Hallo allerseits! Wir veröffentlichen eine Übersetzung des Artikels, der für Studenten der neuen Gruppe des Data Engineer- Kurses erstellt wurde. Wenn Sie lernen möchten, wie Sie ein effizientes und skalierbares Datenverarbeitungssystem zu minimalen Kosten aufbauen können, lesen Sie die Aufzeichnung der Meisterklasse von Yegor Mateshuk!

Vor einigen Wochen schrieb ich einen Artikel über Hadoop, der verschiedene Themen behandelte
Teile und herausgefunden, welche Rolle er im Bereich der Datenentwicklung spielt. In diesem Artikel habe ich
Ich werde eine kurze Beschreibung der verschiedenen Dateiformate in Hadoop geben. Es ist schnell und einfach
Thema. Wenn Sie versuchen zu verstehen, wie Hadoop funktioniert und welchen Platz es in der Arbeit einnimmt
Data Engineer, lesen Sie hier meinen Artikel über Hadoop.
Hadoop-Dateiformate sind in zwei Kategorien unterteilt: zeilenorientiert und spaltenorientiert.
orientiert.
Zeilenorientiert:
Datenzeilen eines Typs werden zusammen gespeichert und bilden eine kontinuierliche
Speicher: SequenceFile, MapFile, Avro Datafile. Also bei Bedarf
Zugriff auf nur eine kleine Datenmenge aus einer Zeile, jedenfalls auf die gesamte Zeile
wird in den Speicher eingelesen. Serialisierungsverzögerungen können bis zu einem gewissen Grad auftreten
Lösen Sie das Problem, aber vollständig aus dem Aufwand des Lesens der gesamten Datenzeile mit
Laufwerk kann nicht loswerden. Zeilenorientierter Speicher
Geeignet in Fällen, in denen die gesamte Linie gleichzeitig bearbeitet werden muss
Daten.
Spaltenorientiert:
Die gesamte Datei ist in mehrere Datenspalten und alle Datenspalten aufgeteilt
zusammen gespeichert: Parkett, RCFile, ORCFile. Spaltenorientiertes Format (Spalten-
orientiert), ermöglicht es Ihnen, unnötige Spalten beim Lesen von Daten zu überspringen, was für geeignet ist
Situationen, in denen eine kleine Anzahl von Zeilen benötigt wird. Aber dieses Format des Lesens und Schreibens
erfordert mehr Speicherplatz, da sich die gesamte Cache-Zeile im Speicher befinden muss
(um eine Spalte mit mehreren Zeilen zu erhalten). Gleichzeitig ist es nicht geeignet für
Streaming-Aufzeichnung, da nach einem Aufnahmefehler die aktuelle Datei nicht sein kann
Wiederhergestellte und linear ausgerichtete Daten können wiederverwendet werden
synchronisiert vom letzten Synchronisationspunkt im Falle eines Schreibfehlers daher
Flume verwendet beispielsweise ein zeilenorientiertes Speicherformat.

Abbildung 1 (links). Logische Tabelle angezeigt
Abbildung 2 (rechts). Zeilenorientierter Speicherort (Sequenzdatei)

Abbildung 3. Spaltenorientiertes Layout
Wenn Sie die Spalten- oder Zeilenausrichtung noch nicht vollständig verstanden haben,
machen Sie sich keine Sorgen. Sie können diesem Link folgen, um den Unterschied zwischen den beiden zu verstehen.
Hier sind einige Dateiformate, die im Hadoop-System weit verbreitet sind:
Sequenzdatei
Das Speicherformat ändert sich abhängig davon, ob der Speicher komprimiert ist.
Verwendet es Schreibkomprimierung oder Blockkomprimierung:

Abbildung 4. Die interne Struktur der Sequenzdatei ohne Komprimierung und mit Komprimierung von Datensätzen.
Ohne Komprimierung:
Speichern in der Reihenfolge, die der Datensatzlänge, Schlüssellänge, Grad Wert,
Schlüsselwert und Wertwert. Bereich ist die Anzahl der Bytes. Serialisierung
durchgeführt mit dem angegebenen.
Datensatzkomprimierung:
Nur der Wert wird komprimiert und der komprimierte Codec wird im Header gespeichert.
Blockkomprimierung:
Mehrere Datensätze werden komprimiert, damit Sie sie verwenden können
Nutzen Sie die Ähnlichkeiten zwischen den beiden Einträgen und sparen Sie Platz. Flaggen
Synchronisationen werden am Anfang und Ende des Blocks hinzugefügt. Minimaler Blockwert
Wird durch das Attribut o.seqfile.compress.blocksizeset festgelegt.

