Im Allgemeinen sieht die Gesichtserkennung und Identifizierung von Menschen anhand ihrer Ergebnisse für Älteste wie Sex im Teenageralter aus - jeder spricht viel über ihn, aber nur wenige üben. Es ist klar, dass wir nicht länger überrascht sind, dass Facebook / VK nach dem Herunterladen von Fotos von freundlichen Versammlungen vorschlägt, die auf dem Bild gefundenen Personen zu markieren. Hier wissen wir jedoch intuitiv, dass soziale Netzwerke eine gute Hilfe in Form eines Verbindungsdiagramms einer Person darstellen. Und wenn es keinen solchen Graphen gibt? Beginnen wir jedoch in der richtigen Reihenfolge.

Anfänglich entstand die Gesichtserkennung und Identifikation von „Freund / Feind“ mit uns aus ausschließlich häuslichen Bedürfnissen - Süchtige betraten die Tür eines Kollegen und überwachten ständig das Bild von der installierten Videokamera und zerlegten sogar, wo der Nachbar und wo der Fremde keine Lust hatten nein
Daher wurde in nur einer Woche ein Prototyp auf dem Knie montiert, der aus einer IP-Kamera, einem Einplatinengerät, einem Bewegungssensor und der Python-Erkennungsbibliothek face_recognition bestand. Da sich die Python-Bibliothek auf einer Single-Plate-Hardware befand, die ziemlich leistungsfähig ist ... sagen wir es vorsichtig, nicht sehr schnell, haben wir beschlossen, den Verarbeitungsprozess wie folgt aufzubauen:
- der Bewegungssensor bestimmt, ob sich in dem ihm anvertrauten Raum bewegt, und signalisiert seine Anwesenheit;
- Ein auf gstreamer basierender schriftlicher Dienst, der ständig einen Stream von einer IP-Kamera empfängt, unterbricht 5 Sekunden vor und 10 Sekunden nach der Erkennung und leitet ihn zur Analyse an die Erkennungsbibliothek weiter.
- Sie wiederum sieht sich das Video an, findet dort Gesichter, vergleicht sie mit bekannten Samples und gibt das Video, falls es unbekannt ist, an den Telegrammkanal weiter. Später sollte es an derselben Stelle gesteuert werden, um Fehlalarme sofort auszuschalten - zum Beispiel, wenn ein Nachbar drehte sich zur Kamera auf der falschen Seite der Proben.
Der gesamte Prozess wurde von unserem geliebten Erlang zusammengeklebt, und beim Testen an Kollegen bewies er seine minimale Arbeitsfähigkeit.
Das zusammengebaute Modell fand jedoch keine Anwendung im wirklichen Leben - nicht wegen seiner technischen Unvollkommenheit, die zweifellos war - wie die Erfahrung zeigt, hat das Sammeln auf dem Knie unter Gewächshaus-Bürobedingungen eine sehr schlechte Tendenz, vor Ort und zum Zeitpunkt der Demonstration gegenüber dem Kunden zu brechen und wegen der organisatorischen lehnten die Bewohner des Eingangs die Mehrheit der Videoüberwachung ab.
Das Projekt ging ins Regal und stocherte regelmäßig mit einem Stock für Demonstrationen während des Verkaufs und den Drang, im persönlichen Haushalt wiedergeboren zu werden.
Alles hat sich geändert, seit wir ein spezifischeres und recht kommerzielles Projekt zum gleichen Thema hatten. Da es nicht möglich wäre, Ecken mit einem Bewegungssensor direkt aus der Problemstellung herauszuschneiden, musste ich mich eingehender mit den Nuancen des Suchens und Erkennens von Gesichtern in drei Köpfen (okay, zweieinhalb, wenn Sie meine zählen) direkt im Stream befassen. Und dann geschah eine Offenbarung.
