Das moderne Web ist ohne Medieninhalte fast undenkbar: Fast jede unserer Großmütter hat Smartphones, jeder sitzt in sozialen Netzwerken und Ausfallzeiten von Diensten sind für Unternehmen teuer. Ihre Aufmerksamkeit ist eine Abschrift von Badoos Geschichte darüber, wie die Bereitstellung von Fotos mithilfe einer Hardwarelösung organisiert wurde, welche Leistungsprobleme dabei aufgetreten sind, was sie verursacht hat und wie diese Probleme mithilfe einer Nginx-basierten Softwarelösung gelöst wurden, während sichergestellt wurde Fehlertoleranz auf allen Ebenen ( Video ). Wir danken den Autoren der Geschichte Oleg Sannis Efimov und Alexander Dymov, die ihre Erfahrungen auf der Uptime Day 4- Konferenz geteilt haben.
Das moderne Web ist ohne Medieninhalte fast undenkbar: Fast jede unserer Großmütter hat Smartphones, jeder sitzt in sozialen Netzwerken und Ausfallzeiten von Diensten sind für Unternehmen teuer. Ihre Aufmerksamkeit ist eine Abschrift von Badoos Geschichte darüber, wie die Bereitstellung von Fotos mithilfe einer Hardwarelösung organisiert wurde, welche Leistungsprobleme dabei aufgetreten sind, was sie verursacht hat und wie diese Probleme mithilfe einer Nginx-basierten Softwarelösung gelöst wurden, während sichergestellt wurde Fehlertoleranz auf allen Ebenen ( Video ). Wir danken den Autoren der Geschichte Oleg Sannis Efimov und Alexander Dymov, die ihre Erfahrungen auf der Uptime Day 4- Konferenz geteilt haben.- Beginnen wir mit einer kurzen Einführung, wie wir Fotos speichern und zwischenspeichern. Wir haben eine Ebene, auf der wir sie speichern, und eine Ebene, auf der wir Fotos zwischenspeichern. Gleichzeitig ist es für uns wichtig, dass jedes Foto eines einzelnen Benutzers auf einem Caching-Server liegt, wenn wir einen großen Erfolg erzielen und die Belastung der Hundert reduzieren möchten. Andernfalls müssten wir so viele Festplatten einlegen, wie viele Server wir noch haben. Wir haben eine Trefferquote von rund 99%, das heißt, wir reduzieren die Auslastung unseres Speichers um das 100-fache. Um dies zu erreichen, hatten wir selbst vor 10 Jahren, als all dies gebaut wurde, 50 Server. Dementsprechend benötigten wir für diese Fotos im Wesentlichen 50 externe Domänen, die diese Server bedienen.
Natürlich stellte sich sofort die Frage: Wenn ein Server ausfällt, ist er nicht verfügbar. Welchen Teil des Datenverkehrs verlieren wir? Wir haben uns angesehen, was auf dem Markt ist, und beschlossen, ein Stück Eisen zu kaufen, um alle unsere Probleme zu lösen. Die Wahl fiel auf die Entscheidung des F5-Netzwerkunternehmens (das übrigens kürzlich NGINX, Inc gekauft hat): BIG-IP Local Traffic Manager.

Was diese Hardware (LTM) bewirkt: Es handelt sich um einen Eisenrouter, der die Eisenredundanz seiner externen Ports übernimmt und es Ihnen ermöglicht, den Datenverkehr basierend auf der Netzwerktopologie und einigen Einstellungen weiterzuleiten und Integritätsprüfungen durchzuführen. Es war uns wichtig, dass dieses Stück Eisen programmiert werden kann. Dementsprechend könnten wir die Logik beschreiben, wie Fotos eines bestimmten Benutzers aus einem bestimmten Cache gegeben wurden. Wie sieht es aus? Es gibt ein Stück Eisen, das im Internet über eine Domain, eine IP, nach SSL-Offload sucht, HTTP-Anforderungen analysiert, von IRule die Cache-Nummer auswählt und den Datenverkehr dorthin leitet. Gleichzeitig werden Integritätsprüfungen durchgeführt, und wenn ein Computer nicht verfügbar ist, haben wir dies in diesem Moment durchgeführt, sodass der Datenverkehr zu einem Sicherungsserver geleitet wurde. Unter dem Gesichtspunkt der Konfiguration gibt es natürlich einige Nuancen, aber im Allgemeinen ist alles ganz einfach: Wir verschreiben eine Karte, passen eine Nummer an unsere IP im Netzwerk an, wir sagen, dass wir die 80. und 443. Ports abhören werden, sagen wir, Wenn der Server nicht verfügbar ist, müssen Sie den Datenverkehr für die Sicherung starten, in diesem Fall den 35., und wir beschreiben eine Reihe von Logikfunktionen, wie diese Architektur zerlegt werden sollte. Das einzige Problem war, dass die Sprache, die die Hardware programmierte, Tcl war. Wenn sich jemand daran erinnert ... ist diese Sprache mehr schreibgeschützt als eine für die Programmierung geeignete Sprache:

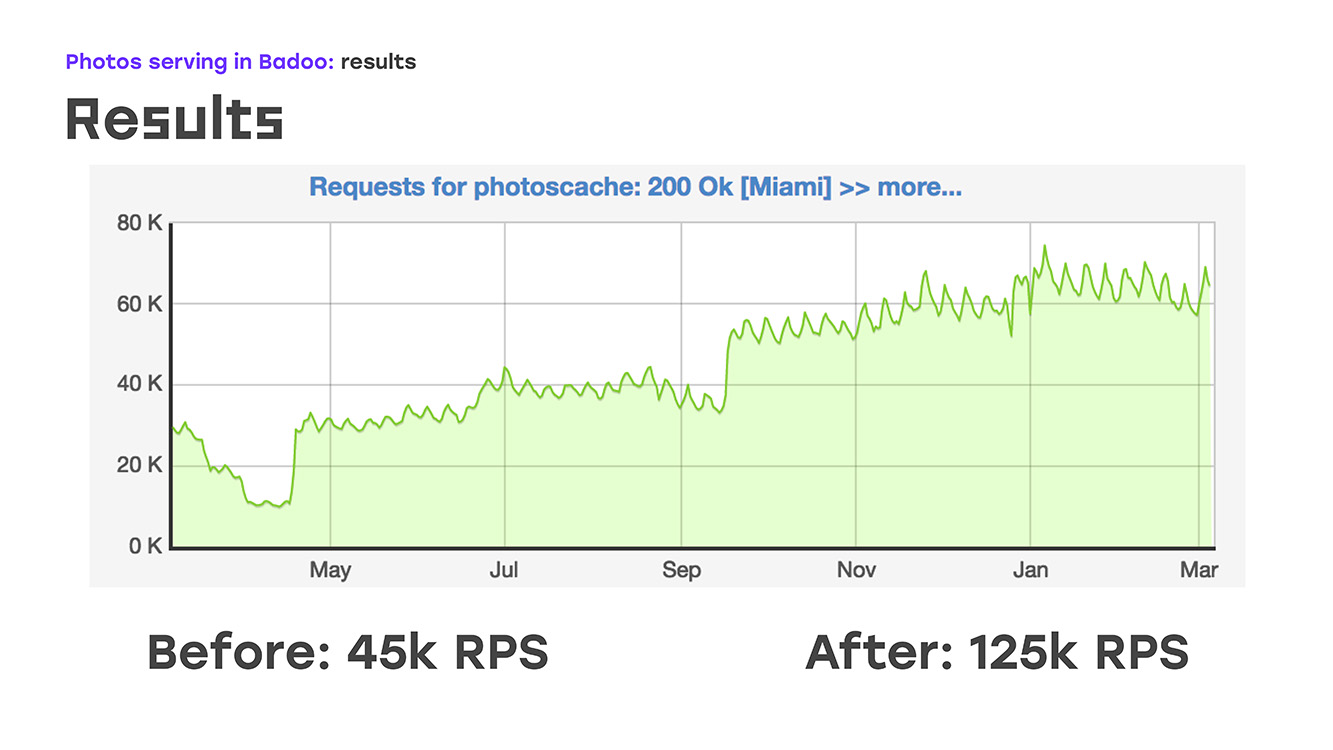
Was haben wir bekommen? Wir haben eine Hardware, die eine hohe Verfügbarkeit unserer Infrastruktur bietet, den gesamten Datenverkehr weiterleitet, für die Gesundheit sorgt und einfach funktioniert. Darüber hinaus funktioniert es seit geraumer Zeit: In den letzten 10 Jahren gab es keine Beschwerden darüber. Zu Beginn des Jahres 2018 haben wir bereits etwa 80.000 Fotos pro Sekunde ausgegeben. Dies sind ungefähr 80 Gigabit Verkehr von unseren beiden Rechenzentren.
Jedoch ...
Anfang 2018 sahen wir ein hässliches Bild in den Charts: Die Reaktionszeit von Fotos hat sich deutlich erhöht. Und es hat aufgehört, uns zu passen. Das Problem ist, dass dieses Verhalten nur auf dem Höhepunkt des Verkehrs sichtbar war - für unser Unternehmen ist dies die Nacht von Sonntag bis Montag. Aber den Rest der Zeit verhielt sich das System wie gewohnt, ohne Anzeichen von Schäden.

Trotzdem musste das Problem gelöst werden. Wir haben mögliche Engpässe identifiziert und begonnen, sie zu beseitigen. Zunächst haben wir natürlich die externen Uplinks erweitert, eine vollständige Prüfung der internen Uplinks durchgeführt und alle möglichen Engpässe festgestellt. Aber all dies ergab kein offensichtliches Ergebnis, das Problem verschwand nicht.
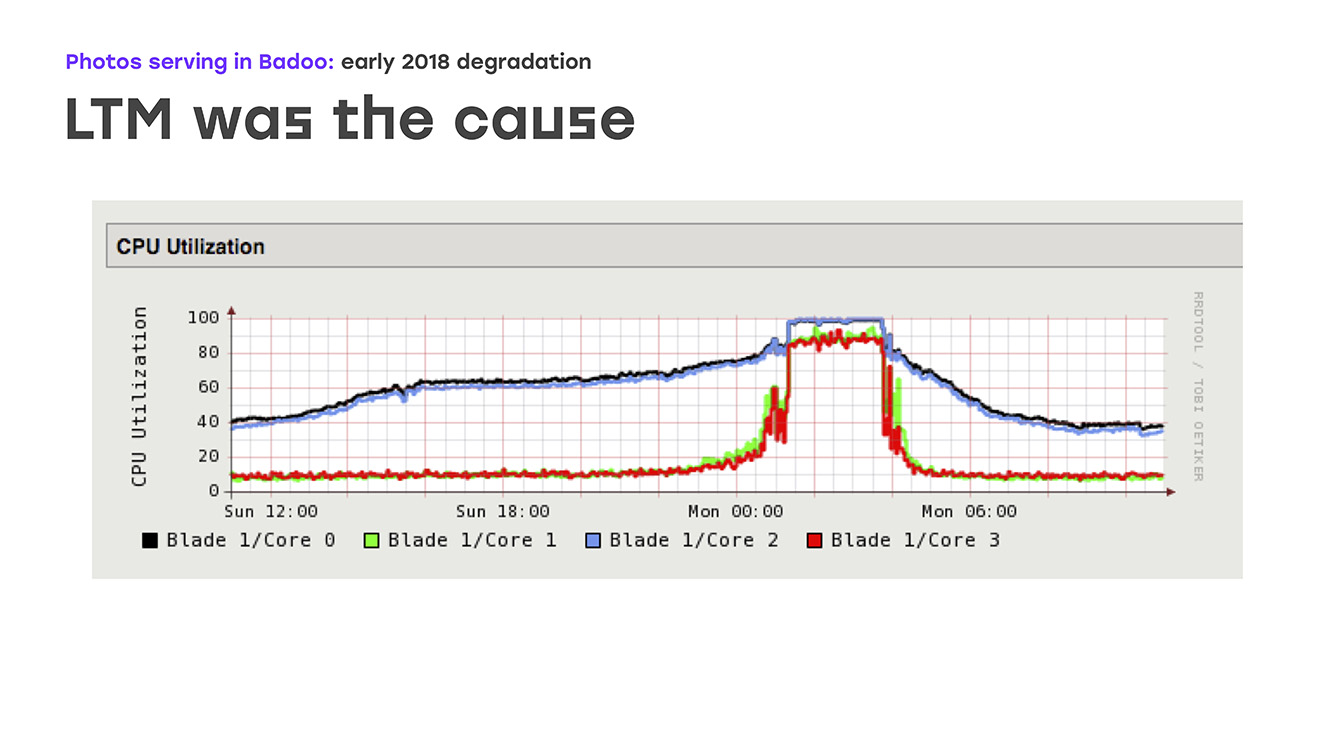
Ein weiterer möglicher Engpass war die Leistung der Foto-Caches selbst. Und wir haben beschlossen, dass das Problem vielleicht bei ihnen liegt. Nun, wir haben die Leistung erweitert - hauptsächlich Netzwerkports in Foto-Caches. Aber auch hier wurde keine offensichtliche Verbesserung festgestellt. Am Ende haben wir genau auf die Leistung von LTM selbst geachtet, und hier haben wir ein trauriges Bild in den Grafiken gesehen: Das Laden aller CPUs beginnt reibungslos zu laufen, liegt dann aber abrupt am Regal an. Gleichzeitig reagiert LTM nicht mehr angemessen auf Integritätsprüfungen und Uplinks und schaltet diese nach dem Zufallsprinzip aus, was zu schwerwiegenden Leistungseinbußen führt.
Das heißt, wir haben die Ursache des Problems und den Engpass identifiziert. Es bleibt zu entscheiden, was wir tun werden.
Das erste, was sich für uns anbietet, ist, LTM selbst irgendwie zu aktualisieren. Aber es gibt einige Nuancen, denn dieses Eisen ist ziemlich einzigartig. Sie gehen nicht zum nächsten Supermarkt und kaufen es nicht. Dies ist ein separater Vertrag, ein separater Lizenzvertrag, und es wird viel Zeit in Anspruch nehmen. Die zweite Möglichkeit besteht darin, sich selbst zu überlegen und eine eigene Lösung für Ihre Komponenten zu entwickeln, vorzugsweise mithilfe eines Open-Access-Programms. Es bleibt nur zu entscheiden, was genau wir dafür wählen und wie viel Zeit wir für die Lösung dieses Problems aufwenden, da die Benutzer keine Fotos erhalten haben. Deshalb muss man das alles sehr, sehr schnell erledigen, könnte man sagen - gestern.
Da die Aufgabe so klang, als würde man „so schnell wie möglich etwas tun und die Hardware verwenden, die wir haben“, dachten wir zuerst, einfach einige der nicht leistungsstärksten Maschinen von vorne zu entfernen und Nginx zu verwenden, mit dem wir arbeiten Wir wissen, wie man arbeitet, und versuchen, all die Logik umzusetzen, die das Stück Eisen früher hatte. Das heißt, wir haben unsere Hardware verlassen, 4 weitere Server eingerichtet, die wir konfigurieren mussten, externe Domänen für sie erstellt, ähnlich wie vor 10 Jahren ... Wir haben ein wenig an Verfügbarkeit verloren, wenn diese Maschinen abstürzten, aber weniger gelöst das Problem unserer Benutzer vor Ort.
Dementsprechend bleibt die Logik dieselbe: Wir setzen Nginx ein, es kann SSL-Offloading durchführen, wir können die Routing-Logik irgendwie programmieren, die Konfigurationen auf Integrität überprüfen und einfach die Logik duplizieren, die wir zuvor hatten.
Wir setzen uns, um Konfigurationen zu schreiben. Anfangs schien alles sehr einfach zu sein, aber leider ist es sehr schwierig, Handbücher für jede Aufgabe zu finden. Daher empfehlen wir nicht nur Google "So konfigurieren Sie Nginx für Fotos": Es ist besser, in der offiziellen Dokumentation nachzulesen, welche Einstellungen es wert sind, berührt zu werden. Es ist jedoch besser, einen bestimmten Parameter selbst auszuwählen. Nun, dann ist alles einfach: Wir beschreiben die Server, die wir haben, wir beschreiben Zertifikate ... Aber das Interessanteste ist in der Tat die Logik des Routings selbst.
Zuerst schien es uns, dass wir einfach unseren Standort beschreiben, die Nummer unseres Foto-Caches darin abgleichen, mit unseren Händen oder dem Generator beschreiben, wie viele Upstreams wir benötigen, in jedem Upstream den Server angeben, zu dem der Datenverkehr gehen soll, und einen Backup-Server für den Fall, dass der Hauptserver nicht verfügbar:

Aber wenn alles so einfach wäre, würden wir wahrscheinlich einfach nach Hause gehen und nichts sagen. Leider sieht die Konfiguration mit den Standardeinstellungen von Nginx, die im Allgemeinen über viele Jahre hinweg und nicht ganz für diesen Fall vorgenommen wurden, folgendermaßen aus: Wenn auf einem Upstream-Server ein Anforderungsfehler oder eine Zeitüberschreitung auftritt, Nginx immer schaltet den Verkehr zum nächsten um. Gleichzeitig wird der Server nach der ersten Datei versehentlich und nach Zeitüberschreitung für 10 Sekunden ausgeschaltet - dies kann nicht einmal konfiguriert werden. Das heißt, wenn wir die Timeout-Option in der Upstream-Direktive entfernen oder zurücksetzen, wird der Server heruntergefahren, obwohl Nginx diese Anforderung nicht verarbeitet und mit einem nicht so guten Fehler antwortet.

Um dies zu vermeiden, haben wir zwei Dinge getan:
a) Sie haben Nginx verboten, dies von Hand zu tun - und leider besteht die einzige Möglichkeit, dies zu tun, darin, einfach die maximalen Fehlereinstellungen festzulegen.
b) Denken Sie daran, dass wir in anderen Projekten ein Modul verwenden, mit dem Sie Hintergrund-Gesundheitsprüfungen durchführen können. Dementsprechend haben wir ziemlich häufig Gesundheitsprüfungen durchgeführt, damit wir im Falle eines Unfalls ein Minimum haben.
Leider ist dies nicht alles, da die ersten zwei Wochen dieses Schemas buchstäblich gezeigt haben, dass die TCP-Integritätsprüfung ebenfalls unzuverlässig ist: In diesem Fall kann weder Nginx noch Nginx im D-Status auf dem Upstream-Server ausgelöst werden Der Kernel akzeptiert die Verbindung, die Integritätsprüfung wird bestanden, funktioniert jedoch nicht. Aus diesem Grund haben wir es sofort durch den Health-Check http'shny ersetzt und einen bestimmten erstellt. Wenn 200 zurückgegeben werden, funktioniert in diesem Skript alles. Sie können zusätzliche Logik ausführen. Überprüfen Sie beispielsweise beim Zwischenspeichern von Servern, ob das Dateisystem ordnungsgemäß bereitgestellt ist:

Und es würde uns passen, außer dass die Schaltung im Moment völlig wiederholte, was das Stück Eisen tat. Aber wir wollten es besser machen. Zuvor hatten wir einen Sicherungsserver, und dies ist wahrscheinlich nicht sehr gut, denn wenn Sie hundert Server haben, ist es unwahrscheinlich, dass ein Sicherungsserver bei mehreren Abstürzen mit der Last fertig wird. Aus diesem Grund haben wir uns entschlossen, die Reservierung auf alle Server zu verteilen: Wir haben gerade einen weiteren separaten Upstream erstellt, alle Server mit bestimmten Parametern dort aufgeschrieben, je nachdem, welche Art von Last sie bewältigen können, und die gleichen Integritätsprüfungen hinzugefügt, die wir zuvor hatten ::

Da es unmöglich ist, innerhalb eines Upstreams zu einem anderen Upstream zu wechseln, musste sichergestellt werden, dass für den Fall, dass der Haupt-Upstream nicht verfügbar war und der richtige Fotocache einfach geschrieben wurde, wir einfach über error_page zum Fallback gingen, von wo aus wir zum Backup April gingen:

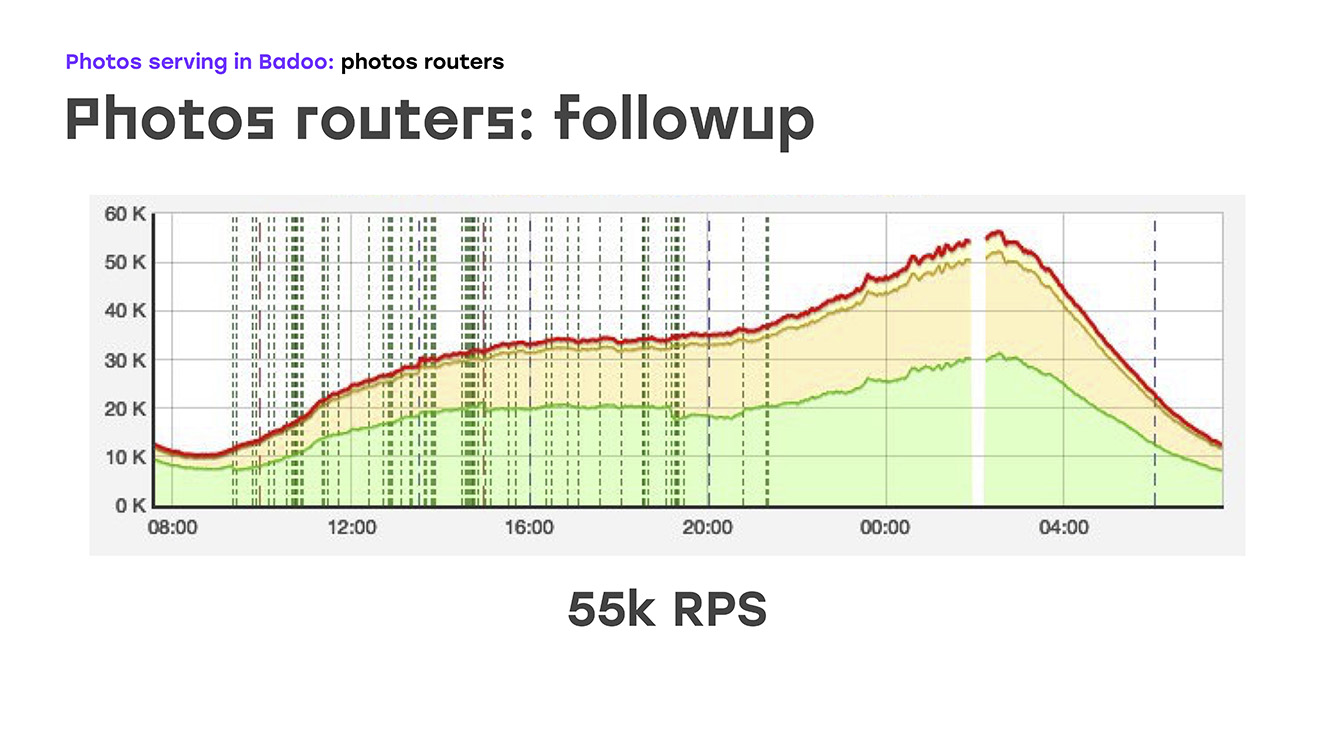
Wenn wir buchstäblich vier Server hinzufügen, haben wir Folgendes erhalten: Wir haben einen Teil der Last ersetzt - von LTM auf diese Server entfernt, dort dieselbe Logik mit Standardhardware und -software implementiert und sofort den Bonus erhalten, dass diese Server skaliert werden können, weil sie einfach sind setzen Sie so viel wie Sie brauchen. Das einzig Negative ist, dass wir die Hochverfügbarkeit für externe Benutzer verloren haben. Aber in diesem Moment musste ich das opfern, weil ich das Problem sofort lösen musste. Also haben wir einen Teil der Last entfernt, das sind ungefähr 40% zu diesem Zeitpunkt, LTM fühlte sich gut an und buchstäblich zwei Wochen nach Beginn des Problems haben wir begonnen, nicht 45.000 Anfragen pro Sekunde, sondern 55.000 zu senden. Tatsächlich sind wir um 20% gewachsen - dies ist eindeutig der Verkehr, den wir dem Benutzer nicht gegeben haben. Danach begannen sie zu überlegen, wie sie das verbleibende Problem lösen könnten - um eine hohe externe Zugänglichkeit zu gewährleisten.
Wir hatten eine Pause, in der wir diskutierten, welche Lösung wir dafür verwenden werden. Es gab Vorschläge zur Gewährleistung der Zuverlässigkeit mithilfe von DNS, zur Verwendung einiger selbst geschriebener Skripte, dynamischer Routing-Protokolle ... Es gab viele Optionen, aber es wurde klar, dass Sie für eine wirklich zuverlässige Fotoausgabe eine weitere Ebene einführen müssen, die dies überwacht. Wir haben diese Maschinen als Fotodirektoren bezeichnet. Als Software, auf die wir uns verlassen haben, habe ich Keepalived gewählt:

Zunächst - woraus Keepalived besteht. Das erste ist das VRRP-Protokoll, das Netzwerkern weithin bekannt ist und sich auf Netzwerkgeräten befindet, die Fehlertoleranz für die externe IP-Adresse bieten, mit der Clients eine Verbindung herstellen. Der zweite Teil ist IPVS, ein virtueller IP-Server, zum Ausgleich zwischen Foto-Routern und zur Gewährleistung der Fehlertoleranz auf dieser Ebene. Und der dritte ist Gesundheitschecks.
Beginnen wir mit dem ersten Teil: VRRP - wie sieht es aus? Es gibt eine bestimmte virtuelle IP, auf der sich ein Eintrag in dns badoocdn.com befindet, über den Clients verbunden sind. Irgendwann haben wir eine IP-Adresse auf einem Server. Keepalived-Pakete werden mithilfe des VRRP-Protokolls zwischen den Servern ausgeführt. Wenn der Assistent vom Radar verschwindet - der Server neu gestartet oder etwas anderes -, erhöht der Sicherungsserver diese IP-Adresse automatisch von sich selbst - es sind keine manuellen Schritte erforderlich. Der Master und das Backup unterscheiden sich hauptsächlich in der Priorität: Je höher der Wert, desto wahrscheinlicher ist es, dass der Computer zum Master wird. Ein sehr großer Vorteil ist, dass es nicht erforderlich ist, IP-Adressen auf dem Server selbst zu konfigurieren. Es reicht aus, sie in der Konfiguration zu beschreiben. Wenn IP-Adressen gleichzeitig einige benutzerdefinierte Routing-Regeln benötigen, wird dies direkt in der Konfiguration beschrieben. Dieselbe Syntax wie beschrieben im VRRP-Paket. Sie werden keine ungewohnten Dinge treffen.
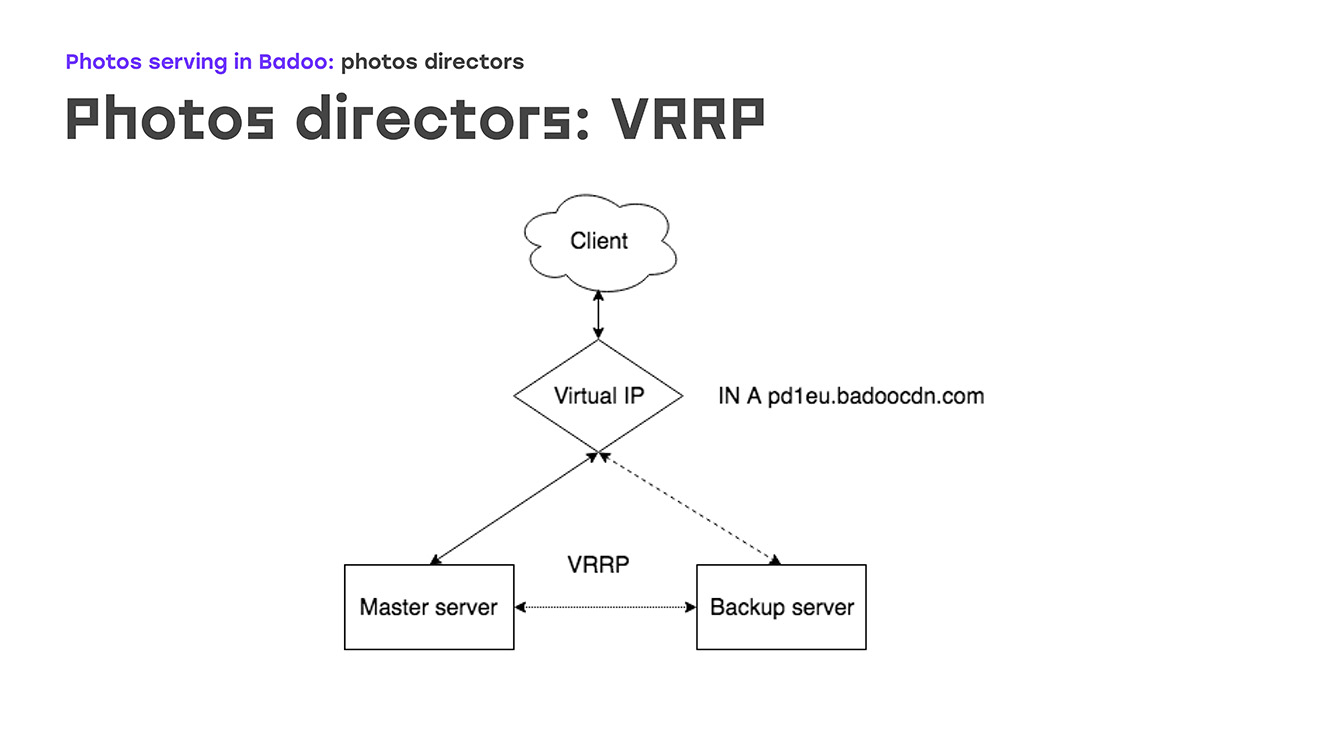
Wie sieht es in der Praxis aus? Was passiert, wenn einer der Server ausfällt? Sobald der Master verschwindet, empfängt unser Backup keine Werbung mehr und wird automatisch zum Master. Nach einiger Zeit haben wir den Master repariert, neu gestartet, Keepalived aufgehoben - die Invertierungen haben eine höhere Priorität als die Sicherung, und die Sicherung wird automatisch zurückgesetzt, die IP-Adressen werden entfernt, es sind keine manuellen Aktionen erforderlich.

So haben wir die Fehlertoleranz der externen IP-Adresse sichergestellt. Der nächste Teil besteht darin, den Datenverkehr auf Foto-Router zu verteilen, die ihn bereits von einer externen IP-Adresse beenden. Mit Ausgleichsprotokollen ist alles ziemlich klar. Dies ist entweder ein einfaches Round-Robin oder etwas komplexere Dinge, wrr, Listenverbindung und so weiter. Dies ist im Prinzip in der Dokumentation beschrieben, es gibt nichts Besonderes. Aber die Versandart ... Hier werden wir näher darauf eingehen - warum sie sich für eine entschieden haben. Dies sind NAT, Direct Routing und TUN. Tatsache ist, dass wir sofort die Rückgabe von 100 Gigabit Verkehr von den Standorten festgelegt haben. Wenn dies geschätzt wird, benötigen Sie 10 Gigabit-Karten, richtig? 10 Gigabit-Karten auf einem Server - das geht zumindest bereits über den Rahmen unseres Konzepts der „Standardausrüstung“ hinaus. Und dann haben wir uns daran erinnert, dass wir nicht nur etwas Verkehr verschenken, sondern auch Fotos verschenken.
Was ist die Funktion? - Der große Unterschied zwischen eingehendem und ausgehendem Verkehr. Der eingehende Verkehr ist sehr klein, der ausgehende ist sehr groß:
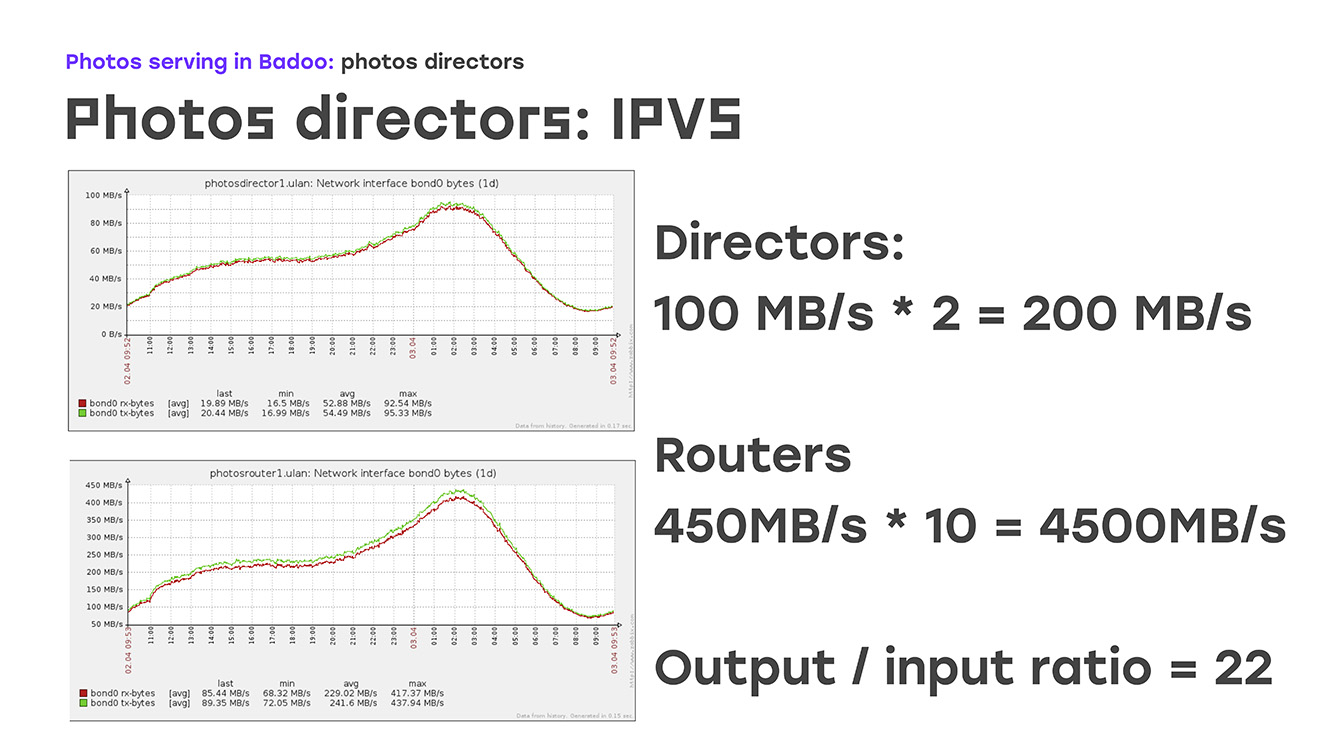
Wenn Sie sich diese Grafiken ansehen, können Sie sehen, dass derzeit etwa 200 MB pro Sekunde beim Regisseur eingehen. Dies ist der gewöhnlichste Tag. Wir geben 4.500 MB pro Sekunde zurück, das Verhältnis beträgt ungefähr 1/22. Es ist bereits klar, dass es ausreicht, einen ausgehenden Datenverkehr zu 22 Arbeitsservern zu gewährleisten, um diese Verbindung vollständig zu gewährleisten. Hier hilft uns der direkte Routing-Algorithmus, der Routing-Algorithmus.
Wie sieht es aus? Laut unserer Tabelle überträgt der Fotodirektor Verbindungen zu Fotoroutern. Die Fotorouter senden den Rückverkehr jedoch direkt an das Internet, senden ihn an den Client. Er wird nicht über den Fotodirektor zurückgesendet. Mit der minimalen Anzahl von Maschinen bieten wir eine vollständige Fehlertoleranz und pumpen den gesamten Verkehr. In den Konfigurationen sieht es so aus: Wir geben den Algorithmus an, in unserem Fall ist es ein einfaches rr, wir stellen eine direkte Routing-Methode bereit und beginnen dann, alle realen Server aufzulisten, wie viele wir haben. Welches wird diesen Verkehr bestimmen. Falls wir dort einen oder zwei weitere Server haben, entsteht ein solcher Bedarf - wir fügen diesen Abschnitt einfach in die Konfiguration ein und machen uns keine Sorgen. Auf der Seite von realen Servern, auf der Seite des Foto-Routers, erfordert diese Methode nur eine sehr minimale Konfiguration, sie ist in der Dokumentation perfekt beschrieben und es gibt keine Fallstricke.
Was besonders schön ist - eine solche Lösung bedeutet keine radikale Veränderung des lokalen Netzwerks, es war uns wichtig, wir mussten es mit minimalen Kosten lösen. Wenn Sie sich die
Ausgabe des IPVS-Administratorbefehls ansehen , werden wir sehen, wie er aussieht. Hier haben wir einen virtuellen Server an Port 443, der die Verbindung abhört, akzeptiert, alle Arbeitsserver aufgelistet ist und klar ist, dass die Verbindung dieselbe ist, plus oder minus. Wenn wir uns die Statistiken auf demselben virtuellen Server ansehen, haben wir eingehende Pakete, eingehende Verbindungen, aber absolut keine ausgehenden. Ausgehende Verbindungen gehen direkt zum Client. Nun, wir konnten aus dem Gleichgewicht bringen. Was passiert nun, wenn einer der Foto-Router ausfällt? Eisen ist schließlich Eisen. Es kann zu Kernel-Panik kommen, es kann brechen, das Netzteil kann durchbrennen. Alles. Hierzu sind Gesundheitskontrollen erforderlich. Dies können entweder die einfachsten sein - überprüfen, wie der Port bei uns geöffnet ist - oder einige komplexere, bis hin zu selbst geschriebenen Skripten, die sogar die Geschäftslogik überprüfen.
Wir haben irgendwo in der Mitte angehalten: Wir haben eine https-Anfrage für einen bestimmten Ort, ein Skript wird aufgerufen, wenn es mit der 200. Antwort antwortet. Wir glauben, dass bei diesem Server alles normal ist, dass es live ist und dass Sie es ganz ruhig einschalten können.
Wie es in der Praxis wieder aussieht. Schalten Sie den Server aus, beispielsweise für den Service - z. B. das Flashen des BIOS. In den Protokollen haben wir sofort eine Zeitüberschreitung, wir sehen die erste Zeile, nach drei Versuchen wird sie als "gespiegelt" markiert und einfach aus der Liste gelöscht.

Es gibt ein zweites mögliches Verhalten, wenn einfach VS auf Null gesetzt wird, aber wenn das Foto zurückgegeben wird, funktioniert es nicht gut. Der Server steigt an, Nginx startet dort, genau dort verstehen die Integritätsprüfungen, dass die Verbindung besteht, dass alles in Ordnung ist und der Server in unserer Liste angezeigt wird und die Last automatisch sofort darauf angewendet wird. Gleichzeitig sind vom diensthabenden Administrator keine manuellen Aktionen erforderlich. Nachts wurde der Server neu gestartet - die Überwachungsabteilung ruft uns nachts nicht an. Sie informieren, dass dies war, alles ist normal.
, , .
, , , . , Keepalivede, , , DBus, SMTP, SNMP, Zabbix'. , , , - , , , IP- . , , . nginx -, . , , : -, health-check' , , , , - - . - , amazon -, , , anomaly detection, , machine learning, , , , , , . .
: , , , - , , , HTTPS health-check'. , , , , , .
? 2018-. , , LTM, - 40 60 , 2018- .