr Interesse an Architektur und den Verbindungen der verschiedenen Teile - kommen Sie vom 7. bis 8. November zu HighLoad ++ .
Alles ist so lecker und es ist nicht klar, was man wählen soll. Abonnieren Sie dann den Newsletter, in dem wir über Berichte sprechen und nützliche Materialien zu diesem Thema sammeln.