Dieser Artikel beschreibt den Prozess des Parsens des Satzes der russischen Sprache unter Verwendung der kontextfreien Grammatik und des LR-Analysealgorithmus.
Die Verarbeitung natürlicher Sprache ist die allgemeine Richtung der künstlichen Intelligenz und der mathematischen Linguistik. Es untersucht die Probleme der Computeranalyse und Synthese natürlicher Sprachen.
Im Allgemeinen ist der Prozess der Analyse von Sätzen in natürlicher Sprache wie folgt: (1) Aufteilen von Sätzen in syntaktische Einheiten - Wörter und Phrasen; (2) Bestimmung der grammatikalischen Parameter jeder Einheit; (3) die Definition der syntaktischen Beziehung zwischen Einheiten. Die Ausgabe ist ein abstrakter Analysebaum.
1. Aufteilen von Sätzen in syntaktische Einheiten
Ein Satz in natürlicher Sprache besteht aus Wortformen und starken Phrasen. Eine Anzahl von Wortformen eines bestimmten Wortes wird als Paradigma bezeichnet.
Zum Beispiel
"": [, , , , , ]
Phrasen - zusammengesetzte Konjunktionen, Prädikate oder stabile Ausdrücke - ändern sich nicht und können nicht ohne Bedeutungsverlust in kleinere Einheiten zerlegt werden. Mit einem Wort meinen wir außerdem jede syntaktische Einheit - eine Wortform oder eine Phrase.
Jedes Wort in einem Satz wird durch ein Tripel bestimmt:
- Wortform / Wortfolge ("geschrieben")
- normale Form des Wortes ("schreiben")
- eine Reihe von grammatikalischen Parametern (['VERB', 'sing', 'musc', 'tran', 'past'])
Daher hat die Aufschlüsselung des Satzes "
Er wird eindeutig nicht zur Sitzung kommen " die folgende Form:
[' ', '', '', '', '', ''] ' ' - ,
2. Definition von grammatikalischen Parametern (Grammatiken)
Ein Gramm ist ein Element einer grammatikalischen Kategorie; Verschiedene Grammatiken derselben Kategorie schließen sich gegenseitig aus und können nicht zusammen ausgedrückt werden. Für jede Wortform definieren wir einen Satz von sieben Grammatiken:
[ , , , , , , ]
Als Quelle verwenden wir das
OpenCorpora- Wörterbuch und seine Schnittstelle
pymorphy2 . Um nach einer Regel in der Grammatik für einen bestimmten Satz von Gramm zu suchen, werden wir sie in allgemeiner Form präsentieren:
'' [NOUN,plur,neut,accs] -> [NOUN,?numb,?per,?gend,accs,None,None] '?' ,
3. Definition der syntaktischen Beziehung zwischen Wörtern
Um die syntaktische Beziehung zwischen Wörtern zu bestimmen, verwenden wir kontextfreie Grammatik und LR-Analyse.
Grammatik- und LR-Analyse
Die formale Grammatik beschreibt eine Sprache in Form von sogenannten Produktionen. Zum Beispiel:
a -> ab | ac
bedeutet die Regel 'a' spawnt 'ab' ODER 'ac'.
Nichtterminale sind Objekte, die jede Essenz der Sprache bezeichnen (Satz, Formel usw.).
Terminals - Objekte, die direkt in der der Grammatik entsprechenden Sprache vorhanden sind und eine bestimmte, unveränderliche Bedeutung haben (Buchstaben, Wörter, Formeln usw.). Kontextfreie Grammatiken sind Grammatiken, bei denen die linken Seiten aller Produkte einzelne Nicht-Terminals sind.
Um die russische Sprache zu beschreiben, verwenden wir die Grammatiktheorie der Komponenten (
Phrasenstrukturgrammatik ), die besagt, dass jede komplexe grammatikalische Einheit aus zwei einfacheren und sich nicht überschneidenden Einheiten besteht, die als unmittelbare Komponenten bezeichnet werden. Folgende Komponenten werden unterschieden:
(1) Nominalgruppe (NP) NP[case='nomn'] -> N[case='nomn'] | ADJ[case='nomn'] NP[case='nomn'] | …
Das heißt, eine Nominativ-Nominalphrase ist ein Substantiv im Nominativ oder ein Adjektiv im Nominativ + eine Nominativ-Nominalphrase ODER eine andere.
(2) Verbale Gruppe (VP) VP[tran] -> V[tran] NP[case='ablt'] | ADJ VP[tran] | …
Mit anderen Worten, eine transitive Verbgruppe ist ein transitives Verb + eine ablative Substantivgruppe ODER ein kurzes Adjektiv + eine transitive Verbgruppe ODER eine andere.
(3) Präpositionalgruppe (PP) PP -> PREP NP[case='datv'] | ...
Eine Präposition ist eine Präposition + eine nominelle Dativgruppe ODER eine andere.
(4) Vollständiges Angebot (S) S -> NP[case='nomn'] VP[tran]
Ein vollständiger Satz liegt genau dann vor, wenn die Substantiv- und Verbgruppen in Anzahl, Person und Geschlecht übereinstimmen.
def agreement(self, node_left, node_right): ... if (numb1 and numb2): if (numb1 != numb2): return False; if (per1 and per2): if (per1 != per2): return False; if (gend1 and gend2): if (gend1 != gend2): return False; return True;
Ein unvollständiger Satz ist ein Satz, bei dem der Nominalteil weggelassen wird. In solchen Sätzen wird die Verbgruppe in der Regel durch ein unpersönliches Verb ausgedrückt. Zum Beispiel "
Ich möchte laufen ", "Es wird
hell ." Ein elliptischer Satz ist ein Satz, bei dem der Verbteil weggelassen und durch einen Bindestrich ersetzt wird. Zum Beispiel: "
Hinter dem Rücken ist ein Wald. Rechts und links sind Sümpfe ."
Um festzustellen, ob dieser Satz zur Grammatiksprache gehört, verwenden wir den LR-Analysealgorithmus. Bei diesem Algorithmus wird ein Analysebaum von unten nach oben (von den Blättern bis zur Wurzel) erstellt. Das Schlüsselelement des Algorithmus ist die Methode der "Transfer-Faltung" (englische
Shift-Reduktion ):
(1) Wir lesen die Zeichen der Eingabezeile, bis eine Kette vorhanden ist, die mit der rechten Seite einiger Regeln übereinstimmt. Legen Sie die gefundene Kette in den Stapel (Übertragung).
(2) Ersetzen Sie die durch die Regel gefundene Kette aus der Grammatik (Faltung).
Wenn alle Zeichenfolgenketten umbrochen wurden, gehört dieser Satz zur Grammatiksprache, und es ist mindestens ein Analysebaum vorhanden.
BaumUm die syntaktische Verbindung darzustellen, verwendet der Satz einen Binärbaum, wobei die Blätter Wörter (Terminals) mit einer Menge von Gramm sind und die Knoten Regeln (Preterminals) sind. Die Wurzel ist der Satz (nicht terminal).
Ein Baumknoten ist wie folgt definiert:
class Node: def __init__(self, word=None, tag=None, grammemes=None, leaf=False): self.word = word;
Die Konstruktion eines Baumes beginnt mit Blättern, denen eine Reihe von Wörtern oder Phrasen sowie eine Reihe seiner Grammatiken zugewiesen sind.
def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)
Als nächstes wird eine LR-Analyse durchgeführt. Jede Faltung entspricht der Vereinigung zweier Knoten oder Blätter unter einem gemeinsamen Vorfahren. Einem Vorfahrenknoten wird ein vorzeitiges Tag zugewiesen, das der Grammatikregel entspricht. Außerdem akzeptiert der Vorfahr Grammatiken des Hauptmitglieds der Gruppe, z. B. werden in der Verbgruppe V [tran] PRCL (z. B.
"möchte" ) die Zeichen aus dem transitiven Verb V [tran] übernommen nicht von einem PRCL-Partikel; und in der Substantivgruppe NP [case = 'nomn'] NP [case = 'gent'] (z. B.
"Vater von Kindern" ) werden die Zeichen dem Substantiv im Nominativ entnommen.
Es ist wichtig zu beachten, dass die Faltung in der festgelegten Reihenfolge erfolgt:
def reduce(self): self.reduce_ADJ() # self.reduce_NP() # self.reduce_PP() # self.reduce_VP() # self.reduce_S() #
Diese Reihenfolge ist wichtig, da sie die Möglichkeit ausschließt, einige Mitglieder des Vorschlags zu „verpassen“. Zuerst werden Adjektive zusammen mit Modifikatoren (z. B.
wahnsinnig schön ) gebildet, dann nominelle Gruppen, präpositionell und schließlich verbal. Danach wird nach vollständigen / unvollständigen Sätzen gesucht. Wenn keine vorhanden sind, hat der Baum keine Wurzel und daher gehört der Satz nicht zur Grammatiksprache.
Betrachten Sie ein bedingtes Beispiel für das Erstellen eines Baums:
sent = " " def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)

NP[case='nomn'] -> NPRO[case='nomn'] NP[case='accs'] -> N[case='accs'] NP[case='datv'] -> ADJ[case='datv'] NP[case='datv']

VP[tran] -> V[tran] NP[case='accs']

VP[tran] -> VP[tran] NP[case='datv']

S -> NP[case='nomn'] VP[tran]
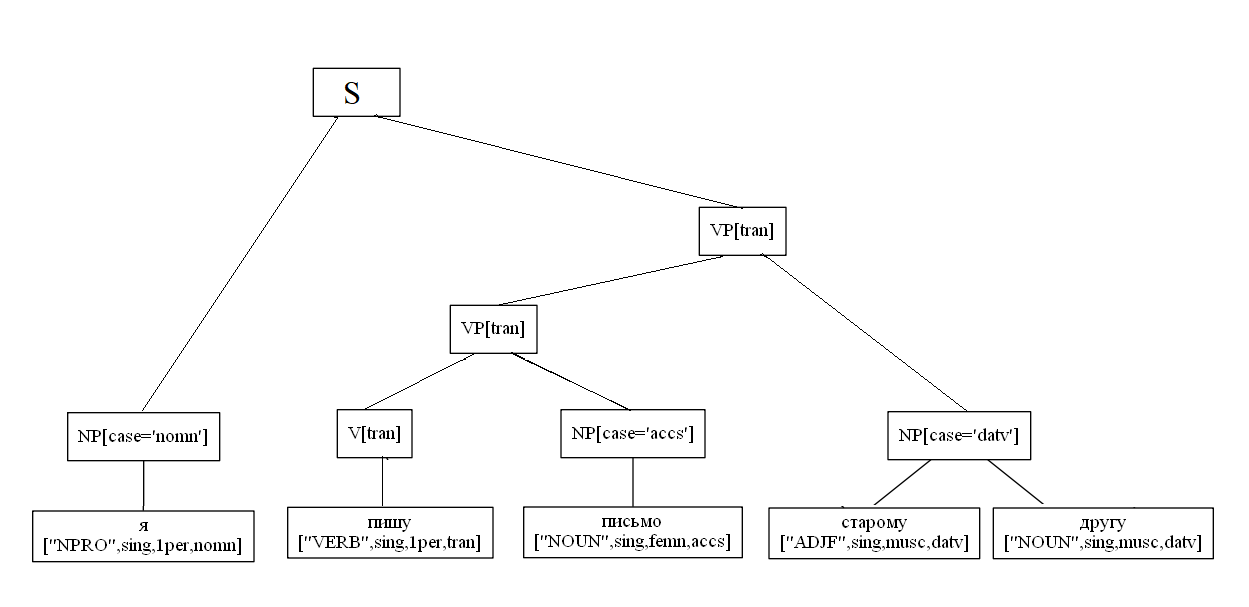
Ein spezielles Beispiel für das Parsen eines zweiteiligen Satzes:
import analyzer parser = analyzer.Parser() sent = " , ." t = parser.parse(sent) t[0].display() S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres'] NP[case='datv'] ['NOUN', 'sing', 'datv'] S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] PP PREP ['PREP'] NP[case='ablt'] ['NOUN', 'sing', 'femn', 'ablt'] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres']
Die Probleme
Die natürliche Sprache ist mehrdeutig, ihr Verständnis hängt von einer Reihe von Faktoren ab - von den Merkmalen der grammatikalischen Struktur der Sprache, von der nationalen Kultur, vom Sprecher usw. Wir listen die Hauptprobleme der maschinellen Sprachverarbeitung auf.
- Offenlegung von Anaphoren. Eine lebende Person versteht Anaphoren basierend auf gesundem Menschenverstand und Kontext, aber für einen Computer ist dies offensichtlich nicht immer einfach.
- Homonymie ist ein Zufall im Klang und in der Schreibweise von Spracheinheiten, deren Bedeutung nicht miteinander in Beziehung steht. Eine Lösung sind probabilistische Methoden. Im Satz „ Ich weiß das gut “ ist die Wahrscheinlichkeit, dass „ das “ ein Pronomen und kein Teilchen ist, größer. Solche Verfahren erfordern ein ausreichend großes Gehäuse.
- Die freie Reihenfolge der Wörter führt dazu, dass die Interpretation des Satzes mehrdeutig sein kann. Zum Beispiel: „ Sein bestimmt das Bewusstsein “ - was bestimmt was? Im Russischen wird die freie Wortreihenfolge durch entwickelte Morphologie, Servicewörter und Satzzeichen kompensiert, aber in den meisten Fällen stellt dies für den Computer ein zusätzliches Problem dar.
- Nicht alle Leute schreiben richtig. Im Internet neigen Menschen dazu, Abkürzungen, Neologismen, Ellipsen und andere Dinge zu verwenden, die der literarischen Norm widersprechen können. Aus diesem Grund ist die Verwendung kontextfreier Grammatiken und Wörterbücher nicht immer möglich.
Fazit
Das Projekt kann verwendet und bearbeitet werden. Es enthält den Analysator selbst, den Analysebaum sowie die russische Grammatik und Grammatik der russischen Sprache sowie ein kleines Wörterbuch mit zusammengesetzten Vereinigungen und Prädikaten, die nicht im OpenCorpora-Wörterbuch enthalten sind. Im Moment kann der Parser für lange komplexe Sätze 3 oder mehr Bäume finden, um dieses Problem zu lösen. Es werden Änderungen an der Grammatik vorgenommen, und es ist auch geplant, probabilistische Methoden zu verwenden.