Googles neue Arbeit bietet eine Architektur neuronaler Netze, die die angeborenen Instinkte und Reflexe von Lebewesen simulieren kann, gefolgt von Weiterbildung während des gesamten Lebens.
Außerdem wird die Anzahl der Verbindungen innerhalb des Netzwerks erheblich reduziert, wodurch die Geschwindigkeit erhöht wird.
Künstliche neuronale Netze sind zwar im Prinzip biologischen ähnlich, unterscheiden sich jedoch immer noch zu stark von ihnen, um in ihrer reinen Form eine starke KI zu erzeugen. Zum Beispiel ist es jetzt unmöglich, ein Modell einer Person in einem Simulator (oder einer Maus oder sogar einem Insekt) zu erstellen, ihm ein „Gehirn“ in Form eines modernen neuronalen Netzwerks zu geben und es zu trainieren. Es funktioniert einfach nicht.
Selbst wenn die Unterschiede im Lernmechanismus (zum Beispiel im Gehirn gibt es kein genaues Analogon zum Algorithmus zur Fehlerrückübertragung) und das Fehlen von Zeitskorrelationen mit mehreren Maßstäben, auf deren Grundlage das biologische Gehirn seine Arbeit aufbaut, verworfen werden, haben künstliche neuronale Netze mehrere weitere Probleme, die es ihnen nicht ermöglichen, ausreichend zu simulieren lebendes Gehirn. Es ist wahrscheinlich, dass aufgrund dieser inhärenten Probleme des jetzt verwendeten mathematischen Apparats das Reinforcement Learning, das darauf ausgelegt ist, die Ausbildung von Lebewesen auf der Grundlage der Belohnung so weit wie möglich nachzuahmen, in der Praxis nicht so gut funktioniert, wie wir es uns wünschen. Obwohl es auf wirklich guten und richtigen Ideen basiert. Die Entwickler selbst scherzen, dass das Gehirn RNN + A3C ist (d. H. Ein wiederkehrender Netzwerk + Schauspieler-Kritiker-Algorithmus für sein Training).
Einer der auffälligsten Unterschiede zwischen dem biologischen Gehirn und künstlichen neuronalen Netzen besteht darin, dass die Struktur des lebenden Gehirns durch Millionen von Jahren Evolution vorkonfiguriert ist. Obwohl der Neokortex, der für die höhere Nervenaktivität bei Säugetieren verantwortlich ist, eine annähernd einheitliche Struktur aufweist, ist die allgemeine Struktur des Gehirns durch Gene klar definiert. Darüber hinaus haben andere Tiere als Säugetiere (Vögel, Fische) überhaupt keinen Neokortex, zeigen aber gleichzeitig ein komplexes Verhalten, das mit modernen neuronalen Netzen nicht erreichbar ist. Eine Person hat auch körperliche Einschränkungen in der Struktur des Gehirns, die schwer zu erklären sind. Beispielsweise beträgt die Auflösung eines Auges ungefähr 100 Megapixel (~ 100 Millionen lichtempfindliche Stäbchen und Zapfen), was bedeutet, dass der Videostream von zwei Augen ungefähr 200 Megapixel mit einer Frequenz von mindestens 15 Bildern pro Sekunde betragen sollte. In Wirklichkeit kann der Sehnerv jedoch nicht mehr als 2-3 Megapixel durch sich hindurchtreten. Und seine Verbindungen richten sich überhaupt nicht auf den nächstgelegenen Teil des Gehirns, sondern auf den okzipitalen Teil des visuellen Kortex.
Ohne die Bedeutung des Neokortex zu beeinträchtigen (grob gesagt kann er bei der Geburt als Analogon zufällig initiierter moderner neuronaler Netze angesehen werden), legen die Fakten nahe, dass sogar eine Person eine große Rolle in einer vorbestimmten Gehirnstruktur spielt. Wenn zum Beispiel ein Baby nur wenige Minuten alt ist, um seine Zunge zu zeigen, wird es dank Spiegelneuronen auch seine Zunge herausstrecken. Das gleiche passiert mit dem Lachen der Kinder. Es ist bekannt, dass Babys von Geburt an mit ausgezeichneter Erkennung menschlicher Gesichter „genäht“ wurden. Noch wichtiger ist jedoch, dass das Nervensystem aller Lebewesen für ihre Lebensbedingungen optimiert ist. Das Baby wird stundenlang nicht weinen, wenn es hungrig ist. Er wird müde werden. Oder Angst vor etwas und halt die Klappe. Der Fuchs wird nicht erschöpft sein, bis der Hunger nach unzugänglichen Trauben greift. Sie wird mehrere Versuche machen, entscheiden, dass er bitter ist und gehen. Und dies ist kein Lernprozess, sondern ein von der Biologie vorgegebenes Verhalten. Darüber hinaus haben verschiedene Arten unterschiedliche. Einige Raubtiere eilen sofort nach Beute, während andere lange Zeit im Hinterhalt sitzen. Und sie lernten dies nicht durch Versuch und Irrtum, sondern so ist ihre Biologie, gegeben durch Instinkte. Ebenso haben viele Tiere von den ersten Lebensminuten an Programme zur Vermeidung von Raubtieren verkabelt, obwohl sie diese physisch noch nicht lernen konnten.
Theoretisch können moderne Methoden zum Trainieren neuronaler Netze von einem vollständig verbundenen Netzwerk aus die Ähnlichkeit eines solchen vorab trainierten Gehirns erzeugen, unnötige Verbindungen auf Null setzen (tatsächlich abschneiden) und nur die notwendigen Verbindungen belassen. Dies erfordert jedoch eine Vielzahl von Beispielen, es ist nicht bekannt, wie sie trainiert werden sollen, und vor allem gibt es derzeit keine guten Möglichkeiten, diese "anfängliche" Struktur des Gehirns zu reparieren. Das anschließende Training ändert diese Gewichte und alles wird schlecht.
Forscher von Google haben diese Frage ebenfalls gestellt. Ist es möglich, eine anfängliche Gehirnstruktur ähnlich der biologischen zu erstellen, die bereits für die Lösung des Problems gut optimiert ist, und sie dann nur neu zu trainieren? Theoretisch wird dies den Lösungsraum dramatisch einschränken und es Ihnen ermöglichen, neuronale Netze schnell zu trainieren.
Leider arbeiten vorhandene Algorithmen zur Optimierung der Netzwerkstruktur wie die Neural Architecture Search (NAS) mit ganzen Blöcken. Nach dem Hinzufügen oder Entfernen muss das neuronale Netzwerk von Grund auf neu trainiert werden. Dies ist ein ressourcenintensiver Prozess, der das Problem nicht vollständig löst.
Daher schlugen die Forscher eine vereinfachte Version vor, die als "Weight Agnostic Neural Networks" (WANN) bezeichnet wird. Die Idee ist, alle Gewichte eines neuronalen Netzwerks durch ein "gemeinsames" Gewicht zu ersetzen. Und im Lernprozess geht es nicht darum, Gewichte zwischen Neuronen auszuwählen, wie in gewöhnlichen neuronalen Netzen, sondern um die Struktur des Netzwerks selbst (Anzahl und Position der Neuronen), die mit den gleichen Gewichten die besten Ergebnisse zeigt. Optimieren Sie es anschließend so, dass das Netzwerk mit allen möglichen Werten dieses Gesamtgewichts gut funktioniert (gemeinsam für alle Verbindungen zwischen Neuronen!).
Dies ergibt die Struktur eines neuronalen Netzwerks, das nicht von bestimmten Gewichten abhängt, sondern mit jedem gut funktioniert. Weil es aufgrund der gesamten Netzwerkstruktur funktioniert. Dies ähnelt dem Gehirn eines Tieres, das bei der Geburt noch nicht mit bestimmten Skalen initialisiert wurde, aber aufgrund seiner allgemeinen Struktur bereits eingebettete Instinkte enthält. Und die anschließende Feinabstimmung der Skalen während des Trainings während des gesamten Lebens macht dieses neuronale Netzwerk noch besser.
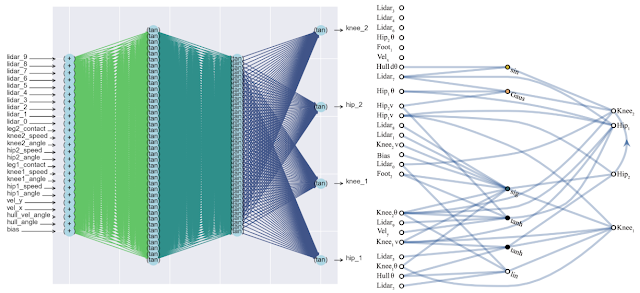
Ein positiver Nebeneffekt dieses Ansatzes ist eine signifikante Verringerung der Anzahl von Neuronen im Netzwerk (da nur die wichtigsten Verbindungen übrig bleiben), was seine Geschwindigkeit erhöht. Nachfolgend finden Sie einen Vergleich der Komplexität eines klassischen vollständig verbundenen neuronalen Netzwerks (links) und eines passenden neuen (rechts).
