AntipovSN und MihhaCF
Teil zwei, in dem Athos alle Regeln hat, aber dem Grafen von la Fer etwas fehlt
UPD Teil Eins ist da
UPD Teil drei hier
Einführung der Autoren:
Guten Tag! Heute setzen wir die Artikelserie fort, die sich mit dem Scoring und der Verwendung der Graphentheorie befasst. Hier können Sie sich mit dem ersten Artikel vertraut machen.
Alle Comic-Allegorien, Beilagen usw. sollen die Erzählung leicht entlasten und nicht in einen langwierigen Vortrag fallen lassen. Wir entschuldigen uns bei allen, die nicht auf unseren Humor eingehen
Der Zweck dieses Artikels: Beschreiben Sie in nicht mehr als 30 Minuten die wichtigsten Methoden zum Speichern von Diagrammdaten und die Regeln und Prinzipien für die Erstellung unseres Modells für die Bewertung eines Kreditnehmers.
Begriffe und Definitionen:
- Eine Hash-Tabelle ist eine Datenstruktur, die eine assoziative Array-Schnittstelle implementiert. Sie ermöglicht das Speichern von Paaren (Schlüssel, Wert) und das Ausführen von drei Operationen: die Operation zum Hinzufügen eines neuen Paares, die Suchoperation und die Operation zum Löschen eines Paares nach Schlüssel. Die Suche nach Hash-Tabellen wird im Durchschnitt während der O (1) -Zeit durchgeführt.
Die von Korol PJSC beauftragten Wirtschaftsprüfer, die Kreditwürdigkeit von One for All NPO zu beurteilen, stießen auf einige Probleme. Einerseits ist es sehr einfach, das Interaktionsschema von 10-15 Unternehmen zu beschreiben und eine erste Bewertung der Interaktion zwischen Unternehmen durchzuführen. Es reicht aus, ein Blatt Papier und einen Stift zur Hand zu haben. Aber was ist, wenn Sie Informationen über das Zusammenspiel von Zehntausenden oder Hunderttausenden von Unternehmen haben? Wenn Sie zum Beispiel die Interaktionen von Aramis mit all seinen Leidenschaften oder D'artagnan mit allen, mit denen er gekämpft hat, beschreiben müssen?
Wie speichere ich Daten über diese Interaktionen?
Welche Datenstrukturen und Ansätze sind zu verwenden?
Auditoren müssten für diese Arbeit ein ganzes Klosterkorps von Schriftstellern aufstellen.
Wir werden dies nicht tun und unseren Auditoren das Wissen und die Technologien der Zukunft vermitteln ( wir werden ihnen Prometheus in Form eines T-800 senden, der ihnen das Licht des Wissens gibt ).
Nun, nun, fangen wir an, die gestellten Fragen zu beantworten. Lass es hell sein!
Wie wir hier geschrieben und gezeichnet haben , ist ein Graph ein Verhältnis von 2 Mengen - eine Menge von Knoten und eine Menge von Kanten. Was ist der beste Weg, um ein Diagramm zu speichern?
Bevor Sie die Frage beantworten, wie das Diagramm gespeichert werden soll, müssen Sie entscheiden, was genau und in welcher Form gespeichert werden soll.
Gemäß der Graphentheorie können Graphknoten beliebige Objekte mit einem beliebigen Satz von Parametern sein (diese Tatsache wird uns später für fortgeschrittene / adaptive Modelle zur Berechnung eines Scoring-Balls nützlich sein).
Was müssen wir also aufbewahren?
Zumindest die Kennung des Knotens und die Kennungen seiner Nachbarn (mit denen er verbunden ist). Das Vorhandensein dieser Daten ermöglicht es Ihnen bereits, in Breite und Tiefe zu suchen.
Muss ich Grafikkantendaten speichern? Ja, wenn es sich um ein gewichtetes Diagramm handelt. In unserem Fall handelt es sich um ein gewichtetes Diagramm, und im ersten Artikel haben wir genau dieses Diagramm gezeichnet.