Das Problem ist, dass die meisten Ergebnisse zu diesem Thema rein akademische Skizzen zum Thema sind: „Ich musste einen Artikel in einer Zeitschrift zu einem modischen Thema schreiben und ein Häkchen für die Veröffentlichung bekommen.“ Ich lenke nicht von den Verdiensten der Wissenschaftler ab - unter den Artikeln, die ich fand, gab es viele nützliche und interessante, aber leider muss ich zugeben, dass die Reproduzierbarkeit der Arbeit ihres auf Github veröffentlichten Codes zu wünschen übrig lässt oder wie ein zweifelhaftes Unterfangen mit Zeitverschwendung aussieht.
Zahlreiche Frameworks für neuronale Netze und maschinelles Lernen waren oft schwer zu heben - die Gesichtserkennung war für sie eine separate enge Aufgabe, die für eine Vielzahl von Problemen, die sie lösten, uninteressant war. Mit anderen Worten, ein vorgefertigtes Beispiel zu nehmen und es auf der Zielhardware auszuführen, nur um zu überprüfen, wie es funktioniert und ob es funktioniert, hat nicht funktioniert. Das war kein Beispiel, und die Notwendigkeit, es zu erhalten, deutete auf eine schlechte Suche bei der Zusammenstellung bestimmter Bibliotheken bestimmter Versionen für streng definierte Betriebssysteme hin. Das heißt, in Bewegung zu nehmen und zu fliegen - buchstäblich Krümel wie die zuvor erwähnte face_recognition, die wir für das vorherige Handwerk verwendet haben.
Große Unternehmen haben uns wie immer gerettet. Sowohl Intel als auch Nvidia haben seit langem die wachsende Dynamik und kommerzielle Attraktivität dieser Aufgabenklasse gespürt, aber als Anbieter von Geräten verteilen sie in erster Linie ihre Frameworks zur kostenlosen Lösung spezifischer Anwendungsprobleme.
Unser Projekt war eher nicht forschend, sondern experimentell, daher haben wir die Lösungen einzelner Anbieter nicht analysiert und verglichen, sondern lediglich das erste mit dem Ziel, einen vorgefertigten Prototyp zu sammeln und im Kampf zu testen und dabei die schnellstmögliche Antwort zu erhalten. Daher fiel die Wahl sehr schnell auf
Intel OpenVINO - eine Bibliothek für die praktische Anwendung des maschinellen Lernens in angewandten Aufgaben.
Zu Beginn haben wir einen Stand zusammengestellt, der traditionell aus einem Nettop mit einem Intel Core i3-Prozessor und IP-Kameras chinesischer Anbieter auf dem Markt besteht. Die Kamera war direkt mit dem Nettop verbunden und versorgte ihn mit einem RTSP-Stream mit einem nicht sehr großen FPS, basierend auf der Annahme, dass die Leute immer noch nicht wie bei Wettbewerben davor laufen würden. Die Verarbeitungsgeschwindigkeit eines Frames (Suchen und Erkennen von Gesichtern) schwankte im Bereich von zehn bis Hunderten von Millisekunden, was völlig ausreichte, um den Suchmechanismus für Personen, die vorhandene Stichproben verwenden, einzubetten. Darüber hinaus hatten wir auch einen Backup-Plan - Intel verfügt über einen speziellen Coprozessor, um die Berechnungen von neuronalen Netzen des
Neural Compute Stick 2 zu beschleunigen, die wir verwenden könnten, wenn wir keinen Allzweckprozessor hätten. Aber - bisher ist nichts passiert.
Nachdem wir die Montage abgeschlossen und die Funktionalität der grundlegenden Beispiele überprüft hatten - eine Besonderheit des Intel SDK war eine schrittweise und sehr detaillierte Beispielanleitung -, begannen wir mit der Erstellung der Software.
