Das Captcha-Thema ist nicht neu, auch für Habr. Die Captcha-Algorithmen ändern sich jedoch ebenso wie die Algorithmen zu ihrer Lösung. Daher wird vorgeschlagen, sich an die alte zu erinnern und die folgende Version von Captcha zu betreiben:

Verstehen Sie dabei die Arbeit eines einfachen neuronalen Netzwerks in der Praxis und verbessern Sie auch dessen Ergebnisse.
Machen Sie sofort einen Vorbehalt, dass wir nicht in Gedanken darüber eintauchen, wie das Neuron funktioniert und was damit zu tun ist. Der Artikel behauptet nicht, wissenschaftlich zu sein, sondern bietet nur ein kleines Tutorial.
Vom Herd aus tanzen. Anstatt mitzumachen
Vielleicht werden die Worte von jemandem wiederholt, aber die meisten Bücher über Deep Learning beginnen wirklich damit, dass dem Leser vorbereitete Daten angeboten werden, mit denen er zu arbeiten beginnt. Irgendwie MNIST - 60.000 handschriftliche Ziffern, CIFAR-10 usw. Nach dem Lesen kommt eine Person vorbereitet heraus ... für diese Datensätze. Es ist völlig unklar, wie Sie Ihre Daten verwenden und vor allem, wie Sie beim Aufbau Ihres eigenen neuronalen Netzwerks etwas verbessern können.
Aus diesem Grund war der Artikel auf
pyimagesearch.com über die Arbeit mit Ihren eigenen Daten sowie deren
Übersetzung sehr nützlich.
Aber wie sie sagen, ist Rettich-Meerrettich nicht süßer: Selbst mit der Übersetzung des gekauten Artikels über Keras gibt es viele blinde Flecken. Auch hier wird ein vorbereiteter Datensatz nur für Katzen, Hunde und Pandas angeboten. Müssen die Lücken selbst ausfüllen.
Dieser Artikel und Code werden jedoch als Grundlage verwendet.
Wir sammeln Daten über Captcha
Hier gibt es nichts Neues. Wir brauchen Captcha-Proben, wie Das Netzwerk wird unter unserer Anleitung von ihnen lernen. Sie können das Captcha selbst abbauen oder hier ein wenig nehmen -
29.000 Captchas . Jetzt müssen Sie die Zahlen aus jedem Captcha herausschneiden. Es ist nicht notwendig, alle 29.000 Captcha zu schneiden, zumal 1 Captcha 5 Ziffern ergibt. 500 Captcha werden mehr als genug sein.
Wie schneide ich? In Photoshop ist dies möglich, aber es ist besser, ein besseres Messer zu haben.
Also hier ist der Python Messer Code -
Download . (Für Windows. Erstellen Sie zuerst die Ordner C: \ 1 \ test und C: \ 1 \ test-out.)
Die Ausgabe ist ein Dump mit Zahlen von 1 bis 9 (das Captcha enthält keine Nullen).
Als nächstes müssen Sie diese Blockierung von den Zahlen in Ordner von 1 bis 9 analysieren und durch die entsprechende Nummer in jeden Ordner einfügen. So lala Beruf. Aber an einem Tag können Sie bis zu 1000 Ziffern erkennen.
Wenn es bei der Auswahl einer Nummer zweifelhaft ist, welche der Nummern es ist, ist es besser, dieses Beispiel zu löschen. Und es ist in Ordnung, wenn die Zahlen verrauscht sind oder unvollständig in den "Frame" eingegeben werden:


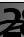
Sie müssen 200 Proben jeder Ziffer in jedem Ordner sammeln. Sie können diese Arbeit an Dienste von Drittanbietern delegieren. Es ist jedoch besser, alles selbst zu erledigen, damit Sie später nicht nach falsch übereinstimmenden Nummern suchen.
Neuronales Netz. Test
Tyat, tyat, unsere Netze zogen den TotenBevor Sie mit Ihren eigenen Daten arbeiten, lesen Sie den obigen Artikel und führen Sie den Code aus, um zu verstehen, dass alle Komponenten (Keras, Tensorflow usw.) installiert sind und ordnungsgemäß funktionieren.
Wir werden ein einfaches Netzwerk verwenden, dessen Startsyntax aus der Befehlszeile (!) Stammt:
python train_simple_nn.py --dataset animals --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
* Tensorflow kann schreiben, wenn Fehler in eigenen Dateien und veraltete Methoden bearbeitet werden. Sie können sie von Hand beheben oder einfach ignorieren.
Die Hauptsache ist, dass nach dem Ausarbeiten des Programms zwei Dateien im Projektprojektordner angezeigt werden: simple_nn_lb.pickle und simple_nn.model, und das Bild des Tieres mit einer Beschriftungs- und Erkennungsrate wird angezeigt, zum Beispiel:

Neuronales Netz - eigene Daten
Nachdem der Netzwerkzustandstest überprüft wurde, können Sie Ihre eigenen Daten verbinden und mit dem Training des Netzwerks beginnen.
Legen Sie in den Ordner dat Ordner Ordner mit Nummern ab, die ausgewählte Stichproben für jede Ziffer enthalten.
Der Einfachheit halber legen wir den Dat-Ordner im Projektordner ab (z. B. neben dem Tierordner).
Die Syntax zum Starten des Netzwerklernens lautet nun:
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Es ist jedoch zu früh, um mit dem Training zu beginnen.
Sie müssen die Datei train_simple_nn.py reparieren.
1. Ganz am Ende der Datei:
Dadurch werden Informationen hinzugefügt.
2.
image = cv2.resize(image, (32, 32)).flatten()
wechseln zu
image = cv2.resize(image, (16, 37)).flatten()
Hier ändern wir die Größe des Eingabebildes. Warum genau diese Größe? Weil die meisten gehackten Ziffern entweder diese Größe haben oder darauf reduziert sind. Wenn Sie auf 32 x 32 Pixel skalieren, wird das Bild verzerrt. Ja und warum?
Darüber hinaus versuchen wir diese Änderung:
try: image = cv2.resize(image, (16, 37)).flatten() except: continue
Weil Das Programm kann einige Bilder und Probleme nicht verarbeiten. Keine, daher werden sie übersprungen.
3. Nun das Wichtigste. Wo es einen Kommentar im Code gibt
Definieren Sie die Architektur 3072-1024-512-3 mit Keras
Die Netzwerkarchitektur im Artikel ist als 3072-1024-512-3 definiert. Dies bedeutet, dass das Netzwerk 3072 (32 Pixel * 32 Pixel * 3) am Eingang empfängt, dann Schicht 1024, Schicht 512 und am Ausgang 3 Optionen - eine Katze, ein Hund oder ein Panda.
In unserem Fall ist die Eingabe 1776 (16 Pixel * 37 Pixel * 3), dann Schicht 1024, Schicht 512, bei der Ausgabe von 9 Varianten von Zahlen.
Deshalb unser Code:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))model.add(Dense(512, activation="sigmoid"))
* 9 Ausgänge müssen nicht zusätzlich angegeben werden, da Das Programm selbst bestimmt die Anzahl der Exits anhand der Anzahl der Ordner im Dataset.
Wir starten
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
Da die Bilder mit Zahlen klein sind, lernt das Netzwerk auch bei schwacher Hardware sehr schnell (5-10 Minuten) und verwendet nur die CPU.
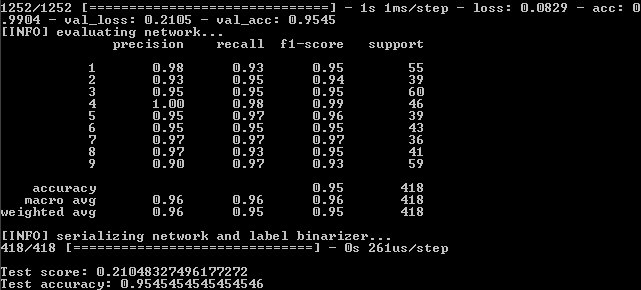
Nachdem Sie das Programm in der Befehlszeile ausgeführt haben, sehen Sie sich die Ergebnisse an:
Dies bedeutet, dass am Trainingssatz eine Wiedergabetreue von 82,19%, bei der Kontrolle von 75,6% und beim Test von 75,59% erreicht wurde.
Wir müssen uns größtenteils auf den letzteren Indikator konzentrieren. Warum die anderen auch wichtig sind, wird später erklärt.
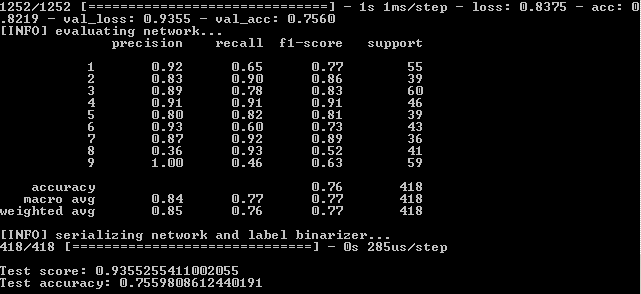
Sehen wir uns auch den grafischen Teil der Arbeit des neuronalen Netzwerks an. Es befindet sich im Ausgabeordner des Projekts simple_nn_plot.png:
Schneller, höher, stärker. Ergebnisse verbessern
Ein bisschen über das Einrichten eines neuronalen Netzwerks, siehe
hier .
Die authentische Option lautet wie folgt.
Epochen hinzufügen.
Im Code ändern wir
EPOCHS = 75
auf
EPOCHS = 200
Erhöhen Sie die "Häufigkeit", mit der das Netzwerk geschult wird.
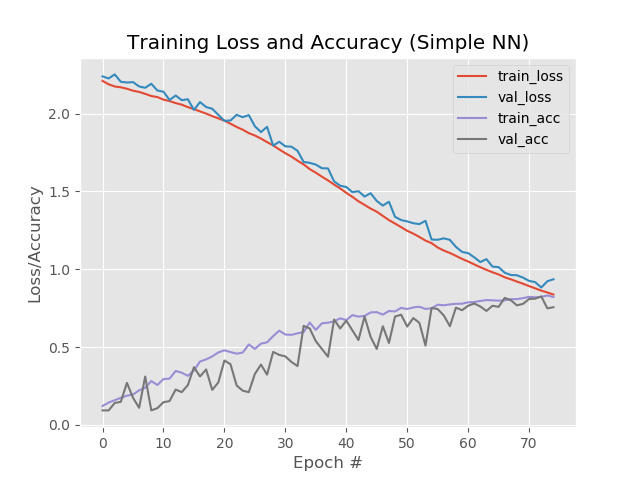
Ergebnis:
Somit 93,5%, 92,6%, 92,6%.
In Bildern:
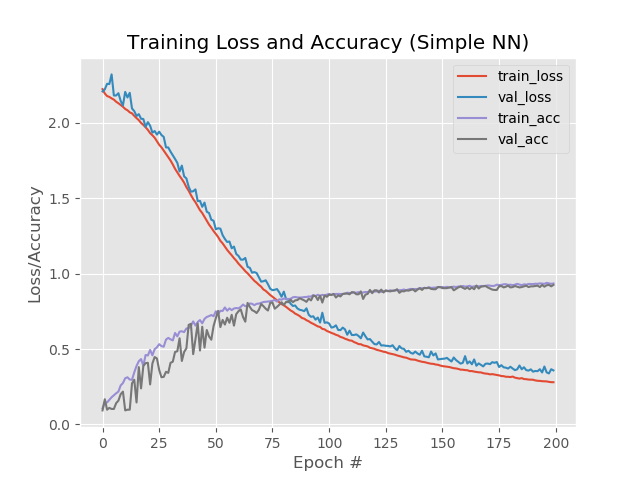
Hier fällt auf, dass sich die blauen und roten Linien nach der 130. Ära voneinander zu lösen beginnen und dies besagt, dass eine weitere Erhöhung der Anzahl der Epochen nicht funktionieren wird. Überprüfen Sie dies heraus.
Im Code ändern wir
EPOCHS = 200
auf
EPOCHS = 500
und wieder weglaufen.
Ergebnis:
Also haben wir:
99%, 95,5%, 95,5%.
Und in der Grafik:
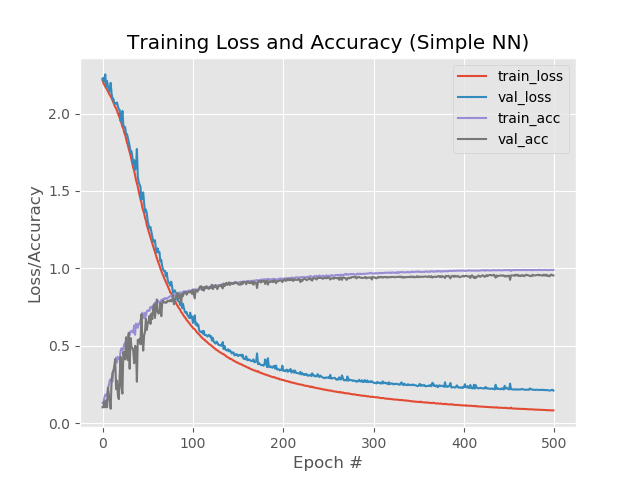
Nun, die Zunahme der Anzahl der Epochen ist eindeutig ins Netz gegangen. Dieses Ergebnis ist jedoch irreführend.
Lassen Sie uns den Netzwerkbetrieb anhand eines realen Beispiels überprüfen.
Zu diesem Zweck befindet sich das Predict.py-Skript im Projektordner. Vor dem Start vorbereiten.
Im Bilderordner des Projekts legen wir die Dateien mit den Bildern von Zahlen aus Captcha ab, auf die das Netzwerk zuvor im Lernprozess nicht gestoßen war. Das heißt, Es ist notwendig, Ziffern zu nehmen, die nicht aus dem Datendatensatz dat stammen.
In der Datei selbst legen wir zwei Zeilen für die Standardbildgröße fest:
ap.add_argument("-w", "--width", type=int, default=16, help="target spatial dimension width") ap.add_argument("-e", "--height", type=int, default=37, help="target spatial dimension height")
Führen Sie über die Befehlszeile aus:
python predict.py --image images/1.jpg --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --flatten 1
Und wir sehen das Ergebnis:
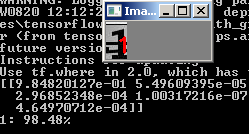
Noch ein Bild:
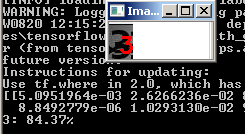
Es funktioniert jedoch nicht mit allen verrauschten Zahlen:
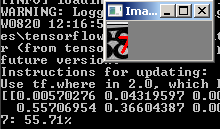
Was kann man hier machen?
- Erhöhen Sie die Anzahl der Kopien von Nummern in den Ordnern für das Training.
- Probieren Sie andere Methoden aus.
Probieren wir andere Methoden aus
Wie Sie der letzten Grafik entnehmen können, weichen die blauen und roten Linien in der 130. Ära voneinander ab. Dies bedeutet, dass das Lernen nach der 130. Ära unwirksam ist. Wir korrigieren das Ergebnis in der 130. Epoche: 89,3%, 88%, 88% und prüfen, ob andere Methoden zur Verbesserung der Netzwerkarbeit funktionieren.
Reduzieren Sie die Lerngeschwindigkeit. INIT_LR = 0.01
auf
INIT_LR = 0.001
Ergebnis:
41%, 39%, 39%
Nun, von.
Fügen Sie eine zusätzliche versteckte Ebene hinzu. model.add(Dense(512, activation="sigmoid"))
auf
model.add(Dense(512, activation="sigmoid")) model.add(Dense(258, activation="sigmoid"))
Ergebnis:
56%, 62%, 62%
Besser, aber nein.
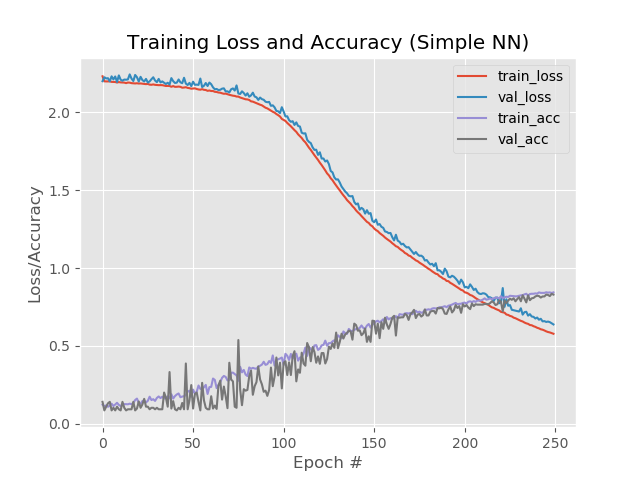
Wenn Sie jedoch die Anzahl der Epochen auf 250 erhöhen:
84%, 83%, 83%
Gleichzeitig lösen sich die roten und blauen Linien nach der 130. Ära nicht mehr voneinander:
 Speichern Sie 250 Epochen und wenden Sie die Ausdünnung an
Speichern Sie 250 Epochen und wenden Sie die Ausdünnung an :
from keras.layers.core import Dropout
Fügen Sie eine Ausdünnung zwischen den Schichten ein:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid")) model.add(Dropout(0.3))
Ergebnis:
53%, 65%, 65%
Der erste Wert ist niedriger als der Rest. Dies zeigt an, dass das Netzwerk nicht lernt. Zu diesem Zweck wird empfohlen, die Anzahl der Epochen zu erhöhen.
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3))
Ergebnis:
88%, 92%, 92%
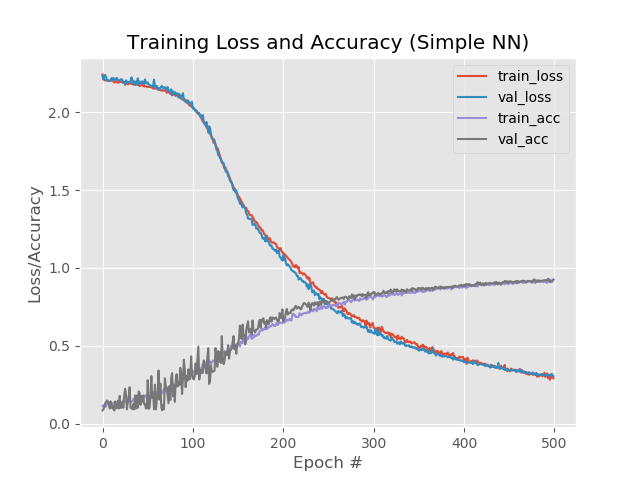
Mit 1 zusätzlichen Schicht, Ausdünnung und 500 Epochen:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid"))
Ergebnis:
92,4%, 92,6%, 92,58%
Trotz eines geringeren Prozentsatzes im Vergleich zu einer einfachen Erhöhung der Epochen auf 500 sieht die Grafik gleichmäßiger aus:
Und das Netzwerk verarbeitet Bilder, die zuvor ausgefallen sind:
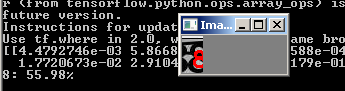
Jetzt werden wir alles in einer Datei sammeln, die das Bild mit dem Captcha an der Eingabe in 5 Ziffern schneidet, jede Ziffer durch das neuronale Netzwerk führt und das Ergebnis an den Python-Interpreter ausgibt.
Hier ist es einfacher. Fügen Sie in der Datei, die uns die Zahlen aus dem Captcha herausschneidet, die Datei hinzu, die sich mit Vorhersagen befasst.
Jetzt schneidet das Programm nicht nur das Captcha in 5 Teile, sondern zeigt auch alle erkannten Zahlen im Interpreter an:

Auch hier muss berücksichtigt werden, dass das Programm nicht 100% des Ergebnisses liefert und häufig eine der 5 Ziffern falsch ist. Dies ist jedoch ein gutes Ergebnis, wenn man bedenkt, dass das Trainingsset nur 170 bis 200 Exemplare pro Nummer enthält.
Die Captcha-Erkennung dauert auf einem Computer mit mittlerer Leistung 3-5 Sekunden.
Wie sonst können Sie versuchen, das Netzwerk zu verbessern? Sie können im Buch "Keras Library - ein Deep-Learning-Tool" A. Dzhulli, S. Pala lesen.
Das letzte Skript, das das Captcha schneidet und erkennt, ist
hier .
Es beginnt ohne Parameter.
Recycelte Skripte zum
Trainieren und
Testen des Netzwerks.
Captcha für den Test, auch mit falsch positiven Ergebnissen -
hier .
Das Modell für die Arbeit ist
hier .
Die Nummern in Ordnern sind
hier .