Reichen diese Informationen aus? Nein.
Woher kamen die Rippen? In den Lehrbüchern sind diese Informationen einfach da, jemand hat sie vor uns gesammelt und verarbeitet. In unserem späten Mittelalter (in diesem Moment lebten die Musketiere) machte sich niemand die Mühe, die Gewichte der Kanten unseres Grafen zu berechnen. Wir müssen es selbst machen. In diesem und dem nächsten Artikel werden wir die spezifische Methode zur Berechnung des Gewichts einer Kante nicht beschreiben, dies wird in Artikel 4 durchgeführt. Jetzt ist es wichtig, dass wir entscheiden, welche Informationen zu unserem Diagramm gespeichert werden sollen.
In unserem Fall gibt es also drei Schlüsselparameter, die wir kennen müssen, um die Punktzahl richtig zu berechnen:
- Eine interne Bewertung eines Knotens - besteht aus Indikatoren, die den Knoten charakterisieren (Umsatz, Schulden, Geldbußen usw.). In unserem Beispiel sind dies:
- Bewertung - ein guter oder schlechter Knoten in Bezug auf NPO "One for all";
- Knotenrang - der König hat den höchsten Rang, Bonacieux - den niedrigsten;
- Das Volumen der Mittel, mit anderen Worten, Zahlungsfähigkeit.
- Bewertung der Rippen. In unserem Fall erfolgt die Verbindungsbewertung für jeden Knoten. Dies bedeutet, dass die Bonacieux-Konstanz-Beziehung möglicherweise nicht der Konstanz-Bonacieux-Verbindung entspricht, da Sie haben unterschiedliche Möglichkeiten, sich gegenseitig zu beeinflussen.
- Knotenebene - wird nicht gespeichert, ist aber ein wichtiger Indikator.
Fragen Sie nicht, woher all diese Zahlen im Modell stammen, das sieht D'artanyan. Im wirklichen Leben werden diese Indikatoren auch nicht von uns berechnet (Handel, Schulden, Geldbußen usw., die wir aus bestehenden Quellen beziehen, wir befinden uns nicht im Mittelalter).
Aus all dem ergibt sich, dass wir zusätzlich zu den Bezeichnern der Knoten die Parameter jedes Knotens und die Gewichte der Kanten speichern müssen, die wir basierend auf der Aggregation der Parameter der Knoten erhalten.
Insgesamt sind folgende Informationen speicherpflichtig:
- Knotenname;
- Knotenparameter
- Knoten des Nachbarn;
- Rippengewicht für jeden Nachbarn.
Großartig! Wir haben herausgefunden, was wir aufbewahren müssen. Jetzt - wie man speichert.
Und wieder ein kleiner Exkurs.
Wie unser Bewertungsprozess in vereinfachter Form aussehen wird:
- Objektdatenerfassung;
- Bildung eines Objekts, das das Graphmodell beschreibt. In dieser Einrichtung werden wir alle unsere Scoring-Operationen durchführen.
Basierend auf diesen beiden Schritten haben wir drei Möglichkeiten:
- Wir speichern Daten über das Scoring-Objekt auf dem SQL / NoSQL-Server. Alle Operationen in Bezug auf Berechnungen, Algorithmen usw. werden direkt auf dem Server ausgeführt.
- Wir speichern Daten über das Scoring-Objekt auf dem SQL / NoSQL-Server. Basierend auf diesen Daten erstellen wir ein separates Objekt (z. B. eine Hash-Tabelle), mit dem wir alle grundlegenden Berechnungen durchführen.
- Die Daten über das Bewertungsobjekt werden im RAM gespeichert. Basierend auf diesen Daten erstellen wir ein separates Objekt (z. B. eine Hash-Tabelle), mit dem wir alle grundlegenden Berechnungen durchführen.
Grundvoraussetzungen für diesen Prozess:
- Arbeitsgeschwindigkeit;
- Zuverlässigkeit
- Überprüfbarkeit.
