Hallo an alle. Vor Beginn des Kurses für maschinelles Lernen verbleibt etwas mehr als eine Woche. Im Vorgriff auf den Beginn des Unterrichts haben wir eine nützliche Übersetzung vorbereitet, die sowohl für unsere Schüler als auch für alle Blog-Leser von Interesse sein wird. Fangen wir an.

Es ist Zeit, die Black Boxes loszuwerden und Vertrauen in maschinelles Lernen aufzubauen!In seinem Buch
„Interpretierbares maschinelles Lernen“ hebt Christoph Molnar die Essenz der Interpretierbarkeit des maschinellen Lernens anhand des folgenden Beispiels perfekt hervor: Stellen Sie sich vor, Sie sind ein Data Science-Experte und versuchen in Ihrer Freizeit anhand ihrer Daten von Facebook und vorherzusagen, wohin Ihre Freunde in den Sommerferien fahren werden Twitter. Wenn die Prognose korrekt ist, werden Ihre Freunde Sie als Assistenten betrachten, der die Zukunft sehen kann. Wenn die Vorhersagen falsch sind, schadet dies nichts anderem als Ihrem Ruf als Analyst. Stellen Sie sich nun vor, es war nicht nur ein lustiges Projekt, sondern es wurden auch Investitionen angezogen. Angenommen, Sie wollten in Immobilien investieren, in denen sich Ihre Freunde wahrscheinlich entspannen. Was passiert, wenn Modellvorhersagen fehlschlagen? Sie werden Geld verlieren. Solange das Modell keine signifikanten Auswirkungen hat, spielt seine Interpretierbarkeit keine große Rolle. Wenn jedoch finanzielle oder soziale Konsequenzen mit den Vorhersagen des Modells verbunden sind, erhält seine Interpretierbarkeit eine völlig andere Bedeutung.
Erklärtes maschinelles Lernen
Interpretieren heißt verständlich erklären oder zeigen. Interpretierbarkeit ist im Kontext eines ML-Systems die Fähigkeit, seine Wirkung zu erklären oder in einer für
Menschen lesbaren Form darzustellen.
Viele Menschen haben Modelle des maschinellen Lernens als „Black Boxes“ bezeichnet. Dies bedeutet, dass wir trotz der Tatsache, dass wir eine genaue Prognose von ihnen erhalten können, die Logik ihrer Zusammenstellung nicht klar erklären oder verstehen können. Aber wie können Sie Erkenntnisse aus dem Modell gewinnen? Welche Dinge sollten beachtet werden und welche Werkzeuge benötigen wir, um dies zu tun? Dies sind wichtige Fragen, die sich bei der Interpretierbarkeit von Modellen stellen.
Bedeutung der Interpretierbarkeit
Die Frage, die sich einige Leute stellen, ist,
warum nicht einfach froh sein, dass wir ein konkretes Ergebnis der Modellarbeit erhalten. Warum ist es so wichtig zu wissen, wie diese oder jene Entscheidung getroffen wurde? Die Antwort liegt in der Tatsache, dass das Modell einen gewissen Einfluss auf nachfolgende Ereignisse in der realen Welt haben kann. Die Interpretierbarkeit ist für Modelle, die Filme empfehlen sollen, viel weniger wichtig als für Modelle, die zur Vorhersage der Wirkung eines Arzneimittels verwendet werden.
"Das Problem ist, dass nur eine Metrik, wie z. B. die Klassifizierungsgenauigkeit, eine unzureichende Beschreibung der meisten realen Aufgaben darstellt." (
Doshi Veles und Kim 2017 )
Hier ist ein großes Bild über erklärbares maschinelles Lernen. In gewisser Weise erfassen wir die Welt (oder vielmehr Informationen daraus), sammeln Rohdaten und verwenden sie für weitere Prognosen. Im Wesentlichen ist die Interpretierbarkeit nur eine weitere Ebene des Modells, die den Menschen hilft, den gesamten Prozess zu verstehen.
