"Berater +" - ein Referenzsystem für Anwälte, Buchhalter und so weiter. Es funktioniert stabil wie eine Uhr. In diesem Beitrag wird empfohlen, diese Uhr in Bezug auf die Textausgabe ein wenig an Ihre Anforderungen anzupassen: Sehen Sie sich an, wie Sie Textinformationen verarbeiten können, die das System mit Python bereitstellt. Arbeiten Sie dabei mit den im Titel deklarierten Textelementen.
Schatten auf dem Zaun
Als Anwalt, der lange Zeit mit dem Hilfsprogramm „Consultant +“ gearbeitet hat, fehlte mir immer die übliche Funktion in diesem System. Diese Funktion war wie folgt. Wenn Änderungen im Regulierungsgesetz auftreten, veröffentlichen die Mitarbeiter von K + einen Überblick über die Änderungen in Form von zwei Textspalten:

Die linke Spalte ist das, was sie vorher war, die rechte Spalte ist die Norm, die jetzt in Kraft ist. Jetzt (vor einigen Jahren) wurde die Funktionalität aktualisiert und die Änderungen sind
fett hervorgehoben und sofort sichtbar. Das ist alles sehr praktisch. Aber es gibt unangenehme Dinge.
Erstens sind einige Normen nicht gegeben, weil Ihr Volumen ist für K + -Mitarbeiter zu groß, und Sie müssen zu den Systemverknüpfungen gehen. Zweitens können Sie diese beiden Spalten nicht einfach in eine reguläre Excel- oder Worttabelle einfügen und kopieren.
Möglicherweise wurde dies absichtlich getan, damit Benutzer aktiver mit dem System arbeiten, einschließlich der Übertragung von nichts von dort.
Nun, ich muss es reparieren.
Die Aufgabe : den Text in zwei Spalten zu verteilen, wo es möglich ist und wo nicht - entfernen Sie einfach die Norm und fügen Sie all dies in eine Excel-Tabelle ein. Lassen Sie uns gleichzeitig sehen, wie Sie die Schriftart, Ausrichtung und andere Kleinigkeiten im Text mithilfe von Python ändern können.
Als Beispiel für unser zukünftiges Programm nehmen wir von K + die Änderungen des Gesetzes "Über JSC". Dieses Gesetz wird oft geändert, daher gibt es noch viel zu tun.
Speichern Sie die Änderungen in einer regulären txt-Datei (z. B. der Edition von .txt). Sie erhalten ungefähr Folgendes:

Es ist also klar, dass jede Änderung durch eine durchgezogene Linie voneinander getrennt ist, die nach dem Speichern die Form zahlreicher „???“ hatte. Es gibt auch eine Änderungsüberschrift, mit der gerechnet werden muss. Bis auf bestimmte Punkte sieht alles einfach aus.
Stoßen Sie also auf Änderungen, die die folgende Form haben:

Hinzu kommt, dass sich einzelne Änderungen in der Länge erheblich unterscheiden.
Wir fahren weiter zu K +.
Erstellen Sie eine neue Datei Consult.py und fügen Sie die ersten Zeilen hinzu:
from __future__ import unicode_literals import codecs import openpyxl
Das openpyxl-Modul ist bereits bekannt. Es ermöglicht Ihnen die Arbeit mit Excel, zwei weitere sind neu. Ihre Funktion besteht darin, russische Zeichen, die von Programmen häufig falsch gelesen werden, korrekt zu verarbeiten.
Erstellen Sie im Voraus eine neue leere Excel-Datei außerhalb des Programms, und benennen Sie sie beispielsweise revision2.xlsx. Wir werden diese Datei mit unserem Programm öffnen und die Daten dort schreiben. Dies wird unsere endgültige Datei sein.
Das Programm öffnet also die Excel-Datei und gibt sie ein:
wb = openpyxl.load_workbook('2.xlsx') sheet=wb.get_active_sheet() x=1 y=0 test=[] test2=[] test3=[]
Außerdem erstellen wir oben 3 leere Listen, in denen wir Daten sammeln: test, test2, test3.
Als nächstes werden wir in die Variable 'a' alles einfügen, was in die Form des Namens der Änderung fallen kann. In y - gibt es eine Trennlinie. Es ist gleich lang:
a=('','','','','','','') y='?????????????????????????????????????????????????????????????????????????'
Nun der lustige Teil.
with open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line
Wir haben die cp1251-codierte TXT-Datei geöffnet. Jede Zeile wurde durch die Streifenmethode vom Ende bis zum Anfang von Leerzeichen befreit.
Wenn die Zeile mit dem Wort "alt" beginnt, überspringen wir es. Warum müssen wir das „Alte“ und das „Neue“ behalten, das ist bereits klar. Als nächstes teilen wir die Zeile: vom Anfang bis zu 35 Zeichen und von 39 Zeichen bis zum Ende. Das heißt, wir beseitigen die Lücke in der Mitte:

Wir setzen den Inhalt des Leerzeichens in Spalte 3 in die Mitte der Zeile, weil Es darf kein Leerzeichen sein, wenn die Änderung in einer Zeile hintereinander geschrieben wird:

Wenn die Zeile mit dem Änderungsheader beginnt (wir haben diese Header in die Variable a geschrieben), schreiben wir diese Zeile sofort, um sie ohne Teilung zu übertreffen, und fügen die Zeile hinzu - x + = 1 (oder x = x + 1). Leere Zeilen, was uns begegnet, vermissen wir.
Betrachten Sie das folgende Codefragment:
if len(col2)==0:
Wenn die Länge von 2 Teilen der Zeichenfolge 0 ist, dh nicht vorhanden ist, erhält test2 den ersten Teil der Zeichenfolge. Wenn in der Zeile ein Leerzeichen vorhanden ist, der zweite Teil der Zeile jedoch nicht vorhanden ist, fallen der erste bzw. der zweite Teil der Zeile in test und test2.
Wenn die Zeile ein Leerzeichen enthält und die Zeile nicht leer ist und mehr als 60 Zeichen lang ist, wird sie zu test3 hinzugefügt.
Wenn die Zeile leer ist, das heißt, wir haben die gesamte Änderung durchlaufen, dann schreiben wir alles, was wir gesammelt haben, in Excel-Zellen und überprüfen gleichzeitig die Lücke im Test (damit sie nicht leer ist) und die Länge von Test3.
Speichern Sie abschließend die Excel-Datei:
wb.save('2.xlsx')
Stile, Schriftart und Textausrichtung in Python
Fügen Sie etwas Schönheit zu unserem Tisch hinzu.
Insbesondere werden wir dafür sorgen, dass bei der Ausgabe von Daten die Änderungsüberschriften fett hervorgehoben werden und der Text selbst kleiner und zum leichteren Lesen formatiert ist.
Mit Python können Sie dies tun. Dazu müssen wir den Code an den Stellen hinzufügen und ändern, an denen wir die Ergebnisse in einer Excel-Datei aufzeichnen:
from openpyxl.styles import Font, Color,NamedStyle, Alignment
al= Alignment(horizontal="justify", vertical="top") ft = Font(name='Calibri', size=9) ft2 = Font(name='Calibri', size=9,bold=True)
if line.startswith(a): sheet.cell(row=x, column=1).value=line
if line==y:
if len(test3)>0:
Das heißt, wir haben nur die anwendbaren Methoden .font und .alignment hinzugefügt.
Das gesamte Programm hatte die Form:
Code from __future__ import unicode_literals import codecs import openpyxl from openpyxl.styles import Font, Color,NamedStyle, Alignment """ 1. Consultant+ , .txt ????????????????????????????????????????????????????????????????????????? 15 1 48 15) 15) excel . word - txt : .txt : 2.xlsx """
Am Ende haben wir also nach der Verarbeitung der Datei durch das Programm eine ziemlich anständige Tabelle mit Gesetzesänderungen:
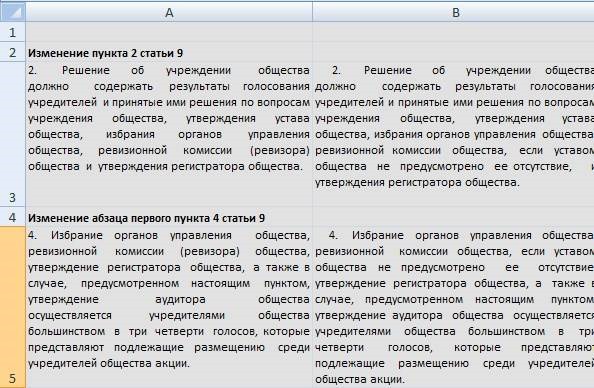
Das Programm kann über den Link
hier heruntergeladen
werden .
Eine Beispieldatei zur Verarbeitung durch das Programm finden Sie
hier .