
In diesem Artikel möchte ich eine Alternative zum traditionellen Testdesignstil mit funktionalen Programmierkonzepten in Scala vorschlagen. Dieser Ansatz wurde durch viele Monate voller Schmerzen inspiriert, die durch die Aufrechterhaltung von Dutzenden fehlgeschlagener Tests und den brennenden Wunsch entstanden waren, sie einfacher und verständlicher zu machen.
Obwohl sich der Code in Scala befindet, sind die vorgeschlagenen Ideen für Entwickler und QS-Ingenieure geeignet, die Sprachen verwenden, die die funktionale Programmierung unterstützen. Einen Github-Link mit der vollständigen Lösung und ein Beispiel finden Sie am Ende des Artikels.
Das Problem
Wenn Sie sich jemals mit Tests befassen mussten (egal welche: Unit-Tests, integrativ oder funktional), wurden sie höchstwahrscheinlich als sequentielle Anweisungen geschrieben. Zum Beispiel:
Nach meiner Erfahrung wird diese Art des Schreibens von Tests von den meisten Entwicklern bevorzugt. Unser Projekt hat ungefähr tausend Tests auf verschiedenen Isolationsstufen, und alle wurden bis vor kurzem in diesem Stil geschrieben. Als das Projekt wuchs, bemerkten wir schwerwiegende Probleme und Verlangsamungen bei der Aufrechterhaltung solcher Tests: Die Behebung dieser Tests würde mindestens genauso lange dauern wie das Schreiben von Produktionscode.
Beim Schreiben neuer Tests mussten wir immer Wege finden, um Daten von Grund auf neu vorzubereiten, normalerweise durch Kopieren und Einfügen von Schritten aus benachbarten Tests. Wenn sich das Datenmodell der Anwendung ändern würde, würde das Kartenhaus zusammenbrechen, und wir müssten jeden fehlgeschlagenen Test reparieren: im schlimmsten Fall - indem wir tief in jeden Test eintauchen und ihn neu schreiben.
Wenn ein Test „ehrlich“ fehlschlagen würde - d. H. Aufgrund eines tatsächlichen Fehlers in der Geschäftslogik - war es unmöglich zu verstehen, was ohne Debugging schief gelaufen ist. Da die Tests so schwer zu verstehen waren, hatte niemand immer das volle Wissen zur Hand, wie sich das System verhalten soll.
All dieser Schmerz ist meiner Meinung nach ein Symptom für die zwei tieferen Probleme eines solchen Testdesigns:
- Es gibt keine klare und praktische Struktur für Tests. Jeder Test ist eine einzigartige Schneeflocke. Mangelnde Struktur führt zu Ausführlichkeit, die viel Zeit in Anspruch nimmt und demotiviert. Unbedeutende Details lenken von dem ab, was am wichtigsten ist - der Anforderung, die der Test bestätigt. Das Kopieren und Einfügen wird zum primären Ansatz beim Schreiben neuer Testfälle.
- Tests helfen Entwicklern nicht bei der Lokalisierung von Fehlern. Sie signalisieren nur, dass es ein Problem gibt. Um zu verstehen, in welchem Zustand der Test ausgeführt wird, müssen Sie ihn in Ihrem Kopf darstellen oder einen Debugger verwenden.
Modellierung
Können wir es besser machen? (Spoiler-Alarm: Wir können.) Lassen Sie uns überlegen, welche Art von Struktur dieser Test haben kann.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Als Faustregel erwartet der zu testende Code einige explizite Parameter (Bezeichner, Größen, Mengen, Filter, um nur einige zu nennen) sowie einige externe Daten (aus einer Datenbank, einer Warteschlange oder einem anderen realen Dienst). Damit unser Test zuverlässig ausgeführt werden kann, ist ein Gerät erforderlich - ein Status, in den das System, die Datenanbieter oder beides versetzt werden.
Mit diesem Gerät bereiten wir eine Abhängigkeit vor , um den zu testenden Code zu initialisieren - füllen Sie eine Datenbank, erstellen Sie eine Warteschlange eines bestimmten Typs usw.
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
Nachdem wir den zu testenden Code für einige Eingabeparameter ausgeführt haben, erhalten wir eine Ausgabe - sowohl explizit (vom zu testenden Code zurückgegeben) als auch implizit (die Änderungen des Status).
result shouldBe 90
Schließlich überprüfen wir, ob die Ausgabe wie erwartet ist, und beenden den Test mit einer oder mehreren Aussagen .
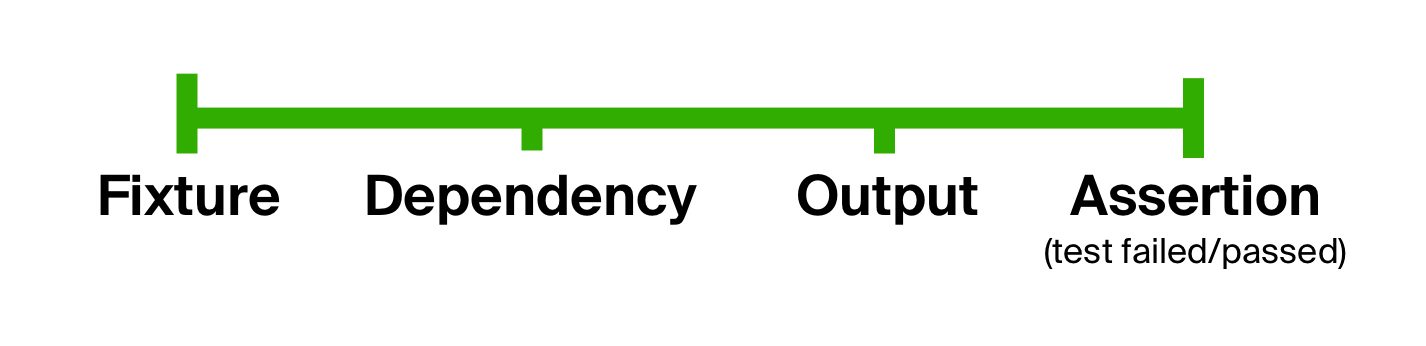
Man kann daraus schließen, dass Tests im Allgemeinen aus denselben Phasen bestehen: Eingabevorbereitung, Codeausführung und Ergebnisbestätigung. Wir können diese Tatsache nutzen, um das erste Problem unserer Tests , d. H. Eine übermäßig liberale Form, zu beseitigen , indem wir den Körper eines Tests explizit in Stufen aufteilen. Eine solche Idee ist nicht neu, wie aus BDD-Tests ( verhaltensgesteuerte Entwicklung ) hervorgeht.
Was ist mit Erweiterbarkeit? Jeder Schritt des Testprozesses kann wiederum eine beliebige Menge von Zwischenschritten enthalten. Zum Beispiel könnten wir einen großen und komplizierten Schritt machen, wie das Bauen eines Scheinwerfers, und es in mehrere Teile teilen, die nacheinander verkettet sind. Auf diese Weise kann der Testprozess unendlich erweiterbar sein, besteht aber letztendlich immer aus denselben wenigen allgemeinen Schritten.

Ausführen von Tests
Versuchen wir, die Idee der Aufteilung des Tests in Stufen umzusetzen, aber zuerst sollten wir bestimmen, welche Art von Ergebnis wir sehen möchten.
Insgesamt möchten wir, dass das Schreiben und Verwalten von Tests weniger arbeitsintensiv und angenehmer wird. Je weniger explizite, nicht eindeutige Anweisungen ein Test enthält, desto weniger Änderungen müssten nach Vertragsänderung oder Umgestaltung vorgenommen werden und desto weniger Zeit würde das Lesen des Tests dauern. Das Design des Tests sollte die Wiederverwendung gängiger Codefragmente fördern und das sinnlose Kopieren und Einfügen verhindern. Es wäre auch schön, wenn die Tests eine einheitliche Form hätten. Die Vorhersagbarkeit verbessert die Lesbarkeit und spart Zeit. Stellen Sie sich zum Beispiel vor, wie viel Zeit angehende Wissenschaftler benötigen würden, um alle Formeln zu lernen, wenn sie in Lehrbüchern im Gegensatz zu Mathematik frei in einer gemeinsamen Sprache geschrieben würden.
Unser Ziel ist es daher, alles Ablenkende und Unnötige zu verbergen und nur das zu belassen, was für das Verständnis von entscheidender Bedeutung ist: Was wird getestet, was sind die erwarteten Ein- und Ausgänge.
Kehren wir zu unserem Modell der Teststruktur zurück.
Technisch kann jeder Schritt durch einen Datentyp und jeder Übergang durch eine Funktion dargestellt werden. Um vom ursprünglichen zum endgültigen Datentyp zu gelangen, können Sie jede Funktion auf das Ergebnis des vorherigen anwenden. Mit anderen Worten, durch Verwendung der Funktionszusammensetzung der Datenvorbereitung (nennen wir es prepare ), der Codeausführung ( execute ) und der Überprüfung des erwarteten Ergebnisses ( check ). Die Eingabe für diese Komposition wäre der allererste Schritt - das Gerät. Nennen wir die resultierende Funktion höherer Ordnung die Testlebenszyklusfunktion .
Testen Sie die Lebenszyklusfunktion def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
Es stellt sich die Frage, woher diese bestimmten Funktionen kommen. Nun, was die Datenaufbereitung betrifft, gibt es nur eine begrenzte Anzahl von Möglichkeiten, dies zu tun - eine Datenbank füllen, verspotten usw. Daher ist es praktisch, spezielle Varianten der prepare zu schreiben, die für alle Tests gemeinsam genutzt werden. Infolgedessen wäre es einfacher, für jeden Fall spezielle Testlebenszyklusfunktionen zu erstellen, die konkrete Implementierungen der Datenaufbereitung verbergen würden. Da die Codeausführung und Zusicherungen für jeden Test (oder jede Gruppe von Tests) mehr oder weniger eindeutig sind, müssen execute und check jedes Mal explizit geschrieben werden.
Testlebenszyklusfunktion für Integrationstests in einer Datenbank angepasst Durch die Delegierung aller administrativen Nuancen an die Testlebenszyklusfunktion erhalten wir die Möglichkeit, den Testprozess zu erweitern, ohne einen bestimmten Test zu berühren. Durch die Verwendung der Funktionszusammensetzung können wir in jedem Schritt des Prozesses eingreifen und Daten extrahieren oder hinzufügen.
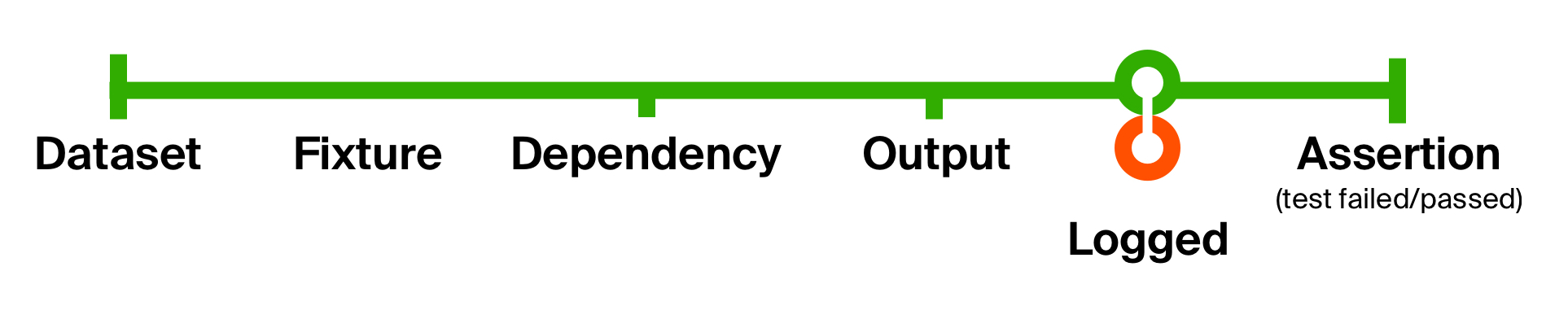
Um die Möglichkeiten eines solchen Ansatzes besser zu veranschaulichen, lösen wir das zweite Problem unseres ersten Tests - das Fehlen zusätzlicher Informationen zur Ermittlung von Problemen. Fügen wir die Protokollierung der zurückgegebenen Codeausführung hinzu. Unsere Protokollierung ändert den Datentyp nicht. Es entsteht nur ein Nebeneffekt - die Ausgabe einer Nachricht an die Konsole. Nach dem Nebeneffekt geben wir es so zurück, wie es ist.
Testen Sie die Lebenszyklusfunktion mit der Protokollierung def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
Mit dieser einfachen Änderung haben wir die Protokollierung der Ausgabe des ausgeführten Codes in jedem Test hinzugefügt. Der Vorteil derart kleiner Funktionen besteht darin, dass sie leicht zu verstehen, zu komponieren und bei Bedarf zu entfernen sind.

Daher sieht unser Test jetzt folgendermaßen aus:
val fixture: SomeMagicalFixture = ???
Der Testkörper wurde präzise, das Gerät und die Prüfungen können in anderen Tests wiederverwendet werden, und wir bereiten die Datenbank nirgendwo mehr manuell vor. Es bleibt nur ein kleines Problem ...
Gerätevorbereitung
Im obigen Code haben wir unter der Annahme gearbeitet, dass das Gerät von irgendwoher an uns übergeben wird. Da Daten der entscheidende Bestandteil wartbarer und unkomplizierter Tests sind, müssen wir uns damit befassen, wie sie einfach erstellt werden können.
Angenommen, unser zu testendes Geschäft verfügt über eine typische mittelgroße relationale Datenbank (der Einfachheit halber enthält es in diesem Beispiel nur 4 Tabellen, in Wirklichkeit können es jedoch Hunderte sein). Einige Tabellen enthalten referenzielle Daten, andere Geschäftsdaten, und all dies kann logisch in eine oder mehrere komplexe Entitäten gruppiert werden. Beziehungen werden mit Fremdschlüsseln verknüpft. Um einen Bonus zu erstellen, ist ein Package erforderlich, für das wiederum ein User erforderlich ist, und so weiter.

Problemumgehungen und Hacks führen nur zu Dateninkonsistenzen und damit zu stundenlangem Debuggen. Aus diesem Grund nehmen wir in keiner Weise Änderungen am Schema vor.
Wir könnten einige Produktionsmethoden verwenden, um es zu füllen, aber selbst bei geringer Kontrolle wirft dies viele schwierige Fragen auf. Was bereitet Daten in Tests für diesen Produktionscode vor? Müssten wir die Tests neu schreiben, wenn sich der Vertrag dieses Codes ändert? Was ist, wenn die Daten vollständig von einem anderen Ort stammen und es keine zu verwendenden Methoden gibt? Wie viele Anforderungen würde es erfordern, eine Entität zu erstellen, die von vielen anderen abhängt?
Ausfüllen der Datenbank im ersten Test insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Verstreute Hilfsmethoden, wie in unserem ersten Beispiel, sind unter einem anderen Deckmantel dasselbe Problem. Sie tragen die Verantwortung für das Management von Abhängigkeiten von uns selbst, die wir vermeiden wollen.
Idealerweise möchten wir eine Datenstruktur, die den Status des gesamten Systems auf einen Blick darstellt. Ein richtiger Kandidat wäre eine Tabelle (oder ein Datensatz wie in PHP oder Python), die nur zusätzliche Felder enthält, die für die Geschäftslogik kritisch sind. Wenn sich dies ändert, ist die Pflege der Tests einfach: Wir ändern lediglich die Felder im Datensatz. Beispiel:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
Aus unserer Tabelle erstellen wir Schlüssel - Entitätsverknüpfungen nach ID. Wenn eine Entität von einer anderen abhängt, wird auch ein Schlüssel für diese andere Entität erstellt. Es kann vorkommen, dass zwei verschiedene Entitäten eine Abhängigkeit mit derselben ID erstellen, was zu einer Verletzung des Primärschlüssels führen kann. Zu diesem Zeitpunkt ist es jedoch unglaublich billig, Schlüssel zu deduplizieren. Da sie nur IDs enthalten, können wir sie in eine Sammlung aufnehmen, die für uns eine Deduplizierung durchführt, z. B. ein Set . Wenn sich dies als unzureichend herausstellt, können wir die intelligentere Deduplizierung immer als separate Funktion implementieren und in die Testlebenszyklusfunktion integrieren.
Schlüssel (Beispiel) sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
Das Generieren gefälschter Daten für Felder (z. B. Namen) wird an eine separate Klasse delegiert. Anschließend erhalten wir mithilfe dieser Klassen- und Konvertierungsregeln für Schlüssel die Zeilenobjekte, die zum Einfügen in die Datenbank vorgesehen sind.
Zeilen (Beispiel) object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Die gefälschten Daten reichen normalerweise nicht aus, daher benötigen wir eine Möglichkeit, bestimmte Felder zu überschreiben. Glücklicherweise sind Objektive genau das, was wir brauchen - wir können sie verwenden, um alle erstellten Zeilen zu durchlaufen und nur die Felder zu ändern, die wir benötigen. Da Objektive Funktionen in Verkleidung sind, können wir sie wie gewohnt zusammenstellen, was ihre größte Stärke ist.
Linse (Beispiel) def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Dank der Komposition können wir verschiedene Optimierungen und Verbesserungen innerhalb des Prozesses anwenden: Beispielsweise könnten wir Zeilen nach Tabelle gruppieren, um sie mit einem einzigen INSERT einzufügen, um die Testausführungszeit zu verkürzen oder den gesamten Status der Datenbank zu protokollieren.
Vorrichtungsvorbereitungsfunktion def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Schließlich bietet uns das Ganze eine Einrichtung. Im Test selbst wird außer dem ursprünglichen Datensatz nichts Zusätzliches angezeigt - alle Details werden durch die Funktionszusammensetzung ausgeblendet.

Unsere Testsuite sieht jetzt so aus:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) "If the buyer's role is" - { "a customer" - { "And the total price of items" - { "< 250 after applying bonuses - no discount" - { "(case: no bonuses)" in calculatePriceFor(dataTable, 1) "(case: has bonuses)" in calculatePriceFor(dataTable, 3) } ">= 250 after applying bonuses" - { "If there are no bonuses - 10% off on the subtotal" in calculatePriceFor(dataTable, 2) "If there are bonuses - 10% off on the subtotal after applying bonuses" in calculatePriceFor(dataTable, 4) } } } "a vip - then they get a 20% off before applying bonuses and then all the other rules apply" in calculatePriceFor(dataTable, 5) }
Und der Hilfecode:
Das Hinzufügen neuer Testfälle zur Tabelle ist eine triviale Aufgabe, mit der wir uns darauf konzentrieren können , mehr Randfälle abzudecken und nicht auf das Schreiben von Boilerplate-Code.
Wiederverwendung der Gerätevorbereitung für verschiedene Projekte
Okay, wir haben eine Menge Code geschrieben, um Fixtures in einem bestimmten Projekt vorzubereiten, und dabei einige Zeit damit verbracht. Was ist, wenn wir mehrere Projekte haben? Sind wir dazu verdammt, das Ganze jedes Mal neu zu erfinden?
Wir können die Fixture-Vorbereitung über ein konkretes Domänenmodell abstrahieren. In der Welt der funktionalen Programmierung gibt es ein Konzept von Typklassen . Ohne auf Details einzugehen, sind sie nicht wie Klassen in OOP, sondern eher wie Schnittstellen, da sie ein bestimmtes Verhalten einer Gruppe von Typen definieren. Der grundlegende Unterschied besteht darin, dass sie nicht vererbt, sondern wie Variablen instanziiert werden. Ähnlich wie bei der Vererbung erfolgt die Auflösung von Typklasseninstanzen jedoch zur Kompilierungszeit . In diesem Sinne können Typklassen wie Erweiterungsmethoden von Kotlin und C # erfasst werden.
Um ein Objekt zu protokollieren, müssen wir nicht wissen, was sich darin befindet, welche Felder und Methoden es hat. Wir kümmern uns nur um ein Verhaltensprotokoll log() mit einer bestimmten Signatur. Das Erweitern jeder einzelnen Klasse mit einer Logged Schnittstelle wäre äußerst mühsam und selbst dann in vielen Fällen nicht möglich - beispielsweise für Bibliotheken oder Standardklassen. Mit Typklassen ist dies viel einfacher. Wir können eine Instanz einer Typklasse namens "Protokolliert" erstellen, z. B. für ein Gerät, um sie in einem für Menschen lesbaren Format zu protokollieren. Für alles andere, das keine Instanz von Logged , können wir einen Fallback bereitstellen: eine Instanz für den Typ Any , der eine Standardmethode toString() , um jedes Objekt in seiner internen Darstellung kostenlos zu protokollieren.
Ein Beispiel für die protokollierte Typklasse und ihre Instanzen trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
Neben der Protokollierung können wir diesen Ansatz während des gesamten Prozesses der Herstellung von Vorrichtungen verwenden. Unsere Lösung schlägt eine abstrakte Methode vor, um Datenbank-Fixtures und eine Reihe von dazugehörigen Typklassen zu erstellen. Es ist das Projekt, das die Verantwortung der Lösung nutzt, um die Instanzen dieser Typklassen zu implementieren, damit das Ganze funktioniert.
Bei der Entwicklung dieses Werkzeugs zur Vorbereitung von Vorrichtungen habe ich die SOLID-Prinzipien als Kompass verwendet, um sicherzustellen, dass es wartbar und erweiterbar ist:
- Das Prinzip der Einzelverantwortung : Jede Typklasse beschreibt ein und nur ein Verhalten eines Typs.
- Das Open / Closed-Prinzip : Wir modifizieren keine der Produktionsklassen. Stattdessen erweitern wir sie um Instanzen von Typklassen.
- Das Liskov-Substitutionsprinzip gilt hier nicht, da wir keine Vererbung verwenden.
- Das Prinzip der Schnittstellentrennung : Wir verwenden viele spezialisierte Typklassen im Gegensatz zu einer globalen.
- Das Prinzip der Abhängigkeitsinversion : Die Funktion zur Vorbereitung von Vorrichtungen hängt nicht von konkreten Typen ab, sondern von abstrakten Typklassen.
Nachdem wir sichergestellt haben, dass alle Prinzipien erfüllt sind, können wir davon ausgehen, dass unsere Lösung wartbar und erweiterbar genug ist, um in verschiedenen Projekten verwendet zu werden.
Nachdem wir die Testlebenszyklusfunktion und die Lösung für die Gerätevorbereitung geschrieben haben, die auch unabhängig von einem konkreten Domänenmodell für eine bestimmte Anwendung ist, sind wir alle bereit, alle verbleibenden Tests zu verbessern.
Fazit
Wir haben vom traditionellen (schrittweisen) Testdesignstil auf funktional umgestellt. Der Schritt-für-Schritt-Stil ist frühzeitig und in kleineren Projekten nützlich, da er Entwickler nicht einschränkt und keine speziellen Kenntnisse erfordert. Wenn jedoch die Anzahl der Tests zu groß wird, fällt ein solcher Stil tendenziell ab. Das Schreiben von Tests im funktionalen Stil wird wahrscheinlich nicht alle Ihre Testprobleme lösen, aber es könnte die Skalierung und Pflege von Tests in Projekten, in denen es Hunderte oder Tausende von Tests gibt, erheblich verbessern. Tests, die im funktionalen Stil geschrieben sind, erweisen sich als prägnanter und konzentrieren sich auf die wesentlichen Dinge (wie Daten, zu testender Code und das erwartete Ergebnis) und nicht auf die Zwischenschritte.
Darüber hinaus haben wir untersucht, wie leistungsfähig Funktionskompositionen und Typklassen in der funktionalen Programmierung sein können. Mit ihrer Hilfe ist es ganz einfach, Lösungen mit Blick auf Erweiterbarkeit und Wiederverwendbarkeit zu entwerfen.
Seit wir den Stil vor einigen Monaten übernommen haben, musste unser Team einige Anstrengungen unternehmen, um sich anzupassen, aber am Ende haben wir das Ergebnis genossen. Neue Tests werden schneller geschrieben, Protokolle machen das Leben viel komfortabler und Datensätze können praktisch überprüft werden, wenn Fragen zu den Feinheiten einiger Logik auftreten. Unser Team ist bestrebt, alle Tests schrittweise auf diesen neuen Stil umzustellen.
Einen Link zur Lösung und ein vollständiges Beispiel finden Sie hier: Github . Viel Spaß beim Testen!