Die Partitionierung ("Partitionierung") in SQL Server mit scheinbarer Einfachheit ("Was ist da - Sie verteilen die Tabelle und die Indizes nach Dateigruppen, Sie erzielen Gewinn bei Verwaltung und Leistung") ist ein ziemlich umfangreiches Thema. Im Folgenden werde ich versuchen zu beschreiben, wie ein Funktions- und Partitionsschema erstellt und angewendet wird und auf welche Probleme Sie möglicherweise stoßen. Ich werde nicht über die Vorteile sprechen, außer auf eine Sache - das Wechseln von Abschnitten, wenn Sie sofort einen großen Datensatz aus einer Tabelle entfernen oder umgekehrt - sofort einen nicht weniger großen Satz in eine Tabelle laden.
In
msdn heißt es: „Daten aus partitionierten Tabellen und Indizes sind in Blöcke unterteilt, die auf mehrere Dateigruppen in der Datenbank verteilt werden können. Die Daten werden horizontal partitioniert, sodass Zeilengruppen einzelnen Abschnitten zugeordnet werden. Alle Abschnitte desselben Index oder derselben Tabelle müssen sich in derselben Datenbank befinden. Eine Tabelle oder ein Index wird beim Ausführen von Abfragen oder Aktualisierungen von Daten als eine einzige logische Entität betrachtet. “
Dort sind auch die Hauptvorteile aufgeführt:
- Übertragen und greifen Sie schnell und effizient auf Teilmengen von Daten zu, während die Integrität des Datensatzes erhalten bleibt
- Wartungsarbeiten können mit einem oder mehreren Abschnitten schneller durchgeführt werden.
- Sie können die Geschwindigkeit der Abfrageausführung erhöhen, abhängig von den Abfragen, die häufig in Ihrer Hardwarekonfiguration ausgeführt werden.
Mit anderen Worten wird die Partitionierung für die horizontale Skalierung verwendet. Die Tabellen / Indizes werden von verschiedenen Dateigruppen „verteilt“, die sich auf verschiedenen physischen Datenträgern befinden können. Dies erhöht den Verwaltungskomfort erheblich und ermöglicht es Ihnen theoretisch, die Leistung von Abfragen zu diesen Daten zu verbessern. Sie können entweder nur den gewünschten Abschnitt (weniger Daten) lesen oder alles lesen parallel (Geräte sind unterschiedlich, schnell zu lesen). In der Praxis ist alles etwas komplizierter und die Steigerung der Leistung von Abfragen an partitionierte Tabellen kann nur funktionieren, wenn Ihre Abfragen die Auswahl nach dem von Ihnen partitionierten Feld verwenden. Wenn Sie noch keine Erfahrung mit partitionierten Tabellen haben, denken Sie daran, dass sich die Leistung Ihrer Abfragen möglicherweise nicht ändert, sich jedoch nach der Partitionierung Ihrer Tabelle verschlechtern kann.
Lassen Sie uns über den absoluten Vorteil sprechen, den Sie definitiv mit der Partitionierung haben (den Sie aber auch nutzen müssen) - dies ist eine garantierte Steigerung des Komforts bei der Verwaltung Ihrer Datenbank. Sie haben beispielsweise eine Tabelle mit einer Milliarde Datensätzen, von denen 900 Millionen aus alten („geschlossenen“) Zeiträumen stammen und schreibgeschützt sind. Mithilfe von Abschnitten können Sie diese alten Daten in eine separate schreibgeschützte Dateigruppe übertragen, sichern und nicht mehr in alle Ihre täglichen Sicherungen ziehen. Die Geschwindigkeit beim Erstellen einer Sicherungskopie nimmt zu und die Größe nimmt ab. Sie können den Index nicht über die gesamte Tabelle, sondern über ausgewählte Abschnitte neu erstellen. Darüber hinaus steigt die Verfügbarkeit Ihrer Datenbank. Wenn eines der Geräte mit der Dateigruppe mit dem Abschnitt ausfällt, ist der Rest weiterhin verfügbar.