Jetzt lass uns reden. Wir setzen uns wie unsere Musketiere bei einer Tasse von dem, was sie dort getrunken haben, zum Beispiel Tee. Die Hauptsache ist, dass wir nicht alle Arten von Schwänzen mit den Wachen stören.
Wenn Langzeitspeicher benötigt wird, können Sie eine Tabelle mit den entsprechenden signifikanten Feldern auswählen. In NoSQL oder RAM ist es besser, Daten in Form einer Liste oder eines Verzeichnisses (Hash-Tabelle) von Objekten zu speichern.
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000 }
Mit den Spitzen mehr oder weniger klar. Wie lassen sich die Bögen / Kanten eines Diagramms am besten darstellen? Dazu müssen Sie das Grundprinzip aller Analysevorgänge im Diagramm verstehen. Der Zugriff auf einen Bogen / eine Kante sollte sehr schnell erfolgen, vorzugsweise sollte die Zugriffszeit O (1) sein. Ein Array oder eine Matrix fällt sofort ein - eine Struktur, in der auf jedes Element per Index schnell zugegriffen werden kann.
[i, j] - das Matrixelement bezeichnet den Bogen des Graphen, wobei i die Kennung des anfänglichen Scheitelpunkts ist, j die Kennung des endgültigen Scheitelpunkts ist, der Zugriff und die Auswahl des anfänglichen Scheitelpunkts direkt durch die Kennung des anfänglichen Scheitelpunkts erfolgen. Der Schnittpunkt von i und j speichert das Gewicht der Kante.
Diese Ansicht weist mehrere Nachteile auf:
- Oft ist die Struktur redundant, insbesondere wenn der Graph dünn ist (eine kleine Anzahl von Kanten). Es gibt viele leere Werte, die darauf hinweisen, dass keine Verbindung besteht.
- Um alle Nachbarn des Scheitelpunkts zu finden, muss das Array aller Elemente der i-ten Zeile der Beziehungsmatrix sortiert werden.
- Eine Matrix mit vielen Spalten kann nicht in der Datenbank gespeichert werden.
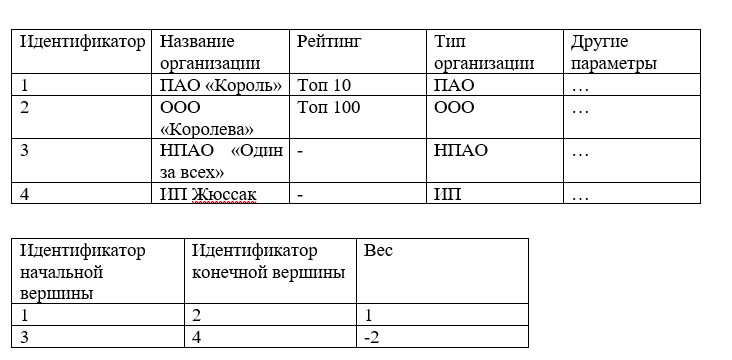
Die nächste Option zum Speichern von Bögen / Kanten ist eine Tabelle, dh eine Reihe von Spalten und Zeilen.
Zum Beispiel:

Eine solche Struktur kann leicht in einer relationalen Datenbank gespeichert werden und die erforderlichen Werte beim Ausführen von SQL-Abfragen auswählen. Wenn es jedoch um RAM geht, nimmt die Komplexität des Findens aller Kanten des Scheitelpunkts zu und nimmt im Allgemeinen O (n) an, wobei n die Anzahl aller Kanten des Diagramms ist.
Es gibt eine weitere sehr gute Graphspeichermethode für fast alle Systeme, ohne die oben beschriebenen Nachteile - dies ist eine Schlüsselwertreferenz oder eine Hash-Tabelle. Das Erhalten aller Kanten des gewünschten Scheitelpunkts erfolgt mit der Geschwindigkeit O (1).
Ein deutliches Minus ist, dass nicht alle Programmiersprachen dieses Design unterstützen.
Wie kann man sich eine ähnliche Struktur in verschiedenen Systemen vorstellen?
In der relationalen Datenbank können Sie die Beziehung der Objekttabellen und Kanten implementieren (vorheriger Absatz).
NoSQL
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
Wenn wir über den Schlüssel auf ein Objekt zugreifen, erhalten wir sofort eine Reihe seiner Verbindungen. Wenn wir ein ungewichtetes Diagramm anstelle eines Arrays von Objekten haben, können Sie ein Array von Bezeichnern von Nachbarn übergeben. Beziehungen: [3,4, ... n]. In Form einer Referenz ist der Schlüssel der Wert. Diese Option ähnelt der vorherigen. Im Verzeichnis, dem Schlüsselwert, können Sie dasselbe Objekt wie im vorherigen Beispiel speichern. Der Schlüssel ist natürlich die Kennung des Scheitelpunkts (es kann eine Zahl geben, es kann eine Zeichenfolge usw. geben, die ein bestimmtes Entwicklungssystem ermöglicht). Außerdem können Sie im Verzeichnis nur Arrays von Links und Informationen zu den Scheitelpunkten in einem anderen Verzeichnis speichern.
Graf[1] = { 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
oder
graf['one_for_all'] = 'Relations': [{3,2}, {4,5}, … {n, -5}]
In unserem Beispiel haben wir die Option zum Speichern von Daten im RAM mit der Erstellung einer Hash-Tabelle zum Bewerten von Daten gewählt. Die Zwischenergebnisse werden in eine Datei auf dem Server geschrieben.
Wir haben schlecht und schlecht definierte Speicherstrukturen. Jetzt ist es an der Zeit herauszufinden, wo wir mit der Erstellung unseres Analysemodells beginnen sollen. Beginnen wir mit einem einfachen - wir definieren die Interaktion mit den nächsten Nachbarn und mit den Nachbarn der Nachbarn (Freunde von Freunden).
Somit ist es möglich, die Wechselwirkung mit allen miteinander verbundenen Eckpunkten zu bestimmen. Nach unseren Beobachtungen ist die Interaktion mit Nachbarn, die tiefer als Stufe 2 liegen, nur in besonderen Fällen von Interesse und wird mit anderen Methoden berechnet. Die Komplexität dieser Berechnung ist ziemlich groß 0 (2 ^ n).
Um den Ball zu berechnen, verwenden wir einen leicht modifizierten Tiefensuchalgorithmus.
Die Verfeinerung wird wie folgt sein:
- Wir müssen keinen bestimmten Scheitelpunkt finden, sondern alle Scheitelpunkte bis zu einer Tiefe von n sortieren, für unsere Aufgabe n = 2.
- Wir sollten keine unnötigen Informationen speichern und davon ausgehen, dass die Berechnung für jeden Knoten im Diagramm durchgeführt werden kann, sodass die Ebene des Knotens nicht im Diagramm gespeichert wird.
- Wenn 2 oder mehr Pfade nach oben führen, werden alle Pfade ausgewertet, weil Wir haben es mit bidirektionaler Kommunikation zu tun und es ist notwendig, die Interaktion von Knoten vollständig zu bewerten.
- Sie müssen in der Lage sein, die Verschachtelungsebene eines beliebigen Scheitelpunkts für eine bestimmte Berechnung zu bestimmen.
Nun, die grundlegenden theoretischen Berechnungen wurden durchgeführt, auch wenn sie jemandem etwas Einfaches und Banales erscheinen. Aber für uns Gascons ist das alles wichtig und interessant, fast genauso wie der Eintritt in die Royal Musketeers.
Wir gehen zur praktischen Umsetzung über. Einer für alle und alle für einen!
Ich werde dich treffen! Wir werden uns auf jeden Fall treffen! Vielleicht in 10 oder 20 Jahren! Aber treffe dich!
Der nächste Artikel ist in der Nähe!