In der Welt der Kryptographie gibt es viele einfache Möglichkeiten, eine Nachricht zu verschlüsseln. Jeder von ihnen ist auf seine Weise gut. Einer von ihnen wird diskutiert.
Ylchu Schzzkgow
Oder übersetzt von "Caesars Chiffre" ins Russische - Caesars Chiffre .

- Was ist seine Essenz?
- Er verschlüsselt die Nachricht und verschiebt jeden Buchstaben um N Punkte. Caesars klassische Chiffre bewegt Buchstaben drei Schritte vorwärts. In einfachen Worten - es war "abv", es wurde "wo".
"Aber was ist mit den Buchstaben am Ende des Alphabets?" Was ist mit Räumen?
Es geht ihnen gut. Wenn Sie den Buchstaben verschieben, geht die Chiffre über den Rahmen des Alphabets hinaus - sie beginnt erneut zu zählen. Das heißt, die Buchstaben "Eyuya" werden zu "abv". Und Räume bleiben Räume.
- Sollte N unbedingt gleich drei sein?
Überhaupt nicht. N kann von drei abweichen. Jedes N zwischen [1: M-1] ist zulässig, wobei M die Anzahl der Buchstaben im Alphabet ist.
Eine solche Chiffre ist leicht zu entziffern, wenn Sie über ihre Existenz Bescheid wissen. Aber es war nicht seine „Zuverlässigkeit“, die mich anzog, sondern etwas anderes.
Krawatte
An einem Sommertag wollte ich wissen:
- Aber was ist, wenn ich ein Wort mit Caesar verschlüssele und am Ausgang ein vorhandenes Wort erhalte?
- Wie viele solcher Wörter sind "Shifter"?
- Und wird es ein Muster geben, wenn N geändert wird?
In den gleichen Minuten suchte ich nach Antworten auf diese Fragen.
Aufgabe: Finde alle Wörter
Rückzug. Aus den Konzerten von Michail Zadornow und persönlichen Erfahrungen habe ich zwei Dinge verstanden:
- Die Amerikaner sind nicht beleidigt über die Rede russischer Komiker.
- Die russische Sprache ist stark und mächtig. Und es gibt viele Wörter darin.
Deshalb habe ich mich für die englische Sprache entschieden. Außerdem gab es einmal Infa, dass die englischsprachigen Leute ein komplettes Wörterbuch mit englischen Wörtern zusammenstellen konnten. Was mich dazu veranlasste, einen solchen Datensatz zu finden.
Die erste Zeile des trägen Googelns brachte mich in dieses Repository . Der Autor versprach 479.000 englische Wörter in praktischen Formaten. Ich mochte die JSON-Datei, in der alle Wörter in einer praktischen Form zum Laden in das Python-Wörterbuch angeordnet waren.
Nach der ersten Autopsie stellte sich heraus, dass es weniger Wörter gab - 370 101 Stück. "Aber das spielt keine Rolle, denn für ein gutes Beispiel wird es ausreichen", dachte ich.
words = json.load(open('words_dictionary.json', 'r')) len(words.keys()) >> 370101
Zuerst müssen Sie ein Alphabet erstellen. Ich beschloss, es auf die für mich bequemste Weise zu einer Liste zu machen. Es war auch notwendig, sich die Anzahl der Buchstaben im Alphabet zu merken:
abc = list('abcdefghijklmnopqrstuvwxyz') abc_len = len(abc)
Zunächst war es interessant, die Funktion der Übersetzung eines Wortes in verschlüsselt zu gestalten. Folgendes ist passiert:
Ich beschloss, aus allen Wörtern einen großen Zyklus zu machen und sie einzeln zu übersetzen. Kam aber auf ein Problem. Es stellte sich heraus, dass einige Wörter ein „-“ enthielten, was überraschend und natürlich zugleich war.
Ohne nachzudenken, zählte ich die Anzahl solcher Wörter und es stellte sich heraus, dass es nur zwei davon gab. Danach hat er beide gelöscht, da dies das Ergebnis kaum beeinflussen wird. Um mir zu helfen, wurde diese Funktion geboren:
Das Wörterbuch sah aus wie:
{'a': 1, 'aa': 1, 'aaa': 1, 'aah': 1, ... }
Deshalb habe ich mich entschieden, nicht schlau zu sein und diese durch verschlüsselte Wörter zu ersetzen. Dazu schrieb eine Funktion:
Und natürlich brauchten wir einen großen Zyklus, der alle Wörter durchläuft, die Wortschieber findet und das Ergebnis speichert. Da ist er:
Möglicherweise haben Sie bemerkt, dass in den Parametern der Funktion "min_len = 0" steht. Er wird in Zukunft gebraucht. Für die Besonderheit dieses Datensatzes war ein "seltsamer" Satz von Wörtern. Wie zum Beispiel: "aa", "aah" und ähnliche Kombinationen. Sie waren es, die das erste Ergebnis lieferten - 660 Wortschieber.
Daher musste ich ein Limit von fünf mindestens fünf Zeichen festlegen, damit die Wörter für das Auge angenehm und den vorhandenen ähnlich waren.
words_result = check_all(words_cesar, min_len=5) words_result >> {'abime': 'delph', 'biabo': 'elder', 'bifer': 'elihu', 'cobra': 'freud', 'colob': 'frore', 'oxime': 'ralph', 'pelta': 'showd', 'primero': 'sulphur', 'teloi': 'whorl', 'xerox': 'ahura'}
Ja, dank des Algorithmus wurden zehn Flip-Wörter gefunden. Meine Lieblingskombination:
Primero [First] → Schwefel [Schwefel]. Die meisten anderen Paare erkennt Google Übersetzer nicht.
Zu diesem Zeitpunkt habe ich den Wissensdurst teilweise gestillt. Aber vor uns standen Fragen wie: "Was ist mit dem anderen N?"
Und mit dieser Funktion fand ich die Antwort:
Der Zyklus endete in 10-15 Sekunden. Es bleibt nur die Ergebnisse zu sehen. Aber wie ich finde, ist es interessanter, wenn es einen Zeitplan gibt. Und hier ist die letzte Funktion, die uns das Ergebnis zeigt:
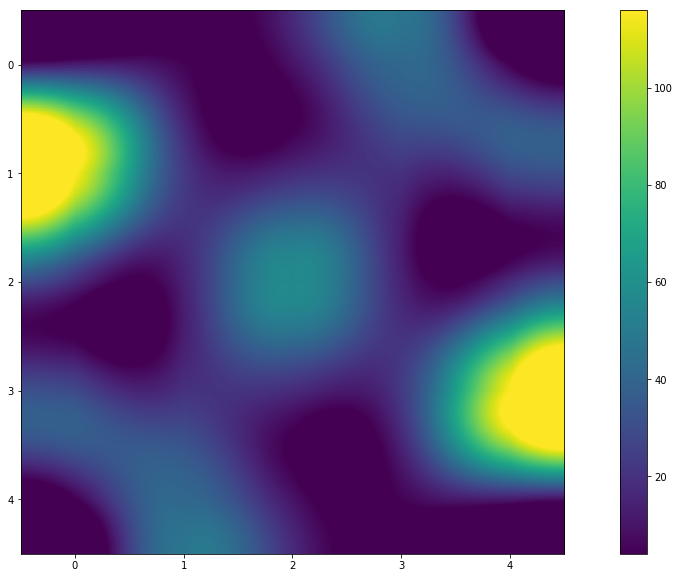
Zusammenfassung
Antworten auf Fragen am Anfang
"Was ist, wenn ich ein Wort mit Caesar verschlüssle und am Ausgang ein vorhandenes Wort erhalte?"
- Das ist sogar sehr gut möglich. Einige N geben viel mehr Wörter als andere.
- Wie viele solcher Wörter "Shifter" gibt es?
- Abhängig von N, der Mindestlänge und natürlich vom Datensatz. In meinem Fall ist bei N = 3 die minimale Wortlänge von 0 und 5 die Anzahl der Wörter: 660 bzw. 10.
- Und wird es ein Muster geben, wenn Sie N ändern?
- Anscheinend ja! An der Grafik (oder Wärmekarte) können Sie erkennen, dass die Farben symmetrisch sind. Und die Werte in der Ergebnismatrix zeigen dies an. Und die Antwort auf die Frage "Warum ist das so?" Ich werde es dem Leser überlassen.
Nachteile dieser Arbeit
- Nicht ganz korrekter Datensatz. Viele Wörter sind nicht offensichtlich. Obwohl es so sein kann. Dies sind " alle " Wörter der englischen Sprache.
- Code
immer kann verbessert werden. - "Caesars Code" ist ein Sonderfall des "Athener Codes", wobei die Formel:
Für "Caesar's Cipher" A = 1. Übrigens hat er mehr Nuancen, was interessanter bedeutet.
Meine Arbeitsdatei mit dem Ergebnis und einer Liste von Schlagwörtern liegt in diesem Repository
Efzp zzhgl!