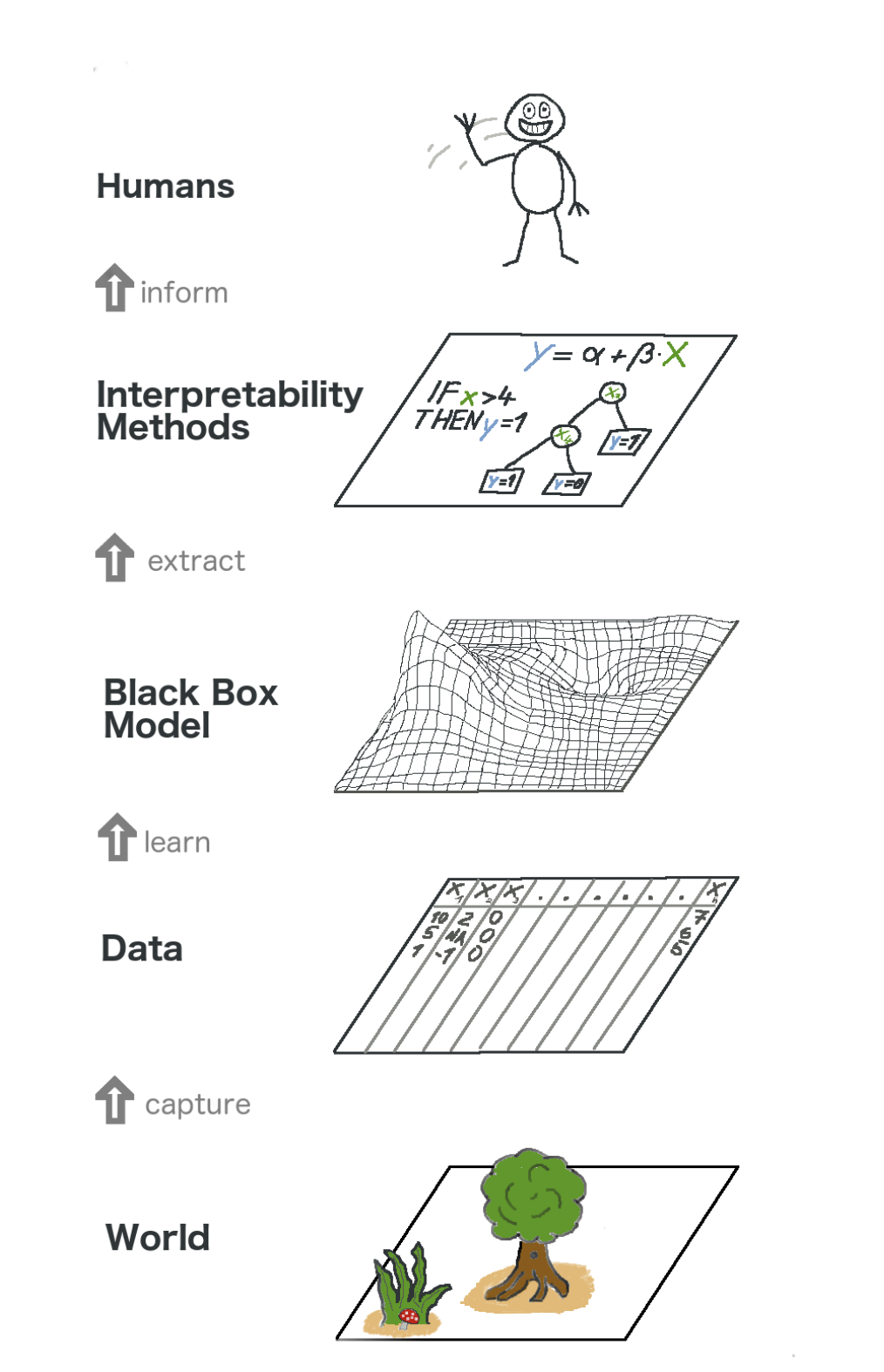 Der Text im Bild von unten nach oben: Welt -> Informationen abrufen -> Daten -> Training -> Black-Box-Modell -> Extrahieren -> Interpretationsmethoden -> Personen
Der Text im Bild von unten nach oben: Welt -> Informationen abrufen -> Daten -> Training -> Black-Box-Modell -> Extrahieren -> Interpretationsmethoden -> PersonenEinige der
Vorteile , die Interpretierbarkeit mit sich bringt, sind:
- Zuverlässigkeit
- Bequemes Debuggen;
- Informationen zu technischen Merkmalen;
- Verwalten der Datenerfassung für Merkmale
- Informationen zur Entscheidungsfindung;
- Vertrauen aufbauen.
Modellinterpretationsmethoden
Eine Theorie macht nur Sinn, solange wir sie in die Praxis umsetzen können. Wenn Sie sich wirklich mit diesem Thema befassen möchten, können Sie versuchen, den Kurs zur Erklärung des maschinellen Lernens von Kaggle zu belegen. Darin finden Sie die richtige Korrelation von Theorie und Code, um Konzepte zu verstehen und die Konzepte der Interpretierbarkeit (Erklärbarkeit) von Modellen mit realen Fällen in die Praxis umzusetzen.
Klicken Sie auf den Screenshot unten, um direkt zur Kursseite zu gelangen. Wenn Sie sich zuerst einen Überblick über das Thema verschaffen möchten, lesen Sie weiter.
Erkenntnisse, die aus Modellen extrahiert werden können
Um das Modell zu verstehen, benötigen wir folgende Erkenntnisse:
- Die wichtigsten Merkmale des Modells;
- Für jede spezifische Prognose des Modells die Auswirkung jedes einzelnen Attributs auf eine bestimmte Prognose.
- Der Einfluss jedes Features auf eine Vielzahl möglicher Prognosen.
Lassen Sie uns einige Methoden diskutieren, die helfen, die obigen Erkenntnisse aus dem Modell zu extrahieren:
Permutationsbedeutung
Welche Funktionen hält das Modell für wichtig? Welche Symptome haben den größten Einfluss? Dieses Konzept wird als Merkmalsbedeutung bezeichnet, und die Permutationsbedeutung ist eine weit verbreitete Methode zur Berechnung der Wichtigkeit von Merkmalen. Es hilft uns zu sehen, an welchem Punkt das Modell unerwartete Ergebnisse liefert, und es hilft uns, anderen zu zeigen, dass unser Modell genau so funktioniert, wie es sollte.
Permutationsbedeutung funktioniert für viele Scikit-Lernbewertungen. Die Idee ist einfach: Ordnen Sie eine Spalte im Validierungsdatensatz willkürlich neu an oder mischen Sie sie, wobei alle anderen Spalten intakt bleiben. Ein Vorzeichen wird als „wichtig“ angesehen, wenn die Genauigkeit des Modells abnimmt und seine Änderung zu einer Zunahme von Fehlern führt. Andererseits wird ein Feature als „unwichtig“ angesehen, wenn das Mischen seiner Werte die Genauigkeit des Modells nicht beeinträchtigt.
Wie funktioniert es
Stellen Sie sich ein Modell vor, das anhand bestimmter Parameter vorhersagt, ob eine Fußballmannschaft die Auszeichnung „Mann des Spiels“ erhält oder nicht. Diese Auszeichnung wird an den Spieler vergeben, der die besten Fähigkeiten des Spiels demonstriert.
Permutation Die Wichtigkeit wird nach dem Training des Modells berechnet. Lassen Sie uns also das
RandomForestClassifier Modell, das als
my_model , anhand der Trainingsdaten trainieren und vorbereiten.
Die Permutationsbedeutung wird mithilfe der
ELI5- Bibliothek berechnet. ELI5 ist eine Bibliothek in Python, mit der Sie verschiedene Modelle des maschinellen Lernens mithilfe einer einheitlichen API visualisieren und debuggen können. Es unterstützt mehrere ML-Frameworks und bietet Möglichkeiten zur Interpretation des Black-Box-Modells.
Berechnung und Visualisierung der Wichtigkeit mit der ELI5-Bibliothek:
(Hier bezeichnen
val_X ,
val_y Validierungssätze)
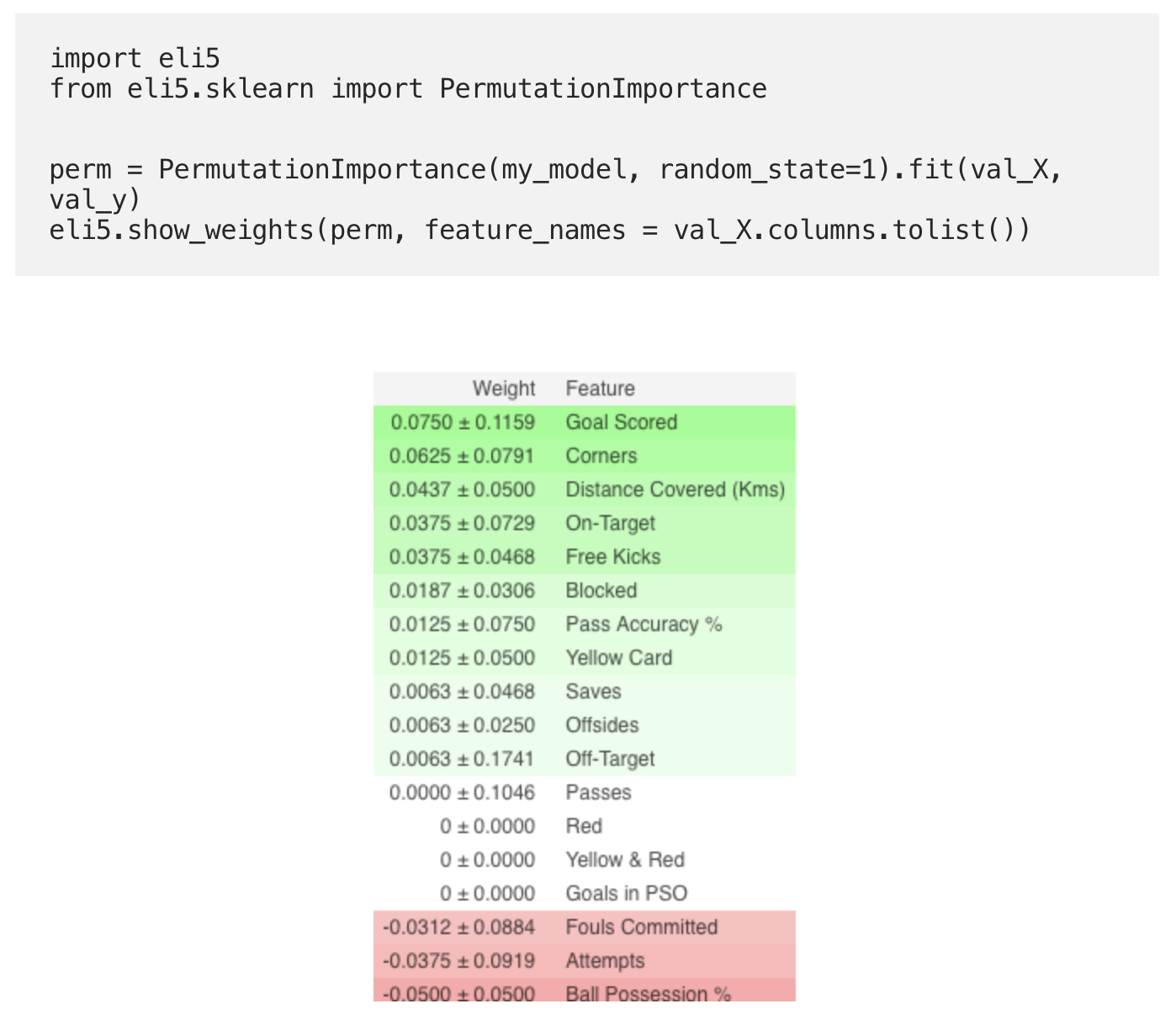
Interpretation
- Die Zeichen oben sind die wichtigsten, unten die geringsten. In diesem Beispiel war das wichtigste Zeichen das erzielte Tor.
- Die Zahl nach ± gibt an, wie sich die Produktivität von einer Permutation zur anderen geändert hat.
- Einige Gewichte sind negativ. Dies liegt an der Tatsache, dass sich in diesen Fällen die Prognosen für die gemischten Daten als genauer als die tatsächlichen Daten herausstellten.
Übe
Um das vollständige Beispiel anzusehen und zu überprüfen, ob Sie alles richtig verstanden haben, rufen Sie die Kaggle-Seite über den
Link auf .
Damit ging der erste Teil der Übersetzung zu Ende. Schreiben Sie Ihre Kommentare und treffen Sie sich auf dem Kurs!
Lesen Sie den zweiten Teil .