Die Hauptaufgabe für uns bestand darin, nach einer Person im Sichtfeld der Kamera zu suchen, sie zu identifizieren und rechtzeitig über ihre Anwesenheit zu informieren. Dementsprechend mussten wir nicht nur Gesichter erkennen und mit Mustern vergleichen (wie dies zu diesem Zeitpunkt nicht weniger Fragen verursachte als alles andere), sondern auch sekundäre Dinge des Schnittstellenplans bereitstellen. Wir müssen nämlich Bilder mit den Gesichtern der notwendigen Personen von derselben Kamera für ihre spätere Identifizierung erhalten. Warum ich denke, dass es bei derselben Kamera auch ganz offensichtlich ist: Der Installationspunkt der Kamera auf dem Objekt und die Objektivoptik führen zu bestimmten Verzerrungen, die vermutlich die Qualität der Erkennung beeinträchtigen können. Wir verwenden eine andere Quelle für Quelldaten als ein Tracking-Tool.
Das heißt, Zusätzlich zum Stream-Handler selbst benötigen wir mindestens ein Videoarchiv und einen Videodateianalysator, der alle erkannten Gesichter von der Aufzeichnung isoliert und die am besten geeigneten als Referenz speichert.
Wie immer haben wir das bekannte Erlang und PostgreSQL als Bindeglied zwischen ffmpeg, Anwendungen auf OpenVINO und Telegram Bot API für Warnungen verwendet. Darüber hinaus benötigten wir eine Web-Benutzeroberfläche, um die Mindestanforderungen für die Verwaltung des Komplexes bereitzustellen, die unser Kollege frontender auf VueJS hochgeladen hatte.
Die Logik der Arbeit war wie folgt:
- Unter der Kontrolle einer Steuerebene (in Erlang) schreibt ffmpeg in fünfminütigen Abschnitten einen Stream von der Kamera zum Video. Ein separater Prozess stellt sicher, dass die Aufzeichnungen in einem genau festgelegten Volumen gespeichert werden, und bereinigt die ältesten, wenn dieser Schwellenwert erreicht ist.
- Über die Web-Benutzeroberfläche können Sie alle Datensätze anzeigen. Sie sind in chronologischer Reihenfolge angeordnet. Auf diese Weise können Sie das gewünschte Fragment isolieren und zur Verarbeitung senden, obwohl dies nicht ohne Schwierigkeiten möglich ist.
- Die Verarbeitung besteht darin, das Video zu analysieren und Frames mit erkannten Gesichtern zu extrahieren. Es handelt sich lediglich um die OpenVINO-basierte Software (ich muss sagen, hier haben wir es geschafft, den Winkel ein wenig zu verringern - die Software zum Analysieren des Streams und zum Analysieren von Dateien ist fast identisch, weshalb das meiste davon verwendet wurde eine gemeinsam genutzte Bibliothek, und die Dienstprogramme selbst unterscheiden sich nur in der Verarbeitungskette (a la modularer gstreamer). Die Verarbeitung erfolgt auf Video, wobei die gefundenen Gesichter mithilfe eines speziell trainierten neuronalen Netzwerks isoliert werden. Die resultierenden Fragmente des Rahmens, der Gesichter enthält, fallen in ein anderes neuronales Netzwerk, das einen 256-Elemente-Vektor bildet, der tatsächlich die Koordinaten der Referenzpunkte des Gesichts einer Person ist. Dieser Vektor, der erkannte Rahmen und die Koordinaten des Rechtecks der gefundenen Fläche werden in der Datenbank gespeichert.
- Nachdem die Verarbeitung abgeschlossen ist, öffnet der Bediener die verschiedenen gezeichneten Rahmen, ist entsetzt über ihre Anzahl und fährt mit der Suche nach Zielpersonen fort. Ausgewählte Beispiele können einer vorhandenen Person hinzugefügt oder eine neue erstellt werden. Nach Abschluss der Verarbeitung der Aufgabe werden die Analyseergebnisse gelöscht, mit Ausnahme der gespeicherten Vektoren, die den Aufzeichnungen von Observablen zugeordnet sind.
- Dementsprechend können wir jederzeit sowohl Frames als auch Erkennungsvektoren betrachten und bearbeiten, wobei erfolglose Samples gelöscht werden.
- Parallel zum Erkennungszyklus im Hintergrund funktioniert der Stream-Analysedienst immer, was dasselbe tut, jedoch mit dem Stream von der Kamera. Er wählt Gesichter im beobachteten Fluss aus und vergleicht sie mit Proben aus der Datenbank, die auf der einfachen Annahme beruhen, dass die Vektoren einer Person näher beieinander liegen als alle anderen Vektoren. Eine paarweise Berechnung des Abstands zwischen den Vektoren erfolgt, wenn der Schwellenwert erreicht ist, eine Aufzeichnung der Erkennung und ein Rahmen in die Datenbank gestellt werden. Darüber hinaus wird in naher Zukunft eine Person zur Stoppliste hinzugefügt, wodurch mehrere Benachrichtigungen über dieselbe Person vermieden werden.
- Die Steuerebene überprüft regelmäßig das Erkennungsprotokoll und benachrichtigt bei neuen Einträgen mit einer Nachricht mit dem angehängten Foto und hebt das Gesicht durch den Bot für diejenigen hervor, die gemäß den Einstellungen zugelassen sind.
Es sieht ungefähr so aus:
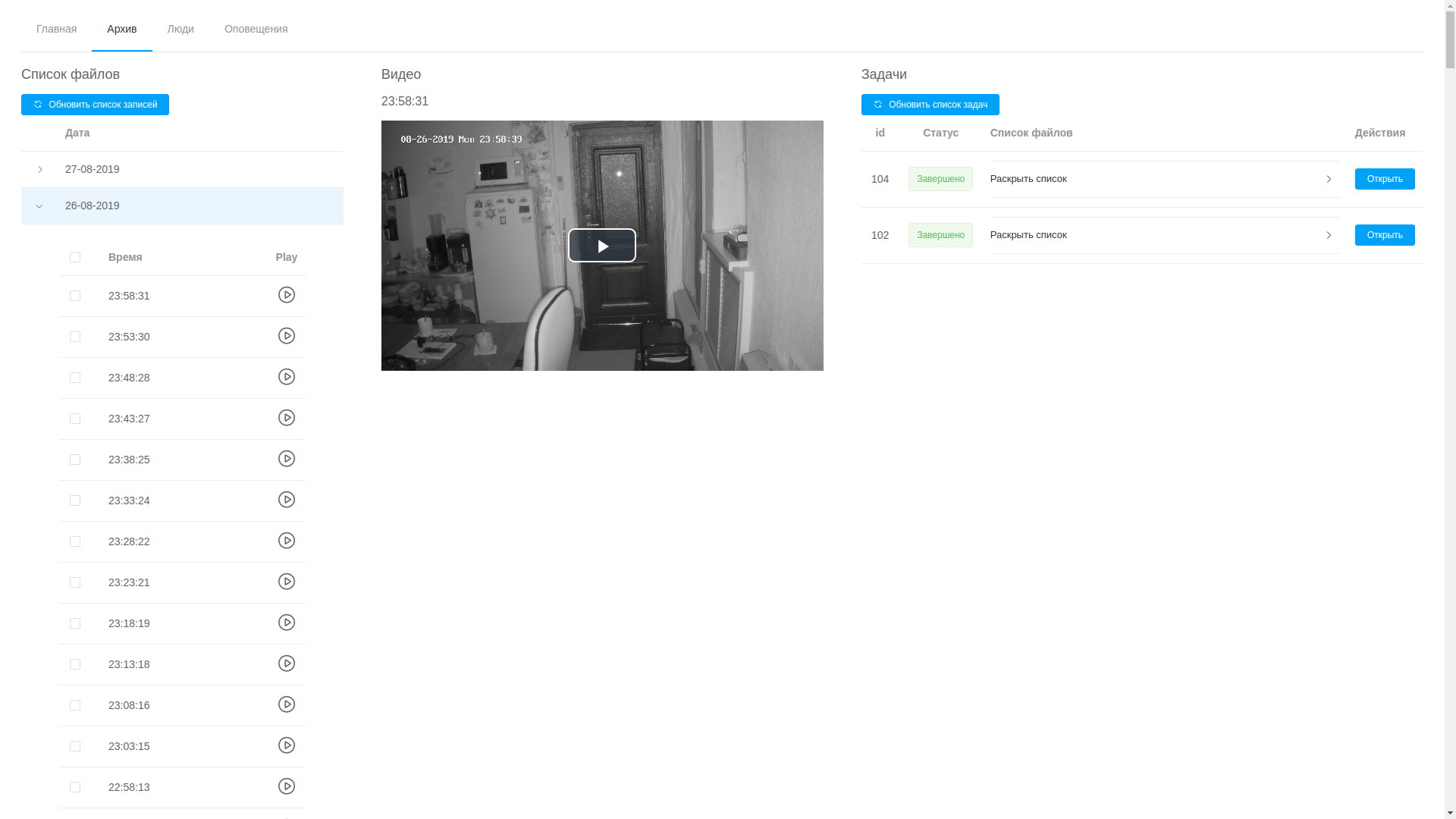 Archiv anzeigen
Archiv anzeigen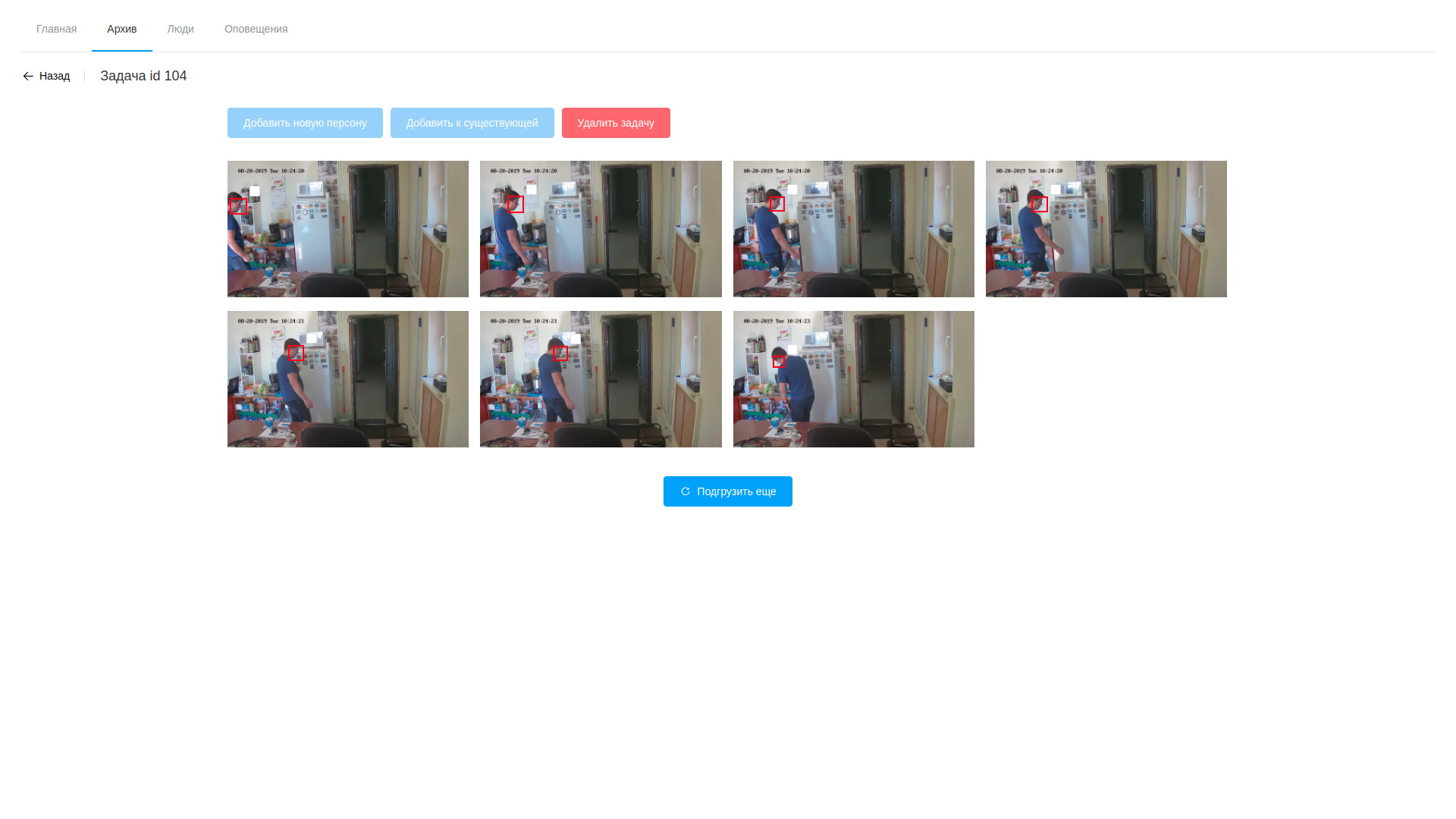 Ergebnisse der Videoanalyse
Ergebnisse der Videoanalyse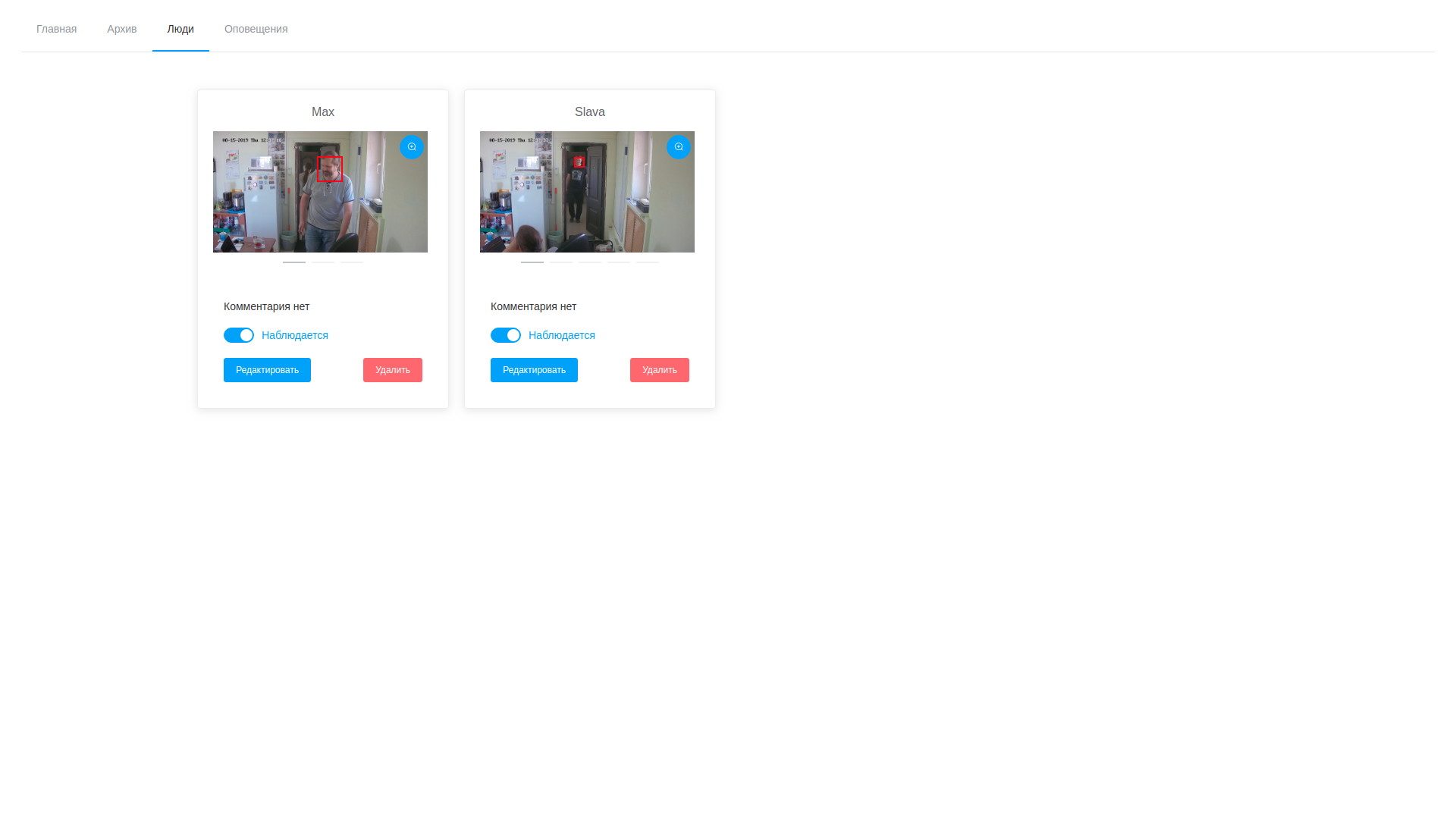 Liste der beobachteten Persönlichkeiten
Liste der beobachteten PersönlichkeitenDie resultierende Lösung ist in vielerlei Hinsicht umstritten und manchmal sogar nicht optimal, sowohl hinsichtlich der Produktivität als auch hinsichtlich der Verkürzung der Reaktionszeit. Ich wiederhole jedoch, wir hatten nicht das Ziel, sofort ein effektives System zu erhalten, sondern einfach diesen Weg zu gehen und die maximale Anzahl von Kegeln zu füllen, enge Pfade und potenzielle nicht offensichtliche Probleme zu identifizieren.
Das zusammengebaute System wurde eine Woche lang unter Gewächshausbürobedingungen getestet. Während dieser Zeit wurden die folgenden Beobachtungen notiert:
- Es besteht eine eindeutige Abhängigkeit der Erkennungsqualität von der Qualität der Originalproben. Wenn die beobachtete Person die Beobachtungszone zu schnell passiert, hinterlässt sie mit hoher Wahrscheinlichkeit keine Daten für die Probenahme und wird nicht erkannt. Ich denke jedoch, dass dies eine Frage der Feinabstimmung des Systems ist, einschließlich der Beleuchtungs- und Videostream-Parameter.
- Da das System Gesichtselemente (Augen, Nase, Mund, Augenbrauen usw.) erkennt, kann es leicht getäuscht werden, indem ein visuelles Hindernis zwischen Gesicht und Kamera (Haare, dunkle Brille, Kapuze usw.) gelegt wird - das Gesicht, höchstwahrscheinlich wird es gefunden, aber der Vergleich mit den Proben wird aufgrund der starken Diskrepanz zwischen den Detektionsvektoren und den Proben nicht funktionieren;
- gewöhnliche Brillen wirken sich nicht zu stark aus - wir hatten Beispiele für positive Reaktionen bei Menschen mit Brille und falsch negative Reaktionen bei Menschen, die zum Testen eine Brille aufsetzten;
- Wenn sich der Bart auf den Originalproben befand und dann verschwunden war, wurde die Anzahl der Operationen reduziert (der Autor dieser Linien hat seinen Bart auf 2 mm gekürzt und die Anzahl der Operationen darauf halbiert).
- Es fanden auch falsch positive Ergebnisse statt. Dies ist eine Gelegenheit für ein weiteres Eintauchen in die Mathematik des Problems und möglicherweise eine Lösung für die Frage der partiellen Entsprechung der Vektoren und die optimale Methode zur Berechnung des Abstands zwischen ihnen. Feldtests sollten diesbezüglich jedoch noch mehr Probleme aufzeigen.
Was soll kommen? Überprüfen Sie das System im Kampf, optimieren Sie den Verarbeitungszyklus der Erkennung, vereinfachen Sie die Suche nach Ereignissen im Videoarchiv, fügen Sie der Analyse weitere Daten hinzu (Alter, Geschlecht, Emotionen) und weitere 100.500 kleine und weniger wichtige Aufgaben, die noch erledigt werden müssen. Aber den ersten Schritt auf dem Weg von tausend Schritten haben wir bereits getan. Wenn jemand seine Erfahrungen bei der Lösung solcher Probleme teilt oder interessante Links zu diesem Thema gibt, bin ich sehr dankbar.