Suchhinweise sind großartig. Wie oft geben wir die vollständige Site-Adresse in die Adressleiste ein? Und der Name des Produkts im Online-Shop? Für solch kurze Abfragen reicht es normalerweise aus, ein paar Zeichen einzugeben, wenn die Suchhinweise gut sind. Und wenn Sie keine zwanzig Finger oder eine unglaubliche Schreibgeschwindigkeit haben, werden Sie sie sicherlich verwenden.
In diesem Artikel werden wir über unseren neuen Suchhinweisdienst hh.ru sprechen, den wir in der vorherigen Ausgabe der
School of Programmers durchgeführt haben .
Der alte Dienst hatte eine Reihe von Problemen:
- Er arbeitete an handverlesenen, beliebten Benutzeranfragen.
- konnte sich nicht an sich ändernde Benutzereinstellungen anpassen;
- Abfragen, die nicht oben aufgeführt sind, konnten nicht eingestuft werden.
- Tippfehler wurden nicht korrigiert.
Im neuen Service haben wir diese Mängel behoben (während wir neue hinzugefügt haben).
Wörterbuch der populären Abfragen
Wenn überhaupt keine Hinweise vorhanden sind, können Sie die Top-N-Abfragen von Benutzern manuell auswählen und aus diesen Abfragen Hinweise unter Verwendung des genauen Vorkommens von Wörtern (mit oder ohne Reihenfolge) generieren. Dies ist eine gute Option - es ist einfach zu implementieren, bietet eine gute Genauigkeit der Eingabeaufforderungen und weist keine Leistungsprobleme auf. Unser Vorschlag hat lange Zeit so funktioniert, aber ein wesentlicher Nachteil dieses Ansatzes ist die unzureichende Vollständigkeit des Themas.
Zum Beispiel ist die Anfrage "Javascript-Entwickler" nicht in eine solche Liste gefallen. Wenn wir also "Javascript-Zeiten" eingeben, haben wir nichts zu zeigen. Wenn wir die Anfrage ergänzen und nur das letzte Wort berücksichtigen, sehen wir zunächst "Javascript-Handwerker". Aus dem gleichen Grund wird es nicht möglich sein, eine Fehlerkorrektur schwieriger als beim Standardansatz durchzuführen, indem die nächstgelegenen Wörter anhand der Damerau-Levenshtein-Entfernung gefunden werden.
Sprachmodell
Ein anderer Ansatz besteht darin, zu lernen, die Wahrscheinlichkeiten von Abfragen zu bewerten und die wahrscheinlichsten Fortsetzungen für eine Benutzerabfrage zu generieren. Verwenden Sie dazu Sprachmodelle - eine Wahrscheinlichkeitsverteilung auf einer Reihe von Wortsequenzen.
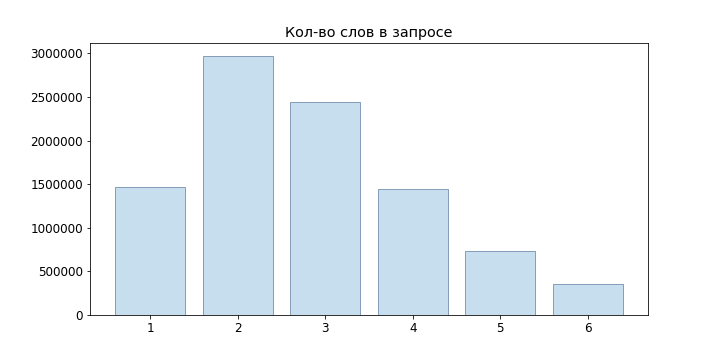
Da Benutzeranfragen meist kurz sind, haben wir nicht einmal Sprachmodelle für neuronale Netze ausprobiert, sondern uns auf n-Gramm beschränkt:
Als einfachstes Modell können wir dann die statistische Definition der Wahrscheinlichkeit nehmen
Ein solches Modell ist jedoch nicht für die Auswertung von Abfragen geeignet, die nicht in unserem Beispiel enthalten waren: Wenn wir den 'Junior Developer Java' nicht beobachtet haben, stellt sich heraus, dass
Um dieses Problem zu lösen, können Sie verschiedene Modelle der Glättung und Interpolation verwenden. Wir haben Backoff verwendet:
Wobei P die geglättete Wahrscheinlichkeit ist
(Wir haben Laplace-Glättung verwendet):
wo V unser Wörterbuch ist.