Abbildung 4. Die interne Struktur der Sequenzdatei mit Blockkomprimierung.
Kartendatei
Eine Kartendatei ist eine Art Sequenzdatei. Nach dem Hinzufügen des Index zu
Die Sequenzdatei und ihre Sortierung führen zu einer Kartendatei. Der Index wird separat gespeichert
Datei, die normalerweise die Indizes jedes der 128 Einträge enthält. Indizes können sein
zum schnellen Abrufen in den Speicher geladen, da die Dateien, in denen Daten gespeichert sind,
angeordnet in der durch den Schlüssel angegebenen Reihenfolge.
Kartendateieinträge müssen in Ordnung sein. Ansonsten wir
Holen Sie sich eine IOException.
Abgeleitete Kartendateitypen:
- SetFile: Eine spezielle Map-Datei zum Speichern einer Folge von Schlüsseln des Typs
Beschreibbar Die Schlüssel werden in einer bestimmten Reihenfolge geschrieben. - ArrayFile: Der Schlüssel ist eine Ganzzahl, die die Position im Array und den Wert angibt
Typ Beschreibbar. - BloomMapFile: Optimiert für die get () -Methode einer Kartendatei mit
dynamische Bloom-Filter. Der Filter wird im Speicher gespeichert und die übliche Methode
get () wird nur zum Lesen aufgerufen, wenn der Schlüsselwert
existiert.
Zu den unten im Hadoop-System aufgeführten Dateien gehören RCFile, ORCFile und Parkett.
Die spaltenorientierte Version von Avro ist Trevni.
RC-Datei
Hive's Record Columnar File - Dieser Dateityp unterteilt die Daten zunächst in Zeilengruppen.
und innerhalb einer Zeilengruppe werden Daten in Spalten gespeichert. Seine Struktur ist wie folgt
Weg:

Abbildung 5. Speicherort der RC-Dateidaten in einem HDFS-Block.
Vergleichen Sie mit rein zeilen- und spaltenorientiert:
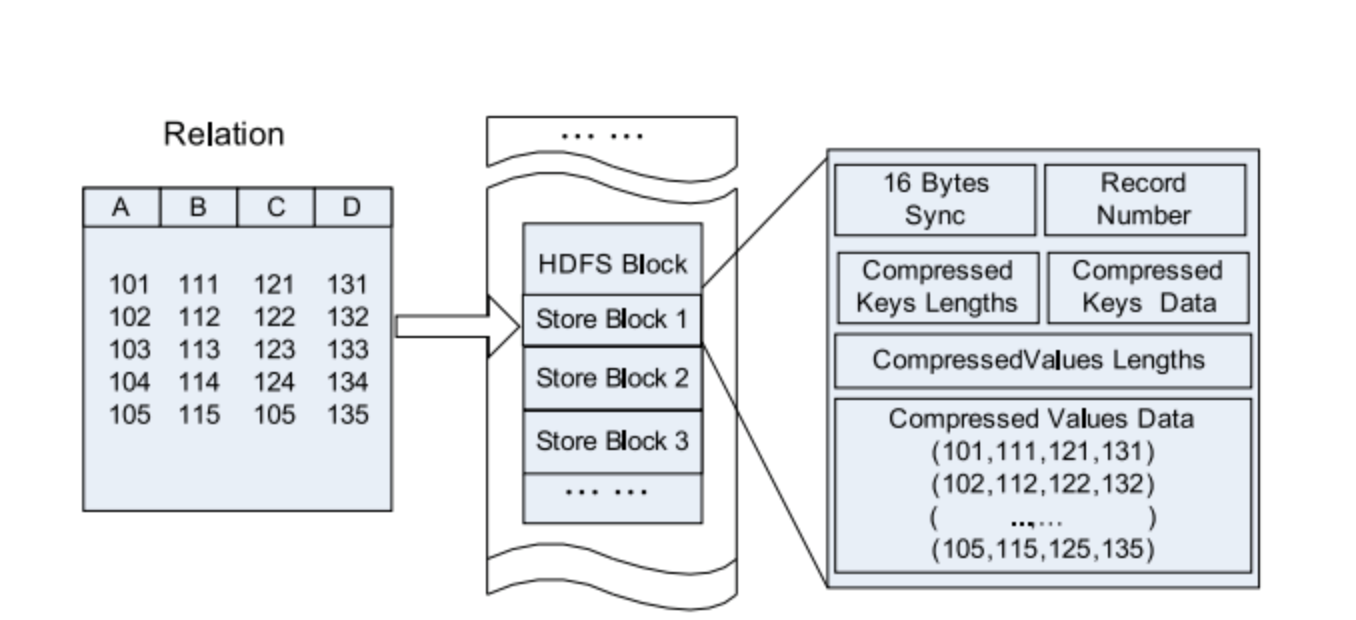
Abbildung 6. Zeile für Zeile im HDFS-Block speichern.

Abbildung 7. Gruppierung nach Spalten in einem HDFS-Block.
ORC-Datei
ORCFile (Optimized Record Columnar File) - ist ein effizienteres Format
Datei als rcfile. Es unterteilt die Daten intern in Streifen von jeweils 250 Millionen.
Jede Spur hat einen Index, Daten und eine Fußzeile. Der Index speichert das Minimum und
den Maximalwert jeder Spalte sowie die Position jeder Zeile in der Spalte.

Abbildung 8. Speicherort der Daten in der ORC-Datei
Hive verwendet die folgenden Befehle, um die .orc-Datei zu verwenden:
Parkett
Generisches spaltenorientiertes Speicherformat basierend auf Google Dremel.
Besonders gut für die Verarbeitung von Daten mit einem hohen Verschachtelungsgrad geeignet.
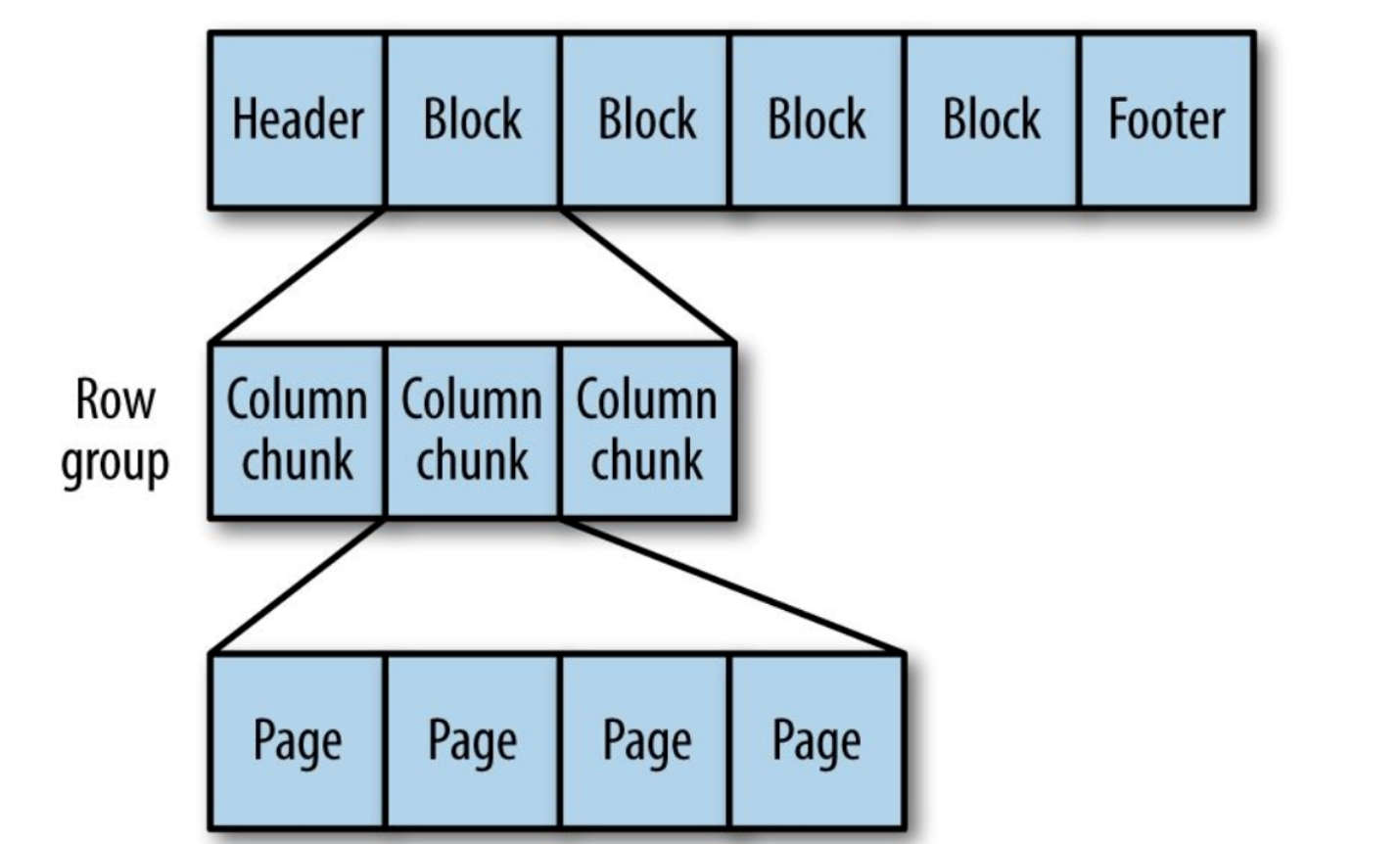
Abbildung 9. Die interne Struktur der Parkettdatei.
Parkett verwandelt verschachtelte Strukturen in flache Säulenspeicher.
Dies wird durch die Wiederholungsebene und die Definitionsebene (F und E) dargestellt und verwendet
Metadaten zum Wiederherstellen von Datensätzen beim Lesen von Daten zum Wiederherstellen aller Datensätze
Datei. Als nächstes sehen Sie ein Beispiel für Forschung und Entwicklung:
AddressBook { contacts: { phoneNumber: “555 987 6543” } contacts: { } } AddressBook { }

Das ist alles. Jetzt kennen Sie die Unterschiede in den Dateiformaten in Hadoop. Wenn
Finden Sie Fehler oder Ungenauigkeiten, wenden Sie sich bitte an
zu mir. Sie können mich auf LinkedIn kontaktieren.