Hinweis perev. : Dieses Material setzt eine wunderbare Reihe von Artikeln des AWS-Technologie-Evangelisten Adrian Hornsby fort, in denen die Bedeutung von Experimenten zur Abschwächung der Folgen von Ausfällen in IT-Systemen einfach und klar erläutert wurde.
"Wenn Sie den Plan nicht vorbereitet haben, planen Sie zu scheitern." - Benjamin Franklin
Im
ersten Teil dieser Artikelserie habe ich das Konzept des Chaos Engineering vorgestellt und erklärt, wie es hilft, Fehler im System zu finden und zu beheben, bevor sie zu Produktionsabstürzen führen. Es wurde auch darüber gesprochen, wie Chaos Engineering zu einem positiven kulturellen Wandel innerhalb von Organisationen beiträgt.
Am Ende des ersten Teils habe ich versprochen, über "Tools und Methoden zur Einführung von Fehlern in Systeme" zu sprechen. Leider hatte mein Kopf diesbezüglich eigene Pläne, und in diesem Artikel werde ich versuchen, die beliebteste Frage zu beantworten, die sich Menschen stellt, die sich mit Chaos-Engineering beschäftigen wollen:
Was soll man zuerst brechen? Gute Frage! Er scheint sich jedoch nicht um diesen Panda zu kümmern ...
 Leg dich nicht mit dem Chaospanda an!Kurze Antwort
Leg dich nicht mit dem Chaospanda an!Kurze Antwort : Streben Sie kritische Dienste auf dem Anforderungspfad an.
Eine lange, aber verständlichere Antwort : Um zu verstehen, wo Experimente mit Chaos beginnen sollen, achten Sie auf drei Bereiche:
- Schauen Sie sich die Geschichte der Fehler an und identifizieren Sie Muster.
- Entscheiden Sie sich für kritische Abhängigkeiten .
- Verwenden Sie das sogenannte. Überbewusstseinseffekt .
Es ist lustig, aber dieser Teil mit dem gleichen Erfolg könnte als
"Reise zur Selbsterkenntnis und Erleuchtung" bezeichnet werden. Darin werden wir anfangen, mit einigen coolen Werkzeugen zu "spielen".
1. Die Antwort liegt in der Vergangenheit
Wenn Sie sich erinnern, habe ich im ersten Teil das Konzept der Fehlerkorrektur (COE) eingeführt - die Methode, mit der wir unsere Fehler analysieren: Fehler in Technologie, Prozess oder Organisation -, um ihre Ursache (n) zu verstehen und zukünftige Wiederholungen zu verhindern . Im Allgemeinen sollte dies beginnen.
"Um die Gegenwart zu verstehen, muss man die Vergangenheit kennen." - Karl Sagan
Sehen Sie sich die Fehlerhistorie an, fügen Sie Tags in SOE oder postmortem'ah ein und klassifizieren Sie sie. Identifizieren Sie allgemeine Muster, die häufig zu Problemen führen, und stellen Sie sich für jedes SOE die folgende Frage:
"Könnte dies vorausgesehen und daher durch die Einführung einer Fehlfunktion verhindert worden sein?"Ich erinnere mich an einen Misserfolg zu Beginn meiner Karriere. Es hätte leicht verhindert werden können, wenn wir ein paar einfache Chaos-Experimente gehabt hätten:
Unter normalen Bedingungen reagieren Backend-Instanzen auf Integritätsprüfungen von einem Load Balancer (ELB ). ELB verwendet diese Überprüfungen, um Anforderungen an fehlerfreie Instanzen umzuleiten. Wenn sich herausstellt, dass eine bestimmte Instanz "ungesund" ist, sendet die ELB keine Anfragen mehr an sie. Einmal, nach einer erfolgreichen Marketingkampagne, wuchs das Verkehrsaufkommen und die Backends reagierten langsamer als gewöhnlich auf Gesundheitsprüfungen. Es sollte gesagt werden, dass diese Integritätsprüfungen tiefgreifend waren , dh der Status der Abhängigkeiten wurde überprüft.