Optionsgenerierung
Wir können also die Wahrscheinlichkeit einer bestimmten Anfrage einschätzen, aber wie können dieselben Anfragen generiert werden? Es ist ratsam, Folgendes zu tun: Lassen Sie den Benutzer eine Abfrage eingeben
Dann können die für uns geeigneten Abfragen aus der Bedingung ermittelt werden
Natürlich sortieren
Es ist nicht möglich, die besten Optionen für jede eingehende Anfrage auszuwählen.
Daher verwenden wir die
Strahlensuche . Für unser n-Gramm-Sprachmodell kommt es auf den folgenden Algorithmus an:
def beam(initial, vocabulary): variants = [initial] for i in range(P): candidates = [] for variant in variants: candidates.extends(generate_candidates(variant, vocabulary)) variants = sorted(candidates)[:N] return candidates def generate_candidates(variant, vocabulary): top_terms = []

Hier sind die grün hervorgehobenen Knoten die endgültig ausgewählten Optionen, die Nummer vor dem Knoten
- Wahrscheinlichkeit
, nach dem Knoten -
.
Es ist viel besser geworden, aber in generate_candidates müssen Sie schnell N beste Begriffe für einen bestimmten Kontext erhalten. Wenn nur die Wahrscheinlichkeiten von n-Gramm gespeichert werden, müssen wir das gesamte Wörterbuch durchgehen, die Wahrscheinlichkeiten aller möglichen Phrasen berechnen und sie dann sortieren. Offensichtlich wird dies bei Online-Abfragen nicht funktionieren.
Bor für Wahrscheinlichkeiten
Um schnell die N besten in bedingten Wahrscheinlichkeitsvarianten der Fortsetzung der Phrase zu erhalten, verwendeten wir Bor in Begriffen. Im Knoten
gespeicherter Koeffizient
Wert
und sortiert nach bedingter Wahrscheinlichkeit
Liste der Begriffe
zusammen mit
. Der Sonderbegriff
eos markiert das Ende einer Phrase.
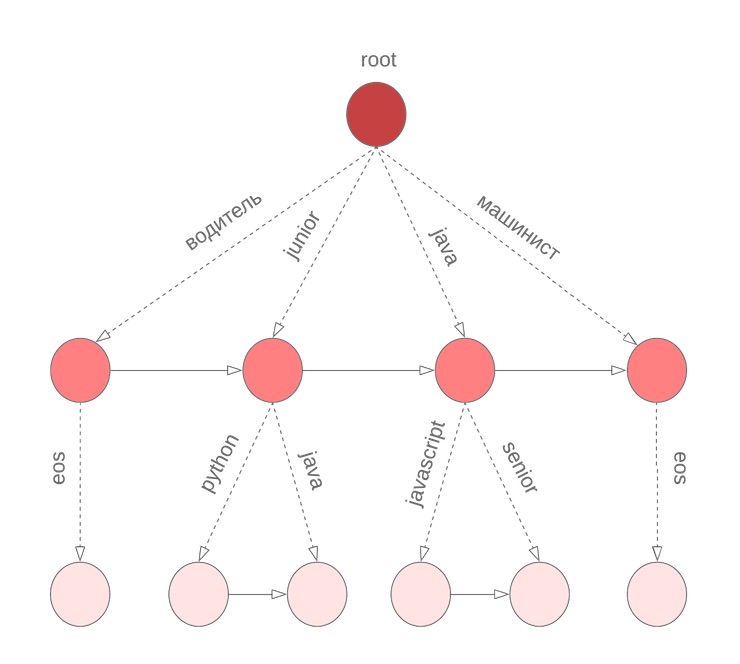
Aber es gibt eine Nuance
Bei dem oben beschriebenen Algorithmus wird davon ausgegangen, dass alle Wörter in der Abfrage abgeschlossen wurden. Dies gilt jedoch nicht für das letzte Wort, das der Benutzer gerade eingibt. Wir müssen erneut das gesamte Wörterbuch durchgehen, um das aktuell eingegebene Wort fortzusetzen. Um dieses Problem zu lösen, verwenden wir ein symbolisches Bor, in dessen Knoten wir M Terme speichern, sortiert nach der Unigrammwahrscheinlichkeit. Zum Beispiel sieht dies aus wie unser Bor für Java, Junior, Jupiter, Javascript mit M = 3:

Bevor wir mit der Strahlensuche beginnen, finden wir die M besten Kandidaten, um das aktuelle Wort fortzusetzen
und wählen Sie die N besten Kandidaten für
.
Tippfehler
Nun, wir haben einen Service entwickelt, mit dem Sie gute Hinweise für eine Benutzeranfrage geben können. Wir sind sogar bereit für neue Wörter. Und alles wäre in Ordnung ...