Um die verbleibenden Vorteile zu erzielen (Abschnitte sofort wechseln; Produktivität steigern), müssen Sie die Datenstruktur speziell entwerfen und Abfragen schreiben.
Ich schätze, ich habe den Leser schon genug in Verlegenheit gebracht und jetzt kann ich mit dem Üben fortfahren.
Erstellen Sie zunächst eine Datenbank mit 4 Dateigruppen, in der wir Experimente durchführen werden:
create database [PartitionTest] on primary (name ='PTestPrimary', filename = 'E:\data\partitionTestPrimary.mdf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg1] (name ='PTestFG1', filename = 'E:\data\partitionTestFG1.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg2] (name ='PTestFG2', filename = 'E:\data\partitionTestFG2.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg3] (name ='PTestFG3', filename = 'E:\data\partitionTestFG3.ndf', size = 8092KB, filegrowth = 1024KB) log on (name = 'PTest_Log', filename = 'E:\data\partitionTest_log.ldf', size = 2048KB, filegrowth = 1024KB); go alter database [PartitionTest] set recovery simple; go use partitionTest;
Erstellen Sie eine Tabelle, die wir quälen werden.
create table ptest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000));
Und füllen Sie es mit Daten für ein Jahr:
;with nums as ( select 0 n union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9 ) insert into ptest(dt, dummy_int, dummy_char) select dateadd(hh, rn-1, '20180101') dt, rn dummy_int, 'dummy char column #' + cast(rn as varchar) from ( select row_number() over(order by (select (null))) rn from nums n1, nums n2, nums n3, nums n4 )t where rn < 8761
Jetzt enthält die pTest-Tabelle einen Datensatz für jede Stunde des Jahres 2018.
Jetzt müssen Sie eine Partitionsfunktion erstellen, die die Randbedingungen für die Aufteilung von Daten in Abschnitte beschreibt. SQL Server unterstützt nur die Bereichspartitionierung.
Wir werden unsere Tabelle nach der Spalte dt (datetime) aufteilen, sodass jeder Abschnitt Daten für 4 Monate enthält (hier habe ich es vermasselt - tatsächlich enthält der erste Abschnitt Daten für 3, der zweite für 4, der dritte für 5 Monate, aber zu Demonstrationszwecken - dies ist kein Problem)
create partition function pfTest (datetime) as range for values ('20180401', '20180801')
Alles scheint normal zu sein, aber hier habe ich absichtlich einen „Fehler“ gemacht. Wenn Sie sich die Syntax in
msdn ansehen, werden Sie feststellen, dass Sie während der Erstellung angeben können, zu welchem Abschnitt der angegebene Rahmen gehören soll - links oder rechts. Aus unbekannten Gründen bezieht sich der angegebene Rand standardmäßig auf den Abschnitt "links". In meinem Fall wäre es daher richtig, eine Partitionsfunktion wie folgt zu erstellen:
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Während ich tatsächlich ausgeführt habe:
create partition function pfTest (datetime) as range left for values ('20180401', '20180801')
Wir werden jedoch später darauf zurückkommen und unsere Partitionsfunktion neu erstellen. In der Zwischenzeit fahren wir mit dem fort, was passiert ist, um zu verstehen, was passiert ist und warum es nicht sehr gut für uns ist.
Nach dem Erstellen der Partitionsfunktion müssen Sie ein Partitionsschema erstellen. Es bindet Abschnitte eindeutig an Dateigruppen:
create partition scheme psTest as partition pfTest to ([FG1], [FG2], [FG3])
Wie Sie sehen können, befinden sich alle drei Abschnitte in verschiedenen Dateigruppen. Jetzt ist es Zeit, unsere Tabelle zu partitionieren. Dazu müssen wir einen Clustered-Index erstellen und anstelle der Dateigruppe, in der er sich befinden soll, das Partitionierungsschema angeben:
create clustered index cix_pTest_id on pTest(id) on psTest(dt)
Und auch hier habe ich im aktuellen Schema einen „Fehler“ gemacht - ich hätte sehr gut einen eindeutigen Clustered-Index für diese Spalte erstellen können. Wenn Sie jedoch einen eindeutigen Index erstellen, sollte die zur Partitionierung verwendete Spalte in den Index aufgenommen werden. Und ich möchte zeigen, was Sie mit dieser Konfiguration erleben können.
Nun wollen wir sehen, was wir in der aktuellen Konfiguration haben (die
Anfrage wird von hier übernommen ):
SELECT sc.name + N'.' + so.name as [Schema.Table], si.index_id as [Index ID], si.type_desc as [Structure], si.name as [Index], stat.row_count AS [Rows], stat.in_row_reserved_page_count * 8./1024./1024. as [In-Row GB], stat.lob_reserved_page_count * 8./1024./1024. as [LOB GB], p.partition_number AS [Partition

So haben wir drei nicht sehr erfolgreiche Abschnitte erhalten - der erste speichert Daten vom Beginn der Zeit bis einschließlich 04/01/2018 00:00:00, der zweite - vom 01/01/2018 00:00:01 bis einschließlich 08/01/2018 00:00:00 einschließlich der dritte vom 08/01/2018 00:00:01 bis zum Ende der Welt (ich habe absichtlich den Bruchteil einer Sekunde verpasst, weil ich mich nicht erinnere, in welche Abstufung SQL Server diese Brüche schreibt, aber die Bedeutung korrekt übertragen wird).
Erstellen Sie nun einen nicht gruppierten Index für das Feld dummy_int, der nach demselben Partitionierungsschema „ausgerichtet“ ist.
Warum brauchen wir einen ausgerichteten Index?Wir benötigen einen ausgerichteten Index, damit wir einen Abschnitt (Schalter) wechseln können - und dies ist eine dieser Operationen, für die sie sich häufig mit der Partitionierung beschäftigen. Wenn die Tabelle mindestens einen nicht ausgerichteten Index enthält, können Sie den Abschnitt nicht wechseln
create nonclustered index nix_pTest_dummyINT on pTest(dummy_int) on psTest(dt);
Und lassen Sie uns sehen, warum ich gesagt habe, dass Ihre Abfragen nach der Implementierung von Abschnitten langsamer werden können. Führen Sie die Anforderung aus:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 SET STATISTICS TIME, IO OFF;
Und sehen wir uns die Ausführungsstatistik an:
Table 'ptest'. Scan count 3, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Und der Umsetzungsplan:

Da unser Index bedingt durch Abschnitte „ausgerichtet“ ist, hat jeder Abschnitt seinen eigenen Index, der mit Indizes für andere Abschnitte „nicht verbunden“ ist. Wir haben dem Feld, nach dem der Index partitioniert ist, keine Bedingungen auferlegt, sodass SQL Server gezwungen ist, die Indexsuche in jedem Abschnitt auszuführen, nämlich 3 Indexsuche anstelle von einem.
Versuchen wir, einen Abschnitt auszuschließen:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 and dt < '20180801' SET STATISTICS TIME, IO OFF;
Und sehen wir uns die Ausführungsstatistik an:
Table 'ptest'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Ja, ein Abschnitt wurde ausgeschlossen und die Suche nach dem gewünschten Wert wurde in nur zwei Abschnitten durchgeführt.
Dies muss bei der Entscheidung für eine Partitionierung beachtet werden. Wenn Sie Abfragen haben, die keine Einschränkung für das Feld verwenden, nach dem die Tabelle partitioniert ist, liegt möglicherweise ein Problem vor.
Wir brauchen den nicht gruppierten Index nicht mehr, also lösche ich ihn
drop index nix_pTest_dummyINT on pTest;
Und warum wurde ein Nicht-Cluster-Index benötigt?Im Allgemeinen brauchte ich es nicht, ich konnte dasselbe mit dem Cluster-Index anzeigen. Ich weiß nicht, warum ich es erstellt habe, aber da ich es erstellt und Screenshots erstellt habe, verschwinden Sie nicht
Stellen Sie sich nun das folgende Szenario vor: Wir archivieren die Daten aus dieser Tabelle alle 4 Monate - wir entfernen die alten Daten und fügen einen Abschnitt für die nächsten vier Monate hinzu (die Organisation des „Schiebefensters“ ist in msdn und dem Haufen von Blogs beschrieben).
Wir unterteilen die Aufgabe in kleine und verständliche Unteraufgaben:
- Fügen Sie einen Abschnitt für Daten vom 01.01.2019 bis zum 01.04.2019 hinzu
- Erstellen Sie eine leere Bühnentabelle
- Schalten Sie den Datenbereich bis zum 04/01/2018 in der Stufentabelle
- Entfernen Sie den leeren Bereich
Lass uns gehen:
1. Wir geben bekannt, dass der neue Abschnitt in der FG1-Dateigruppe erstellt wird, da er bald von uns befreit wird:
alter partition scheme psTest next used [FG1];
Ändern Sie die Partitionsfunktion, indem Sie einen neuen Rahmen hinzufügen:
SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Wir schauen uns die Statistiken an:
Table 'ptest'. Scan count 1, logical reads 76171, physical reads 0, read-ahead reads 753, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 7440, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Die Tabelle enthält 8809 Seiten (Cluster-Index), sodass die Anzahl der Lesungen natürlich über Gut und Böse hinausgeht. Mal sehen, was wir jetzt in Abschnitten haben.

Im Allgemeinen war alles wie erwartet - ein neuer Abschnitt mit einer oberen Grenze erschien (denken Sie daran, dass die Randbedingungen für uns zum linken Abschnitt gehören) 01/01/2019 und ein leerer Abschnitt, in dem es andere Daten mit einem längeren Datum geben wird.
Alles scheint in Ordnung zu sein, aber warum gibt es so viele Lesungen? Wir schauen uns die obige Abbildung genau an und sehen, dass die Daten aus dem dritten Abschnitt, die in FG3 waren, in FG1 endeten, aber der nächste Abschnitt, leer, in FG3.
2. Erstellen Sie eine Bühnentabelle.
Um einen Abschnitt in eine Tabelle zu wechseln und umgekehrt, benötigen wir eine leere Tabelle, in der dieselben Einschränkungen und Indizes wie in unserer partitionierten Tabelle erstellt werden. Die Tabelle sollte sich in derselben Dateigruppe befinden wie der Abschnitt, den wir dort „wechseln“ möchten. Der erste (archivierte) Abschnitt befindet sich in FG1, daher erstellen wir eine Tabelle und einen Clusterindex an derselben Stelle:
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id) on [FG1];
Sie müssen diese Tabelle nicht partitionieren.
3. Jetzt können wir wechseln:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Und hier ist was wir bekommen:
4947, 16, 1, 59 ALTER TABLE SWITCH statement failed. There is no identical index in source table 'PartitionTest.dbo.pTest' for the index 'cix_stageTest_id' in target table 'PartitionTest.dbo.stageTest' .
Lustig, mal sehen, was wir in den Indizes haben:
select o.name tblName, i.name indexName, c.name columnName, ic.is_included_column from sys.indexes i join sys.objects o on i.object_id = o.object_id join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id join sys.columns c on ic.column_id = c.column_id and o.object_id = c.object_id where o.name in ('pTest', 'stageTest')
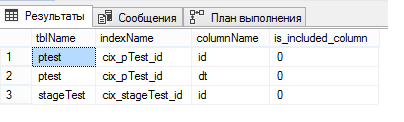
Denken Sie daran, ich habe geschrieben, dass es notwendig ist, einen eindeutigen Clustered-Index für eine partitionierte Tabelle zu erstellen. Genau deshalb war es notwendig. Beim Erstellen eines eindeutigen Clustered-Index müsste SQL Server die Spalte, nach der wir die Tabelle partitionieren, explizit in den Index aufnehmen. Daher fügte er sie selbst hinzu und vergaß, dies zu sagen. Und ich verstehe wirklich nicht warum.
Im Allgemeinen ist das Problem jedoch verständlich. Wir erstellen den Clusterindex für die Stufentabelle neu.
create clustered index cix_stageTest_id on stageTest(id, dt) with (drop_existing = on) on [FG1];
Und jetzt versuchen wir noch einmal, den Abschnitt zu wechseln:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Ta Dam! Der Abschnitt ist gewechselt, sehen Sie, was es uns gekostet hat:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Aber nichts. Das Umschalten eines Abschnitts in eine leere Tabelle und umgekehrt (eine vollständige Tabelle in einen leeren Abschnitt) erfolgt ausschließlich mit Metadaten, und genau deshalb ist die Partitionierung eine sehr, sehr coole Sache.
Mal sehen, was mit unseren Abschnitten los ist:

Und bei ihnen ist alles super. Im ersten Abschnitt sind keine Datensätze mehr vorhanden, die sicher für die stageTest-Tabelle übrig bleiben. Wir können weitermachen
4. Wir müssen nur noch unseren leeren ersten Abschnitt löschen. Lassen Sie es uns tun und sehen, was passiert:
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
Dies ist in unserem Fall auch nur eine Operation für Metadaten. Wir schauen uns die Abschnitte an:

Wir haben sozusagen nur 3 Abschnitte, jeder in einer eigenen Dateigruppe. Mission erfüllt. Was könnte hier verbessert werden? Zunächst möchte ich, dass sich die Grenzwerte auf die „richtigen“ Abschnitte beziehen, damit die Abschnitte alle Daten für 4 Monate enthalten. Und ich würde gerne sehen, dass die Erstellung eines neuen Abschnitts weniger kostet. Lesen Sie Daten zehnmal mehr als die Tabelle selbst - Fehlschlag.
Mit dem ersten können wir jetzt nichts machen, aber mit dem zweiten werden wir es versuchen. Erstellen wir einen neuen Abschnitt, der Daten vom 01.01.2019 bis zum 01.04.2019 und nicht bis zum Ende der Zeit enthält:
alter partition scheme psTest next used [FG2]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190401'); SET STATISTICS TIME, IO OFF;
Und wir sehen:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Ha! Also ist diese Operation jetzt nur für Metadaten? Ja, wenn Sie einen leeren Abschnitt "teilen" - dies ist eine Operation nur für Metadaten. Daher ist es die richtige Entscheidung, sowohl den linken als auch den rechten garantierten leeren Abschnitt beizubehalten und gegebenenfalls einen neuen auszuwählen - sie von dort "auszuschneiden".
Nun wollen wir sehen, was passiert, wenn ich die Daten von der Stufentabelle zurück in die partitionierte Tabelle zurückgeben möchte. Dazu brauche ich:
- Erstellen Sie links einen neuen Abschnitt für Daten
- Wechseln Sie die Tabelle in diesen Abschnitt
Wir versuchen (und erinnern uns an diesen StageTest in FG1):
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20180401'); SET STATISTICS TIME, IO OFF;
Wir sehen:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 2939, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Nun, nicht schlecht, d.h. Lesen Sie nur den linken Abschnitt (den wir teilen) und das wars. Okay Um eine nicht partitionierte nicht leere Tabelle in einen partitionierten Tabellenabschnitt umzuwandeln, muss die Quelltabelle Einschränkungen aufweisen, damit SQL Server weiß, dass alles in Ordnung ist und das Umschalten als Vorgang für Metadaten durchgeführt werden kann (anstatt alles in einer Zeile zu lesen und zu überprüfen, ob der Abschnitt den Bedingungen entspricht oder nicht) ):
alter table stageTest add constraint check_dt check (dt <= '20180401')
Versuch zu wechseln:
SET STATISTICS TIME, IO ON; alter table stageTest switch to pTest partition 1 SET STATISTICS TIME, IO OFF;
Statistik:
SQL Server Execution Times: CPU time = 15 ms, elapsed time = 39 ms.
Auch hier erfolgt die Operation nur für Metadaten. Wir schauen uns an, was mit unseren Abschnitten passiert:

Okay Es scheint geklärt zu sein. Und jetzt werden wir versuchen, das Funktions- und Partitionierungsschema neu zu erstellen (ich habe das Partitionierungsschema und die Funktion gelöscht, die Tabelle neu erstellt und neu gefüllt und den Clusterindex mithilfe des neuen Partitionierungsschemas neu erstellt):
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Mal sehen, welche Abschnitte wir jetzt haben:

Nun haben wir drei „logische“ Abschnitte - vom Beginn der Zeit bis zum 04/01/2018 00:00:00 (nicht inklusive), vom 04/01/2018 00:00:00 (inklusive) bis zum 08/01/2018 00:00:00 ( nicht inklusive) und drittens alles, was größer oder gleich 01/01/2018 00:00:00 ist.
Versuchen wir nun, dieselbe Aufgabe zum Archivieren von Daten auszuführen, die wir mit der vorherigen Partitionsfunktion ausgeführt haben.
1. Fügen Sie einen neuen Abschnitt hinzu:
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Wir schauen uns die Statistiken an:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 3685, physical reads 0, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Zumindest nicht vernünftig - lesen Sie nur den letzten Abschnitt. Wir schauen uns an, was wir in Abschnitten haben:

Beachten Sie, dass der abgeschlossene dritte Abschnitt in FG3 weiterhin vorhanden ist und in FG1 ein neuer leerer Abschnitt erstellt wurde.
2. Wir erstellen eine Stufentabelle und den CORRECT-Clusterindex darauf
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id, dt) on [FG1];
3. Abschnitt wechseln
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Statistiken besagen, dass die Metadatenoperation wie folgt lautet:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms.
Jetzt alles ohne Überraschungen.
4. Entfernen Sie unnötige Abschnitte
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
Und hier haben wir eine Überraschung:
Table 'ptest'. Scan count 1, logical reads 27057, physical reads 0, read-ahead reads 251, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Wir schauen uns an, was wir mit den Abschnitten haben:

Und hier wird klar: Unser Abschnitt Nr. 2 wurde von der fg2-Dateigruppe in die fg1-Dateigruppe verschoben. Klasse. Können wir etwas dagegen tun?
Vielleicht müssen wir nur immer einen leeren Abschnitt haben und die Grenze zwischen dem "immer leeren" linken Abschnitt und dem Abschnitt, den wir zu einem anderen Tisch "gewechselt" haben, "zerstören".
Fazit:- Verwenden Sie die vollständige Syntax zum Erstellen einer Partitionsfunktion. Verlassen Sie sich nicht auf die Standardwerte. Möglicherweise erhalten Sie nicht das, was Sie möchten.
- Halten Sie sich links und rechts im leeren Bereich - sie sind sehr nützlich für Sie, wenn Sie ein "Schiebefenster" organisieren.
- Nicht leere Abschnitte teilen und zusammenführen - es tut immer weh, vermeiden Sie dies, wenn möglich.
- Überprüfen Sie Ihre Abfragen. Wenn sie den Filter nicht nach der Spalte verwenden, nach der Sie die Tabelle partitionieren möchten, und Sie die Möglichkeit benötigen, Abschnitte zu wechseln, kann sich ihre Leistung erheblich verringern.
- Wenn Sie etwas tun möchten, testen Sie zuerst nicht in der Produktion.
Hoffe das Material war hilfreich. Vielleicht hat es sich als zerknittert herausgestellt. Wenn Sie der Meinung sind, dass etwas von dem Erklärten nicht bekannt gegeben wird, schreiben Sie, ich werde versuchen, es zu beenden. Vielen Dank für Ihre Aufmerksamkeit.