Für eine Weile war jedoch alles in Ordnung.
Dann begann einer der Fälle bereits unter ziemlich stressigen Bedingungen, eine unkritische, reguläre Cron-Aufgabe aus der ETL-Kategorie auszuführen. Die Kombination aus hohem Datenverkehr und Cronjob beschleunigte die CPU-Auslastung um fast 100%. Das Überladen des Prozessors verlangsamte die Reaktionen auf Integritätsprüfungen noch mehr - so sehr, dass ELB entschied, dass bei der Instanz Probleme auftraten. Wie erwartet hat der Balancer die Verteilung des Datenverkehrs an ihn eingestellt, was wiederum zu einer Erhöhung der Belastung der verbleibenden Instanzen in der Gruppe führte.
Plötzlich scheiterten auch alle anderen Instanzen an der Integritätsprüfung.
Das Starten einer neuen Instanz erforderte das Herunterladen und Installieren von Paketen und dauerte viel länger als ELB, um sie nacheinander in der Autoscale-Gruppe zu trennen. Es ist klar, dass der gesamte Prozess bald einen kritischen Punkt erreichte und die Anwendung fiel.
Dann haben wir die folgenden Punkte für immer verstanden:
- Um die Software beim Erstellen einer neuen Instanz über einen längeren Zeitraum zu installieren, ist es besser, den unveränderlichen Ansatz und Golden AMI zu bevorzugen.
- In schwierigen Situationen sollten Reaktionen auf Gesundheitschecks und ELBs Vorrang haben - das Letzte, was Sie tun möchten, ist, den verbleibenden Instanzen das Leben zu erschweren.
- Das lokale Caching von Integritätsprüfungen (auch für einige Sekunden) hilft sehr.
- Führen Sie in einer schwierigen Situation keine Cron-Aufgaben und andere unkritische Prozesse aus - sparen Sie Ressourcen für die wichtigsten Aufgaben.
- Verwenden Sie bei der automatischen Skalierung kleinere Instanzen. Eine Gruppe von 10 kleinen Exemplaren ist besser als 4 große; Wenn eine Instanz ausfällt, werden im ersten Fall 10% des Datenverkehrs auf 9 Punkte verteilt, im zweiten Fall 25% des Datenverkehrs auf drei Punkte.
Könnte
dies also vorausgesehen und daher durch die Einführung des Problems verhindert werden?Ja und auf verschiedene Weise.
Erstens, indem Sie eine hohe CPU-Auslastung mit Tools wie
stress-ng oder
cpuburn :
❯ stress-ng --matrix 1 -t 60s
 stress-ng
stress-ngZweitens: Überladen der Instanz mit
wrk und anderen ähnlichen Dienstprogrammen:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
Die Experimente sind relativ einfach, aber sie können gute Denkanstöße geben, ohne den Stress eines echten Versagens erleben zu müssen.
Hören Sie hier
jedoch nicht auf . Versuchen Sie, den Fehler in einer Testumgebung zu reproduzieren, und überprüfen Sie Ihre Antwort auf die Frage „
Könnte dies vorausgesehen und daher durch die Einführung einer Fehlfunktion verhindert worden sein? ". Dies ist ein Mini-Chaos-Experiment innerhalb eines Chaos-Experiments, um Annahmen zu testen, aber beginnend mit einem Fehler.
 War es ein Traum oder ist es wirklich passiert?
War es ein Traum oder ist es wirklich passiert?Studieren Sie also die Fehlerhistorie, analysieren Sie die
COE , markieren und klassifizieren Sie sie nach dem „Schadensradius“ - genauer gesagt nach der Anzahl der betroffenen Kunden - und suchen Sie dann nach Mustern. Fragen Sie sich, ob dies durch die Einführung des Problems hätte vorausgesehen und verhindert werden können. Überprüfen Sie Ihre Antwort.