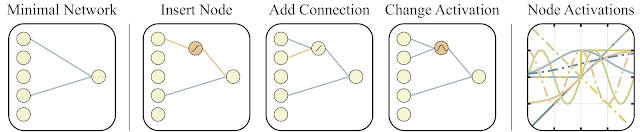
Um nach einer solchen Architektur zu suchen, verwendeten die Forscher den Topologie-Suchalgorithmus (NEAT). Zuerst wird eine Reihe einfacher neuronaler Netze erstellt, und dann wird eine von drei Aktionen ausgeführt: Ein neues Neuron wird zu der bestehenden Verbindung zwischen zwei Neuronen hinzugefügt, eine neue Verbindung mit zufälligen Neuronen wird zu einem anderen Neuron hinzugefügt oder die Aktivierungsfunktion in den Neuronen ändert sich (siehe die folgenden Abbildungen). Und dann werden im Gegensatz zum klassischen NAS, bei dem nach optimalen Gewichten zwischen Neuronen gesucht wird, hier alle Gewichte mit einer einzigen Zahl initialisiert. Und es wird eine Optimierung durchgeführt, um die Netzwerkstruktur zu finden, die in einem weiten Wertebereich dieses einen Gesamtgewichts am besten funktioniert. Auf diese Weise wird ein Netzwerk erhalten, das nicht vom spezifischen Gewicht zwischen Neuronen abhängt, sondern im gesamten Bereich gut funktioniert (aber alle Gewichte werden immer noch durch eine Zahl initiiert und unterscheiden sich nicht wie in normalen Netzwerken). Darüber hinaus versuchen sie als zusätzliches Ziel für die Optimierung, die Anzahl der Neuronen im Netzwerk zu minimieren.
Nachfolgend finden Sie eine allgemeine Übersicht über den Algorithmus.
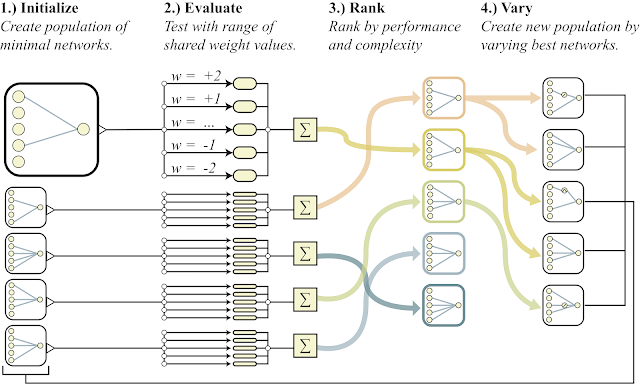
- schafft eine Population einfacher neuronaler Netze
- Jedes Netzwerk initialisiert alle seine Gewichte mit einer Zahl und für einen weiten Bereich von Zahlen: w = -2 ... + 2
- Die resultierenden Netzwerke werden nach der Qualität der Lösung des Problems und nach der Anzahl der Neuronen (nach unten) sortiert.
- Im Teil der besten Vertreter wird ein Neuron hinzugefügt, eine Verbindung oder die Aktivierungsfunktion in einem Neuron ändert sich
- Diese modifizierten Netzwerke werden als Initiale in Punkt 1) verwendet.
All dies ist gut, aber Hunderte, wenn nicht Tausende verschiedener Ideen wurden für neuronale Netze vorgeschlagen. Funktioniert das in der Praxis? Ja, das tut es. Nachfolgend finden Sie ein Beispiel für das Suchergebnis einer solchen Netzwerkarchitektur für das klassische Pendelwagenproblem. Wie aus der Abbildung ersichtlich, funktioniert das neuronale Netzwerk gut mit allen Varianten des Gesamtgewichts (besser mit +1,0, versucht aber auch, das Pendel von -1,5 anzuheben). Und nachdem dieses einzelne Gewicht optimiert wurde, funktioniert es einwandfrei (Option „Fein abgestimmte Gewichte“ in der Abbildung).
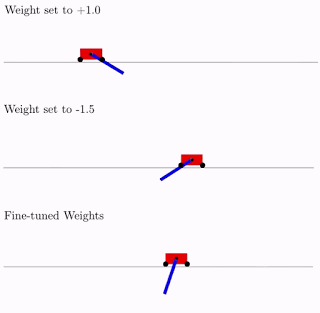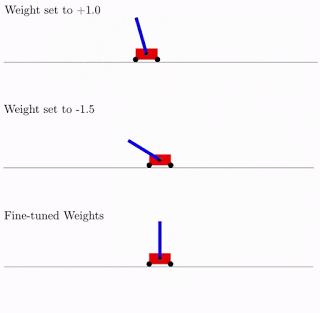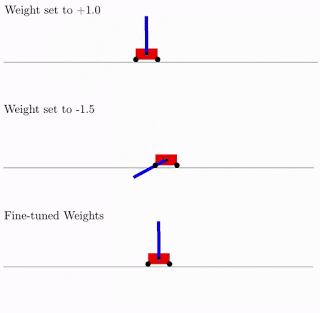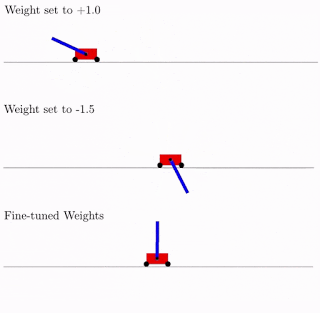
In der Regel können Sie dieses einzelne Gesamtgewicht neu trainieren, da die Auswahl der Architektur auf einer begrenzten diskreten Anzahl von Parametern erfolgt (im obigen Beispiel -2, -1,1,2). Und Sie können einen genaueren optimalen Parameter erhalten, z. B. 1,5. Und Sie können das beste Gesamtgewicht als Ausgangspunkt für die Umschulung aller Gewichte verwenden, wie beim klassischen Training neuronaler Netze.
Dies ähnelt der Art und Weise, wie Tiere trainiert werden. Mit Instinkten, die bei der Geburt nahezu optimal sind, und unter Verwendung dieser durch die Gene vorgegebenen Gehirnstruktur als erste trainieren die Tiere im Laufe ihres Lebens ihr Gehirn unter bestimmten äußeren Bedingungen. Weitere Details in einem kürzlich erschienenen Artikel in der Zeitschrift Nature .
Unten finden Sie ein Beispiel für ein Netzwerk, das WANN für eine pixelbasierte Maschinensteuerungsaufgabe gefunden hat. Bitte beachten Sie, dass dies eine Fahrt mit dem "bloßen Instinkt" ist, mit dem gleichen Gesamtgewicht in allen Gelenken, ohne die klassische Feinabstimmung aller Gewichte. Gleichzeitig ist das neuronale Netzwerk äußerst einfach aufgebaut.
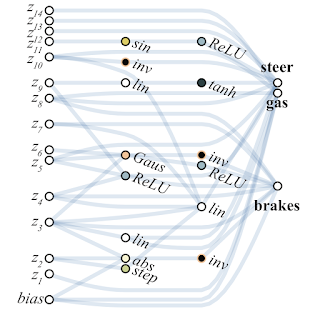

Forscher schlagen vor, Ensembles aus WANN-Netzwerken als weiteren Anwendungsfall für WANN zu erstellen. Das übliche zufällig initialisierte neuronale Netzwerk auf MNIST zeigt also eine Genauigkeit von etwa 10%. Ein ausgewähltes einzelnes neuronales WANN-Netzwerk liefert ungefähr 80%, aber ein Ensemble von WANN mit unterschiedlichen Gesamtgewichten zeigt bereits> 90%.
Infolgedessen ahmt die von Google-Forschern vorgeschlagene Methode zur Suche nach der anfänglichen Architektur eines optimalen neuronalen Netzwerks nicht nur das Lernen von Tieren nach (Geburt mit eingebauten optimalen Instinkten und Umschulung während des Lebens), sondern vermeidet auch die Simulation des gesamten Tierlebens durch vollwertiges Lernen des gesamten Netzwerks in klassischen evolutionären Algorithmen Einfache und schnelle Netzwerke gleichzeitig. Das reicht aus, um ein wenig zu trainieren, um ein vollständig optimales neuronales Netzwerk zu erhalten.
Referenzen
- Google AI-Blogeintrag
- Ein interaktiver Artikel, in dem Sie das Gesamtgewicht ändern und das Ergebnis überwachen können
- Naturartikel über die Bedeutung eingebetteter Instinkte bei der Geburt