Hallo an alle. Bis zum Beginn des Kurses für maschinelles Lernen verbleiben noch einige Tage. Im Vorgriff auf den Beginn des Unterrichts haben wir eine nützliche Übersetzung vorbereitet, die sowohl für unsere Schüler als auch für alle Blog-Leser von Interesse sein wird. Und heute teilen wir Ihnen den letzten Teil dieser Übersetzung mit.

Teilabhängigkeitsdiagramme
Partielle Abhängigkeitsdiagramme (partielle Abhängigkeitsdiagramme oder PDP, PD-Diagramme) zeigen einen unbedeutenden Einfluss von einem oder zwei Merkmalen auf das vorhergesagte Ergebnis des maschinellen Lernmodells (
JH Friedman 2001 ). PDP kann die Beziehung zwischen dem Ziel und den ausgewählten Features mithilfe von 1D- oder 2D-Diagrammen anzeigen.
Wie funktioniert es
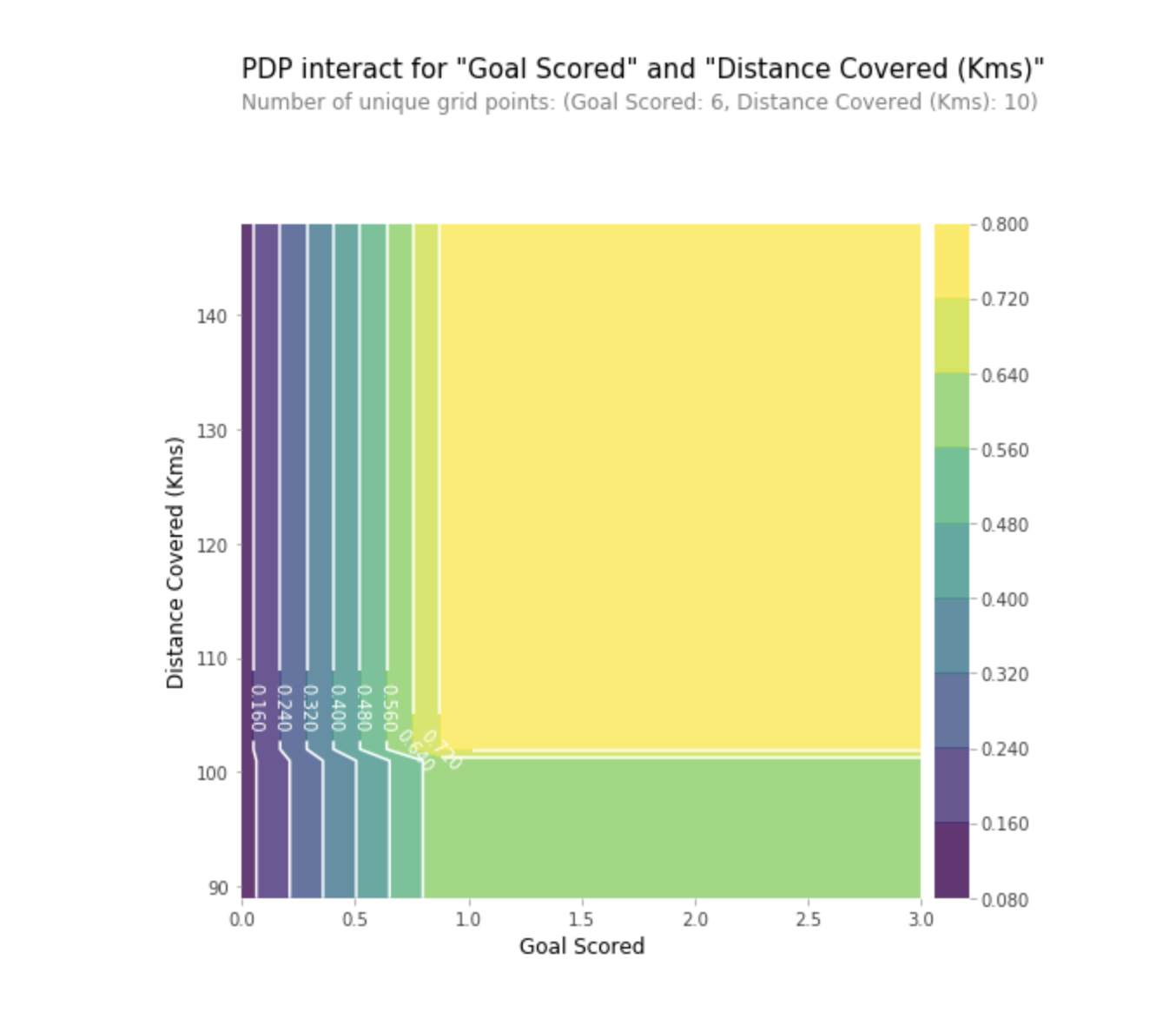
PDPs werden auch nach dem Training des Modells berechnet. In dem oben diskutierten Fußballproblem gab es viele Anzeichen, wie übertragene Vorlagen, Torversuche, erzielte Tore usw. Beginnen wir mit einer Zeile. Nehmen wir an, die Linie ist eine Mannschaft, die 50% der Zeit den Ball hatte und 100 Vorlagen, 10 Torversuche und 1 Tor erzielte.
Wir trainieren unser Modell und berechnen die Wahrscheinlichkeit, dass das Team einen Spieler hat, der „Man of the Game“ erhalten hat, was unsere Zielvariable ist. Dann wählen wir die Variable aus und ändern kontinuierlich ihren Wert. Zum Beispiel berechnen wir das Ergebnis, vorausgesetzt, die Mannschaft hat 1 Tor, 2 Tore, 3 Tore usw. erzielt. Alle diese Werte spiegeln sich in der Grafik wider. Am Ende erhalten wir eine Grafik der Abhängigkeit der vorhergesagten Ergebnisse von den erzielten Toren.
Die in Python zum Erstellen von PDP verwendete Bibliothek wird als Python-Toolbox für partielle Abhängigkeitsdiagramme oder einfach als PDPbox bezeichnet .
from matplotlib import pyplot as plt from pdpbox import pdp, get_dataset, info_plots
Interpretation
- Die Y-Achse repräsentiert die Änderung der Vorhersage aufgrund der im Original oder ganz links vorhergesagten Werte.
- Der blaue Bereich zeigt das Konfidenzintervall an.
- In der Grafik "Tor erzielt" sehen wir, dass ein erzieltes Tor die Wahrscheinlichkeit erhöht, eine Auszeichnung als "Mann des Spiels" zu erhalten. Nach einiger Zeit tritt jedoch eine Sättigung auf.
Mithilfe von 2D-Grafiken können wir auch die teilweise Abhängigkeit zweier Merkmale gleichzeitig visualisieren.
 Übe
ÜbeSHAP-Werte
SHAP steht für SHapley Additive EXPLAIN. Diese Methode hilft, die Prognose in Teile aufzuteilen, um die Bedeutung jedes Merkmals aufzudecken. Es basiert auf Vector Shapley, einem Prinzip, das in der Spieltheorie verwendet wird, um zu bestimmen, wie viel jeder Spieler zu seinem erfolgreichen Ergebnis in einem gemeinsamen Spiel beiträgt (https://medium.com/civis-analytics/demystifying-black-box-models-with-shap-). Wertanalyse-3e20b536fc80). Einen Kompromiss zwischen Genauigkeit und Interpretierbarkeit zu finden, kann oft schwierig sein, aber SHAP-Werte können beides bieten.
Wie funktioniert es
Kehren wir noch einmal zum Beispiel des Fußballs zurück, in dem wir die Wahrscheinlichkeit vorhersagen wollten, dass eine Mannschaft einen Spieler hat, der die Auszeichnung „Mann des Spiels“ gewonnen hat. SHAP - Werte interpretieren den Einfluss eines bestimmten Werts eines Merkmals im Vergleich zu der Prognose, die wir gemacht hätten, wenn dieses Merkmal einen Grundwert angenommen hätte.
SHAP - Werte werden mithilfe der Shap - Bibliothek berechnet, die einfach über PyPI oder conda installiert werden kann.
SHAP - Werte zeigen, wie sehr dieses bestimmte Merkmal unsere Vorhersage verändert hat (im Vergleich dazu, wie wir diese Vorhersage mit einem Grundwert dieses Merkmals gemacht hätten). Angenommen, wir wollten wissen, wie die Prognose aussehen würde, wenn die Mannschaft 3 Tore anstelle eines festen Grundbetrags erzielen würde. Wenn wir diese Frage beantworten können, können wir die gleichen Schritte für andere Zeichen wie folgt ausführen:
sum(SHAP values for all features) = pred_for_team - pred_for_baseline_values
Daher kann die Prognose in Form der folgenden Grafik dargestellt werden:
 Hier ist der Link zum Gesamtbild.
Hier ist der Link zum Gesamtbild.Interpretation
Das obige Beispiel zeigt die Vorzeichen, von denen jedes zur Bewegung der Modellausgabe zum Basiswert (durchschnittliche statistische Ausgabe des Modells gemäß dem zuvor an ihn übergebenen Trainingsdatensatz) zur endgültigen Ausgabe des Modells beiträgt. Zeichen, die die Prognose oben vorantreiben, werden rot angezeigt, und Zeichen, die die Genauigkeit verringern, werden unten angezeigt.
- Der Basiswert beträgt hier 0,4979, während die Prognose 0,7 beträgt.
- Mit
Goal Scores = 2 hat das Merkmal den größten Einfluss auf die Verbesserung der Prognose - Das
ball possession hat den höchsten Effekt auf die Senkung der endgültigen Vorhersage.
Übe
SHAP - Werte haben eine viel tiefere theoretische Rechtfertigung als das, was ich hier erwähnt habe. Folgen Sie dem
Link , um das Problem besser zu verstehen.
Erweiterte Verwendung von SHAP-Werten
Durch das Aggregieren mehrerer SHAP-Werte erhalten Sie eine detailliertere Ansicht des Modells.
Um eine Vorstellung davon zu bekommen, welche Features für das Modell am wichtigsten sind, können wir SHAP-Werte für jedes Feature und für jedes Beispiel erstellen. Das zusammenfassende Diagramm zeigt, welche Funktionen am wichtigsten sind und welchen Einfluss sie auf den Datensatz haben.
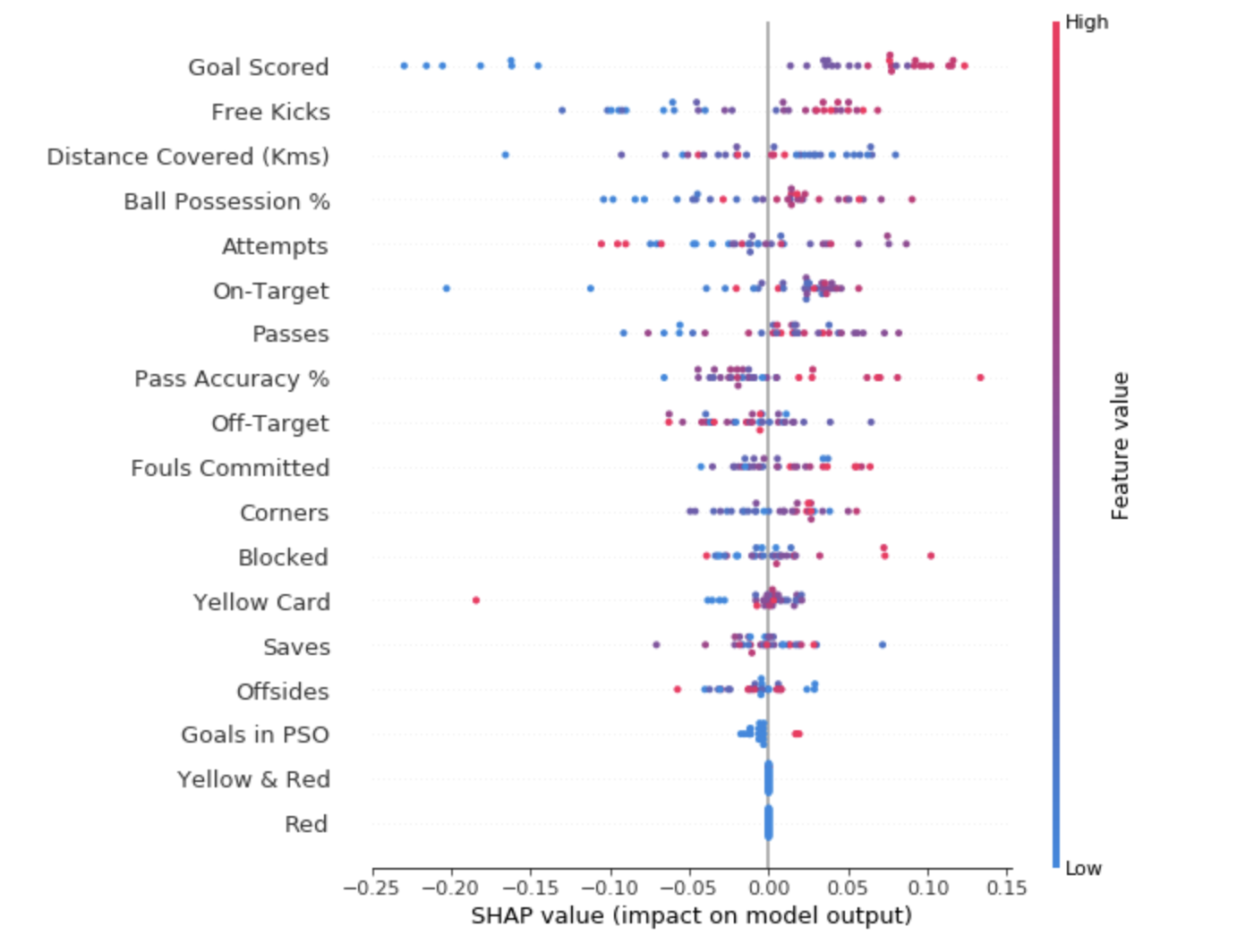
Für jeden Punkt:
- Die vertikale Anordnung zeigt, welches Vorzeichen es widerspiegelt;
- Die Farbe gibt an, ob dieses Objekt für diese Datensatzzeichenfolge von hoher oder schwacher Bedeutung ist.
- Die horizontale Anordnung zeigt, ob der Einfluss des Werts dieses Merkmals zu einer genaueren Vorhersage geführt hat oder nicht.
Der Punkt in der oberen linken Ecke bedeutet, dass die Mannschaft mehrere Tore erzielt hat, die Wahrscheinlichkeit einer erfolgreichen Prognose jedoch um 0,25 verringert hat.
Während das SHAP-Zusammenfassungsdiagramm einen allgemeinen Überblick über jedes Merkmal bietet, zeigt das SHAP-Abhängigkeitsdiagramm, wie die Modellausgabe vom Merkmalwert abhängt. Das SHAP-Beitragsabhängigkeitsdiagramm bietet einen ähnlichen PDP-Einblick, fügt jedoch weitere Details hinzu.
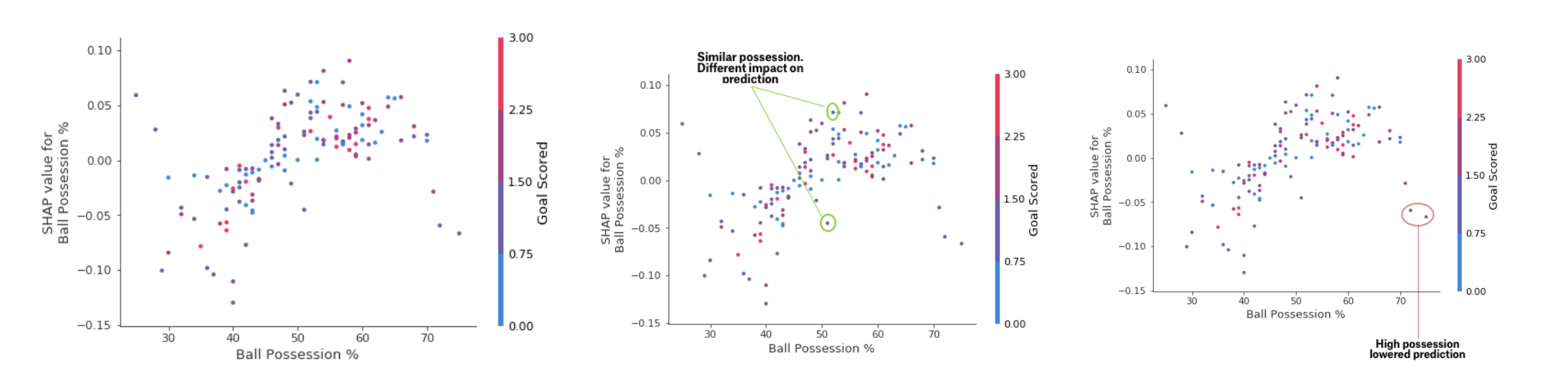 Einzahlungsabhängigkeitstabelle
EinzahlungsabhängigkeitstabelleDie oben dargestellten Grafiken zeigen, dass das Vorhandensein eines Schwertes die Chancen des Teams erhöht, dass es sein Spieler ist, der eine Belohnung erhält. Wenn eine Mannschaft jedoch nur ein Tor erzielt, ändert sich dieser Trend, da die Schiedsrichter entscheiden können, dass die Mannschaftsspieler den Ball zu lange halten und zu wenige Tore erzielen.
ÜbeFazit
Maschinelles Lernen sollte keine Black Box mehr sein. Was nützt ein gutes Modell, wenn wir anderen die Ergebnisse ihrer Arbeit nicht erklären können? Die Interpretierbarkeit ist ebenso wichtig wie die Qualität des Modells. Um Akzeptanz zu erlangen, ist es unerlässlich, dass maschinelle Lernsysteme klare Erklärungen für ihre Entscheidungen liefern können. Wie Albert Einstein sagte: "Wenn Sie etwas nicht in einfacher Sprache erklären können, verstehen Sie es nicht."
Quellen:- "Interpretierbares maschinelles Lernen: Ein Leitfaden, um Black-Box-Modelle erklärbar zu machen." Christoph Molnar
- Erklärungsmikrokurs für maschinelles Lernen bei Kaggle
Lesen Sie den ersten Teil