Wechseln Sie dann zu den gängigsten Mustern mit dem größten Bereich.
2. Erstellen Sie eine Abhängigkeitskarte
Nehmen Sie sich einen Moment Zeit, um über Ihre Bewerbung nachzudenken. Gibt es eine klare Karte seiner Abhängigkeiten? Wissen Sie, welche Auswirkungen sie im Falle eines Ausfalls haben werden?
Wenn Sie mit dem Code Ihrer Anwendung nicht sehr vertraut sind oder er zu groß geworden ist, kann es schwierig sein zu verstehen, was der Code tut und welche Abhängigkeiten er hat. Das Verständnis dieser Abhängigkeiten und ihrer möglichen Auswirkungen auf die Anwendung und die Benutzer ist entscheidend, um zu verstehen, wo mit dem Chaos Engineering begonnen werden soll: Die Komponente mit dem größten Zerstörungsradius wird der Ausgangspunkt sein.
Das Erkennen und Dokumentieren von Abhängigkeiten wird als "
Abhängigkeitszuordnung " bezeichnet. Normalerweise wird es für Anwendungen mit einer umfangreichen Codebasis unter Verwendung von Tools zum Profilieren von Code
(Codeprofilieren) und Instrumentieren
(Instrumentieren) ausgeführt . Sie können Karten auch erstellen, indem Sie den Netzwerkverkehr überwachen.
Es sind jedoch nicht alle Abhängigkeiten gleich (was den Prozess weiter verkompliziert). Einige sind
kritisch , andere sind
zweitrangig (zumindest theoretisch, da Abstürze häufig auf Abhängigkeitsprobleme zurückzuführen sind, die als unkritisch angesehen wurden) .
Ohne kritische Abhängigkeiten kann ein Dienst nicht funktionieren. Unkritische Abhängigkeiten
sollten sich im Falle eines Sturzes
nicht auf den Service auswirken. Um mit Abhängigkeiten umgehen zu können, müssen Sie die von der Anwendung verwendeten APIs genau kennen. Es kann viel komplizierter sein, als es sich anhört - zumindest für große Anwendungen.
Durchsuchen Sie zunächst alle APIs. Markieren Sie die wichtigsten
und kritischsten . Nehmen Sie die
Abhängigkeiten aus dem Code-Repository, überprüfen Sie die
Verbindungsprotokolle und sehen Sie sich dann die
Dokumentation an (natürlich, falls vorhanden - sonst haben Sie immer noch weitere Probleme). Verwenden Sie die Tools zum
Profilieren und Nachverfolgen und filtern Sie externe Anrufe.
Sie können Programme wie
netstat , ein Befehlszeilenprogramm, das eine Liste aller Netzwerkverbindungen (aktive Sockets) im System anzeigt. Geben Sie beispielsweise Folgendes ein, um alle aktuellen Verbindungen anzuzeigen:
❯ netstat -a | more

In AWS können Sie Flussprotokolle VPC verwenden - eine Methode, mit der Sie Informationen zum IP-Verkehr sammeln können, der zu oder von Netzwerkschnittstellen auf VPCs geleitet wird. Solche Protokolle können bei anderen Aufgaben hilfreich sein, z. B. bei der Suche nach einer Antwort auf die Frage, warum bestimmter Datenverkehr die Instanz nicht erreicht.
Sie können auch
AWS X-Ray verwenden . Mit X-Ray erhalten Sie eine detaillierte "End" -Übersicht
(Ende-zu-Ende) der Anforderungen, während sie die Anwendung durchlaufen, und erstellen eine Karte der grundlegenden Komponenten der Anwendung. Dies ist sehr praktisch, wenn Sie Abhängigkeiten identifizieren müssen.
