
In der Umgebung von SRE- / DevOps-Ingenieuren werden Sie nicht überrascht sein, dass eines Tages ein Kunde (oder ein Überwachungssystem) erscheint und sagt, dass „alles verloren ist“: Die Website funktioniert nicht, Zahlungen vergehen nicht, das Leben verfällt ... Egal wie ich in dieser Situation helfen möchte Ohne ein einfaches und verständliches Werkzeug kann dies sehr schwierig sein. Oft ist das Problem im Code der Anwendung selbst verborgen - Sie müssen es nur lokalisieren.
Und in Trauer und Freude ...
So kam es, dass wir New Relic schon lange sehr mochten. Es war und ist ein hervorragendes Tool zur Überwachung der Anwendungsleistung und ermöglicht es Ihnen, die Microservice-Architektur (mithilfe Ihres Agenten) und vieles mehr zu instrumentieren. Und alles könnte wunderbar sein, wenn nicht die Änderungen in der Preispolitik des Dienstes: Die
Kosten haben sich seit 2013 mehr als verdreifacht . Darüber hinaus erfordert die Erlangung eines Testkontos seit letztem Jahr die Kommunikation mit einem persönlichen Manager, was es schwierig macht, das Produkt einem potenziellen Kunden zu präsentieren.
Die übliche Situation: New Relic wird nicht „laufend“ benötigt, es wird nur zu dem Zeitpunkt in Erinnerung gerufen, als die Probleme begannen. Sie müssen jedoch weiterhin regelmäßig zahlen (140 USD pro Server und Monat), und in der automatisch skalierbaren Cloud-Infrastruktur sind die Beträge ziemlich hoch. Es besteht zwar die Möglichkeit von "Pay-As-You-Go", aber um New Relic zu aktivieren, müssen Sie die Anwendung neu starten, was zum Verlust der Problemsituation führen kann, für die alles gestartet wurde. Vor nicht allzu langer Zeit hat New Relic einen neuen Tarifplan eingeführt -
Essentials , der auf den ersten Blick als vernünftige Alternative zu Professional erscheint. Bei näherer Betrachtung stellte sich jedoch heraus, dass einige wichtige Funktionen fehlen (insbesondere fehlen
wichtige Transaktionen ,
anwendungsübergreifende Rückverfolgung ,
verteilte Rückverfolgung ). .
Infolgedessen haben wir darüber nachgedacht, eine billigere Alternative zu finden, und unsere Wahl fiel auf die beiden Dienste Datadog und Atatus. Warum genau auf ihnen?
Über Wettbewerber
Ich muss sofort sagen, dass es andere Lösungen auf dem Markt gibt. Wir haben sogar Open Source-Optionen in Betracht gezogen, aber nicht jeder Client verfügt über freie Kapazität zum Hosten von selbst gehosteten Lösungen ... - Außerdem sind zusätzliche Wartungsarbeiten erforderlich. Das Paar, das wir ausgewählt haben, hat sich als am nächsten an
unseren Bedürfnissen erwiesen:
- integrierte und entwickelte Unterstützung für PHP-Anwendungen (der Stack unserer Kunden ist sehr vielfältig, aber er ist ein klarer Marktführer bei der Suche nach einer Alternative zu New Relic);
- erschwingliche Kosten (weniger als 100 USD pro Monat und Host);
- automatische Instrumentierung;
- Kubernetes-Integration
- Die Ähnlichkeit mit der New Relic-Oberfläche ist ein spürbares Plus (weil unsere Ingenieure daran gewöhnt sind).
Daher haben wir in der Phase der Erstauswahl einige andere beliebte Lösungen eliminiert, insbesondere:
- Tideways, AppDynamics und Dynatrace - für den Preis;
- Stapeln - ist in der Russischen Föderation blockiert und zeigt zu wenig Daten an.
Der nachfolgende Artikel ist so strukturiert, dass die betrachteten Lösungen kurz vorgestellt werden. Anschließend werde ich über unsere typische Interaktion mit New Relic und die Erfahrungen / Eindrücke bei der Durchführung ähnlicher Vorgänge in anderen Diensten sprechen.
Präsentation ausgewählter Wettbewerber

Wahrscheinlich hat jeder von
New Relic gehört ? Dieser Dienst begann seine Entwicklung vor mehr als 10 Jahren im Jahr 2008. Wir verwenden es seit 2012 aktiv und hatten keine Integrationsprobleme mit einer wirklich großen Anzahl von Anwendungen in PHP, Ruby und Python. Außerdem hatten wir Erfahrung mit der Integration in C # und Go. Die Autoren des Dienstes bieten Lösungen für die Überwachung von Anwendungen, Infrastrukturen, die Verfolgung von Mikroservice-Infrastrukturen, die Erstellung praktischer Anwendungen für Benutzergeräte und vieles mehr.
Der New Relic-Agent arbeitet jedoch mit proprietären Protokollen und bietet keine OpenTracing-Unterstützung. Für die erweiterte Instrumentierung sind Änderungen speziell für New Relic erforderlich. Schließlich hat die Unterstützung für Kubernetes bislang experimentellen Status.
 Datadog
Datadog , dessen Entwicklung im Jahr 2010 begann, sieht in Bezug auf seine Verwendung in Kubernetes-Umgebungen deutlich interessanter aus als New Relic. Insbesondere unterstützt es die Integration in die Protokolle NGINX Ingress, Log Collection, Statsd und OpenTracing, mit denen Sie eine Benutzeranforderung ab dem Zeitpunkt der Verbindung zum Ende der Arbeit verfolgen und Protokolle für diese Anforderung finden können (sowohl auf der Webserverseite als auch auf der Seite Verbraucher).
Bei der Verwendung von Datadog wurden wir mit der Tatsache konfrontiert, dass manchmal fälschlicherweise eine Microservice-Karte erstellt wurde, und mit einigen technischen Fehlern. Zum Beispiel hat er die Art des Dienstes falsch bestimmt (er hat Django für einen Caching-Dienst genommen) und die 500. Fehler in einer PHP-Anwendung unter Verwendung der beliebten Predis-Bibliothek verursacht.
 Atatus
Atatus ist das jüngste Instrument; Service im Jahr 2014 gestartet. Das Marketingbudget ist den aufgeführten Wettbewerbern deutlich unterlegen, Erwähnungen sind weitaus seltener. Trotzdem ist das Tool selbst New Relic sehr ähnlich und nicht nur in den Funktionen (APM, Browserüberwachung usw.), sondern auch im Erscheinungsbild.
Ein wesentlicher Nachteil ist nur die Unterstützung von Node.js und PHP. Andererseits ist es viel besser implementiert als Datadog. Im Gegensatz zu letzterem benötigt Atatus keine Anwendungen, um zusätzliche Tags im Code zu ändern oder festzulegen.
Wie wir mit New Relic arbeiten
Lassen Sie uns nun herausfinden, wie wir New Relic im Allgemeinen verwenden. Angenommen, wir haben ein Problem, das gelöst werden muss:
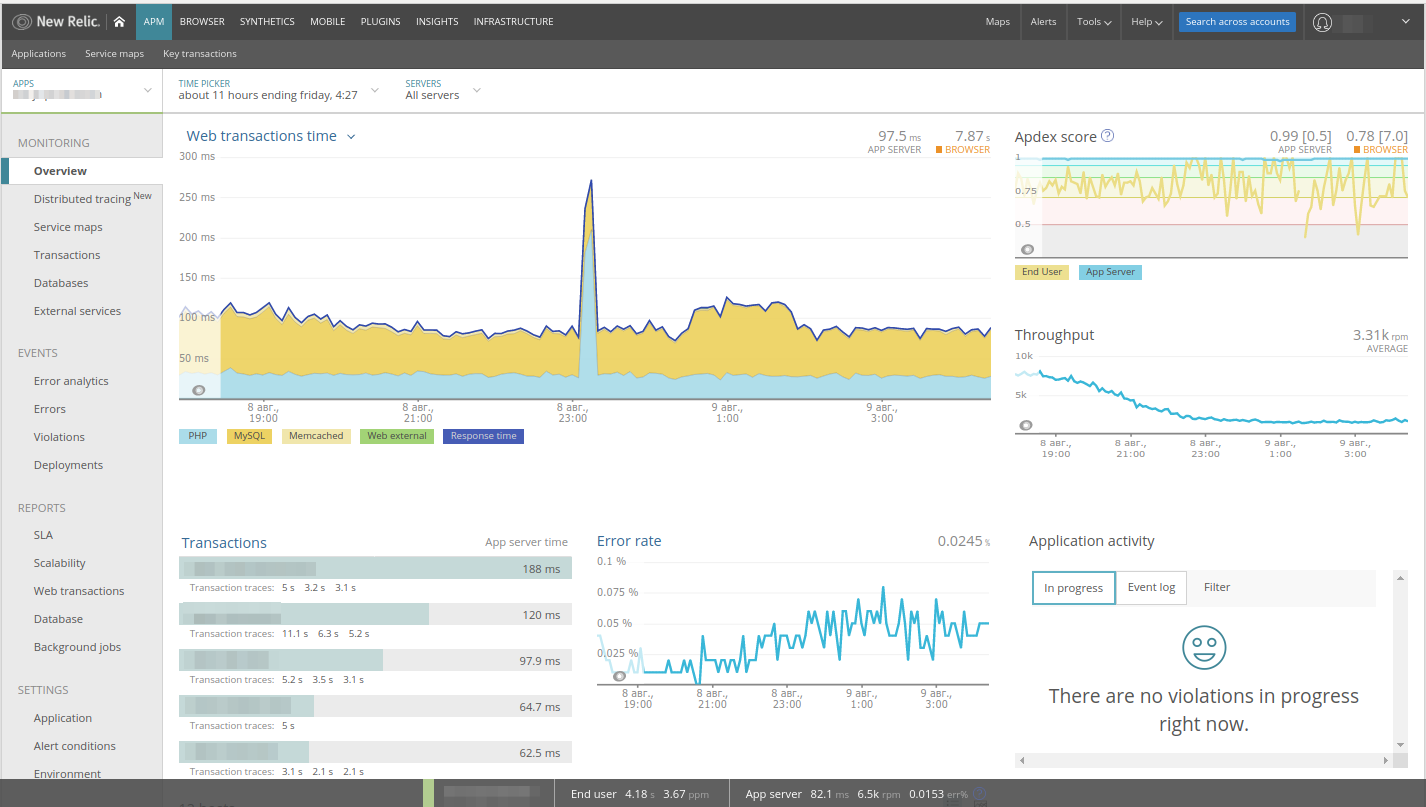
Es ist leicht, einen
Anstieg auf dem Diagramm zu bemerken - wir analysieren ihn. In New Relic werden Webtransaktionen sofort für die Webanwendung ausgewählt, alle Komponenten werden im Leistungsdiagramm angezeigt, es gibt Fehlerraten- und Anforderungsraten-Panels ... Am wichtigsten ist, dass Sie direkt von diesen Panels aus zwischen verschiedenen Teilen der Anwendung wechseln können (z. B. durch Klicken auf MySQL wird zum Datenbankabschnitt).
Da in diesem Beispiel ein Anstieg der
PHP- Aktivität zu beobachten ist, klicken Sie auf dieses Diagramm und gehen Sie automatisch zu
Transaktionen :
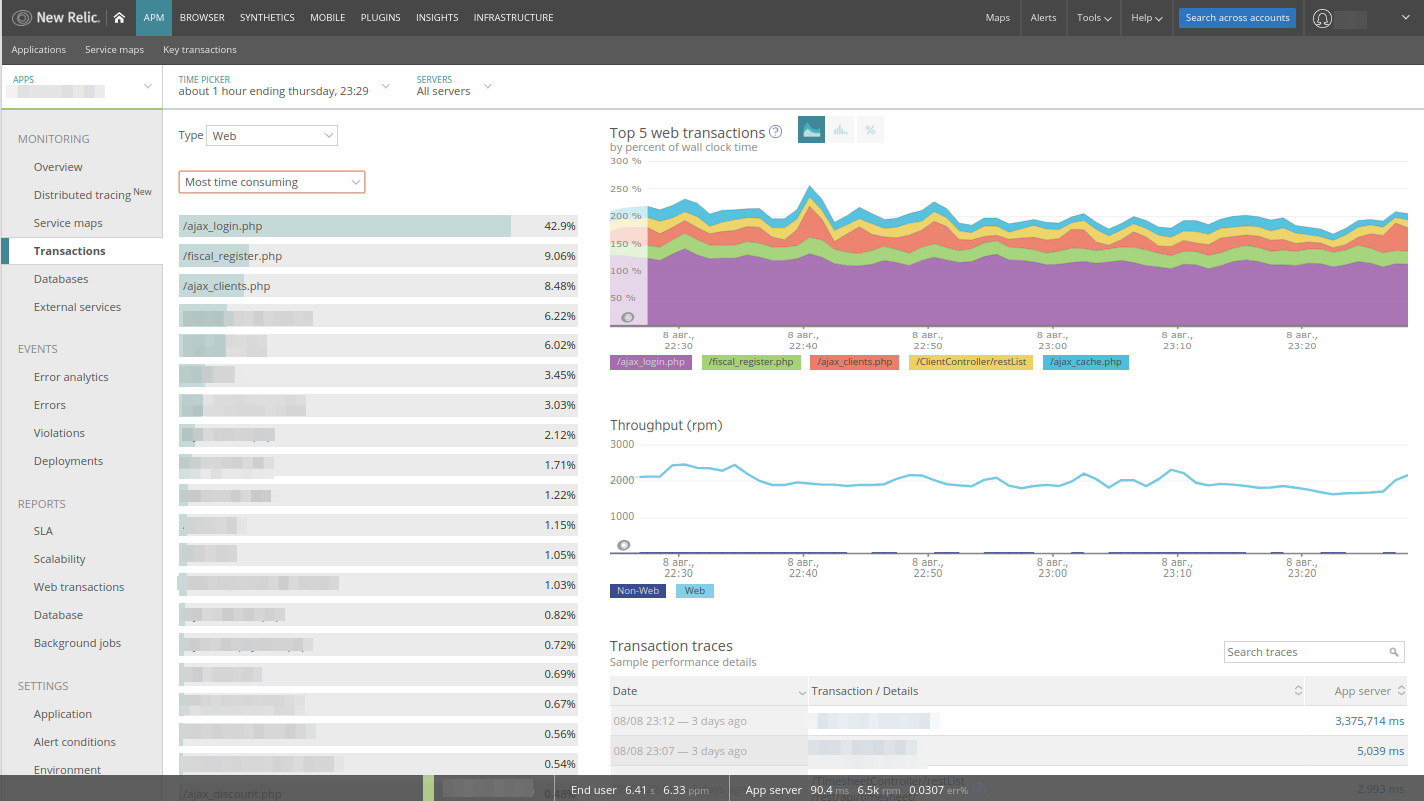
Die Liste der Transaktionen, bei denen es sich im Wesentlichen um Controller aus dem MVC-Modell handelt, ist bereits nach
Zeitaufwendig sortiert, was sehr praktisch ist: Wir sehen sofort, was die Anwendung tut. Hier finden Sie Beispiele für lange Abfragen, die von New Relic automatisch erfasst werden. Das Wechseln der Sortierung ist leicht zu finden:
- der am meisten geladene Anwendungscontroller;
- Der am häufigsten angeforderte Controller
- der langsamste der Controller.
Darüber hinaus können Sie jede Transaktion erweitern und sehen, was die Anwendung zum Zeitpunkt der Codeausführung tat:
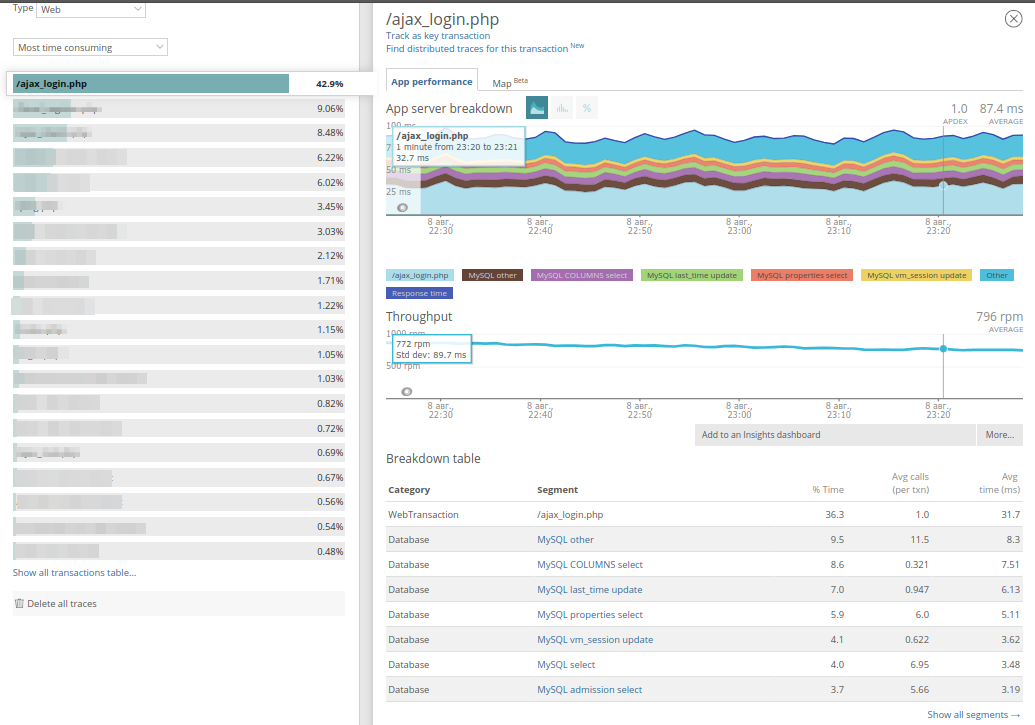
Schließlich werden Beispiele für lange Abfragespuren (die länger als 2 Sekunden funktionieren) in der Anwendung gespeichert. Hier ist das Panel für eine lange Transaktion:

Es ist ersichtlich, dass zwei Methoden viel Zeit in Anspruch nehmen, und mit der Zeit, zu der die Anforderung ausgeführt wurde, werden auch deren URI und Domäne angezeigt. Sehr oft hilft dies, die Abfrage in den Protokollen zu finden. In den
Trace-Details können Sie sehen, woher diese Methoden stammen:
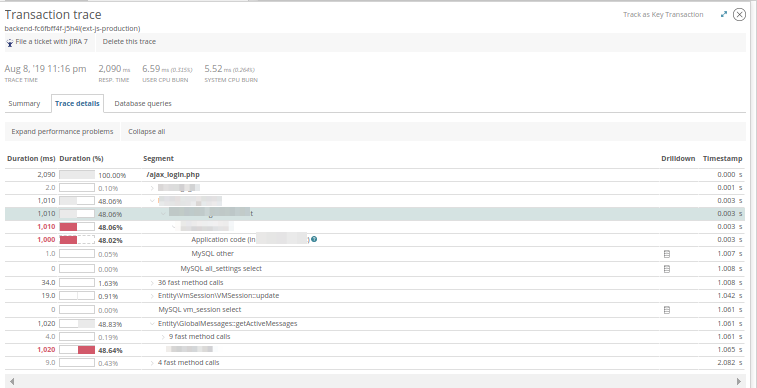
Und in
Datenbankabfragen - bewerten Sie die Datenbankabfragen, die zum Zeitpunkt der Anwendung ausgeführt wurden:

Mit diesem Wissen können wir die Ursache für die Verlangsamung der Anwendung beurteilen und gemeinsam mit dem Entwickler eine Strategie zur Lösung des Problems entwickeln. In Wirklichkeit liefert New Relic nicht immer ein klares Bild, aber es hilft bei der Auswahl des Untersuchungsvektors:
- das lange
PDO::Construct führte uns zu der seltsamen Funktionsweise von pgpoll; - Instabilität in der Zeit
Memcache::Get falsche Konfiguration der virtuellen Maschine erhalten; - Die verdächtig längere Zeit für die Verarbeitung der Vorlage führte zu einer verschachtelten Schleife mit einer Überprüfung auf das Vorhandensein von 500 Avataren im Objektspeicher.
- usw…
Es kommt auch vor, dass anstelle der Ausführung von Code auf dem Hauptbildschirm etwas im Zusammenhang mit der externen Datenspeicherung wächst - und es spielt keine Rolle, was es sein wird: Redis oder PostgreSQL - alle sind auf der Registerkarte "
Datenbanken" ausgeblendet.

Sie können eine bestimmte Basis für die Recherche auswählen und die Abfragen sortieren - ähnlich wie in Transaktionen. Auf der Registerkarte "Anfrage" können Sie sehen, wie viel diese Anfrage in den einzelnen Anwendungscontrollern enthalten ist, und bewerten, wie oft sie aufgerufen wird. Es ist sehr bequem:
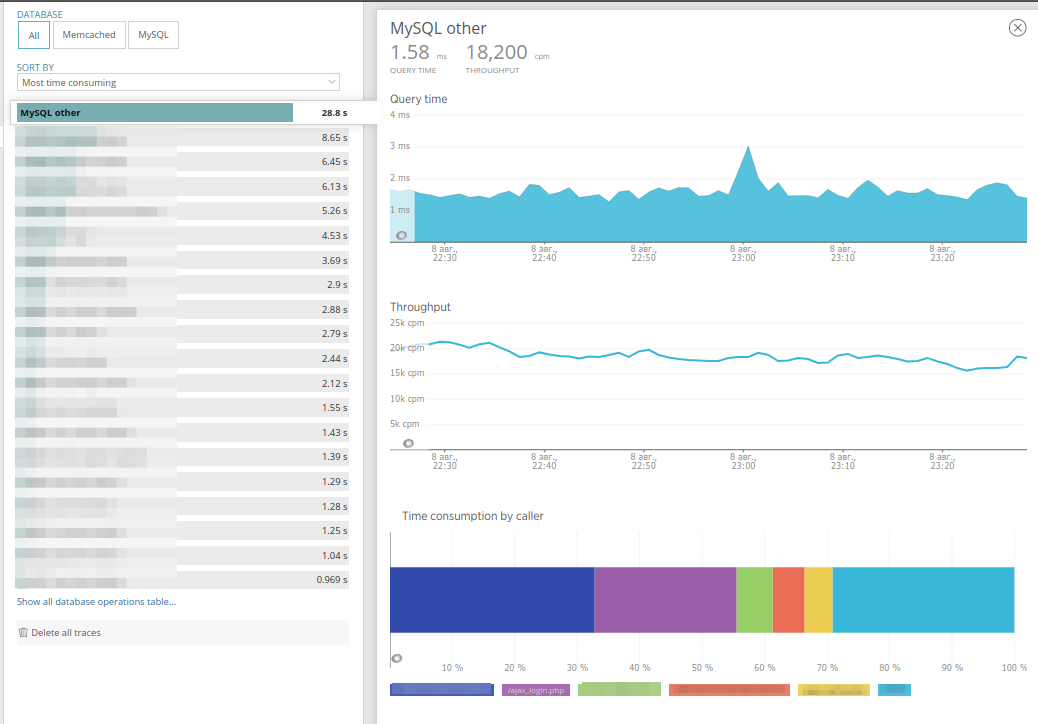
Die Registerkarte
Externe Dienste enthält ähnliche Daten, die Anforderungen für externe HTTP-Dienste verbergen, z. B. den Zugriff auf den Objektspeicher, das Senden von Ereignissen an den Wachposten oder dergleichen. Die Registerkarte ähnelt inhaltlich den Datenbanken:

Wettbewerber: Chancen und Eindrücke
Das Interessanteste ist nun, die Funktionen von New Relic mit denen der Wettbewerber zu vergleichen. Leider konnten wir nicht alle drei Tools mit derselben Version einer Anwendung testen, die in der Produktion ausgeführt wird. Trotzdem haben wir versucht, die identischsten Situationen / Konfigurationen zu vergleichen.
1. Datadog
Datadog begrüßt uns mit einem Panel mit einer Reihe von Diensten:
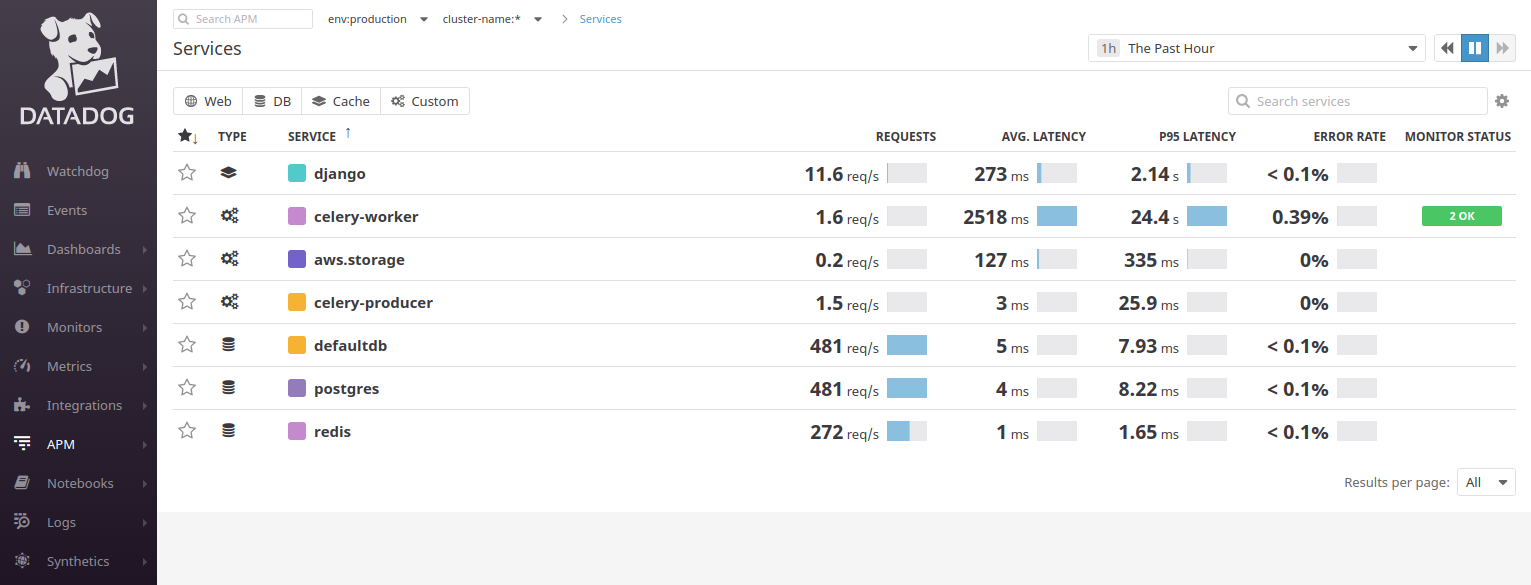
Er versucht, Anwendungen in Komponenten / Microservices zu unterteilen. In der Beispielanwendung Django sehen wir zwei Verbindungen zu PostgreSQL (
defaultdb und
postgres ) sowie zu Celery, Redis. Für die Arbeit mit Datadog müssen Sie über ein Mindestwissen über die Prinzipien von MVC verfügen: Sie müssen verstehen, woher Benutzeranforderungen kommen. Normalerweise hilft dabei
eine Service Map :

Übrigens gibt es in New Relic etwas Ähnliches:
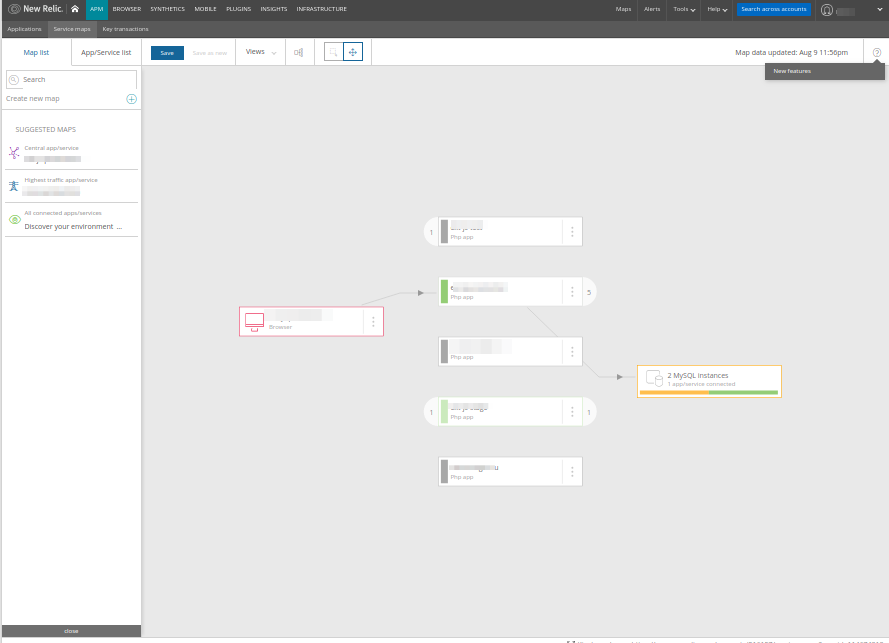
... und ihre Karte wird meiner Meinung nach einfacher und verständlicher: Sie zeigt nicht die Komponenten einer Anwendung an (was sie unnötig detailliert machen würde, wie im Fall von Datadog), sondern nur bestimmte Dienste oder Mikrodienste.
Zurück zu Datadog: Aus der Service Map geht hervor, dass Benutzeranforderungen an Django gehen. Gehen wir zum Django-Service und sehen endlich, was wir erwartet haben:
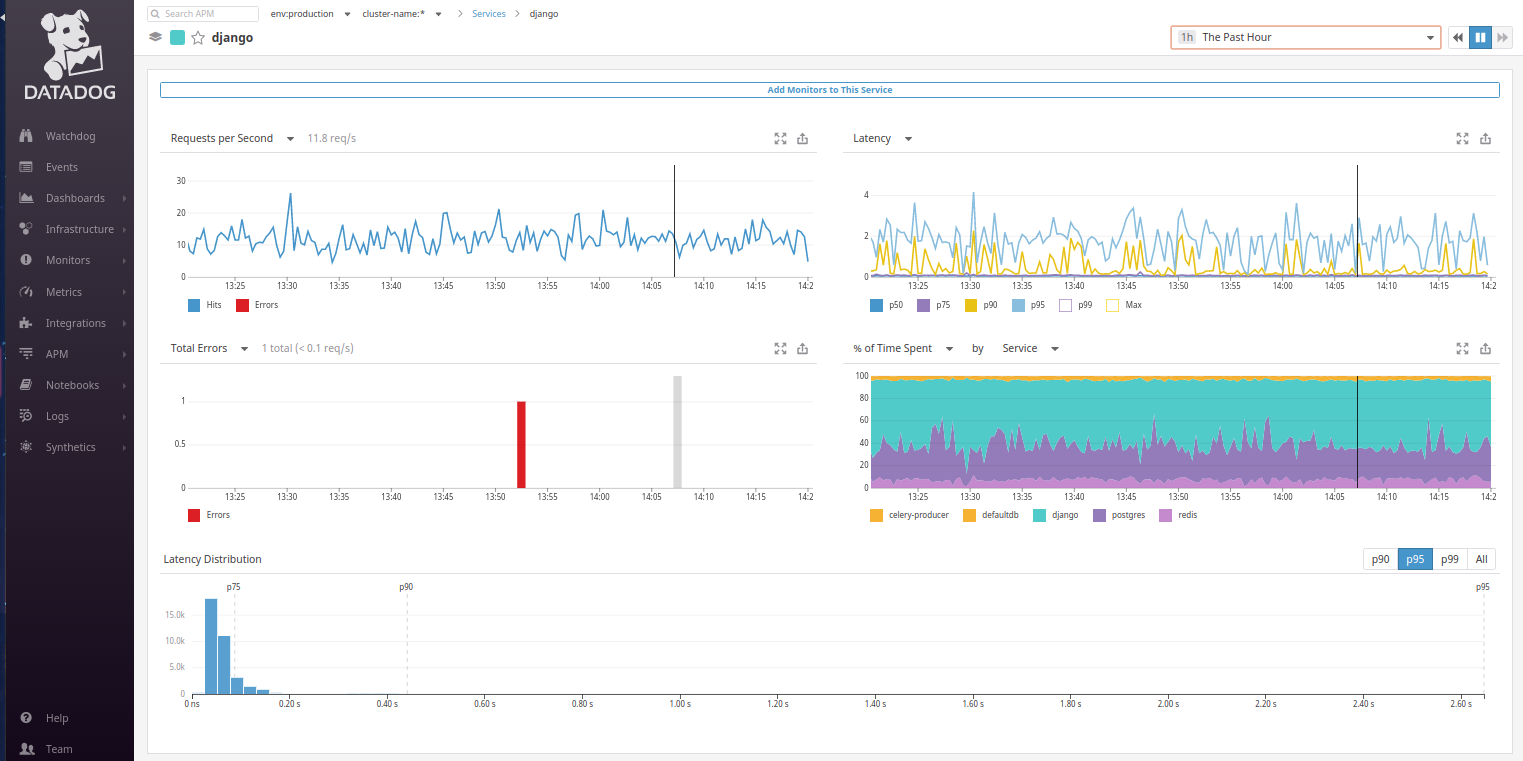
Leider gibt es standardmäßig kein
Web-Transaktions- Zeitdiagramm, das dem im New Relic-Hauptfenster ähnelt. Es kann jedoch anstelle des Diagramms
% der aufgewendeten Zeit konfiguriert werden. Es reicht aus, die
durchschnittliche Zeit pro Anfrage nach Typ zu
ändern ... und jetzt sieht uns das vertraute Diagramm an!
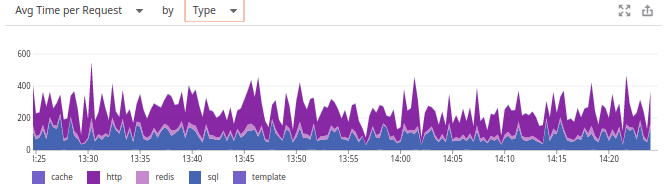
Warum sich Datadog für einen anderen Zeitplan entschieden hat, ist uns ein Rätsel. Es war auch frustrierend, dass sich das System (im Gegensatz zu beiden Mitbewerbern) nicht an die Wahl des Benutzers erinnert und daher nur die Erstellung von benutzerdefinierten Panels spart.
Ich war jedoch erfreut über die Möglichkeit in Datadog, von diesen Diagrammen zu den Metriken verwandter Server zu wechseln, die Protokolle zu lesen und die Auslastung der Webserver-Handler (Gunicorn) zu bewerten. Alles ist fast das gleiche wie in New Relic ... und sogar ein paar mehr (Protokolle)!
Unter den Diagrammen befinden sich Transaktionen, die New Relic völlig ähnlich sind:
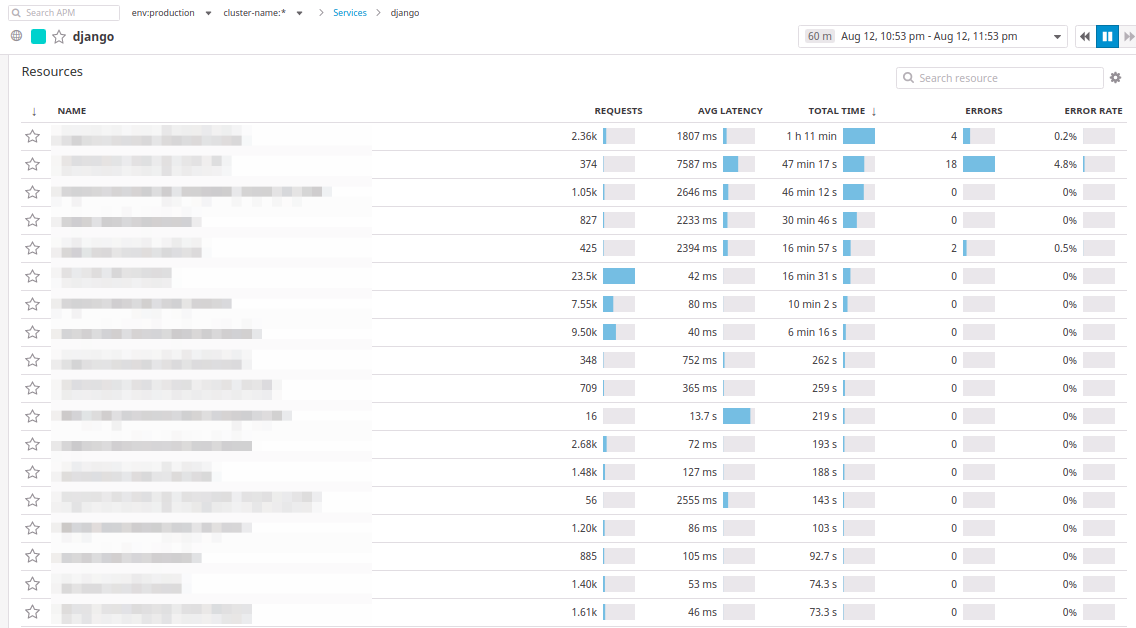
In Datadog werden Transaktionen als
Ressourcen bezeichnet . Sie können die Controller nach der Anzahl der Anforderungen, nach der durchschnittlichen Antwortzeit und nach der maximal verstrichenen Zeit für einen ausgewählten Zeitraum sortieren.
Sie können die Ressource erweitern und alles sehen, was wir bereits in New Relic beobachtet haben:
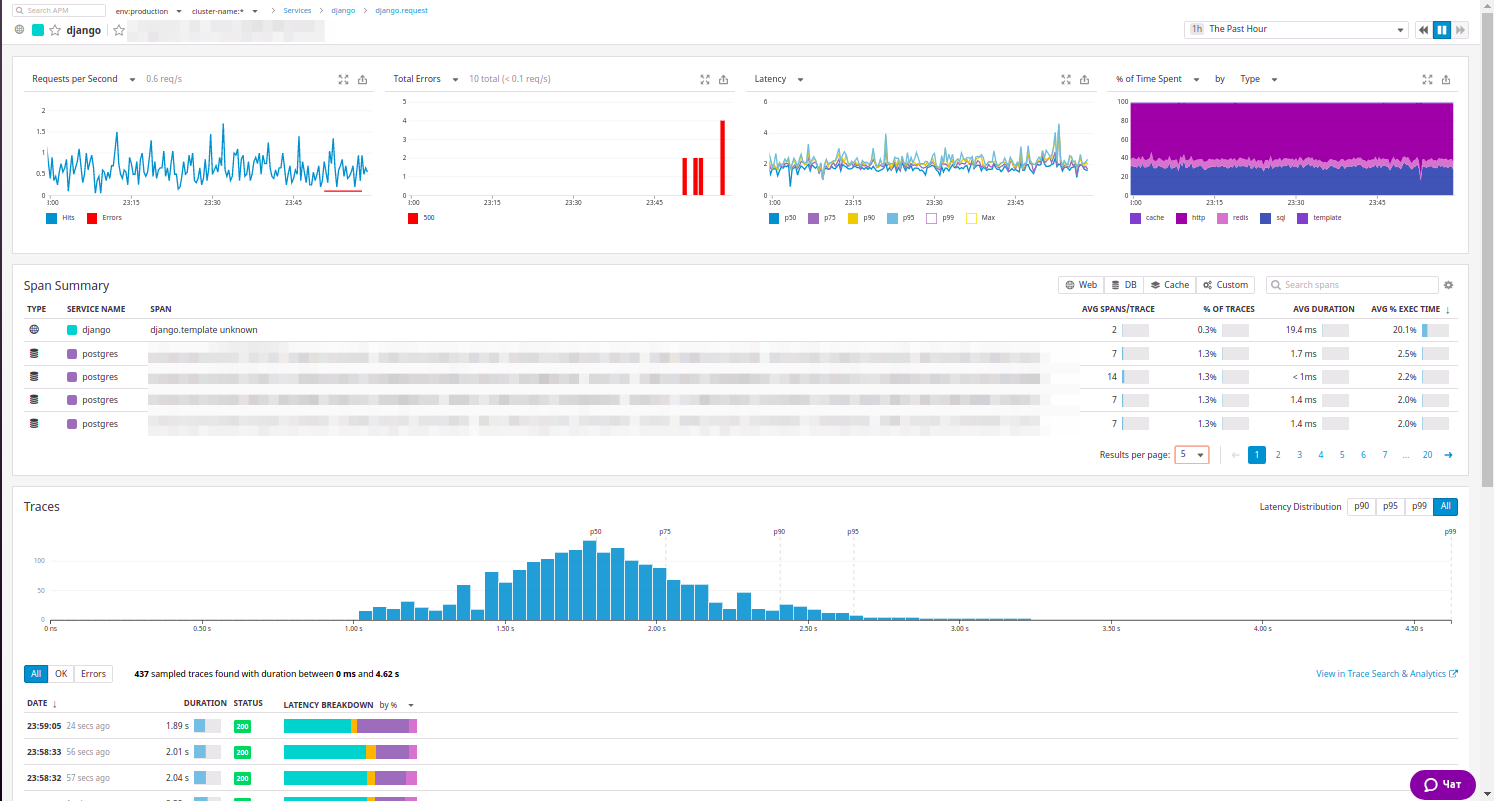
Es gibt Statistiken über die Ressource, eine allgemeine Liste interner Anrufe und Beispiele für Anforderungen, die nach dem Antwortcode sortiert werden können ... Übrigens, unsere Ingenieure haben diese Sortierung wirklich gemocht.
Jede Beispielressource in Datadog kann erweitert und untersucht werden:

Die Abfrageparameter, ein zusammenfassendes Diagramm der verstrichenen Zeit für jede der Komponenten und ein Wasserfalldiagramm, in dem die Reihenfolge der Aufrufe angezeigt wird, werden angezeigt. Sie können auch zur Baumansicht des Wasserfalldiagramms wechseln:

Am interessantesten ist es, die Last des Hosts anzuzeigen, auf dem die Anforderung ausgeführt wurde, und die Anforderungsprotokolle anzuzeigen.
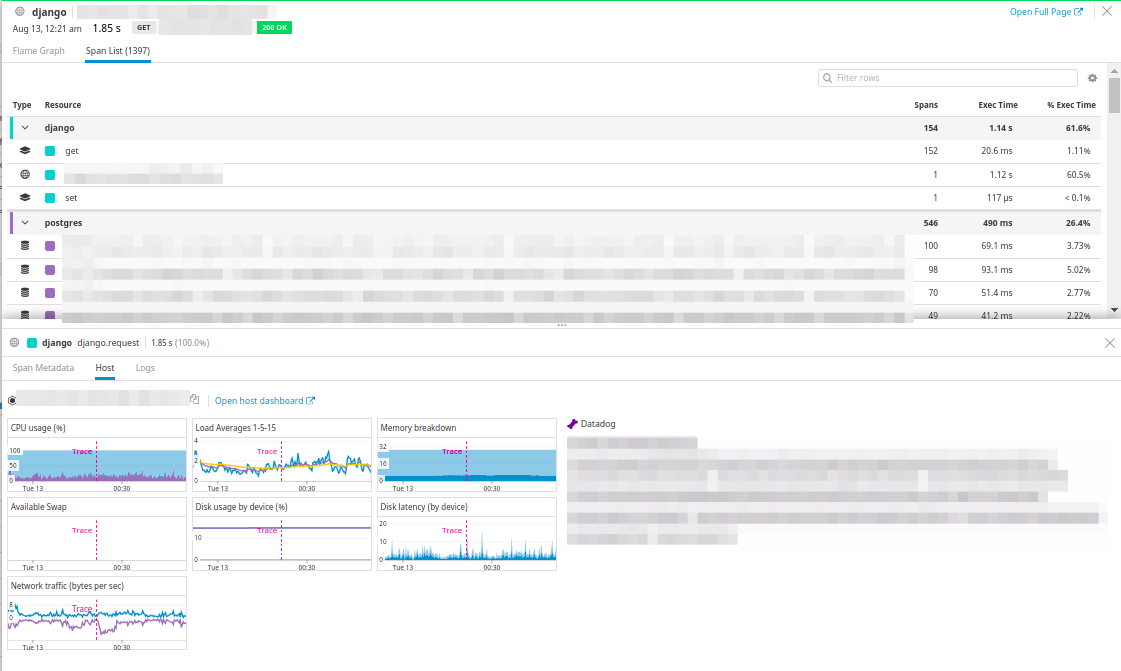
Tolle Integration!
Möglicherweise fragen Sie sich, wo sich die Registerkarten
Datenbanken und
externe Dienste befinden, wie in New Relic. Sie sind nicht hier: Da Datadog die Anwendung in Komponenten analysiert, wird PostgreSQL als
separater Dienst betrachtet , und anstelle von externen Diensten lohnt es sich, nach
aws.storage zu suchen (dies gilt auch für alle anderen externen Dienste, auf die die Anwendung zugreifen kann).

Und hier ist ein Beispiel mit
postgres :
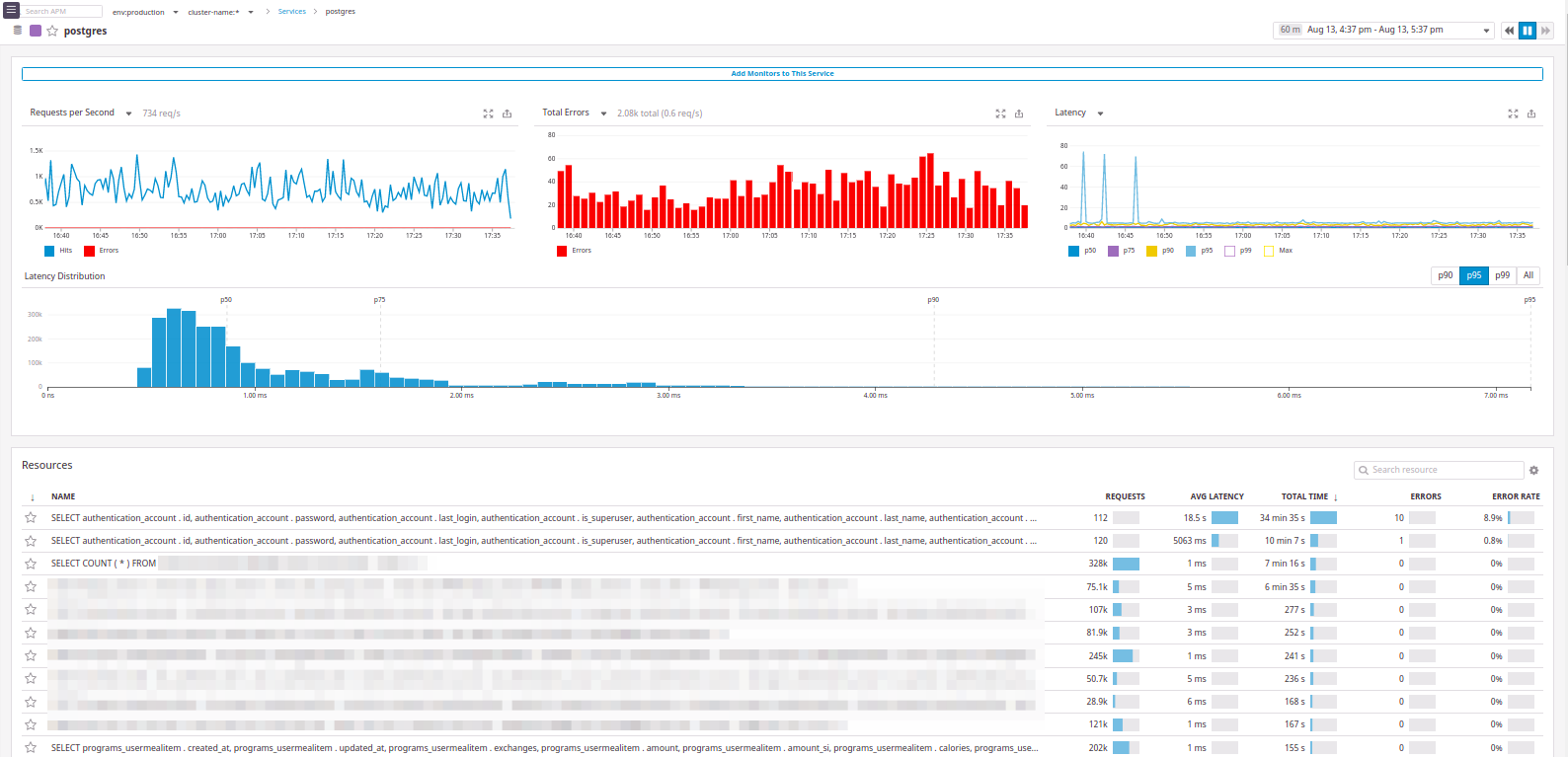
In der Tat gibt es alles, was wir wollten:
Es ist ersichtlich, von welchem "Service" die Anfrage kam.
Es ist nicht überflüssig, sich daran zu erinnern, dass Datadog perfekt in NGINX Ingress integriert ist und eine End-to-End-Ablaufverfolgung ab dem Moment ermöglicht, in dem eine Anforderung im Cluster eintrifft. Außerdem können Sie Statistikmetriken akzeptieren, Protokolle sammeln und Metriken hosten.
Ein großes Plus von Datadog ist, dass sein Preis
aus der Überwachung der Infrastruktur, APM, Protokollverwaltung und Synthetik-Test besteht, d. H. Sie können flexibel einen Plan auswählen.
2. Atatus
Das Atatus-Team behauptet, dass ihr Service "der gleiche wie bei New Relic ist, aber besser". Mal sehen, ob das wirklich so ist.
Die Titelleiste sieht wirklich gleich aus, aber es war nicht möglich, die in der Anwendung verwendeten Redis und Memcached zu bestimmen.
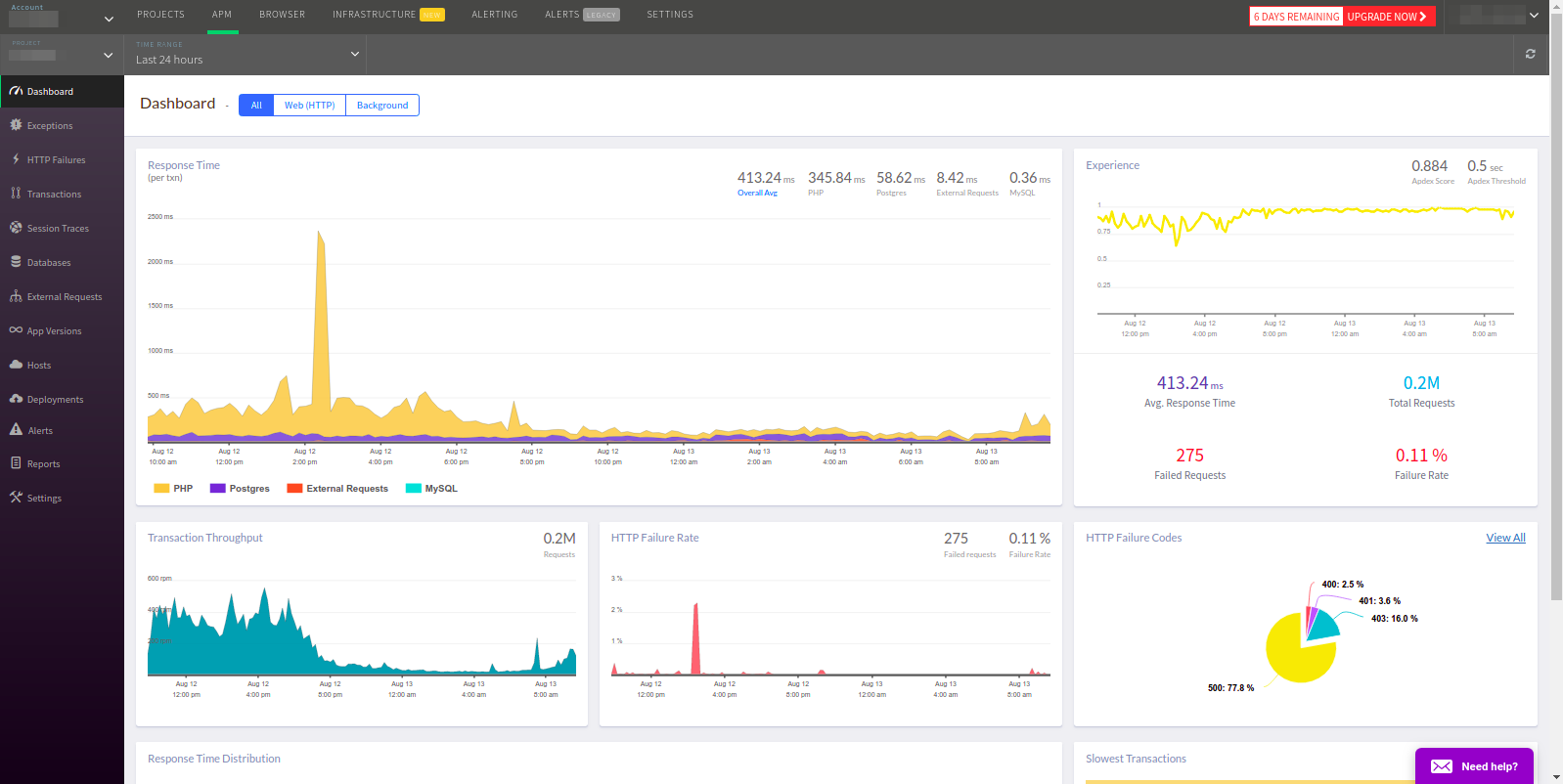
APM wählt standardmäßig alle Transaktionen aus, obwohl normalerweise nur das Web benötigt wird. Wie in Datadog gibt es keine Möglichkeit, über das Hauptfenster zum gewünschten Dienst zu gelangen. Darüber hinaus werden Transaktionen nach Fehlern aufgelistet, was für APM nicht sehr logisch aussieht.
Bei Atatus-Transaktionen ist alles New Relic so ähnlich wie möglich. Minus - Sie können die Dynamik für jeden Controller nicht sofort sehen. Sie müssen in der Controller-Tabelle danach suchen und nach der am
meisten verbrauchten Zeit sortieren:

Die übliche Liste der Controller finden
Sie auf der Registerkarte Durchsuchen:
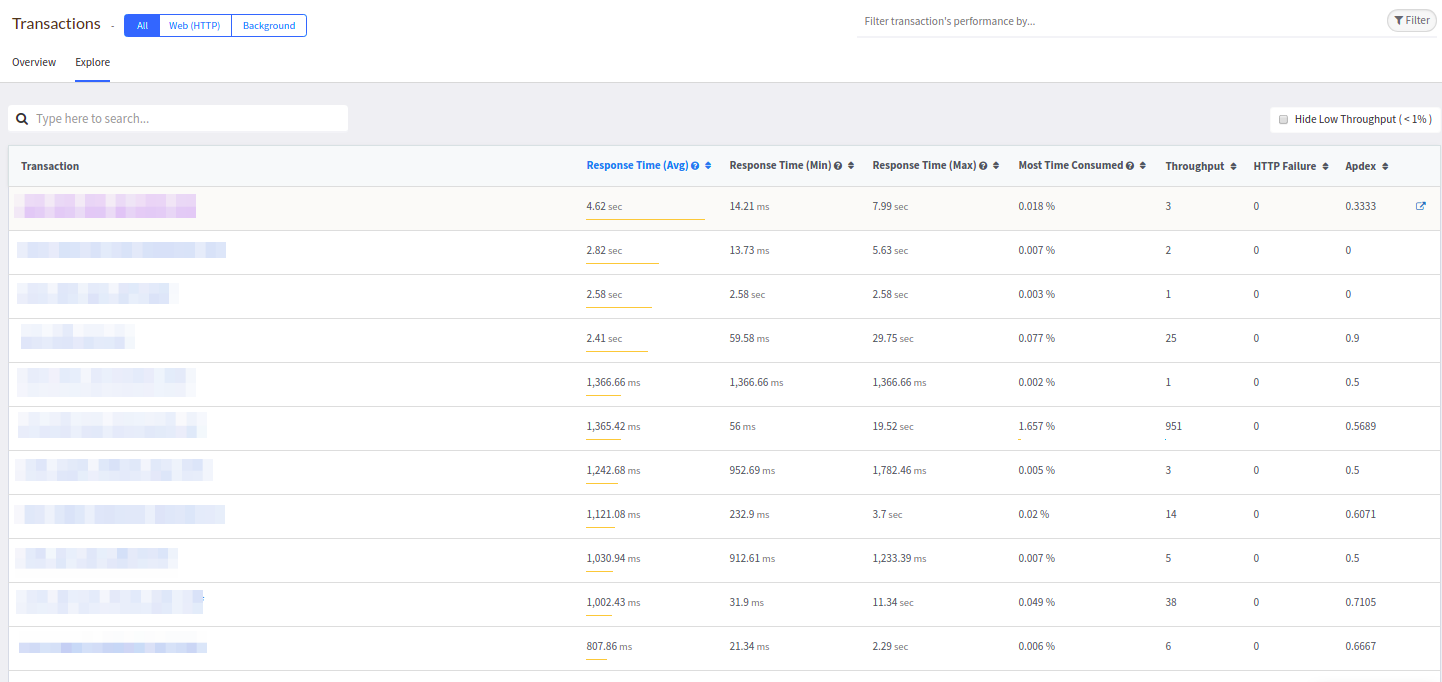
In gewisser Weise ähnelt diese Tabelle Datadog und ähnelt eher der in New Relic.
Jede Transaktion kann bereitgestellt werden und sehen, was die Anwendung getan hat:

Das Panel ähnelt auch eher Datadog: Es gibt eine Reihe von Anfragen, ein Gesamtbild der Anrufe. Der obere Bereich enthält eine Registerkarte mit
HTTP-Fehlerfehlern und Beispielen für langsame
Sitzungsablaufverfolgungsanforderungen :

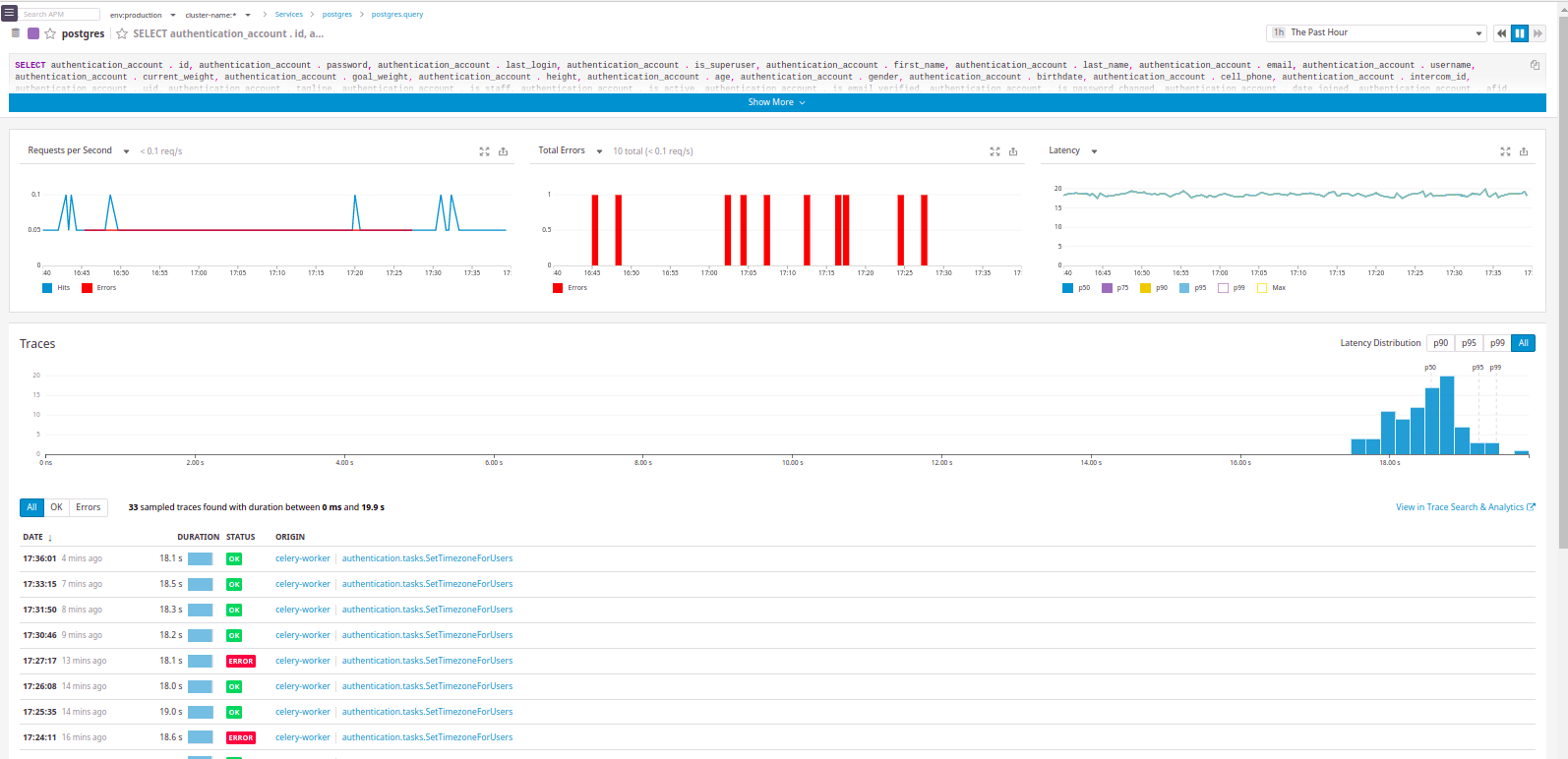
Wenn Sie eine Transaktion durchführen, sehen Sie ein Beispiel für eine Ablaufverfolgung. Sie können eine Liste der Abfragen an die Datenbank abrufen und die Anforderungsheader anzeigen. Alles ist ähnlich wie bei New Relic:

Im Allgemeinen war Atatus mit detaillierten Spuren zufrieden - ohne das typische New Relic-Einkleben von Anrufen in einen Erinnerungsblock:
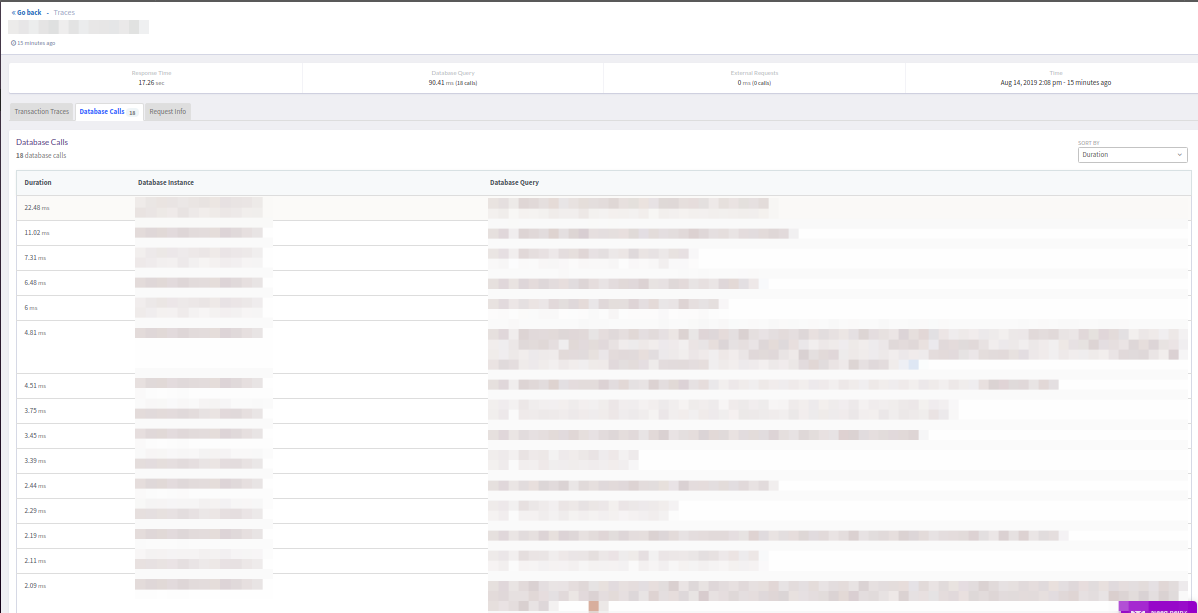
Es gibt jedoch nicht genügend Filter, die (wie in New Relic) ultraschnelle Anforderungen (<5 ms) abschneiden würden. Andererseits war es angenehm, die endgültige Transaktionsantwort (erfolgreich oder fehlerhaft) anzuzeigen.
Im Bereich "
Datenbanken" können Sie die Anforderungen der Anwendung an externe Datenbanken untersuchen. Ich möchte Sie daran erinnern, dass Atatus nur PostgreSQL und MySQL gefunden hat, obwohl Redis und memcached ebenfalls an dem Projekt beteiligt sind.
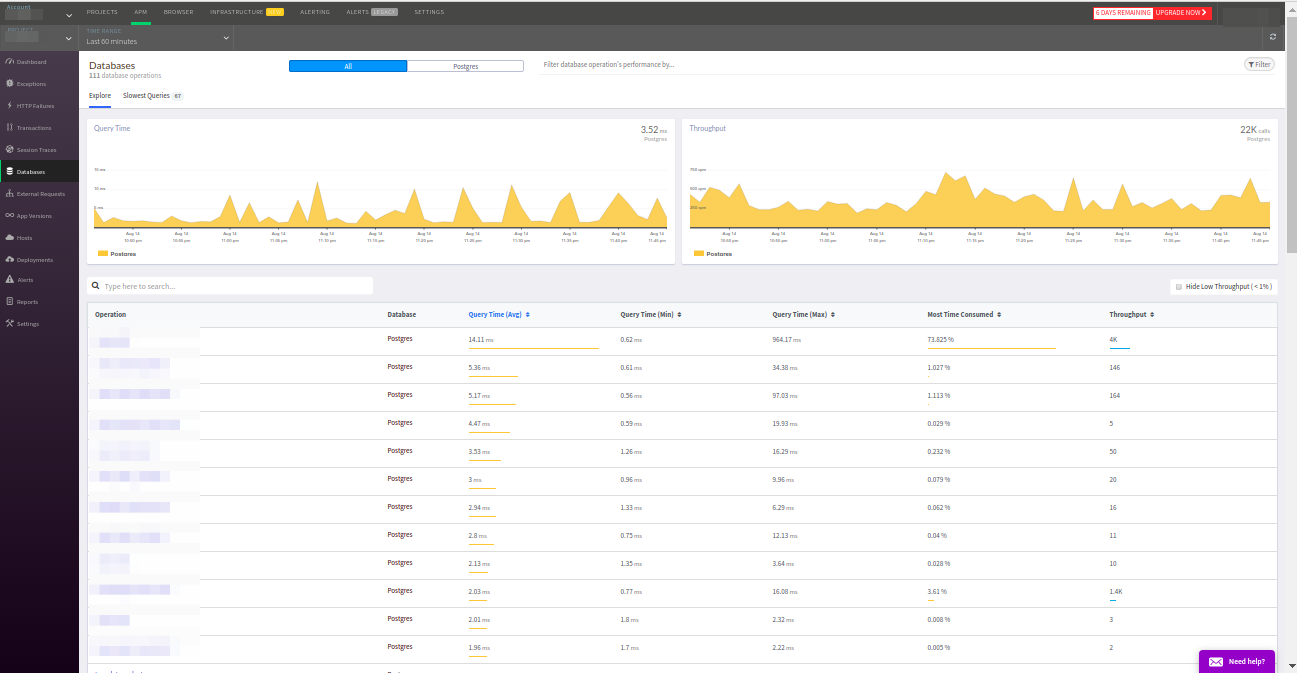
Anfragen werden nach den üblichen Kriterien sortiert: Antworthäufigkeit, durchschnittliche Antwortzeit usw. Ich möchte auch die Registerkarte mit den langsamsten Abfragen beachten - dies ist sehr praktisch. Darüber hinaus stimmten die Daten auf dieser Registerkarte für PostgreSQL mit den Daten aus der Erweiterung
pg_stat_statements überein - ein hervorragendes Ergebnis!
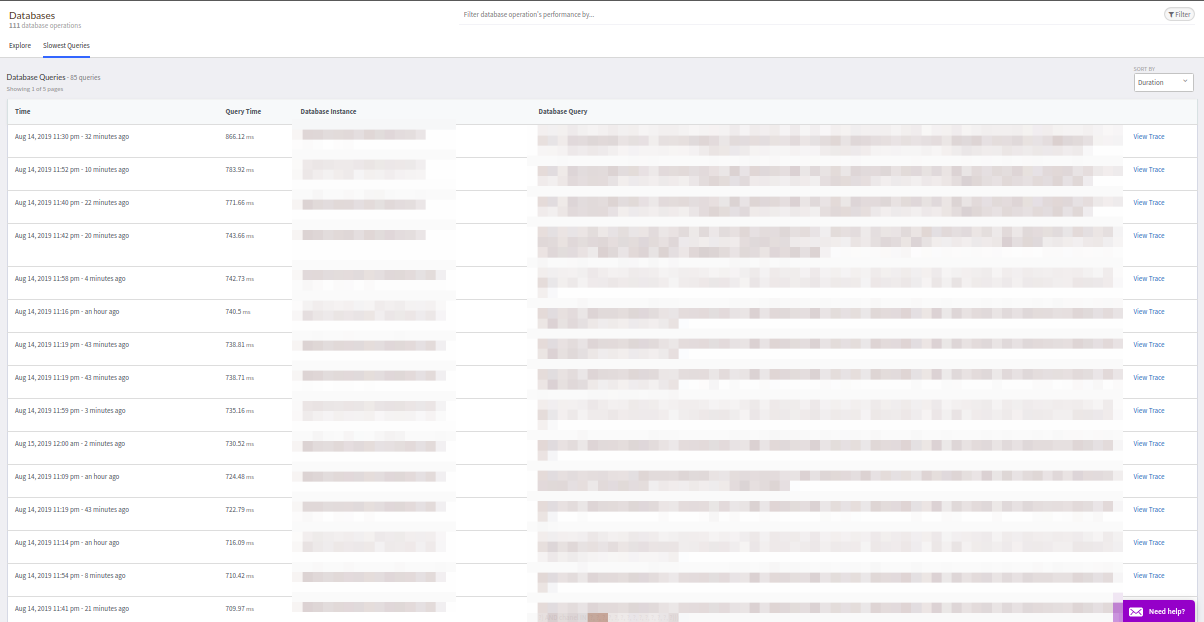
Die Registerkarte
Externe Anforderungen ist identisch mit Datenbanken.
Schlussfolgerungen
Beide vorgestellten Tools zeigten in der Rolle von APM eine gute Leistung. Jeder von ihnen kann das notwendige Minimum bieten. Fassen Sie unsere Eindrücke kurz wie folgt zusammen:
Datadog
Vorteile:
- bequemer Tarifplan (APM kostet 31 USD pro Host);
- gut mit Python durchgeführt;
- Integrationsfähigkeit in OpenTracing
- Kubernetes-Integration
- Integration mit NGINX Ingress.
Nachteile:
- Der einzige APM, der aufgrund eines Modulfehlers (predis) zu einer Unzugänglichkeit der Anwendung geführt hat.
- schwache PHP-Auto-Tools;
- teilweise seltsame Definition von Dienstleistungen und deren Zweck.
Atatus
Vorteile:
- tiefe Instrumentierung von PHP;
- Neue Relic-ähnliche Benutzeroberfläche.
Nachteile:
- funktioniert nicht unter älteren Betriebssystemen (Ubuntu 12.05, CentOS 5);
- schwache Autowerkzeuge;
- Unterstützung für nur zwei Sprachen (Node.js und PHP);
- langsamer Betrieb der Schnittstelle.
Angesichts des Atatus-Preises von 69 USD pro Monat und Server würden wir lieber Datadog verwenden, das sich perfekt in unsere Anforderungen einfügt (Webanwendungen in K8s) und viele nützliche Funktionen bietet.
PS
Lesen Sie auch in unserem Blog: