In diesem Artikel werde ich unsere Erfahrungen mit der Migration von Preply nach Kubernetes beschreiben, wie und warum wir dies getan haben, auf welche Schwierigkeiten wir gestoßen sind und welche Vorteile wir erzielt haben.

Kubernetes für Kubernetes? Nein, geschäftliche Anforderungen!
Rund um Kubernetes gibt es viel Hype und das aus gutem Grund. Viele Leute sagen, dass es alle Probleme lösen wird, einige sagen, dass Sie höchstwahrscheinlich keine Kubernetes benötigen . Die Wahrheit liegt natürlich irgendwo dazwischen.

Alle diese Diskussionen darüber, wo und wann Kubernetes benötigt wird, verdienen jedoch einen separaten Artikel. Jetzt werde ich ein wenig über unsere Geschäftsanforderungen und die Funktionsweise von Preply vor der Migration zu Kubernetes sprechen:
- Als wir Skullcandy Flow verwendeten , hatten wir viele Zweige, die alle zu einem gemeinsamen Zweig namens
stage-rc verschmolzen und auf der Bühne eingesetzt wurden. Das QA-Team testete diese Umgebung, nachdem der Zweig im Master fröhlich getestet und der Master auf dem Produkt bereitgestellt worden war. Der gesamte Vorgang dauerte ca. 3-4 Stunden und wir konnten 0 bis 2 Mal am Tag bereitstellen - Als wir den defekten Code für das Produkt bereitstellten, mussten wir alle Änderungen, die in der neuesten Version enthalten waren, zurücksetzen. Es war auch schwierig zu finden, welche Änderung unser Produkt beschädigte
- Wir haben AWS Elastic Beanstalk zum Hosten unserer Anwendung verwendet. In unserem Fall dauerte jede Beanstalk-Bereitstellung 45 Minuten (die gesamte Pipeline zusammen mit den Tests wurde in 90 Minuten erstellt ). Das Zurücksetzen auf die vorherige Version der Anwendung dauerte 45 Minuten
Um unsere Produkte und Prozesse im Unternehmen zu verbessern, wollten wir:
- Brechen Sie einen Monolithen in Microservices
- Stellen Sie schneller und häufiger bereit
- Rollback schneller
- Ändern Sie unseren Entwicklungsprozess, weil wir dachten, dass er nicht mehr effektiv ist
Unsere Bedürfnisse
Wir verändern den Entwicklungsprozess
Um unsere Innovationen mit Skullcandy Flow umzusetzen, mussten wir für jede Branche eine dynamische Umgebung schaffen. Bei unserem Ansatz mit Anwendungskonfiguration in Elastic Beanstalk war dies schwierig und teuer. Wir wollten Umgebungen schaffen, die:
- Schnell und einfach bereitzustellen (vorzugsweise Container)
- Arbeitete vor Ort Instanzen
- Sie waren ähnlich wie Prod
Wir haben uns für Trunk-Based Development entschieden. Mit seiner Hilfe verfügt jedes Feature über einen eigenen Zweig, der unabhängig vom Rest zu einem Master zusammengeführt werden kann. Ein Hauptzweig kann jederzeit bereitgestellt werden.
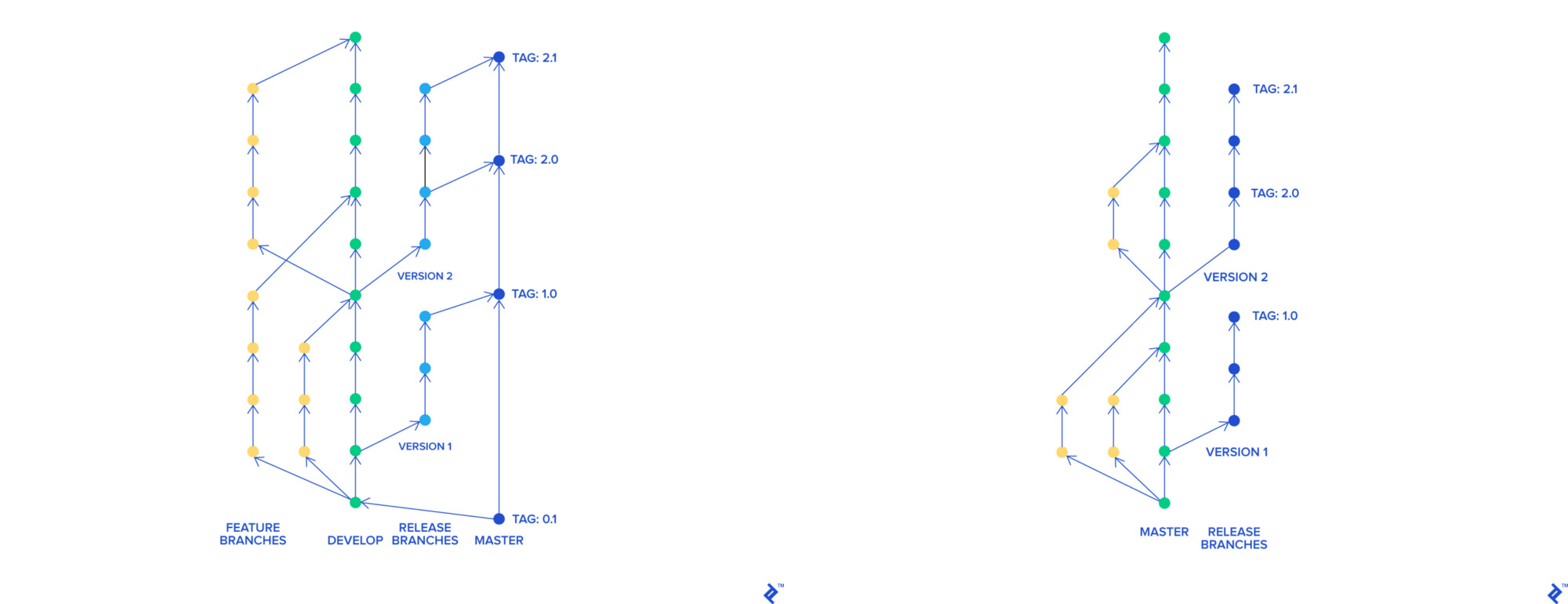
Git-Flow und Trunk-Based Development
Stellen Sie schneller und häufiger bereit
Mit dem neuen Trunk-basierten Prozess konnten wir Innovationen schneller nacheinander an die Hauptniederlassung liefern. Dies hat uns sehr geholfen, defekten Code im Produkt zu finden und zurückzusetzen. Die Bereitstellungszeit betrug jedoch immer noch 90 Minuten und die Rollback-Zeit 45 Minuten. Aus diesem Grund konnten wir die Bereitstellung nicht häufiger 4-5 Mal pro Tag durchführen.
Bei der Verwendung der Servicearchitektur für Elastic Beanstalk sind ebenfalls Probleme aufgetreten. Die naheliegendste Lösung bestand darin, Container und Instrumente zu verwenden, um sie zu orchestrieren. Darüber hinaus hatten wir bereits Erfahrung mit Docker und Docker-Compose für die lokale Entwicklung.
Unser nächster Schritt war die Erforschung der beliebten Container-Orchestratoren:
- AWS ECS
- Schwarm
- Apache Mesos
- Nomad
- Kubernetes
Wir haben uns entschieden, bei Kubernetes zu bleiben, und deshalb. Unter den fraglichen Orchestratoren hatte jeder einen wichtigen Fehler: ECS ist eine herstellerabhängige Lösung, Swarm hat bereits die Kubernetes-Lorbeeren verloren, Apache Mesos sah mit seinen Zookeepern wie ein Raumschiff für uns aus. Nomad schien interessant zu sein, aber es zeigte sich nur in der Integration mit anderen Hashicorp-Produkten vollständig. Wir waren auch enttäuscht, dass die Namespaces in Nomad bezahlt wurden.
Trotz seiner hohen Einstiegsschwelle ist Kubernetes der De-facto-Standard in der Container-Orchestrierung. Kubernetes as a Service ist bei den meisten großen Cloud-Anbietern verfügbar. Das Orchester befindet sich in aktiver Entwicklung, hat eine große Community von Benutzern und Entwicklern und eine gute Dokumentation.
Wir haben erwartet, dass unsere Plattform in einem Jahr vollständig auf Kubernetes migriert wird. Zwei Plattformingenieure ohne Kubernetes-Erfahrung waren an der Teilstartmigration beteiligt.
Verwenden von Kubernetes
Wir haben mit dem Proof of Concept begonnen, einen Testcluster erstellt und alles, was wir getan haben, detailliert dokumentiert. Wir haben uns für Kops entschieden , da EKS in unserer Region zu diesem Zeitpunkt noch nicht verfügbar war (in Irland wurde dies im September 2018 angekündigt).
Während der Arbeit mit dem Cluster haben wir Cluster-Autoscaler , Cert-Manager , Prometheus, Integrationen mit Hashicorp Vault, Jenkins und vieles mehr getestet. Wir haben mit Rolling-Update-Strategien „gespielt“, waren mit mehreren Netzwerkproblemen konfrontiert, insbesondere mit DNS , und haben unser Wissen über Cluster-Clustering gestärkt.
Sie verwendeten Spot-Instanzen , um die Infrastrukturkosten zu optimieren. Um Benachrichtigungen über Spot- Probleme zu erhalten, verwendeten sie den Kube-Spot-Termination-Notice-Handler . Spot Instance Advisor kann Ihnen bei der Auswahl des Spot-Instanztyps helfen.
Wir haben die Migration von Skullcandy Flow zu Trunk-basierter Entwicklung gestartet, wo wir für jede Pulrequest eine dynamische Phase gestartet haben. Dadurch konnten wir die Lieferzeit für neue Funktionen von 4-6 auf 1-2 Stunden reduzieren .
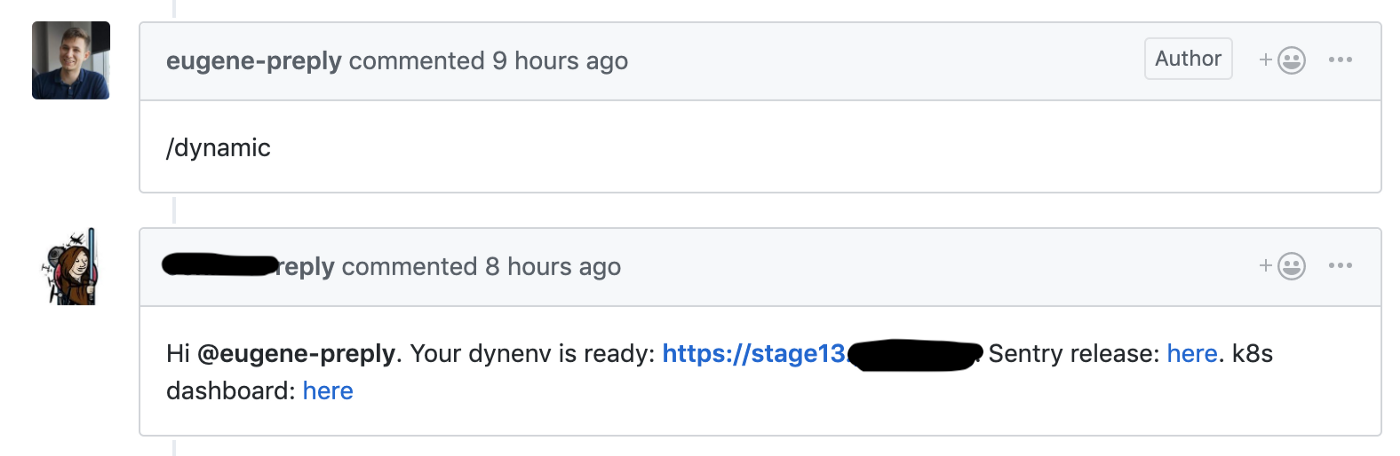
Github Hook startet die Erstellung einer dynamischen Umgebung für Pull-Anforderungen
Wir haben einen Testcluster für diese dynamischen Umgebungen verwendet. Jede Umgebung befand sich in einem separaten Namespace. Entwickler hatten Zugriff auf das Kubernetes Dashboard, um ihren Code zu debuggen.
Wir sind froh, dass wir bereits 1-2 Monate nach Beginn der Nutzung von Kubernetes profitieren konnten.
Bühnen- und Verkaufscluster
Unsere Einstellungen für Bühnen- und Produktcluster:
- kops und Kubernetes 1.11 (die neueste Version zum Zeitpunkt der Clustererstellung)
- Drei Hauptknoten in verschiedenen Zugriffszonen
- Private Netzwerktopologie mit dedizierter Bastion, Calico CNI
- Prometheus zum Sammeln von Metriken wird im selben Cluster wie PVC bereitgestellt (es ist zu berücksichtigen, dass wir Metriken nicht lange speichern).
- Datadog Agent für APM
- Dex + dex-k8s-Authentifikator , um Entwicklern Zugriff auf den Cluster zu gewähren
- Knoten für Bühnencluster arbeiten vor Ort
Bei der Arbeit mit Clustern sind verschiedene Probleme aufgetreten. Beispielsweise unterschieden sich die Versionen des Nginx Ingress- und Datadog-Agenten in den Clustern. In diesem Zusammenhang funktionierten einige Dinge im Stage-Cluster, aber nicht im Produkt. Aus diesem Grund haben wir uns entschlossen, die Softwareversionen in den Clustern vollständig einzuhalten, um solche Fälle zu vermeiden.
Prod nach Kubernetes migrieren
Bühnen- und Lebensmittelcluster sind bereit, und wir sind bereit, mit der Migration zu beginnen. Wir verwenden Monorepa mit folgender Struktur:
. ├── microservice1 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microservice2 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microserviceN │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── helm │ ├── microservice1 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microservice2 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microserviceN │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml └── Jenkinsfile
Die Stamm- Jenkinsfile enthält eine Korrespondenztabelle zwischen dem Namen des Mikrodienstes und dem Verzeichnis, in dem sich sein Code befindet. Wenn der Entwickler die Pull-Anforderung an den Master hält, wird in GitHub ein Tag erstellt. Dieses Tag wird mithilfe von Jenkins gemäß der Jenkins-Datei auf dem Produkt bereitgestellt.
Das helm/ Verzeichnis enthält HELM-Diagramme mit zwei separaten Wertedateien für Bühne und Verkauf. Wir verwenden Skaffold, um viele HELM-Diagramme auf der Bühne bereitzustellen. Wir haben versucht, die Schirmtabelle zu verwenden, haben jedoch festgestellt, dass die Skalierung schwierig ist.
In Übereinstimmung mit der Zwölf-Faktor-App schreibt jeder neue Mikrodienst im Produkt Protokolle in stdout, liest Geheimnisse aus Vault und verfügt über eine Reihe grundlegender Warnungen (Überprüfung der Anzahl der funktionierenden Herde, fünfhundert Fehler und Latens beim Eintritt).
Unabhängig davon, ob wir neue Funktionen in Microservices importieren oder nicht, in unserem Fall liegt die Hauptfunktionalität im Django-Monolithen, und dieser Monolith funktioniert immer noch mit Elastic Beanstalk.

Brechen Sie den Monolithen in Microservices // Der Vigeland Park in Oslo
Wir haben AWS Cloudfront als CDN verwendet und damit eine kanarische Bereitstellung während unserer Migration. Wir haben begonnen, den Monolithen auf Kubernetes zu migrieren und ihn auf einigen Sprachversionen und auf den internen Seiten der Site (wie dem Admin-Panel) zu testen. Ein ähnlicher Migrationsprozess ermöglichte es uns, Fehler auf dem Produkt zu erkennen und unsere Bereitstellungen in nur wenigen Iterationen zu verbessern. Innerhalb weniger Wochen haben wir den Zustand der Plattform, die Auslastung und die Überwachung überwacht, und am Ende wurden 100% des Verkaufsverkehrs auf Kubernetes umgestellt.
Danach konnten wir die Verwendung von Elastic Beanstalk vollständig ablehnen.
Zusammenfassung
Die vollständige Migration dauerte 11 Monate, wie oben erwähnt. Wir planten, die Frist von 1 Jahr einzuhalten.
Tatsächlich sind die Ergebnisse offensichtlich:
- Die Bereitstellungszeit verringerte sich von 90 Minuten auf 40 Minuten
- Die Anzahl der Bereitstellungen stieg von 0-2 auf 10-15 pro Tag (und wächst immer noch!)
- Die Rollback-Zeit verringerte sich von 45 auf 1-2 Minuten
- Wir können problemlos neue Microservices an das Produkt liefern
- Wir haben unsere Überwachung, Protokollierung und Verwaltung von Geheimnissen aufgeräumt, sie zentralisiert und als Code beschrieben
Es war eine sehr coole Migrationserfahrung und wir arbeiten immer noch an vielen Plattformverbesserungen. Lesen Sie unbedingt den coolen Artikel über die Erfahrungen mit Kubernetes aus dem Jura. Er war einer der YAML-Ingenieure, die an der Implementierung von Kubernetes in Preply beteiligt waren.