Aber Benutzer passen auf und wechseln nicht die Tastaturen.Wie kann man das lösen? Das erste, was mir in den Sinn kommt, ist die Suche nach Korrekturen, indem die nächstgelegenen Optionen für den Abstand Damerau-Levenshtein gefunden werden. Dies ist definiert als die Mindestanzahl an Einfügungen / Löschungen / Ersetzungen eines Zeichens oder die Transposition zweier benachbarter Zeichen, die erforderlich sind, um ein anderes aus einer Zeile zu erhalten. Leider berücksichtigt dieser Abstand nicht die Wahrscheinlichkeit eines bestimmten Ersatzes. Für das eingegebene Wort "Sapper" erhalten wir also, dass die Optionen "Sammler" und "Schweißer" gleichwertig sind, obwohl es intuitiv so aussieht, als hätten sie das zweite Wort im Sinn.
Das zweite Problem ist, dass wir den Kontext, in dem der Fehler aufgetreten ist, nicht berücksichtigen. Zum Beispiel sollten wir in der Abfrage "Order Sapper" immer noch die Option "Collector" anstelle von "Welder" bevorzugen.
Wenn Sie sich der Aufgabe nähern, Tippfehler unter probabilistischen Gesichtspunkten zu korrigieren, ist es ganz natürlich, zu einem
Modell eines verrauschten Kanals zu gelangen :
- Alphabet gesetzt ;;
- Satz aller nachgestellten Linien über ihn;
- viele Zeilen, die richtige Wörter sind ;;
- gegebene Verteilungen wo .
Dann wird die Korrekturaufgabe so eingestellt, dass das richtige Wort w für die Eingabe s gefunden wird. Messen Sie je nach Fehlerquelle
Es kann auf verschiedene Arten erstellt werden. In unserem Fall ist es ratsam, die Wahrscheinlichkeit von Tippfehlern abzuschätzen (nennen wir sie elementare Ersetzungen).
, wobei t, r symbolische n-Gramm sind, und dann auswerten
als die Wahrscheinlichkeit, s von w durch die wahrscheinlichsten elementaren Ersetzungen zu erhalten.
Lass
- Aufteilen der Zeichenfolge x in n Teilzeichenfolgen (möglicherweise Null). Das Brill-Moore-Modell beinhaltet die Berechnung der Wahrscheinlichkeit
wie folgt:
P (s | w) \ ungefähr \ max_ {R \ in Teil_n (s)} T \ in Teil_n (s)} \ prod_ {i = 1} ^ {n} P_e (T_i | R_i)
Aber wir müssen finden
::
Indem wir lernen, P (w | s) zu bewerten, lösen wir auch das Problem der Rangfolgeoptionen mit derselben Damerau-Levenshtein-Entfernung und können den Kontext bei der Korrektur eines Tippfehlers berücksichtigen.
Berechnung
Um die Wahrscheinlichkeiten elementarer Substitutionen zu berechnen, helfen uns Benutzerabfragen erneut: Wir werden Wortpaare (s, w) zusammenstellen, die
- nah in Damerau-Levenshtein;
- Eines der Wörter ist häufiger als das andere N-mal.
Für solche Paare betrachten wir die optimale Ausrichtung nach Levenshtein:
Wir setzen alle möglichen Partitionen von s und w zusammen (wir haben uns auf die Längen n = 2, 3 beschränkt): n → n, pr → rn, pro → rn, ro → po, m → ``, mm → m usw. Für jedes n-Gramm finden wir
Berechnung
Berechnung
direkt nimmt
: Wir müssen alle möglichen Partitionen von w mit allen möglichen Partitionen von s sortieren. Die Dynamik des Präfixes kann jedoch eine Antwort geben
Dabei ist n die maximale Länge der elementaren Substitutionen:
d [i, j] = \ begin {Fälle} d [0, j] = 0 & j> = k \\ d [i, 0] = 0 & i> = k \\ d [0, j] = P (s [0: j] \ Raum | \ Raum w [0]) & j <k \\ d [i, 0] = P (s [0] \ Raum | \ Raum w [0: i]) & i <k \\ d [i, j] = \ underset {k, l \ le n, k \ lt i, l \ lt j} {max} (P (s [jl: j] \ space | \ space w) [ik: i]) \ cdot d [ik-1, jl-1]) \ end {case}
Hier ist P die Wahrscheinlichkeit der entsprechenden Zeile im k-Gramm-Modell. Wenn Sie genau hinschauen, ist es dem Wagner-Fisher-Algorithmus mit Ukkonen-Clipping sehr ähnlich. Bei jedem Schritt bekommen wir
durch Auflisten aller Korrekturen
in
vorbehaltlich
und die Wahl des wahrscheinlichsten.
Zurück zu
Also können wir rechnen
. Jetzt müssen wir mehrere Optionen zur Maximierung auswählen
. Genauer gesagt für die ursprüngliche Anfrage
du musst wählen
wo
maximal. Leider passte eine ehrliche Auswahl an Optionen nicht zu unseren Anforderungen an die Reaktionszeit (und die Projektfrist ging zu Ende), sodass wir uns auf den folgenden Ansatz konzentrierten:
- Aus der ursprünglichen Abfrage erhalten wir mehrere Optionen, indem wir die k letzten Wörter ändern:
- Wir korrigieren das Tastaturlayout, wenn der resultierende Term eine um ein Vielfaches höhere Wahrscheinlichkeit als der ursprüngliche hat.
- wir finden Wörter, deren Damerau-Levenshtein-Abstand d nicht überschreitet;
- Wählen Sie aus diesen Top-N-Optionen für ;;
- Senden Sie BeamSearch zusammen mit der ursprünglichen Anforderung an die Eingabe.
- Bei der Rangfolge der Ergebnisse werden die erhaltenen Optionen abgezinst .
Für Abschnitt 1.2 haben wir den FB-Trie-Algorithmus (Vorwärts- und Rückwärts-Trie) verwendet, der auf der Fuzzy-Suche in den Vorwärts- und Rückwärts-Präfixbäumen basiert. Dies erwies sich als schneller als die Auswertung von P (s | w) im gesamten Wörterbuch.
Abfragestatistik
Mit der Erstellung des Sprachmodells ist alles einfach: Wir sammeln Statistiken zu Benutzerabfragen (wie oft haben wir eine Abfrage für eine bestimmte Phrase durchgeführt, wie viele Benutzer, wie viele registrierte Benutzer), teilen Anforderungen in n-Gramm auf und erstellen Bohrer. Komplizierter mit dem Fehlermodell: Zum Erstellen wird mindestens ein Wörterbuch mit den richtigen Wörtern benötigt. Wie oben erwähnt, haben wir zur Auswahl der Trainingspaare die Annahme verwendet, dass solche Paare in der Entfernung Damerau-Levenshtein nahe beieinander liegen sollten und eines häufiger als das andere mehrmals auftreten sollte.
Die Daten sind jedoch immer noch zu verrauscht: xss-Injektionsversuche, falsches Layout, zufälliger Text aus der Zwischenablage, erfahrene Benutzer mit den Anforderungen „Programmierer c nicht 1c“,
Anforderungen der Katze, die über die Tastatur gesendet wurden.
Was haben Sie beispielsweise versucht, durch eine solche Anfrage zu finden? Um die Quelldaten zu löschen, haben wir daher Folgendes ausgeschlossen:
- Niederfrequenzterme;
- Enthält Abfragesprachenoperatoren
- obszöner Wortschatz.
Sie korrigierten auch das Tastaturlayout und verglichen es mit Wörtern aus den Texten von Stellenangeboten und offenen Wörterbüchern. Natürlich war es nicht möglich, alles zu reparieren, aber solche Optionen sind normalerweise entweder vollständig abgeschnitten oder befinden sich am Ende der Liste.
In prod
Kurz vor dem Projektschutz starteten sie einen Service in der Produktion für interne Tests und nach ein paar Tagen - für 20% der Benutzer. In hh.ru durchlaufen alle Änderungen, die für Benutzer von Bedeutung sind, ein
System von AB-Tests , mit denen wir nicht nur die Bedeutung und Qualität der Änderungen
überprüfen , sondern auch
Fehler finden können .
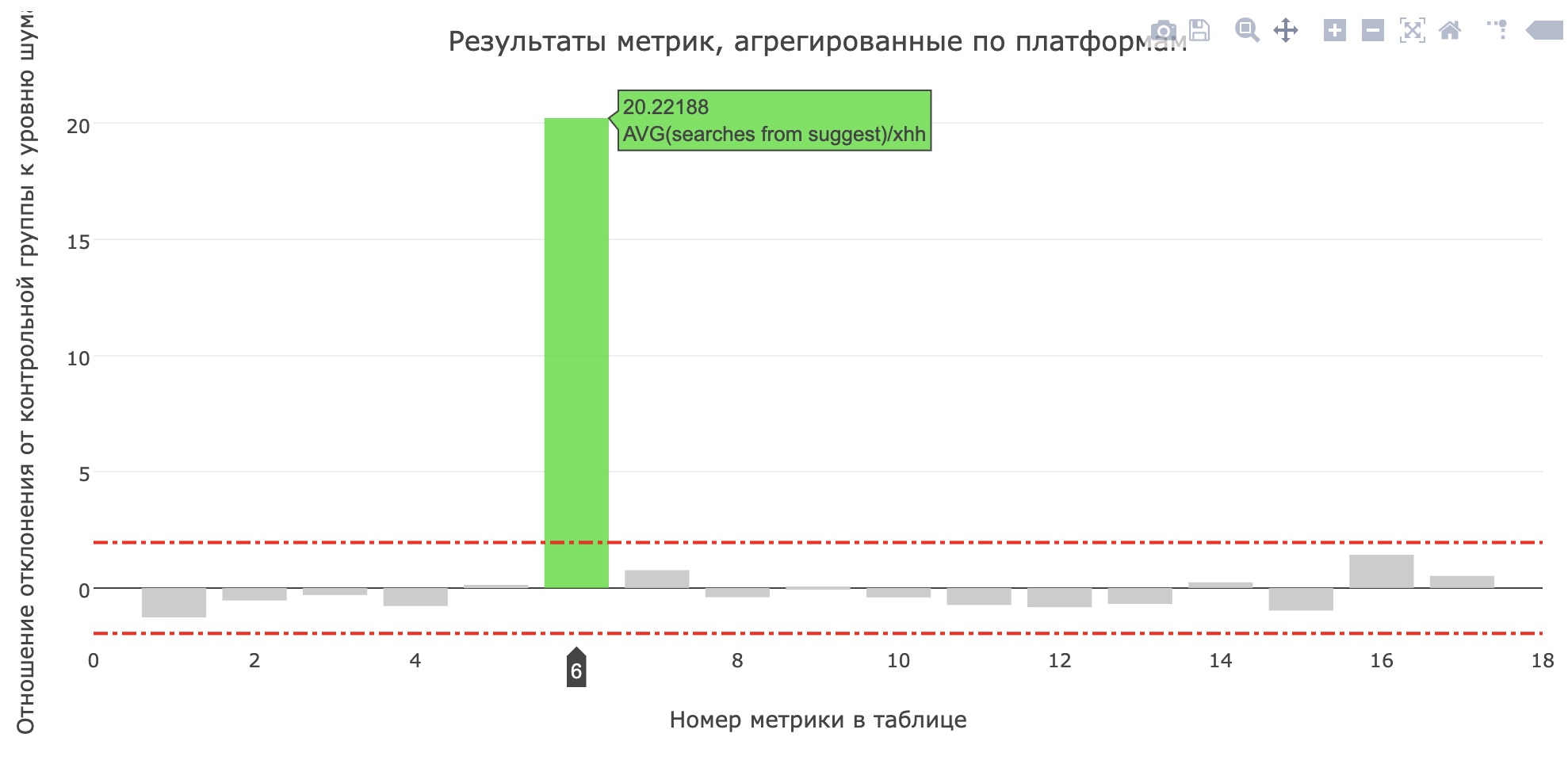
Die Metrik der durchschnittlichen Anzahl von Suchanfragen aus dem Sujest für Bewerber hat sich aufgehellt (von 0,959 auf 1,1355), und der Anteil der Suchanfragen aus dem Sujest aller Suchanfragen ist von 12,78% auf 15,04% gestiegen. Leider sind die wichtigsten Produktmetriken nicht gewachsen, aber die Benutzer haben definitiv begonnen, mehr Tipps zu verwenden.
Am Ende
Es gab keinen Platz für eine Geschichte über die Prozesse der Schule, andere getestete Modelle, die Tools, die wir für Modellvergleiche geschrieben haben, und Besprechungen, in denen wir entschieden haben, welche Funktionen entwickelt werden sollen, um eine Zwischendemo zu erhalten. Schauen Sie sich die
Aufzeichnungen der vergangenen Schule an , hinterlassen Sie eine Anfrage unter
https://school.hh.ru , erledigen Sie interessante Aufgaben und kommen Sie zum Lernen. Übrigens wurde der Service zur Überprüfung von Aufgaben auch von den Absolventen des vorherigen Satzes durchgeführt.
Was zu lesen?
- Einführung in das Sprachmodell
- Brill-Moore-Modell
- Fb-trie
- Was passiert mit Ihrer Suchanfrage?