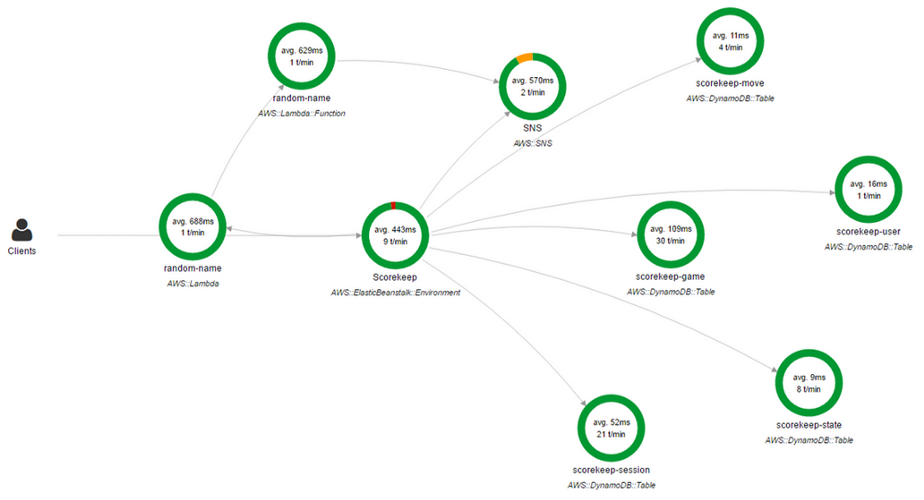 AWS Röntgenkonsole
AWS RöntgenkonsoleEine Netzwerkabhängigkeitskarte ist nur eine Teillösung. Ja, es wird angezeigt, welche Anwendung mit welcher verknüpft ist, es gibt jedoch andere Abhängigkeiten.
Viele Anwendungen verwenden DNS, um eine Verbindung zu Abhängigkeiten herzustellen, während andere den Diensterkennungsmechanismus oder sogar fest codierte IP-Adressen in Konfigurationsdateien verwenden können (z. B. in
/etc/hosts ).
Sie können beispielsweise mithilfe von
iptables ein
Blackhole-DNS erstellen und sehen, welche Fehler auftreten. Geben Sie dazu den folgenden Befehl ein:
❯ iptables -I OUTPUT -p udp --dport 53 -j REJECT -m comment --comment "Reject DNS"
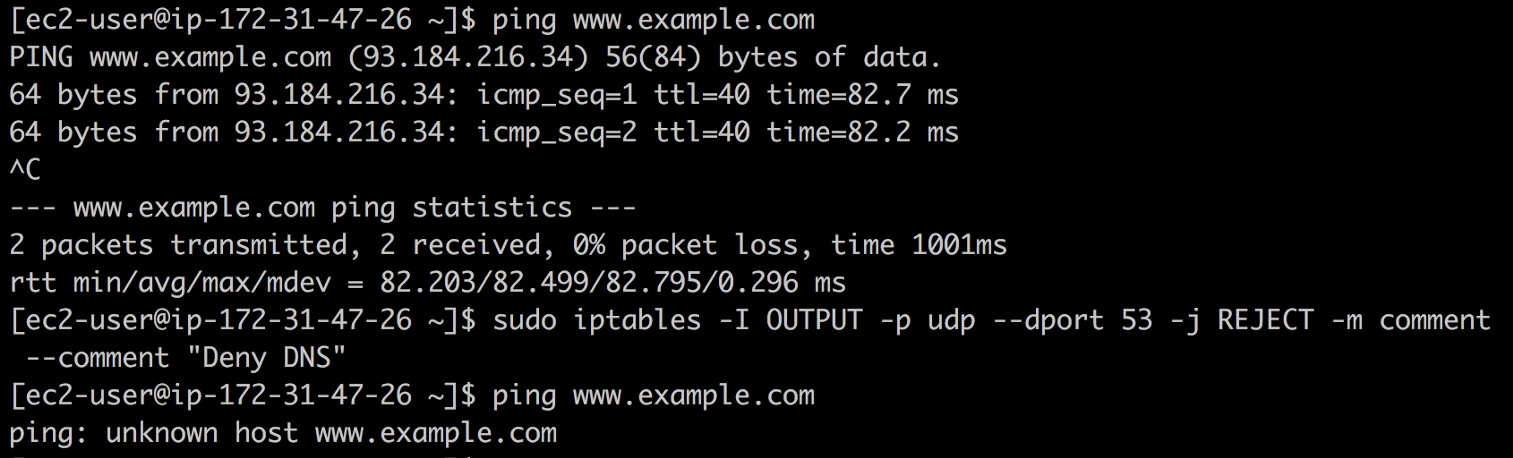 Schwarzes Loch DNS
Schwarzes Loch DNSWenn Sie IP-Adressen in
/etc/hosts oder anderen Konfigurationsdateien finden, von denen Sie nichts wissen (ja, dies passiert leider), können
iptables erneut
iptables .
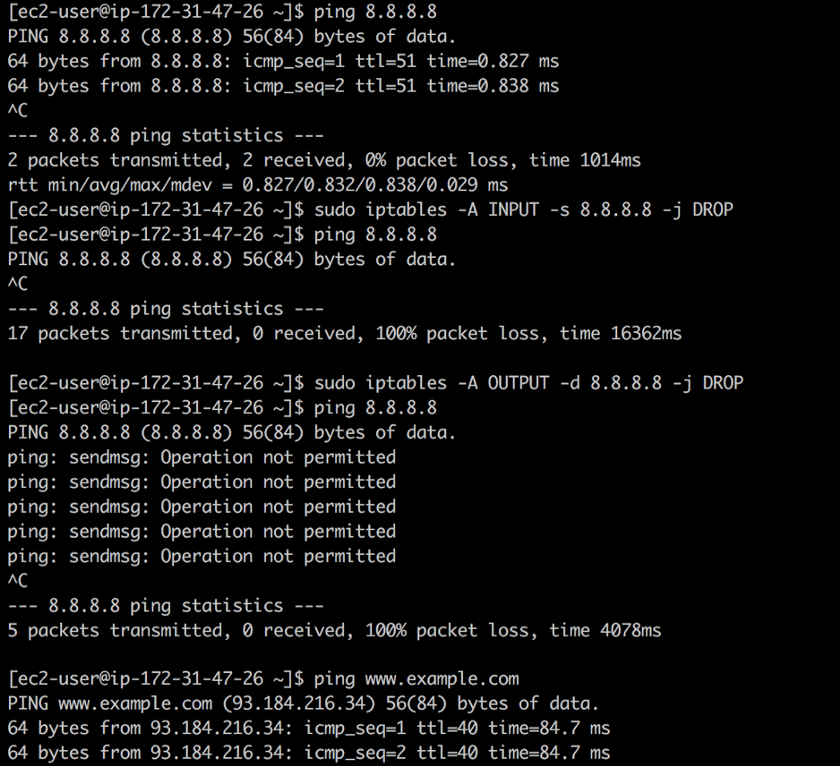
8.8.8.8 Sie finden
8.8.8.8 und wissen nicht, dass dies die Adresse des öffentlichen DNS-Servers von Google ist. Mit
iptables Sie eingehenden und ausgehenden Datenverkehr an diese Adresse mit den folgenden Befehlen schließen:
❯ iptables -A INPUT -s 8.8.8.8 -j DROP -m comment --comment "Reject from 8.8.8.8" ❯ iptables -A OUTPUT -d 8.8.8.8 -j DROP -m comment --comment "Reject to 8.8.8.8"
 Nahzugriff
NahzugriffDie erste Regel löscht alle Pakete aus dem öffentlichen DNS von Google:
ping funktioniert, aber Pakete werden nicht zurückgegeben. Die zweite Regel verwirft alle Pakete, die von Ihrem System in Richtung des öffentlichen DNS von Google kommen. Als Reaktion auf
ping Vorgang nicht zugelassen .
Hinweis: In diesem speziellen Fall ist es besser, whois 8.8.8.8 , dies ist jedoch nur ein Beispiel.Sie können noch tiefer in das Kaninchenloch vordringen, da alles, was TCP und UDP verwendet, tatsächlich von der IP abhängt. In den meisten Fällen ist IP an ARP gebunden. Vergessen Sie nicht die Firewalls ...
 Wenn Sie sich für eine rote Pille entscheiden, bleiben Sie im Wunderland und ich werde zeigen, wie tief das Kaninchenloch geht. “
Wenn Sie sich für eine rote Pille entscheiden, bleiben Sie im Wunderland und ich werde zeigen, wie tief das Kaninchenloch geht. “Ein radikalerer Ansatz ist es
, die Autos
einzeln auszuschalten und zu sehen, was kaputt ist ... ein "Affe des Chaos" zu werden. Natürlich sind viele Produktionssysteme nicht für einen solch groben Angriff ausgelegt, aber zumindest kann er in einer Testumgebung ausprobiert werden.
Das Erstellen einer Abhängigkeitskarte ist oft eine sehr lange Übung. Ich habe kürzlich mit einem Kunden gesprochen, dass ich fast zwei Jahre damit verbracht habe, ein Tool zu entwickeln, das im halbautomatischen Modus Abhängigkeitskarten für Hunderte von Mikrodiensten und Teams generiert.
Das Ergebnis ist jedoch äußerst interessant und nützlich. Sie werden viel über Ihr System, seine Abhängigkeiten und Operationen lernen. Seien Sie noch einmal geduldig: Die Reise selbst ist von größter Bedeutung.
3. Vorsicht vor Arroganz
"Wer von was träumt, glaubt daran." - Demosthenes
Haben Sie jemals von der
Auswirkung von Überbewusstsein gehört ?
Laut Wikipedia ist der Effekt von Überbewusstsein "eine kognitive Verzerrung, bei der das Vertrauen einer Person in ihre Handlungen und Entscheidungen viel höher ist als die objektive Genauigkeit dieser Urteile, insbesondere wenn das Vertrauensniveau relativ hoch ist."
 Basierend auf Instinkt und Erfahrung ...
Basierend auf Instinkt und Erfahrung ...Aus eigener Erfahrung kann ich sagen, dass diese Verzerrung ein guter Hinweis darauf ist, wo man mit dem Chaos Engineering beginnen soll.
Vorsicht vor dem selbstbewussten Bediener:
Charlie: Dieses Ding ist seit ungefähr fünf Jahren nicht mehr gefallen, alles ist in Ordnung!
Fehler: "Warte ... ich werde bald sein!"
Bias als Folge des Selbstvertrauens ist aufgrund verschiedener Faktoren, die es beeinflussen, eine heimtückische und sogar gefährliche Sache. Dies gilt insbesondere dann, wenn Teammitglieder ihre Seele in eine bestimmte Technologie stecken oder viel Zeit mit „Korrekturen“ verbringen.
Zusammenfassend
Die Suche nach einem Ausgangspunkt für Chaos Engineering liefert immer mehr Ergebnisse als erwartet, und Teams, die zu schnell anfangen zu brechen, verlieren die globalere und interessantere Essenz von (Chaos)
Engineering aus den Augen - die kreative Anwendung
wissenschaftlicher Methoden und
empirischer Beweise für Design, Entwicklung , Betrieb, Wartung und Verbesserung von (Software-) Systemen.
Damit endet der zweite Teil. Bitte schreiben Sie Bewertungen, teilen Sie Meinungen oder klatschen Sie einfach in die Hände auf
Medium .
Im nächsten Teil werde ich mich wirklich mit den Tools und Techniken zur Einführung von Systemfehlern befassen. Bis! AKTUALISIERT (19. Dezember): Die
Übersetzung des dritten Teils ist verfügbar.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: